CloudCom 2012 Taipei, Taiwan December 5, 2012
|
|
|
- Lydia Horton
- 8 years ago
- Views:
Transcription


1 Hadoop 23 - dotnext CloudCom 2012 Taipei, Taiwan December 5, 2012 viraj@yahoo-inc.com

, ORNL (TN)")
2 About Me Principal Engg in the Yahoo! Grid Team since May 2008 PhD from Rutgers University, NJ Specialization in Data Streaming, Grid, Autonomic Computing Worked on streaming data from live simulations executing in NERSC (CA), ORNL (TN) to Princeton Plasma Physics Lab (PPPL - NJ) Library introduce less then 5% overhead on computation PhD Thesis on In-Transit data processing for peta-scale simulation workflows Developed CorbaCoG kit for Globus Active contributor to Hadoop Apache, Pig, HCat and developer of Hadoop Vaidya - 2 -

3 Agenda - (10:30am -12pm) Overview and Introduction HDFS Federation YARN Hadoop 23 User Impact - 3 -


4 Hadoop Technology Stack at Yahoo! HDFS Distributed File System Map/Reduce Data Processing Paradigm HBase and HFile columnar storage PIG Data Processing Language HIVE SQL like query processing language HCatalog Table abstraction on top of big data allows interaction with Pig and Hive Oozie Workflow Management System Oozie HCatalog Hive PIG Map Reduce HBase File Format (HFile) HDFS 4-4 -

5 Evolution of Big Data Systems Low-Latency Analytic Processing 2009 Yahoo! S Google Percolator 2010 Microsoft Stream Insight 2011 Twitter Storm 2012 Berkeley Spark 2012 Cloudera Impala 2009 IBM Streams 2008 Hive Big Data 2006 PIG 2007 HBase 2006 Google Dremel Hadoop Google Map Reduce, BigTable - 5 -

6 Map & Reduce Primitives in Lisp (& Other functional languages) 1970s Google Paper

7 Map Output_List = Map (Input_List) Square (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) = (1, 4, 9, 16, 25, 36,49, 64, 81, 100) - 7 -

8 Reduce Output_Element = Reduce (Input_List) Sum (1, 4, 9, 16, 25, 36,49, 64, 81, 100) =
 =")
9 Parallelism Map is inherently parallel Each list element processed independently Reduce is inherently sequential Unless processing multiple lists Grouping to produce multiple lists - 9 -

10 Apache Hadoop Version Stable Version: (aka Hadoop 1.0) Stable release of Hadoop currently run at Yahoo! Latest Version: Being tested for certification in Yahoo! Hadoop version in process of development in conjunction with Hortonworks

11 HDFS Data is organized into files and directories Files are divided into uniform sized blocks (default 64MB) and distributed across cluster nodes HDFS exposes block placement so that computation can be migrated to data

12 Hadoop 0.23 (dotnext) Highlights Major Hadoop release adopted by Yahoo! in over 2 years (after Hadoop 0.20 /Hadoop 1.0.2) Primary focus is scalability HDFS Federation larger namespace & scalability Larger aggregated namespace Helps for better Grid consolidation YARN aka MRv2 Job run reliability Agility & Evolution Hadoop 23 initial release does not target availability Addressed in future releases of Hadoop

13 Hadoop 23 Story at Yahoo! Extra effort is being taken to certify applications with Hadoop 23 Sufficient time is provided for users to test their applications in Hadoop 23 Users are encouraged to get accounts to test if their applications run on a sandbox cluster which has Hadoop 23 installed Roll Out Plan Q through Q Hadoop 23 will be installed in a phased manner on 50k nodes

14 HADOOP 23 FEATURES HDFS FEDERATION

15 Non Federated HDFS Architecture
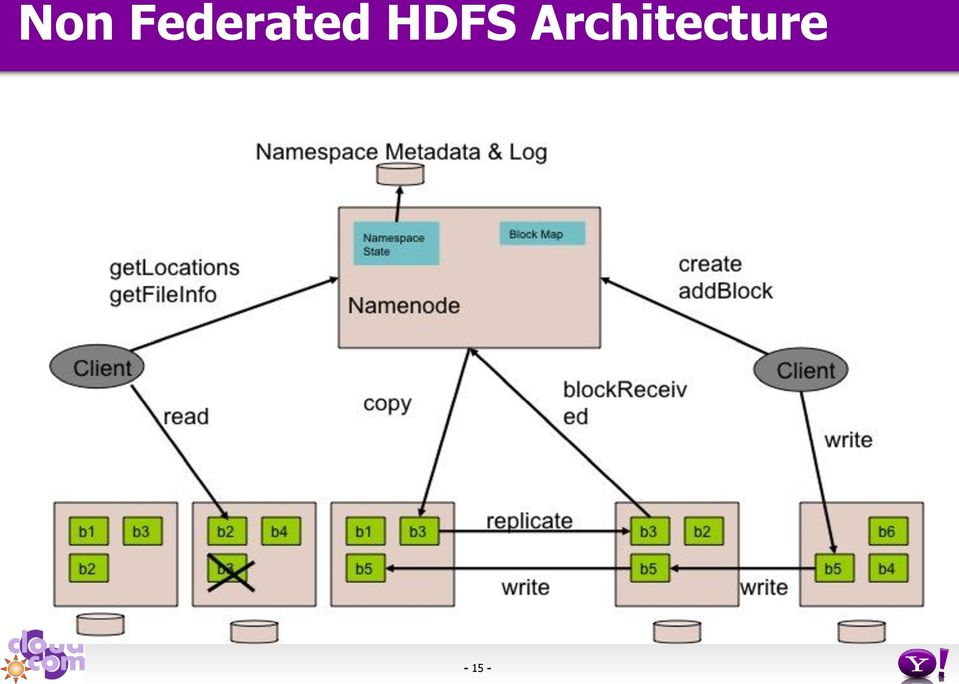

16 Block Storage Namespace Non Federated HDFS Architecture Two main layers Namespace Namenode NS Block Management Consists of dirs, files and blocks Supports create, delete, modify and list files or dirs operations Datanode Datanode Block Storage Storage Block Management Datanode cluster membership Supports create/delete/modify/get block location operations Manages replication and replica placement Storage - provides read and write access to blocks

17 Block Storage Namespace Non Federated HDFS Architecture Implemented as Namenode NS Block Management Single Namespace Volume Namespace Volume = Namespace + Blocks Single namenode with a namespace Datanode Storage Datanode Entire namespace is in memory Provides Block Management Datanodes store block replicas Block files stored on local file system

18 Limitation - Single Namespace Scalability Storage scales horizontally - namespace doesn t Limited number of files, dirs and blocks 250 million files and blocks at 64GB Namenode heap size Performance File system operations throughput limited by a single node 120K read ops/sec and 6000 write ops/sec Poor Isolation All the tenants share a single namespace Separate volume for tenants is not possible Lacks separate namespace for different categories of applications Experimental apps can affect production apps Example - HBase could use its own namespace Isolation is problem, even in a small cluster


19 Block Storage Namespace Limitation Tight coupling Namespace and Block Management are distinct services Tightly coupled due to co-location Scaling block management independent of namespace is simpler Simplifies Namespace and scaling it Block Storage could be a generic service Namespace is one of the applications to use the service Other services can be built directly on Block Storage HBase Foreign namespaces Namenode NS Block Management Datanode Datanode Storage

20 Block Storage Namespace HDFS Federation NN-1 NN-k NN-n NS1 NS k Foreign NS n Pool 1 Pool k Block Pools Pool n Datanode 1 Datanode 2 Datanode m Common Storage It is an administrative/operational feature for better managing resources Multiple independent Namenodes and Namespace Volumes in a cluster Namespace Volume = Namespace + Block Pool Block Storage as generic storage service Set of blocks for a Namespace Volume is called a Block Pool DNs store blocks for all the Namespace Volumes no partitioning

21 Managing Namespaces Federation has multiple namespaces Don t you need a single global namespace? Key is to share the data and the names used to access the data A global namespace is one way to do that Client-side mount table is another way to share. Shared mount-table => global shared view Personalized mount-table => per-application view Share the data that matter by mounting it Client-side implementation of mount tables No single point of failure No hotspot for root and top level directories NS1 data project NS2 / home Client-side mount-table NS3 tmp NS4-21 -
22 viewfs:// schema instead of hdfs:// schema With striped HDFS, user's applications were forced to use explicit URL of the source strip to read the data Federation hides all that detail. User sees only one single Virtual storage: The viewfs: URI schema can be used as the default file system replacing the hdfs schema
23 Client-Side Mount Table and VIEWFS Client-Side Mount Table is a type of file name indirection analogous to mount points in a conventional file system Indirection table available to the client application "client-side" is truly client side as HDFS client library is involved Namenodes are not part of the implementation. Data can be moved from one namespace to another without requiring changes in user applications An appropriate Client Side Mount Table should be provided
24 Client-Side Mount Table and VIEWFS The mount table is specified in a config file, like all other Hadoop configurations, core-site.xml The Client Side Mount Table definitions will by supplied by the Operations team 0.20.XXX <property> <name>fs.default.name</name> <value>hdfs://namenode:port/</value> </property> 0.23 <property> <name>fs.default.name</name> <value>viewfs://clustername/</value> </property>
25 Client-Side Mount Table Example mounttable.xml has a definition of the mount table called "KrRd" for the cluster MyCluster. MyCluster is a federation of the three name spaces managed by the three Namenodes nn1" nn2" and nn3" /user and /tmp managed by nn1. /projects/foo managed by nn2 /projects/bar managed by nn3"
26 Client-Side Mount Table XML Example <configuration> <property> <name>fs.viewfs.mounttable.krrd.link./user</name> <value> hdfs://nn1/user </value> </property> <property> <name>fs.viewfs.mounttable.krrd.link./tmp</name> <value> hdfs://nn1/tmp </value> </property> <property> <name>fs.viewfs.mounttable.krrd.link./projects/foo</name> <value> hdfs://nn2/projects/foo </value> </property> <property> <name>fs.viewfs.mounttable.krrd.link./projects/bar</name> <value> hdfs://nn3/projects/bar</value> </property> </configuration>
27 HDFS Federation - Wire Compatibility Wire Backward Compatibility Hadoop 23 is NOT RPC wire compatible with prior version s of Hadoop (0.20.X) Client must be updated to use the same version of Hadoop client library as installed on the server Application must be recompiled with new version of HDFS library API compatible
28 HDFS Federation: Append Functionality Append Functionality HDFS Federation has full support of append functionality along with flush. The hflush call by the writing client, ensures that all previously written bytes are visible to all new reading clients
29 HDFS Federation - Sticky Bits Sticky Bits for Directories Directories (not files) have sticky-bits. A file in a sticky directory may only be removed or renamed by: a user if the user has write permission for the directory and the user is the owner of the file, or the owner of the directory, or the super-user
30 HDFS Federation - FileContext File Context: New API for access to HDFS features. Replacement for the existing File System interface. FileContext is intended for application developers. FileSystem is intended for Service Provider
31 HDFS Federation - Symbolic Links Symbolic links allow the redirection of a filename to full URI Symbolic links may cross file systems No requirement for the target to exist when the link is created Symbolic links are available only via the File Context interface
32 HDFS Federation - Hadoop ARchive (HAR) har://scheme-hostname:port/archivepath/fileinarchive If no scheme is provided it assumes the underlying filesystem har:///archivepath/fileinarchive Naming scheme with viewfs har:///viewfs://cluster-name/foo/bar har:///foo/bar, if the default file system is viewfs: har:///hdfs://name-server/a/b/foo/bar
33 HDFS Federation - MapReduce Hadoop framework transparently handles initialization of delegation token for all the Namenodes in the current Federated HDFS User job requires to access external HDFS Set mapreduce.job.hdfs-servers with a comma separated list of the Namenodes
34 YET ANOTHER RESOURCE NEGOTIATOR (YARN) NEXT GENERATION OF HADOOP MAP-REDUCE
35 Hadoop MapReduce Today JobTracker Manages cluster resources and job scheduling TaskTracker Per-node agent Manage tasks
36 Current Limitations of the Job Tracker Scalability Maximum Cluster size 4,000 nodes Maximum concurrent tasks 40,000 Single point of failure Failure kills all queued and running jobs Jobs need to be re-submitted by users Restart is very tricky due to complex state Hard partition of resources into map and reduce slots
37 Current Limitations of the Job Tracker Lacks support for alternate paradigms Iterative applications implemented using MapReduce are 10x slower. Example: K-Means, PageRank Lack of wire-compatible protocols Client and cluster must be of same version Applications and workflows cannot migrate to different clusters
38 Design Theme for YARN Reliability Availability Scalability - Clusters of 6,000-10,000 machines Each machine with 16 cores, 48G/96G RAM, 24TB/36TB disks 100,000 concurrent tasks 10,000 concurrent jobs Wire Compatibility Agility & Evolution Ability for customers to control upgrades to the grid software stack
39 Design Methodology Split up the two major functions of JobTracker Cluster resource management Application life-cycle management MapReduce becomes user-land library
40 Architecture
41 Architecture
42 Architecture
43 Architecture of YARN Resource Manager Global resource scheduler Hierarchical queues Node Manager Per-machine agent Manages the life-cycle of container Container resource monitoring Application Master Per-application Manages application scheduling and task execution
44 Improvements vis-à-vis current Job Tracker Scalability Application life-cycle management is very expensive Partition resource management and application life-cycle management Application management is distributed Hardware trends - Currently run clusters of 4,000 machines 6, machines > 12, machines <16+ cores, 48/96G, 24TB> v/s <8 cores, 16G, 4TB>
45 Improvements vis-à-vis current Job Tracker Availability Resource Manager No single point of failure availability via ZooKeeper Targeted in Future release of Hadoop 23 Application Masters are restarted automatically on RM restart Applications continue to progress with existing resources during restart, new resources aren t allocated Application Master Optional failover via application-specific checkpoint MapReduce applications pick up where they left off
46 Improvements vis-à-vis current Job Tracker Wire Compatibility Protocols are wire-compatible Old clients can talk to new servers Rolling upgrades
47 Improvements vis-à-vis current Job Tracker Innovation and Agility MapReduce now becomes a user-land library Multiple versions of MapReduce (& ecosystems) can run in the same cluster Faster deployment cycles for improvements Customers upgrade MapReduce versions on their schedule Users can run customized versions of MapReduce HOP (Hadoop Online Prototype) modified version of Hadoop MapReduce that allows data to be pipelined between tasks and between jobs
48 Improvements vis-à-vis current Job Tracker Utilization Generic resource model Memory (in 23 the rest are for future releases) CPU Disk b/w Network b/w Remove fixed partition of map and reduce slots
49 Improvements vis-à-vis current Job Tracker Support for programming paradigms other than MapReduce MPI : Work already in progress Master-Worker Machine Learning Iterative processing Enabled by allowing use of paradigm-specific Application Master Run all on the same Hadoop cluster
50 Performance Improvements Small Job Optimizations Runs all tasks of Small job (i.e. job with up to 3/4 tasks) entirely in Application Master's JVM Reduces JVM startup time and also eliminates inter-node and inter-process data transfer during the shuffle phase. Transparent to the user Several Other improvements Speculation: Less aggressive Overhauled Shuffling algorithm yielding 30% improvement
51 Experiences of YARN High Points Scalable Largest YARN cluster in the world built at Yahoo! running on (Hadoop ), with no scalability issues so far Ran tests to validate that YARN should scale to 10,000 nodes. Surprisingly Stable Web Services Better Utilization of Resources at Yahoo! No fixed partitioning between Map and Reduce Tasks Latency from resource available to resource re-assigned is far better than 1.x in big clusters
52 Performance ( vs ) HDFS Read (Throughput 5.37% higher) MapReduce Sort (Runtime 4.59% smaller, Throughput 3.98% higher) Shuffle (Shuffle Time 13.25% smaller) Gridmix (Runtime 5.29% smaller) Small Jobs Uber AM (Word Count 3.5x faster, 27.7x fewer resources)
53 YARN Synergy with new Compute Paradigms MPI ( nightly snapshot) Machine Learning (Spark) Real-time Streaming (S4 and Storm) Graph Processing (GIRAPH-13)
54 The Not So Good Oozie on YARN can have potential deadlocks (MAPREDUCE- 4304) UberAM can mitigate this Some UI scalability issues (YARN-151, MAPREDUCE-4720) Some pages download very large tables and paginate in JavaScript Minor incompatibilities in the distributed cache No generic history server (MAPREDUCE-3061) AM failures hard to debug (MAPREDUCE-4428, MAPREDUCE- 3688)
55 HADOOP 23 IMPACT ON END USERS
56 Hadoop 23 Compatibility Command Line Users should depend on environment variables: $HADOOP_COMMON_HOME $HADOOP_MAPRED_HOME $HADOOP_HDFS_HOME hadoop command to execute mapred or hdfs subcommands has been deprecated Old usage (will work) New Usage hadoop queue showacls hadoop fs -ls hadoop mapred job -kill <job_id> mapred queue -showacls hdfs dfs ls <path> mapred job -kill <job_id>
57 Hadoop 23 Compatibility Map Reduce An application that is using a version of Hadoop 20 will not work in Hadoop 0.23 Hadoop 0.23 version is API compatible with Hadoop 0.20 But not binary compatible Hadoop Java programs will not require any code change, However users have to recompile with Hadoop 0.23 If code change is required, please let us know. Streaming applications should work without modifications Hadoop Pipes (using C/C++ interface) application will require a recompilation with new libraries
58 Hadoop 23 Compatibility - Pipes Although not deprecated, no future enhancements are planned. Potential of being deprecated in future As of now, it should work as expected. Recompilation with new Hadoop library is required. Recommended use of Hadoop Streaming for any new development
59 Hadoop 23 Compatibility - Ecosystems Applications relying on default setup of Oozie, Pig and Hive should continue to work. Pig and Hive scripts should continue to work as expected Pig and Hive UDFs written in Java/Python should continue to function as expected Recompilation of Java UDF s against Hadoop 23 is required
60 Hadoop 23 Compatibility Matrix for Pig Pig Version Hadoop or Hadoop Works with Hadoop Incompatible with Hadoop Works with Hadoop Works with Hadoop and upwards Works with Hadoop release Works with Hadoop
61 Hadoop 23 Compatibility - Pig Pig versions and future releases will be fully supported on Hadoop 0.23 No Changes in Pig script if it uses relative paths in HDFS Changes in pig script is required if HDFS absolute path (hdfs:// ) is used HDFS Federation part of Hadoop 23 requires the usage of viewfs:// (HDFS discussion to follow) Change hdfs:// schema to use viewfs:// schema Java UDF s must be re-compiled with Pig jar Ensures if user is using incompatible or deprecated APIs Code change might not be required for most cases
62 Hadoop 23 Compatibility Matrix for Oozie Oozie Version Hadoop Hadoop Works with Hadoop 20 release Incompatible with Hadoop Incompatible with Hadoop 20 release Works with Hadoop
63 Hadoop 23 Compatibility - Oozie Oozie and later versions compatible with Hadoop 23 Existing user workflow and coordinator definition (XML) should continue to work as expected No need to redeploy the Oozie coordinator jobs Users will need to update workflow definition to use viewfs:// instead of hdfs:// schema Due to HDFS Federation (discussion to follow) If HDFS is updated to have multi-volume (i.e. Federated) and there is a need to relocate the data
64 Hadoop 23 Compatibility Oozie Actions All Java actions must be recompiled with Hadoop 23 libraries distcp action or Java action invoking distcp requires Hadoop 23 compatible distcp jar Users responsibility to package Hadoop 23 compatible jars with their workflow definition Pig jar needs to be packaged for Pig action to function in Hadoop
65 Hadoop 23 - Oozie Challenges Learning curve for maven builds Build iterations, local maven staging repo staleness Queue configurations, container allocations require revisiting the design Many iterations of Hadoop 23 deployment Overhead to test Oozie compatibility with new release Initial deployment of YARN did not have a view of the Application Master (AM) logs Manual ssh to AM for debugging launcher jobs
66 Hadoop 23 Compatibility - Hive Hive version and upwards are fully supported Hive SQL/scripts should continue to work without any modification Java UDF s in Hive must be re-compiled with Hadoop 23 compatible hive.jar Ensures if user is using incompatible or deprecated APIs
67 Hadoop 23 Hive Challenges Deprecation of code in MiniMRCluster that fetches the stack trace from the JobTracker no longer works Extra amount of time in debugging and rewriting test cases Incompatibility of HDFS commands between Hadoop and rmr vs. -rm -r mkdir vs. mkdir p Results in fixing tests in new ways or inventing workarounds so that they run in both Hadoop and Hadoop 0.23 As Hive uses MapRed API s; more work required for certification Would be good to move to MapReduce API s (for example: Pig)
68 Hadoop 23 Compatibility - HCat HCat 0.4 and upwards version will be certified to work with Hadoop
69 Hadoop 23 New Features User Logs in User Dir User logs (stdout/stderr/syslog from the job) go into /user/ HDFS dir and are subject to quotas User logs have potential to fill up user HDFS quota User has to periodically clean up Previously in Hadoop 20 were stored on task tracker machines Deleted after a fixed interval Storing of User logs fails if User quota on HDFS maxed out Application Master logs (counters, start time, #maps, #reducers) Stored on the system directories Cleaned up on a periodic basis
70 Hadoop 23 Compatibility - Job History API Log Format History API & Log format are changed Affects all applications and tools that directly use Hadoop History API Stored as Avro serialization in JSon format Applications and tools are recommended to use Rumen Data extraction and analysis tool for Map-Reduce men.pdf
71 Hadoop 23 Queue Changes Hadoop 23 has support for Hierarchical Queues Container Queues contain other Leaf/Job Queues Jobs are submitted to Leaf queues Higher level of controls to the administrators Better scheduling of jobs with competing resources within the container queues Queues (as before) can steal resources beyond their capacity subject to their Max-Capacity setting
72 Hadoop 23 Compatibility - Web-UI Different Look and Feel to Web UI Customizable by the user Any user applications/tools depending on Web UI screen-scrapping to extract data will fail Users should depend on the web services API instead

73 Resource Manager
74 32 bits 64 bit JDK for Hadoop 23? Only 32 bit JDK is certified for Hadoop bit JDK would be bundled but not certified 64 bit support postponed to post Hadoop 23 deployment
75 Hadoop 23 Operations and Services Grid Operations at Yahoo! transitioned Hadoop Namenode to Hadoop 23 smoothly No data was lost Matched the container configurations on Hadoop 23 clusters with the old Map Reduce slots Map Reduce slots were configured based on memory hence transition was smooth Scheduling, planning and migration of Hadoop applications to Hadoop 23 for about 100+ customers was a major task for solutions Many issues were caught in the last minute needed emergency fixes (globbing, pig.jar packaging, change in mkdir command ) Hadoop build planned
76 Acknowledgements YARN Robert Evans, Thomas Graves, Jason Lowe Pig - Rohini Paliniswamy Hive and HCatalog Chris Drome Oozie Mona Chitnis and Mohammad Islam Services and Operations Rajiv Chittajallu and Kimsukh Kundu
77 References 0.23 Documentation Release Notes YARN Documentation HDFS Federation Documentation
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
Hadoop. History and Introduction. Explained By Vaibhav Agarwal
 Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Hadoop History and Introduction Explained By Vaibhav Agarwal Agenda Architecture HDFS Data Flow Map Reduce Data Flow Hadoop Versions History Hadoop version 2 Hadoop Architecture HADOOP (HDFS) Data Flow
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
YARN Apache Hadoop Next Generation Compute Platform
 YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
YARN Apache Hadoop Next Generation Compute Platform Bikas Saha @bikassaha Hortonworks Inc. 2013 Page 1 Apache Hadoop & YARN Apache Hadoop De facto Big Data open source platform Running for about 5 years
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop. New York Oracle User Group Vikas Sawhney
 Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
Introduction to Hadoop New York Oracle User Group Vikas Sawhney GENERAL AGENDA Driving Factors behind BIG-DATA NOSQL Database 2014 Database Landscape Hadoop Architecture Map/Reduce Hadoop Eco-system Hadoop
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing
 YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
HDFS Under the Hood. Sanjay Radia. Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc.
 HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK hdpguru@gmail.com Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 PART 2 PART 3 BIG DATA PATTERNS...253 PART 4 BEYOND MAPREDUCE...385
 brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
brief contents PART 1 BACKGROUND AND FUNDAMENTALS...1 1 Hadoop in a heartbeat 3 2 Introduction to YARN 22 PART 2 DATA LOGISTICS...59 3 Data serialization working with text and beyond 61 4 Organizing and
Hadoop. Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
 Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Source Alessandro Rezzani, Big Data - Architettura, tecnologie e metodi per l utilizzo di grandi basi di dati, Apogeo Education, ottobre 2013 wikipedia Hadoop Apache Hadoop is an open-source software
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Sujee Maniyam, ElephantScale
 Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Hadoop PRESENTATION 2 : New TITLE and GOES Noteworthy HERE Sujee Maniyam, ElephantScale SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer timo.aaltonen@tut.fi Assistants: Henri Terho and Antti
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Big Data Storage Options for Hadoop Sam Fineberg, HP Storage
 Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Sam Fineberg, HP Storage SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations
Qsoft Inc www.qsoft-inc.com
 Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Big Data & Hadoop Qsoft Inc www.qsoft-inc.com Course Topics 1 2 3 4 5 6 Week 1: Introduction to Big Data, Hadoop Architecture and HDFS Week 2: Setting up Hadoop Cluster Week 3: MapReduce Part 1 Week 4:
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM
 HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
HADOOP ADMINISTATION AND DEVELOPMENT TRAINING CURRICULUM 1. Introduction 1.1 Big Data Introduction What is Big Data Data Analytics Bigdata Challenges Technologies supported by big data 1.2 Hadoop Introduction
Big Data Processing using Hadoop. Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center
 Big Data Processing using Hadoop Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Apache Hadoop Hadoop INRIA S.IBRAHIM 2 2 Hadoop Hadoop is a top- level Apache project» Open source implementation
Big Data Processing using Hadoop Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Apache Hadoop Hadoop INRIA S.IBRAHIM 2 2 Hadoop Hadoop is a top- level Apache project» Open source implementation
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
A very short Intro to Hadoop
 4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
4 Overview A very short Intro to Hadoop photo by: exfordy, flickr 5 How to Crunch a Petabyte? Lots of disks, spinning all the time Redundancy, since disks die Lots of CPU cores, working all the time Retry,
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney") Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Big Data Analytics(Hadoop) Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Understanding Big Data and Big Data Analytics Getting familiar with Hadoop Technology Hadoop release and upgrades
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Accelerating and Simplifying Apache
 Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Google Bing Daytona Microsoft Research
 Google Bing Daytona Microsoft Research Raise your hand Great, you can help answer questions ;-) Sit with these people during lunch... An increased number and variety of data sources that generate large
Google Bing Daytona Microsoft Research Raise your hand Great, you can help answer questions ;-) Sit with these people during lunch... An increased number and variety of data sources that generate large
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
HADOOP. Revised 10/19/2015
 HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
Hadoop 2.6 Configuration and More Examples
 Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Lecture 2 (08/31, 09/02, 09/09): Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015
: Hadoop. Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015") Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
Lecture 2 (08/31, 09/02, 09/09): Hadoop Decisions, Operations & Information Technologies Robert H. Smith School of Business Fall, 2015 K. Zhang BUDT 758 What we ll cover Overview Architecture o Hadoop
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 ISSN 2278-7763
 International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
International Journal of Advancements in Research & Technology, Volume 3, Issue 2, February-2014 10 A Discussion on Testing Hadoop Applications Sevuga Perumal Chidambaram ABSTRACT The purpose of analysing
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
CURSO: ADMINISTRADOR PARA APACHE HADOOP
 CURSO: ADMINISTRADOR PARA APACHE HADOOP TEST DE EJEMPLO DEL EXÁMEN DE CERTIFICACIÓN www.formacionhadoop.com 1 Question: 1 A developer has submitted a long running MapReduce job with wrong data sets. You
CURSO: ADMINISTRADOR PARA APACHE HADOOP TEST DE EJEMPLO DEL EXÁMEN DE CERTIFICACIÓN www.formacionhadoop.com 1 Question: 1 A developer has submitted a long running MapReduce job with wrong data sets. You
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Big Data Technology Core Hadoop: HDFS-YARN Internals
 Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
The Evolving Apache Hadoop Eco-System
 The Evolving Apache Hadoop Eco-System What it means for Big Data Analytics and Storage Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop and Big Data Analytics
The Evolving Apache Hadoop Eco-System What it means for Big Data Analytics and Storage Sanjay Radia Architect/Founder, Hortonworks Inc. All Rights Reserved Page 1 Outline Hadoop and Big Data Analytics
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Communicating with the Elephant in the Data Center
 Communicating with the Elephant in the Data Center Who am I? Instructor Consultant Opensource Advocate http://www.laubersoltions.com sml@laubersolutions.com Twitter: @laubersm Freenode: laubersm Outline
Communicating with the Elephant in the Data Center Who am I? Instructor Consultant Opensource Advocate http://www.laubersoltions.com sml@laubersolutions.com Twitter: @laubersm Freenode: laubersm Outline
Apache Hadoop: Past, Present, and Future
 The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
CSE-E5430 Scalable Cloud Computing. Lecture 4
 Lecture 4 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 5.10-2015 1/23 Hadoop - Linux of Big Data Hadoop = Open Source Distributed Operating System
Lecture 4 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 5.10-2015 1/23 Hadoop - Linux of Big Data Hadoop = Open Source Distributed Operating System
Apache Hadoop new way for the company to store and analyze big data
 Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Apache Hadoop new way for the company to store and analyze big data Reyna Ulaque Software Engineer Agenda What is Big Data? What is Hadoop? Who uses Hadoop? Hadoop Architecture Hadoop Distributed File
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Ankush Cluster Manager - Hadoop2 Technology User Guide
 Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Ankush Cluster Manager - Hadoop2 Technology User Guide Ankush User Manual 1.5 Ankush User s Guide for Hadoop2, Version 1.5 This manual, and the accompanying software and other documentation, is protected
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Certified Big Data and Apache Hadoop Developer VS-1221
 Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Certified Big Data and Apache Hadoop Developer VS-1221 Certified Big Data and Apache Hadoop Developer Certification Code VS-1221 Vskills certification for Big Data and Apache Hadoop Developer Certification
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Data processing goes big
 Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
Test report: Integration Big Data Edition Data processing goes big Dr. Götz Güttich Integration is a powerful set of tools to access, transform, move and synchronize data. With more than 450 connectors,
BIG DATA HADOOP TRAINING
 BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
BIG DATA HADOOP TRAINING DURATION 40hrs AVAILABLE BATCHES WEEKDAYS (7.00AM TO 8.30AM) & WEEKENDS (10AM TO 1PM) MODE OF TRAINING AVAILABLE ONLINE INSTRUCTOR LED CLASSROOM TRAINING (MARATHAHALLI, BANGALORE)
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Important Notice. (c) 2010-2013 Cloudera, Inc. All rights reserved.
 2010-2013 Cloudera, Inc. All rights reserved.") Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Upcoming Announcements
 Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC jmarkham@hortonworks.com Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC jmarkham@hortonworks.com Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Pro Apache Hadoop. Second Edition. Sameer Wadkar. Madhu Siddalingaiah
 Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
Pro Apache Hadoop Second Edition Sameer Wadkar Madhu Siddalingaiah Contents J About the Authors About the Technical Reviewer Acknowledgments Introduction xix xxi xxiii xxv Chapter 1: Motivation for Big
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
The Top 10 7 Hadoop Patterns and Anti-patterns. Alex Holmes @
 The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
The Top 10 7 Hadoop Patterns and Anti-patterns Alex Holmes @ whoami Alex Holmes Software engineer Working on distributed systems for many years Hadoop since 2008 @grep_alex grepalex.com what s hadoop...
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
MapReduce with Apache Hadoop Analysing Big Data
 MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
MapReduce with Apache Hadoop Analysing Big Data April 2010 Gavin Heavyside gavin.heavyside@journeydynamics.com About Journey Dynamics Founded in 2006 to develop software technology to address the issues
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms
 Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Performance Evaluation for BlobSeer and Hadoop using Machine Learning Algorithms Elena Burceanu, Irina Presa Automatic Control and Computers Faculty Politehnica University of Bucharest Emails: {elena.burceanu,
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Apache Sentry. Prasad Mujumdar prasadm@apache.org prasadm@cloudera.com
 Apache Sentry Prasad Mujumdar prasadm@apache.org prasadm@cloudera.com Agenda Various aspects of data security Apache Sentry for authorization Key concepts of Apache Sentry Sentry features Sentry architecture
Apache Sentry Prasad Mujumdar prasadm@apache.org prasadm@cloudera.com Agenda Various aspects of data security Apache Sentry for authorization Key concepts of Apache Sentry Sentry features Sentry architecture
Big Data Operations Guide for Cloudera Manager v5.x Hadoop
 Big Data Operations Guide for Cloudera Manager v5.x Hadoop Logging into the Enterprise Cloudera Manager 1. On the server where you have installed 'Cloudera Manager', make sure that the server is running,
Big Data Operations Guide for Cloudera Manager v5.x Hadoop Logging into the Enterprise Cloudera Manager 1. On the server where you have installed 'Cloudera Manager', make sure that the server is running,
Reduction of Data at Namenode in HDFS using harballing Technique
 Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.
Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.