Error Log Processing for Accurate Failure Prediction. Humboldt-Universität zu Berlin
|
|
|
- Donald Daniels
- 8 years ago
- Views:
Transcription

1 Error Log Processing for Accurate Failure Prediction Felix Salfner ICSI Berkeley Steffen Tschirpke Humboldt-Universität zu Berlin

2 Introduction Context of work: Error-based online failure prediction: error events Data used: C A C B data window present time prediction failure? t Commercial telecommunication system 200 components, 2000 classes Error- and failure logs In this talk we present the data preprocessing concepts we applied to obtain accurate failure prediction results 2

3 Contents Key facts on the data Overview of online failure prediction and data preprocessing process Detailed description of major preprocessing concepts Assigning IDs to Error Messages Failure Sequence Clustering Noise Filtering Experiments and Results 3

4 Key Facts on the Data Experimental setup: Telecommunication System response times Call Tracker error logs failure log 200 days of data from a 273 days period 26,991,314 error log records 1,560 failures of two types Failure Definition: response time calls If within a 5 min interval more than 0.01% of calls experience a response time > 250ms 250ms Performance Failures 5 min 5 min t 0.01% > 0.01% Failure! 4

5 Online Failure Prediction Approach: Pattern recognition using Hidden Semi-Markov Models Failure Sequence 1 Non-Failure Sequence 1 Failure Sequence 2 Non-Failure Sequence 2 B C A F A B C B A B F C B A t t d t l t d t d t l t d HSMM for Failure Ssequences HSMM for Non-Failure Sequences Objectives for data preprocessing: Create a data set to train HSMM models exposing key properties of system Identify how to process incoming data during runtime Tasks: Machine-processable data Error-ID assignment Separate sequences for inherent failure mechanisms Clustering Distinguishing, noise-free sequences Noise Filtering 5

6 Training Data Preprocessing Error Log Failure Log Error-ID assignment Tupling Timestamp extraction Sequence Extraction Non-Failure Sequences Failure Sequences Clustering Noise Filtering 1 Noise Filtering u Sequences for Failure-Mechanism 1 Sequences for Failure-Mechanism u Model 0 Model 1 Model u 6

7 Error ID Assignment Problem: Error logs contain no message IDs Example message of a log record: process 34: end of buffer reached Task: Assign an ID to message to characterize what has happened Approach: Two steps: Remove numbers process xx: end of buffer reached ID assignment based on Levenshtein's edit distance with constant threshold Data No of Messages Reduction Original 1,695,160 Without numbers 12,533 Levenshtein 1,435 7

8 Failure Sequence Clustering Error Log Failure Log Error-ID assignment Tupling Timestamp extraction Sequence Extraction Non-Failure Sequences Failure Sequences Clustering Noise Filtering 1 Noise Filtering u Sequences for Failure-Mechanism 1 Sequences for Failure-Mechanism u Model 0 Model 1 Model u 8


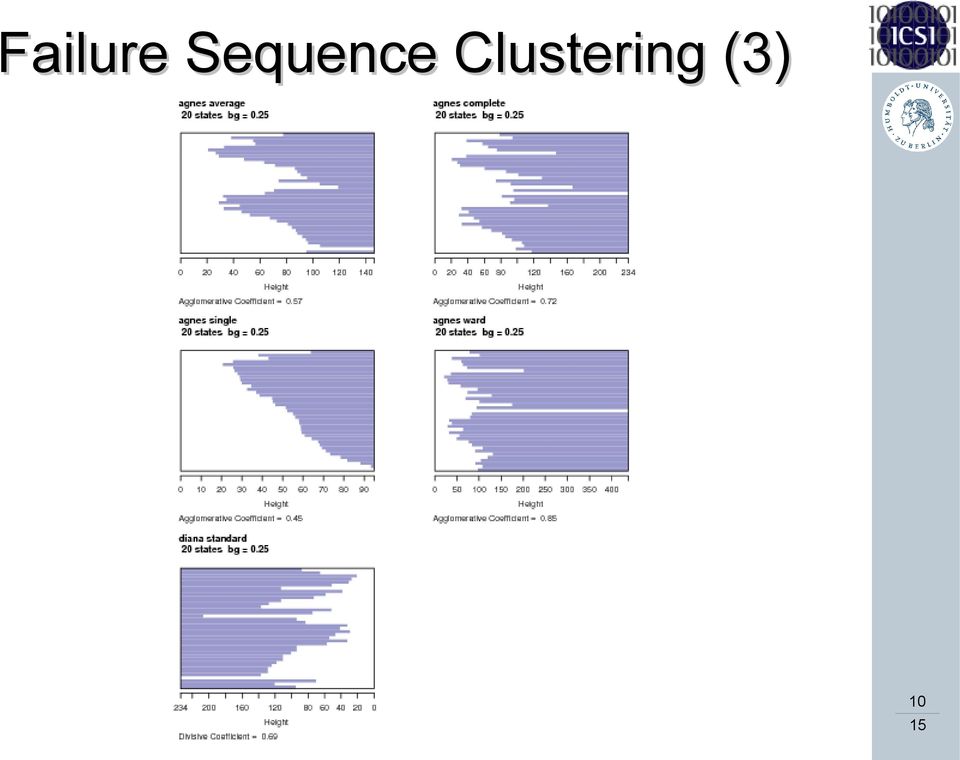
9 Failure Sequence Clustering (2) Goal: Divide set of training failure sequences into subsets Group according to sequence similarity Approach: A F 1 B A A C F 2 B A B F 3 A B Train a small HSMM for each sequence Apply each HSMM to all sequences Sequence log-likelihoods express similarities M 1 M M Make matrix symmetric by Apply standard clustering algorithm 9

")
10 Failure Sequence Clustering (3) 10
11 Noise Filtering Error Log Failure Log Error-ID assignment Tupling Timestamp extraction Sequence Extraction Non-Failure Sequences Failure Sequences Clustering Noise Filtering 1 Noise Filtering u Sequences for Failure-Mechanism 1 Sequences for Failure-Mechanism u Model 0 Model 1 Model u 11

12 Noise Filtering (2) Problem: Clustered failure sequences contain many unrelated errors Main reason: parallelism in the system Assumption: Indicative events occur more frequently prior to a failure than within other sequences Apply a statistical test to quantify what more frequently is A F 1 B A A C F 2 B A B F 3 A B A F 4 A B A C F 5 B A Clustering Filtering Group 1 F 3 F 5 B C A B B A Filtering Group n F 1 F 2 F 4 A B A A C B A A AB A A A C B A B A t t A A B A t Training Sequences for Failure Mechanism 1 Training Sequences for Failure Mechanism n time of failure 12

13 Noise Filtering (3) Testing variable derived from goodness-of-fit test: denotes the number of occurrences of error denotes the total number of errors in the time window. denotes the prior probability of occurrence of error Keep events in the sequence if Three ways to estimate priors from training data set Entire dataset Training sequences G 1 G 3 G 2 G 4 Failure training sequences Results 13

14 Experiments and Results Objective: Predict upcoming failures as accurate as possible Metric used: F-Measure: Precision: relative number of correct alarms to total number of alarms Recall: relative number of correct alarms to total number of failures F-Measure: harmonic mean of precision and recall Failure prediction is achieved by comparing sequence likelihood of an incoming sequence computed from failure and non-failure models Classification involves a customizable decision threshold Maximum F-Measure Data Max. F- Measure Relative Quality Optimal Results % Without grouping % Without filtering % B HSMM for failure sequences Sequence likelihood C t d classification Failure prediction A HSMM for non-failure sequences Sequence likelihood t 14

15 Conclusions We have presented the data preprocessing techniques that we have applied for online failure prediction in a commercial telecommunication system The presented techniques include: Assignment of IDs to error messages using Levenshtein's edit distance Failure sequence clustering Noise filtering based on a statistical test Using error and failure logs of the commercial telecommunication system, we showed that elaborate data preprocessing is an essential step to achieve accurate failure predictions

16 Backup 16

17 Tupling Goal: Remove multiple reporting of the same issue Approach: Problem: Combine messages of the same type if they occur closer in time to each other than a threshold ε. Determine the threshold value ε Solution suggested by Tsao and Siewiorek: Observe the number of tuples for various values of ε and apply the elbow rule ε

18 HSMM Model Structure for Failure Sequence Clustering s 2 s 1 s 3 F s 5 s 4

19 Cluster Distance Metrics Single linkage complete linkage Average linkage

20 Online Failure Prediction Error messages Error ID assignment error message Tuplingsequence Sequence Extraction Filtering 1 Filtering u Model 0 Model 1 Model u Sequence Likelihood 0 Sequence Likelihood 1 Sequence Likelihood u Classification Failure Prediction

21 Comparison of Techniques periodic DFT Eventset SVD-SVM HSMM precision recall F-measure false positive rate 21
22 Hidden Semi-Markov Model g 13 (t) t N-1 F b 1 (A) b 1 (B) b 1 (C) 0 g 12 (t) t b 2 (A) b 2 (B) b 2 (C) 0 g 23 (t) b 3 (A) b 3 (B) Discrete time Markov chain (DTMC) States (1,, N-1,F) Transition probabilities Hidden Markov Model (HMM) t b 3 (C) 0 b N-1 (A) b N-1 (B) b N-1 (C) Each state can generate (error) symbols (A,B,C,F) Discrete probability distribution of symbols per state b i (X) Hidden Semi-Markov Model (HSMM) Time-dependent transition probabilities g ij (t) 22
23 Proactive Fault Management Running System Measurements Failure Avoidance Preparation for Failure Prediction Model Online Failure Prediction 23
Error Log Processing for Accurate Failure Prediction
 Error Log Processing for Accurate Failure Prediction Felix Salfner International Computer Science Institute, Berkeley salfner@icsi.berkeley.edu Steffen Tschirpke Humboldt-Universität zu Berlin tschirpk@informatik.hu-berlin.de
Error Log Processing for Accurate Failure Prediction Felix Salfner International Computer Science Institute, Berkeley salfner@icsi.berkeley.edu Steffen Tschirpke Humboldt-Universität zu Berlin tschirpk@informatik.hu-berlin.de
Proactive Fault Management
 Proactive Fault Management Felix Salfner 7.7.2010 www.rok.informatik.hu-berlin.de/members/salfner Contents Introduction Variable Selection Online Failure Prediction Overview Four Online Failure Prediction
Proactive Fault Management Felix Salfner 7.7.2010 www.rok.informatik.hu-berlin.de/members/salfner Contents Introduction Variable Selection Online Failure Prediction Overview Four Online Failure Prediction
Using Hidden Semi-Markov Models for Effective Online Failure Prediction
 Using Hidden Semi-Markov Models for Effective Online Failure Prediction Felix Salfner and Miroslaw Malek Institut für Informatik, Humboldt-Universität zu Berlin Unter den Linden 6, 10099 Berlin, Germany
Using Hidden Semi-Markov Models for Effective Online Failure Prediction Felix Salfner and Miroslaw Malek Institut für Informatik, Humboldt-Universität zu Berlin Unter den Linden 6, 10099 Berlin, Germany
Online Failure Prediction in Cloud Datacenters
 Online Failure Prediction in Cloud Datacenters Yukihiro Watanabe Yasuhide Matsumoto Once failures occur in a cloud datacenter accommodating a large number of virtual resources, they tend to spread rapidly
Online Failure Prediction in Cloud Datacenters Yukihiro Watanabe Yasuhide Matsumoto Once failures occur in a cloud datacenter accommodating a large number of virtual resources, they tend to spread rapidly
Discovering process models from empirical data
 Discovering process models from empirical data Laura Măruşter (l.maruster@tm.tue.nl), Ton Weijters (a.j.m.m.weijters@tm.tue.nl) and Wil van der Aalst (w.m.p.aalst@tm.tue.nl) Eindhoven University of Technology,
Discovering process models from empirical data Laura Măruşter (l.maruster@tm.tue.nl), Ton Weijters (a.j.m.m.weijters@tm.tue.nl) and Wil van der Aalst (w.m.p.aalst@tm.tue.nl) Eindhoven University of Technology,
Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations
 Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations C. Wright, L. Ballard, S. Coull, F. Monrose, G. Masson Talk held by Goran Doychev Selected Topics in Information Security and
Spot me if you can: Uncovering spoken phrases in encrypted VoIP conversations C. Wright, L. Ballard, S. Coull, F. Monrose, G. Masson Talk held by Goran Doychev Selected Topics in Information Security and
Numerical Field Extraction in Handwritten Incoming Mail Documents
 Numerical Field Extraction in Handwritten Incoming Mail Documents Guillaume Koch, Laurent Heutte and Thierry Paquet PSI, FRE CNRS 2645, Université de Rouen, 76821 Mont-Saint-Aignan, France Laurent.Heutte@univ-rouen.fr
Numerical Field Extraction in Handwritten Incoming Mail Documents Guillaume Koch, Laurent Heutte and Thierry Paquet PSI, FRE CNRS 2645, Université de Rouen, 76821 Mont-Saint-Aignan, France Laurent.Heutte@univ-rouen.fr
Real Time Fraud Detection With Sequence Mining on Big Data Platform. Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA
 Real Time Fraud Detection With Sequence Mining on Big Data Platform Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA Open Source Big Data Eco System Query (NOSQL) : Cassandra,
Real Time Fraud Detection With Sequence Mining on Big Data Platform Pranab Ghosh Big Data Consultant IEEE CNSV meeting, May 6 2014 Santa Clara, CA Open Source Big Data Eco System Query (NOSQL) : Cassandra,
Crowdclustering with Sparse Pairwise Labels: A Matrix Completion Approach
 Outline Crowdclustering with Sparse Pairwise Labels: A Matrix Completion Approach Jinfeng Yi, Rong Jin, Anil K. Jain, Shaili Jain 2012 Presented By : KHALID ALKOBAYER Crowdsourcing and Crowdclustering
Outline Crowdclustering with Sparse Pairwise Labels: A Matrix Completion Approach Jinfeng Yi, Rong Jin, Anil K. Jain, Shaili Jain 2012 Presented By : KHALID ALKOBAYER Crowdsourcing and Crowdclustering
LogMaster: Mining Event Correlations in Logs of Large-scale Cluster Systems
 2012 31st International Symposium on Reliable Distributed Systems LogMaster: Mining Event Correlations in Logs of Large-scale Cluster Systems Xiaoyu Fu, Rui Ren, Jianfeng Zhan, Wei Zhou, Zhen Jia, Gang
2012 31st International Symposium on Reliable Distributed Systems LogMaster: Mining Event Correlations in Logs of Large-scale Cluster Systems Xiaoyu Fu, Rui Ren, Jianfeng Zhan, Wei Zhou, Zhen Jia, Gang
W6.B.1. FAQs CS535 BIG DATA W6.B.3. 4. If the distance of the point is additionally less than the tight distance T 2, remove it from the original set
 http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
http://wwwcscolostateedu/~cs535 W6B W6B2 CS535 BIG DAA FAQs Please prepare for the last minute rush Store your output files safely Partial score will be given for the output from less than 50GB input Computer
Alignment and Preprocessing for Data Analysis
 Alignment and Preprocessing for Data Analysis Preprocessing tools for chromatography Basics of alignment GC FID (D) data and issues PCA F Ratios GC MS (D) data and issues PCA F Ratios PARAFAC Piecewise
Alignment and Preprocessing for Data Analysis Preprocessing tools for chromatography Basics of alignment GC FID (D) data and issues PCA F Ratios GC MS (D) data and issues PCA F Ratios PARAFAC Piecewise
Supply chain management by means of FLM-rules
 Supply chain management by means of FLM-rules Nicolas Le Normand, Julien Boissière, Nicolas Méger, Lionel Valet LISTIC Laboratory - Polytech Savoie Université de Savoie B.P. 80439 F-74944 Annecy-Le-Vieux,
Supply chain management by means of FLM-rules Nicolas Le Normand, Julien Boissière, Nicolas Méger, Lionel Valet LISTIC Laboratory - Polytech Savoie Université de Savoie B.P. 80439 F-74944 Annecy-Le-Vieux,
Document Image Retrieval using Signatures as Queries
 Document Image Retrieval using Signatures as Queries Sargur N. Srihari, Shravya Shetty, Siyuan Chen, Harish Srinivasan, Chen Huang CEDAR, University at Buffalo(SUNY) Amherst, New York 14228 Gady Agam and
Document Image Retrieval using Signatures as Queries Sargur N. Srihari, Shravya Shetty, Siyuan Chen, Harish Srinivasan, Chen Huang CEDAR, University at Buffalo(SUNY) Amherst, New York 14228 Gady Agam and
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree
 Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Practical Online Failure Prediction for Blue Gene/P: Period-based vs Event-driven
 Practical Online Failure Prediction for Blue Gene/P: Period-based vs Event-driven Li Yu, Ziming Zheng, Zhiling Lan Department of Computer Science Illinois Institute of Technology {lyu17, zzheng11, lan}@iit.edu
Practical Online Failure Prediction for Blue Gene/P: Period-based vs Event-driven Li Yu, Ziming Zheng, Zhiling Lan Department of Computer Science Illinois Institute of Technology {lyu17, zzheng11, lan}@iit.edu
Mining the Software Change Repository of a Legacy Telephony System
 Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
Mining the Software Change Repository of a Legacy Telephony System Jelber Sayyad Shirabad, Timothy C. Lethbridge, Stan Matwin School of Information Technology and Engineering University of Ottawa, Ottawa,
System Management and Operation for Cloud Computing Systems
 System Management and Operation for Cloud Computing Systems Motomitsu Adachi Toshihiro Kodaka Motoyuki Kawaba Yasuhide Matsumoto With the progress of virtualization technology, cloud systems have been
System Management and Operation for Cloud Computing Systems Motomitsu Adachi Toshihiro Kodaka Motoyuki Kawaba Yasuhide Matsumoto With the progress of virtualization technology, cloud systems have been
FALSE ALARMS IN FAULT-TOLERANT DOMINATING SETS IN GRAPHS. Mateusz Nikodem
 Opuscula Mathematica Vol. 32 No. 4 2012 http://dx.doi.org/10.7494/opmath.2012.32.4.751 FALSE ALARMS IN FAULT-TOLERANT DOMINATING SETS IN GRAPHS Mateusz Nikodem Abstract. We develop the problem of fault-tolerant
Opuscula Mathematica Vol. 32 No. 4 2012 http://dx.doi.org/10.7494/opmath.2012.32.4.751 FALSE ALARMS IN FAULT-TOLERANT DOMINATING SETS IN GRAPHS Mateusz Nikodem Abstract. We develop the problem of fault-tolerant
Implementing Heuristic Miner for Different Types of Event Logs
 Implementing Heuristic Miner for Different Types of Event Logs Angelina Prima Kurniati 1, GunturPrabawa Kusuma 2, GedeAgungAry Wisudiawan 3 1,3 School of Compuing, Telkom University, Indonesia. 2 School
Implementing Heuristic Miner for Different Types of Event Logs Angelina Prima Kurniati 1, GunturPrabawa Kusuma 2, GedeAgungAry Wisudiawan 3 1,3 School of Compuing, Telkom University, Indonesia. 2 School
Detection. Perspective. Network Anomaly. Bhattacharyya. Jugal. A Machine Learning »C) Dhruba Kumar. Kumar KaKta. CRC Press J Taylor & Francis Croup
 Dhruba Kumar. Kumar KaKta. CRC Press J Taylor & Francis Croup") Network Anomaly Detection A Machine Learning Perspective Dhruba Kumar Bhattacharyya Jugal Kumar KaKta»C) CRC Press J Taylor & Francis Croup Boca Raton London New York CRC Press is an imprint of the Taylor
Network Anomaly Detection A Machine Learning Perspective Dhruba Kumar Bhattacharyya Jugal Kumar KaKta»C) CRC Press J Taylor & Francis Croup Boca Raton London New York CRC Press is an imprint of the Taylor
How To Use Neural Networks In Data Mining
 International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
GETTING STARTED WITH LABVIEW POINT-BY-POINT VIS
 USER GUIDE GETTING STARTED WITH LABVIEW POINT-BY-POINT VIS Contents Using the LabVIEW Point-By-Point VI Libraries... 2 Initializing Point-By-Point VIs... 3 Frequently Asked Questions... 5 What Are the
USER GUIDE GETTING STARTED WITH LABVIEW POINT-BY-POINT VIS Contents Using the LabVIEW Point-By-Point VI Libraries... 2 Initializing Point-By-Point VIs... 3 Frequently Asked Questions... 5 What Are the
Large-Scale Data Sets Clustering Based on MapReduce and Hadoop
 Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Journal of Computational Information Systems 7: 16 (2011) 5956-5963 Available at http://www.jofcis.com Large-Scale Data Sets Clustering Based on MapReduce and Hadoop Ping ZHOU, Jingsheng LEI, Wenjun YE
Ericsson T18s Voice Dialing Simulator
 Ericsson T18s Voice Dialing Simulator Mauricio Aracena Kovacevic, Anna Dehlbom, Jakob Ekeberg, Guillaume Gariazzo, Eric Lästh and Vanessa Troncoso Dept. of Signals Sensors and Systems Royal Institute of
Ericsson T18s Voice Dialing Simulator Mauricio Aracena Kovacevic, Anna Dehlbom, Jakob Ekeberg, Guillaume Gariazzo, Eric Lästh and Vanessa Troncoso Dept. of Signals Sensors and Systems Royal Institute of
POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing. By: Chris Abbott
 POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing By: Chris Abbott Introduction What is penetration testing? Methodology for assessing network security, by generating and executing
POMPDs Make Better Hackers: Accounting for Uncertainty in Penetration Testing By: Chris Abbott Introduction What is penetration testing? Methodology for assessing network security, by generating and executing
Failure Prediction in IBM BlueGene/L Event Logs
 Seventh IEEE International Conference on Data Mining Failure Prediction in IBM BlueGene/L Event Logs Yinglung Liang, Yanyong Zhang ECE Department, Rutgers University {ylliang, yyzhang}@ece.rutgers.edu
Seventh IEEE International Conference on Data Mining Failure Prediction in IBM BlueGene/L Event Logs Yinglung Liang, Yanyong Zhang ECE Department, Rutgers University {ylliang, yyzhang}@ece.rutgers.edu
Less naive Bayes spam detection
 Less naive Bayes spam detection Hongming Yang Eindhoven University of Technology Dept. EE, Rm PT 3.27, P.O.Box 53, 5600MB Eindhoven The Netherlands. E-mail:h.m.yang@tue.nl also CoSiNe Connectivity Systems
Less naive Bayes spam detection Hongming Yang Eindhoven University of Technology Dept. EE, Rm PT 3.27, P.O.Box 53, 5600MB Eindhoven The Netherlands. E-mail:h.m.yang@tue.nl also CoSiNe Connectivity Systems
Problem Detection and Diagnosis under Sporadic Operations and Changes
 Problem Detection and Diagnosis under Sporadic Operations and Changes Liming Zhu, Research Group Leader, NICTA SPEC DevOps WG, 2015 May. NICTA (National ICT Australia) Australia s National Centre of Excellence
Problem Detection and Diagnosis under Sporadic Operations and Changes Liming Zhu, Research Group Leader, NICTA SPEC DevOps WG, 2015 May. NICTA (National ICT Australia) Australia s National Centre of Excellence
Discovering Structured Event Logs from Unstructured Audit Trails for Workflow Mining
 Discovering Structured Event Logs from Unstructured Audit Trails for Workflow Mining Liqiang Geng 1, Scott Buffett 1, Bruce Hamilton 1, Xin Wang 2, Larry Korba 1, Hongyu Liu 1, and Yunli Wang 1 1 IIT,
Discovering Structured Event Logs from Unstructured Audit Trails for Workflow Mining Liqiang Geng 1, Scott Buffett 1, Bruce Hamilton 1, Xin Wang 2, Larry Korba 1, Hongyu Liu 1, and Yunli Wang 1 1 IIT,
Cluster Analysis. Isabel M. Rodrigues. Lisboa, 2014. Instituto Superior Técnico
 Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Instituto Superior Técnico Lisboa, 2014 Introduction: Cluster analysis What is? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Finding soon-to-fail disks in a haystack
 Finding soon-to-fail disks in a haystack Moises Goldszmidt Microsoft Research Abstract This paper presents a detector of soon-to-fail disks based on a combination of statistical models. During operation
Finding soon-to-fail disks in a haystack Moises Goldszmidt Microsoft Research Abstract This paper presents a detector of soon-to-fail disks based on a combination of statistical models. During operation
Discrete Optimization
 Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING
 A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
Proactive self-healing mechanisms for IP networks. IETF89/NMRG33 London Bruno Vidalenc, Laurent Ciavaglia
 Proactive self-healing mechanisms for IP networks IETF89/NMRG33 London Bruno Vidalenc, Laurent Ciavaglia 1 Overview Goal: extra-resilient IP networks How: new autonomic capability Proactive and adaptive
Proactive self-healing mechanisms for IP networks IETF89/NMRG33 London Bruno Vidalenc, Laurent Ciavaglia 1 Overview Goal: extra-resilient IP networks How: new autonomic capability Proactive and adaptive
Inferring Probabilistic Models of cis-regulatory Modules. BMI/CS 776 www.biostat.wisc.edu/bmi776/ Spring 2015 Colin Dewey cdewey@biostat.wisc.
 Inferring Probabilistic Models of cis-regulatory Modules MI/S 776 www.biostat.wisc.edu/bmi776/ Spring 2015 olin Dewey cdewey@biostat.wisc.edu Goals for Lecture the key concepts to understand are the following
Inferring Probabilistic Models of cis-regulatory Modules MI/S 776 www.biostat.wisc.edu/bmi776/ Spring 2015 olin Dewey cdewey@biostat.wisc.edu Goals for Lecture the key concepts to understand are the following
Nino Pellegrino October the 20th, 2015
 Learning Behavioral Fingerprints from NetFlows... using Timed Automata Nino Pellegrino October the 20th, 2015 Nino Pellegrino Learning Behavioral Fingerprints October the 20th, 2015 1 / 32 Use case Nino
Learning Behavioral Fingerprints from NetFlows... using Timed Automata Nino Pellegrino October the 20th, 2015 Nino Pellegrino Learning Behavioral Fingerprints October the 20th, 2015 1 / 32 Use case Nino
User Authentication/Identification From Web Browsing Behavior
 User Authentication/Identification From Web Browsing Behavior US Naval Research Laboratory PI: Myriam Abramson, Code 5584 Shantanu Gore, SEAP Student, Code 5584 David Aha, Code 5514 Steve Russell, Code
User Authentication/Identification From Web Browsing Behavior US Naval Research Laboratory PI: Myriam Abramson, Code 5584 Shantanu Gore, SEAP Student, Code 5584 David Aha, Code 5514 Steve Russell, Code
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Introduction. A. Bellaachia Page: 1
 Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS
 UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
UNSUPERVISED MACHINE LEARNING TECHNIQUES IN GENOMICS Dwijesh C. Mishra I.A.S.R.I., Library Avenue, New Delhi-110 012 dcmishra@iasri.res.in What is Learning? "Learning denotes changes in a system that enable
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS
 DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
DATA MINING CLUSTER ANALYSIS: BASIC CONCEPTS 1 AND ALGORITHMS Chiara Renso KDD-LAB ISTI- CNR, Pisa, Italy WHAT IS CLUSTER ANALYSIS? Finding groups of objects such that the objects in a group will be similar
Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data
 Master of Business Information Systems, Department of Mathematics and Computer Science Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data Master Thesis Author: ing. Y.P.J.M.
Master of Business Information Systems, Department of Mathematics and Computer Science Using Trace Clustering for Configurable Process Discovery Explained by Event Log Data Master Thesis Author: ing. Y.P.J.M.
A NEW HYBRID ALGORITHM FOR BUSINESS INTELLIGENCE RECOMMENDER SYSTEM
 A NEW HYBRID ALGORITHM FOR BUSINESS INTELLIGENCE RECOMMENDER SYSTEM PPrabhu 1 and NAnbazhagan 2 1 Directorate of Distance Education, Alagappa University, Karaikudi, Tamilnadu, INDIA 2 Department of Mathematics,
A NEW HYBRID ALGORITHM FOR BUSINESS INTELLIGENCE RECOMMENDER SYSTEM PPrabhu 1 and NAnbazhagan 2 1 Directorate of Distance Education, Alagappa University, Karaikudi, Tamilnadu, INDIA 2 Department of Mathematics,
Failures of software have been identified as the single largest source of unplanned downtime and
 Advanced Failure Prediction in Complex Software Systems Günther A. Hoffmann, Felix Salfner, Miroslaw Malek Humboldt University Berlin, Department of Computer Science, Computer Architecture and Communication
Advanced Failure Prediction in Complex Software Systems Günther A. Hoffmann, Felix Salfner, Miroslaw Malek Humboldt University Berlin, Department of Computer Science, Computer Architecture and Communication
Database Marketing, Business Intelligence and Knowledge Discovery
 Database Marketing, Business Intelligence and Knowledge Discovery Note: Using material from Tan / Steinbach / Kumar (2005) Introduction to Data Mining,, Addison Wesley; and Cios / Pedrycz / Swiniarski
Database Marketing, Business Intelligence and Knowledge Discovery Note: Using material from Tan / Steinbach / Kumar (2005) Introduction to Data Mining,, Addison Wesley; and Cios / Pedrycz / Swiniarski
Convention Paper Presented at the 135th Convention 2013 October 17 20 New York, USA
 Audio Engineering Society Convention Paper Presented at the 135th Convention 2013 October 17 20 New York, USA This Convention paper was selected based on a submitted abstract and 750-word precis that have
Audio Engineering Society Convention Paper Presented at the 135th Convention 2013 October 17 20 New York, USA This Convention paper was selected based on a submitted abstract and 750-word precis that have
1. Classification problems
 Neural and Evolutionary Computing. Lab 1: Classification problems Machine Learning test data repository Weka data mining platform Introduction Scilab 1. Classification problems The main aim of a classification
Neural and Evolutionary Computing. Lab 1: Classification problems Machine Learning test data repository Weka data mining platform Introduction Scilab 1. Classification problems The main aim of a classification
Three Methods for ediscovery Document Prioritization:
 Three Methods for ediscovery Document Prioritization: Comparing and Contrasting Keyword Search with Concept Based and Support Vector Based "Technology Assisted Review-Predictive Coding" Platforms Tom Groom,
Three Methods for ediscovery Document Prioritization: Comparing and Contrasting Keyword Search with Concept Based and Support Vector Based "Technology Assisted Review-Predictive Coding" Platforms Tom Groom,
Data Mining Clustering (2) Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining
 Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining") Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining Clustering (2) Toon Calders Sheets are based on the those provided by Tan, Steinbach, and Kumar. Introduction to Data Mining Outline Partitional Clustering Distance-based K-means, K-medoids,
Data Mining 5. Cluster Analysis
 Data Mining 5. Cluster Analysis 5.2 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Data Structures Interval-Valued (Numeric) Variables Binary Variables Categorical Variables Ordinal Variables Variables
Data Mining 5. Cluster Analysis 5.2 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Data Structures Interval-Valued (Numeric) Variables Binary Variables Categorical Variables Ordinal Variables Variables
Examining Case Management Demand using Event Log Complexity Metrics
 Examining Case Management Demand using Event Log Complexity Metrics @Adaptive CM 2014 Workshop Marian Benner-Wickner, Matthias Book, Tobias Brückmann, Volker Gruhn Agenda Problem domain Event log complexity
Examining Case Management Demand using Event Log Complexity Metrics @Adaptive CM 2014 Workshop Marian Benner-Wickner, Matthias Book, Tobias Brückmann, Volker Gruhn Agenda Problem domain Event log complexity
Visual-based ID Verification by Signature Tracking
 Visual-based ID Verification by Signature Tracking Mario E. Munich and Pietro Perona California Institute of Technology www.vision.caltech.edu/mariomu Outline Biometric ID Visual Signature Acquisition
Visual-based ID Verification by Signature Tracking Mario E. Munich and Pietro Perona California Institute of Technology www.vision.caltech.edu/mariomu Outline Biometric ID Visual Signature Acquisition
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
DNA: An Online Algorithm for Credit Card Fraud Detection for Games Merchants
 DNA: An Online Algorithm for Credit Card Fraud Detection for Games Merchants Michael Schaidnagel D-72072 Tübingen, Germany Michael.Schaidnagel@web.de Ilia Petrov, Fritz Laux Data Management Lab Reutlingen
DNA: An Online Algorithm for Credit Card Fraud Detection for Games Merchants Michael Schaidnagel D-72072 Tübingen, Germany Michael.Schaidnagel@web.de Ilia Petrov, Fritz Laux Data Management Lab Reutlingen
The Basics of Graphical Models
 The Basics of Graphical Models David M. Blei Columbia University October 3, 2015 Introduction These notes follow Chapter 2 of An Introduction to Probabilistic Graphical Models by Michael Jordan. Many figures
The Basics of Graphical Models David M. Blei Columbia University October 3, 2015 Introduction These notes follow Chapter 2 of An Introduction to Probabilistic Graphical Models by Michael Jordan. Many figures
Web Usage Mining: Identification of Trends Followed by the user through Neural Network
 International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 3, Number 7 (2013), pp. 617-624 International Research Publications House http://www. irphouse.com /ijict.htm Web
International Journal of Information and Computation Technology. ISSN 0974-2239 Volume 3, Number 7 (2013), pp. 617-624 International Research Publications House http://www. irphouse.com /ijict.htm Web
FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT MINING SYSTEM
 International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
International Journal of Innovative Computing, Information and Control ICIC International c 0 ISSN 34-48 Volume 8, Number 8, August 0 pp. 4 FUZZY CLUSTERING ANALYSIS OF DATA MINING: APPLICATION TO AN ACCIDENT
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
ECE 533 Project Report Ashish Dhawan Aditi R. Ganesan
 Handwritten Signature Verification ECE 533 Project Report by Ashish Dhawan Aditi R. Ganesan Contents 1. Abstract 3. 2. Introduction 4. 3. Approach 6. 4. Pre-processing 8. 5. Feature Extraction 9. 6. Verification
Handwritten Signature Verification ECE 533 Project Report by Ashish Dhawan Aditi R. Ganesan Contents 1. Abstract 3. 2. Introduction 4. 3. Approach 6. 4. Pre-processing 8. 5. Feature Extraction 9. 6. Verification
Discrete Hidden Markov Model Training Based on Variable Length Particle Swarm Optimization Algorithm
 Discrete Hidden Markov Model Training Based on Variable Length Discrete Hidden Markov Model Training Based on Variable Length 12 Xiaobin Li, 1Jiansheng Qian, 1Zhikai Zhao School of Computer Science and
Discrete Hidden Markov Model Training Based on Variable Length Discrete Hidden Markov Model Training Based on Variable Length 12 Xiaobin Li, 1Jiansheng Qian, 1Zhikai Zhao School of Computer Science and
TELEMETRY NETWORK INTRUSION DETECTION SYSTEM
 TELEMETRY NETWORK INTRUSION DETECTION SYSTEM Authors: Nadim Maharjan and Paria Moazzemi Advisors: Dr. Richard Dean, Dr. Farzad Moazzami and Dr. Yacob Astatke Department of Electrical and Computer Engineering
TELEMETRY NETWORK INTRUSION DETECTION SYSTEM Authors: Nadim Maharjan and Paria Moazzemi Advisors: Dr. Richard Dean, Dr. Farzad Moazzami and Dr. Yacob Astatke Department of Electrical and Computer Engineering
The CUSUM algorithm a small review. Pierre Granjon
 The CUSUM algorithm a small review Pierre Granjon June, 1 Contents 1 The CUSUM algorithm 1.1 Algorithm............................... 1.1.1 The problem......................... 1.1. The different steps......................
The CUSUM algorithm a small review Pierre Granjon June, 1 Contents 1 The CUSUM algorithm 1.1 Algorithm............................... 1.1.1 The problem......................... 1.1. The different steps......................
TIETS34 Seminar: Data Mining on Biometric identification
 TIETS34 Seminar: Data Mining on Biometric identification Youming Zhang Computer Science, School of Information Sciences, 33014 University of Tampere, Finland Youming.Zhang@uta.fi Course Description Content
TIETS34 Seminar: Data Mining on Biometric identification Youming Zhang Computer Science, School of Information Sciences, 33014 University of Tampere, Finland Youming.Zhang@uta.fi Course Description Content
Approximate Search Engine Optimization for Directory Service
 Approximate Search Engine Optimization for Directory Service Kai-Hsiang Yang and Chi-Chien Pan and Tzao-Lin Lee Department of Computer Science and Information Engineering, National Taiwan University, Taipei,
Approximate Search Engine Optimization for Directory Service Kai-Hsiang Yang and Chi-Chien Pan and Tzao-Lin Lee Department of Computer Science and Information Engineering, National Taiwan University, Taipei,
The Role of Size Normalization on the Recognition Rate of Handwritten Numerals
 The Role of Size Normalization on the Recognition Rate of Handwritten Numerals Chun Lei He, Ping Zhang, Jianxiong Dong, Ching Y. Suen, Tien D. Bui Centre for Pattern Recognition and Machine Intelligence,
The Role of Size Normalization on the Recognition Rate of Handwritten Numerals Chun Lei He, Ping Zhang, Jianxiong Dong, Ching Y. Suen, Tien D. Bui Centre for Pattern Recognition and Machine Intelligence,
A Statistical Text Mining Method for Patent Analysis
 A Statistical Text Mining Method for Patent Analysis Department of Statistics Cheongju University, shjun@cju.ac.kr Abstract Most text data from diverse document databases are unsuitable for analytical
A Statistical Text Mining Method for Patent Analysis Department of Statistics Cheongju University, shjun@cju.ac.kr Abstract Most text data from diverse document databases are unsuitable for analytical
Probabilistic Model Checking at Runtime for the Provisioning of Cloud Resources
 Probabilistic Model Checking at Runtime for the Provisioning of Cloud Resources Athanasios Naskos, Emmanouela Stachtiari, Panagiotis Katsaros, and Anastasios Gounaris Aristotle University of Thessaloniki,
Probabilistic Model Checking at Runtime for the Provisioning of Cloud Resources Athanasios Naskos, Emmanouela Stachtiari, Panagiotis Katsaros, and Anastasios Gounaris Aristotle University of Thessaloniki,
Introduction to Algorithmic Trading Strategies Lecture 2
 Introduction to Algorithmic Trading Strategies Lecture 2 Hidden Markov Trading Model Haksun Li haksun.li@numericalmethod.com www.numericalmethod.com Outline Carry trade Momentum Valuation CAPM Markov chain
Introduction to Algorithmic Trading Strategies Lecture 2 Hidden Markov Trading Model Haksun Li haksun.li@numericalmethod.com www.numericalmethod.com Outline Carry trade Momentum Valuation CAPM Markov chain
Intelligent Log Analyzer. André Restivo <andre.restivo@portugalmail.pt>
 Intelligent Log Analyzer André Restivo 9th January 2003 Abstract Server Administrators often have to analyze server logs to find if something is wrong with their machines.
Intelligent Log Analyzer André Restivo 9th January 2003 Abstract Server Administrators often have to analyze server logs to find if something is wrong with their machines.
Classification of Household Devices by Electricity Usage Profiles
 Classification of Household Devices by Electricity Usage Profiles Jason Lines 1, Anthony Bagnall 1, Patrick Caiger-Smith 2, and Simon Anderson 2 1 School of Computing Sciences University of East Anglia
Classification of Household Devices by Electricity Usage Profiles Jason Lines 1, Anthony Bagnall 1, Patrick Caiger-Smith 2, and Simon Anderson 2 1 School of Computing Sciences University of East Anglia
Probabilistic Latent Semantic Analysis (plsa)
") Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org} References
Probabilistic Latent Semantic Analysis (plsa) SS 2008 Bayesian Networks Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org} References
Globally Optimal Crowdsourcing Quality Management
 Globally Optimal Crowdsourcing Quality Management Akash Das Sarma Stanford University akashds@stanford.edu Aditya G. Parameswaran University of Illinois (UIUC) adityagp@illinois.edu Jennifer Widom Stanford
Globally Optimal Crowdsourcing Quality Management Akash Das Sarma Stanford University akashds@stanford.edu Aditya G. Parameswaran University of Illinois (UIUC) adityagp@illinois.edu Jennifer Widom Stanford
A Framework for Intelligent Online Customer Service System
 A Framework for Intelligent Online Customer Service System Yiping WANG Yongjin ZHANG School of Business Administration, Xi an University of Technology Abstract: In a traditional customer service support
A Framework for Intelligent Online Customer Service System Yiping WANG Yongjin ZHANG School of Business Administration, Xi an University of Technology Abstract: In a traditional customer service support
NC STATE UNIVERSITY Exploratory Analysis of Massive Data for Distribution Fault Diagnosis in Smart Grids
 Exploratory Analysis of Massive Data for Distribution Fault Diagnosis in Smart Grids Yixin Cai, Mo-Yuen Chow Electrical and Computer Engineering, North Carolina State University July 2009 Outline Introduction
Exploratory Analysis of Massive Data for Distribution Fault Diagnosis in Smart Grids Yixin Cai, Mo-Yuen Chow Electrical and Computer Engineering, North Carolina State University July 2009 Outline Introduction
BigData. An Overview of Several Approaches. David Mera 16/12/2013. Masaryk University Brno, Czech Republic
 BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
BigData An Overview of Several Approaches David Mera Masaryk University Brno, Czech Republic 16/12/2013 Table of Contents 1 Introduction 2 Terminology 3 Approaches focused on batch data processing MapReduce-Hadoop
How To Cluster Of Complex Systems
 Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Exploiting Evidence from Unstructured Data to Enhance Master Data Management
 Exploiting Evidence from Unstructured Data to Enhance Master Data Management Karin Murthy 1 Prasad M Deshpande 1 Atreyee Dey 1 Ramanujam Halasipuram 1 Mukesh Mohania 1 Deepak P 1 Jennifer Reed 2 Scott
Exploiting Evidence from Unstructured Data to Enhance Master Data Management Karin Murthy 1 Prasad M Deshpande 1 Atreyee Dey 1 Ramanujam Halasipuram 1 Mukesh Mohania 1 Deepak P 1 Jennifer Reed 2 Scott
Enhancing Quality of Data using Data Mining Method
 JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2, ISSN 25-967 WWW.JOURNALOFCOMPUTING.ORG 9 Enhancing Quality of Data using Data Mining Method Fatemeh Ghorbanpour A., Mir M. Pedram, Kambiz Badie, Mohammad
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2, ISSN 25-967 WWW.JOURNALOFCOMPUTING.ORG 9 Enhancing Quality of Data using Data Mining Method Fatemeh Ghorbanpour A., Mir M. Pedram, Kambiz Badie, Mohammad
EXPLORING SPATIAL PATTERNS IN YOUR DATA
 EXPLORING SPATIAL PATTERNS IN YOUR DATA OBJECTIVES Learn how to examine your data using the Geostatistical Analysis tools in ArcMap. Learn how to use descriptive statistics in ArcMap and Geoda to analyze
EXPLORING SPATIAL PATTERNS IN YOUR DATA OBJECTIVES Learn how to examine your data using the Geostatistical Analysis tools in ArcMap. Learn how to use descriptive statistics in ArcMap and Geoda to analyze
Tutorial for proteome data analysis using the Perseus software platform
 Tutorial for proteome data analysis using the Perseus software platform Laboratory of Mass Spectrometry, LNBio, CNPEM Tutorial version 1.0, January 2014. Note: This tutorial was written based on the information
Tutorial for proteome data analysis using the Perseus software platform Laboratory of Mass Spectrometry, LNBio, CNPEM Tutorial version 1.0, January 2014. Note: This tutorial was written based on the information
Seion. A Statistical Method for Alarm System Optimisation. White Paper. Dr. Tim Butters. Data Assimilation & Numerical Analysis Specialist
 Seion A Statistical Method for Alarm System Optimisation By Dr. Tim Butters Data Assimilation & Numerical Analysis Specialist tim.butters@sabisu.co www.sabisu.co Contents 1 Introduction 2 2 Challenge 2
Seion A Statistical Method for Alarm System Optimisation By Dr. Tim Butters Data Assimilation & Numerical Analysis Specialist tim.butters@sabisu.co www.sabisu.co Contents 1 Introduction 2 2 Challenge 2
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification
 Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati tnpatil2@gmail.com, ss_sherekar@rediffmail.com
Performance Analysis of Naive Bayes and J48 Classification Algorithm for Data Classification Tina R. Patil, Mrs. S. S. Sherekar Sant Gadgebaba Amravati University, Amravati tnpatil2@gmail.com, ss_sherekar@rediffmail.com
Categorical Data Visualization and Clustering Using Subjective Factors
 Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
Categorical Data Visualization and Clustering Using Subjective Factors Chia-Hui Chang and Zhi-Kai Ding Department of Computer Science and Information Engineering, National Central University, Chung-Li,
PayLess: A Low Cost Network Monitoring Framework for Software Defined Networks
 PayLess: A Low Cost Network Monitoring Framework for Software Defined Networks Shihabur R. Chowdhury, Md. Faizul Bari, Reaz Ahmed and Raouf Boutaba David R. Cheriton School of Computer Science, University
PayLess: A Low Cost Network Monitoring Framework for Software Defined Networks Shihabur R. Chowdhury, Md. Faizul Bari, Reaz Ahmed and Raouf Boutaba David R. Cheriton School of Computer Science, University
Business Process Modeling
 Business Process Concepts Process Mining Kelly Rosa Braghetto Instituto de Matemática e Estatística Universidade de São Paulo kellyrb@ime.usp.br January 30, 2009 1 / 41 Business Process Concepts Process
Business Process Concepts Process Mining Kelly Rosa Braghetto Instituto de Matemática e Estatística Universidade de São Paulo kellyrb@ime.usp.br January 30, 2009 1 / 41 Business Process Concepts Process
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach
 Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
Detecting Spam Bots in Online Social Networking Sites: A Machine Learning Approach Alex Hai Wang College of Information Sciences and Technology, The Pennsylvania State University, Dunmore, PA 18512, USA
Performance Metrics for Graph Mining Tasks
 Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Performance Metrics for Graph Mining Tasks 1 Outline Introduction to Performance Metrics Supervised Learning Performance Metrics Unsupervised Learning Performance Metrics Optimizing Metrics Statistical
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Statistical machine learning, high dimension and big data
 Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
Multi-Algorithm Ontology Mapping with Automatic Weight Assignment and Background Knowledge
 Multi-Algorithm Mapping with Automatic Weight Assignment and Background Knowledge Shailendra Singh and Yu-N Cheah School of Computer Sciences Universiti Sains Malaysia 11800 USM Penang, Malaysia shai14@gmail.com,
Multi-Algorithm Mapping with Automatic Weight Assignment and Background Knowledge Shailendra Singh and Yu-N Cheah School of Computer Sciences Universiti Sains Malaysia 11800 USM Penang, Malaysia shai14@gmail.com,
Data Mining Using Neural Network Approaches Using SAS and Java
 Data Mining Using Neural Network Approaches Using SAS and Java David Bell, State of California Genetic Disease Branch ABSTRACT This paper will explore the uses of two Neural Net approaches to pattern analyses
Data Mining Using Neural Network Approaches Using SAS and Java David Bell, State of California Genetic Disease Branch ABSTRACT This paper will explore the uses of two Neural Net approaches to pattern analyses
Standardization and Its Effects on K-Means Clustering Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING
 EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
Copyright Shraddha Pradip Sen 2011 ALL RIGHTS RESERVED
 LOG ANALYSIS TECHNIQUE: PICVIZ by SHRADDHA PRADIP SEN DR. YANG XIAO, COMMITTEE CHAIR DR. XIAOYAN HONG DR. SUSAN VRBSKY DR. SHUHUI LI A THESIS Submitted in partial fulfillment of the requirements for the
LOG ANALYSIS TECHNIQUE: PICVIZ by SHRADDHA PRADIP SEN DR. YANG XIAO, COMMITTEE CHAIR DR. XIAOYAN HONG DR. SUSAN VRBSKY DR. SHUHUI LI A THESIS Submitted in partial fulfillment of the requirements for the
TS3: an Improved Version of the Bilingual Concordancer TransSearch
 TS3: an Improved Version of the Bilingual Concordancer TransSearch Stéphane HUET, Julien BOURDAILLET and Philippe LANGLAIS EAMT 2009 - Barcelona June 14, 2009 Computer assisted translation Preferred by
TS3: an Improved Version of the Bilingual Concordancer TransSearch Stéphane HUET, Julien BOURDAILLET and Philippe LANGLAIS EAMT 2009 - Barcelona June 14, 2009 Computer assisted translation Preferred by
Hidden Markov Models in Bioinformatics. By Máthé Zoltán Kőrösi Zoltán 2006
 Hidden Markov Models in Bioinformatics By Máthé Zoltán Kőrösi Zoltán 2006 Outline Markov Chain HMM (Hidden Markov Model) Hidden Markov Models in Bioinformatics Gene Finding Gene Finding Model Viterbi algorithm
Hidden Markov Models in Bioinformatics By Máthé Zoltán Kőrösi Zoltán 2006 Outline Markov Chain HMM (Hidden Markov Model) Hidden Markov Models in Bioinformatics Gene Finding Gene Finding Model Viterbi algorithm
Second International Workshop on Preservation of Evolving Big Data - Panel on Big Data Quality
 Second International Workshop on Preservation of Evolving Big Data - Panel on Big Data Quality Angela Bonifati University of Lyon 1 Liris CNRS, France March 15, 2016 Angela Bonifati 2nd Diachron Workshop
Second International Workshop on Preservation of Evolving Big Data - Panel on Big Data Quality Angela Bonifati University of Lyon 1 Liris CNRS, France March 15, 2016 Angela Bonifati 2nd Diachron Workshop