Supervised Learning Evaluation (via Sentiment Analysis)!
|
|
|
- Leo Cox
- 7 years ago
- Views:
Transcription
1 Supervised Learning Evaluation (via Sentiment Analysis)!

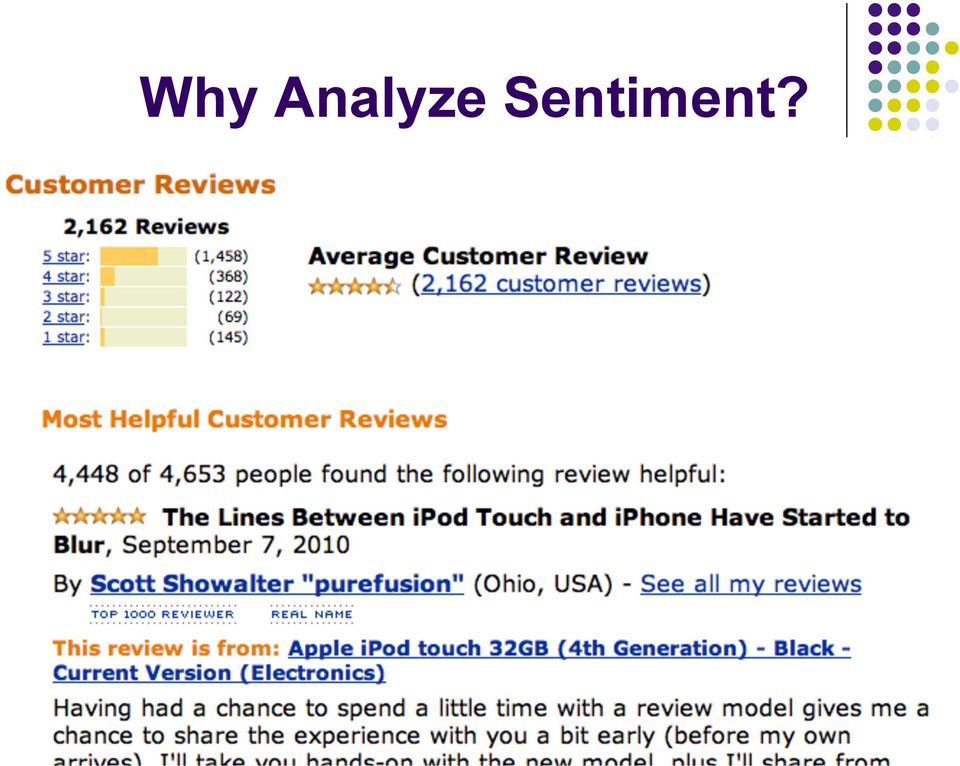
2 Why Analyze Sentiment?
3 Sentiment Analysis (Opinion Mining) Automatically label documents with their sentiment Toward a topic Aggregated over documents More fine-grained analysis Within specific domains

4 Sentiment Analysis - Approaches

5 What are the challenges to Sentiment Analysis? domain specificity thwarted expectations sarcasm and subtle nature of sentiment sufficient, high quality training data

6 What are the challenges to Sentiment Analysis? Cold Small

7 What are the challenges to Sentiment Analysis? domain specificity thwarted expectations sarcasm and subtle nature of sentiment sufficient, high quality training data

8 What are the challenges to Sentiment Analysis? domain specificity This film should be brilliant It sounds like a great plot, the actors are first grade, and the supporting cast is good as well, and Stallone is attempting to deliver a good performance However, it can t hold up (Pang et al, 2002) thwarted expectations sarcasm and subtle nature of sentiment sufficient, high quality training data
 thwarted expectations sarcasm and subtle")
9 What are the challenges to Sentiment Analysis? domain specificity thwarted expectations sarcasm and subtle nature of sentiment sufficient, high quality training data

10 What are the challenges to Sentiment Analysis? domain specificity thwarted expectations sarcasm and subtle nature of sentiment sufficient, high quality training data

11 Supervised Classification Example

12 Supervised Classification Example
13 Supervised Classification Example

14 Supervised Classification Example
15 Supervised Classification Example
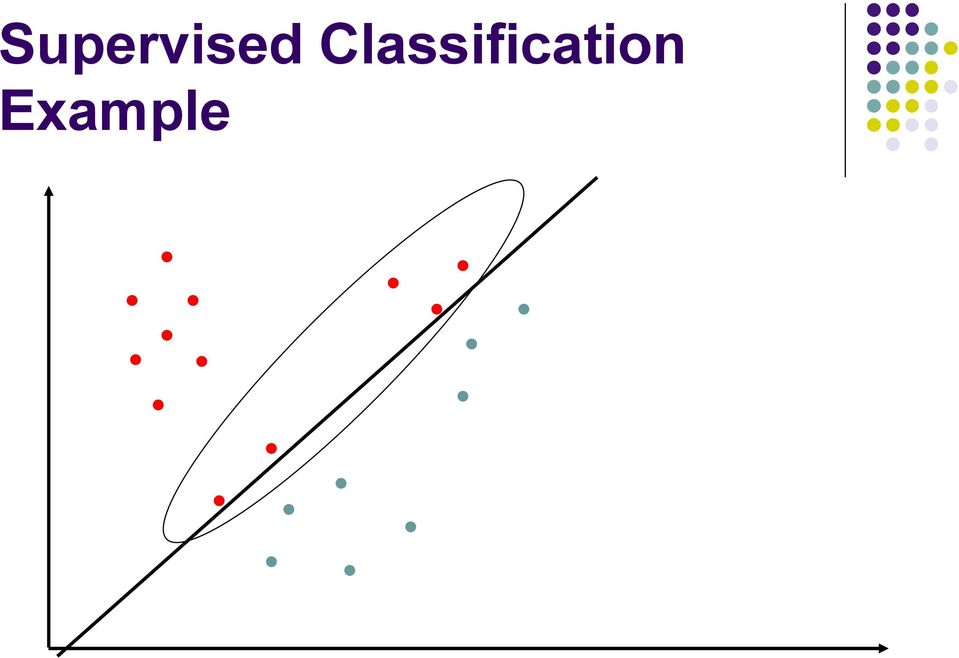
16 Supervised Classification Example Accuracy

17 Supervised Classification Example Accuracy 15/20 = 075

18 Supervised Classification Example Accuracy 15/20 = 075 Precision

19 Supervised Classification Example Accuracy 15/20 = 075 Precision 7/12 = 058

20 Supervised Classification Example Accuracy 15/20 = 075 Precision 7/12 = 058 Recall

21 Supervised Classification Example Accuracy 15/20 = 075 Precision 7/12 = 058 Recall 7/7 = 10
22 Supervised Classification Example Accuracy 15/20 = 075 Precision 7/12 = 058 Recall 7/7 = 10 F1 (2PR/(P+R))
23 Supervised Classification Example Accuracy 15/20 = 075 Precision 7/12 = 058 Recall 7/7 = 10 F1 (2PR/(P+R)) = 073
24 Supervised ML in practice Supervised learning algorithm choice Support Vector Machines Naïve Bayes Neural Networks Decision Trees Configuration Feature Selection Training Data =
25 Unsupervised Clustering Example
26 Unsupervised Clustering Example
27 Evaluation: Classic Reuters Data Set Sec 1524 Most (over)used data set documents 9603 training, 3299 test articles (ModApte split) 118 categories An article can be in more than one category Learn 118 binary category distinctions (118 2-class classifiers) Average number of classes assigned 124 for docs with at least one category Only about 10 out of 118 categories are large Common categories (#train, #test) Earn (2877, 1087) Acquisitions (1650, 179) Money-fx (538, 179) Grain (433, 149) Crude (389, 189) Trade (369,119) Interest (347, 131) Ship (197, 89) Wheat (212, 71) Corn (182, 56) 27
28 Reuters Text Categorization data set (Reuters-21578) document Sec 1524 <REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="12981" NEWID="798"> <DATE> 2-MAR :51:4342</DATE> <TOPICS><D>livestock</D><D>hog</D></TOPICS> <TITLE>AMERICAN PORK CONGRESS KICKS OFF TOMORROW</TITLE> <DATELINE> CHICAGO, March 2 - </DATELINE><BODY>The American Pork Congress kicks off tomorrow, March 3, in Indianapolis with 160 of the nations pork producers from 44 member states determining industry positions on a number of issues, according to the National Pork Producers Council, NPPC Delegates to the three day Congress will be considering 26 resolutions concerning various issues, including the future direction of farm policy and the tax law as it applies to the agriculture sector The delegates will also debate whether to endorse concepts of a national PRV (pseudorabies virus) control and eradication program, the NPPC said A large trade show, in conjunction with the congress, will feature the latest in technology in all areas of the industry, the NPPC added Reuter </BODY></TEXT></REUTERS> 28
29 Sec 1524 Per class evaluation measures Recall: Fraction of docs in class i classified correctly: Precision: Fraction of docs assigned class i that are actually about class i: j j c ii c ij c ii c ji F Measure (F1) = 2PR/(P + R) Accuracy: Fraction of docs classified correctly: i j c ii i c ij 29
30 Sec 1524 Confusion Matrix This (i, j) entry means 53 of the docs actually in class i were put in class j by the classifier Class assigned by classifier Actual Class 53 30
31 Sec 1524 Micro- vs Macro-Averaging If we have more than one class, how do we combine multiple performance measures into one quantity? Macroaveraging: Compute performance for each class, then average Microaveraging: Collect decisions for all classes, compute contingency table, evaluate 31
32 Micro- vs Macro-Averaging: Example Sec 1524 Class 1 Class 2 Micro Ave Table Truth: yes Truth: no Truth: yes Truth: no Truth: yes Truth: no Classifi er: yes Classifi er: yes Classifier: yes Classifi er: no Classifi er: no Classifier: no Macroaveraged precision: ( )/2 = 07 Microaveraged precision: 100/120 = 83 Microaveraged score is dominated by score on common classes 32
33 Vector Space Model each document is a vector similarity of two documents = distance between two vectors A query is just a short document Rank all docs by their distance to the query What s the right distance metric? Cosine Similarity the dot-product (sum of products) of two normalized vectors happens to be cosine of the angle between them! (d j d k )/( d j d k ) = cos(θ) θ 33
34 TFIDF What terms are most important? 34
35 TFIDF example TF IDF (Term Frequency Inverse Doc Frequency) For each doc d, and a term t TFIDF = (freq of t in d)/(total #words in d) TF / (#docs with this term)/(total #docs) IDF 35
36 TFIDF in practice Term frequency and document frequency tables are both calculated in the indexing process Used to summarize a document 36
37 Sec
38 Yang&Liu: SVM vs Other Methods Sec
39 Naïve Bayes Classifier: Naïve Bayes Assumption P(c j ) Estimated from the frequency of classes in the training examples P(x 1, x 2,, x n c j ) Could only be estimated from a very large number of training examples Naïve Bayes Conditional Independence Assumption: Assume that the prob of observing the conjunction of attributes is equal to the product of the indiv probs P(x i c j )
40
41 P(pos features) = P(pos)* product of probabilities P(feature pos) = P(pos) * P( pomona pos) * P( college pos) * P( is pos) * P( great pos) =0333 * 6/5000 * 100/5000 * 98/5000 * 40/5000
42 Naïve Bayes Classification Emotion Classifier Pomona College is great input output Positive 300 Reviews of Colleges
43 Words Positive Doc Count Negative Doc Count Neutral Doc Count pomona college great the bad is Total count
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
1 o Semestre 2007/2008
 Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus
 Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Facebook Friend Suggestion Eytan Daniyalzade and Tim Lipus 1. Introduction Facebook is a social networking website with an open platform that enables developers to extract and utilize user information
Reference Books. Data Mining. Supervised vs. Unsupervised Learning. Classification: Definition. Classification k-nearest neighbors
 Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Classification k-nearest neighbors Data Mining Dr. Engin YILDIZTEPE Reference Books Han, J., Kamber, M., Pei, J., (2011). Data Mining: Concepts and Techniques. Third edition. San Francisco: Morgan Kaufmann
Introduction to Data Mining
 Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
Introduction to Data Mining Jay Urbain Credits: Nazli Goharian & David Grossman @ IIT Outline Introduction Data Pre-processing Data Mining Algorithms Naïve Bayes Decision Tree Neural Network Association
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Projektgruppe. Categorization of text documents via classification
 Projektgruppe Steffen Beringer Categorization of text documents via classification 4. Juni 2010 Content Motivation Text categorization Classification in the machine learning Document indexing Construction
Projektgruppe Steffen Beringer Categorization of text documents via classification 4. Juni 2010 Content Motivation Text categorization Classification in the machine learning Document indexing Construction
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
Anti-Spam Filter Based on Naïve Bayes, SVM, and KNN model
 AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Sentiment Analysis of Movie Reviews and Twitter Statuses. Introduction
 Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Sentiment Analysis of Movie Reviews and Twitter Statuses Introduction Sentiment analysis is the task of identifying whether the opinion expressed in a text is positive or negative in general, or about
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification
 Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati tnpatil2@gmail.com, ss_sherekar@rediffmail.com
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati tnpatil2@gmail.com, ss_sherekar@rediffmail.com
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Car Insurance. Jan Tomášek Štěpán Havránek Michal Pokorný
 Car Insurance Jan Tomášek Štěpán Havránek Michal Pokorný Competition details Jan Tomášek Official text As a customer shops an insurance policy, he/she will receive a number of quotes with different coverage
Car Insurance Jan Tomášek Štěpán Havránek Michal Pokorný Competition details Jan Tomášek Official text As a customer shops an insurance policy, he/she will receive a number of quotes with different coverage
Performance Metrics for Graph Mining Tasks
 Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Framing Business Problems as Data Mining Problems
 Framing Business Problems as Data Mining Problems Asoka Diggs Data Scientist, Intel IT January 21, 2016 Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Framing Business Problems as Data Mining Problems Asoka Diggs Data Scientist, Intel IT January 21, 2016 Legal Notices This presentation is for informational purposes only. INTEL MAKES NO WARRANTIES, EXPRESS
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
TF-IDF. David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt
 TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
TF-IDF David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt Administrative Homework 3 available soon Assignment 2 available soon Popular media article
10-601. Machine Learning. http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
 10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
Machine Learning: Overview
 Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Machine Learning: Overview Why Learning? Learning is a core of property of being intelligent. Hence Machine learning is a core subarea of Artificial Intelligence. There is a need for programs to behave
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Data Mining Fundamentals
 Part I Data Mining Fundamentals Data Mining: A First View Chapter 1 1.11 Data Mining: A Definition Data Mining The process of employing one or more computer learning techniques to automatically analyze
Part I Data Mining Fundamentals Data Mining: A First View Chapter 1 1.11 Data Mining: A Definition Data Mining The process of employing one or more computer learning techniques to automatically analyze
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Why is Internal Audit so Hard?
 Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Towards Effective Recommendation of Social Data across Social Networking Sites
 Towards Effective Recommendation of Social Data across Social Networking Sites Yuan Wang 1,JieZhang 2, and Julita Vassileva 1 1 Department of Computer Science, University of Saskatchewan, Canada {yuw193,jiv}@cs.usask.ca
Towards Effective Recommendation of Social Data across Social Networking Sites Yuan Wang 1,JieZhang 2, and Julita Vassileva 1 1 Department of Computer Science, University of Saskatchewan, Canada {yuw193,jiv}@cs.usask.ca
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
203.4770: Introduction to Machine Learning Dr. Rita Osadchy
 203.4770: Introduction to Machine Learning Dr. Rita Osadchy 1 Outline 1. About the Course 2. What is Machine Learning? 3. Types of problems and Situations 4. ML Example 2 About the course Course Homepage:
203.4770: Introduction to Machine Learning Dr. Rita Osadchy 1 Outline 1. About the Course 2. What is Machine Learning? 3. Types of problems and Situations 4. ML Example 2 About the course Course Homepage:
SI485i : NLP. Set 6 Sentiment and Opinions
 SI485i : NLP Set 6 Sentiment and Opinions It's about finding out what people think... Can be big business Someone who wants to buy a camera Looks for reviews online Someone who just bought a camera Writes
SI485i : NLP Set 6 Sentiment and Opinions It's about finding out what people think... Can be big business Someone who wants to buy a camera Looks for reviews online Someone who just bought a camera Writes
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis
 Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Detecting E-mail Spam Using Spam Word Associations
 Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 p10co977@coed.svnit.ac.in 2 dpr@coed.svnit.ac.in
Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 p10co977@coed.svnit.ac.in 2 dpr@coed.svnit.ac.in
Introduction to Information Retrieval http://informationretrieval.org
 Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Introduction to Information Retrieval http://informationretrieval.org IIR 6&7: Vector Space Model Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 2011-08-29 Schütze:
Statistical Validation and Data Analytics in ediscovery. Jesse Kornblum
 Statistical Validation and Data Analytics in ediscovery Jesse Kornblum Administrivia Silence your mobile Interactive talk Please ask questions 2 Outline Introduction Big Questions What Makes Things Similar?
Statistical Validation and Data Analytics in ediscovery Jesse Kornblum Administrivia Silence your mobile Interactive talk Please ask questions 2 Outline Introduction Big Questions What Makes Things Similar?
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
A Decision Support Approach based on Sentiment Analysis Combined with Data Mining for Customer Satisfaction Research
 145 A Decision Support Approach based on Sentiment Analysis Combined with Data Mining for Customer Satisfaction Research Nafissa Yussupova, Maxim Boyko, and Diana Bogdanova Faculty of informatics and robotics
145 A Decision Support Approach based on Sentiment Analysis Combined with Data Mining for Customer Satisfaction Research Nafissa Yussupova, Maxim Boyko, and Diana Bogdanova Faculty of informatics and robotics
Machine Learning. Mausam (based on slides by Tom Mitchell, Oren Etzioni and Pedro Domingos)
") Machine Learning Mausam (based on slides by Tom Mitchell, Oren Etzioni and Pedro Domingos) What Is Machine Learning? A computer program is said to learn from experience E with respect to some class of
Machine Learning Mausam (based on slides by Tom Mitchell, Oren Etzioni and Pedro Domingos) What Is Machine Learning? A computer program is said to learn from experience E with respect to some class of
The Enron Corpus: A New Dataset for Email Classification Research
 The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
F. Aiolli - Sistemi Informativi 2007/2008
 Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
Text Categorization Text categorization (TC - aka text classification) is the task of buiding text classifiers, i.e. sofware systems that classify documents from a domain D into a given, fixed set C =
STATISTICA. Financial Institutions. Case Study: Credit Scoring. and
 Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
CONTENTS PREFACE 1 INTRODUCTION 1 2 DATA VISUALIZATION 19
 PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
PREFACE xi 1 INTRODUCTION 1 1.1 Overview 1 1.2 Definition 1 1.3 Preparation 2 1.3.1 Overview 2 1.3.2 Accessing Tabular Data 3 1.3.3 Accessing Unstructured Data 3 1.3.4 Understanding the Variables and Observations
Eng. Mohammed Abdualal
 Islamic University of Gaza Faculty of Engineering Computer Engineering Department Information Storage and Retrieval (ECOM 5124) IR HW 5+6 Scoring, term weighting and the vector space model Exercise 6.2
Islamic University of Gaza Faculty of Engineering Computer Engineering Department Information Storage and Retrieval (ECOM 5124) IR HW 5+6 Scoring, term weighting and the vector space model Exercise 6.2
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Recognition. Sanja Fidler CSC420: Intro to Image Understanding 1 / 28
 Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Recognition Topics that we will try to cover: Indexing for fast retrieval (we still owe this one) History of recognition techniques Object classification Bag-of-words Spatial pyramids Neural Networks Object
Personalized Hierarchical Clustering
 Personalized Hierarchical Clustering Korinna Bade, Andreas Nürnberger Faculty of Computer Science, Otto-von-Guericke-University Magdeburg, D-39106 Magdeburg, Germany {kbade,nuernb}@iws.cs.uni-magdeburg.de
Personalized Hierarchical Clustering Korinna Bade, Andreas Nürnberger Faculty of Computer Science, Otto-von-Guericke-University Magdeburg, D-39106 Magdeburg, Germany {kbade,nuernb}@iws.cs.uni-magdeburg.de
Machine Learning Capacity and Performance Analysis and R
 Machine Learning and R May 3, 11 30 25 15 10 5 25 15 10 5 30 25 15 10 5 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 100 80 60 40 100 80 60 40 100 80 60 40 30 25 15 10 5 25 15 10
Machine Learning and R May 3, 11 30 25 15 10 5 25 15 10 5 30 25 15 10 5 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 0 2 4 6 8 101214161822 100 80 60 40 100 80 60 40 100 80 60 40 30 25 15 10 5 25 15 10
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Project Report. Document Clustering. Meryem Uzun-Per
 Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Data Mining Project Report Document Clustering Meryem Uzun-Per 504112506 Table of Content Table of Content... 2 1. Project Definition... 3 2. Literature Survey... 3 3. Methods... 4 3.1. K-means algorithm...
Maximize Revenues on your Customer Loyalty Program using Predictive Analytics
 Maximize Revenues on your Customer Loyalty Program using Predictive Analytics 27 th Feb 14 Free Webinar by Before we begin... www Q & A? Your Speakers @parikh_shachi Technical Analyst @tatvic Loves js
Maximize Revenues on your Customer Loyalty Program using Predictive Analytics 27 th Feb 14 Free Webinar by Before we begin... www Q & A? Your Speakers @parikh_shachi Technical Analyst @tatvic Loves js
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Data Mining Yelp Data - Predicting rating stars from review text
 Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University rchada@cs.stonybrook.edu Chetan Naik Stony Brook University cnaik@cs.stonybrook.edu ABSTRACT The majority
Data Mining Yelp Data - Predicting rating stars from review text Rakesh Chada Stony Brook University rchada@cs.stonybrook.edu Chetan Naik Stony Brook University cnaik@cs.stonybrook.edu ABSTRACT The majority
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
How To Cluster
 Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Data Clustering Dec 2nd, 2013 Kyrylo Bessonov Talk outline Introduction to clustering Types of clustering Supervised Unsupervised Similarity measures Main clustering algorithms k-means Hierarchical Main
Chapter ML:XI (continued)
") Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
Chapter ML:XI (continued) XI. Cluster Analysis Data Mining Overview Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization
 A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
A Partially Supervised Metric Multidimensional Scaling Algorithm for Textual Data Visualization Ángela Blanco Universidad Pontificia de Salamanca ablancogo@upsa.es Spain Manuel Martín-Merino Universidad
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts
 MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
MACHINE LEARNING IN HIGH ENERGY PHYSICS
 MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
Text Analytics Illustrated with a Simple Data Set
 CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
CSC 594 Text Mining More on SAS Enterprise Miner Text Analytics Illustrated with a Simple Data Set This demonstration illustrates some text analytic results using a simple data set that is designed to
Data Mining and Neural Networks in Stata
 Data Mining and Neural Networks in Stata 2 nd Italian Stata Users Group Meeting Milano, 10 October 2005 Mario Lucchini e Maurizo Pisati Università di Milano-Bicocca mario.lucchini@unimib.it maurizio.pisati@unimib.it
Data Mining and Neural Networks in Stata 2 nd Italian Stata Users Group Meeting Milano, 10 October 2005 Mario Lucchini e Maurizo Pisati Università di Milano-Bicocca mario.lucchini@unimib.it maurizio.pisati@unimib.it
from Larson Text By Susan Miertschin
 Decision Tree Data Mining Example from Larson Text By Susan Miertschin 1 Problem The Maximum Miniatures Marketing Department wants to do a targeted mailing gpromoting the Mythic World line of figurines.
Decision Tree Data Mining Example from Larson Text By Susan Miertschin 1 Problem The Maximum Miniatures Marketing Department wants to do a targeted mailing gpromoting the Mythic World line of figurines.
Predictive Modeling in Workers Compensation 2008 CAS Ratemaking Seminar
 Predictive Modeling in Workers Compensation 2008 CAS Ratemaking Seminar Prepared by Louise Francis, FCAS, MAAA Francis Analytics and Actuarial Data Mining, Inc. www.data-mines.com Louise.francis@data-mines.cm
Predictive Modeling in Workers Compensation 2008 CAS Ratemaking Seminar Prepared by Louise Francis, FCAS, MAAA Francis Analytics and Actuarial Data Mining, Inc. www.data-mines.com Louise.francis@data-mines.cm
Clustering Technique in Data Mining for Text Documents
 Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Recommender Systems: Content-based, Knowledge-based, Hybrid. Radek Pelánek
 Recommender Systems: Content-based, Knowledge-based, Hybrid Radek Pelánek 2015 Today lecture, basic principles: content-based knowledge-based hybrid, choice of approach,... critiquing, explanations,...
Recommender Systems: Content-based, Knowledge-based, Hybrid Radek Pelánek 2015 Today lecture, basic principles: content-based knowledge-based hybrid, choice of approach,... critiquing, explanations,...
CI6227: Data Mining. Lesson 11b: Ensemble Learning. Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore.
 CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
CI6227: Data Mining Lesson 11b: Ensemble Learning Sinno Jialin PAN Data Analytics Department, Institute for Infocomm Research, A*STAR, Singapore Acknowledgements: slides are adapted from the lecture notes
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
ISSN: 2321-7782 (Online) Volume 2, Issue 10, October 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. ~ Spring~r
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Search Engines. Stephen Shaw <stesh@netsoc.tcd.ie> 18th of February, 2014. Netsoc
 Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Search Engines Stephen Shaw Netsoc 18th of February, 2014 Me M.Sc. Artificial Intelligence, University of Edinburgh Would recommend B.A. (Mod.) Computer Science, Linguistics, French,
Predictive Modeling Techniques in Insurance
 Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
Machine Learning. Chapter 18, 21. Some material adopted from notes by Chuck Dyer
 Machine Learning Chapter 18, 21 Some material adopted from notes by Chuck Dyer What is learning? Learning denotes changes in a system that... enable a system to do the same task more efficiently the next
Machine Learning Chapter 18, 21 Some material adopted from notes by Chuck Dyer What is learning? Learning denotes changes in a system that... enable a system to do the same task more efficiently the next
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Mining. Practical. Data. Monte F. Hancock, Jr. Chief Scientist, Celestech, Inc. CRC Press. Taylor & Francis Group
 Practical Data Mining Monte F. Hancock, Jr. Chief Scientist, Celestech, Inc. CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint of the Taylor Ei Francis Group, an Informs
Practical Data Mining Monte F. Hancock, Jr. Chief Scientist, Celestech, Inc. CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint of the Taylor Ei Francis Group, an Informs
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Predictive Data modeling for health care: Comparative performance study of different prediction models
 Predictive Data modeling for health care: Comparative performance study of different prediction models Shivanand Hiremath hiremat.nitie@gmail.com National Institute of Industrial Engineering (NITIE) Vihar
Predictive Data modeling for health care: Comparative performance study of different prediction models Shivanand Hiremath hiremat.nitie@gmail.com National Institute of Industrial Engineering (NITIE) Vihar
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC
 Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Exam in course TDT4215 Web Intelligence - Solutions and guidelines -
 English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
English Student no:... Page 1 of 12 Contact during the exam: Geir Solskinnsbakk Phone: 94218 Exam in course TDT4215 Web Intelligence - Solutions and guidelines - Friday May 21, 2010 Time: 0900-1300 Allowed
Data quality in Accounting Information Systems
 Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
STATISTICA. Clustering Techniques. Case Study: Defining Clusters of Shopping Center Patrons. and
 Clustering Techniques and STATISTICA Case Study: Defining Clusters of Shopping Center Patrons STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table
Clustering Techniques and STATISTICA Case Study: Defining Clusters of Shopping Center Patrons STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table
Term extraction for user profiling: evaluation by the user
 Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
A Comparison of Event Models for Naive Bayes Text Classification
 A Comparison of Event Models for Naive Bayes Text Classification Andrew McCallum mccallum@justresearch.com Just Research 4616 Henry Street Pittsburgh, PA 15213 Kamal Nigam knigam@cs.cmu.edu School of Computer
A Comparison of Event Models for Naive Bayes Text Classification Andrew McCallum mccallum@justresearch.com Just Research 4616 Henry Street Pittsburgh, PA 15213 Kamal Nigam knigam@cs.cmu.edu School of Computer
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)
 LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING)") ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
ARTIFICIAL INTELLIGENCE (CSCU9YE) LECTURE 6: MACHINE LEARNING 2: UNSUPERVISED LEARNING (CLUSTERING) Gabriela Ochoa http://www.cs.stir.ac.uk/~goc/ OUTLINE Preliminaries Classification and Clustering Applications
AUTO CLAIM FRAUD DETECTION USING MULTI CLASSIFIER SYSTEM
 AUTO CLAIM FRAUD DETECTION USING MULTI CLASSIFIER SYSTEM ABSTRACT Luis Alexandre Rodrigues and Nizam Omar Department of Electrical Engineering, Mackenzie Presbiterian University, Brazil, São Paulo 71251911@mackenzie.br,nizam.omar@mackenzie.br
AUTO CLAIM FRAUD DETECTION USING MULTI CLASSIFIER SYSTEM ABSTRACT Luis Alexandre Rodrigues and Nizam Omar Department of Electrical Engineering, Mackenzie Presbiterian University, Brazil, São Paulo 71251911@mackenzie.br,nizam.omar@mackenzie.br
Course 395: Machine Learning
 Course 395: Machine Learning Lecturers: Maja Pantic (maja@doc.ic.ac.uk) Stavros Petridis (sp104@doc.ic.ac.uk) Goal (Lectures): To present basic theoretical concepts and key algorithms that form the core
Course 395: Machine Learning Lecturers: Maja Pantic (maja@doc.ic.ac.uk) Stavros Petridis (sp104@doc.ic.ac.uk) Goal (Lectures): To present basic theoretical concepts and key algorithms that form the core
Credit Card Fraud Detection and Concept-Drift Adaptation with Delayed Supervised Information
 Credit Card Fraud Detection and Concept-Drift Adaptation with Delayed Supervised Information Andrea Dal Pozzolo, Giacomo Boracchi, Olivier Caelen, Cesare Alippi, and Gianluca Bontempi 15/07/2015 IEEE IJCNN
Credit Card Fraud Detection and Concept-Drift Adaptation with Delayed Supervised Information Andrea Dal Pozzolo, Giacomo Boracchi, Olivier Caelen, Cesare Alippi, and Gianluca Bontempi 15/07/2015 IEEE IJCNN
Large-Scale Data Sets Clustering Based on MapReduce and Hadoop
 Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
How To Learn From The Revolution
 The Revolution Learning from : Text, Feelings and Machine Learning IT Management, CBS Supply Chain Leaders Forum 3 September 2015 The Revolution Learning from : Text, Feelings and Machine Learning Outline
The Revolution Learning from : Text, Feelings and Machine Learning IT Management, CBS Supply Chain Leaders Forum 3 September 2015 The Revolution Learning from : Text, Feelings and Machine Learning Outline
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC)
") large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
large-scale machine learning revisited Léon Bottou Microsoft Research (NYC) 1 three frequent ideas in machine learning. independent and identically distributed data This experimental paradigm has driven
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning
 in Semi-supervised Learning Reducing Dimension and Maintaining Meaning") Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
Non-negative Matrix Factorization (NMF) in Semi-supervised Learning Reducing Dimension and Maintaining Meaning SAMSI 10 May 2013 Outline Introduction to NMF Applications Motivations NMF as a middle step
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING
 dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
dm106 TEXT MINING FOR CUSTOMER RELATIONSHIP MANAGEMENT: AN APPROACH BASED ON LATENT SEMANTIC ANALYSIS AND FUZZY CLUSTERING ABSTRACT In most CRM (Customer Relationship Management) systems, information on
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Three Methods for ediscovery Document Prioritization:
 Three Methods for ediscovery Document Prioritization: Comparing and Contrasting Keyword Search with Concept Based and Support Vector Based "Technology Assisted Review-Predictive Coding" Platforms Tom Groom,
Three Methods for ediscovery Document Prioritization: Comparing and Contrasting Keyword Search with Concept Based and Support Vector Based "Technology Assisted Review-Predictive Coding" Platforms Tom Groom,