Computation of Mutual Information Metric for Image Registration on Multiple GPUs
|
|
|
- Brook Burke
- 8 years ago
- Views:
Transcription
1 Computation of Mutual Information Metric for Image Registration on Multiple GPUs Andrew V. Adinetz 1, Markus Axer 2, Marcel Huysegoms 2, Stefan Köhnen 2, Jiri Kraus 3, Dirk Pleiter 1 1 JSC, Forschungszentrum Jülich 2 INM-1, Forschungszentrum Jülich 3 NVIDIA GmbH Presented at HeteroPar 13 workshop of EuroPar 13

2 Outline Brain Image Registration Multi-GPU Implementation system memory listupdate Performance Evaluation Conclusion 2

3 Preparation of the brain 3

4 Pushing the limits for a cellular brain model BigBrain first high-resolution brain model at microscopical scale! 7404 histological sec/ons stained for cell bodies! scanned with a flad bed scanner! original resolu/on μm 3 ( pixels)! downscaling to 20 μm isotropic! removal of ar/facts! 1 Terabyte in cooperation with Alan Evans, McGill, Montreal Amunts et al. (2013) Science

5

6

7
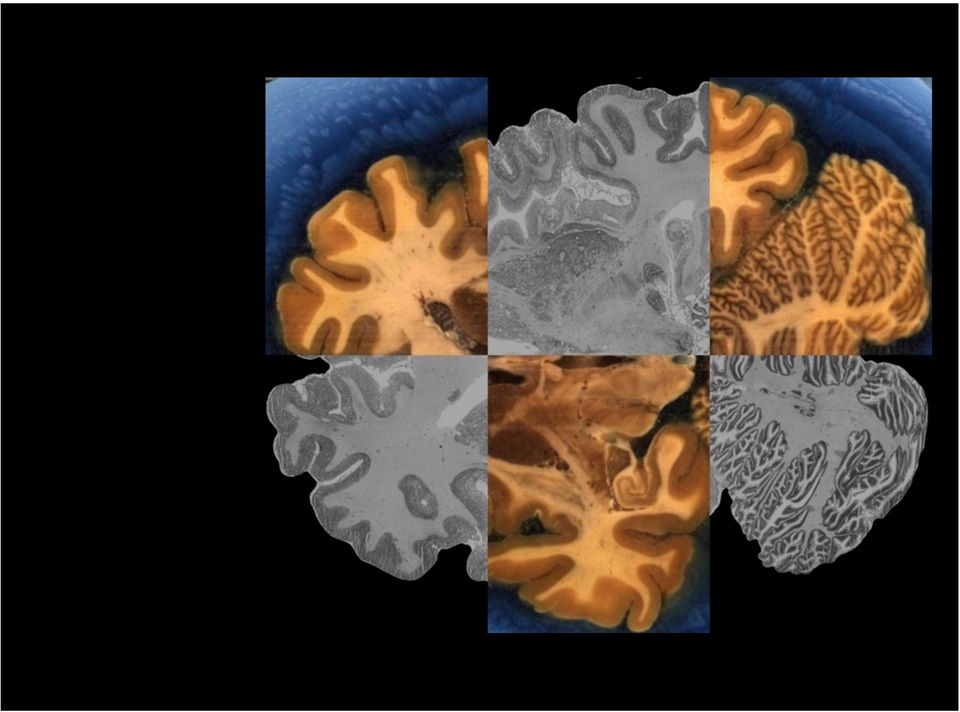
8 Image Registration Registration = process of image alignment ITK Workflow 8

9 Mutual Information Metric MI(I f,i m ) = p(i, j)log 2 j i, j p f (i) = p(i, j) i p m ( j) = p(i, j) p(i, j) p f (i) p m ( j) i, j pixel values ( ) successful for multi-modal registration 9

10 Two Image Cross-Histogram for(int y = 0; y < fixed_sz_y; y++) for(int x = 0; x < fixed_sz_x; x++) { int i = bin(fixed[x, y]); float x1 = transform_x(x, y); float y1 = transform_y(x, y); int j = bin(interpolate(moving, x1, y1)); histogram[i, j]++; // atomic on GPU } main computational kernel transform can be complex (1000+ parameters) GPU implementation: 1 pixel/thread, atomics 10
![int j = bin(interpolate(moving, x1, y1)); histogram[i, j]++; // atomic on GPU } main](/docs-images/45/901527/images/page_10.jpg "computational kernel transform can be complex (1000+ parameters) GPU implementation: 1")
11 Large Data Size Large-area Polarimeter Polarizing Microscope size: px pixel size: µm file size: 30 MB size: px Need mul(ple GPUs! pixel size: 1.6 x 1.6 µm file size: 40 GB 11

12 Multi-GPU Mutual Information Domain decomposition distribute fixed and moving images histogram contributions summed up Moving image: how to handle? irregular access pattern Approaches System memory replication (sysmem) Listupdate (listupdate) 12

13 System Memory Replication Replicate entire moving image in pinned host RAM accessible to GPU + easy to implement system memory accesses are slower cannot use texture interpolation Optimizations moving image halo in GPU RAM 13

14 Listupdate On remote access send message On receiving message compute contributions Active messaging variant buffering relies on undocumented features Listupdate chunking buffer size bounded communication-computation overlap typedef struct { float[2] movingcoords; short destrank; char fixedbin; } message_t; 14

15 Writeout: Atomics vs Grouping Atomics determine write posi(on using atomics warp- aggregated increment Grouping write to per- pixel buffer group (compress) 15

16 Chunk Processing and Overlap y Fixed Image Fixed Image (0,0) x 1 2 Process chunk Group Exchange Handle messages Process chunk Group Exchange Process chunk Group

17 Listupdate typedef struct { float[2] movingcoords; short destrank; char fixedbin; } message_t; + computation-communication overlap hard to implement chunk processing (or won t fit into buffer) Optimizations buffers: AoS vs. SoA atomics vs. grouping using multiple streams 17

18 Benchmark setup y Remote access Fixed Image Fixed Image Mask (0,0) x 18
")
19 Test Hardware JUDGE 256-node GPU cluster Each M2070 node: 2x M2070 (Fermi) GPU, each 6 GB RAM 12-core X GHz, 96 GB RAM JuHydra single-node Kepler machine 2x K20X (Kepler) GPU, each 6 GB RAM 16-core E GHz, 64 GB RAM 19
 GPU, each 6 GB RAM 16-core E5-2650 CPU @ 2 GHz, 64")
20 Baseline: Full Replication (M2070) Run/me in seconds GPU 2 - GPUs 4 - GPUs Rota/on angle ideal scalability 20

21 Sysmem on Fermi Run/me in seconds GPU 2- GPUs Baseline 2 GPUs Rota/on angle 21
22 Sysmem on Fermi: Explanation No sysmem Access Good Coalescing Few sysmem Access Bad Coalescing Many sysmem Access Bad Coalescing Most sysmem Access Good Coalescing 22
23 Sysmem on Fermi: PCI-E Queries Run/me in seconds Sysmem_queries Rota/on angle 2- GPUs Baseline 2 GPUs Total Sysmem_queries 0 23
24 Sysmem: Halo Sizes Time, s Angle, degrees 2 K20X, baseline 2 K20X, sysmem 2 K20X, 5% halo 2 K20X, 10% halo 2 K20X, 15% halo 2 K20X, 20% halo 2 K20X, 25% halo mostly quan(ta(ve, not qualita(ve difference 24
25 Listupdate: Multiple Streams Time, s Angle, degrees 2 K20X, 1 stream 2 K20X, 2 streams 2 K20X, 3 streams 2 K20X, 4 streams streams look the best
26 Listupdate: AoS vs SoA, Atomics vs Group typedef struct { float[2] movingcoords; char fixedbin; } message_t; Time, s Angle, degrees SoA + atomics looks best K20X, SoA 2 K20X, AoS 2 K20X, compress
27 Sysmem vs. Listupdate: Fermi Time, s Angle, degrees 4 M2070, SoA 4 M2070, baseline 4 M2070, sysmem 4 M2070, 25% halo on Fermi, sysmem is be_er 27
28 Sysmem vs. Listupdate: Kepler (Closeup) Time, s Angle, degrees 2 K20X, SoA 2 K20X, baseline 2 K20X, sysmem 2 K20X, 25% halo on Kepler, listupdate is be_er 28
29 Conclusions Fermi performance limited by atomics system memory replication is better Kepler 10x faster than Fermi no longer dominated by atomics listupdate (atomic, SoA, 4 streams) is better Future work Compression Trials on real images 29
30 Questions? INM-1 at FZJ: NVidia Application Lab at FZJ: Andrew V. Adinetz: Jiri Kraus: Dirk Pleiter: 30
Computer Graphics Hardware An Overview
 Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
GPU Computing with CUDA Lecture 4 - Optimizations. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
GPU Computing with CUDA Lecture 4 - Optimizations Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 3 Control flow Coalescing Latency hiding
Robust Algorithms for Current Deposition and Dynamic Load-balancing in a GPU Particle-in-Cell Code
 Robust Algorithms for Current Deposition and Dynamic Load-balancing in a GPU Particle-in-Cell Code F. Rossi, S. Sinigardi, P. Londrillo & G. Turchetti University of Bologna & INFN GPU2014, Rome, Sept 17th
Robust Algorithms for Current Deposition and Dynamic Load-balancing in a GPU Particle-in-Cell Code F. Rossi, S. Sinigardi, P. Londrillo & G. Turchetti University of Bologna & INFN GPU2014, Rome, Sept 17th
Bringing Big Data Modelling into the Hands of Domain Experts
 Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
Bringing Big Data Modelling into the Hands of Domain Experts David Willingham Senior Application Engineer MathWorks david.willingham@mathworks.com.au 2015 The MathWorks, Inc. 1 Data is the sword of the
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB
 BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
BENCHMARKING CLOUD DATABASES CASE STUDY on HBASE, HADOOP and CASSANDRA USING YCSB Planet Size Data!? Gartner s 10 key IT trends for 2012 unstructured data will grow some 80% over the course of the next
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
CUDA in the Cloud Enabling HPC Workloads in OpenStack With special thanks to Andrew Younge (Indiana Univ.) and Massimo Bernaschi (IAC-CNR)
 and Massimo Bernaschi (IAC-CNR)") CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu With special thanks to Andrew Younge (Indiana Univ.) and Massimo
CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu With special thanks to Andrew Younge (Indiana Univ.) and Massimo
GPU File System Encryption Kartik Kulkarni and Eugene Linkov
 GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
GPU File System Encryption Kartik Kulkarni and Eugene Linkov 5/10/2012 SUMMARY. We implemented a file system that encrypts and decrypts files. The implementation uses the AES algorithm computed through
Texture Cache Approximation on GPUs
 Texture Cache Approximation on GPUs Mark Sutherland Joshua San Miguel Natalie Enright Jerger {suther68,enright}@ece.utoronto.ca, joshua.sanmiguel@mail.utoronto.ca 1 Our Contribution GPU Core Cache Cache
Texture Cache Approximation on GPUs Mark Sutherland Joshua San Miguel Natalie Enright Jerger {suther68,enright}@ece.utoronto.ca, joshua.sanmiguel@mail.utoronto.ca 1 Our Contribution GPU Core Cache Cache
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect
 SIGGRAPH 2013 Shaping the Future of Visual Computing NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect NVIDIA
SIGGRAPH 2013 Shaping the Future of Visual Computing NVIDIA IndeX Enabling Interactive and Scalable Visualization for Large Data Marc Nienhaus, NVIDIA IndeX Engineering Manager and Chief Architect NVIDIA
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration. Sina Meraji sinamera@ca.ibm.com
 Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Please Note IBM s statements regarding its plans, directions, and intent are subject to
Towards Fast SQL Query Processing in DB2 BLU Using GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Please Note IBM s statements regarding its plans, directions, and intent are subject to
Stream Processing on GPUs Using Distributed Multimedia Middleware
 Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK
 HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs
 A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
GPU Hardware Performance. Fall 2015
 Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
Fall 2015 Atomic operations performs read-modify-write operations on shared or global memory no interference with other threads for 32-bit and 64-bit integers (c. c. 1.2), float addition (c. c. 2.0) using
High Performance Computing in CST STUDIO SUITE
 High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
A Performance Analysis of Distributed Indexing using Terrier
 A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
A Performance Analysis of Distributed Indexing using Terrier Amaury Couste Jakub Kozłowski William Martin Indexing Indexing Used by search
Parquet. Columnar storage for the people
 Parquet Columnar storage for the people Julien Le Dem @J_ Processing tools lead, analytics infrastructure at Twitter Nong Li nong@cloudera.com Software engineer, Cloudera Impala Outline Context from various
Parquet Columnar storage for the people Julien Le Dem @J_ Processing tools lead, analytics infrastructure at Twitter Nong Li nong@cloudera.com Software engineer, Cloudera Impala Outline Context from various
Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com
 mzahran@cs.nyu.edu http://www.mzahran.com") CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
CSCI-GA.3033-012 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Modern GPUs A Hardware Perspective Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Modern GPU
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
SQream Technologies Ltd - Confiden7al
 SQream Technologies Ltd - Confiden7al 1 Ge#ng Big Data Done On a GPU- Based Database Ori Netzer VP Product 26- Mar- 14 Analy7cs Performance - 3 TB, 18 Billion records SQream Database 400x More Cost Efficient!
SQream Technologies Ltd - Confiden7al 1 Ge#ng Big Data Done On a GPU- Based Database Ori Netzer VP Product 26- Mar- 14 Analy7cs Performance - 3 TB, 18 Billion records SQream Database 400x More Cost Efficient!
Interactive Level-Set Segmentation on the GPU
 Interactive Level-Set Segmentation on the GPU Problem Statement Goal Interactive system for deformable surface manipulation Level-sets Challenges Deformation is slow Deformation is hard to control Solution
Interactive Level-Set Segmentation on the GPU Problem Statement Goal Interactive system for deformable surface manipulation Level-sets Challenges Deformation is slow Deformation is hard to control Solution
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age
 Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
CUDA SKILLS. Yu-Hang Tang. June 23-26, 2015 CSRC, Beijing
 CUDA SKILLS Yu-Hang Tang June 23-26, 2015 CSRC, Beijing day1.pdf at /home/ytang/slides Referece solutions coming soon Online CUDA API documentation http://docs.nvidia.com/cuda/index.html Yu-Hang Tang @
CUDA SKILLS Yu-Hang Tang June 23-26, 2015 CSRC, Beijing day1.pdf at /home/ytang/slides Referece solutions coming soon Online CUDA API documentation http://docs.nvidia.com/cuda/index.html Yu-Hang Tang @
Applications to Computational Financial and GPU Computing. May 16th. Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61
 F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
F# Applications to Computational Financial and GPU Computing May 16th Dr. Daniel Egloff +41 44 520 01 17 +41 79 430 03 61 Today! Why care about F#? Just another fashion?! Three success stories! How Alea.cuBase
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Optimizing Application Performance with CUDA Profiling Tools
 Optimizing Application Performance with CUDA Profiling Tools Why Profile? Application Code GPU Compute-Intensive Functions Rest of Sequential CPU Code CPU 100 s of cores 10,000 s of threads Great memory
Optimizing Application Performance with CUDA Profiling Tools Why Profile? Application Code GPU Compute-Intensive Functions Rest of Sequential CPU Code CPU 100 s of cores 10,000 s of threads Great memory
GPU Accelerated Signal Processing in OpenStack. John Paul Walters. Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.
 GPU Accelerated Signal Processing in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu Outline Motivation OpenStack Background Heterogeneous OpenStack GPU
GPU Accelerated Signal Processing in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu Outline Motivation OpenStack Background Heterogeneous OpenStack GPU
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Technical Paper. Performance and Tuning Considerations for SAS on Fusion-io ioscale Flash Storage
 Technical Paper Performance and Tuning Considerations for SAS on Fusion-io ioscale Flash Storage Release Information Content Version: 1.0 May 2014. Trademarks and Patents SAS Institute Inc., SAS Campus
Technical Paper Performance and Tuning Considerations for SAS on Fusion-io ioscale Flash Storage Release Information Content Version: 1.0 May 2014. Trademarks and Patents SAS Institute Inc., SAS Campus
GPU Renderfarm with Integrated Asset Management & Production System (AMPS)
") GPU Renderfarm with Integrated Asset Management & Production System (AMPS) Tackling two main challenges in CG movie production Presenter: Dr. Chen Quan Multi-plAtform Game Innovation Centre (MAGIC), Nanyang
GPU Renderfarm with Integrated Asset Management & Production System (AMPS) Tackling two main challenges in CG movie production Presenter: Dr. Chen Quan Multi-plAtform Game Innovation Centre (MAGIC), Nanyang
Clustering Billions of Data Points Using GPUs
 Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
Clustering Billions of Data Points Using GPUs Ren Wu ren.wu@hp.com Bin Zhang bin.zhang2@hp.com Meichun Hsu meichun.hsu@hp.com ABSTRACT In this paper, we report our research on using GPUs to accelerate
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
IT of SPIM Data Storage and Compression. EMBO Course - August 27th! Jeff Oegema, Peter Steinbach, Oscar Gonzalez
 IT of SPIM Data Storage and Compression EMBO Course - August 27th Jeff Oegema, Peter Steinbach, Oscar Gonzalez 1 Talk Outline Introduction and the IT Team SPIM Data Flow Capture, Compression, and the Data
IT of SPIM Data Storage and Compression EMBO Course - August 27th Jeff Oegema, Peter Steinbach, Oscar Gonzalez 1 Talk Outline Introduction and the IT Team SPIM Data Flow Capture, Compression, and the Data
Medical Image Processing on the GPU. Past, Present and Future. Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.
 Medical Image Processing on the GPU Past, Present and Future Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.edu Outline Motivation why do we need GPUs? Past - how was GPU programming
Medical Image Processing on the GPU Past, Present and Future Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.edu Outline Motivation why do we need GPUs? Past - how was GPU programming
Hardware/Software Guidelines
 There are many things to consider when preparing for a TRAVERSE v11 installation. The number of users, application modules and transactional volume are only a few. Reliable performance of the system is
There are many things to consider when preparing for a TRAVERSE v11 installation. The number of users, application modules and transactional volume are only a few. Reliable performance of the system is
Scalable Cloud Computing Solutions for Next Generation Sequencing Data
 Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data
 Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
OpenCL Optimization. San Jose 10/2/2009 Peng Wang, NVIDIA
 OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
Recent Advances in HPC for Structural Mechanics Simulations
 Recent Advances in HPC for Structural Mechanics Simulations 1 Trends in Engineering Driving Demand for HPC Increase product performance and integrity in less time Consider more design variants Find the
Recent Advances in HPC for Structural Mechanics Simulations 1 Trends in Engineering Driving Demand for HPC Increase product performance and integrity in less time Consider more design variants Find the
Pedraforca: ARM + GPU prototype
 www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
MIRAX SCAN The new way of looking at pathology
 Microscopy from Carl Zeiss MIRAX SCAN The new way of looking at pathology Greater reliability. Greater efficiency. Virtual microscopy for research & analysis. Better. More efficient. Quality as the basis
Microscopy from Carl Zeiss MIRAX SCAN The new way of looking at pathology Greater reliability. Greater efficiency. Virtual microscopy for research & analysis. Better. More efficient. Quality as the basis
Testing 3Vs (Volume, Variety and Velocity) of Big Data
 of Big Data") Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Workshop on Parallel and Distributed Scientific and Engineering Computing, Shanghai, 25 May 2012
 Scientific Application Performance on HPC, Private and Public Cloud Resources: A Case Study Using Climate, Cardiac Model Codes and the NPB Benchmark Suite Peter Strazdins (Research School of Computer Science),
Scientific Application Performance on HPC, Private and Public Cloud Resources: A Case Study Using Climate, Cardiac Model Codes and the NPB Benchmark Suite Peter Strazdins (Research School of Computer Science),
GPU Computing with CUDA Lecture 2 - CUDA Memories. Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile
 GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
GPU Computing with CUDA Lecture 2 - CUDA Memories Christopher Cooper Boston University August, 2011 UTFSM, Valparaíso, Chile 1 Outline of lecture Recap of Lecture 1 Warp scheduling CUDA Memory hierarchy
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU
 Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
Efficient Parallel Graph Exploration on Multi-Core CPU and GPU Pervasive Parallelism Laboratory Stanford University Sungpack Hong, Tayo Oguntebi, and Kunle Olukotun Graph and its Applications Graph Fundamental
Experiences on using GPU accelerators for data analysis in ROOT/RooFit
 Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Packet-based Network Traffic Monitoring and Analysis with GPUs
 Packet-based Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2014 March 24-27, 2014 SAN JOSE, CALIFORNIA Background Main
Packet-based Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2014 March 24-27, 2014 SAN JOSE, CALIFORNIA Background Main
ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop. Emily Apsey Performance Engineer
 ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop Emily Apsey Performance Engineer Presentation Overview What it takes to successfully virtualize ArcGIS Pro in Citrix XenApp and XenDesktop - Shareable
ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop Emily Apsey Performance Engineer Presentation Overview What it takes to successfully virtualize ArcGIS Pro in Citrix XenApp and XenDesktop - Shareable
GPU Architecture. Michael Doggett ATI
 GPU Architecture Michael Doggett ATI GPU Architecture RADEON X1800/X1900 Microsoft s XBOX360 Xenos GPU GPU research areas ATI - Driving the Visual Experience Everywhere Products from cell phones to super
GPU Architecture Michael Doggett ATI GPU Architecture RADEON X1800/X1900 Microsoft s XBOX360 Xenos GPU GPU research areas ATI - Driving the Visual Experience Everywhere Products from cell phones to super
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Network Traffic Monitoring & Analysis with GPUs
 Network Traffic Monitoring & Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2013 March 18-21, 2013 SAN JOSE, CALIFORNIA Background Main uses for network
Network Traffic Monitoring & Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2013 March 18-21, 2013 SAN JOSE, CALIFORNIA Background Main uses for network
GPU Performance Analysis and Optimisation
 GPU Performance Analysis and Optimisation Thomas Bradley, NVIDIA Corporation Outline What limits performance? Analysing performance: GPU profiling Exposing sufficient parallelism Optimising for Kepler
GPU Performance Analysis and Optimisation Thomas Bradley, NVIDIA Corporation Outline What limits performance? Analysing performance: GPU profiling Exposing sufficient parallelism Optimising for Kepler
Cloud Computing. Alex Crawford Ben Johnstone
 Cloud Computing Alex Crawford Ben Johnstone Overview What is cloud computing? Amazon EC2 Performance Conclusions What is the Cloud? A large cluster of machines o Economies of scale [1] Customers use a
Cloud Computing Alex Crawford Ben Johnstone Overview What is cloud computing? Amazon EC2 Performance Conclusions What is the Cloud? A large cluster of machines o Economies of scale [1] Customers use a
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data
 Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
NVIDIA Tools For Profiling And Monitoring. David Goodwin
 NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
NVIDIA Tools For Profiling And Monitoring David Goodwin Outline CUDA Profiling and Monitoring Libraries Tools Technologies Directions CScADS Summer 2012 Workshop on Performance Tools for Extreme Scale
GeoImaging Accelerator Pansharp Test Results
 GeoImaging Accelerator Pansharp Test Results Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance
GeoImaging Accelerator Pansharp Test Results Executive Summary After demonstrating the exceptional performance improvement in the orthorectification module (approximately fourteen-fold see GXL Ortho Performance
Use of Hadoop File System for Nuclear Physics Analyses in STAR
 1 Use of Hadoop File System for Nuclear Physics Analyses in STAR EVAN SANGALINE UC DAVIS Motivations 2 Data storage a key component of analysis requirements Transmission and storage across diverse resources
1 Use of Hadoop File System for Nuclear Physics Analyses in STAR EVAN SANGALINE UC DAVIS Motivations 2 Data storage a key component of analysis requirements Transmission and storage across diverse resources
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices
 The Yin and Yang of Processing Data Warehousing Queries on GPU Devices Yuan Yuan Rubao Lee Xiaodong Zhang Department of Computer Science and Engineering The Ohio State University {yuanyu, liru, zhang}@cse.ohio-state.edu
The Yin and Yang of Processing Data Warehousing Queries on GPU Devices Yuan Yuan Rubao Lee Xiaodong Zhang Department of Computer Science and Engineering The Ohio State University {yuanyu, liru, zhang}@cse.ohio-state.edu
Can High-Performance Interconnects Benefit Memcached and Hadoop?
 Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Can High-Performance Interconnects Benefit Memcached and Hadoop? D. K. Panda and Sayantan Sur Network-Based Computing Laboratory Department of Computer Science and Engineering The Ohio State University,
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter
 Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
HP ProLiant SL270s Gen8 Server. Evaluation Report
 HP ProLiant SL270s Gen8 Server Evaluation Report Thomas Schoenemeyer, Hussein Harake and Daniel Peter Swiss National Supercomputing Centre (CSCS), Lugano Institute of Geophysics, ETH Zürich schoenemeyer@cscs.ch
HP ProLiant SL270s Gen8 Server Evaluation Report Thomas Schoenemeyer, Hussein Harake and Daniel Peter Swiss National Supercomputing Centre (CSCS), Lugano Institute of Geophysics, ETH Zürich schoenemeyer@cscs.ch
Design and Implementation of a Storage Repository Using Commonality Factoring. IEEE/NASA MSST2003 April 7-10, 2003 Eric W. Olsen
 Design and Implementation of a Storage Repository Using Commonality Factoring IEEE/NASA MSST2003 April 7-10, 2003 Eric W. Olsen Axion Overview Potentially infinite historic versioning for rollback and
Design and Implementation of a Storage Repository Using Commonality Factoring IEEE/NASA MSST2003 April 7-10, 2003 Eric W. Olsen Axion Overview Potentially infinite historic versioning for rollback and
Interactive Level-Set Deformation On the GPU
 Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
Interactive Level-Set Deformation On the GPU Institute for Data Analysis and Visualization University of California, Davis Problem Statement Goal Interactive system for deformable surface manipulation
Benchmarking Hadoop & HBase on Violin
 Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Technical White Paper Report Technical Report Benchmarking Hadoop & HBase on Violin Harnessing Big Data Analytics at the Speed of Memory Version 1.0 Abstract The purpose of benchmarking is to show advantages
Remote Graphical Visualization of Large Interactive Spatial Data
 Remote Graphical Visualization of Large Interactive Spatial Data ComplexHPC Spring School 2011 International ComplexHPC Challenge Cristinel Mihai Mocan Computer Science Department Technical University
Remote Graphical Visualization of Large Interactive Spatial Data ComplexHPC Spring School 2011 International ComplexHPC Challenge Cristinel Mihai Mocan Computer Science Department Technical University
SAS Grid Manager Testing and Benchmarking Best Practices for SAS Intelligence Platform
 SAS Grid Manager Testing and Benchmarking Best Practices for SAS Intelligence Platform INTRODUCTION Grid computing offers optimization of applications that analyze enormous amounts of data as well as load
SAS Grid Manager Testing and Benchmarking Best Practices for SAS Intelligence Platform INTRODUCTION Grid computing offers optimization of applications that analyze enormous amounts of data as well as load
Copyright 2011 Penguin Computing, Inc. All rights reserved. Interactive Preclinical Analytics via GPU Cloud Platform
 Copyright 2011 Penguin Computing, Inc. All rights reserved Interactive Preclinical Analytics via GPU Cloud Platform Numira and Penguin Partnership Penguin POD Innovative HPC as a Service platform > Strong
Copyright 2011 Penguin Computing, Inc. All rights reserved Interactive Preclinical Analytics via GPU Cloud Platform Numira and Penguin Partnership Penguin POD Innovative HPC as a Service platform > Strong
Scientific Computing Data Management Visions
 Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
Scaling in the Cloud with AWS. By: Eli White (CTO & Co-Founder @ mojolive) eliw.com - @eliw - mojolive.com
 eliw.com - @eliw - mojolive.com") Scaling in the Cloud with AWS By: Eli White (CTO & Co-Founder @ mojolive) eliw.com - @eliw - mojolive.com Welcome! Why is this guy talking to us? Please ask questions! 2 What is Scaling anyway? Enabling
Scaling in the Cloud with AWS By: Eli White (CTO & Co-Founder @ mojolive) eliw.com - @eliw - mojolive.com Welcome! Why is this guy talking to us? Please ask questions! 2 What is Scaling anyway? Enabling
Scaling Database Performance in Azure
 Scaling Database Performance in Azure Results of Microsoft-funded Testing Q1 2015 2015 2014 ScaleArc. All Rights Reserved. 1 Test Goals and Background Info Test Goals and Setup Test goals Microsoft commissioned
Scaling Database Performance in Azure Results of Microsoft-funded Testing Q1 2015 2015 2014 ScaleArc. All Rights Reserved. 1 Test Goals and Background Info Test Goals and Setup Test goals Microsoft commissioned
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
On the Cost of Mining Very Large Open Source Repositories
 On the Cost of Mining Very Large Open Source Repositories Sean Banerjee Carnegie Mellon University Bojan Cukic University of North Carolina at Charlotte BIGDSE, Florence 2015 Introduction Issue tracking
On the Cost of Mining Very Large Open Source Repositories Sean Banerjee Carnegie Mellon University Bojan Cukic University of North Carolina at Charlotte BIGDSE, Florence 2015 Introduction Issue tracking
Turbomachinery CFD on many-core platforms experiences and strategies
 Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
CUDA Optimization with NVIDIA Tools. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
CUDA Optimization with NVIDIA Tools Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nvidia Tools 2 What Does the Application
GPU-Based Network Traffic Monitoring & Analysis Tools
 GPU-Based Network Traffic Monitoring & Analysis Tools Wenji Wu; Phil DeMar wenji@fnal.gov, demar@fnal.gov CHEP 2013 October 17, 2013 Coarse Detailed Background Main uses for network traffic monitoring
GPU-Based Network Traffic Monitoring & Analysis Tools Wenji Wu; Phil DeMar wenji@fnal.gov, demar@fnal.gov CHEP 2013 October 17, 2013 Coarse Detailed Background Main uses for network traffic monitoring
PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0
 PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0 15 th January 2014 Al Chrosny Director, Software Engineering TreeAge Software, Inc. achrosny@treeage.com Andrew Munzer Director, Training and Customer
PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0 15 th January 2014 Al Chrosny Director, Software Engineering TreeAge Software, Inc. achrosny@treeage.com Andrew Munzer Director, Training and Customer
Network Traffic Monitoring and Analysis with GPUs
 Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2013 March 18-21, 2013 SAN JOSE, CALIFORNIA Background Main uses for network
Network Traffic Monitoring and Analysis with GPUs Wenji Wu, Phil DeMar wenji@fnal.gov, demar@fnal.gov GPU Technology Conference 2013 March 18-21, 2013 SAN JOSE, CALIFORNIA Background Main uses for network
Veeam Best Practices with Exablox
 Veeam Best Practices with Exablox Overview Exablox has worked closely with the team at Veeam to provide the best recommendations when using the the Veeam Backup & Replication software with OneBlox appliances.
Veeam Best Practices with Exablox Overview Exablox has worked closely with the team at Veeam to provide the best recommendations when using the the Veeam Backup & Replication software with OneBlox appliances.
NVIDIA GeForce GTX 580 GPU Datasheet
 NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
Lecture 10: Dynamic Memory Allocation 1: Into the jaws of malloc()
") CS61: Systems Programming and Machine Organization Harvard University, Fall 2009 Lecture 10: Dynamic Memory Allocation 1: Into the jaws of malloc() Prof. Matt Welsh October 6, 2009 Topics for today Dynamic
CS61: Systems Programming and Machine Organization Harvard University, Fall 2009 Lecture 10: Dynamic Memory Allocation 1: Into the jaws of malloc() Prof. Matt Welsh October 6, 2009 Topics for today Dynamic
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
How To Test Your Code On A Cuda Gdb (Gdb) On A Linux Computer With A Gbd (Gbd) And Gbbd Gbdu (Gdb) (Gdu) (Cuda
 On A Linux Computer With A Gbd (Gbd) And Gbbd Gbdu (Gdb) (Gdu) (Cuda") Mitglied der Helmholtz-Gemeinschaft Hands On CUDA Tools and Performance-Optimization JSC GPU Programming Course 26. März 2011 Dominic Eschweiler Outline of This Talk Introduction Setup CUDA-GDB Profiling
Mitglied der Helmholtz-Gemeinschaft Hands On CUDA Tools and Performance-Optimization JSC GPU Programming Course 26. März 2011 Dominic Eschweiler Outline of This Talk Introduction Setup CUDA-GDB Profiling
Coping with Complexity: CPUs, GPUs and Real-world Applications
 Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
The Rise of Industrial Big Data. Brian Courtney General Manager Industrial Data Intelligence
 The Rise of Industrial Big Data Brian Courtney General Manager Industrial Data Intelligence Agenda Introduction Big Data for the industrial sector Case in point: Big data saves millions at GE Energy Seeking
The Rise of Industrial Big Data Brian Courtney General Manager Industrial Data Intelligence Agenda Introduction Big Data for the industrial sector Case in point: Big data saves millions at GE Energy Seeking
Auto-Tunning of Data Communication on Heterogeneous Systems
 1 Auto-Tunning of Data Communication on Heterogeneous Systems Marc Jordà 1, Ivan Tanasic 1, Javier Cabezas 1, Lluís Vilanova 1, Isaac Gelado 1, and Nacho Navarro 1, 2 1 Barcelona Supercomputing Center
1 Auto-Tunning of Data Communication on Heterogeneous Systems Marc Jordà 1, Ivan Tanasic 1, Javier Cabezas 1, Lluís Vilanova 1, Isaac Gelado 1, and Nacho Navarro 1, 2 1 Barcelona Supercomputing Center
Table of Contents. P a g e 2
 Solution Guide Balancing Graphics Performance, User Density & Concurrency with NVIDIA GRID Virtual GPU Technology (vgpu ) for Autodesk AutoCAD Power Users V1.0 P a g e 2 Table of Contents The GRID vgpu
Solution Guide Balancing Graphics Performance, User Density & Concurrency with NVIDIA GRID Virtual GPU Technology (vgpu ) for Autodesk AutoCAD Power Users V1.0 P a g e 2 Table of Contents The GRID vgpu
Parallel Prefix Sum (Scan) with CUDA. Mark Harris mharris@nvidia.com
 with CUDA. Mark Harris mharris@nvidia.com") Parallel Prefix Sum (Scan) with CUDA Mark Harris mharris@nvidia.com April 2007 Document Change History Version Date Responsible Reason for Change February 14, 2007 Mark Harris Initial release April 2007
Parallel Prefix Sum (Scan) with CUDA Mark Harris mharris@nvidia.com April 2007 Document Change History Version Date Responsible Reason for Change February 14, 2007 Mark Harris Initial release April 2007
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION
 DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
DOCLITE: DOCKER CONTAINER-BASED LIGHTWEIGHT BENCHMARKING ON THE CLOUD
 DOCLITE: DOCKER CONTAINER-BASED LIGHTWEIGHT BENCHMARKING ON THE CLOUD 1 Supervisors: Dr. Adam Barker Dr. Blesson Varghese Summer School 2015 Lawan Thamsuhang Subba Structure of Presentation 2 Introduction
DOCLITE: DOCKER CONTAINER-BASED LIGHTWEIGHT BENCHMARKING ON THE CLOUD 1 Supervisors: Dr. Adam Barker Dr. Blesson Varghese Summer School 2015 Lawan Thamsuhang Subba Structure of Presentation 2 Introduction
High Performance. CAEA elearning Series. Jonathan G. Dudley, Ph.D. 06/09/2015. 2015 CAE Associates
 High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
Secondary Storage. Any modern computer system will incorporate (at least) two levels of storage: magnetic disk/optical devices/tape systems
 two levels of storage: magnetic disk/optical devices/tape systems") 1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity
1 Any modern computer system will incorporate (at least) two levels of storage: primary storage: typical capacity cost per MB $3. typical access time burst transfer rate?? secondary storage: typical capacity