Link Prediction in Social Networks
|
|
|
- Gervais Parsons
- 8 years ago
- Views:
Transcription
1 CS378 Data Mining Final Project Report Dustin Ho : dsh544 Eric Shrewsberry : eas2389 Link Prediction in Social Networks 1. Introduction Social networks are becoming increasingly more prevalent in the daily lifestyle of the 21st century student. Key to the definition of a social network is the nature of the relationship between the people participating in the network, and especially the formation/ dissolution of these relationships. By viewing a social network as an undirected graph, with the people as the nodes and the relationships between them as edges, we can begin to formulate techniques to analyze the network in order to obtain interesting and useful results. In particular, link prediction, or the problem of estimating the probability a given relationship will form at a future time, given evidence of the social graph, plays a critical role in the evolution of the network and is the focus of our study. 2. Original Proposal Our original project proposal was to explore the mechanisms of social network evolution through testing various methods of unsupervised link prediction on the social network datasets. We found many of the predictors listed in the Kleinberg paper [1] to be interesting and we intended on implementing as many as we could in order to measure their performance on this dataset. A secondary goal we had was to visualize the results we obtained in a clear and informative manner, preferably in an interactive form. Also, we originally planned on to using Python as our language of choice for this project. Many of these assumptions have changed in the past few weeks as we worked on this project, though our end goal remains the same: to analyze the natural layout of social networks and to build and test various predictive models of link prediction in social networks. 3. Background Research In order to familiarize ourselves with the current state of the field, we spent time reading both papers that Wei suggested as well as seeking out resources on our own. Of note were the many websites and papers we looked at detailing typical layouts of social networks. This was our primary motivator in deciding to visualize the data, and affirming that it indeed follows a power-law distribution. The Kleinberg paper [1] has proven to be the most useful to us so far. Partly because it was written in a very accessible manner and partly because it presented such compelling results, we have been mostly trying to replicate the algorithms and methods discussed in this paper.

![The Song paper [2] we really only used to get a feel of the properties of the data.](/docs-images/33/16673219/images/2-0.png "A few of the methods in the paper felt very advanced, and we decided to only try to implement them if we had time at the end of the project.")
2 The Song paper [2] we really only used to get a feel of the properties of the data. A few of the methods in the paper felt very advanced, and we decided to only try to implement them if we had time at the end of the project. We also greatly benefited from the discussion of ROC Curves in class[5] and have adopted it as our primary metric by which we evaluate various link prediction techniques. We feel the ROC Curves provide a new way of perceiving the accuracy of different predictors and make it clear when a predictor performs well. Something else we considered was spectral clustering as a method for link prediction[4] after our meeting with Dr. Dhillon and Wei Tang. However, we ran into significant issues with the implementation of the method, which we discuss later. 4. Examining Properties of the Social Network This is a graph of the degrees of separation from an individual. Due to the limitations of our visualization framework (discussed later), we decided that visualizing degrees of separation in the graph would be an interesting way to visualize the data. It takes a lot of time to process the separation tree for moderately to large sized sets of data. For the full LiveJournal set it takes 5 days to process the full separation tree for one
![We also greatly benefited from the discussion of ROC Curves in class[5] and have adopted it as our primary metric by which we evaluate various link prediction techniques.](/docs-images/44/16673219/images/page_2.jpg "We feel the ROC Curves provide a new way of perceiving the accuracy of different predictors and make it clear when a predictor performs well.")
3 person. In contrast, the views of node degree frequency took less than 10 minutes to process for the entire set. Because of the large amount of time required for the separation tree, we spent a lot of time trying to optimize our algorithm, but so far none of our efforts have produced significant improvements.


4 Livejournal Myspace Max Mean Median 17 9 Mode 1 1 The node degree frequency graph shows a power-law distribution. We were surprised to learn that the most frequent node degree in both cases is 1. Having one connection in a pool of over 1.5M certainly demonstrates how sparseness of the data. We think this shows that a large number of users are not engaged in the social networking aspects of livejournal and myspace, or the users sign up for a single purpose and do not care to come back. We spent a good deal of time examining different visualization options including popular packages such as GraphViz, NetworkX, and NodeBox. In the end, the package that seemed the most relevant was Walrus [3], a tool developed by the Cooperative Association for Internet Data Analysis. It has the ability to visualize incredibly large graphs (extremely essential for our 2 million node networks) in a way that was visually appealing. We also ran the graph and analysis algorithms on the new arxiv data we recieved: Graph of index 2 from the astro-ph dataset for 6 and then 11 years cumulative.


5 Graph of index 2084 from the hep-th dataset for 6 and then 11 years cumlulative. As was expected, the total number of nodes as well as the degree of closer nodes increased dramatically over the last 5 years in the datasets. As one can see, there is a slight increase in nodes connected directly to the the root node in each case. There is also a huge increase in total nodes, and many additional layers added separating the root node from its furthest connection. The code for generating these graphs is explained in the readme, and more pictures and graph files are contained in the project folder. 5. Unsupervised Link Prediction Before the mid-term report, we only had access to the immense LiveJournal and MySpace datasets, as such we only ran the predictors on a 100k subset of the LiveJournal network (about 5% of all the data in that month) and tested predictive accuracy over the next month. We assumed the number of links that develop over the course of the month was known in order to simplify the problem, though testing shows that we could build a pretty good linear estimator of links per month. Predictor Accuracy (%) Random Common Neighbors Preferential Attachment As predicted, these simple classifiers don't do very well, but they perform much better than random (especially since the graph is sparse). Preliminary data shows these predictors running on MySpace seem to be slightly more accurate, though the sample size of 5,000

6 seemed too small to report conclusively. We decided not to investigate further on these datasets, instead turning our attention to the arxiv datasets made available to us. Previously, running a predictor on even a subset of the LiveJournal network could take a day. The arxiv datasets allowed us to try multiple methods, with multiple datasets in the matter of hours. All computation was run on Dustin Ho's computer (Quad Core 3.2 Ghz, 6GB RAM) since the largest dataset needed approximately 5GB of RAM. All of our code is available on our website [6]. A README is provided to assist with reproduction of our results. We created a test harness to help automate the data collection process as well as separate scoring functions for each predictor we wished to test. The data we used was collected by Kleinberg [1] and consists of 3 sections of the arxiv coauthorship network: gr-qc (general relativity and quantum mechanics), hep-ph (high energy physics - phenomenology), and hep-th (high energy physics - theory). This data was collected over the course of 11 years, with networks available for each year. We tried a variety of test situations, including testing over 5 years to predict the next 6 years, testing over 3 years to predict the next 3 years, and testing over 1 year to predict the following year. It is this last situation where we felt most comfortable with, and we compiled the results for this data as follows: Results: Common Neighbors Predictor, 1 year training, 1 year testing data. Common Neighbors on GR-QC
![All computation was run on Dustin Ho's computer (Quad Core 3.2 Ghz, 6GB RAM) since the largest dataset needed approximately 5GB of RAM. All of our code is available on our website [6].](/docs-images/44/16673219/images/page_6.jpg "A README is provided to assist with reproduction of our results.")
7 Common Neighbors on HEP-PH Common Neighbors on HEP-TH

8 Common Neighbors was our simplest predictor, and the baseline by which we compared the other predictors we implemented (Note that it barely does better than random). It simply scores a link based upon the number of neighbors two nodes have in common. Preferential Attachment Predictor, 1 year training, 1 year testing data. Preferential Attachment on GR-QC

9 Preferential Attachment on HEP-PH Preferential Attachment on HEP-TH
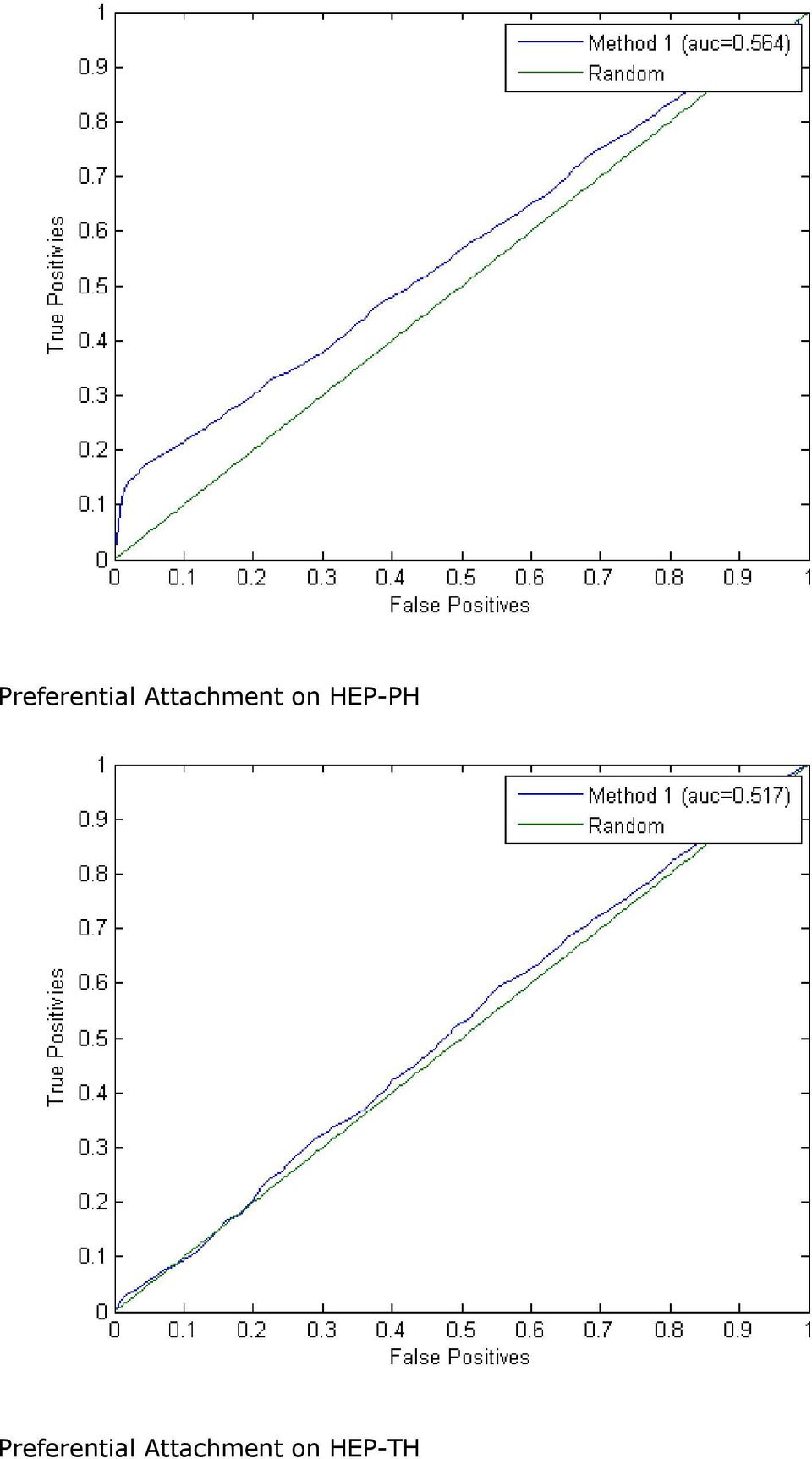
10 Preferential Attachment - This predictor takes the product of the degree of each vertex pair to score the link. We note that it appears to perform better than common neighbors on each data set. Also, HEP-TH accuracy and GR-QC ROC curves seem to exactly match up. We reproduced these results to double check, however, and didn't find any source of error to account for this apparent discrepancy. Weighted Katz Predictor, 1 year training, 1 year testing data. Weighted Katz on GR-QC

11 Weighted Katz on HEP-PH Weighted Katz on HEP-TH

12 Weighted Katz considers the number of, and length of, paths between two nodes to score the link between them. Weighted Katz appears to perform slightly better than Common Neighbors, but worse than Preferential Attachment, except for the case of HEP-PH, where Weighted Katz performs the best. 6. Problems we have encountered The biggest obstacles we had run into is the sheer size of the datasets. With the LiveJournal network spanning around 1.7 million nodes and the MySpace network at around 2.1 million nodes, we quickly run into both time and space restrictions. So far we have been satisfied with taking a simple subset of the graph (usually around 5% or 100,000 nodes) in order to test our predictors, but there is a fairly large problem with taking subsets of social networks. Since social networks are so highly based on clustering (and therefore are not evenly distributed), a bad subset choice could throw away a lot of the useful evidence that could be used in link prediction. We have explored many methods for getting around this problem, including taking a subgraph, which resulted in poor data, as well as attempting to find the "core" of a dataset, as described in Kleinberg [1]. It is possible that the Condor clusters could be used to alleviate this problem, however we have tried many different requirements and configurations of the condor job description and have yet to find one that works even on the fairly simple common neighbors predictor for a full network and finishes in a reasonable amount of time. We have also tried using the sparse() option in MATLAB to take advantage of the fact that the adjacency list description of the networks are sparse, but that also has proven to be unfruitful.

13 We have also explored using low-rank approximations of the full network, and working with those since creation of predictors is of high complexity while predictor testing is a linear operation. After receiving the arxiv data though, we have been successful at using the full dataset for our predictors. Even on the largest dataset and the Katz (most complicated) predictor, runtime is less than an hour. Also of note is our attempt at using spectral graph embedding for link prediction. However, though we were able to get GRACLUS to install correctly and made some attempts at implementing the algorithm, our data didn't seem to be correct and we ran into many bug issues. In the end we decided not to include our incomplete algorithm and just submit the data with which we were comfortable with the quality. 7. Things we learned We enjoyed this project greatly and felt that we got a taste of research in the Data Mining field. We come out of this project with a new appreciation of the complexity of social networks and the difficult problem that is Link Prediction. Of note is the sheer size of the dataset and the time spent on computing it - in no other project have we had to work on computations that lasted for days (and once even a whole week). It is now obvious to us the critical importance of complexity in this field, and the power of smart code to reduce running time by orders of magnitude. We have only scratched the surface of link prediction, but the cleverness of the algorithms and predictor we have examined leave us intrigued towards the possibilities of more powerful, more elegant solutions to this problem. In conclusion, we feel we have learned a great deal from this project and would like to thank both the professor and the TA for the opportunity to work on such an interesting problem. References 1. D. Liben-Nowell and J. Kleinberg. The Link-prediction Problem for Social Networks. In Journal of the American Society for Information Science 58(7), H. Song, T. Cho, V. Dave, Y. Zhang and L. Qiu. Scalable Proximity Estimation and Link Prediction in Online Social Networks. In Proc. of the ACM/USENIX Internet Measurement Conference, The Cooperative Association for Internet Data Analysis (CAIDA). Walrus - Graph Visualization Tool H. Song, B. Savas, T. Cho, V. Dave, Z. Lu, I. S. Dhillon, Y. Zhang and L. Qiu, "Clustered Embedding of Massive Online Social Networks", submitted for publication, February W. Tang. "ROC Curves". CS378 Lecture, Spring D. Ho, E. Shrewsberry. "Link Prediction in Social Networks".

14

Graph Theory and Complex Networks: An Introduction. Chapter 06: Network analysis
 Graph Theory and Complex Networks: An Introduction Maarten van Steen VU Amsterdam, Dept. Computer Science Room R4.0, steen@cs.vu.nl Chapter 06: Network analysis Version: April 8, 04 / 3 Contents Chapter
Graph Theory and Complex Networks: An Introduction Maarten van Steen VU Amsterdam, Dept. Computer Science Room R4.0, steen@cs.vu.nl Chapter 06: Network analysis Version: April 8, 04 / 3 Contents Chapter
Network Metrics, Planar Graphs, and Software Tools. Based on materials by Lala Adamic, UMichigan
 Network Metrics, Planar Graphs, and Software Tools Based on materials by Lala Adamic, UMichigan Network Metrics: Bowtie Model of the Web n The Web is a directed graph: n webpages link to other webpages
Network Metrics, Planar Graphs, and Software Tools Based on materials by Lala Adamic, UMichigan Network Metrics: Bowtie Model of the Web n The Web is a directed graph: n webpages link to other webpages
Part 2: Community Detection
 Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
Chapter 8: Graph Data Part 2: Community Detection Based on Leskovec, Rajaraman, Ullman 2014: Mining of Massive Datasets Big Data Management and Analytics Outline Community Detection - Social networks -
How To Cluster Of Complex Systems
 Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
CS 207 - Data Science and Visualization Spring 2016
 CS 207 - Data Science and Visualization Spring 2016 Professor: Sorelle Friedler sorelle@cs.haverford.edu An introduction to techniques for the automated and human-assisted analysis of data sets. These
CS 207 - Data Science and Visualization Spring 2016 Professor: Sorelle Friedler sorelle@cs.haverford.edu An introduction to techniques for the automated and human-assisted analysis of data sets. These
Graphs over Time Densification Laws, Shrinking Diameters and Possible Explanations
 Graphs over Time Densification Laws, Shrinking Diameters and Possible Explanations Jurij Leskovec, CMU Jon Kleinberg, Cornell Christos Faloutsos, CMU 1 Introduction What can we do with graphs? What patterns
Graphs over Time Densification Laws, Shrinking Diameters and Possible Explanations Jurij Leskovec, CMU Jon Kleinberg, Cornell Christos Faloutsos, CMU 1 Introduction What can we do with graphs? What patterns
Virtual Landmarks for the Internet
 Virtual Landmarks for the Internet Liying Tang Mark Crovella Boston University Computer Science Internet Distance Matters! Useful for configuring Content delivery networks Peer to peer applications Multiuser
Virtual Landmarks for the Internet Liying Tang Mark Crovella Boston University Computer Science Internet Distance Matters! Useful for configuring Content delivery networks Peer to peer applications Multiuser
Protein Protein Interaction Networks
 Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs
 SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs Fabian Hueske, TU Berlin June 26, 21 1 Review This document is a review report on the paper Towards Proximity Pattern Mining in Large
SIGMOD RWE Review Towards Proximity Pattern Mining in Large Graphs Fabian Hueske, TU Berlin June 26, 21 1 Review This document is a review report on the paper Towards Proximity Pattern Mining in Large
How To Understand The Network Of A Network
 Roles in Networks Roles in Networks Motivation for work: Let topology define network roles. Work by Kleinberg on directed graphs, used topology to define two types of roles: authorities and hubs. (Each
Roles in Networks Roles in Networks Motivation for work: Let topology define network roles. Work by Kleinberg on directed graphs, used topology to define two types of roles: authorities and hubs. (Each
Link Prediction Analysis in the Wikipedia Collaboration Graph
 Link Prediction Analysis in the Wikipedia Collaboration Graph Ferenc Molnár Department of Physics, Applied Physics, and Astronomy Rensselaer Polytechnic Institute Troy, New York, 121 Email: molnaf@rpi.edu
Link Prediction Analysis in the Wikipedia Collaboration Graph Ferenc Molnár Department of Physics, Applied Physics, and Astronomy Rensselaer Polytechnic Institute Troy, New York, 121 Email: molnaf@rpi.edu
SIMS 255 Foundations of Software Design. Complexity and NP-completeness
 SIMS 255 Foundations of Software Design Complexity and NP-completeness Matt Welsh November 29, 2001 mdw@cs.berkeley.edu 1 Outline Complexity of algorithms Space and time complexity ``Big O'' notation Complexity
SIMS 255 Foundations of Software Design Complexity and NP-completeness Matt Welsh November 29, 2001 mdw@cs.berkeley.edu 1 Outline Complexity of algorithms Space and time complexity ``Big O'' notation Complexity
Outline. NP-completeness. When is a problem easy? When is a problem hard? Today. Euler Circuits
 Outline NP-completeness Examples of Easy vs. Hard problems Euler circuit vs. Hamiltonian circuit Shortest Path vs. Longest Path 2-pairs sum vs. general Subset Sum Reducing one problem to another Clique
Outline NP-completeness Examples of Easy vs. Hard problems Euler circuit vs. Hamiltonian circuit Shortest Path vs. Longest Path 2-pairs sum vs. general Subset Sum Reducing one problem to another Clique
Big Data Analytics of Multi-Relationship Online Social Network Based on Multi-Subnet Composited Complex Network
 , pp.273-284 http://dx.doi.org/10.14257/ijdta.2015.8.5.24 Big Data Analytics of Multi-Relationship Online Social Network Based on Multi-Subnet Composited Complex Network Gengxin Sun 1, Sheng Bin 2 and
, pp.273-284 http://dx.doi.org/10.14257/ijdta.2015.8.5.24 Big Data Analytics of Multi-Relationship Online Social Network Based on Multi-Subnet Composited Complex Network Gengxin Sun 1, Sheng Bin 2 and
KnowledgeSTUDIO HIGH-PERFORMANCE PREDICTIVE ANALYTICS USING ADVANCED MODELING TECHNIQUES
 HIGH-PERFORMANCE PREDICTIVE ANALYTICS USING ADVANCED MODELING TECHNIQUES Translating data into business value requires the right data mining and modeling techniques which uncover important patterns within
HIGH-PERFORMANCE PREDICTIVE ANALYTICS USING ADVANCED MODELING TECHNIQUES Translating data into business value requires the right data mining and modeling techniques which uncover important patterns within
Graph Theory and Complex Networks: An Introduction. Chapter 06: Network analysis. Contents. Introduction. Maarten van Steen. Version: April 28, 2014
 Graph Theory and Complex Networks: An Introduction Maarten van Steen VU Amsterdam, Dept. Computer Science Room R.0, steen@cs.vu.nl Chapter 0: Version: April 8, 0 / Contents Chapter Description 0: Introduction
Graph Theory and Complex Networks: An Introduction Maarten van Steen VU Amsterdam, Dept. Computer Science Room R.0, steen@cs.vu.nl Chapter 0: Version: April 8, 0 / Contents Chapter Description 0: Introduction
Numerical Algorithms Group. Embedded Analytics. A cure for the common code. www.nag.com. Results Matter. Trust NAG.
 Embedded Analytics A cure for the common code www.nag.com Results Matter. Trust NAG. Executive Summary How much information is there in your data? How much is hidden from you, because you don t have access
Embedded Analytics A cure for the common code www.nag.com Results Matter. Trust NAG. Executive Summary How much information is there in your data? How much is hidden from you, because you don t have access
Computer Algorithms. NP-Complete Problems. CISC 4080 Yanjun Li
 Computer Algorithms NP-Complete Problems NP-completeness The quest for efficient algorithms is about finding clever ways to bypass the process of exhaustive search, using clues from the input in order
Computer Algorithms NP-Complete Problems NP-completeness The quest for efficient algorithms is about finding clever ways to bypass the process of exhaustive search, using clues from the input in order
An Empirical Study of Two MIS Algorithms
 An Empirical Study of Two MIS Algorithms Email: Tushar Bisht and Kishore Kothapalli International Institute of Information Technology, Hyderabad Hyderabad, Andhra Pradesh, India 32. tushar.bisht@research.iiit.ac.in,
An Empirical Study of Two MIS Algorithms Email: Tushar Bisht and Kishore Kothapalli International Institute of Information Technology, Hyderabad Hyderabad, Andhra Pradesh, India 32. tushar.bisht@research.iiit.ac.in,
Graph Mining and Social Network Analysis
 Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
INDEX. Introduction Page 3. Methodology Page 4. Findings. Conclusion. Page 5. Page 10
 FINDINGS 1 INDEX 1 2 3 4 Introduction Page 3 Methodology Page 4 Findings Page 5 Conclusion Page 10 INTRODUCTION Our 2016 Data Scientist report is a follow up to last year s effort. Our aim was to survey
FINDINGS 1 INDEX 1 2 3 4 Introduction Page 3 Methodology Page 4 Findings Page 5 Conclusion Page 10 INTRODUCTION Our 2016 Data Scientist report is a follow up to last year s effort. Our aim was to survey
Graph/Network Visualization
 Graph/Network Visualization Data model: graph structures (relations, knowledge) and networks. Applications: Telecommunication systems, Internet and WWW, Retailers distribution networks knowledge representation
Graph/Network Visualization Data model: graph structures (relations, knowledge) and networks. Applications: Telecommunication systems, Internet and WWW, Retailers distribution networks knowledge representation
Scalable Proximity Estimation and Link Prediction in Online Social Networks
 Scalable Proximity Estimation and Link Prediction in Online Social Networks Han Hee Song Tae Won Cho Vacha Dave Yin Zhang Lili Qiu The University of Texas at Austin {hhsong, khatz, vacha, yzhang, lili}@cs.utexas.edu
Scalable Proximity Estimation and Link Prediction in Online Social Networks Han Hee Song Tae Won Cho Vacha Dave Yin Zhang Lili Qiu The University of Texas at Austin {hhsong, khatz, vacha, yzhang, lili}@cs.utexas.edu
Testing Automation for Distributed Applications By Isabel Drost-Fromm, Software Engineer, Elastic
 Testing Automation for Distributed Applications By Isabel Drost-Fromm, Software Engineer, Elastic The challenge When building distributed, large-scale applications, quality assurance (QA) gets increasingly
Testing Automation for Distributed Applications By Isabel Drost-Fromm, Software Engineer, Elastic The challenge When building distributed, large-scale applications, quality assurance (QA) gets increasingly
Music Mood Classification
 Music Mood Classification CS 229 Project Report Jose Padial Ashish Goel Introduction The aim of the project was to develop a music mood classifier. There are many categories of mood into which songs may
Music Mood Classification CS 229 Project Report Jose Padial Ashish Goel Introduction The aim of the project was to develop a music mood classifier. There are many categories of mood into which songs may
Practical Graph Mining with R. 5. Link Analysis
 Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
Practical Graph Mining with R 5. Link Analysis Outline Link Analysis Concepts Metrics for Analyzing Networks PageRank HITS Link Prediction 2 Link Analysis Concepts Link A relationship between two entities
Hard Disk Drive vs. Kingston SSDNow V+ 200 Series 240GB: Comparative Test
 Hard Disk Drive vs. Kingston Now V+ 200 Series 240GB: Comparative Test Contents Hard Disk Drive vs. Kingston Now V+ 200 Series 240GB: Comparative Test... 1 Hard Disk Drive vs. Solid State Drive: Comparative
Hard Disk Drive vs. Kingston Now V+ 200 Series 240GB: Comparative Test Contents Hard Disk Drive vs. Kingston Now V+ 200 Series 240GB: Comparative Test... 1 Hard Disk Drive vs. Solid State Drive: Comparative
Stability of QOS. Avinash Varadarajan, Subhransu Maji {avinash,smaji}@cs.berkeley.edu
 Stability of QOS Avinash Varadarajan, Subhransu Maji {avinash,smaji}@cs.berkeley.edu Abstract Given a choice between two services, rest of the things being equal, it is natural to prefer the one with more
Stability of QOS Avinash Varadarajan, Subhransu Maji {avinash,smaji}@cs.berkeley.edu Abstract Given a choice between two services, rest of the things being equal, it is natural to prefer the one with more
Knowledge Discovery and Data Mining. Bootstrap review. Bagging Important Concepts. Notes. Lecture 19 - Bagging. Tom Kelsey. Notes
 Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Lecture 6 Online and streaming algorithms for clustering
 CSE 291: Unsupervised learning Spring 2008 Lecture 6 Online and streaming algorithms for clustering 6.1 On-line k-clustering To the extent that clustering takes place in the brain, it happens in an on-line
CSE 291: Unsupervised learning Spring 2008 Lecture 6 Online and streaming algorithms for clustering 6.1 On-line k-clustering To the extent that clustering takes place in the brain, it happens in an on-line
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
White Paper: Impact of Inventory on Network Design
 White Paper: Impact of Inventory on Network Design Written as Research Project at Georgia Tech with support from people at IBM, Northwestern, and Opex Analytics Released: January 2014 Georgia Tech Team
White Paper: Impact of Inventory on Network Design Written as Research Project at Georgia Tech with support from people at IBM, Northwestern, and Opex Analytics Released: January 2014 Georgia Tech Team
Social Media Mining. Graph Essentials
 Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
Graph Essentials Graph Basics Measures Graph and Essentials Metrics 2 2 Nodes and Edges A network is a graph nodes, actors, or vertices (plural of vertex) Connections, edges or ties Edge Node Measures
Distributed Computing over Communication Networks: Maximal Independent Set
 Distributed Computing over Communication Networks: Maximal Independent Set What is a MIS? MIS An independent set (IS) of an undirected graph is a subset U of nodes such that no two nodes in U are adjacent.
Distributed Computing over Communication Networks: Maximal Independent Set What is a MIS? MIS An independent set (IS) of an undirected graph is a subset U of nodes such that no two nodes in U are adjacent.
Automatic Inventory Control: A Neural Network Approach. Nicholas Hall
 Automatic Inventory Control: A Neural Network Approach Nicholas Hall ECE 539 12/18/2003 TABLE OF CONTENTS INTRODUCTION...3 CHALLENGES...4 APPROACH...6 EXAMPLES...11 EXPERIMENTS... 13 RESULTS... 15 CONCLUSION...
Automatic Inventory Control: A Neural Network Approach Nicholas Hall ECE 539 12/18/2003 TABLE OF CONTENTS INTRODUCTION...3 CHALLENGES...4 APPROACH...6 EXAMPLES...11 EXPERIMENTS... 13 RESULTS... 15 CONCLUSION...
MapReduce Algorithms. Sergei Vassilvitskii. Saturday, August 25, 12
 MapReduce Algorithms A Sense of Scale At web scales... Mail: Billions of messages per day Search: Billions of searches per day Social: Billions of relationships 2 A Sense of Scale At web scales... Mail:
MapReduce Algorithms A Sense of Scale At web scales... Mail: Billions of messages per day Search: Billions of searches per day Social: Billions of relationships 2 A Sense of Scale At web scales... Mail:
USING SPECTRAL RADIUS RATIO FOR NODE DEGREE TO ANALYZE THE EVOLUTION OF SCALE- FREE NETWORKS AND SMALL-WORLD NETWORKS
 USING SPECTRAL RADIUS RATIO FOR NODE DEGREE TO ANALYZE THE EVOLUTION OF SCALE- FREE NETWORKS AND SMALL-WORLD NETWORKS Natarajan Meghanathan Jackson State University, 1400 Lynch St, Jackson, MS, USA natarajan.meghanathan@jsums.edu
USING SPECTRAL RADIUS RATIO FOR NODE DEGREE TO ANALYZE THE EVOLUTION OF SCALE- FREE NETWORKS AND SMALL-WORLD NETWORKS Natarajan Meghanathan Jackson State University, 1400 Lynch St, Jackson, MS, USA natarajan.meghanathan@jsums.edu
Mining Social Network Graphs
 Mining Social Network Graphs Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata November 13, 17, 2014 Social Network No introduc+on required Really? We s7ll need to understand
Mining Social Network Graphs Debapriyo Majumdar Data Mining Fall 2014 Indian Statistical Institute Kolkata November 13, 17, 2014 Social Network No introduc+on required Really? We s7ll need to understand
Predictive Modeling Techniques in Insurance
 Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
Predictive Modeling Techniques in Insurance Tuesday May 5, 2015 JF. Breton Application Engineer 2014 The MathWorks, Inc. 1 Opening Presenter: JF. Breton: 13 years of experience in predictive analytics
Big Data Big Deal? Salford Systems www.salford-systems.com
 Big Data Big Deal? Salford Systems www.salford-systems.com 2015 Copyright Salford Systems 2010-2015 Big Data Is The New In Thing Google trends as of September 24, 2015 Difficult to read trade press without
Big Data Big Deal? Salford Systems www.salford-systems.com 2015 Copyright Salford Systems 2010-2015 Big Data Is The New In Thing Google trends as of September 24, 2015 Difficult to read trade press without
Map-like Wikipedia Visualization. Pang Cheong Iao. Master of Science in Software Engineering
 Map-like Wikipedia Visualization by Pang Cheong Iao Master of Science in Software Engineering 2011 Faculty of Science and Technology University of Macau Map-like Wikipedia Visualization by Pang Cheong
Map-like Wikipedia Visualization by Pang Cheong Iao Master of Science in Software Engineering 2011 Faculty of Science and Technology University of Macau Map-like Wikipedia Visualization by Pang Cheong
DECENTRALIZED SCALE-FREE NETWORK CONSTRUCTION AND LOAD BALANCING IN MASSIVE MULTIUSER VIRTUAL ENVIRONMENTS
 DECENTRALIZED SCALE-FREE NETWORK CONSTRUCTION AND LOAD BALANCING IN MASSIVE MULTIUSER VIRTUAL ENVIRONMENTS Markus Esch, Eric Tobias - University of Luxembourg MOTIVATION HyperVerse project Massive Multiuser
DECENTRALIZED SCALE-FREE NETWORK CONSTRUCTION AND LOAD BALANCING IN MASSIVE MULTIUSER VIRTUAL ENVIRONMENTS Markus Esch, Eric Tobias - University of Luxembourg MOTIVATION HyperVerse project Massive Multiuser
Analysis of Algorithms, I
 Analysis of Algorithms, I CSOR W4231.002 Eleni Drinea Computer Science Department Columbia University Thursday, February 26, 2015 Outline 1 Recap 2 Representing graphs 3 Breadth-first search (BFS) 4 Applications
Analysis of Algorithms, I CSOR W4231.002 Eleni Drinea Computer Science Department Columbia University Thursday, February 26, 2015 Outline 1 Recap 2 Representing graphs 3 Breadth-first search (BFS) 4 Applications
V. Adamchik 1. Graph Theory. Victor Adamchik. Fall of 2005
 V. Adamchik 1 Graph Theory Victor Adamchik Fall of 2005 Plan 1. Basic Vocabulary 2. Regular graph 3. Connectivity 4. Representing Graphs Introduction A.Aho and J.Ulman acknowledge that Fundamentally, computer
V. Adamchik 1 Graph Theory Victor Adamchik Fall of 2005 Plan 1. Basic Vocabulary 2. Regular graph 3. Connectivity 4. Representing Graphs Introduction A.Aho and J.Ulman acknowledge that Fundamentally, computer
Subgraph Patterns: Network Motifs and Graphlets. Pedro Ribeiro
 Subgraph Patterns: Network Motifs and Graphlets Pedro Ribeiro Analyzing Complex Networks We have been talking about extracting information from networks Some possible tasks: General Patterns Ex: scale-free,
Subgraph Patterns: Network Motifs and Graphlets Pedro Ribeiro Analyzing Complex Networks We have been talking about extracting information from networks Some possible tasks: General Patterns Ex: scale-free,
Inet-3.0: Internet Topology Generator
 Inet-3.: Internet Topology Generator Jared Winick Sugih Jamin {jwinick,jamin}@eecs.umich.edu CSE-TR-456-2 Abstract In this report we present version 3. of Inet, an Autonomous System (AS) level Internet
Inet-3.: Internet Topology Generator Jared Winick Sugih Jamin {jwinick,jamin}@eecs.umich.edu CSE-TR-456-2 Abstract In this report we present version 3. of Inet, an Autonomous System (AS) level Internet
Asking Hard Graph Questions. Paul Burkhardt. February 3, 2014
 Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Beyond Watson: Predictive Analytics and Big Data U.S. National Security Agency Research Directorate - R6 Technical Report February 3, 2014 300 years before Watson there was Euler! The first (Jeopardy!)
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Social Media Mining. Network Measures
 Klout Measures and Metrics 22 Why Do We Need Measures? Who are the central figures (influential individuals) in the network? What interaction patterns are common in friends? Who are the like-minded users
Klout Measures and Metrics 22 Why Do We Need Measures? Who are the central figures (influential individuals) in the network? What interaction patterns are common in friends? Who are the like-minded users
InfiniteGraph: The Distributed Graph Database
 A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
A Performance and Distributed Performance Benchmark of InfiniteGraph and a Leading Open Source Graph Database Using Synthetic Data Objectivity, Inc. 640 West California Ave. Suite 240 Sunnyvale, CA 94086
Small-World Characteristics of Internet Topologies and Implications on Multicast Scaling
 Small-World Characteristics of Internet Topologies and Implications on Multicast Scaling Shudong Jin Department of Electrical Engineering and Computer Science, Case Western Reserve University Cleveland,
Small-World Characteristics of Internet Topologies and Implications on Multicast Scaling Shudong Jin Department of Electrical Engineering and Computer Science, Case Western Reserve University Cleveland,
How To Find Local Affinity Patterns In Big Data
 Detection of local affinity patterns in big data Andrea Marinoni, Paolo Gamba Department of Electronics, University of Pavia, Italy Abstract Mining information in Big Data requires to design a new class
Detection of local affinity patterns in big data Andrea Marinoni, Paolo Gamba Department of Electronics, University of Pavia, Italy Abstract Mining information in Big Data requires to design a new class
Distributed Dynamic Load Balancing for Iterative-Stencil Applications
 Distributed Dynamic Load Balancing for Iterative-Stencil Applications G. Dethier 1, P. Marchot 2 and P.A. de Marneffe 1 1 EECS Department, University of Liege, Belgium 2 Chemical Engineering Department,
Distributed Dynamic Load Balancing for Iterative-Stencil Applications G. Dethier 1, P. Marchot 2 and P.A. de Marneffe 1 1 EECS Department, University of Liege, Belgium 2 Chemical Engineering Department,
WHITE PAPER. The Top Six Reasons to Simplify the Customer Service Desktop
 The Top Six Reasons to Simplify the Customer Service Desktop Top Six Reasons to Simplify The Customer Service Desktop Hint: Whether you have 1, 3, or 25 applications, you are still dealing with complexity.
The Top Six Reasons to Simplify the Customer Service Desktop Top Six Reasons to Simplify The Customer Service Desktop Hint: Whether you have 1, 3, or 25 applications, you are still dealing with complexity.
Final Project Report
 CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
CPSC545 by Introduction to Data Mining Prof. Martin Schultz & Prof. Mark Gerstein Student Name: Yu Kor Hugo Lam Student ID : 904907866 Due Date : May 7, 2007 Introduction Final Project Report Pseudogenes
An Open Framework for Reverse Engineering Graph Data Visualization. Alexandru C. Telea Eindhoven University of Technology The Netherlands.
 An Open Framework for Reverse Engineering Graph Data Visualization Alexandru C. Telea Eindhoven University of Technology The Netherlands Overview Reverse engineering (RE) overview Limitations of current
An Open Framework for Reverse Engineering Graph Data Visualization Alexandru C. Telea Eindhoven University of Technology The Netherlands Overview Reverse engineering (RE) overview Limitations of current
Distance Degree Sequences for Network Analysis
 Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Universität Konstanz Computer & Information Science Algorithmics Group 15 Mar 2005 based on Palmer, Gibbons, and Faloutsos: ANF A Fast and Scalable Tool for Data Mining in Massive Graphs, SIGKDD 02. Motivation
Hadoop Based Link Prediction Performance Analysis
 Hadoop Based Link Prediction Performance Analysis Yuxiao Dong, Casey Robinson, Jian Xu Department of Computer Science and Engineering University of Notre Dame Notre Dame, IN 46556, USA Email: ydong1@nd.edu,
Hadoop Based Link Prediction Performance Analysis Yuxiao Dong, Casey Robinson, Jian Xu Department of Computer Science and Engineering University of Notre Dame Notre Dame, IN 46556, USA Email: ydong1@nd.edu,
Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs
 1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
1.1 Introduction Lavastorm Analytic Library Predictive and Statistical Analytics Node Pack FAQs For brevity, the Lavastorm Analytics Library (LAL) Predictive and Statistical Analytics Node Pack will be
Six Degrees of Separation in Online Society
 Six Degrees of Separation in Online Society Lei Zhang * Tsinghua-Southampton Joint Lab on Web Science Graduate School in Shenzhen, Tsinghua University Shenzhen, Guangdong Province, P.R.China zhanglei@sz.tsinghua.edu.cn
Six Degrees of Separation in Online Society Lei Zhang * Tsinghua-Southampton Joint Lab on Web Science Graduate School in Shenzhen, Tsinghua University Shenzhen, Guangdong Province, P.R.China zhanglei@sz.tsinghua.edu.cn
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
Adaptive Context-sensitive Analysis for JavaScript
 Adaptive Context-sensitive Analysis for JavaScript Shiyi Wei and Barbara G. Ryder Department of Computer Science Virginia Tech Blacksburg, VA, USA {wei, ryder}@cs.vt.edu Abstract Context sensitivity is
Adaptive Context-sensitive Analysis for JavaScript Shiyi Wei and Barbara G. Ryder Department of Computer Science Virginia Tech Blacksburg, VA, USA {wei, ryder}@cs.vt.edu Abstract Context sensitivity is
Dmitri Krioukov CAIDA/UCSD
 Hyperbolic geometry of complex networks Dmitri Krioukov CAIDA/UCSD dima@caida.org F. Papadopoulos, M. Boguñá, A. Vahdat, and kc claffy Complex networks Technological Internet Transportation Power grid
Hyperbolic geometry of complex networks Dmitri Krioukov CAIDA/UCSD dima@caida.org F. Papadopoulos, M. Boguñá, A. Vahdat, and kc claffy Complex networks Technological Internet Transportation Power grid
CS 2112 Spring 2014. 0 Instructions. Assignment 3 Data Structures and Web Filtering. 0.1 Grading. 0.2 Partners. 0.3 Restrictions
 CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Graph Mining on Big Data System. Presented by Hefu Chai, Rui Zhang, Jian Fang
 Graph Mining on Big Data System Presented by Hefu Chai, Rui Zhang, Jian Fang Outline * Overview * Approaches & Environment * Results * Observations * Notes * Conclusion Overview * What we have done? *
Graph Mining on Big Data System Presented by Hefu Chai, Rui Zhang, Jian Fang Outline * Overview * Approaches & Environment * Results * Observations * Notes * Conclusion Overview * What we have done? *
Complex Network Visualization based on Voronoi Diagram and Smoothed-particle Hydrodynamics
 Complex Network Visualization based on Voronoi Diagram and Smoothed-particle Hydrodynamics Zhao Wenbin 1, Zhao Zhengxu 2 1 School of Instrument Science and Engineering, Southeast University, Nanjing, Jiangsu
Complex Network Visualization based on Voronoi Diagram and Smoothed-particle Hydrodynamics Zhao Wenbin 1, Zhao Zhengxu 2 1 School of Instrument Science and Engineering, Southeast University, Nanjing, Jiangsu
Course Description This course will change the way you think about data and its role in business.
 INFO-GB.3336 Data Mining for Business Analytics Section 32 (Tentative version) Spring 2014 Faculty Class Time Class Location Yilu Zhou, Ph.D. Associate Professor, School of Business, Fordham University
INFO-GB.3336 Data Mining for Business Analytics Section 32 (Tentative version) Spring 2014 Faculty Class Time Class Location Yilu Zhou, Ph.D. Associate Professor, School of Business, Fordham University
STATISTICA. Financial Institutions. Case Study: Credit Scoring. and
 Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Evaluation of a New Method for Measuring the Internet Degree Distribution: Simulation Results
 Evaluation of a New Method for Measuring the Internet Distribution: Simulation Results Christophe Crespelle and Fabien Tarissan LIP6 CNRS and Université Pierre et Marie Curie Paris 6 4 avenue du président
Evaluation of a New Method for Measuring the Internet Distribution: Simulation Results Christophe Crespelle and Fabien Tarissan LIP6 CNRS and Université Pierre et Marie Curie Paris 6 4 avenue du président
Reputation Network Analysis for Email Filtering
 Reputation Network Analysis for Email Filtering Jennifer Golbeck, James Hendler University of Maryland, College Park MINDSWAP 8400 Baltimore Avenue College Park, MD 20742 {golbeck, hendler}@cs.umd.edu
Reputation Network Analysis for Email Filtering Jennifer Golbeck, James Hendler University of Maryland, College Park MINDSWAP 8400 Baltimore Avenue College Park, MD 20742 {golbeck, hendler}@cs.umd.edu
SOCIAL NETWORK ANALYSIS EVALUATING THE CUSTOMER S INFLUENCE FACTOR OVER BUSINESS EVENTS
 SOCIAL NETWORK ANALYSIS EVALUATING THE CUSTOMER S INFLUENCE FACTOR OVER BUSINESS EVENTS Carlos Andre Reis Pinheiro 1 and Markus Helfert 2 1 School of Computing, Dublin City University, Dublin, Ireland
SOCIAL NETWORK ANALYSIS EVALUATING THE CUSTOMER S INFLUENCE FACTOR OVER BUSINESS EVENTS Carlos Andre Reis Pinheiro 1 and Markus Helfert 2 1 School of Computing, Dublin City University, Dublin, Ireland
Understanding Neo4j Scalability
 Understanding Neo4j Scalability David Montag January 2013 Understanding Neo4j Scalability Scalability means different things to different people. Common traits associated include: 1. Redundancy in the
Understanding Neo4j Scalability David Montag January 2013 Understanding Neo4j Scalability Scalability means different things to different people. Common traits associated include: 1. Redundancy in the
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Smart Queue Scheduling for QoS Spring 2001 Final Report
 ENSC 833-3: NETWORK PROTOCOLS AND PERFORMANCE CMPT 885-3: SPECIAL TOPICS: HIGH-PERFORMANCE NETWORKS Smart Queue Scheduling for QoS Spring 2001 Final Report By Haijing Fang(hfanga@sfu.ca) & Liu Tang(llt@sfu.ca)
ENSC 833-3: NETWORK PROTOCOLS AND PERFORMANCE CMPT 885-3: SPECIAL TOPICS: HIGH-PERFORMANCE NETWORKS Smart Queue Scheduling for QoS Spring 2001 Final Report By Haijing Fang(hfanga@sfu.ca) & Liu Tang(llt@sfu.ca)
Applying Social Network Analysis to the Information in CVS Repositories
 Applying Social Network Analysis to the Information in CVS Repositories Luis Lopez-Fernandez, Gregorio Robles, Jesus M. Gonzalez-Barahona GSyC, Universidad Rey Juan Carlos {llopez,grex,jgb}@gsyc.escet.urjc.es
Applying Social Network Analysis to the Information in CVS Repositories Luis Lopez-Fernandez, Gregorio Robles, Jesus M. Gonzalez-Barahona GSyC, Universidad Rey Juan Carlos {llopez,grex,jgb}@gsyc.escet.urjc.es
Performance Metrics for Graph Mining Tasks
 Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
DATA EXPERTS MINE ANALYZE VISUALIZE. We accelerate research and transform data to help you create actionable insights
 DATA EXPERTS We accelerate research and transform data to help you create actionable insights WE MINE WE ANALYZE WE VISUALIZE Domains Data Mining Mining longitudinal and linked datasets from web and other
DATA EXPERTS We accelerate research and transform data to help you create actionable insights WE MINE WE ANALYZE WE VISUALIZE Domains Data Mining Mining longitudinal and linked datasets from web and other
Community Detection Proseminar - Elementary Data Mining Techniques by Simon Grätzer
 Community Detection Proseminar - Elementary Data Mining Techniques by Simon Grätzer 1 Content What is Community Detection? Motivation Defining a community Methods to find communities Overlapping communities
Community Detection Proseminar - Elementary Data Mining Techniques by Simon Grätzer 1 Content What is Community Detection? Motivation Defining a community Methods to find communities Overlapping communities
File Management. Chapter 12
 Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Software tools for Complex Networks Analysis. Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team
 Team") Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Software tools for Complex Networks Analysis Fabrice Huet, University of Nice Sophia- Antipolis SCALE (ex-oasis) Team MOTIVATION Why do we need tools? Source : nature.com Visualization Properties extraction
Energy Efficient MapReduce
 Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
Energy Efficient MapReduce Motivation: Energy consumption is an important aspect of datacenters efficiency, the total power consumption in the united states has doubled from 2000 to 2005, representing
An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset
 P P P Health An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset Peng Liu 1, Elia El-Darzi 2, Lei Lei 1, Christos Vasilakis 2, Panagiotis Chountas 2, and Wei Huang
P P P Health An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset Peng Liu 1, Elia El-Darzi 2, Lei Lei 1, Christos Vasilakis 2, Panagiotis Chountas 2, and Wei Huang
Understanding Sociograms
 Understanding Sociograms A Guide to Understanding Network Analysis Mapping Developed for Clients of: Durland Consulting, Inc. Elburn, IL Durland Consulting, Inc. Elburn IL Copyright 2003 Durland Consulting,
Understanding Sociograms A Guide to Understanding Network Analysis Mapping Developed for Clients of: Durland Consulting, Inc. Elburn, IL Durland Consulting, Inc. Elburn IL Copyright 2003 Durland Consulting,
Leveraging Ensemble Models in SAS Enterprise Miner
 ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
ABSTRACT Paper SAS133-2014 Leveraging Ensemble Models in SAS Enterprise Miner Miguel Maldonado, Jared Dean, Wendy Czika, and Susan Haller SAS Institute Inc. Ensemble models combine two or more models to
LDIF - Linked Data Integration Framework
 LDIF - Linked Data Integration Framework Andreas Schultz 1, Andrea Matteini 2, Robert Isele 1, Christian Bizer 1, and Christian Becker 2 1. Web-based Systems Group, Freie Universität Berlin, Germany a.schultz@fu-berlin.de,
LDIF - Linked Data Integration Framework Andreas Schultz 1, Andrea Matteini 2, Robert Isele 1, Christian Bizer 1, and Christian Becker 2 1. Web-based Systems Group, Freie Universität Berlin, Germany a.schultz@fu-berlin.de,
MODEL SELECTION FOR SOCIAL NETWORKS USING GRAPHLETS
 MODEL SELECTION FOR SOCIAL NETWORKS USING GRAPHLETS JEANNETTE JANSSEN, MATT HURSHMAN, AND NAUZER KALYANIWALLA Abstract. Several network models have been proposed to explain the link structure observed
MODEL SELECTION FOR SOCIAL NETWORKS USING GRAPHLETS JEANNETTE JANSSEN, MATT HURSHMAN, AND NAUZER KALYANIWALLA Abstract. Several network models have been proposed to explain the link structure observed
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Character Image Patterns as Big Data
 22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
22 International Conference on Frontiers in Handwriting Recognition Character Image Patterns as Big Data Seiichi Uchida, Ryosuke Ishida, Akira Yoshida, Wenjie Cai, Yaokai Feng Kyushu University, Fukuoka,
Tableau Server Scalability Explained
 Tableau Server Scalability Explained Author: Neelesh Kamkolkar Tableau Software July 2013 p2 Executive Summary In March 2013, we ran scalability tests to understand the scalability of Tableau 8.0. We wanted
Tableau Server Scalability Explained Author: Neelesh Kamkolkar Tableau Software July 2013 p2 Executive Summary In March 2013, we ran scalability tests to understand the scalability of Tableau 8.0. We wanted
Scala Storage Scale-Out Clustered Storage White Paper
 White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
What is Data Science? Data, Databases, and the Extraction of Knowledge Renée T., @becomingdatasci, November 2014
 What is Data Science? { Data, Databases, and the Extraction of Knowledge Renée T., @becomingdatasci, November 2014 Let s start with: What is Data? http://upload.wikimedia.org/wikipedia/commons/f/f0/darpa
What is Data Science? { Data, Databases, and the Extraction of Knowledge Renée T., @becomingdatasci, November 2014 Let s start with: What is Data? http://upload.wikimedia.org/wikipedia/commons/f/f0/darpa
Grow Revenues and Reduce Risk with Powerful Analytics Software
 Grow Revenues and Reduce Risk with Powerful Analytics Software Overview Gaining knowledge through data selection, data exploration, model creation and predictive action is the key to increasing revenues,
Grow Revenues and Reduce Risk with Powerful Analytics Software Overview Gaining knowledge through data selection, data exploration, model creation and predictive action is the key to increasing revenues,
Big Graph Processing: Some Background
 Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Big Graph Processing: Some Background Bo Wu Colorado School of Mines Part of slides from: Paul Burkhardt (National Security Agency) and Carlos Guestrin (Washington University) Mines CSCI-580, Bo Wu Graphs
Predicting the Stock Market with News Articles
 Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Introducing Performance Engineering by means of Tools and Practical Exercises
 Introducing Performance Engineering by means of Tools and Practical Exercises Alexander Ufimtsev, Trevor Parsons, Lucian M. Patcas, John Murphy and Liam Murphy Performance Engineering Laboratory, School
Introducing Performance Engineering by means of Tools and Practical Exercises Alexander Ufimtsev, Trevor Parsons, Lucian M. Patcas, John Murphy and Liam Murphy Performance Engineering Laboratory, School
Scaling Graphite Installations
 Scaling Graphite Installations Graphite basics Graphite is a web based Graphing program for time series data series plots. Written in Python Consists of multiple separate daemons Has it's own storage backend
Scaling Graphite Installations Graphite basics Graphite is a web based Graphing program for time series data series plots. Written in Python Consists of multiple separate daemons Has it's own storage backend
Brillig Systems Making Projects Successful
 Metrics for Successful Automation Project Management Most automation engineers spend their days controlling manufacturing processes, but spend little or no time controlling their project schedule and budget.
Metrics for Successful Automation Project Management Most automation engineers spend their days controlling manufacturing processes, but spend little or no time controlling their project schedule and budget.