Abstract. Question Answering Techniques for the World Wide Web. Jimmy Lin and Boris Katz MIT Artificial Intelligence Laboratory.
|
|
|
- Bernard Fisher
- 8 years ago
- Views:
Transcription
1 Question Answering Techniques for the World Wide Web Jimmy Lin and Boris Katz MIT Artificial Intelligence Laboratory Tutorial presentation at The 11 th Conference of the European Chapter of the Association of Computational Linguistics (EACL-2003) April 12, 2003 Abstract Question answering systems have become increasingly popular because they deliver users short, succinct answers instead of overloading them with a large number of irrelevant documents. The vast amount of information readily available on the World Wide Web presents new opportunities and challenges for question answering. In order for question answering systems to benefit from this vast store of useful knowledge, they must cope with large volumes of useless data. Many characteristics of the World Wide Web distinguish Web-based question answering from question answering on closed corpora such as newspaper texts. The Web is vastly larger in size and boasts incredible data redundancy, which renders it amenable to statistical techniques for answer extraction. A data-driven approach can yield high levels of performance and nicely complements traditional question answering techniques driven by information extraction. In addition to enormous amounts of unstructured text, the Web also contains pockets of structured and semistructured knowledge that can serve as a valuable resource for question answering. By organizing these resources and annotating them with natural language, we can successfully incorporate Web knowledge into question answering systems. This tutorial surveys recent Web-based question answering technology, focusing on two separate paradigms: knowledge mining using statistical tools and knowledge annotation using database concepts. Both approaches can employ a wide spectrum of techniques ranging in linguistic sophistication from simple bag-of-words treatments to full syntactic parsing.

2 Introduction Why question answering? Question answering provides intuitive information access Computers should respond to human information needs with just the right information What role does the World Wide Web play in question answering? The Web is an enormous store of human knowledge This knowledge is a valuable resource for question answering How can we effectively utilize the World Wide Web to answer natural language questions? QA Techniques for the WWW: Introduction Different Types of Questions What does Cog look like? Who directed Gone with the Wind? Gone with the Wind (1939) was directed by George Cukor, Victor Fleming, and Sam Wood. How many cars left the garage yesterday between noon and 1pm? What were the causes of the French Revolution? QA Techniques for the WWW: Introduction

3 Factoid Question Answering Modern systems are limited to answering factbased questions Answers are typically named-entities Who discovered Oxygen? When did Hawaii become a state? Where is Ayer s Rock located? What team won the World Series in 1992? Future systems will move towards harder questions, e.g., Why and how questions Questions that require simple inferences This tutorial focuses on using the Web to answer factoid questions QA Techniques for the WWW: Introduction Two Axes of Exploration Nature of the information What type of information is the system utilizing to answer natural language questions? Structured Knowledge (Databases) Unstructured Knowledge (Free text) Nature of the technique How linguistically sophisticated are the techniques employed to answer natural language questions? Linguistically Sophisticated (e.g., syntactic parsing) Linguistically Uninformed (e.g., n-gram generation) QA Techniques for the WWW: Introduction

4 Two Techniques for Web QA Knowledge Annotation Database Concepts nature of the technique Linguistically sophisticated nature of the information Structured Knowledge (Databases) Unstructured Knowledge (Free text) Linguistically uninformed Knowledge Mining Statistical tools QA Techniques for the WWW: Introduction Outline: Top-Level General Overview: Origins of Web-based Question Answering Knowledge Mining: techniques that effectively employ unstructured text on the Web for question answering Knowledge Annotation: techniques that effectively employ structured and semistructured sources on the Web for question answering QA Techniques for the WWW: Introduction

5 Outline: General Overview Short history of question answering Natural language interfaces to databases Blocks world Plans and scripts Modern question answering systems Question answering tracks at TREC Evaluation methodology Formal scoring metrics QA Techniques for the WWW: Introduction Outline: Knowledge Mining Overview How can we leverage the enormous quantities of unstructured text available on the Web for question answering? Leveraging data redundancy Survey of selected end-to-end systems Survey of selected knowledge mining techniques Challenges and potential solutions What are the limitations of data redundancy? How can linguistically-sophisticated techniques help? QA Techniques for the WWW: Introduction

6 Outline: Knowledge Annotation Overview How can we leverage structured and semistructured Web sources for question answering? START and Omnibase The first question answering system for the Web Other annotation-based systems Challenges and potential solutions Can research from related fields help? Can we discover structured data from free text? What role will the Semantic Web play? QA Techniques for the WWW: Introduction General Overview Question Answering Techniques for the World Wide Web

7 A Short History of QA Natural language interfaces to databases Blocks world Plans and scripts Emergence of the Web IR+IE-based QA and large-scale evaluation Re-discovery of the Web Overview: History of QA NL Interfaces to Databases Natural language interfaces to relational databases BASEBALL baseball statistics Who did the Red Sox lose to on July 5? On how many days in July did eight teams play? LUNAR analysis of lunar rocks What is the average concentration of aluminum in high alkali rocks? How many Brescias contain Olivine? LIFER personnel statistics [Green et al. 1961] [Woods et al. 1972] [Hendrix 1977ab] What is the average salary of math department secretaries? How many professors are there in the compsci department? Overview: History of QA

8 Typical Approaches Direct Translation: determine mapping rules between syntactic structures and database queries (e.g., LUNAR) S NP VP Det N V N (for_every X (is_rock X) (contains X magnesium) (printout X)) which rock contains magnesium Semantic Grammar: parse at the semantic level directly into database queries (e.g., LIFER) TOP PRESENT ITEM EMPLOYEE ATTRIBUTE NAME Overview: History of QA what is the salary of Martin Devine Properties of Early NL Systems Often brittle and not scalable Natural language understanding process was a mix of syntactic and semantic processing Domain knowledge was often embedded implicitly in the parser Narrow and restricted domain Users were often presumed to have some knowledge of underlying data tables Systems performed syntactic and semantic analysis of questions Discourse modeling (e.g., anaphora, ellipsis) is easier in a narrow domain Overview: History of QA
 TOP PRESENT ITEM EMPLOYEE ATTRIBUTE NAME Overview: History of QA what is the salary of Martin Devine Properties of Early NL Systems Often brittle and not scalable Natural language")
9 Blocks World Interaction with a robotic arm in a world filled with colored blocks [Winograd 1972] Not only answered questions, but also followed commands What is on top of the red brick? Is the blue cylinder larger than the one you are holding? Pick up the yellow brick underneath the green brick. The blocks world domain was a fertile ground for other research Near-miss learning Understanding line drawings [Winston 1975] [Waltz 1975] Acquisition of problem solving strategies [Sussman 1973] Overview: History of QA Plans and Scripts QUALM [Lehnert 1977,1981] Application of scripts and plans for story comprehension Very restrictive domain, e.g., restaurant scripts Implementation status uncertain difficult to separate discourse theory from working system UNIX Consultant [Wilensky 1982; Wilensky et al. 1989] Allowed users to interact with UNIX, e.g., ask How do I delete a file? User questions were translated into goals and matched with plans for achieving that goal: paradigm not suitable for general purpose question answering Effectiveness and scalability of approach is unknown due to lack of rigorous evaluation Overview: History of QA
![The blocks world domain was a fertile ground for other research Near-miss learning Understanding line drawings [Winston 1975] [Waltz 1975] Acquisition of problem solving strategies [Sussman 1973]](/docs-images/42/565831/images/page_9.jpg "Overview: History of QA Plans and Scripts QUALM [Lehnert 1977,1981] Application of scripts and plans for story comprehension Very restrictive domain, e.g.")
10 Emergence of the Web Before the Web Question answering systems had limited audience All knowledge had to be hand-coded and specially prepared With the Web Millions can access question answering services Question answering systems could take advantage of already-existing knowledge: virtual collaboration Overview: History of QA START MIT: [Katz 1988,1997; Katz et al. 2002a] The first question answering system for the World Wide Web On-line and continuously operating since 1993 Has answered millions of questions from hundreds of thousands of users all over the world Engages in virtual collaboration by utilizing knowledge freely available on the Web Introduced the knowledge annotation approach to question answering Overview: History of QA
![2002a] The first question answering system for the World Wide Web On-line and continuously operating since 1993 Has answered millions of questions from hundreds of thousands of users all over the](/docs-images/42/565831/images/page_10.jpg "world Engages in virtual collaboration by utilizing knowledge freely available on the Web Introduced the knowledge annotation approach to question answering http://www.ai.mit.")
11 Additional START Applications START is easily adaptable to different domains: Analogy/explanation-based learning Answering questions from the GRE [Winston et al. 1983] [Katz 1988] Answering questions in the JPL press room regarding the Voyager flyby of Neptune (1989) [Katz 1990] START Bosnia Server dedicated to the U.S. mission in Bosnia (1996) START Mars Server to inform the public about NASA s planetary missions (2001) START Museum Server for an ongoing exhibit at the MIT Museum (2001) Overview: History of QA START in Action Overview: History of QA
![1983] [Katz 1988] Answering questions in the JPL press room regarding the Voyager flyby of Neptune (1989) [Katz 1990] START Bosnia Server](/docs-images/42/565831/images/page_11.jpg "dedicated to the U.S.")
12 START in Action Overview: History of QA START in Action Overview: History of QA
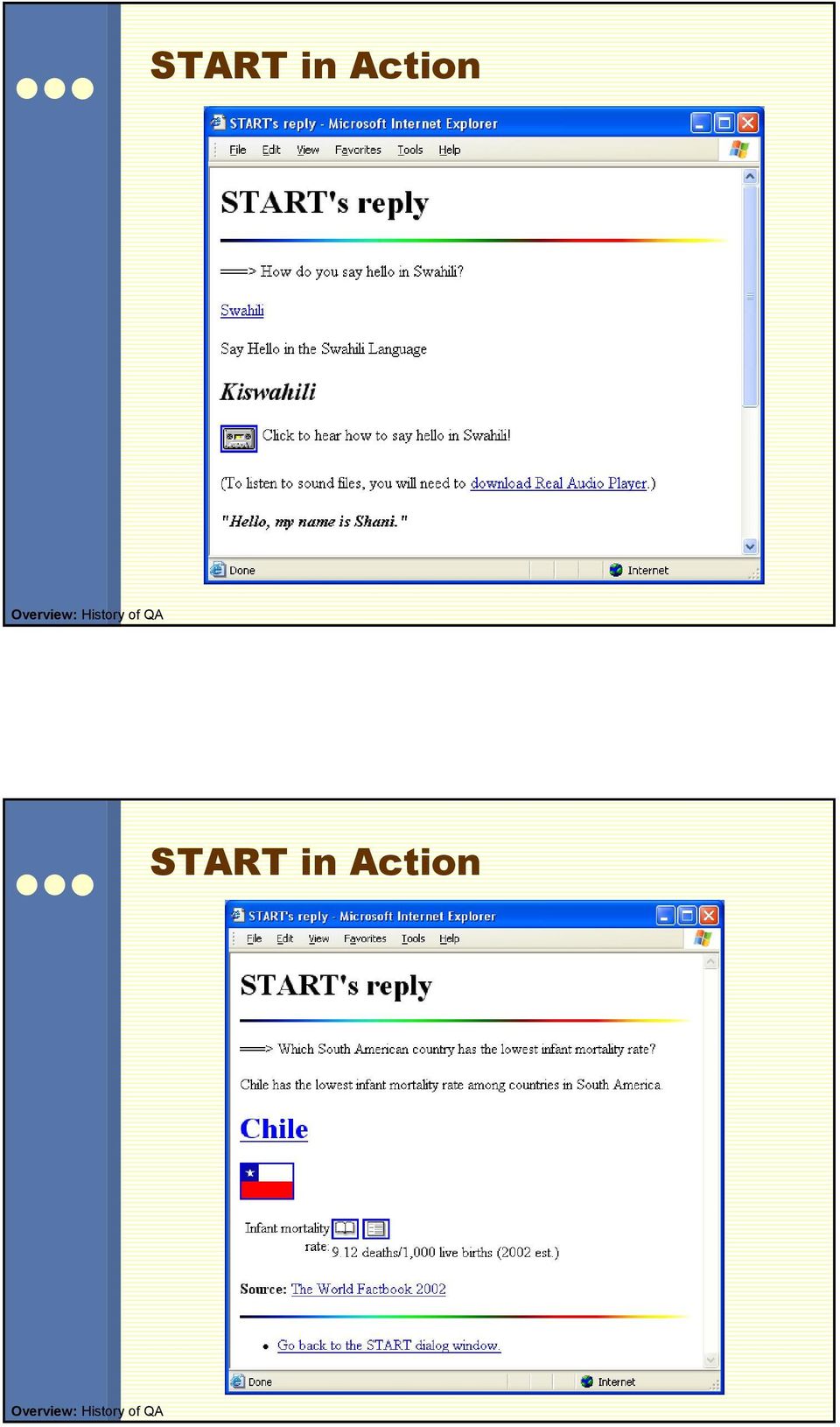
13 START in Action Overview: History of QA Related Strands: IR and IE Information retrieval has a long history Origins can be traced back to Vannevar Bush (1945) Active field since mid-1950s Primary focus on document retrieval Finer-grained IR: emergence of passage retrieval techniques in early 1990s Information extraction seeks to distill information from large numbers of documents Concerned with filling in pre-specified templates with participating entities Started in the late 1980s with the Message Understanding Conferences (MUCs) Overview: History of QA
 Overview:")
14 IR+IE-based QA Recent question answering systems are based on information retrieval and information extraction Answers are extracted from closed corpora, e.g., newspaper and encyclopedia articles Techniques range in sophistication from simple keyword matching to some parsing Formal, large-scale evaluations began with the TREC QA tracks Facilitated rapid dissemination of results and formation of a community Dramatically increased speed at which new techniques have been adopted Overview: History of QA Re-discovery of the Web IR+IE-based systems focus on answering questions from a closed corpus Artifact of the TREC setup Recently, researchers have discovered a wealth of resource on the Web Vast amounts of unstructured free text Pockets of structured and semistructured sources This is where we are today How can we effectively utilize the Web to answer natural language questions? Overview: History of QA

15 The Short Answer Knowledge Mining: techniques that effectively employ unstructured text on the Web for question answering Knowledge Annotation: techniques that effectively employ structured and semistructured sources on the Web for question answering Overview: History of QA General Overview: TREC Question Answering Tracks Question Answering Techniques for the World Wide Web

16 TREC QA Tracks Question answering track at the Text Retrieval Conference (TREC) Large-scale evaluation of question answering Sponsored by NIST (with later support from ARDA) Uses formal evaluation methodologies from information retrieval Formal evaluation is a part of a larger community process Overview: TREC QA The TREC Cycle Proceedings Publication Call for Participation Task Definition TREC Conference Document Procurement Results Analysis Topic Development Results Evaluation Relevance Assessments Evaluation Experiments Overview: TREC QA

17 TREC QA Tracks TREC-8 QA Track [Voorhees and Tice 1999,2000b] 200 questions: backformulations of the corpus Systems could return up to five answers answer = [ answer string, docid ] Two test conditions: 50-byte or 250-byte answer strings MRR scoring metric TREC-9 QA Track [Voorhees and Tice 2000a] 693 questions: from search engine logs Systems could return up to five answers answer = [ answer string, docid ] Two test conditions: 50-byte or 250-byte answer strings MRR scoring metric Overview: TREC QA TREC QA Tracks TREC 2001 QA Track [Voorhees 2001,2002a] 500 questions: from search engine logs Systems could return up to five answers answer = [ answer string, docid ] 50-byte answers only Approximately a quarter of the questions were definition questions (unintentional) TREC 2002 QA Track [Voorhees 2002b] 500 questions: from search engine logs Each system could only return one answer per question answer = [ exact answer string, docid ] All answers were sorted by decreasing confidence Introduction of exact answers and CWS metric Overview: TREC QA
![answer string, docid ] Two test conditions: 50-byte or 250-byte answer strings MRR scoring metric Overview: TREC QA TREC QA Tracks TREC 2001 QA Track [Voorhees 2001,2002a] 500 questions: from search](/docs-images/42/565831/images/page_17.jpg "engine logs Systems could return up to five answers answer = [ answer string, docid ] 50-byte answers only Approximately a quarter of the questions were definition questions (unintentional) TREC 2002")
18 Evaluation Metrics Mean Reciprocal Rank (MRR) (through TREC 2001) Reciprocal rank = inverse of rank at which first correct answer was found: {1, 0.5, 0.33, 0.25, 0.2, 0} MRR = average over all questions Judgments: correct, unsupported, incorrect Correct: answer string answers the question in a responsive fashion and is supported by the document Unsupported: answer string is correct but the document does not support the answer Incorrect: answer string does not answer the question Strict score: unsupported counts as incorrect Lenient score: unsupported counts as correct Overview: TREC QA Evaluation Metrics Confidence-Weighted Score (CWS) (TREC 2002) Evaluates how well systems know what they know Q c i=1 i / i i c = number of correct answers in first i questions Q Q = total number of questions Judgments: correct, unsupported, inexact, wrong Exact answers Mississippi the Mississippi the Mississippi River Mississippi River mississippi Inexact answers At 2,348 miles the Mississippi River is the longest river in the US. 2,348; Mississippi Missipp Overview: TREC QA
 (TREC 2002) Evaluates how well systems know what they know Q c i=1 i / i i c = number of correct answers in")
19 Knowledge Mining Question Answering Techniques for the World Wide Web Knowledge Mining: Overview Question Answering Techniques for the World Wide Web

20 Knowledge Mining Definition: techniques that effectively employ unstructured text on the Web for question answering Key Ideas: Leverage data redundancy Use simple statistical techniques to bridge question and answer gap Use linguistically-sophisticated techniques to improve answer quality Knowledge Mining: Overview Key Questions How is the Web different from a closed corpus? How can we quantify and leverage data redundancy? How can data-driven approaches help solve some NLP challenges? How do we make the most out of existing search engines? How can we effectively employ unstructured text on the Web for question answering? Knowledge Mining: Overview

21 Knowledge Mining nature of the technique Linguistically sophisticated nature of the information Structured Knowledge (Databases) Unstructured Knowledge (Free text) Linguistically uninformed Knowledge Mining Statistical tools Knowledge Mining: Overview Knowledge and Data Mining How is knowledge mining related to data mining? Knowledge Mining Data Mining Answers specific natural language questions Discovers interesting patterns and trends Benefits from wellspecified input and output Often suffers from vague goals Primarily utilizes textual sources Utilizes a variety of data from text to numerical databases Similarities: Both are driven by enormous quantities of data Both leverage statistical and data-driven techniques Knowledge Mining: Overview
22 Present and Future Current state of knowledge mining: Most research activity concentrated in the last two years Good performance using statistical techniques Future of knowledge mining: Build on statistical techniques Overcome brittleness of current natural language techniques Address remaining challenges with linguistic knowledge Selectively employ linguistic analysis: use it only in beneficial situations Knowledge Mining: Overview Origins of Knowledge Mining The origins of knowledge mining lie in information retrieval and information extraction Information Retrieval Document Retrieval Passage Retrieval Information Extraction IR+IE-based QA Knowledge Mining Traditional question answering on closed corpora Question answering using the Web Knowledge Mining: Overview
23 Traditional IR+IE-based QA NL question Question Analyzer IR Query Document Retriever Question Type Documents Passage Retriever Passages Answer Extractor Answers Knowledge Mining: Overview Traditional IR+IE-based QA Question Analyzer Determines expected answer type Generates query for IR engine Document Retriever Input = natural language question Input = IR query Narrows corpus down to a smaller set of potentially relevant documents Passage Retrieval Input = set of documents Narrows documents down to a set of passages for additional processing Answer Extractor Input = set of passages + question type Extracts the final answer to the question Typically matches entities from passages against the expected answer type May employ more linguistically-sophisticated processing Knowledge Mining: Overview
24 References: IR+IE-based QA General Survey [Hirschman and Gaizauskas 2001] Sample Systems Cymfony at TREC-8 Three-level information extraction architecture IBM at TREC-9 (and later versions) [Prager et al. 1999] Predictive annotations: perform named-entity detection at time of index creation FALCON (and later versions) [Harabagiu et al. 2000a] Employs question/answer logic unification and feedback loops Tutorials [Srihari and Li 1999] [Harabagiu and Moldovan 2001, 2002] Knowledge Mining: Overview Just Another Corpus? Is the Web just another corpus? Can we simply apply traditional IR+IE-based question answering techniques on the Web? Questions Questions Closed corpus (e.g., news articles)? The Web Answers Answers Knowledge Mining: Overview
25 Not Just Another Corpus The Web is qualitatively different from a closed corpus Many IR+IE-based question answering techniques will still be effective But we need a different set of techniques to capitalize on the Web as a document collection Knowledge Mining: Overview Size and Data Redundancy How big? Tens of terabytes? No agreed upon methodology to even measure it Google indexes over 3 billion Web pages (early 2003) Size introduces engineering issues Use existing search engines? Limited control over search results Crawl the Web? Very resource intensive Size gives rise to data redundancy Knowledge stated multiple times in multiple documents in multiple formulations Knowledge Mining: Overview
26 Other Considerations Poor quality of many individual pages Documents contain misspellings, incorrect grammar, wrong information, etc. Some Web pages aren t even documents (tables, lists of items, etc.): not amenable to named-entity extraction or parsing Heterogeneity Range in genre: encyclopedia articles vs. weblogs Range in objectivity: CNN articles vs. cult websites Range in document complexity: research journal papers vs. elementary school book reports Knowledge Mining: Overview Ways of Using the Web Use the Web as the primary corpus of information If needed, project answers onto another corpus (for verification purposes) Combine use of the Web with other corpora Employ Web data to supplement a primary corpus (e.g., collection of newspaper articles) Use the Web only for some questions Combine Web and non-web answers (e.g., weighted voting) Knowledge Mining: Overview
27 Capitalizing on Search Engines Data redundancy would be useless unless we could easily access all that data Leverage existing information retrieval infrastructure [Brin and Page 1998] The engineering task of indexing and retrieving terabyte-sized document collections has been solved Existing search engines are good enough Build systems on top of commercial search engines, e.g., Google, FAST, AltaVista, Teoma, etc. Question Question Analysis Web Search Engine Results Processing Answer Knowledge Mining: Overview Knowledge Mining: Leveraging Data Redundancy Question Answering Techniques for the World Wide Web
28 Leveraging Data Redundancy Take advantage of different reformulations The expressiveness of natural language allows us to say the same thing in multiple ways This poses a problem for question answering Question asked in one way When did Colorado become a state? How do we bridge these two? Answer stated in another way Colorado was admitted to the Union on August 1, With data redundancy, it is likely that answers will be stated in the same way the question was asked Cope with poor document quality When many documents are analyzed, wrong answers become noise Knowledge Mining: Leveraging Data Redundancy Leveraging Data Redundancy Data Redundancy = Surrogate for sophisticated NLP Obvious reformulations of questions can be easily found Who killed Abraham Lincoln? (1) John Wilkes Booth killed Abraham Lincoln. (2) John Wilkes Booth altered history with a bullet. He will forever be known as the man who ended Abraham Lincoln s life. When did Wilt Chamberlain score 100 points? (1) Wilt Chamberlain scored 100 points on March 2, 1962 against the New York Knicks. (2) On December 8, 1961, Wilt Chamberlain scored 78 points in a triple overtime game. It was a new NBA record, but Warriors coach Frank McGuire didn t expect it to last long, saying, He ll get 100 points someday. McGuire s prediction came true just a few months later in a game against the New York Knicks on March 2. Knowledge Mining: Leveraging Data Redundancy
29 Leveraging Data Redundancy Data Redundancy can overcome poor document quality Lots of wrong answers, but even more correct answers What s the rainiest place in the world? (1) Blah blah Seattle blah blah Hawaii blah blah blah blah blah blah (2) Blah Sahara Desert blah blah blah blah blah blah blah Amazon (3) Blah blah blah blah blah blah blah Mount Waiale'ale in Hawaii blah (4) Blah blah blah Hawaii blah blah blah blah Amazon blah blah (5) Blah Mount Waiale'ale blah blah blah blah blah blah blah blah blah What is the furthest planet in the Solar System? (1) Blah Pluto blah blah blah blah Planet X blah blah (2) Blah blah blah blah Pluto blah blah blah blah blah blah blah blah (3) Blah blah blah Planet X blah blah blah blah blah blah blah Pluto (4) Blah Pluto blah blah blah blah blah blah blah blah Pluto blah blah Knowledge Mining: Leveraging Data Redundancy General Principles Match answers using surface patterns Apply regular expressions over textual snippets to extract answers Bypass linguistically sophisticated techniques, e.g., parsing Rely on statistics and data redundancy Expect many occurrences of the answer mixed in with many occurrences of wrong, misleading, or lower quality answers Develop techniques for filtering, sorting large numbers of candidates Can we quantify data redundancy? Knowledge Mining: Leveraging Data Redundancy
30 Leveraging Massive Data Sets [Banko and Brill 2001] Grammar Correction: {two, to, too} {principle, principal} Knowledge Mining: Leveraging Data Redundancy Observations: Banko and Brill For some applications, learning technique is less important than amount of training data In the limit (i.e., infinite data), performance of different algorithms converges It doesn t matter if the data is (somewhat) noisy Why compare performance of learning algorithms on (relatively) small corpora? In many applications, data is free! Throwing more data at a problem is sometimes the easiest solution (hence, we should try it first) Knowledge Mining: Leveraging Data Redundancy
31 Effects of Data Redundancy [Breck et al. 2001; Light et al. 2001] Are questions with more answer occurrences easier? Examined the effect of answer occurrences on question answering performance (on TREC-8 results) ~27% of systems produced a correct answer for questions with 1 answer occurrence. ~50% of systems produced a correct answer for questions with 7 answer occurrences. Knowledge Mining: Leveraging Data Redundancy Effects of Data Redundancy [Clarke et al. 2001a] How does corpus size affect performance? Selected 87 people questions from TREC-9; Tested effect of corpus size on passage retrieval algorithm (using 100GB TREC Web Corpus) Conclusion: having more data improves performance Knowledge Mining: Leveraging Data Redundancy
32 Effects of Data Redundancy [Dumais et al. 2002] How many search engine results should be used? Plotted performance of a question answering system against the number of search engine snippets used Performance drops as too many irrelevant results get returned # Snippets MRR MRR as a function of number of snippets returned from the search engine. (TREC-9, q ) Knowledge Mining: Leveraging Data Redundancy Knowledge Mining: System Survey Question Answering Techniques for the World Wide Web
33 Knowledge Mining: Systems Ionaut (AT&T Research) MULDER (University of Washington) AskMSR (Microsoft Research) InsightSoft-M (Moscow, Russia) MultiText (University of Waterloo) Shapaqa (Tilburg University) Aranea (MIT) TextMap (USC/ISI) LAMP (National University of Singapore) NSIR (University of Michigan) PRIS (National University of Singapore) AnswerBus (University of Michigan) Knowledge Mining: System Survey Selected systems, apologies for any omissions Generic System NL question Question Analyzer Automatically learned or manually encoded Surface patterns Web Query Web Interface Question Type Snippets Redundancy-based modules Web Answers Answer Projection TREC Answers Knowledge Mining: System Survey
34 Common Techniques Match answers using surface patterns Apply regular expressions over textual snippets to extract answers Surface patterns may also help in generating queries; they are either learned automatically or entered manually Leverage statistics and multiple answer occurrences Generate n-grams from snippets Vote, tile, filter, etc. Apply information extraction technology Ensure that candidates match expected answer type Knowledge Mining: System Survey Ionaut AT&T Research: [Abney et al. 2000] Application of IR+IE-based question answering paradigm on documents gathered from a Web crawl Passage Retrieval Entity Extraction Entity Classification Query Classification Entity Ranking Knowledge Mining: System Survey
35 Ionaut: Overview Passage Retrieval SMART IR System [Salton 1971; Buckley and Lewit 1985] Segment documents into three-sentence passages Entity Extraction Cass partial parser [Abney 1996] Entity Classification Proper names: person, location, organization Dates Quantities Durations, linear measures Knowledge Mining: System Survey Ionaut: Overview Query Classification: 8 hand-crafted rules Who, whom Person Where, whence, whither Location When Date And other simple rules Criteria for Entity Ranking: Match between query classification and entity classification Frequency of entity Position of entity within retrieved passages Knowledge Mining: System Survey
36 Ionaut: Evaluation End-to-end performance: TREC-8 (informal) Exact answer: 46% answer in top 5, MRR 50-byte: 39% answer in top 5, MRR 250-byte: 68% answer in top 5, MRR Error analysis Good performance on person, location, date, and quantity (60%) Poor performance on other types Knowledge Mining: System Survey MULDER U. Washington: [Kwok et al. 2001] Question Parsing MEI PC-Kimmo Query Formulation Original Question Parse Trees Question Classification Query Formulation Rules Quote NP PC-Kimmo Search Engine Queries Search Engine Link Parser WordNet Classification Rules T-form Grammar Web Pages Answer Answer Selection Final Ballot Clustering Scoring Candidate Answers Answer Extraction Match Phrase Type NLP Parser Summary Extraction + Scoring Knowledge Mining: System Survey
37 MULDER: Parsing Question Parsing Maximum Entropy Parser (MEI) PC-KIMMO for tagging of unknown words Question Classification Link Parser [Sleator and Temperly 1991,1993] [Charniak 1999] [Antworth 1999] Manually encoded rules (e.g., How ADJ = measure) WordNet (e.g., find hypernyms of object) Knowledge Mining: System Survey MULDER: Querying Query Formulation Query expansion (use attribute nouns in WordNet) How tall is Mt. Everest the height of Mt. Everest is Tokenization question answering question answering Transformations Who was the first American in space was the first American in Space, the first American in space was Who shot JFK shot JFK When did Nixon visit China Nixon visited China Search Engine: submit results to Google Knowledge Mining: System Survey
38 MULDER: Answer Extraction Answer Extraction: extract summaries directly from Web pages Locate regions with keywords Score regions by keyword density and keyword idf values Select top regions and parse them with MEI Extract phrases of the expected answer type Answer Selection: score candidates based on Simple frequency voting Closeness to keywords in the neighborhood Knowledge Mining: System Survey MULDER: Evaluation Evaluation on TREC-8 (200 questions) Did not use MRR metric: results not directly comparable User effort : how much text users must read in order to find the correct answer Knowledge Mining: System Survey
39 AskMSR [Brill et al. 2001; Banko et al. 2002; Brill et al. 2002] AskMSR-A {ans A1, ans A2,, ans AM } Question System Combination AskMSR-B {ans B1, ans B2,, ans BN } {ans 1, ans 2,, ans 5 } Query Reformulator Harvest Engine Answer Filtering Answer Tiling Answer Projection Search Engine [ans 1, docid 1 ] [ans 2, docid 2 ] [ans 3, docid 3 ] [ans 4, docid 4 ] NIL Knowledge Mining: System Survey AskMSR: N-Gram Harvesting Use text patterns derived from question to extract sequences of tokens that are likely to contain the answer Question: Who is Bill Gates married to? Look five tokens to the right < Bill Gates is married to, right, 5>... It is now the largest software company in the world. Today, Bill Gates is married to co-worker Melinda French. They live together in a house in the Redmond I also found out that Bill Gates is married to Melinda French Gates and they have a daughter named Jennifer Katharine Gates and a son named Rory John Gates. I of Microsoft, and they both developed Microsoft. * Presently Bill Gates is married to Melinda French Gates. They have two children: a daughter, Jennifer, and a... Generate N-Grams from Google summary snippets (bypassing original Web pages) co-worker, co-worker Melinda, co-worker Melinda French, Melinda, Melinda French, Melinda French they, French, French they, French they live Knowledge Mining: System Survey
Data-Intensive Question Answering
 Data-Intensive Question Answering Eric Brill, Jimmy Lin, Michele Banko, Susan Dumais and Andrew Ng Microsoft Research One Microsoft Way Redmond, WA 98052 {brill, mbanko, sdumais}@microsoft.com jlin@ai.mit.edu;
Data-Intensive Question Answering Eric Brill, Jimmy Lin, Michele Banko, Susan Dumais and Andrew Ng Microsoft Research One Microsoft Way Redmond, WA 98052 {brill, mbanko, sdumais}@microsoft.com jlin@ai.mit.edu;
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
TREC 2003 Question Answering Track at CAS-ICT
 TREC 2003 Question Answering Track at CAS-ICT Yi Chang, Hongbo Xu, Shuo Bai Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China changyi@software.ict.ac.cn http://www.ict.ac.cn/
TREC 2003 Question Answering Track at CAS-ICT Yi Chang, Hongbo Xu, Shuo Bai Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China changyi@software.ict.ac.cn http://www.ict.ac.cn/
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System
 Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Question Answering and Multilingual CLEF 2008
 Dublin City University at QA@CLEF 2008 Sisay Fissaha Adafre Josef van Genabith National Center for Language Technology School of Computing, DCU IBM CAS Dublin sadafre,josef@computing.dcu.ie Abstract We
Dublin City University at QA@CLEF 2008 Sisay Fissaha Adafre Josef van Genabith National Center for Language Technology School of Computing, DCU IBM CAS Dublin sadafre,josef@computing.dcu.ie Abstract We
Question Answering for Dutch: Simple does it
 Question Answering for Dutch: Simple does it Arjen Hoekstra Djoerd Hiemstra Paul van der Vet Theo Huibers Faculty of Electrical Engineering, Mathematics and Computer Science, University of Twente, P.O.
Question Answering for Dutch: Simple does it Arjen Hoekstra Djoerd Hiemstra Paul van der Vet Theo Huibers Faculty of Electrical Engineering, Mathematics and Computer Science, University of Twente, P.O.
Term extraction for user profiling: evaluation by the user
 Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Domain Adaptive Relation Extraction for Big Text Data Analytics. Feiyu Xu
 Domain Adaptive Relation Extraction for Big Text Data Analytics Feiyu Xu Outline! Introduction to relation extraction and its applications! Motivation of domain adaptation in big text data analytics! Solutions!
Domain Adaptive Relation Extraction for Big Text Data Analytics Feiyu Xu Outline! Introduction to relation extraction and its applications! Motivation of domain adaptation in big text data analytics! Solutions!
Interactive Dynamic Information Extraction
 Interactive Dynamic Information Extraction Kathrin Eichler, Holmer Hemsen, Markus Löckelt, Günter Neumann, and Norbert Reithinger Deutsches Forschungszentrum für Künstliche Intelligenz - DFKI, 66123 Saarbrücken
Interactive Dynamic Information Extraction Kathrin Eichler, Holmer Hemsen, Markus Löckelt, Günter Neumann, and Norbert Reithinger Deutsches Forschungszentrum für Künstliche Intelligenz - DFKI, 66123 Saarbrücken
Web-Based Question Answering: A Decision-Making Perspective
 UAI2003 AZARI ET AL. 11 Web-Based Question Answering: A Decision-Making Perspective David Azari Eric Horvitz Susan Dumais Eric Brill University of Washington Microsoft Research Microsoft Research Microsoft
UAI2003 AZARI ET AL. 11 Web-Based Question Answering: A Decision-Making Perspective David Azari Eric Horvitz Susan Dumais Eric Brill University of Washington Microsoft Research Microsoft Research Microsoft
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework
 Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Toward a Question Answering Roadmap
 Toward a Question Answering Roadmap Mark T. Maybury 1 The MITRE Corporation 202 Burlington Road Bedford, MA 01730 maybury@mitre.org Abstract Growth in government investment, academic research, and commercial
Toward a Question Answering Roadmap Mark T. Maybury 1 The MITRE Corporation 202 Burlington Road Bedford, MA 01730 maybury@mitre.org Abstract Growth in government investment, academic research, and commercial
Web Mining. Margherita Berardi LACAM. Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it
 Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Statistical Machine Translation
 Statistical Machine Translation Some of the content of this lecture is taken from previous lectures and presentations given by Philipp Koehn and Andy Way. Dr. Jennifer Foster National Centre for Language
Statistical Machine Translation Some of the content of this lecture is taken from previous lectures and presentations given by Philipp Koehn and Andy Way. Dr. Jennifer Foster National Centre for Language
So today we shall continue our discussion on the search engines and web crawlers. (Refer Slide Time: 01:02)
") Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Collecting Polish German Parallel Corpora in the Internet
 Proceedings of the International Multiconference on ISSN 1896 7094 Computer Science and Information Technology, pp. 285 292 2007 PIPS Collecting Polish German Parallel Corpora in the Internet Monika Rosińska
Proceedings of the International Multiconference on ISSN 1896 7094 Computer Science and Information Technology, pp. 285 292 2007 PIPS Collecting Polish German Parallel Corpora in the Internet Monika Rosińska
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
A Framework-based Online Question Answering System. Oliver Scheuer, Dan Shen, Dietrich Klakow
 A Framework-based Online Question Answering System Oliver Scheuer, Dan Shen, Dietrich Klakow Outline General Structure for Online QA System Problems in General Structure Framework-based Online QA system
A Framework-based Online Question Answering System Oliver Scheuer, Dan Shen, Dietrich Klakow Outline General Structure for Online QA System Problems in General Structure Framework-based Online QA system
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR
 Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Wikipedia and Web document based Query Translation and Expansion for Cross-language IR Ling-Xiang Tang 1, Andrew Trotman 2, Shlomo Geva 1, Yue Xu 1 1Faculty of Science and Technology, Queensland University
Why is Internal Audit so Hard?
 Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
Why is Internal Audit so Hard? 2 2014 Why is Internal Audit so Hard? 3 2014 Why is Internal Audit so Hard? Waste Abuse Fraud 4 2014 Waves of Change 1 st Wave Personal Computers Electronic Spreadsheets
MAN VS. MACHINE. How IBM Built a Jeopardy! Champion. 15.071x The Analytics Edge
 MAN VS. MACHINE How IBM Built a Jeopardy! Champion 15.071x The Analytics Edge A Grand Challenge In 2004, IBM Vice President Charles Lickel and coworkers were having dinner at a restaurant All of a sudden,
MAN VS. MACHINE How IBM Built a Jeopardy! Champion 15.071x The Analytics Edge A Grand Challenge In 2004, IBM Vice President Charles Lickel and coworkers were having dinner at a restaurant All of a sudden,
Timeline (1) Text Mining 2004-2005 Master TKI. Timeline (2) Timeline (3) Overview. What is Text Mining?
 Text Mining 2004-2005 Master TKI. Timeline (2) Timeline (3) Overview. What is Text Mining?") Text Mining 2004-2005 Master TKI Antal van den Bosch en Walter Daelemans http://ilk.uvt.nl/~antalb/textmining/ Dinsdag, 10.45-12.30, SZ33 Timeline (1) [1 februari 2005] Introductie (WD) [15 februari 2005]
Text Mining 2004-2005 Master TKI Antal van den Bosch en Walter Daelemans http://ilk.uvt.nl/~antalb/textmining/ Dinsdag, 10.45-12.30, SZ33 Timeline (1) [1 februari 2005] Introductie (WD) [15 februari 2005]
Flattening Enterprise Knowledge
 Flattening Enterprise Knowledge Do you Control Your Content or Does Your Content Control You? 1 Executive Summary: Enterprise Content Management (ECM) is a common buzz term and every IT manager knows it
Flattening Enterprise Knowledge Do you Control Your Content or Does Your Content Control You? 1 Executive Summary: Enterprise Content Management (ECM) is a common buzz term and every IT manager knows it
The Prolog Interface to the Unstructured Information Management Architecture
 The Prolog Interface to the Unstructured Information Management Architecture Paul Fodor 1, Adam Lally 2, David Ferrucci 2 1 Stony Brook University, Stony Brook, NY 11794, USA, pfodor@cs.sunysb.edu 2 IBM
The Prolog Interface to the Unstructured Information Management Architecture Paul Fodor 1, Adam Lally 2, David Ferrucci 2 1 Stony Brook University, Stony Brook, NY 11794, USA, pfodor@cs.sunysb.edu 2 IBM
Optimization of Internet Search based on Noun Phrases and Clustering Techniques
 Optimization of Internet Search based on Noun Phrases and Clustering Techniques R. Subhashini Research Scholar, Sathyabama University, Chennai-119, India V. Jawahar Senthil Kumar Assistant Professor, Anna
Optimization of Internet Search based on Noun Phrases and Clustering Techniques R. Subhashini Research Scholar, Sathyabama University, Chennai-119, India V. Jawahar Senthil Kumar Assistant Professor, Anna
The University of Washington s UW CLMA QA System
 The University of Washington s UW CLMA QA System Dan Jinguji, William Lewis,EfthimisN.Efthimiadis, Joshua Minor, Albert Bertram, Shauna Eggers, Joshua Johanson,BrianNisonger,PingYu, and Zhengbo Zhou Computational
The University of Washington s UW CLMA QA System Dan Jinguji, William Lewis,EfthimisN.Efthimiadis, Joshua Minor, Albert Bertram, Shauna Eggers, Joshua Johanson,BrianNisonger,PingYu, and Zhengbo Zhou Computational
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
3 Paraphrase Acquisition. 3.1 Overview. 2 Prior Work
 Unsupervised Paraphrase Acquisition via Relation Discovery Takaaki Hasegawa Cyberspace Laboratories Nippon Telegraph and Telephone Corporation 1-1 Hikarinooka, Yokosuka, Kanagawa 239-0847, Japan hasegawa.takaaki@lab.ntt.co.jp
Unsupervised Paraphrase Acquisition via Relation Discovery Takaaki Hasegawa Cyberspace Laboratories Nippon Telegraph and Telephone Corporation 1-1 Hikarinooka, Yokosuka, Kanagawa 239-0847, Japan hasegawa.takaaki@lab.ntt.co.jp
Optimization of Search Results with Duplicate Page Elimination using Usage Data A. K. Sharma 1, Neelam Duhan 2 1, 2
 Optimization of Search Results with Duplicate Page Elimination using Usage Data A. K. Sharma 1, Neelam Duhan 2 1, 2 Department of Computer Engineering, YMCA University of Science & Technology, Faridabad,
Optimization of Search Results with Duplicate Page Elimination using Usage Data A. K. Sharma 1, Neelam Duhan 2 1, 2 Department of Computer Engineering, YMCA University of Science & Technology, Faridabad,
Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval
 Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval Yih-Chen Chang and Hsin-Hsi Chen Department of Computer Science and Information
Approaches of Using a Word-Image Ontology and an Annotated Image Corpus as Intermedia for Cross-Language Image Retrieval Yih-Chen Chang and Hsin-Hsi Chen Department of Computer Science and Information
Incorporating Window-Based Passage-Level Evidence in Document Retrieval
 Incorporating -Based Passage-Level Evidence in Document Retrieval Wensi Xi, Richard Xu-Rong, Christopher S.G. Khoo Center for Advanced Information Systems School of Applied Science Nanyang Technological
Incorporating -Based Passage-Level Evidence in Document Retrieval Wensi Xi, Richard Xu-Rong, Christopher S.G. Khoo Center for Advanced Information Systems School of Applied Science Nanyang Technological
ifinder ENTERPRISE SEARCH
 DATA SHEET ifinder ENTERPRISE SEARCH ifinder - the Enterprise Search solution for company-wide information search, information logistics and text mining. CUSTOMER QUOTE IntraFind stands for high quality
DATA SHEET ifinder ENTERPRISE SEARCH ifinder - the Enterprise Search solution for company-wide information search, information logistics and text mining. CUSTOMER QUOTE IntraFind stands for high quality
Natural Language to Relational Query by Using Parsing Compiler
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Putting IBM Watson to Work In Healthcare
 Martin S. Kohn, MD, MS, FACEP, FACPE Chief Medical Scientist, Care Delivery Systems IBM Research marty.kohn@us.ibm.com Putting IBM Watson to Work In Healthcare 2 SB 1275 Medical data in an electronic or
Martin S. Kohn, MD, MS, FACEP, FACPE Chief Medical Scientist, Care Delivery Systems IBM Research marty.kohn@us.ibm.com Putting IBM Watson to Work In Healthcare 2 SB 1275 Medical data in an electronic or
Removing Web Spam Links from Search Engine Results
 Removing Web Spam Links from Search Engine Results Manuel EGELE pizzaman@iseclab.org, 1 Overview Search Engine Optimization and definition of web spam Motivation Approach Inferring importance of features
Removing Web Spam Links from Search Engine Results Manuel EGELE pizzaman@iseclab.org, 1 Overview Search Engine Optimization and definition of web spam Motivation Approach Inferring importance of features
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata
 Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Generating SQL Queries Using Natural Language Syntactic Dependencies and Metadata Alessandra Giordani and Alessandro Moschitti Department of Computer Science and Engineering University of Trento Via Sommarive
Web Data Management - Some Issues
 Web Data Management - Some Issues Properties of Web Data Lack of a schema Data is at best semi-structured Missing data, additional attributes, similar data but not identical Volatility Changes frequently
Web Data Management - Some Issues Properties of Web Data Lack of a schema Data is at best semi-structured Missing data, additional attributes, similar data but not identical Volatility Changes frequently
» A Hardware & Software Overview. Eli M. Dow <emdow@us.ibm.com:>
 » A Hardware & Software Overview Eli M. Dow Overview:» Hardware» Software» Questions 2011 IBM Corporation Early implementations of Watson ran on a single processor where it took 2 hours
» A Hardware & Software Overview Eli M. Dow Overview:» Hardware» Software» Questions 2011 IBM Corporation Early implementations of Watson ran on a single processor where it took 2 hours
Big Data: Rethinking Text Visualization
 Big Data: Rethinking Text Visualization Dr. Anton Heijs anton.heijs@treparel.com Treparel April 8, 2013 Abstract In this white paper we discuss text visualization approaches and how these are important
Big Data: Rethinking Text Visualization Dr. Anton Heijs anton.heijs@treparel.com Treparel April 8, 2013 Abstract In this white paper we discuss text visualization approaches and how these are important
Mining Opinion Features in Customer Reviews
 Mining Opinion Features in Customer Reviews Minqing Hu and Bing Liu Department of Computer Science University of Illinois at Chicago 851 South Morgan Street Chicago, IL 60607-7053 {mhu1, liub}@cs.uic.edu
Mining Opinion Features in Customer Reviews Minqing Hu and Bing Liu Department of Computer Science University of Illinois at Chicago 851 South Morgan Street Chicago, IL 60607-7053 {mhu1, liub}@cs.uic.edu
Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg
 Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg March 1, 2007 The catalogue is organized into sections of (1) obligatory modules ( Basismodule ) that
Module Catalogue for the Bachelor Program in Computational Linguistics at the University of Heidelberg March 1, 2007 The catalogue is organized into sections of (1) obligatory modules ( Basismodule ) that
Question Prediction Language Model
 Proceedings of the Australasian Language Technology Workshop 2007, pages 92-99 Question Prediction Language Model Luiz Augusto Pizzato and Diego Mollá Centre for Language Technology Macquarie University
Proceedings of the Australasian Language Technology Workshop 2007, pages 92-99 Question Prediction Language Model Luiz Augusto Pizzato and Diego Mollá Centre for Language Technology Macquarie University
Anotaciones semánticas: unidades de busqueda del futuro?
 Anotaciones semánticas: unidades de busqueda del futuro? Hugo Zaragoza, Yahoo! Research, Barcelona Jornadas MAVIR Madrid, Nov.07 Document Understanding Cartoon our work! Complexity of Document Understanding
Anotaciones semánticas: unidades de busqueda del futuro? Hugo Zaragoza, Yahoo! Research, Barcelona Jornadas MAVIR Madrid, Nov.07 Document Understanding Cartoon our work! Complexity of Document Understanding
Multi language e Discovery Three Critical Steps for Litigating in a Global Economy
 Multi language e Discovery Three Critical Steps for Litigating in a Global Economy 2 3 5 6 7 Introduction e Discovery has become a pressure point in many boardrooms. Companies with international operations
Multi language e Discovery Three Critical Steps for Litigating in a Global Economy 2 3 5 6 7 Introduction e Discovery has become a pressure point in many boardrooms. Companies with international operations
Get the most value from your surveys with text analysis
 PASW Text Analytics for Surveys 3.0 Specifications Get the most value from your surveys with text analysis The words people use to answer a question tell you a lot about what they think and feel. That
PASW Text Analytics for Surveys 3.0 Specifications Get the most value from your surveys with text analysis The words people use to answer a question tell you a lot about what they think and feel. That
Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words
 , pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
, pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
Machine Learning Approach To Augmenting News Headline Generation
 Machine Learning Approach To Augmenting News Headline Generation Ruichao Wang Dept. of Computer Science University College Dublin Ireland rachel@ucd.ie John Dunnion Dept. of Computer Science University
Machine Learning Approach To Augmenting News Headline Generation Ruichao Wang Dept. of Computer Science University College Dublin Ireland rachel@ucd.ie John Dunnion Dept. of Computer Science University
Text Analytics with Ambiverse. Text to Knowledge. www.ambiverse.com
 Text Analytics with Ambiverse Text to Knowledge www.ambiverse.com Version 1.0, February 2016 WWW.AMBIVERSE.COM Contents 1 Ambiverse: Text to Knowledge............................... 5 1.1 Text is all Around
Text Analytics with Ambiverse Text to Knowledge www.ambiverse.com Version 1.0, February 2016 WWW.AMBIVERSE.COM Contents 1 Ambiverse: Text to Knowledge............................... 5 1.1 Text is all Around
Brill s rule-based PoS tagger
 Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
Introduction to Information Retrieval
 Introduction to Information Retrieval Christof Monz and Maarten de Rijke Spring 2002 Introduction to Information Retrieval, Spring 2002, Week 1 Copyright c Christof Monz & Maarten de Rijke 1 Today s Program
Introduction to Information Retrieval Christof Monz and Maarten de Rijke Spring 2002 Introduction to Information Retrieval, Spring 2002, Week 1 Copyright c Christof Monz & Maarten de Rijke 1 Today s Program
Mining Text Data: An Introduction
 Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
Bölüm 10. Metin ve WEB Madenciliği http://ceng.gazi.edu.tr/~ozdemir Mining Text Data: An Introduction Data Mining / Knowledge Discovery Structured Data Multimedia Free Text Hypertext HomeLoan ( Frank Rizzo
How To Write A Summary Of A Review
 PRODUCT REVIEW RANKING SUMMARIZATION N.P.Vadivukkarasi, Research Scholar, Department of Computer Science, Kongu Arts and Science College, Erode. Dr. B. Jayanthi M.C.A., M.Phil., Ph.D., Associate Professor,
PRODUCT REVIEW RANKING SUMMARIZATION N.P.Vadivukkarasi, Research Scholar, Department of Computer Science, Kongu Arts and Science College, Erode. Dr. B. Jayanthi M.C.A., M.Phil., Ph.D., Associate Professor,
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 ISSN 2229-5518
 International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 INTELLIGENT MULTIDIMENSIONAL DATABASE INTERFACE Mona Gharib Mohamed Reda Zahraa E. Mohamed Faculty of Science,
International Journal of Scientific & Engineering Research, Volume 4, Issue 11, November-2013 5 INTELLIGENT MULTIDIMENSIONAL DATABASE INTERFACE Mona Gharib Mohamed Reda Zahraa E. Mohamed Faculty of Science,
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
HELP DESK SYSTEMS. Using CaseBased Reasoning
 HELP DESK SYSTEMS Using CaseBased Reasoning Topics Covered Today What is Help-Desk? Components of HelpDesk Systems Types Of HelpDesk Systems Used Need for CBR in HelpDesk Systems GE Helpdesk using ReMind
HELP DESK SYSTEMS Using CaseBased Reasoning Topics Covered Today What is Help-Desk? Components of HelpDesk Systems Types Of HelpDesk Systems Used Need for CBR in HelpDesk Systems GE Helpdesk using ReMind
Text Analytics. A business guide
 Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
PiQASso: Pisa Question Answering System
 PiQASso: Pisa Question Answering System Giuseppe Attardi, Antonio Cisternino, Francesco Formica, Maria Simi, Alessandro Tommasi Dipartimento di Informatica, Università di Pisa, Italy {attardi, cisterni,
PiQASso: Pisa Question Answering System Giuseppe Attardi, Antonio Cisternino, Francesco Formica, Maria Simi, Alessandro Tommasi Dipartimento di Informatica, Università di Pisa, Italy {attardi, cisterni,
Real-Time Identification of MWE Candidates in Databases from the BNC and the Web
 Real-Time Identification of MWE Candidates in Databases from the BNC and the Web Identifying and Researching Multi-Word Units British Association for Applied Linguistics Corpus Linguistics SIG Oxford Text
Real-Time Identification of MWE Candidates in Databases from the BNC and the Web Identifying and Researching Multi-Word Units British Association for Applied Linguistics Corpus Linguistics SIG Oxford Text
Connecting library content using data mining and text analytics on structured and unstructured data
 Submitted on: May 5, 2013 Connecting library content using data mining and text analytics on structured and unstructured data Chee Kiam Lim Technology and Innovation, National Library Board, Singapore.
Submitted on: May 5, 2013 Connecting library content using data mining and text analytics on structured and unstructured data Chee Kiam Lim Technology and Innovation, National Library Board, Singapore.
Detecting Parser Errors Using Web-based Semantic Filters
 Detecting Parser Errors Using Web-based Semantic Filters Alexander Yates Stefan Schoenmackers University of Washington Computer Science and Engineering Box 352350 Seattle, WA 98195-2350 Oren Etzioni {ayates,
Detecting Parser Errors Using Web-based Semantic Filters Alexander Yates Stefan Schoenmackers University of Washington Computer Science and Engineering Box 352350 Seattle, WA 98195-2350 Oren Etzioni {ayates,
Predicting the Stock Market with News Articles
 Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Domain Classification of Technical Terms Using the Web
 Systems and Computers in Japan, Vol. 38, No. 14, 2007 Translated from Denshi Joho Tsushin Gakkai Ronbunshi, Vol. J89-D, No. 11, November 2006, pp. 2470 2482 Domain Classification of Technical Terms Using
Systems and Computers in Japan, Vol. 38, No. 14, 2007 Translated from Denshi Joho Tsushin Gakkai Ronbunshi, Vol. J89-D, No. 11, November 2006, pp. 2470 2482 Domain Classification of Technical Terms Using
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Effective Self-Training for Parsing
 Effective Self-Training for Parsing David McClosky dmcc@cs.brown.edu Brown Laboratory for Linguistic Information Processing (BLLIP) Joint work with Eugene Charniak and Mark Johnson David McClosky - dmcc@cs.brown.edu
Effective Self-Training for Parsing David McClosky dmcc@cs.brown.edu Brown Laboratory for Linguistic Information Processing (BLLIP) Joint work with Eugene Charniak and Mark Johnson David McClosky - dmcc@cs.brown.edu
Enhancing the relativity between Content, Title and Meta Tags Based on Term Frequency in Lexical and Semantic Aspects
 Enhancing the relativity between Content, Title and Meta Tags Based on Term Frequency in Lexical and Semantic Aspects Mohammad Farahmand, Abu Bakar MD Sultan, Masrah Azrifah Azmi Murad, Fatimah Sidi me@shahroozfarahmand.com
Enhancing the relativity between Content, Title and Meta Tags Based on Term Frequency in Lexical and Semantic Aspects Mohammad Farahmand, Abu Bakar MD Sultan, Masrah Azrifah Azmi Murad, Fatimah Sidi me@shahroozfarahmand.com
1 o Semestre 2007/2008
 Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Outline 1 2 3 4 5 Outline 1 2 3 4 5 Exploiting Text How is text exploited? Two main directions Extraction Extraction
Large-Scale Test Mining
 Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
Large-Scale Test Mining SIAM Conference on Data Mining Text Mining 2010 Alan Ratner Northrop Grumman Information Systems NORTHROP GRUMMAN PRIVATE / PROPRIETARY LEVEL I Aim Identify topic and language/script/coding
A Comparative Study on Sentiment Classification and Ranking on Product Reviews
 A Comparative Study on Sentiment Classification and Ranking on Product Reviews C.EMELDA Research Scholar, PG and Research Department of Computer Science, Nehru Memorial College, Putthanampatti, Bharathidasan
A Comparative Study on Sentiment Classification and Ranking on Product Reviews C.EMELDA Research Scholar, PG and Research Department of Computer Science, Nehru Memorial College, Putthanampatti, Bharathidasan
NATURAL LANGUAGE TO SQL CONVERSION SYSTEM
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) ISSN 2249-6831 Vol. 3, Issue 2, Jun 2013, 161-166 TJPRC Pvt. Ltd. NATURAL LANGUAGE TO SQL CONVERSION
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) ISSN 2249-6831 Vol. 3, Issue 2, Jun 2013, 161-166 TJPRC Pvt. Ltd. NATURAL LANGUAGE TO SQL CONVERSION
Data Mining on Social Networks. Dionysios Sotiropoulos Ph.D.
 Data Mining on Social Networks Dionysios Sotiropoulos Ph.D. 1 Contents What are Social Media? Mathematical Representation of Social Networks Fundamental Data Mining Concepts Data Mining Tasks on Digital
Data Mining on Social Networks Dionysios Sotiropoulos Ph.D. 1 Contents What are Social Media? Mathematical Representation of Social Networks Fundamental Data Mining Concepts Data Mining Tasks on Digital
Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy
 The Deep Web: Surfacing Hidden Value Michael K. Bergman Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy Presented by Mat Kelly CS895 Web-based Information Retrieval
The Deep Web: Surfacing Hidden Value Michael K. Bergman Web-Scale Extraction of Structured Data Michael J. Cafarella, Jayant Madhavan & Alon Halevy Presented by Mat Kelly CS895 Web-based Information Retrieval
Natural Language Database Interface for the Community Based Monitoring System *
 Natural Language Database Interface for the Community Based Monitoring System * Krissanne Kaye Garcia, Ma. Angelica Lumain, Jose Antonio Wong, Jhovee Gerard Yap, Charibeth Cheng De La Salle University
Natural Language Database Interface for the Community Based Monitoring System * Krissanne Kaye Garcia, Ma. Angelica Lumain, Jose Antonio Wong, Jhovee Gerard Yap, Charibeth Cheng De La Salle University
Open Domain Information Extraction. Günter Neumann, DFKI, 2012
 Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
From Terminology Extraction to Terminology Validation: An Approach Adapted to Log Files
 Journal of Universal Computer Science, vol. 21, no. 4 (2015), 604-635 submitted: 22/11/12, accepted: 26/3/15, appeared: 1/4/15 J.UCS From Terminology Extraction to Terminology Validation: An Approach Adapted
Journal of Universal Computer Science, vol. 21, no. 4 (2015), 604-635 submitted: 22/11/12, accepted: 26/3/15, appeared: 1/4/15 J.UCS From Terminology Extraction to Terminology Validation: An Approach Adapted
Chapter-1 : Introduction 1 CHAPTER - 1. Introduction
 Chapter-1 : Introduction 1 CHAPTER - 1 Introduction This thesis presents design of a new Model of the Meta-Search Engine for getting optimized search results. The focus is on new dimension of internet
Chapter-1 : Introduction 1 CHAPTER - 1 Introduction This thesis presents design of a new Model of the Meta-Search Engine for getting optimized search results. The focus is on new dimension of internet
The University of Amsterdam s Question Answering System at QA@CLEF 2007
 The University of Amsterdam s Question Answering System at QA@CLEF 2007 Valentin Jijkoun, Katja Hofmann, David Ahn, Mahboob Alam Khalid, Joris van Rantwijk, Maarten de Rijke, and Erik Tjong Kim Sang ISLA,
The University of Amsterdam s Question Answering System at QA@CLEF 2007 Valentin Jijkoun, Katja Hofmann, David Ahn, Mahboob Alam Khalid, Joris van Rantwijk, Maarten de Rijke, and Erik Tjong Kim Sang ISLA,
Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection
 Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection Gareth J. F. Jones, Declan Groves, Anna Khasin, Adenike Lam-Adesina, Bart Mellebeek. Andy Way School of Computing,
Dublin City University at CLEF 2004: Experiments with the ImageCLEF St Andrew s Collection Gareth J. F. Jones, Declan Groves, Anna Khasin, Adenike Lam-Adesina, Bart Mellebeek. Andy Way School of Computing,
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC
 Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
Text Mining in JMP with R Andrew T. Karl, Senior Management Consultant, Adsurgo LLC Heath Rushing, Principal Consultant and Co-Founder, Adsurgo LLC 1. Introduction A popular rule of thumb suggests that
A Corpus Linguistics-based Approach for Estimating Arabic Online Content
 A Corpus Linguistics-based Approach for Estimating Arabic Online Content Anas Tawileh Systematics Consulting anas@systematics.ca Mansour Al Ghamedi King Abdulaziz City for Science and Technology mghamdi@kacst.edu.sa
A Corpus Linguistics-based Approach for Estimating Arabic Online Content Anas Tawileh Systematics Consulting anas@systematics.ca Mansour Al Ghamedi King Abdulaziz City for Science and Technology mghamdi@kacst.edu.sa
Urdu-English Cross-Language Question Answering System
 Final Degree Project FINAL DEGREE PROJECT Urdu-English Cross-Language Question Answering System MEDITERRANEAN UNIVERSITY OF SCIENCE AND TECHNOLOGY JUNE 2006 SUPERVISED BY: PAOLO ROSSO BY: GEET FARUKH 2204003
Final Degree Project FINAL DEGREE PROJECT Urdu-English Cross-Language Question Answering System MEDITERRANEAN UNIVERSITY OF SCIENCE AND TECHNOLOGY JUNE 2006 SUPERVISED BY: PAOLO ROSSO BY: GEET FARUKH 2204003
Subordinating to the Majority: Factoid Question Answering over CQA Sites
 Journal of Computational Information Systems 9: 16 (2013) 6409 6416 Available at http://www.jofcis.com Subordinating to the Majority: Factoid Question Answering over CQA Sites Xin LIAN, Xiaojie YUAN, Haiwei
Journal of Computational Information Systems 9: 16 (2013) 6409 6416 Available at http://www.jofcis.com Subordinating to the Majority: Factoid Question Answering over CQA Sites Xin LIAN, Xiaojie YUAN, Haiwei
Specialty Answering Service. All rights reserved.
 0 Contents 1 Introduction... 2 1.1 Types of Dialog Systems... 2 2 Dialog Systems in Contact Centers... 4 2.1 Automated Call Centers... 4 3 History... 3 4 Designing Interactive Dialogs with Structured Data...
0 Contents 1 Introduction... 2 1.1 Types of Dialog Systems... 2 2 Dialog Systems in Contact Centers... 4 2.1 Automated Call Centers... 4 3 History... 3 4 Designing Interactive Dialogs with Structured Data...
A Comparative Approach to Search Engine Ranking Strategies
 26 A Comparative Approach to Search Engine Ranking Strategies Dharminder Singh 1, Ashwani Sethi 2 Guru Gobind Singh Collage of Engineering & Technology Guru Kashi University Talwandi Sabo, Bathinda, Punjab
26 A Comparative Approach to Search Engine Ranking Strategies Dharminder Singh 1, Ashwani Sethi 2 Guru Gobind Singh Collage of Engineering & Technology Guru Kashi University Talwandi Sabo, Bathinda, Punjab
TREC 2007 ciqa Task: University of Maryland
 TREC 2007 ciqa Task: University of Maryland Nitin Madnani, Jimmy Lin, and Bonnie Dorr University of Maryland College Park, Maryland, USA nmadnani,jimmylin,bonnie@umiacs.umd.edu 1 The ciqa Task Information
TREC 2007 ciqa Task: University of Maryland Nitin Madnani, Jimmy Lin, and Bonnie Dorr University of Maryland College Park, Maryland, USA nmadnani,jimmylin,bonnie@umiacs.umd.edu 1 The ciqa Task Information
Finding Advertising Keywords on Web Pages. Contextual Ads 101
 Finding Advertising Keywords on Web Pages Scott Wen-tau Yih Joshua Goodman Microsoft Research Vitor R. Carvalho Carnegie Mellon University Contextual Ads 101 Publisher s website Digital Camera Review The
Finding Advertising Keywords on Web Pages Scott Wen-tau Yih Joshua Goodman Microsoft Research Vitor R. Carvalho Carnegie Mellon University Contextual Ads 101 Publisher s website Digital Camera Review The
Customizing an English-Korean Machine Translation System for Patent Translation *
 Customizing an English-Korean Machine Translation System for Patent Translation * Sung-Kwon Choi, Young-Gil Kim Natural Language Processing Team, Electronics and Telecommunications Research Institute,
Customizing an English-Korean Machine Translation System for Patent Translation * Sung-Kwon Choi, Young-Gil Kim Natural Language Processing Team, Electronics and Telecommunications Research Institute,
Making Sense of the Mayhem: Machine Learning and March Madness
 Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
Special Topics in Computer Science
 Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation.
 CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation. Miguel Ruiz, Anne Diekema, Páraic Sheridan MNIS-TextWise Labs Dey Centennial Plaza 401 South Salina Street Syracuse, NY 13202 Abstract:
CINDOR Conceptual Interlingua Document Retrieval: TREC-8 Evaluation. Miguel Ruiz, Anne Diekema, Páraic Sheridan MNIS-TextWise Labs Dey Centennial Plaza 401 South Salina Street Syracuse, NY 13202 Abstract:
Machine Learning using MapReduce
 Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
Machine Learning using MapReduce What is Machine Learning Machine learning is a subfield of artificial intelligence concerned with techniques that allow computers to improve their outputs based on previous
CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING
 CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. Is there valuable
CAPTURING THE VALUE OF UNSTRUCTURED DATA: INTRODUCTION TO TEXT MINING Mary-Elizabeth ( M-E ) Eddlestone Principal Systems Engineer, Analytics SAS Customer Loyalty, SAS Institute, Inc. Is there valuable
Slide 7. Jashapara, Knowledge Management: An Integrated Approach, 2 nd Edition, Pearson Education Limited 2011. 7 Nisan 14 Pazartesi
 WELCOME! WELCOME! Chapter 7 WELCOME! Chapter 7 WELCOME! Chapter 7 KNOWLEDGE MANAGEMENT TOOLS: WELCOME! Chapter 7 KNOWLEDGE MANAGEMENT TOOLS: Component Technologies LEARNING OBJECTIVES LEARNING OBJECTIVES
WELCOME! WELCOME! Chapter 7 WELCOME! Chapter 7 WELCOME! Chapter 7 KNOWLEDGE MANAGEMENT TOOLS: WELCOME! Chapter 7 KNOWLEDGE MANAGEMENT TOOLS: Component Technologies LEARNING OBJECTIVES LEARNING OBJECTIVES
An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System
 An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System Asanee Kawtrakul ABSTRACT In information-age society, advanced retrieval technique and the automatic
An Overview of a Role of Natural Language Processing in An Intelligent Information Retrieval System Asanee Kawtrakul ABSTRACT In information-age society, advanced retrieval technique and the automatic
Constituency. The basic units of sentence structure
 Constituency The basic units of sentence structure Meaning of a sentence is more than the sum of its words. Meaning of a sentence is more than the sum of its words. a. The puppy hit the rock Meaning of
Constituency The basic units of sentence structure Meaning of a sentence is more than the sum of its words. Meaning of a sentence is more than the sum of its words. a. The puppy hit the rock Meaning of
Machine Data Analytics with Sumo Logic
 Machine Data Analytics with Sumo Logic A Sumo Logic White Paper Introduction Today, organizations generate more data in ten minutes than they did during the entire year in 2003. This exponential growth
Machine Data Analytics with Sumo Logic A Sumo Logic White Paper Introduction Today, organizations generate more data in ten minutes than they did during the entire year in 2003. This exponential growth
Unlocking The Value of the Deep Web. Harvesting Big Data that Google Doesn t Reach
 Unlocking The Value of the Deep Web Harvesting Big Data that Google Doesn t Reach Introduction Every day, untold millions search the web with Google, Bing and other search engines. The volumes truly are
Unlocking The Value of the Deep Web Harvesting Big Data that Google Doesn t Reach Introduction Every day, untold millions search the web with Google, Bing and other search engines. The volumes truly are
Mining Signatures in Healthcare Data Based on Event Sequences and its Applications
 Mining Signatures in Healthcare Data Based on Event Sequences and its Applications Siddhanth Gokarapu 1, J. Laxmi Narayana 2 1 Student, Computer Science & Engineering-Department, JNTU Hyderabad India 1
Mining Signatures in Healthcare Data Based on Event Sequences and its Applications Siddhanth Gokarapu 1, J. Laxmi Narayana 2 1 Student, Computer Science & Engineering-Department, JNTU Hyderabad India 1
Learning Translation Rules from Bilingual English Filipino Corpus
 Proceedings of PACLIC 19, the 19 th Asia-Pacific Conference on Language, Information and Computation. Learning Translation s from Bilingual English Filipino Corpus Michelle Wendy Tan, Raymond Joseph Ang,
Proceedings of PACLIC 19, the 19 th Asia-Pacific Conference on Language, Information and Computation. Learning Translation s from Bilingual English Filipino Corpus Michelle Wendy Tan, Raymond Joseph Ang,