Lustre & Cluster. - monitoring the whole thing Erich Focht
|
|
|
- Ashlynn Mitchell
- 8 years ago
- Views:
Transcription
1 Lustre & Cluster - monitoring the whole thing Erich Focht NEC HPC Europe LAD 2014, Reims, September 22-23,

2 Overview Introduction LXFS Lustre in a Data Center IBviz: Infiniband Fabric visualization Monitoring Lustre & other metrics Aggregators Percentiles Jobs 2

3 Introduction NEC Corporation HQ in Tokyo, Japan Established employees Business activities in over 140 countries NEC HPC Europe Part of NEC Deutschland Offices in Düsseldorf, Paris, Stuttgart. Scalar clusters Parallel FS and Storage Vector systems Solutions, Services, R&D 3

4 Parallel Filesystem Product: LXFS Built with Lustre Since 2007: parallel filesystem solution integrating validated HW (servers, networks, high performance storage), deployment, management, monitoring SW. Two flavours: LXFS standard Community edition Lustre LXFS Enterprise Intel(R) Enterprise Edition for Lustre* Software Level 3 support from Intel 4
")
5 Lustre Based LXFS Appliance Each LXFS block is a pre-installed appliance Entire storage cluster configuration is in one place: LxDaemon Describes the setup, hierarchy Contains all configurable parameters Single data source used for deployment, management, monitoring Deploying the storage cluster is very easy and reliable: Simple and reliable provisioning Auto-generate configuration of components from data in LxDaemon Storage devices setup, configuration Servers setup, configuration HA setup, services, dependencies, STONITH Formatting, Lustre mounting Managing & monitoring LXFS Simple CLI, hiding complexity of underlying setup Health monitoring: pro-active, sends messages to admins, reacts to issues Performance monitoring: time-history, GUI, discover issues and bottlenecks 5

6 Eg.: Performance Optimized OSS Block Specs > 6GB/s write, > 7.5GB/s read, up to 384TB in 8U (storage) 2 Servers: highly available, active-active 2 x 6core E5-2620(-v2) 2 x LSI9207 HBA, 1 x Mellanox ConnectX 3 FDR HCA Storage NEC SNA460 + SNA060 (built on NetApp E5500)... Ost1-6 OSS1 Ost7-12 OSS2 RAID EBOD Performance example 80 NL-SAS 7.2k IOR In noisy environment 6
.")
7 Concrete Setup: Automotive Company Datacenter Top level switch 2 x 2 x 12 x 12x4GB/s x FDR 8x6GB/s > 20GB/s aggregated bandwidth... High-bandwidth island FDR High-bandwidth island Some nodes 7

8 Demonstrate 20GB/s on 8 or 16 Nodes! Check all layers! OSS to Block Devices vdbench, sgpdd-survey, with Lustre: obdfilter-survey Read/write to controller cache! Check PCIe, HBAs (SAS) LNET Lnet-selftest Peer credits? Enough transactions in flight? Lustre client Benchmark 2 hosts, 8 volume groups, 64 threads / blk device MB/s write read time [10s] IOR, stonewalling... but... 8

9 The Infiniband Fabric: Routes! Top level switch Paths used by 2 nodes 2 x 2 x 12 x Max 8 paths 12x4GB/s used for write x6GB/s > 20GB/s aggregated bandwidth... High-bandwidth island 2 x FDR FDR Read and write paths differ! High-bandwidth island Some nodes 9

10 Demonstrate 20GB/s on 8 or 16 Nodes! Given the routing is static: select nodes carefully Out of a pool of reserved nodes Minimize oversubscription of InfiniBand links on both paths... to OSTs/OSSes that are involved... and back to client nodes Use stonewalling Result from 16 clients Write: max 24.7GB/s Read: max 26.6GB/s MB/s Threads

11 Trivial Remarks Performance of storage devices is huge Performance of one OSS is O(IB link bandwidth) If overcommitting inter-switch-links we hit quickly the limit Sane way of integrating is more expensive and more complex: Lustre/Lnet routers Additional hardware Each responsible for its island Can also limit I/O bandwidth in an island 11

12 Integrated In Datacenter: The Right Way Top level switch 2 x 2 x Lnet Router... Lnet Router Lnet Router... At least 30+ additional servers IB cables Free IB switch ports Separate config for each island's router in order to keep scope local Lnet Router FDR 2 x FDR 8x6GB/s... High-bandwidth island High-bandwidth island Some nodes > 20GB/s aggregated bandwidth 12

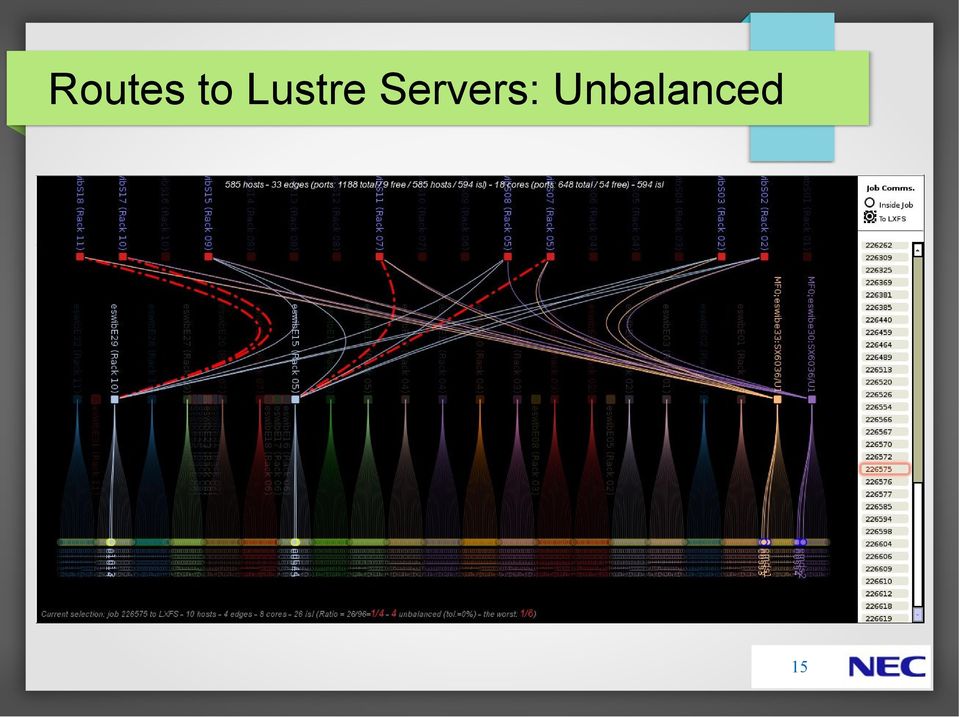
13 IBviz Development inspired by benchmarking experience described before Visualize the detected IB fabric, focus on inter-switch links (ISLs) Mistakes in network are visible (eg. missing links) Compute number of static routes (read/write) going over ISLs Which links are actually used in an MPI job? How much bandwidth is really available? Which Links are used for IO and what bandwidth is available) 13

14 Routes Between Compute Nodes: Balanced 14

15 Routes to Lustre Servers: Unbalanced 15
16 Monitoring Cluster & Lustre Together Lustre Servers... ok Ganglia standard metrics own metric generators delivering metrics into Ganglia, Nagios Cluster Compute Nodes... ok See above... Ganglia, Nagios, own metrics IB ports... ok Own metrics, in Ganglia, attached to hosts Need more and better IB routes and inter-switch-link stats... Routes: ok, ISL stats: doable Don't fit well into hierarchy... Ganglia won't work any more 16

17 Monitoring Cluster & Lustre Together Lustre Clients... Plenty of statistics on clients and servers often: no access to clients: use metrics on servers Scaling problem! At least 4 metrics per OST and client 1, O(10), more metrics per MDT and client 1000 clients, 50 OSTs: 200k additional metrics in monitoring system Jobs Ultimately, we want to know which jobs are performing poorly on Lustre, why, advise users, tune their code, the filesystem, use ost pools... Either map client nodes to jobs (easy, no change on cluster needed) Or use (newer) tagging mechanism provided by Lustre Store metrics per job!? Rather unusual in normal monitoring systems 17

18 Monitoring Cluster & Lustre Together Aggregation! Reduce number of metrics stored Do we care about each OST read/write bandwidth for each client node? Rather look at total bandwidths and transaction sizes of node Example: 50 OSTs * 4 metrics -> 4 metrics 200k metrics -> 4k metrics to store But still processing 200k metrics What about jobs? In order to see whether anything goes wrong, do we need info on each compute node? The work described on the following pages has been funded by the German Ministry of Education and Research (BMBF) within the FEPA project. 18

19 Aggregate Job Metrics: in FEPA Project Percentiles Instead of looking at the metric of each node in a job, look at all at once Example data: Sort your data: Get the percentiles: Value Number of observations Value intervals (bins) 10th 20th 50th Percentiles 90th 100th 19
 10th 20th 50th Percentiles 90th")
20 Architecture: Data Collection / Aggregation gmetad RRDs Lustre server metrics Per OST Lustre client metrics gmond MDS trigger OSS OSS 1... Agg client metrics 4 orchestrator gmond trigger OSS gmetad Cluster metrics 5 6 trigger 6 Cluster gmetad Agg job metrics 6 RRDs Resource manager Aggregated client Lustre metrics RRDs gmond Aggregated job percentile metrics 20

21 Architecture: Visualization gmetad Lustre server metrics RRDs LxGUI MDS OSS LxDaemon OSS... Aggregated client Lustre metrics Aggregated job percentile metrics OSS gmetad Cluster metrics LxDaemon integrates ganglia Grid and Cluster hierarchies into a single one, allowing simultaneous access to multiple gmetad data sources through an XPATH alike query language. gmetad RRDs Cluster Resource manager RRDs 21
22 Metrics Hierarchies 22
23 Cluster Metrics: DP MFLOPS Percentiles 23
24 MFLOPS avg vs. Lustre Write Percentiles 24
25 Job: Lustre Read KB/s Percentiles 25
26 Totalpower Percentiles in a Job 26
27 Metrics from different Ganglia Hierarchies 27
28 Conclusion Computer systems are complex: Infiniband network: even static metrics help understand system performance There are plenty of metrics to measure and watch Storing all of them is currently not an option Per Job metrics are most useful for users. Aggregation But monitoring systems not really prepared for jobs data Ganglia turned out to be quite flexible and helpful, but gmetad and RRD have their issues... 28
Commoditisation of the High-End Research Storage Market with the Dell MD3460 & Intel Enterprise Edition Lustre
 Commoditisation of the High-End Research Storage Market with the Dell MD3460 & Intel Enterprise Edition Lustre University of Cambridge, UIS, HPC Service Authors: Wojciech Turek, Paul Calleja, John Taylor
Commoditisation of the High-End Research Storage Market with the Dell MD3460 & Intel Enterprise Edition Lustre University of Cambridge, UIS, HPC Service Authors: Wojciech Turek, Paul Calleja, John Taylor
Lustre Monitoring with OpenTSDB
 Lustre Monitoring with OpenTSDB 2015/9/22 DataDirect Networks Japan, Inc. Shuichi Ihara 2 Lustre Monitoring Background Lustre is a black box Users and Administrators want to know what s going on? Find
Lustre Monitoring with OpenTSDB 2015/9/22 DataDirect Networks Japan, Inc. Shuichi Ihara 2 Lustre Monitoring Background Lustre is a black box Users and Administrators want to know what s going on? Find
Architecting a High Performance Storage System
 WHITE PAPER Intel Enterprise Edition for Lustre* Software High Performance Data Division Architecting a High Performance Storage System January 2014 Contents Introduction... 1 A Systematic Approach to
WHITE PAPER Intel Enterprise Edition for Lustre* Software High Performance Data Division Architecting a High Performance Storage System January 2014 Contents Introduction... 1 A Systematic Approach to
Current Status of FEFS for the K computer
 Current Status of FEFS for the K computer Shinji Sumimoto Fujitsu Limited Apr.24 2012 LUG2012@Austin Outline RIKEN and Fujitsu are jointly developing the K computer * Development continues with system
Current Status of FEFS for the K computer Shinji Sumimoto Fujitsu Limited Apr.24 2012 LUG2012@Austin Outline RIKEN and Fujitsu are jointly developing the K computer * Development continues with system
Building a Top500-class Supercomputing Cluster at LNS-BUAP
 Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Building a Top500-class Supercomputing Cluster at LNS-BUAP Dr. José Luis Ricardo Chávez Dr. Humberto Salazar Ibargüen Dr. Enrique Varela Carlos Laboratorio Nacional de Supercómputo Benemérita Universidad
Application Performance for High Performance Computing Environments
 Application Performance for High Performance Computing Environments Leveraging the strengths of Computationally intensive applications With high performance scale out file serving In data storage modules
Application Performance for High Performance Computing Environments Leveraging the strengths of Computationally intensive applications With high performance scale out file serving In data storage modules
High-Availability and Scalable Cluster-in-a-Box HPC Storage Solution
 Intel Solutions Reference Architecture High-Availability and Scalable Cluster-in-a-Box HPC Storage Solution Using RAIDIX Storage Software Integrated with Intel Enterprise Edition for Lustre* Audience and
Intel Solutions Reference Architecture High-Availability and Scalable Cluster-in-a-Box HPC Storage Solution Using RAIDIX Storage Software Integrated with Intel Enterprise Edition for Lustre* Audience and
New Storage System Solutions
 New Storage System Solutions Craig Prescott Research Computing May 2, 2013 Outline } Existing storage systems } Requirements and Solutions } Lustre } /scratch/lfs } Questions? Existing Storage Systems
New Storage System Solutions Craig Prescott Research Computing May 2, 2013 Outline } Existing storage systems } Requirements and Solutions } Lustre } /scratch/lfs } Questions? Existing Storage Systems
An Alternative Storage Solution for MapReduce. Eric Lomascolo Director, Solutions Marketing
 An Alternative Storage Solution for MapReduce Eric Lomascolo Director, Solutions Marketing MapReduce Breaks the Problem Down Data Analysis Distributes processing work (Map) across compute nodes and accumulates
An Alternative Storage Solution for MapReduce Eric Lomascolo Director, Solutions Marketing MapReduce Breaks the Problem Down Data Analysis Distributes processing work (Map) across compute nodes and accumulates
Post-production Video Editing Solution Guide with Microsoft SMB 3 File Serving AssuredSAN 4000
 Post-production Video Editing Solution Guide with Microsoft SMB 3 File Serving AssuredSAN 4000 Dot Hill Systems introduction 1 INTRODUCTION Dot Hill Systems offers high performance network storage products
Post-production Video Editing Solution Guide with Microsoft SMB 3 File Serving AssuredSAN 4000 Dot Hill Systems introduction 1 INTRODUCTION Dot Hill Systems offers high performance network storage products
Lustre failover experience
 Lustre failover experience Lustre Administrators and Developers Workshop Paris 1 September 25, 2012 TOC Who we are Our Lustre experience: the environment Deployment Benchmarks What's next 2 Who we are
Lustre failover experience Lustre Administrators and Developers Workshop Paris 1 September 25, 2012 TOC Who we are Our Lustre experience: the environment Deployment Benchmarks What's next 2 Who we are
HPC @ CRIBI. Calcolo Scientifico e Bioinformatica oggi Università di Padova 13 gennaio 2012
 HPC @ CRIBI Calcolo Scientifico e Bioinformatica oggi Università di Padova 13 gennaio 2012 what is exact? experience on advanced computational technologies a company lead by IT experts with a strong background
HPC @ CRIBI Calcolo Scientifico e Bioinformatica oggi Università di Padova 13 gennaio 2012 what is exact? experience on advanced computational technologies a company lead by IT experts with a strong background
PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 11 th, 2014 NEC Corporation
 September 11 th, 2014 NEC Corporation") PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 11 th, 2014 NEC Corporation 1. Overview of NEC PCIe SSD Appliance for Microsoft SQL Server Page 2 NEC Corporation
PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 11 th, 2014 NEC Corporation 1. Overview of NEC PCIe SSD Appliance for Microsoft SQL Server Page 2 NEC Corporation
Sun Constellation System: The Open Petascale Computing Architecture
 CAS2K7 13 September, 2007 Sun Constellation System: The Open Petascale Computing Architecture John Fragalla Senior HPC Technical Specialist Global Systems Practice Sun Microsystems, Inc. 25 Years of Technical
CAS2K7 13 September, 2007 Sun Constellation System: The Open Petascale Computing Architecture John Fragalla Senior HPC Technical Specialist Global Systems Practice Sun Microsystems, Inc. 25 Years of Technical
Highly-Available Distributed Storage. UF HPC Center Research Computing University of Florida
 Highly-Available Distributed Storage UF HPC Center Research Computing University of Florida Storage is Boring Slow, troublesome, albatross around the neck of high-performance computing UF Research Computing
Highly-Available Distributed Storage UF HPC Center Research Computing University of Florida Storage is Boring Slow, troublesome, albatross around the neck of high-performance computing UF Research Computing
New and Improved Lustre Performance Monitoring Tool. Torben Kling Petersen, PhD Principal Engineer. Chris Bloxham Principal Architect
 New and Improved Lustre Performance Monitoring Tool Torben Kling Petersen, PhD Principal Engineer Chris Bloxham Principal Architect Lustre monitoring Performance Granular Aggregated Components Subsystem
New and Improved Lustre Performance Monitoring Tool Torben Kling Petersen, PhD Principal Engineer Chris Bloxham Principal Architect Lustre monitoring Performance Granular Aggregated Components Subsystem
NetApp High-Performance Computing Solution for Lustre: Solution Guide
 Technical Report NetApp High-Performance Computing Solution for Lustre: Solution Guide Robert Lai, NetApp August 2012 TR-3997 TABLE OF CONTENTS 1 Introduction... 5 1.1 NetApp HPC Solution for Lustre Introduction...5
Technical Report NetApp High-Performance Computing Solution for Lustre: Solution Guide Robert Lai, NetApp August 2012 TR-3997 TABLE OF CONTENTS 1 Introduction... 5 1.1 NetApp HPC Solution for Lustre Introduction...5
Lustre * Filesystem for Cloud and Hadoop *
 OpenFabrics Software User Group Workshop Lustre * Filesystem for Cloud and Hadoop * Robert Read, Intel Lustre * for Cloud and Hadoop * Brief Lustre History and Overview Using Lustre with Hadoop Intel Cloud
OpenFabrics Software User Group Workshop Lustre * Filesystem for Cloud and Hadoop * Robert Read, Intel Lustre * for Cloud and Hadoop * Brief Lustre History and Overview Using Lustre with Hadoop Intel Cloud
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
Comparing SMB Direct 3.0 performance over RoCE, InfiniBand and Ethernet. September 2014
 Comparing SMB Direct 3.0 performance over RoCE, InfiniBand and Ethernet Anand Rangaswamy September 2014 Storage Developer Conference Mellanox Overview Ticker: MLNX Leading provider of high-throughput,
Comparing SMB Direct 3.0 performance over RoCE, InfiniBand and Ethernet Anand Rangaswamy September 2014 Storage Developer Conference Mellanox Overview Ticker: MLNX Leading provider of high-throughput,
Kriterien für ein PetaFlop System
 Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
FLOW-3D Performance Benchmark and Profiling. September 2012
 FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
How To Monitor Infiniband Network Data From A Network On A Leaf Switch (Wired) On A Microsoft Powerbook (Wired Or Microsoft) On An Ipa (Wired/Wired) Or Ipa V2 (Wired V2)
 On A Microsoft Powerbook (Wired Or Microsoft) On An Ipa (Wired/Wired) Or Ipa V2 (Wired V2)") INFINIBAND NETWORK ANALYSIS AND MONITORING USING OPENSM N. Dandapanthula 1, H. Subramoni 1, J. Vienne 1, K. Kandalla 1, S. Sur 1, D. K. Panda 1, and R. Brightwell 2 Presented By Xavier Besseron 1 Date:
INFINIBAND NETWORK ANALYSIS AND MONITORING USING OPENSM N. Dandapanthula 1, H. Subramoni 1, J. Vienne 1, K. Kandalla 1, S. Sur 1, D. K. Panda 1, and R. Brightwell 2 Presented By Xavier Besseron 1 Date:
Configuration Maximums
 Topic Configuration s VMware vsphere 5.1 When you select and configure your virtual and physical equipment, you must stay at or below the maximums supported by vsphere 5.1. The limits presented in the
Topic Configuration s VMware vsphere 5.1 When you select and configure your virtual and physical equipment, you must stay at or below the maximums supported by vsphere 5.1. The limits presented in the
SMB Direct for SQL Server and Private Cloud
 SMB Direct for SQL Server and Private Cloud Increased Performance, Higher Scalability and Extreme Resiliency June, 2014 Mellanox Overview Ticker: MLNX Leading provider of high-throughput, low-latency server
SMB Direct for SQL Server and Private Cloud Increased Performance, Higher Scalability and Extreme Resiliency June, 2014 Mellanox Overview Ticker: MLNX Leading provider of high-throughput, low-latency server
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
Hadoop on the Gordon Data Intensive Cluster
 Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
HPC Update: Engagement Model
 HPC Update: Engagement Model MIKE VILDIBILL Director, Strategic Engagements Sun Microsystems mikev@sun.com Our Strategy Building a Comprehensive HPC Portfolio that Delivers Differentiated Customer Value
HPC Update: Engagement Model MIKE VILDIBILL Director, Strategic Engagements Sun Microsystems mikev@sun.com Our Strategy Building a Comprehensive HPC Portfolio that Delivers Differentiated Customer Value
Performance Comparison of Intel Enterprise Edition for Lustre* software and HDFS for MapReduce Applications
 Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
Performance Comparison of Intel Enterprise Edition for Lustre software and HDFS for MapReduce Applications Rekha Singhal, Gabriele Pacciucci and Mukesh Gangadhar 2 Hadoop Introduc-on Open source MapReduce
GPFS Storage Server. Concepts and Setup in Lemanicus BG/Q system" Christian Clémençon (EPFL-DIT)" " 4 April 2013"
 4 April 2013") GPFS Storage Server Concepts and Setup in Lemanicus BG/Q system" Christian Clémençon (EPFL-DIT)" " Agenda" GPFS Overview" Classical versus GSS I/O Solution" GPFS Storage Server (GSS)" GPFS Native RAID
GPFS Storage Server Concepts and Setup in Lemanicus BG/Q system" Christian Clémençon (EPFL-DIT)" " Agenda" GPFS Overview" Classical versus GSS I/O Solution" GPFS Storage Server (GSS)" GPFS Native RAID
Jason Hill HPC Operations Group ORNL Cray User s Group 2011, Fairbanks, AK 05-25-2011
 Determining health of Lustre filesystems at scale Jason Hill HPC Operations Group ORNL Cray User s Group 2011, Fairbanks, AK 05-25-2011 Overview Overview of architectures Lustre health and importance Storage
Determining health of Lustre filesystems at scale Jason Hill HPC Operations Group ORNL Cray User s Group 2011, Fairbanks, AK 05-25-2011 Overview Overview of architectures Lustre health and importance Storage
Sun Storage Perspective & Lustre Architecture. Dr. Peter Braam VP Sun Microsystems
 Sun Storage Perspective & Lustre Architecture Dr. Peter Braam VP Sun Microsystems Agenda Future of Storage Sun s vision Lustre - vendor neutral architecture roadmap Sun s view on storage introduction The
Sun Storage Perspective & Lustre Architecture Dr. Peter Braam VP Sun Microsystems Agenda Future of Storage Sun s vision Lustre - vendor neutral architecture roadmap Sun s view on storage introduction The
BRIDGING EMC ISILON NAS ON IP TO INFINIBAND NETWORKS WITH MELLANOX SWITCHX
 White Paper BRIDGING EMC ISILON NAS ON IP TO INFINIBAND NETWORKS WITH Abstract This white paper explains how to configure a Mellanox SwitchX Series switch to bridge the external network of an EMC Isilon
White Paper BRIDGING EMC ISILON NAS ON IP TO INFINIBAND NETWORKS WITH Abstract This white paper explains how to configure a Mellanox SwitchX Series switch to bridge the external network of an EMC Isilon
High Availability in Lustre. John Fragalla Principal Solutions Architect High Performance Computing
 High Availability in Lustre John Fragalla Principal Solutions Architect High Performance Computing Goal for Lustre HA Detect failures and provide architecture to deal with any level of Failure Provide
High Availability in Lustre John Fragalla Principal Solutions Architect High Performance Computing Goal for Lustre HA Detect failures and provide architecture to deal with any level of Failure Provide
Developing High-Performance, Scalable, cost effective storage solutions with Intel Cloud Edition Lustre* and Amazon Web Services
 Reference Architecture Developing Storage Solutions with Intel Cloud Edition for Lustre* and Amazon Web Services Developing High-Performance, Scalable, cost effective storage solutions with Intel Cloud
Reference Architecture Developing Storage Solutions with Intel Cloud Edition for Lustre* and Amazon Web Services Developing High-Performance, Scalable, cost effective storage solutions with Intel Cloud
Network Contention and Congestion Control: Lustre FineGrained Routing
 Network Contention and Congestion Control: Lustre FineGrained Routing Matt Ezell HPC Systems Administrator Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory International Workshop on
Network Contention and Congestion Control: Lustre FineGrained Routing Matt Ezell HPC Systems Administrator Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory International Workshop on
Lessons learned from parallel file system operation
 Lessons learned from parallel file system operation Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association
Lessons learned from parallel file system operation Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State of Baden-Württemberg and National Laboratory of the Helmholtz Association
Scala Storage Scale-Out Clustered Storage White Paper
 White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
White Paper Scala Storage Scale-Out Clustered Storage White Paper Chapter 1 Introduction... 3 Capacity - Explosive Growth of Unstructured Data... 3 Performance - Cluster Computing... 3 Chapter 2 Current
Lustre SMB Gateway. Integrating Lustre with Windows
 Lustre SMB Gateway Integrating Lustre with Windows Hardware: Old vs New Compute 60 x Dell PowerEdge 1950-8 x 2.6Ghz cores, 16GB, 500GB Sata, 1GBe - Win7 x64 Storage 1 x Dell R510-12 x 2TB Sata, RAID5,
Lustre SMB Gateway Integrating Lustre with Windows Hardware: Old vs New Compute 60 x Dell PowerEdge 1950-8 x 2.6Ghz cores, 16GB, 500GB Sata, 1GBe - Win7 x64 Storage 1 x Dell R510-12 x 2TB Sata, RAID5,
Picking the right number of targets per server for BeeGFS. Jan Heichler March 2015 v1.2
 Picking the right number of targets per server for BeeGFS Jan Heichler March 2015 v1.2 Evaluating the MetaData Performance of BeeGFS 2 Abstract In this paper we will show the performance of two different
Picking the right number of targets per server for BeeGFS Jan Heichler March 2015 v1.2 Evaluating the MetaData Performance of BeeGFS 2 Abstract In this paper we will show the performance of two different
High Performance Computing OpenStack Options. September 22, 2015
 High Performance Computing OpenStack PRESENTATION TITLE GOES HERE Options September 22, 2015 Today s Presenters Glyn Bowden, SNIA Cloud Storage Initiative Board HP Helion Professional Services Alex McDonald,
High Performance Computing OpenStack PRESENTATION TITLE GOES HERE Options September 22, 2015 Today s Presenters Glyn Bowden, SNIA Cloud Storage Initiative Board HP Helion Professional Services Alex McDonald,
Preparation Guide. How to prepare your environment for an OnApp Cloud v3.0 (beta) deployment.
 deployment.") Preparation Guide v3.0 BETA How to prepare your environment for an OnApp Cloud v3.0 (beta) deployment. Document version 1.0 Document release date 25 th September 2012 document revisions 1 Contents 1. Overview...
Preparation Guide v3.0 BETA How to prepare your environment for an OnApp Cloud v3.0 (beta) deployment. Document version 1.0 Document release date 25 th September 2012 document revisions 1 Contents 1. Overview...
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems
 Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Performance Comparison of SQL based Big Data Analytics with Lustre and HDFS file systems Rekha Singhal and Gabriele Pacciucci * Other names and brands may be claimed as the property of others. Lustre File
Building a cost-effective and high-performing public cloud. Sander Cruiming, founder Cloud Provider
 Building a cost-effective and high-performing public cloud Sander Cruiming, founder Cloud Provider 1 Agenda Introduction of Cloud Provider Overview of our previous cloud architecture Challenges of that
Building a cost-effective and high-performing public cloud Sander Cruiming, founder Cloud Provider 1 Agenda Introduction of Cloud Provider Overview of our previous cloud architecture Challenges of that
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012
 Author: Motti Beck, Mellanox Technologies Date: March 27, 2012") Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
Unstructured Data Accelerator (UDA) Author: Motti Beck, Mellanox Technologies Date: March 27, 2012 1 Market Trends Big Data Growing technology deployments are creating an exponential increase in the volume
PRIMERGY server-based High Performance Computing solutions
 PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
Cluster Implementation and Management; Scheduling
 Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Cluster Implementation and Management; Scheduling CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Cluster Implementation and Management; Scheduling Spring 2013 1 /
Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks
 WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
WHITE PAPER July 2014 Achieving Real-Time Business Solutions Using Graph Database Technology and High Performance Networks Contents Executive Summary...2 Background...3 InfiniteGraph...3 High Performance
HPC Growing Pains. Lessons learned from building a Top500 supercomputer
 HPC Growing Pains Lessons learned from building a Top500 supercomputer John L. Wofford Center for Computational Biology & Bioinformatics Columbia University I. What is C2B2? Outline Lessons learned from
HPC Growing Pains Lessons learned from building a Top500 supercomputer John L. Wofford Center for Computational Biology & Bioinformatics Columbia University I. What is C2B2? Outline Lessons learned from
Configuration Maximums
 Configuration s vsphere 6.0 This document supports the version of each product listed and supports all subsequent versions until the document is replaced by a new edition. To check for more recent editions
Configuration s vsphere 6.0 This document supports the version of each product listed and supports all subsequent versions until the document is replaced by a new edition. To check for more recent editions
Michael Kagan. michael@mellanox.com
 Virtualization in Data Center The Network Perspective Michael Kagan CTO, Mellanox Technologies michael@mellanox.com Outline Data Center Transition Servers S as a Service Network as a Service IO as a Service
Virtualization in Data Center The Network Perspective Michael Kagan CTO, Mellanox Technologies michael@mellanox.com Outline Data Center Transition Servers S as a Service Network as a Service IO as a Service
Florida Site Report. US CMS Tier-2 Facilities Workshop. April 7, 2014. Bockjoo Kim University of Florida
 Florida Site Report US CMS Tier-2 Facilities Workshop April 7, 2014 Bockjoo Kim University of Florida Outline Site Overview Computing Resources Site Status Future Plans Summary 2 Florida Tier-2 Paul Avery
Florida Site Report US CMS Tier-2 Facilities Workshop April 7, 2014 Bockjoo Kim University of Florida Outline Site Overview Computing Resources Site Status Future Plans Summary 2 Florida Tier-2 Paul Avery
Monitoring Tools for Large Scale Systems
 Monitoring Tools for Large Scale Systems Ross Miller, Jason Hill, David A. Dillow, Raghul Gunasekaran, Galen Shipman, Don Maxwell Oak Ridge Leadership Computing Facility, Oak Ridge National Laboratory
Monitoring Tools for Large Scale Systems Ross Miller, Jason Hill, David A. Dillow, Raghul Gunasekaran, Galen Shipman, Don Maxwell Oak Ridge Leadership Computing Facility, Oak Ridge National Laboratory
LSI SAS inside 60% of servers. 21 million LSI SAS & MegaRAID solutions shipped over last 3 years. 9 out of 10 top server vendors use MegaRAID
 The vast majority of the world s servers count on LSI SAS & MegaRAID Trust us, build the LSI credibility in storage, SAS, RAID Server installed base = 36M LSI SAS inside 60% of servers 21 million LSI SAS
The vast majority of the world s servers count on LSI SAS & MegaRAID Trust us, build the LSI credibility in storage, SAS, RAID Server installed base = 36M LSI SAS inside 60% of servers 21 million LSI SAS
The Future of Computing Cisco Unified Computing System. Markus Kunstmann Channels Systems Engineer
 The Future of Computing Cisco Unified Computing System Markus Kunstmann Channels Systems Engineer 2009 Cisco Systems, Inc. All rights reserved. Data Centers Are under Increasing Pressure Collaboration
The Future of Computing Cisco Unified Computing System Markus Kunstmann Channels Systems Engineer 2009 Cisco Systems, Inc. All rights reserved. Data Centers Are under Increasing Pressure Collaboration
LLNL Production Plans and Best Practices
 LLNL Production Plans and Best Practices Lustre User Group, 2014. Miami, FL April 8, 2014 LLNL-PRES-652453 This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore
LLNL Production Plans and Best Practices Lustre User Group, 2014. Miami, FL April 8, 2014 LLNL-PRES-652453 This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore
Configuring LNet Routers for File Systems based on Intel Enterprise Edition for Lustre* Software
 Configuring LNet Routers for File Systems based on Intel Enterprise Edition for Lustre* Software Partner Guide High Performance Data Division Software Version: 2.4.0.0 World Wide Web: http://www.intel.com
Configuring LNet Routers for File Systems based on Intel Enterprise Edition for Lustre* Software Partner Guide High Performance Data Division Software Version: 2.4.0.0 World Wide Web: http://www.intel.com
Intel Cluster Ready Appro Xtreme-X Computers with Mellanox QDR Infiniband
 Intel Cluster Ready Appro Xtreme-X Computers with Mellanox QDR Infiniband A P P R O I N T E R N A T I O N A L I N C Steve Lyness Vice President, HPC Solutions Engineering slyness@appro.com Company Overview
Intel Cluster Ready Appro Xtreme-X Computers with Mellanox QDR Infiniband A P P R O I N T E R N A T I O N A L I N C Steve Lyness Vice President, HPC Solutions Engineering slyness@appro.com Company Overview
Lustre Networking BY PETER J. BRAAM
 Lustre Networking BY PETER J. BRAAM A WHITE PAPER FROM CLUSTER FILE SYSTEMS, INC. APRIL 2007 Audience Architects of HPC clusters Abstract This paper provides architects of HPC clusters with information
Lustre Networking BY PETER J. BRAAM A WHITE PAPER FROM CLUSTER FILE SYSTEMS, INC. APRIL 2007 Audience Architects of HPC clusters Abstract This paper provides architects of HPC clusters with information
Cray Lustre File System Monitoring
 Cray Lustre File System Monitoring esfsmon Jeff Keopp OSIO/ES Systems Cray Inc. St. Paul, MN USA keopp@cray.com Harold Longley OSIO Cray Inc. St. Paul, MN USA htg@cray.com Abstract The Cray Data Management
Cray Lustre File System Monitoring esfsmon Jeff Keopp OSIO/ES Systems Cray Inc. St. Paul, MN USA keopp@cray.com Harold Longley OSIO Cray Inc. St. Paul, MN USA htg@cray.com Abstract The Cray Data Management
JUROPA Linux Cluster An Overview. 19 May 2014 Ulrich Detert
 Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
Mitglied der Helmholtz-Gemeinschaft JUROPA Linux Cluster An Overview 19 May 2014 Ulrich Detert JuRoPA JuRoPA Jülich Research on Petaflop Architectures Bull, Sun, ParTec, Intel, Mellanox, Novell, FZJ JUROPA
LMT Lustre Monitoring Tools
 LMT Lustre Monitoring Tools April 13, 2011 Christopher Morrone, P. O. Box 808, Livermore, CA 94551 This work performed under the auspices of the U.S. Department of Energy by under Contract DE-AC52-07NA27344
LMT Lustre Monitoring Tools April 13, 2011 Christopher Morrone, P. O. Box 808, Livermore, CA 94551 This work performed under the auspices of the U.S. Department of Energy by under Contract DE-AC52-07NA27344
Scientific Computing Data Management Visions
 Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
SPC BENCHMARK 2/ENERGY EXECUTIVE SUMMARY ORACLE CORPORATION ORACLE ZFS STORAGE ZS3-2 APPLIANCE (2-NODE CLUSTER) SPC-2/E V1.5
 SPC-2/E V1.5") SPC BENCHMARK 2/ENERGY EXECUTIVE SUMMARY ORACLE CORPORATION ORACLE ZFS STORAGE ZS3-2 APPLIANCE (2-NODE CLUSTER) SPC-2/E V1.5 Submitted for Review: June 25, 2014 EXECUTIVE SUMMARY Page 2 of 12 EXECUTIVE
SPC BENCHMARK 2/ENERGY EXECUTIVE SUMMARY ORACLE CORPORATION ORACLE ZFS STORAGE ZS3-2 APPLIANCE (2-NODE CLUSTER) SPC-2/E V1.5 Submitted for Review: June 25, 2014 EXECUTIVE SUMMARY Page 2 of 12 EXECUTIVE
Determining the health of Lustre filesystems at scale
 Determining the health of Lustre filesystems at scale Jason J. Hill, Dustin B. Leverman, Scott M. Koch, David A. Dillow Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory {hilljj,leverman,smkoch,dillowda}@ornl.gov
Determining the health of Lustre filesystems at scale Jason J. Hill, Dustin B. Leverman, Scott M. Koch, David A. Dillow Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory {hilljj,leverman,smkoch,dillowda}@ornl.gov
Bright Idea: GE s Storage Performance Best Practices Brian W. Walker
 Bright Idea: GE s Storage Performance Best Practices Brian W. Walker Principal Architect, Cloud Solutions 1 Speaker Introduction Brian Walker Principal Architect, Cloud Solutions Brian brings more than
Bright Idea: GE s Storage Performance Best Practices Brian W. Walker Principal Architect, Cloud Solutions 1 Speaker Introduction Brian Walker Principal Architect, Cloud Solutions Brian brings more than
ECLIPSE Best Practices Performance, Productivity, Efficiency. March 2009
 ECLIPSE Best Practices Performance, Productivity, Efficiency March 29 ECLIPSE Performance, Productivity, Efficiency The following research was performed under the HPC Advisory Council activities HPC Advisory
ECLIPSE Best Practices Performance, Productivity, Efficiency March 29 ECLIPSE Performance, Productivity, Efficiency The following research was performed under the HPC Advisory Council activities HPC Advisory
A Holistic Model of the Energy-Efficiency of Hypervisors
 A Holistic Model of the -Efficiency of Hypervisors in an HPC Environment Mateusz Guzek,Sebastien Varrette, Valentin Plugaru, Johnatan E. Pecero and Pascal Bouvry SnT & CSC, University of Luxembourg, Luxembourg
A Holistic Model of the -Efficiency of Hypervisors in an HPC Environment Mateusz Guzek,Sebastien Varrette, Valentin Plugaru, Johnatan E. Pecero and Pascal Bouvry SnT & CSC, University of Luxembourg, Luxembourg
Preview of a Novel Architecture for Large Scale Storage
 Preview of a Novel Architecture for Large Scale Storage Andreas Petzold, Christoph-Erdmann Pfeiler, Jos van Wezel Steinbuch Centre for Computing STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the
Preview of a Novel Architecture for Large Scale Storage Andreas Petzold, Christoph-Erdmann Pfeiler, Jos van Wezel Steinbuch Centre for Computing STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the
The Use of Flash in Large-Scale Storage Systems. Nathan.Rutman@Seagate.com
 The Use of Flash in Large-Scale Storage Systems Nathan.Rutman@Seagate.com 1 Seagate s Flash! Seagate acquired LSI s Flash Components division May 2014 Selling multiple formats / capacities today Nytro
The Use of Flash in Large-Scale Storage Systems Nathan.Rutman@Seagate.com 1 Seagate s Flash! Seagate acquired LSI s Flash Components division May 2014 Selling multiple formats / capacities today Nytro
Deploying Hadoop on Lustre Sto rage:
 Deploying Hadoop on Lustre Sto rage: Lessons learned and best practices. J. Mario Gallegos- Dell, Zhiqi Tao- Intel and Quy Ta- Dell Apr 15 2015 Integration of HPC workloads and Big Data w orkloads on Tulane
Deploying Hadoop on Lustre Sto rage: Lessons learned and best practices. J. Mario Gallegos- Dell, Zhiqi Tao- Intel and Quy Ta- Dell Apr 15 2015 Integration of HPC workloads and Big Data w orkloads on Tulane
Introduction to Infiniband. Hussein N. Harake, Performance U! Winter School
 Introduction to Infiniband Hussein N. Harake, Performance U! Winter School Agenda Definition of Infiniband Features Hardware Facts Layers OFED Stack OpenSM Tools and Utilities Topologies Infiniband Roadmap
Introduction to Infiniband Hussein N. Harake, Performance U! Winter School Agenda Definition of Infiniband Features Hardware Facts Layers OFED Stack OpenSM Tools and Utilities Topologies Infiniband Roadmap
Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA
 WHITE PAPER April 2014 Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA Executive Summary...1 Background...2 File Systems Architecture...2 Network Architecture...3 IBM BigInsights...5
WHITE PAPER April 2014 Driving IBM BigInsights Performance Over GPFS Using InfiniBand+RDMA Executive Summary...1 Background...2 File Systems Architecture...2 Network Architecture...3 IBM BigInsights...5
PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters. from One Stop Systems (OSS)
 Clusters. from One Stop Systems (OSS)") PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters from One Stop Systems (OSS) PCIe Over Cable PCIe provides greater performance 8 7 6 5 GBytes/s 4
PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters from One Stop Systems (OSS) PCIe Over Cable PCIe provides greater performance 8 7 6 5 GBytes/s 4
Installing Hadoop over Ceph, Using High Performance Networking
 WHITE PAPER March 2014 Installing Hadoop over Ceph, Using High Performance Networking Contents Background...2 Hadoop...2 Hadoop Distributed File System (HDFS)...2 Ceph...2 Ceph File System (CephFS)...3
WHITE PAPER March 2014 Installing Hadoop over Ceph, Using High Performance Networking Contents Background...2 Hadoop...2 Hadoop Distributed File System (HDFS)...2 Ceph...2 Ceph File System (CephFS)...3
JuRoPA. Jülich Research on Petaflop Architecture. One Year on. Hugo R. Falter, COO Lee J Porter, Engineering
 JuRoPA Jülich Research on Petaflop Architecture One Year on Hugo R. Falter, COO Lee J Porter, Engineering HPC Advisoy Counsil, Workshop 2010, Lugano 1 Outline The work of ParTec on JuRoPA (HF) Overview
JuRoPA Jülich Research on Petaflop Architecture One Year on Hugo R. Falter, COO Lee J Porter, Engineering HPC Advisoy Counsil, Workshop 2010, Lugano 1 Outline The work of ParTec on JuRoPA (HF) Overview
Scripts for InfiniBand Monitoring
 Scripts for InfiniBand Monitoring Blake Caldwell April 30, 2015 ORNL is managed by UT-Battelle for the US Department of Energy Monitoring tools IB Health Check D3.js visualizations Perfquery balancing
Scripts for InfiniBand Monitoring Blake Caldwell April 30, 2015 ORNL is managed by UT-Battelle for the US Department of Energy Monitoring tools IB Health Check D3.js visualizations Perfquery balancing
Can High-Performance Interconnects Benefit Memcached and Hadoop?
 Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
High Throughput File Servers with SMB Direct, Using the 3 Flavors of RDMA network adapters
 High Throughput File Servers with SMB Direct, Using the 3 Flavors of network adapters Jose Barreto Principal Program Manager Microsoft Corporation Abstract In Windows Server 2012, we introduce the SMB
High Throughput File Servers with SMB Direct, Using the 3 Flavors of network adapters Jose Barreto Principal Program Manager Microsoft Corporation Abstract In Windows Server 2012, we introduce the SMB
Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage
 White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
White Paper Scaling Objectivity Database Performance with Panasas Scale-Out NAS Storage A Benchmark Report August 211 Background Objectivity/DB uses a powerful distributed processing architecture to manage
Building All-Flash Software Defined Storages for Datacenters. Ji Hyuck Yun (dr.jhyun@sk.com) Storage Tech. Lab SK Telecom
 Storage Tech. Lab SK Telecom") Building All-Flash Software Defined Storages for Datacenters Ji Hyuck Yun (dr.jhyun@sk.com) Storage Tech. Lab SK Telecom Introduction R&D Motivation Synergy between SK Telecom and SK Hynix Service & Solution
Building All-Flash Software Defined Storages for Datacenters Ji Hyuck Yun (dr.jhyun@sk.com) Storage Tech. Lab SK Telecom Introduction R&D Motivation Synergy between SK Telecom and SK Hynix Service & Solution
Advancing Applications Performance With InfiniBand
 Advancing Applications Performance With InfiniBand Pak Lui, Application Performance Manager September 12, 2013 Mellanox Overview Ticker: MLNX Leading provider of high-throughput, low-latency server and
Advancing Applications Performance With InfiniBand Pak Lui, Application Performance Manager September 12, 2013 Mellanox Overview Ticker: MLNX Leading provider of high-throughput, low-latency server and
A Shared File System on SAS Grid Manger in a Cloud Environment
 A Shared File System on SAS Grid Manger in a Cloud Environment ABSTRACT Ying-ping (Marie) Zhang, Intel Corporation, Chandler, Arizona Margaret Carver, SAS Institute, Cary, North Carolina Gabriele Paciucci,
A Shared File System on SAS Grid Manger in a Cloud Environment ABSTRACT Ying-ping (Marie) Zhang, Intel Corporation, Chandler, Arizona Margaret Carver, SAS Institute, Cary, North Carolina Gabriele Paciucci,
ALPS Supercomputing System A Scalable Supercomputer with Flexible Services
 ALPS Supercomputing System A Scalable Supercomputer with Flexible Services 1 Abstract Supercomputing is moving from the realm of abstract to mainstream with more and more applications and research being
ALPS Supercomputing System A Scalable Supercomputer with Flexible Services 1 Abstract Supercomputing is moving from the realm of abstract to mainstream with more and more applications and research being
Scalable filesystems boosting Linux storage solutions
 Scalable filesystems boosting Linux storage solutions Daniel Kobras science + computing ag IT-Dienstleistungen und Software für anspruchsvolle Rechnernetze Tübingen München Berlin Düsseldorf Motivation
Scalable filesystems boosting Linux storage solutions Daniel Kobras science + computing ag IT-Dienstleistungen und Software für anspruchsvolle Rechnernetze Tübingen München Berlin Düsseldorf Motivation
BIG DATA The Petabyte Age: More Isn't Just More More Is Different wired magazine Issue 16/.07
 BIG DATA The Petabyte Age: More Isn't Just More More Is Different wired magazine Issue 16/.07 Martien Ouwens Datacenter Solutions Architect Sun Microsystems 1 Big Data, The Petabyte Age: Relational Next
BIG DATA The Petabyte Age: More Isn't Just More More Is Different wired magazine Issue 16/.07 Martien Ouwens Datacenter Solutions Architect Sun Microsystems 1 Big Data, The Petabyte Age: Relational Next
IBM Spectrum Scale vs EMC Isilon for IBM Spectrum Protect Workloads
 89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com @EdisonGroupInc 212.367.7400 IBM Spectrum Scale vs EMC Isilon for IBM Spectrum Protect Workloads A Competitive Test and Evaluation Report
89 Fifth Avenue, 7th Floor New York, NY 10003 www.theedison.com @EdisonGroupInc 212.367.7400 IBM Spectrum Scale vs EMC Isilon for IBM Spectrum Protect Workloads A Competitive Test and Evaluation Report
SMB Advanced Networking for Fault Tolerance and Performance. Jose Barreto Principal Program Managers Microsoft Corporation
 SMB Advanced Networking for Fault Tolerance and Performance Jose Barreto Principal Program Managers Microsoft Corporation Agenda SMB Remote File Storage for Server Apps SMB Direct (SMB over RDMA) SMB Multichannel
SMB Advanced Networking for Fault Tolerance and Performance Jose Barreto Principal Program Managers Microsoft Corporation Agenda SMB Remote File Storage for Server Apps SMB Direct (SMB over RDMA) SMB Multichannel
SAN Conceptual and Design Basics
 TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
TECHNICAL NOTE VMware Infrastructure 3 SAN Conceptual and Design Basics VMware ESX Server can be used in conjunction with a SAN (storage area network), a specialized high speed network that connects computer
ECLIPSE Performance Benchmarks and Profiling. January 2009
 ECLIPSE Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox, Schlumberger HPC Advisory Council Cluster
ECLIPSE Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox, Schlumberger HPC Advisory Council Cluster
Open Cirrus: Towards an Open Source Cloud Stack
 Open Cirrus: Towards an Open Source Cloud Stack Karlsruhe Institute of Technology (KIT) HPC2010, Cetraro, June 2010 Marcel Kunze KIT University of the State of Baden-Württemberg and National Laboratory
Open Cirrus: Towards an Open Source Cloud Stack Karlsruhe Institute of Technology (KIT) HPC2010, Cetraro, June 2010 Marcel Kunze KIT University of the State of Baden-Württemberg and National Laboratory
Data Management Best Practices
 December 4, 2013 Data Management Best Practices Ryan Mokos Outline Overview of Nearline system (HPSS) Hardware File system structure Data transfer on Blue Waters Globus Online (GO) interface Web GUI Command-Line
December 4, 2013 Data Management Best Practices Ryan Mokos Outline Overview of Nearline system (HPSS) Hardware File system structure Data transfer on Blue Waters Globus Online (GO) interface Web GUI Command-Line
高 通 量 科 学 计 算 集 群 及 Lustre 文 件 系 统. High Throughput Scientific Computing Clusters And Lustre Filesystem In Tsinghua University
 高 通 量 科 学 计 算 集 群 及 Lustre 文 件 系 统 High Throughput Scientific Computing Clusters And Lustre Filesystem In Tsinghua University 清 华 信 息 科 学 与 技 术 国 家 实 验 室 ( 筹 ) 公 共 平 台 与 技 术 部 清 华 大 学 科 学 与 工 程 计 算 实 验
高 通 量 科 学 计 算 集 群 及 Lustre 文 件 系 统 High Throughput Scientific Computing Clusters And Lustre Filesystem In Tsinghua University 清 华 信 息 科 学 与 技 术 国 家 实 验 室 ( 筹 ) 公 共 平 台 与 技 术 部 清 华 大 学 科 学 与 工 程 计 算 实 验
Springpath Data Platform with Cisco UCS Servers
 Springpath Data Platform with Cisco UCS Servers Reference Architecture March 2015 SPRINGPATH DATA PLATFORM WITH CISCO UCS SERVERS Reference Architecture 1.0 Introduction to Springpath Data Platform 1 2.0
Springpath Data Platform with Cisco UCS Servers Reference Architecture March 2015 SPRINGPATH DATA PLATFORM WITH CISCO UCS SERVERS Reference Architecture 1.0 Introduction to Springpath Data Platform 1 2.0
Lustre* is designed to achieve the maximum performance and scalability for POSIX applications that need outstanding streamed I/O.
 Reference Architecture Designing High-Performance Storage Tiers Designing High-Performance Storage Tiers Intel Enterprise Edition for Lustre* software and Intel Non-Volatile Memory Express (NVMe) Storage
Reference Architecture Designing High-Performance Storage Tiers Designing High-Performance Storage Tiers Intel Enterprise Edition for Lustre* software and Intel Non-Volatile Memory Express (NVMe) Storage
Performance of the JMA NWP models on the PC cluster TSUBAME.
 Performance of the JMA NWP models on the PC cluster TSUBAME. K.Takenouchi 1), S.Yokoi 1), T.Hara 1) *, T.Aoki 2), C.Muroi 1), K.Aranami 1), K.Iwamura 1), Y.Aikawa 1) 1) Japan Meteorological Agency (JMA)
Performance of the JMA NWP models on the PC cluster TSUBAME. K.Takenouchi 1), S.Yokoi 1), T.Hara 1) *, T.Aoki 2), C.Muroi 1), K.Aranami 1), K.Iwamura 1), Y.Aikawa 1) 1) Japan Meteorological Agency (JMA)
SX1012: High Performance Small Scale Top-of-Rack Switch
 WHITE PAPER August 2013 SX1012: High Performance Small Scale Top-of-Rack Switch Introduction...1 Smaller Footprint Equals Cost Savings...1 Pay As You Grow Strategy...1 Optimal ToR for Small-Scale Deployments...2
WHITE PAPER August 2013 SX1012: High Performance Small Scale Top-of-Rack Switch Introduction...1 Smaller Footprint Equals Cost Savings...1 Pay As You Grow Strategy...1 Optimal ToR for Small-Scale Deployments...2
Mellanox Cloud and Database Acceleration Solution over Windows Server 2012 SMB Direct
 Mellanox Cloud and Database Acceleration Solution over Windows Server 2012 Direct Increased Performance, Scaling and Resiliency July 2012 Motti Beck, Director, Enterprise Market Development Motti@mellanox.com
Mellanox Cloud and Database Acceleration Solution over Windows Server 2012 Direct Increased Performance, Scaling and Resiliency July 2012 Motti Beck, Director, Enterprise Market Development Motti@mellanox.com
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013
 Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
Hadoop MapReduce over Lustre* High Performance Data Division Omkar Kulkarni April 16, 2013 * Other names and brands may be claimed as the property of others. Agenda Hadoop Intro Why run Hadoop on Lustre?
I D C O P I N I O N S I T U A T I O N O V E R V I E W. Sponsored by: NEC. Kazuhiko Hayashi October 2014
 IDC Japan 3rd Floor, Hulic Kudan Building, 1-13-5 Kudankita, Chiyoda-ku, Tokyo 102-0073 P.81.3.3556.4760 W H I T E P A P E R H i g h l y - R e l i a b l e S e r v e r R e q u i r e d i n D a t a c e n
IDC Japan 3rd Floor, Hulic Kudan Building, 1-13-5 Kudankita, Chiyoda-ku, Tokyo 102-0073 P.81.3.3556.4760 W H I T E P A P E R H i g h l y - R e l i a b l e S e r v e r R e q u i r e d i n D a t a c e n