Introduction to Big Data in HPC, Hadoop and HDFS Part Two
|
|
|
- Gertrude Freeman
- 8 years ago
- Views:
Transcription
1 Introduction to Big Data in HPC, Hadoop and HDFS Part Two Research Field Key Technologies Jülich Supercomputing Centre Supercomputing & Big Data Dr. Ing. Morris Riedel Adjunct Associated Professor, University of Iceland Jülich Supercomputing Centre, Germany Head of Research Group High Productivity Data Processing Cy-Tera/LinkSCEEM HPC Administrator Workshop, Nicosia, The Cyprus Institute, 19 th January 21 th January 2015

2 Overall Course Outline 2/ 81

3 Overall Course Outline Part One Big Data Challenges & HPC Tools Understanding Big Data in Science & Engineering Statistical Data Mining and Learning from Big Data OpenMP/MPI Tool Example for Clustering Big Data MPI Tool Example for Classification of Big Data coffee break Part Two Big Data & Distributed Computing Tools Exploring Parallel & Distributed Computing Approaches Examples of Map-Reduce & Big Data Processing with Hadoop Tools for handling Big Data storage & replication methods Technologied for Large-scale distributed Big Data Management 3/ 81

4 Part Two 4/ 81
5 Part Two Outline Part One Big Data Challenges & HPC Tools Understanding Big Data in Science & Engineering Statistical Data Mining and Learning from Big Data OpenMP/MPI Tool Example for Clustering Big Data MPI Tool Example for Classification of Big Data coffee break Part Two Big Data & Distributed Computing Tools Exploring Parallel & Distributed Computing Approaches Examples of Map-Reduce & Big Data Processing with Hadoop Tools for handling Big Data storage & replication methods Technologies for Large-scale distributed Big Data Management 5/ 81

6 Emerging Big Data Analytics vs. Traditional Data Analysis Data Analytics are powerful techniques to work on large data Data Analysis is the in-depth interpretation of research data Both are a complementary technique for understanding datasets Data analytics may point to interesting events for data analysis Data Analysis supports the search for causality Describing exactly WHY something is happening Understanding causality is hard and time-consuming Searching it often leads us down the wrong paths Data Big Data Analytics focussed on correlation Not focussed on causality enough THAT it is happening Discover novel patterns/events and WHAT is happening more quickly Using correlations for invaluable insights often data speaks for itself 6/ 81

7 Google Flu Analytics Hype vs. (Scientific) Reality 2009 H1N1 Virus made headlines Nature paper from Google employees Explains how Google is able to predict flus Not only national scale, but down to regions even Possible via logged big data search queries [1] Jeremy Ginsburg et al., Detecting influenza epidemics using search engine query data, Nature 457, The Parable of Google Flu Large errors in flu prediction were avoidable and offer lessons for the use of big data (1) Transparency and Replicability impossible (2) Study the Algorithm since they keep changing (3) It s Not Just About Size of the Data ~1998-today [1] David Lazer, Ryan Kennedy, Gary King, and Alessandro Vespignani, The Parable of Google Flu: Traps in Big Data Analysis, Science Vol (343), / 81
![logged big data search queries [1] Jeremy Ginsburg et al.](/docs-images/40/1729693/images/page_7.jpg ", Detecting influenza epidemics using search engine query data, Nature 457, 2009 2014 The Parable of Google Flu Large errors in flu prediction were avoidable and offer lessons for the use of big")
8 Modern Data Mining Applications Properties opportunity to exploit parallelism Require handling of immense amounts of data quickly Provide data that is extremely regular and can be independently processed Many modern data mining applications require computing on compute nodes (i.e. processors/cores) that operate independently from each other Independent means there is little or even no communication between tasks Examples from the Web Ranking of Web pages by importance (includes iterated matrix-vector multiplication) Searches in social networking sites (includes search in graph with hundreds of nodes/billions of edges) Major difference to typical HPC workload Not simulation of physical phenomena 8/ 81
 Major difference to typical HPC workload Not simulation of physical phenomena 8/")
9 Hiding the complexity of computing & data Many users of parallel data processing machines are not technical savvy users and don t need to know system details Scientific domain-scientists (e.g. biology) need to focus on their science & data Scientists from statistics/machine-learning need to focus on their algorithms & data Non-technical users raise the following requirements for a data processing machinery : [3] Science Progress The data processing machinery needs to be easy to program The machinery must hide the complexities of computing (e.g. different networks, various operating systems, etc.) It needs to take care of the complexities of parallelization (e.g. scheduling, task distribution, synchronization, etc.) 9/ 81

10 Data Processing Machinery Available Today Specialized Parallel Computers (aka Supercomputers) Interconnent between nodes is expensive (i.e. Infiniband/Myrinet) Interconnect not always needed in data analysis (independence in datasets) Programming is relatively difficult/specific, parallel programming is profession of its own Large compute clusters dominate data-intensive computing Offer cheaper parallelism (no expensive interconnect & switches between nodes) Compute nodes (i.e. processors/cores) interconnected with usual ethernet cables Provide large collections of commodity hardware (e.g. normal processors/cores) 10 / 81

11 Possible Failures during Operation Rule of thumb: The bigger the cluster is, the more frequent failures happen Reasons for failures Loss of a single node within a rack (e.g. hard disk crash, memory errors) Loss of an entire rack (e.g. network issues) Operating software errors/bugs Consequences of failures Long-running compute tasks (e.g. hours/days) need to be restarted Already written data may become inconsistent and needs to be removed Access to unique datasets maybe hindered or even unavailable 11 / 81

12 Two Key Requirements for Big Data Analytics Taking into account the ever-increasing amounts of big data Think: Big Data not always denoted by volume, there is velocity, variety, 1. Fault-tolerant and scalable data analytics processing approach Data analytics computations must be divided in small task for easy restart Restart of one data analytics task has no affect on other active tasks E.g. Hadoop implementation of the map-reduce paradigm A data analytics processing programming model is required that is easy to use and simple to program with fault-tolerance already within its design 2. Reliable scalable big data storage method Data is (almost always) accessible even if failures in nodes/disks occur Enable the access of large quantities of data with good performance E.g. Hadoop Distributed File System (HDFS) implementation A specialized distributed file system is required that assumes failures as default 12 / 81

13 Part Two Questions 13 / 81
14 Part Two Outline Part One Big Data Challenges & HPC Tools Understanding Big Data in Science & Engineering Statistical Data Mining and Learning from Big Data OpenMP/MPI Tool Example for Clustering Big Data MPI Tool Example for Classification of Big Data coffee break Part Two Big Data & Distributed Computing Tools Exploring Parallel & Distributed Computing Approaches Examples of Map-Reduce & Big Data Processing with Hadoop Tools for handling Big Data storage & replication methods Technologies for Large-scale distributed Big Data Management 14 / 81

15 Motivation: Increasing complexities in traditional HPC Different HPC Programming elements (barriers, mutexes, shared-/distributed memory, etc.) Task distribution issues (scheduling, synchronization, inter-process-communication, etc.) Complex heterogenous architectures (UMA, NUMA, hybrid, various network topologies, etc.) Data/Functional parallelism approaches (SMPD, MPMD, domain decomposition, ghosts/halo, etc. ) [4] Introduction to High Performance Computing for Scientists and Engineers [5] Parallel Computing Tutorial More recently, increasing complexity for scientists working with GPGPU solutions (e.g. CUDA, etc.) 15 / 81
 Data/Functional parallelism approaches (SMPD, MPMD, domain decomposition, ghosts/halo, etc.")
16 Inspired by Traditional Model in Computer Science Break big tasks in many sub-tasks and aggregate/combine results Divide & Conquer Problem 1 partition (1) Partition the whole problem space (2) Combine the partly solutions of each partition to a whole solution of the problem Worker Worker Worker Result 2 combine P1 P2 P3 16 / 81

17 Origins of the Map-Reduce Programming Model Origin: Invented via the proprietary Google technology by Google technologists Drivers: Applications and data mining approaches around the Web Foundations go back to functional programming (e.g. LISP) [6] MapReduce: Simplified Dataset on Large Clusters, 2004 Established open source community Apache Hadoop in production (mostly business) [7] Apache Hadoop Open Source Implementation of the map-reduce programming model Based on Java programming language Broadly used also by commercial vendors within added-value software Foundation for many higher-level algorithms, frameworks, and approaches 17 / 81

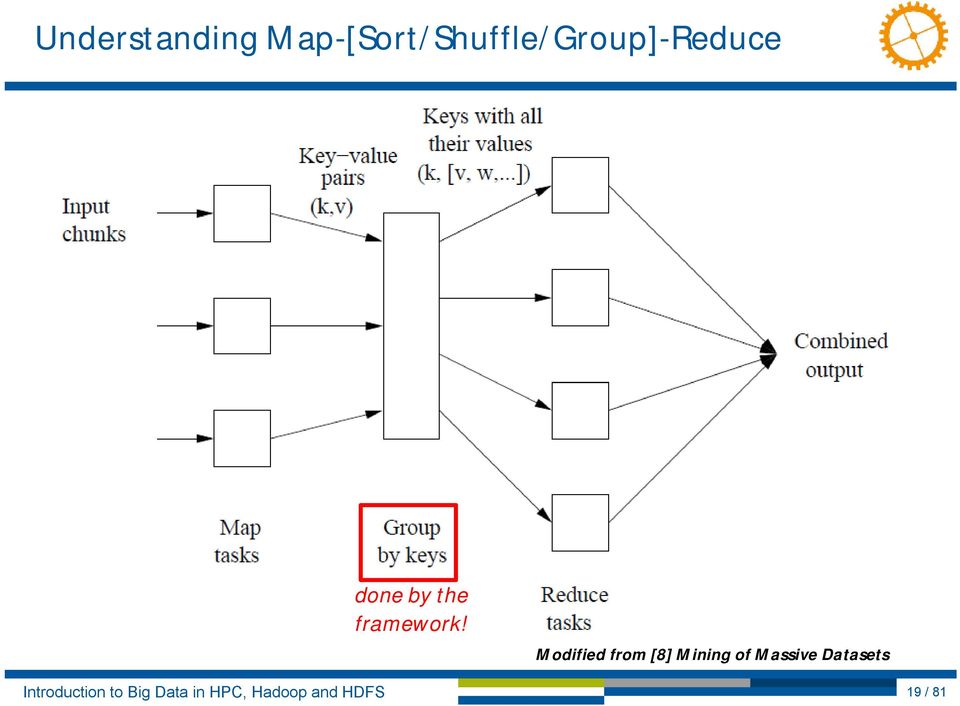
18 Map-Reduce Programming Model Enables many common calculations easily on large-scale data Efficiently performed on computing clusters (but security critics exists) Offers system that is tolerant of hardware failures in computation Simple Programming Model Users need to provide two functions Map & Reduce with key/value pairs Tunings are possible with numerous configurations & combine operation Key to the understanding: The Map-Reduce Run-Time Three phases not just map-reduce Takes care or the partitioning of input data and the communication Manages parallel execution and performs sort/shuffle/grouping Coordinates/schedules all tasks that either run Map and Reduce tasks Handles faults/errors in execution and re-submit tasks Experience from Practice: Talk to your users what they want to do with map-reduce exactly algorithm implemented, developments? 18 / 81

19 Understanding Map-[Sort/Shuffle/Group]-Reduce done by the framework! Modified from [8] Mining of Massive Datasets 19 / 81
20 Key-Value Data Structures Two key functions to program by user: map and reduce Third phase sort/shuffle works with keys and sorts/groups them Input keys and values (k1,v1) are drawn from a different domain than the output keys and values (k2,v2) Intermediate keys and values (k2,v2) are from the same domain as the output keys and values map (k1,v1) list(k2,v2) reduce (k2,list(v2)) list(v2) 20 / 81
 list(k2,v2) reduce (k2,list(v2))")
21 Key-Value Data Structures Programming Effort map (k1,v1) list(k2,v2) reduce (k2,list(v2)) list(v2) // counting words example map(string key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); // the framework performs sort/shuffle // with the specified keys reduce(string key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); Goal: Counting the number of each word appearing in a document (or text-stream more general) Key-Value pairs are implemented as Strings in this text-processing example for each function and as Iterator over a list Map (docname, doctext) list (wordkey, 1), Reduce (wordkey, list (1, )) list (numbercounted) [6] MapReduce: Simplified Dataset on Large Clusters, / 81
22 Map-Reduce Example: WordCount 22 / 81
23 Map-Reduce on FutureGrid/FutureSystems Transition Process FutureGrid/FutureSystems Affects straightforward use, but elements remain Contact if interested UoIceland Teaching Project Apply for an account Upload of SSH is necessary Close to real production environment Batch system (Torque) for scheduling myhadoop Torque Is a set of scripts that configure and instantiate Hadoop as a batch job myhadoop is currently installed on four different systems Alamo, Hotel, India, Sierra [17] FutureGrid/FutureSystems UoIceland Teaching Project [18] FutureGrid/FutureSystems Submit WordCount Example 23 / 81
24 Further Map-Reduce example: URL Access Very similar to the WordCount example is the following one: Count of URL Access Frequency ( How often people use a page ) Google (and other Web organizations) store billions of logs ( information ) Users independently click on pages or follow links nice parallelization Map function here processes logs of Web page requests (URL, 1) Reduce function adds togeter all values for same URL (URL, N times) [6] MapReduce: Simplified Dataset on Large Clusters Many examples and applications are oriented towards processing large quantities of Web data text Examples are typically not scientific datasets or contents of traditional business warehouse databases 24 / 81
25 Communication in Map-Reduce Algorithms Greatest cost in the communication of a map-reduce algorithm Algorithms often trade communication cost against degree of parallelism and use principle of data locality (use less network) Taking data locality into account Data locality means that network bandwidth is conserved by taking advantage of the approach that the input data (managed by DFS) is stored on (or very near, e.g. same network switch) the local disks of the machines that make up the computing clusters Modified from [6] MapReduce: Simplified Dataset on Large Clusters 25 / 81
26 Map-Reduce Optimizations Local Combiner The Map-Reduce programming model is based on Mapper, Combiner, Partitioner, and Reducer functionality supported by powerful shuffle/sort/aggregation of keys by the framework Mapper functionality is applied to input data and computes intermediate results in a distributed fashion Map Phase (local) Combiner functionality is applied in-memory to Map outputs and performs local aggregation of its results Partitioner determines to which reducer intermediate data is shuffled (cf. Computer Vision) Reduce Phase Reduce functionality is applied to intermediate input data from the Map-Phase and aggregates it for results modified from [14] Computer Vision using Map-Reduce 26 / 81
27 Not every problem can be solved with Map-Reduce Map-Reduce is not a solution to every parallelizable problem Only specific algorithms benefit from the map-reduce approach No communication-intensive parallel tasks (e.g. PDE solver) with MPI Applications that require often updates of existing datasets (writes) Implementations often have severe security limitations (distributed) Example: Amazon Online retail sales Requires a lot of updates on their product databases on each user action (a problem for the underlying file system optimization) Processes that involve little calculation but still change the database Employs thousands of computing nodes and offers them ( Amazon Cloud ) (maybe they using map-reduce for certain analytics: buying patterns) [8] Mining of Massive Datasets 27 / 81
28 Map-Reduce Limitation: Missing some form of State What if values depend on previously computed values? Map-Reduce runs map & reduce tasks in parallel and finishes Problematic when result of one Map-Reduce run is influencing another Map-Reduce run iteration state? ST sample data loaded from local file system according to partition file training samples are support vectors of former layer REDUCE REDUCE REDUCE REDUCE REDUCE Trained classifier MAP MAP MAP STOP Iterations with decrease of map & reduce tasks time [15] Study on Parallel SVM Based on MapReduce 28 / 81
29 The Need for Iterative Map-Reduce Map-Reduce runs map and reduce tasks and finishes Many parallel algorithms are iterative in nature Example from many application fields such as data clustering, dimension reduction, link analysis, or machine learning Iterative Map-Reduce enables algorithms with same Map-Reduce tasks ideas, but added is a loop to perform iterations until conditions are satisfied The transfer of states from one iteration to another iteration is specifically supported in this approach modified from [12] Z. Sun et al. 29 / 81
30 Iterative Map-Reduce with Twister MapReduce jobs are controlled by the Client node Via a multi-step process Configuration phase: The Client assigns Map-Reduce methods to the job prepares KeyValue pairs prepares static data for Map-Reduce tasks (through the partition file) if required Running phase: The Client between iterations receives results collected by the combine method exits gracefully when the job is done (check condition) Message communication between jobs Realized with message brokers, i.e. NaradaBrokering or ActiveMQ [13] Twister Web page 30 / 81
31 Overview: Iterative Map-Reduce with Twister ST = state over iterations! [13] Twister Web page 31 / 81
32 Distribute Small State with Distributed Cache Mappers need to read state from a single file (vs. data chunks) Example: Distributed spell-check application Every Mapper reads same copy of the dictionary before processing docs Dictionary ( state ) is small (~ MBs), but all nodes need to reach it Solution: Hadoop provides DistributedCache Optimal to contain small files needed for initialization (or shared libraries even) State (or input data= needed on all nodes of the cluster Simple use with Java DistributedCache Class Method AddCacheFile() add names of files which should be sent to all nodes on the system (need to be in HDFS) by the framework ST [16] Hadoop Distributed Cache = state of data per iteration or small data required by every node 32 / 81
33 Hadoop 2.x vs. Hadoop 1.x Releases Apache Hadoop 1.x had several limitations, but is still used a lot Apache Hadoop 2.x consisted of significant improvements New Scheduler Hadoop YARN with lots of configuation options (YARN = Yet Another Resource Negotiator: Map-reduce used beyond its idea) HDFS Improvements Use multiple independent Namenodes/Namespaces as federated system (addressing single point of failure ) Map-Reduce Improvements JobTracker functions are seperated into two new components (addressing single point of failure ) New ResourceManager manages the global assignment of compute resources to applications New ApplicationMaster manages the application scheduling and coordination [11] Hadoop 2.x different scheduling policies can be configured 33 / 81
34 Apache Hadoop Key Configuration Overview core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> </configuration> NameNode JobTracker E.g. NameNode, Default status page: E.g. JobTracker, Default status page: core-site.xml contains core properties of Hadoop (fs.default.name is just one example) hdfs-site.xml contains properties directly related to HDFS (e.g. dfs.replication is just one example) mapred-site.xml contains properties related to the map-reduce programming environment 34 / 81
35 Hadoop Selected Administration & Configuration (1) Release Download Check Webpage Well maintained, often new versions [7] Apache Hadoop JobTracker, e.g. max. of map / reduce jobs per node 35 / 81
36 Hadoop Selected Administration & Configuration (2) conf/mapred-site.xml Version 2: JobTracker split : resource management and job scheduling/monitoring conf/yarn-site.xml Yarn for resource management 36 / 81
37 Hadoop Usage Examples 37 / 81
38 Apache Hadoop Architecture Elements NameNode (and Secondary NameNode) Service that has all information about the HDFS file system ( data nodes ) JobTracker (point of failure no secondary instance!) Service that farms out map-reduce tasks to specific nodes in the cluster TaskTracker (close to DataNodes, offering job slots to submit to) Entity in a node in the cluster that accepts/performs map-reduce tasks Standard Apache Hadoop Deployment (Data nodes & TaskTrackers) Secondary NameNode NameNode DataNode Part of the HDFS filesystem Responds to requests from the NameNode for filesystem operations compute nodes with data storage JobTracker 38 / 81
39 Reliability & Fault-Tolerance in Map-Reduce (1) 1. Users use the client application to submit jobs to the JobTracker 2. A JobTracker interacts with the NameNode to get data location 3. The JobTracker locates TaskTracker nodes with available slots at or near the data ( data locality principle ) 4. The JobTracker submits the work to the chosen TaskTracker nodes Map-Reduce Jobs Big Data required for job Standard Apache Hadoop Deployment (Data nodes & TaskTrackers) 4 TaskTracker 3 Secondary NameNode NameNode 2 1 compute nodes with data storage JobTracker 39 / 81
40 Reliability & Fault-Tolerance in Map-Reduce (2) 5. The TaskTracker nodes are monitored (ensure reliability ) Fault tolerance : If they do not submit heartbeat signals often enough, they are deemed to have failed & the work is given to different TaskTracker 6. The TaskTracker notifies the JobTracker when a task fails The JobTracker decides next action: it may resubmit the job elsewhere or it may mark that specific record as something to avoid The Jobtracker may may even blacklist the TaskTracker as unreliable Standard Apache Hadoop Deployment (Data nodes & TaskTrackers) TaskTracker 6 TaskTracker 6 Secondary NameNode NameNode 7. When the work is completed, the JobTracker updates its status 8. Client applications can poll the JobTracker for information 5 8 compute nodes with data storage JobTracker 7 40 / 81
41 Cluster Setups with Hadoop-On-Demand (HOD) Hadoop On Demand (HOD) is a specific Hadoop distribution for provisioning virtual Hadoop cluster deployments over a large physical cluster that is managed by a scheduler (i.e. Torque). When to use? A given physical cluster exists with nodes managed by scheduling system Semi-Automatic Deployment approach HOD provisions and maintains Hadoop Map-Reduce and HDFS instances through interaction with several HOD components on given physical nodes Performs cluster node allocation Starts Hadoop Map/Reduce and HDFS daemons on allocated nodes Makes it easy for administrators to quickly setup and use Hadoop Includes automatic configurations Generates configuration files for the Hadoop daemons and client 41 / 81
42 HOD Deployment on Different Cluster Node Types Submit nodes Users use the HOD client on these nodes to allocate cluster nodes and use the Hadoop client to submit Map-Reduce jobs [27] HOD Architecture Compute nodes The resource manager runs HOD components on these nodes to provision the Hadoop daemons that enable Map-Reduce jobs allocated compute nodes hod components 3 Resource Manager 2 Specific node The usage of HOD is optimized for users that do not want to know the low-level technical details 5 hod client hadoop client 1 compute nodes submit node 4 42 / 81
43 HOD Detailed Architecture Elements Basic System Architecture of HOD includes: A Resource Manager & Scheduling system (i.e. Torque) Hadoop Map/Reduce and HDFS daemons need to run Various HOD components (HOD RingMaster, HOD Rings) HOD RingMaster Starts as a process of the compute nodes (mother superior, in Torque) Uses a resource manager interface (pbsdsh, in Torque) Runs the HodRing as distributed tasks on the allocated compute nodes HOD Rings Communicate with the HOD RingMaster to get Hadoop commands (e.g. new map-reduce jobs) and run them accordingly Once the Hadoop commands are started they register with the RingMaster, giving information about the daemons of the HOD Rings Torque Map-Reduce Jobs hod ringmaster Since map-reduce version 2 HOD is deprected and YARN is the scheduler to be used instead hodring 43 / 81
44 Hadoop Adoptions In Industry [19] IBM Smart Data Innovation Lab [2] [1] [2] [2] [2] [2] [1] [2] class label Closed Source Algorithms in Business Solutions (e.g. also IBM SPSS) Classification Uptake of Hadoop in many different business environments, SMEs, etc. 44 / 81
45 Map-Reduce Deployment Models Map-Reduce deployments are particularly well suited for cloud computing deployments Deployments need still some useful map-reduce codes (cf. to MPI/OpenMP w/o their codes) Options to move data to strong computing power... or move compute tasks close to data EUROPE? ICELAND? High Trust? Data Privacy Low Trust? On-premise full custom Map-Reduce Appliance Map-Reduce Hosting Map-Reduce As-A-Service Bare-metal Virtualized [23] Inspired by a study on Hadoop by Accenture Clouds 45 / 81
46 Data Analytics in the view of Open Data Science Experience in investigation of available parallel data mining algorithms Clustering++ Algorithm A Implementation Regression++ closed/old source, also after asking paper authors Algorithm Extension A Implementation Classification++ implementations available Parallelization of Algorithm Extension A A implementations rare and/or not stable MLlib Stable open source algorithms are still rather rare (Map-reduce, MPI/OpenMP, and GPGPUs) 46 / 81
47 Data Analytics with SVM Algorithm Availability Tool Platform Approach Parallel Support Vector Machine Apache Mahout Java; Apache Hadoop 1.0 (map-reduce); HTC No strategy for implementation (Website), serial SVM in code Apache Spark/MLlib Apache Spark; HTC Only linear SVM; no multi-class implementation Twister/ParallelSVM Java; Apache Hadoop 1.0 (map-reduce); Twister (iterations), HTC Much dependencies on other software: Hadoop, Messaging, etc. Version 0.9 development Scikit-Learn Python; HPC/HTC Multi-class Implementations of SVM, but not fully parallelized pisvm C code; Message Passing Interface (MPI); HPC Simple multi-class parallel SVM implementation outdated (~2011) GPU accelerated LIBSVM CUDA language Multi-class parallel SVM, relatively hard to program, no std. (CUDA) psvm C code; Message Passing Interface (MPI); HPC Unstable beta, SVM implementation outdated (~2011) 47 / 81
48 Lessons Learned Hadoop & Map-Reduce Be careful of investing time & efforts Frameworks keep significantly fast changing, no peer-reviews as in HPC (e.g. Hadoop 1.0 Hadoop 2.0, new move of community to Spark) Map-reduce basically standard, but not as stable as established MPI or OpenMP Hadoop 2.0 improvements with YARN to work in HPC scheduling environments Consider and observe developments around Apache Spark Solutions on-top-of Hadoop keep changing Many different frameworks are available on top of Hadoop Often business-driven developments (e.g. to be used in recommender systems) Data Analytics with Mahout have only a limited number of algorithms (E.g. Decision trees, collaborative filtering, no SVMs, no artifical neural networks) Data Analytics with Twister works, but limited algorithms (E.g. SVM v.0.9 works, but old development/research version, unmaintained) 48 / 81
49 Part Two Questions 49 / 81
50 Part Two Outline Part One Big Data Challenges & HPC Tools Understanding Big Data in Science & Engineering Statistical Data Mining and Learning from Big Data OpenMP/MPI Tool Example for Clustering Big Data MPI Tool Example for Classification of Big Data coffee break Part Two Big Data & Distributed Computing Tools Exploring Parallel & Distributed Computing Approaches Examples of Map-Reduce & Big Data Processing with Hadoop Tools for handling Big Data storage & replication methods Technologies for Large-scale distributed Big Data Management 50 / 81
51 Distributed File Systems vs. Parallel File Systems Distributed File Systems Clients, servers, and storage devices are geographically dispersed among machines of a distributed system (often appear as single system ) Manage access to files from multiple processes But generally treat concurrent access as an unusual event E.g. Hadoop Distributed File System (HDFS) implementation Parallel File Systems Deal with many problematic questions arising during parallel programming E.g. How can hundreds or thousands of processes access the same file concurrently and efficiently? E.g. How should file pointers work? E.g. Can the UNIX sequential consistency semantics be preserved? E.g. How should file blocks be cached and buffered? 51 / 81
52 Hadoop Distributed File System (HDFS) A specialized filesystem designed for reliability and scalability Designed to run on comodity hardware Many similarities with existing distributed file systems Takes advantage of file and data replication concept Differences to traditional distributed file systems are significant Designed to be highly fault-tolerant improves dependability! Enables use with applications that have extremely large data sets Provides high throughput access to application data HDFS relaxes a few POSIX requirements Enables streaming access to file system data Origin HDFS was originally built as infrastructure for the Apache Nutch web search engine project [9] The Hadoop Distributed File System 52 / 81
53 HDFS Key Feature: File Replication Concept File replication is a useful redundancy for improving availability and performance Ideal: Replicas reside on failure-independent machines Availability of one replica should not depend on availability of others Requires ability to place replica on particular machine Failure-independent machines hard to find, but in system design easier Replication should be hidden from users But replicas must be distinguishable at lower level Different DataNode s are not visible to end-users Replication control at higher level Degree of replication must be adjustable (e.g. Hadoop configuration files) Modified from [10] Virtual Workshop 53 / 81
54 HDFS Master/NameNode The master/name node is replicated A directory for the file system as a whole knows where to find the copies All participants using the DFS know where the directory copies are The Master/Name node keeps metadata (e.g. node knows about the blocks of files) E.g. horizontal partitioning Modified from [10] Virtual Workshop 54 / 81
55 HDFS File Operations Different optimized operations on different nodes NameNode Determines the mapping of pure data blocks to DataNodes ( metadata) Executes file system namespace operations E.g. opening, closing, and renaming files and directories DataNode Serving read and write requests from HDFS filesystem clients Performs block creation, deletion, and replication (upon instruction from the NameNode) [10] Virtual Workshop 55 / 81
56 HDFS File/Block(s) Distribution Example [9] The Hadoop Distributed File System 56 / 81
57 Working with HDFS HDFS can be deployed in conjunction with another filesystem But HDFS files are not directly accessible via the normal file system Normal User Commands Create a directory named /foodir e.g. bin/hadoop dfs -mkdir /foodir View the contents of a file named /foodir/myfile.txt e.g. bin/hadoop dfs cat /foodir/myfile.txt Administrator Commands Generate a list of DataNodes e.g. bin/hadoop dfsadmin -report Decommission DataNode datanodename (e.g. maintenance/check reasons) e.g. bin/hadoop dfsadmin decommission datanodename [9] The Hadoop Distributed File System 57 / 81
Classification Techniques in Remote Sensing Research using Smart Data Analytics
 Classification Techniques in Remote Sensing Research using Smart Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Morris Riedel Juelich Supercomputing
Classification Techniques in Remote Sensing Research using Smart Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Morris Riedel Juelich Supercomputing
High Productivity Data Processing Analytics Methods with Applications
 High Productivity Data Processing Analytics Methods with Applications Dr. Ing. Morris Riedel et al. Adjunct Associate Professor School of Engineering and Natural Sciences, University of Iceland Research
High Productivity Data Processing Analytics Methods with Applications Dr. Ing. Morris Riedel et al. Adjunct Associate Professor School of Engineering and Natural Sciences, University of Iceland Research
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Scalable Developments for Big Data Analytics in Remote Sensing
 Scalable Developments for Big Data Analytics in Remote Sensing Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group Leader,
Scalable Developments for Big Data Analytics in Remote Sensing Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group Leader,
Sriram Krishnan, Ph.D. sriram@sdsc.edu
 Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
European Data Infrastructure - EUDAT Data Services & Tools
 European Data Infrastructure - EUDAT Data Services & Tools Dr. Ing. Morris Riedel Research Group Leader, Juelich Supercomputing Centre Adjunct Associated Professor, University of iceland BDEC2015, 2015-01-28
European Data Infrastructure - EUDAT Data Services & Tools Dr. Ing. Morris Riedel Research Group Leader, Juelich Supercomputing Centre Adjunct Associated Professor, University of iceland BDEC2015, 2015-01-28
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
On Establishing Big Data Breakwaters
 On Establishing Big Data Breakwaters with Analytics Dr. - Ing. Morris Riedel Head of Research Group High Productivity Data Processing, Juelich Supercomputing Centre, Germany Adjunct Associated Professor,
On Establishing Big Data Breakwaters with Analytics Dr. - Ing. Morris Riedel Head of Research Group High Productivity Data Processing, Juelich Supercomputing Centre, Germany Adjunct Associated Professor,
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Map Reduce / Hadoop / HDFS
 Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
Chapter 3: Map Reduce / Hadoop / HDFS 97 Overview Outline Distributed File Systems (re-visited) Motivation Programming Model Example Applications Big Data in Apache Hadoop HDFS in Hadoop YARN 98 Overview
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware
 Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Open source software framework designed for storage and processing of large scale data on clusters of commodity hardware Created by Doug Cutting and Mike Carafella in 2005. Cutting named the program after
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS
 A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
A STUDY ON HADOOP ARCHITECTURE FOR BIG DATA ANALYTICS Dr. Ananthi Sheshasayee 1, J V N Lakshmi 2 1 Head Department of Computer Science & Research, Quaid-E-Millath Govt College for Women, Chennai, (India)
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
marlabs driving digital agility WHITEPAPER Big Data and Hadoop
 marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
marlabs driving digital agility WHITEPAPER Big Data and Hadoop Abstract This paper explains the significance of Hadoop, an emerging yet rapidly growing technology. The prime goal of this paper is to unveil
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Big Data Processing with Google s MapReduce. Alexandru Costan
 1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
1 Big Data Processing with Google s MapReduce Alexandru Costan Outline Motivation MapReduce programming model Examples MapReduce system architecture Limitations Extensions 2 Motivation Big Data @Google:
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney") Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
HPC ABDS: The Case for an Integrating Apache Big Data Stack
 HPC ABDS: The Case for an Integrating Apache Big Data Stack with HPC 1st JTC 1 SGBD Meeting SDSC San Diego March 19 2014 Judy Qiu Shantenu Jha (Rutgers) Geoffrey Fox gcf@indiana.edu http://www.infomall.org
HPC ABDS: The Case for an Integrating Apache Big Data Stack with HPC 1st JTC 1 SGBD Meeting SDSC San Diego March 19 2014 Judy Qiu Shantenu Jha (Rutgers) Geoffrey Fox gcf@indiana.edu http://www.infomall.org
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Introduction to MapReduce and Hadoop
 Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Introduction to MapReduce and Hadoop Jie Tao Karlsruhe Institute of Technology jie.tao@kit.edu Die Kooperation von Why Map/Reduce? Massive data Can not be stored on a single machine Takes too long to process
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Lecture 10 - Functional programming: Hadoop and MapReduce
 Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Lecture 10 - Functional programming: Hadoop and MapReduce Sohan Dharmaraja Sohan Dharmaraja Lecture 10 - Functional programming: Hadoop and MapReduce 1 / 41 For today Big Data and Text analytics Functional
Processing of Hadoop using Highly Available NameNode
 Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Parallel Computing. Benson Muite. benson.muite@ut.ee http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM
 IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
IMPLEMENTING PREDICTIVE ANALYTICS USING HADOOP FOR DOCUMENT CLASSIFICATION ON CRM SYSTEM Sugandha Agarwal 1, Pragya Jain 2 1,2 Department of Computer Science & Engineering ASET, Amity University, Noida,
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu
on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu") Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan sriram@sdsc.edu Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan sriram@sdsc.edu Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Accelerating and Simplifying Apache
 Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
How To Install Hadoop 1.2.1.1 From Apa Hadoop 1.3.2 To 1.4.2 (Hadoop)
") Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
Contents Download and install Java JDK... 1 Download the Hadoop tar ball... 1 Update $HOME/.bashrc... 3 Configuration of Hadoop in Pseudo Distributed Mode... 4 Format the newly created cluster to create
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
Keywords: Big Data, HDFS, Map Reduce, Hadoop
 Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Volume 5, Issue 7, July 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Configuration Tuning
Selected Parallel and Scalable Methods for Scientific Big Data Analytics
 Selected Parallel and Scalable Methods for Scientific Big Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group
Selected Parallel and Scalable Methods for Scientific Big Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group
Lecture Data Warehouse Systems
 Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Lecture Data Warehouse Systems Eva Zangerle SS 2013 PART C: Novel Approaches in DW NoSQL and MapReduce Stonebraker on Data Warehouses Star and snowflake schemas are a good idea in the DW world C-Stores
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
White Paper. Big Data and Hadoop. Abhishek S, Java COE. Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP
 White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
White Paper Big Data and Hadoop Abhishek S, Java COE www.marlabs.com Cloud Computing Mobile DW-BI-Analytics Microsoft Oracle ERP Java SAP ERP Table of contents Abstract.. 1 Introduction. 2 What is Big
Networking in the Hadoop Cluster
 Hadoop and other distributed systems are increasingly the solution of choice for next generation data volumes. A high capacity, any to any, easily manageable networking layer is critical for peak Hadoop
Hadoop and other distributed systems are increasingly the solution of choice for next generation data volumes. A high capacity, any to any, easily manageable networking layer is critical for peak Hadoop
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms
 Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, sborkar95@gmail.com Assistant Professor, Information
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Selected Parallel and Scalable Methods for Scientific Big Data Analytics
 Selected Parallel and Scalable Methods for Scientific Big Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group
Selected Parallel and Scalable Methods for Scientific Big Data Analytics Federated Systems and Data Division Research Group High Productivity Data Processing Dr.-Ing. Morris Riedel et al. Research Group
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Hadoop MapReduce Tutorial - Reduce Comp variability in Data Stamps
 Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
Distributed Recommenders Fall 2010 Distributed Recommenders Distributed Approaches are needed when: Dataset does not fit into memory Need for processing exceeds what can be provided with a sequential algorithm
MapReduce (in the cloud)
") MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
MapReduce (in the cloud) How to painlessly process terabytes of data by Irina Gordei MapReduce Presentation Outline What is MapReduce? Example How it works MapReduce in the cloud Conclusion Demo Motivation:
Hadoop@LaTech ATLAS Tier 3
 Cerberus Hadoop Hadoop@LaTech ATLAS Tier 3 David Palma DOSAR Louisiana Tech University January 23, 2013 Cerberus Hadoop Outline 1 Introduction Cerberus Hadoop 2 Features Issues Conclusions 3 Cerberus Hadoop
Cerberus Hadoop Hadoop@LaTech ATLAS Tier 3 David Palma DOSAR Louisiana Tech University January 23, 2013 Cerberus Hadoop Outline 1 Introduction Cerberus Hadoop 2 Features Issues Conclusions 3 Cerberus Hadoop
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
<Insert Picture Here> Oracle and/or Hadoop And what you need to know
 Oracle and/or Hadoop And what you need to know Jean-Pierre Dijcks Data Warehouse Product Management Agenda Business Context An overview of Hadoop and/or MapReduce Choices, choices,
Oracle and/or Hadoop And what you need to know Jean-Pierre Dijcks Data Warehouse Product Management Agenda Business Context An overview of Hadoop and/or MapReduce Choices, choices,
MAPREDUCE Programming Model
 CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
CS 2510 COMPUTER OPERATING SYSTEMS Cloud Computing MAPREDUCE Dr. Taieb Znati Computer Science Department University of Pittsburgh MAPREDUCE Programming Model Scaling Data Intensive Application MapReduce
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at