2. NAIVE BAYES CLASSIFIERS
|
|
|
- Tracy Doyle
- 8 years ago
- Views:
Transcription
1 Spam Filtering with Naive Bayes Which Naive Bayes? Vangelis Metsis Institute of Informatics and Telecommunications, N.C.S.R. Demokritos, Athens, Greece Ion Androutsopoulos Department of Informatics, Athens University of Economics and Business, Athens, Greece Georgios Paliouras Institute of Informatics and Telecommunications, N.C.S.R. Demokritos, Athens, Greece ABSTRACT Naive Bayes is very popular in commercial and open-source anti-spam filters. There are, however, several forms of Naive Bayes, something the anti-spam literature does not always acknowledge. We discuss five different versions of Naive Bayes, and compare them on six new, non-encoded datasets, that contain ham messages of particular Enron users and fresh spam messages. The new datasets, which we make publicly available, are more realistic than previous comparable benchmarks, because they maintain the temporal order of the messages in the two categories, and they emulate the varying proportion of spam and ham messages that users receive over time. We adopt an experimental procedure that emulates the incremental training of personalized spam filters, and we plot roc curves that allow us to compare the different versions of nb over the entire tradeoff between true positives and true negatives.. INTRODUCTION Although several machine learning algorithms have been employed in anti-spam filtering, including algorithms that are considered top-performers in text classification, like Boosting and Support Vector Machines (see, for example, [, 6,, 6]), Naive Bayes (nb) classifiers currently appear to be particularly popular in commercial and open-source spam filters. This is probably due to their simplicity, which makes them easy to implement, their linear computational complexity, and their accuracy, which in spam filtering is comparable to that of more elaborate learning algorithms [2]. There are, however, several forms of nb classifiers, and the anti-spam literature does not always acknowledge this. In their seminal papers on learning-based spam filters, Sahami et al. [2] used a nb classifier with a multi-variate Bernoulli model (this is also the model we had used in []), a form of nb that relies on Boolean attributes, whereas Pantel and Lin [9] in effect adopted the multinomial form of nb, which normally takes into account term frequencies. Mc- Callum and Nigam [7] have shown experimentally that the This version of the paper contains some minor corrections in the description of, which were made after the conference. Work carried out mostly while at the Department of Informatics, Athens University of Economics and Business. CEAS 26 - Third Conference on and Anti-Spam, July 27-28, 26, Mountain View, California USA multinomial nb performs generally better than the multivariate Bernoulli nb in text classification, a finding that Schneider [2] and Hovold [2] verified with spam filtering experiments on Ling-Spam and the pu corpora [, 2, 23]. In further work on text classification, which included experiments on Ling-Spam, Schneider [] found that the multinomial nb surprisingly performs even better when term frequencies are replaced by Boolean attributes. The multi-variate Bernoulli nb can be modified to accommodate continuous attributes, leading to what we call the multi-variate Gauss nb, by assuming that the values of each attribute follow a normal distribution within each category []. Alternatively, the distribution of each attribute in each category can be taken to be the average of several normal distributions, one for every different value the attribute has in the training data of that category, leading to a nb version that John and Langley [] call (fb). In previous work [2], we found that fb clearly outperforms the multi-variate Gauss nb on the pu corpora, when the attributes are term frequencies divided by document lengths, but we did not compare fb against the other nb versions. In this paper we shed more light on the five versions of nb mentioned above, and we evaluate them experimentally on six new, non-encoded datasets, collectively called Enron- Spam, which we make publicly available. Each dataset contains ham (non-spam) messages from a single user of the Enron corpus [5], to which we have added fresh spam messages with varying ham-spam ratios. Although a similar approach was adopted in the public benchmark of the trec Spam Track, to be discussed below, we believe that our datasets are better suited to evaluations of personalized filters, i.e., filters that are trained on incoming messages of a particular user they are intended to protect, which is the type of filters the experiments of this paper consider. Unlike Ling-Spam and the pu corpora, in the new datasets we maintain the order in which the original messages of the two categories were received, and we emulate the varying proportion of ham and spam messages that users receive over time. This allows us to conduct more realistic experiments, and to take into account the incremental training of personal filters. Furthermore, rather than focussing on a handful of relative misclassification costs (cost of false positives vs. false negatives; λ =, 9, 999 in our previous work), The Enron-Spam datasets are available from and in both raw and pre-processed form. Ling-Spam and the pu corpora are also available from the same addresses.

2 we plot entire roc curves, which allow us to compare the different versions of nb over the entire tradeoff between true positives and true negatives. Note that several publicly available spam filters appear to be using techniques described as Bayesian, but which are very different from any form of nb discussed in the academic literature and any other technique that would normally be called Bayesian therein. 2 Here we focus on nb versions published in the academic literature, leaving comparisons against other Bayesian techniques for future work. Section 2 below presents the event models and assumptions of the nb versions we considered. Section 3 explains how the datasets of our experiments were assembled and the evaluation methodology we used; it also highlights some pitfalls that have to be avoided when constructing spam filtering benchmarks. Section then presents and discusses our experimental results. Section 5 concludes and provides directions for further work. 2. NAIVE BAYES CLASSIFIERS As a simplification, we focus on the textual content of the messages. Operational filters would also consider information such as the presence of suspicious headers or token obfuscation [, 2], which can be added as additional attributes in the message representation discussed below. Alternatively, separate classifiers can be trained for textual and other attributes, and then form an ensemble [9, 22]. In our experiments, each message is ultimately represented as a vector x,..., x m, where x,..., x m are the values of attributes X,..., X m, and each attribute provides information about a particular token of the message. 3 In the simplest case, all the attributes are Boolean: X i = if the message contains the token; otherwise, X i =. Alternatively, their values may be term frequencies (tf), showing how many times the corresponding token occurs in the message. Attributes with tf values carry more information than Boolean ones. Hence, one might expect nb versions that use tf attributes to perform better than those with Boolean attributes, an expectation that is not always confirmed, as already mentioned. A third alternative we employed, hereafter called normalized tf, is to divide term frequencies by the total number of token occurrences in the message, to take into account the message s length. The motivation is that knowing, for example, that rich occurs 3 times in a message may be a good indication that the message is spam if it is only two paragraphs long, but not if the message is much longer. Following common text classification practice, we do not assign attributes to tokens that are too rare (we discard tokens that do not occur in at least 5 messages of the training data). We also rank the remaining attributes by information gain, and use only the m best, as in [, 2, 2], and elsewhere. We experimented with m = 5,, and 3. Note that the information gain ranking treats the at- 2 These techniques derive mostly from P. Graham s A plan for spam ; see 3 Attributes may also be mapped to character or token n- grams, but previous attempts to use n-grams in spam filtering led to contradictory or inconclusive results [2, 2, 9]. We treat punctuation and other non-alphabetic characters as separate tokens. Many of these are highly informative as attributes, because they are more common in spam messages (especially obfuscated ones) than ham messages; see [2]. tributes as Boolean, which may not be entirely satisfactory when employing a nb version with non-boolean attributes. Schneider [2] experimented with alternative versions of the information gain measure, intended to be more suitable to the tf-valued attributes of the multinomial nb. His results, however, indicate that the alternative versions do not lead to higher accuracy, although sometimes they allow the same level of accuracy to be reached with fewer attributes. From Bayes theorem, the probability that a message with vector x = x,..., x m belongs in category c is: p(c x) = p(c) p( x c). p( x) Since the denominator does not depend on the category, nb classifies each message in the category that maximizes p(c) p( x c). In the case of spam filtering, this is equivalent to classifying a message as spam whenever: p(c s) p( x c s) p(c s) p( x c s) + p(c h ) p( x c h ) > T, with T =.5, where c h and c s denote the ham and spam categories. By varying T, one can opt for more true negatives (correctly classified ham messages) at the expense of fewer true positives (correctly classified spam messages), or viceversa. The a priori probabilities p(c) are typically estimated by dividing the number of training messages of category c by the total number of training messages. The probabilities p( x c) are estimated differently in each nb version. 2. Multi-variate Bernoulli NB Let us denote by F = {t,..., t m} the set of tokens that correspond to the m attributes after attribute selection. The multi-variate Bernoulli nb treats each message d as a set of tokens, containing (only once) each t i that occurs in d. Hence, d can be represented by a binary vector x = x,..., x m, where each x i shows whether or not t i occurs in d. Furthermore, each message d of category c is seen as the result of m Bernoulli trials, where at each trial we decide whether or not t i will occur in d. The probability of a positive outcome at trial i (t i occurs in d) is p(t i c). The multi-variate Bernoulli nb makes the additional assumption that the outcomes of the trials are independent given the category. This is a naive assumption, since word co-occurrences in a category are not independent. Similar assumptions are made in all nb versions, and although in most cases they are over-simplistic, they still lead to very good performance in many classification tasks; see, for example, [5] for a theoretical explanation. p( x c) can be computed as: p( x c) = my i= p(t i c) xi ( p(t i c)) ( x i), Then, and the criterion for classifying a message as spam becomes: p(c s) Qm i= p(ti cs)xi ( p(t i c s)) ( x i) Qm Pc {c s,c h } p(c) i= p(ti c)x i ( p(ti c)) > T, ( x i) where each p(t c) is estimated using a Laplacean prior as: p(t c) = + Mt,c 2 + M c, and M t,c is the number of training messages of category c that contain token t, while M c is the total number of training messages of category c.

3 2.2 attributes The multinomial nb with tf attributes treats each message d as a bag of tokens, containing each one of t i as many times as it occurs in d. Hence, d can be represented by a vector x = x,..., x m, where each x i is now the number of occurrences of t i in d. Furthermore, each message d of category c is seen as the result of picking independently d tokens from F with replacement, with probability p(t i c) for each t i. 5 Then, p( x c) is the multinomial distribution: p( x c) = p( d ) d! my i= p(t i c) x i, x i! where we have followed the common assumption [7, 2, ] that d does not depend on the category c. This is an additional over-simplistic assumption, which is more questionable in spam filtering. For example, the probability of receiving a very long spam message appears to be smaller than that of receiving an equally long ham message. The criterion for classifying a message as spam becomes: p(c s) Qm i= p(ti cs)x i Qm Pc {c s,c h } p(c) i= p(ti > T, c)x i where each p(t c) is estimated using a Laplacean prior as: p(t c) = + Nt,c m + N c, and N t,c is now the number of occurrences of token t in the training messages of category c, while N c = P m i= Nt i,c. 2.3 Multinomial NB, Boolean attributes The multinomial nb with Boolean attributes is the same as with tf attributes, including the estimates of p(t c), except that the attributes are now Boolean. It differs from the multi-variate Bernoulli nb in that it does not take into account directly the absence (x i = ) of tokens from the message (there is no ( p(t i c)) ( xi) factor), and it estimates the p(t c) with a different Laplacean prior. It may seem strange that the multinomial nb might perform better with Boolean attributes, which provide less information than tf ones. As Schneider [] points out, however, it has been proven [7] that the multinomial nb with tf attributes is equivalent to a nb version with attributes modelled as following Poisson distributions in each category, assuming that the document length is independent of the category. Hence, the multinomial nb may perform better with Boolean attributes, if tf attributes in reality do not follow Poisson distributions. 2. Multi-variate Gauss NB The multi-variate Bernoulli nb can be modified for realvalued attributes, by assuming that each attribute follows a normal distribution g(x i; µ i,c, σ i,c) in each category c, where: g(x i; µ i,c, σ i,c) = e (x i µ i,c ) 2 2σ i,c 2, σ i,c 2π and the mean (µ i,c) and typical deviation (σ i,c) of each distribution are estimated from the training data. Then, as- 5 In effect, this is a unigram language model. Additional variants of the multinomial nb can be formed by using n- gram language models instead [2]. See also [3] for other improvements that can be made to the multinomial nb. suming again that the values of the attributes are independent given the category, we get: p( x c) = my i= g(x i; µ i,c, σ i,c), and the criterion for classifying a message as spam becomes: p(c s) Qm i= g(xi; µi,cs, σ i,cs ) Qm > T. p(c) i= g(xi; µi,c, σi,c) Pc {c s,c h } This allows us to use normalized tf attributes, whose values are (non-negative) reals, unlike the tf attributes of the multinomial nb. Real-valued attributes, however, may not follow normal distributions. With our normalized tf attributes, there is also the problem that negative values are not used, which leads to a significant loss of probability mass in the (presumed) normal distributions of attributes whose variances are large and means are close to zero. 2.5 Instead of using a single normal distribution for each attribute per category, fb models p(x i c) as the average of L i,c normal distributions with different mean values, but the same typical deviation: X p(x i c) = L i,c L i,c l= g(x i; µ i,c,l, σ c), where L i,c is the number of different values X i has in the training data of category c. Each of these values is used as the mean µ i,c,l of a normal distribution of that category. All the distributions of a category c are taken to have the same typical deviation, estimated as σ c = Mc, where M c is again the number of training messages in c. Hence, the distributions of each category become narrower as more training messages of that category are accumulated; in the case of our normalized tf attributes, this also alleviates the problem of probability mass loss of the multi-variate Gauss nb. By averaging several normal distributions, fb can approximate the true distributions of real-valued attributes more closely than the multi-variate Gauss nb, when the assumption that the attributes follow normal distributions is violated. The computational complexity of all five nb versions is O(m N) during training, where N is the total number of training messages. At classification time, the computational complexity of the first four versions is O(m), while the complexity of fb is O(m N), because of the need to sum the L i distributions. Consult [2] for further details. 3. DATASETS AND METHODOLOGY There has been significant effort to generate public benchmark datasets for anti-spam filtering. One of the main concerns is how to protect the privacy of the users (senders and receivers) whose ham messages are included in the datasets. The first approach is to use ham messages collected from freely accessible newsgroups, or mailing lists with public archives. Ling-Spam, the earliest of our benchmark datasets, follows this approach [23]. It consists of spam messages received at the time and ham messages retrieved from the archives of the Linguist list, a moderated and, hence, spamfree list about linguistics. Ling-Spam has the disadvantage that its ham messages are more topic-specific than the
 is the multinomial distribution: p( x c) = p( d ) d! my i= p(t i c) x i, x i! where we have followed the common assumption [7, 2, ] that d does not depend on the category c.")
4 messages most users receive. Hence, it can lead to overoptimistic estimates of the performance of learning-based spam filters. The SpamAssassin corpus is similar, in that its ham messages are publicly available; they were collected from public fora, or they were donated by users with the understanding they may be made public. 6 Since they were received by different users, however, SpamAssassin s ham messages are less topic-specific than those a single user would receive. Hence, the resulting dataset is inappropriate for experimentation with personalized spam filters. An alternative solution to the privacy problem is to distribute information about each message (e.g., the frequencies of particular words in each message), rather than the messages themselves. The Spambase collection follows this approach. It consists of vectors, each representing a single message (spam or ham), with each vector containing the values of pre-selected attributes, mostly word frequencies. The same approach was adopted in a corpus developed for a recently announced ecml-pkdd 26 challenge. 7 Datasets that adopt this approach, however, are much more restrictive than Ling-Spam and the SpamAssassin corpus, because their messages are not available in raw form, and, hence, it is impossible to experiment with attributes other than those chosen by their creators. A third approach is to release benchmarks each consisting of messages received by a particular user, after replacing each token by a unique number in all the messages. The mapping between tokens and numbers is not released, making it extremely difficult to recover the original messages, other than perhaps common words and phrases therein. This bypasses privacy problems, while producing messages whose token sequences are very close, from a statistical point of view, to the original ones. We have used this encoding scheme in the pu corpora [, 2, 23]. However, the loss of the original tokens still imposes restrictions; for example, it is impossible to experiment with different tokenizers. Following the Enron investigation, the personal files of approximately 5 Enron employees were made publicly available. 8 The files included a large number of personal messages, which have been used to create classification benchmarks [3, 5], including a public benchmark corpus for the trec Spam Track. 9 During the construction of the latter benchmark, several spam filters were employed to weed spam out of the Enron message collection. The collection was then augmented with spam messages collected in, leading to a benchmark with 3, ham and approximately 5, spam messages. The Spam Track experiments did not separate the resulting corpus into personal mailboxes, although such a division might have been possible via the To: field. Hence, the experiments corresponded to the scenario where a single filter is trained on a collection of messages received by many different users, as opposed to using personalized filters. As we were more interested in personalized spam filters, we focussed on six Enron employees who had large mail- 6 The SpamAssassin corpus and Spambase are available from and mlearn/mlrepository.html. 7 See 8 See 9 Consult gvcormac/spam/ for further details. We do not discuss the other three corpora of the Spam Track, as they are not publicly available. boxes. More specifically, we used the mailboxes of employees farmer-d, kaminski-v, kitchen-l, williams-w3, beck-s, and lokay-m, in the cleaned-up form provided by Bekkerman [3], which includes only ham messages. We also used spam messages obtained from four different sources: () the SpamAssassin corpus, (2) the Honeypot project, (3) the spam collection of Bruce Guenter (bg), 2 and spam collected by the third author of this paper (gp). The first three spam sources above collect spam via traps (e.g., addresses published on the Web in a way that makes it clear to humans, but not to crawlers, that they should not be used), resulting in multiple copies of the same messages. We applied a heuristic to the spam collection we obtained from each one of the first three spam sources, to identify and remove multiple copies; the heuristic is based on the number of common text lines in each pair of spam messages. After removing duplicates, we merged the spam collections obtained from sources and 2, because the messages from source were too few to be used on their own and did not include recent spam, whereas the messages from source 2 were fresher, but they covered a much shorter period of time. The resulting collection (dubbed sh; SpamAssassin spam plus Honeypot) contains messages sent between May 2 and July. From the third spam source (bg) we kept messages sent between August 2 and July, a period ending close to the time our datasets were constructed. Finally, the fourth spam source is the only one that does not rely on traps. It contains all the spam messages received by gp between December 23 and September ; duplicates were not removed in this case, as they are part of a normal stream of incoming spam. The six ham message collections (six Enron users) were each paired with one of the three spam collections (sh, bg, gp). Since the vast majority of spam messages are not personalized, we believe that mixing ham messages received by one user with spam messages received by others leads to reasonable benchmarks, provided that additional steps are taken, as discussed below. The same approach can be used in future to replace the spam messages of our datasets with fresher ones. We also varied the ham-spam ratios, by randomly subsampling the spam or ham messages, where necessary. In three of the resulting benchmark datasets, we used a ham-spam ratio of approximately 3:, while in the other three we inverted the ratio to :3. The total number of messages in each dataset is between five and six thousand. The six datasets emulate different situations faced by real users, allowing us to obtain a more complete picture of the performance of learning-based filters. Table summarizes the characteristics of the six datasets. Hereafter, we refer to the first, second,..., sixth dataset of Table as Enron, Enron2,..., Enron6, respectively. In addition to what was mentioned above, the six datasets were subjected to the following pre-processing steps. First, we removed messages sent by the owner of the mailbox (we checked if the address of the owner appeared in the To:, Cc:, or Bcc: fields), since we believe users are increasingly adopting better ways to keep copies of outgoing messages. Second, as a simplification, we removed all html tags and the headers of the messages, keeping only their The mailboxes can be downloaded from umass.edu/ ronb/datasets/enron flat.tar.gz. Consult 2 See
, rather than the messages themselves.")
5 Table : Composition of the six benchmark datasets. ham + spam ham:spam ham, spam periods farmer-d + gp 3672:5 [2/99, /2], [2/3, 9/5] kaminski-v + sh 36:6 [2/99, 5/], [5/, 7/5] kitchen-l + bg 2:5 [2/, 2/2], [8/, 7/5] williams-w3 + gp 5:5 [/, 2/2], 2/3, 9/5] beck-s + sh 5:3675 [/, 5/], [5/, 7/5] lokay-m + bg 5:5 [6/, 3/2], [8/, 7/5] subjects and bodies. In operational filters, html tags and headers can provide additional useful attributes, as mentioned above; hence, our datasets lead to conservative estimates of the performance of operational filters. Third, we removed spam messages written in non-latin character sets, because the ham messages of our datasets are all written in Latin characters, and, therefore, non-latin spam messages would be too easy to identify; i.e., we opted again for harder datasets, that lead to conservative performance estimates. One of the main goals of our evaluation was to emulate the situation that a new user of a personalized learningbased anti-spam filter faces: the user starts with a small amount of training messages, and retrains the filter as new messages arrive. As noted in [8], this incremental retraining and evaluation differs significantly from the cross-validation experiments that are commonly used to measure the performance of learning algorithms, and which have been adopted in many previous spam filtering experiments, including our own [2]. There are several reasons for this, including the varying size of the training set, the increasingly more sophisticated tricks used by spam senders over time, the varying proportion of spam to ham messages in different time periods, which makes the estimation of priors difficult, and the topic shift of spam messages over time. Hence, an incremental retraining and evaluation procedure that also takes into account the characteristics of spam that vary over time is essential when comparing different learning algorithms in spam filtering. In order to realize this incremental procedure with the use of our six datasets, we needed to order the messages of each dataset in a way that preserves the original order of arrival of the messages in each category; i.e., each spam message must be preceded by all spam messages that arrived earlier, and the same applies to ham messages. The varying ham-ratio ratio over time also had to be emulated. (The reader is reminded that the spam and ham messages of each dataset are from different time periods. Hence, one cannot simply use the dates of the messages.) This was achieved by using the following algorithm in each dataset:. Let S and H be the sets of spam and ham messages of the dataset, respectively. 2. Order the messages of H by time of arrival. 3. Insert S spam slots between the ordered messages of H by S independent random draws from {,..., H } with replacement. If the outcome of a draw is i, a new spam slot is inserted after the i-th ham message. A ham message may thus be followed by several slots.. Fill the spam slots with the messages of S, by iteratively filling the earliest empty spam slot with the oldest message of S that has not been placed to a slot. The actual dates of the messages are then discarded, and we assume that the messages (ham and spam) of each dataset Enron - ham:spam ratio per batch batch number Figure : Fluctuation of the ham-spam ratio. arrive in the order produced by the algorithm above. Figure shows the resulting fluctuation of the ham-spam ratio over batches of adjacent messages each. The first batch contains the oldest messages, the second one the messages that arrived immediately after those of the first batch, etc. The ham-spam ratio in the entire dataset is 2.5. In each ordered dataset, the incremental retraining and evaluation procedure was implemented as follows:. Split the sequence of messages into batches b,..., b l of k adjacent messages each, preserving the order of arrival. Batch b l may have less than k messages. 2. For i = to l, train the filter (including attribute selection) on the messages of batches,..., i, and test it on the messages of b i+. Note that at the end of the evaluation, each message of the dataset (excluding b ) will have been classified exactly once. The number of true positives (TP) is the number of spam messages that have been classified as spam, and similarly for false positives (FP, ham misclassified as spam), true negatives (TN, correctly classified ham), and false negatives (FN, spam misclassified as ham). We set k =, which emulates the situation where the filter is retrained every new messages. 3 We assume that the user marks as false negatives spam messages that pass the filter, and inspects periodically for false positives a spam folder, where messages identified by the filter as spam end up. TP In our evaluation, we used spam recall ( ) and ham TP+FN TN recall ( ). Spam recall is the proportion of spam messages that the filter managed to identify correctly (how much TN +FP spam it blocked), whereas ham recall is the proportion of ham messages that passed the filter. Spam recall is the complement of spam misclassification rate, and ham recall the complement of ham misclassification rate, the two measures that were used in the trec Spam Track. In order to evaluate the different nb versions across the entire tradeoff between true positives and true negatives, we present the evaluation results by means of roc curves, plotting sensitivity (spam recall) against specificity (the complement of ham recall, or ham misclassification rate). This is the 3 An nb-based filter can easily be retrained on-line, immediately after receiving each new message. We chose k = to make it easier to add in future work additional experiments with other learning algorithms, such as svms, which are computationally more expensive to train.
![2/3, 9/5] beck-s + sh 5:3675 [/, 5/], [5/, 7/5] lokay-m + bg 5:5 [6/, 3/2], [8/, 7/5] subjects and bodies.](/docs-images/45/4778710/images/page_5.jpg "In operational filters, html tags and headers can provide additional useful attributes, as mentioned above; hence, our datasets lead to conservative estimates of the performance of operational")
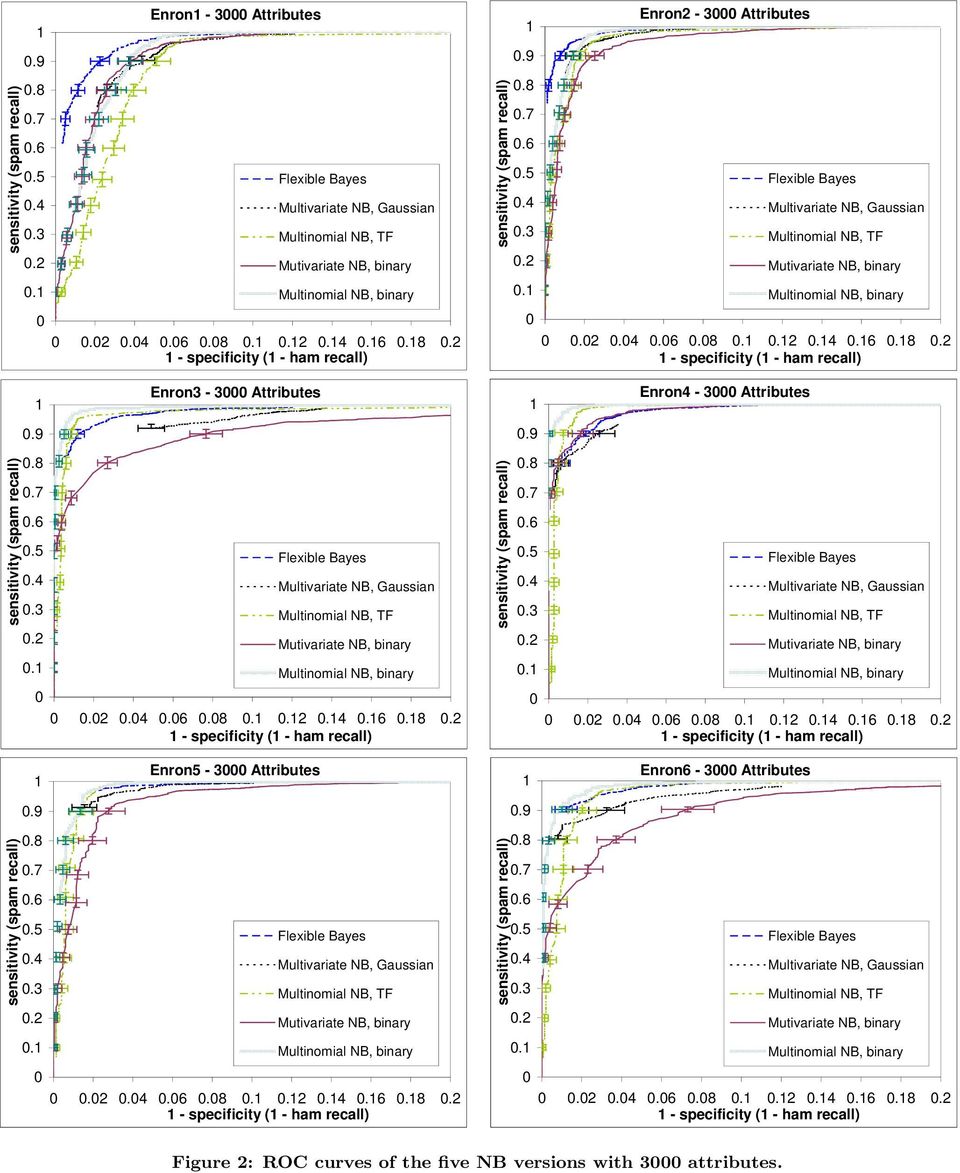
6 nb version Enr Enr2 Enr3 Enr Enr5 Enr6 fb mv Gauss mn tf mv Bernoulli mn Boolean Table 2: Maximum difference ( ) in spam recall across 5,, 3 attributes for T =.5. nb version Enr Enr2 Enr3 Enr Enr5 Enr6 fb mv Gauss mn tf mv Bernoulli mn Boolean Table 3: Maximum difference ( ) in ham recall across 5,, 3 attributes for T =.5. normal definition of roc analysis, when treating spam as the positive and ham as the negative class. The roc curves capture the overall performance of the different nb versions in each dataset, but fail to provide a picture of the progress made by each nb version during the incremental procedure. For this reason, we additionally examine the learning curves of the five methods in terms of the two measures for T =.5, i.e., we plot spam and ham recall as the training set increases during the incremental retraining and evaluation procedure.. EXPERIMENTAL RESULTS. Size of attribute set We first examined the impact of the number of attributes on the effectiveness of the five nb versions. As mentioned above, we experimented with 5,, and 3 attributes. The full results of these experiments (not reported here) indicate that overall the best results are achieved with 3 attributes, as one might have expected. The differences in effectiveness across different numbers of attributes, however, are rather insignificant. As an example, Tables 2 and 3 show the maximum differences in spam and ham recall, respectively, across the three sizes of the attribute set, for each nb version and dataset, with T =.5; note that the differences are in percentage points. The tables show that the differences are very small in all five nb versions for this threshold value, and we obtained very similar results for all thresholds. Consequently, in operational filters the differences in effectiveness may not justify the increased computational cost that larger attribute sets require, even though the increase in computational cost is linear in the number of attributes..2 Comparison of NB versions Figure 2 shows the roc curves of the five nb versions in each one of the six datasets. 5 All the curves are for 3 attributes, and the error bars correspond to 5 confidence intervals; we show error bars only at some points to avoid We used a modified version of filtron [8] for our experiments, with weka s implementations of the five nb versions; see ml/weka/. 5 Please view the figures in color, consulting the on-line version of this paper if necessary; see cluttering the diagrams. Since the tolerance of most users on misclassifying ham messages is very limited, we have restricted the horizontal axis ( specificity = ham recall) of all diagrams to [,.2], i.e., a maximum of 2% of misclassified ham, in order to improve the readability of the diagrams. On the vertical axis (sensitivity, spam recall) we show the full range, which allows us to examine what proportion of spam messages the five nb versions manage to block when requesting a very low ham misclassification rate (when specificity approaches ). The optimal performance point in an roc diagram is the top-left corner, while the area under each curve (auc) is often seen as a summary of the performance of the corresponding method. We do not, however, believe that standard auc is a good measure for spam filters, because it is dominated by non-high specificity (ham recall) regions, which are of no interest in practice. Perhaps one should compute the area for specificity [,.2] or [,.]. Even then, however, it is debatable how the area should be computed when roc curves do not span the entire [,.2] or [,.] range of the horizontal axis (see below). A first conclusion that can be drawn from the results of Figure 2 is that some datasets, such as Enron, are easier than others, such as Enron. There does not seem to be a clear justification for these differences, in terms of the hamspam ratio or the spam source used in each dataset. Despite its theoretical association to term frequencies, in all six datasets the multinomial nb seems to be doing better when Boolean attributes are used, which agrees with Schneider s observations []. The difference, however, is in most cases very small and not always statistically significant; it is clearer in the first dataset and, to a lesser extent, in the last one. Furthermore, the multinomial nb with Boolean attributes seems to be the best performer in out of 6 datasets, although again by a small and not always statistically significant margin, and it is clearly outperformed only by fb in the other 2 datasets. This is particularly interesting, since many nb-based spam filters appear to adopt the multinomial nb with tf attributes or the multi-variate Bernoulli nb (which uses Boolean attributes); the latter seems to be the worst among the nb versions we evaluated. Among the nb versions that we tested with normalized tf attributes (fb and the multi-variate Gauss nb), overall fb is clearly the best. However, fb does not always outperform the other nb version that uses non-boolean attributes, namely the multinomial nb with tf attributes. The fb classifier shows signs of impressive superiority in Enron and Enron2; and its performance is almost undistinguishable from that of the top performers in Enron5 and Enron6. However, it does not perform equally well, compared to the top performers, in the other two datasets (Enron3, Enron), which strangely include what appears to be the easiest dataset (Enron). One problem we noticed with fb is that its estimates for p(c x) are very close to or ; hence, varying the threshold T has no effect on the classification of many messages. This did not allow us to obtain higher ham recall (lower specificity) by trading off spam recall (sensitivity) as well as in the other nb versions, which is why the fb roc curves are shorter in some of the diagrams. (The same comment applies to the multi-variate Gauss nb.) Having said that, we were able to reach a ham recall level of 99.9% or higher with fb in most of the datasets. Overall, the multinomial nb with Boolean attributes and fb obtained the best results in our experiments, but the dif-

7 Enron - 3 Attributes specificity ( - ham recall) Enron3-3 Attributes specificity ( - ham recall) Enron2-3 Attributes specificity ( - ham recall) Enron - 3 Attributes specificity ( - ham recall) Enron5-3 Attributes Enron6-3 Attributes specificity ( - ham recall) specificity ( - ham recall) Figure 2: ROC curves of the five NB versions with 3 attributes.
8 nb version Enr Enr2 Enr3 Enr Enr5 Enr6 Avg. fb mv Gauss mn tf mv Bern mn Bool Table : Spam recall (%) for 3 attributes, T =.5. nb version Enr Enr2 Enr3 Enr Enr5 Enr6 Avg. fb mv Gauss mn tf mv Bern mn Bool Table 5: Ham recall (%) for 3 attributes, T =.5. ferences from the other nb versions were often very small. Taking into account its smoother trade-off between ham and spam recall, and its better computational complexity at run time, we tend to prefer the multinomial nb with Boolean attributes over fb, but further experiments are necessary to establish its superiority with confidence. For completeness, Tables and 5 list the spam and ham recall, respectively, of the nb versions on the 6 datasets for T =.5, although comparing at a fixed threshold T is not particularly informative; for example, two methods may obtain the same results at different thresholds. On average, the multinomial nb with Boolean attributes again has the best results, both in spam and ham recall..3 Learning curves Figure 3 shows the learning curves (spam and ham recall as more training messages are accumulated over time) of the multinomial nb with Boolean attributes on the six datasets for T =.5. It is interesting to observe that the curves do not increase monotonically, unlike most text classification experiments, presumably because of the unpredictable fluctuation of the ham-spam ratio, the changing topics of spam, and the adversarial nature of anti-spam filtering. In the easiest dataset (Enron) the classifier reaches almost perfect performance, especially in terms of ham recall, after a few hundreds of messages, and quickly returns to nearperfect performance whenever a deviation occurs. As more training messages are accumulated, the deviations from the perfect performance almost disappear. In contrast, in more difficult datasets (e.g., Enron) the fluctuation of ham and spam recall is continuous. The classifier seems to adapt quickly to changes, though, avoiding prolonged plateaus of low performance. Spam recall is particularly high and stable in Enron5, but this comes at the expense of frequent large fluctuations of ham recall; hence, the high spam recall may be the effect of a tradeoff between spam and ham recall. 5. CONCLUSIONS AND FURTHER WORK We discussed and evaluated experimentally in a spam filtering context five different versions of the Naive Bayes (nb) classifier. Our investigation included two versions of nb that have not been used widely in the spam filtering literature, namely (fb) and the multinomial nb with Boolean attributes. We emulated the situation faced by a new user of a personalized learning-based spam filter, adopting an incremental retraining and evaluation procedure. The six datasets that we used, and which we make publicly available, were created by mixing freely available ham and spam messages in different proportions. The mixing procedure emulates the unpredictable fluctuation over time of the hamspam ratio in real mailboxes. Our evaluation included plotting roc curves, which allowed us to compare the different nb versions across the entire tradeoff between true positives and true negatives. The most interesting result of our evaluation was the very good performance of the two nb versions that have been used less in spam filtering, i.e., fb and the multinomial nb with Boolean attributes; these two versions collectively obtained the best results in our experiments. Taking also into account its lower computational complexity at run time and its smoother trade-off between ham and spam recall, we tend to prefer the multinomial nb with Boolean attributes over fb, but further experiments are needed to be confident. The best results in terms of effectiveness were generally achieved with the largest attribute set (3 attributes), as one might have expected, but the gain was rather insignificant, compared to smaller and computationally cheaper attribute sets. We are currently collecting more data, in a setting that will allow us to evaluate the five nb versions and other learning algorithms on several real mailboxes with the incremental retraining and evaluation method. The obvious caveat of these additional real-user experiments is that it will not be possible to provide publicly the resulting datasets in a nonencoded form. Therefore, we plan to release them using the encoding scheme of the pu datasets. 6. REFERENCES [] I. Androutsopoulos, J. Koutsias, K. Chandrinos, and C. Spyropoulos. An experimental comparison of Naive Bayesian and keyword-based anti-spam filtering with encrypted personal messages. In 23rd ACM SIGIR Conference, pages 6 67, Athens, Greece, 2. [2] I. Androutsopoulos, G. Paliouras, and E. Michelakis. Learning to filter unsolicited commercial . technical report 2/2, NCSR Demokritos, 2. [3] R. Beckermann, A. McCallum, and G. Huang. Automatic categorization of into folders: benchmark experiments on Enron and SRI corpora. Technical report IR-8, University of Massachusetts Amherst, 2. [] X. Carreras and L. Marquez. Boosting trees for anti-spam filtering. In th International Conference on Recent Advances in Natural Language Processing, pages 58 6, Tzigov Chark, Bulgaria, 2. [5] P. Domingos and M. Pazzani. On the optimality of the simple Bayesian classifier under zero-one loss. Machine Learning, 29(2 3):33, 997. [6] H. D. Drucker, D. Wu, and V. Vapnik. Support Vector Machines for spam categorization. IEEE Transactions On Neural Networks, (5):8 5, 999. [7] S. Eyheramendy, D. Lewis, and D. Madigan. On the Naive Bayes model for text categorization. In 9th International Workshop on Artificial Intelligence and Statistics, pages , Key West, Florida, 23. [8] T. Fawcett. In vivo spam filtering: a challenge
 for 3 attributes, T =.5. ferences from the other nb versions were often very small.")
9 Enron - Multinomial NB, Boolean - 3 Attributes Enron2 - Multinomial NB, Boolean - 3 Attributes Enron3 - Multinomial NB, Boolean - 3 Attributes Number of s x Number of s x Number of s x Enron - Multinomial NB, Boolean - 3 Attributes Enron5 - Multinomial NB, Boolean - 3 Attributes Enron6 - Multinomial NB, Boolean - 3 Attributes Number of s x Number of s x Number of s x Figure 3: Learning curves for the multinomial NB with Boolean attributes and T =.5. problem for KDD. SIGKDD Explorations, 5(2): 8, 23. [9] S. Hershkop and S. Stolfo. Combining models for false positive reduction. In th ACM SIGKDD Conference, pages 98 7, Chicago, Illinois,. [] J. G. Hidalgo. Evaluating cost-sensitive unsolicited bulk categorization. In 7th ACM Symposium on Applied Computing, pages 65 62, 22. [] J. G. Hidalgo and M. M. Lopez. Combining text and heuristics for cost-sensitive spam filtering. In th Computational Natural Language Learning Workshop, pages 99 2, Lisbon, Portugal, 2. [2] J. Hovold. Naive Bayes spam filtering using word-position-based attributes. In 2nd Conference on and Anti-Spam, Stanford, CA,. [3] J. T. J.D.M. Rennie, L. Shih and D. Karger. Tackling the poor assumptions of Naive Bayes classifiers. In 2th International Conference on Machine Learning, pages , Washington, DC, 23. [] G. John and P. Langley. Estimating continuous distributions in Bayesian classifiers. In th Conference on Uncertainty in Artificial Intelligence, pages , Montreal, Quebec, 995. [5] B. Klimt and Y. Yang. The Enron corpus: a new dataset for classification research. In 5th European Conference on Machine Learning and the 8th European Conference on Principles and Practice of Knowledge Discovery in Databases, pages , Pisa, Italy, 2. [6] A. Kolcz and J. Alspector. SVM-based filtering of spam with content-specific misclassification costs. In Workshop on Text Mining, IEEE International Conference on Data Mining, San Jose, California, 2. [7] A. McCallum and K. Nigam. A comparison of event models for naive bayes text classification. In AAAI 98 Workshop on Learning for Text Categorization, pages 8, Madison, Wisconsin, 998. [8] E. Michelakis, I. Androutsopoulos, G. Paliouras, G. Sakkis, and P. Stamatopoulos. Filtron: a learning-based anti-spam filter. In st Conference on and Anti-Spam, Mountain View, CA, 2. [9] P. Pantel and D. Lin. SpamCop: a spam classification and organization program. In Learning for Text Categorization Papers from the AAAI Workshop, pages 95 98, Madison, Wisconsin, 998. [2] F. Peng, D. Schuurmans, and S. Wang. Augmenting naive bayes classifiers with statistical language models. Information Retrieval, 7: 35, 2. [2] M. Sahami, S. Dumais, D. Heckerman, and E. Horvitz. A Bayesian approach to filtering junk . In Learning for Text Categorization Papers from the AAAI Workshop, pages 55 62, Madison, Wisconsin, 998. [22] G. Sakkis, I. Androutsopoulos, G. Paliouras, V. Karkaletsis, C. Spyropoulos, and P. Stamatopoulos. Stacking classifiers for anti-spam filtering of . In Conference on Empirical Methods in Natural Language Processing, pages 5, Carnegie Mellon University, Pittsburgh, PA, 2. [23] G. Sakkis, I. Androutsopoulos, G. Paliouras, V. Karkaletsis, C. Spyropoulos, and P. Stamatopoulos. A memory-based approach to anti-spam filtering for mailing lists. Information Retrieval, 6(): 73, 23. [2] K.-M. Schneider. A comparison of event models for Naive Bayes anti-spam filtering. In th Conference of the European Chapter of the ACL, pages 3, Budapest, Hungary, 23. [] K.-M. Schneider. On word frequency information and negative evidence in Naive Bayes text classification. In th International Conference on Advances in Natural Language Processing, pages 7 85, Alicante, Spain, 2.
: 8, 23. [9] S. Hershkop and S. Stolfo.")
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering
 A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
A Two-Pass Statistical Approach for Automatic Personalized Spam Filtering Khurum Nazir Junejo, Mirza Muhammad Yousaf, and Asim Karim Dept. of Computer Science, Lahore University of Management Sciences
Simple Language Models for Spam Detection
 Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
Simple Language Models for Spam Detection Egidio Terra Faculty of Informatics PUC/RS - Brazil Abstract For this year s Spam track we used classifiers based on language models. These models are used to
CAS-ICT at TREC 2005 SPAM Track: Using Non-Textual Information to Improve Spam Filtering Performance
 CAS-ICT at TREC 2005 SPAM Track: Using Non-Textual Information to Improve Spam Filtering Performance Shen Wang, Bin Wang and Hao Lang, Xueqi Cheng Institute of Computing Technology, Chinese Academy of
CAS-ICT at TREC 2005 SPAM Track: Using Non-Textual Information to Improve Spam Filtering Performance Shen Wang, Bin Wang and Hao Lang, Xueqi Cheng Institute of Computing Technology, Chinese Academy of
Bayesian Spam Filtering
 Bayesian Spam Filtering Ahmed Obied Department of Computer Science University of Calgary amaobied@ucalgary.ca http://www.cpsc.ucalgary.ca/~amaobied Abstract. With the enormous amount of spam messages propagating
Bayesian Spam Filtering Ahmed Obied Department of Computer Science University of Calgary amaobied@ucalgary.ca http://www.cpsc.ucalgary.ca/~amaobied Abstract. With the enormous amount of spam messages propagating
Naive Bayes Spam Filtering Using Word-Position-Based Attributes
 Naive Bayes Spam Filtering Using Word-Position-Based Attributes Johan Hovold Department of Computer Science Lund University Box 118, 221 00 Lund, Sweden johan.hovold.363@student.lu.se Abstract This paper
Naive Bayes Spam Filtering Using Word-Position-Based Attributes Johan Hovold Department of Computer Science Lund University Box 118, 221 00 Lund, Sweden johan.hovold.363@student.lu.se Abstract This paper
Learning to Filter Unsolicited Commercial E-Mail
 Learning to Filter Unsolicited Commercial E-Mail Ion Androutsopoulos Athens University of Economics and Business and Georgios Paliouras and Eirinaios Michelakis National Centre for Scientific Research
Learning to Filter Unsolicited Commercial E-Mail Ion Androutsopoulos Athens University of Economics and Business and Georgios Paliouras and Eirinaios Michelakis National Centre for Scientific Research
Three-Way Decisions Solution to Filter Spam Email: An Empirical Study
 Three-Way Decisions Solution to Filter Spam Email: An Empirical Study Xiuyi Jia 1,4, Kan Zheng 2,WeiweiLi 3, Tingting Liu 2, and Lin Shang 4 1 School of Computer Science and Technology, Nanjing University
Three-Way Decisions Solution to Filter Spam Email: An Empirical Study Xiuyi Jia 1,4, Kan Zheng 2,WeiweiLi 3, Tingting Liu 2, and Lin Shang 4 1 School of Computer Science and Technology, Nanjing University
PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering
 2007 IEEE/WIC/ACM International Conference on Web Intelligence PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering Khurum Nazir Juneo Dept. of Computer Science Lahore University
2007 IEEE/WIC/ACM International Conference on Web Intelligence PSSF: A Novel Statistical Approach for Personalized Service-side Spam Filtering Khurum Nazir Juneo Dept. of Computer Science Lahore University
A Bayesian Topic Model for Spam Filtering
 Journal of Information & Computational Science 1:12 (213) 3719 3727 August 1, 213 Available at http://www.joics.com A Bayesian Topic Model for Spam Filtering Zhiying Zhang, Xu Yu, Lixiang Shi, Li Peng,
Journal of Information & Computational Science 1:12 (213) 3719 3727 August 1, 213 Available at http://www.joics.com A Bayesian Topic Model for Spam Filtering Zhiying Zhang, Xu Yu, Lixiang Shi, Li Peng,
Abstract. Find out if your mortgage rate is too high, NOW. Free Search
 Statistics and The War on Spam David Madigan Rutgers University Abstract Text categorization algorithms assign texts to predefined categories. The study of such algorithms has a rich history dating back
Statistics and The War on Spam David Madigan Rutgers University Abstract Text categorization algorithms assign texts to predefined categories. The study of such algorithms has a rich history dating back
Filtering Junk Mail with A Maximum Entropy Model
 Filtering Junk Mail with A Maximum Entropy Model ZHANG Le and YAO Tian-shun Institute of Computer Software & Theory. School of Information Science & Engineering, Northeastern University Shenyang, 110004
Filtering Junk Mail with A Maximum Entropy Model ZHANG Le and YAO Tian-shun Institute of Computer Software & Theory. School of Information Science & Engineering, Northeastern University Shenyang, 110004
An Approach to Detect Spam Emails by Using Majority Voting
 An Approach to Detect Spam Emails by Using Majority Voting Roohi Hussain Department of Computer Engineering, National University of Science and Technology, H-12 Islamabad, Pakistan Usman Qamar Faculty,
An Approach to Detect Spam Emails by Using Majority Voting Roohi Hussain Department of Computer Engineering, National University of Science and Technology, H-12 Islamabad, Pakistan Usman Qamar Faculty,
A MACHINE LEARNING APPROACH TO SERVER-SIDE ANTI-SPAM E-MAIL FILTERING 1 2
 UDC 004.75 A MACHINE LEARNING APPROACH TO SERVER-SIDE ANTI-SPAM E-MAIL FILTERING 1 2 I. Mashechkin, M. Petrovskiy, A. Rozinkin, S. Gerasimov Computer Science Department, Lomonosov Moscow State University,
UDC 004.75 A MACHINE LEARNING APPROACH TO SERVER-SIDE ANTI-SPAM E-MAIL FILTERING 1 2 I. Mashechkin, M. Petrovskiy, A. Rozinkin, S. Gerasimov Computer Science Department, Lomonosov Moscow State University,
Developing Methods and Heuristics with Low Time Complexities for Filtering Spam Messages
 Developing Methods and Heuristics with Low Time Complexities for Filtering Spam Messages Tunga Güngör and Ali Çıltık Boğaziçi University, Computer Engineering Department, Bebek, 34342 İstanbul, Turkey
Developing Methods and Heuristics with Low Time Complexities for Filtering Spam Messages Tunga Güngör and Ali Çıltık Boğaziçi University, Computer Engineering Department, Bebek, 34342 İstanbul, Turkey
Impact of Feature Selection Technique on Email Classification
 Impact of Feature Selection Technique on Email Classification Aakanksha Sharaff, Naresh Kumar Nagwani, and Kunal Swami Abstract Being one of the most powerful and fastest way of communication, the popularity
Impact of Feature Selection Technique on Email Classification Aakanksha Sharaff, Naresh Kumar Nagwani, and Kunal Swami Abstract Being one of the most powerful and fastest way of communication, the popularity
Single-Class Learning for Spam Filtering: An Ensemble Approach
 Single-Class Learning for Spam Filtering: An Ensemble Approach Tsang-Hsiang Cheng Department of Business Administration Southern Taiwan University of Technology Tainan, Taiwan, R.O.C. Chih-Ping Wei Institute
Single-Class Learning for Spam Filtering: An Ensemble Approach Tsang-Hsiang Cheng Department of Business Administration Southern Taiwan University of Technology Tainan, Taiwan, R.O.C. Chih-Ping Wei Institute
On Attacking Statistical Spam Filters
 On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Abstract. The efforts of anti-spammers
On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Abstract. The efforts of anti-spammers
SVM-Based Spam Filter with Active and Online Learning
 SVM-Based Spam Filter with Active and Online Learning Qiang Wang Yi Guan Xiaolong Wang School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China Email:{qwang, guanyi,
SVM-Based Spam Filter with Active and Online Learning Qiang Wang Yi Guan Xiaolong Wang School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China Email:{qwang, guanyi,
Using Online Linear Classifiers to Filter Spam Emails
 BIN WANG 1,2 GARETH J.F. JONES 2 WENFENG PAN 1 Using Online Linear Classifiers to Filter Spam Emails 1 Institute of Computing Technology, Chinese Academy of Sciences, China 2 School of Computing, Dublin
BIN WANG 1,2 GARETH J.F. JONES 2 WENFENG PAN 1 Using Online Linear Classifiers to Filter Spam Emails 1 Institute of Computing Technology, Chinese Academy of Sciences, China 2 School of Computing, Dublin
Three types of messages: A, B, C. Assume A is the oldest type, and C is the most recent type.
 Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Spam Detection System Combining Cellular Automata and Naive Bayes Classifier
 Spam Detection System Combining Cellular Automata and Naive Bayes Classifier F. Barigou*, N. Barigou**, B. Atmani*** Computer Science Department, Faculty of Sciences, University of Oran BP 1524, El M Naouer,
Spam Detection System Combining Cellular Automata and Naive Bayes Classifier F. Barigou*, N. Barigou**, B. Atmani*** Computer Science Department, Faculty of Sciences, University of Oran BP 1524, El M Naouer,
Non-Parametric Spam Filtering based on knn and LSA
 Non-Parametric Spam Filtering based on knn and LSA Preslav Ivanov Nakov Panayot Markov Dobrikov Abstract. The paper proposes a non-parametric approach to filtering of unsolicited commercial e-mail messages,
Non-Parametric Spam Filtering based on knn and LSA Preslav Ivanov Nakov Panayot Markov Dobrikov Abstract. The paper proposes a non-parametric approach to filtering of unsolicited commercial e-mail messages,
Combining Global and Personal Anti-Spam Filtering
 Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
Combining Global and Personal Anti-Spam Filtering Richard Segal IBM Research Hawthorne, NY 10532 Abstract Many of the first successful applications of statistical learning to anti-spam filtering were personalized
An Efficient Spam Filtering Techniques for Email Account
 American Journal of Engineering Research (AJER) e-issn : 2320-0847 p-issn : 2320-0936 Volume-02, Issue-10, pp-63-73 www.ajer.org Research Paper Open Access An Efficient Spam Filtering Techniques for Email
American Journal of Engineering Research (AJER) e-issn : 2320-0847 p-issn : 2320-0936 Volume-02, Issue-10, pp-63-73 www.ajer.org Research Paper Open Access An Efficient Spam Filtering Techniques for Email
Combining SVM classifiers for email anti-spam filtering
 Combining SVM classifiers for email anti-spam filtering Ángela Blanco Manuel Martín-Merino Abstract Spam, also known as Unsolicited Commercial Email (UCE) is becoming a nightmare for Internet users and
Combining SVM classifiers for email anti-spam filtering Ángela Blanco Manuel Martín-Merino Abstract Spam, also known as Unsolicited Commercial Email (UCE) is becoming a nightmare for Internet users and
Batch and On-line Spam Filter Comparison
 Batch and On-line Spam Filter Comparison Gordon V. Cormack David R. Cheriton School of Computer Science University of Waterloo Waterloo, Ontario N2L 3G1, Canada gvcormac@uwaterloo.ca Andrej Bratko Department
Batch and On-line Spam Filter Comparison Gordon V. Cormack David R. Cheriton School of Computer Science University of Waterloo Waterloo, Ontario N2L 3G1, Canada gvcormac@uwaterloo.ca Andrej Bratko Department
Bayesian Spam Detection
 Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Scholarly Horizons: University of Minnesota, Morris Undergraduate Journal Volume 2 Issue 1 Article 2 2015 Bayesian Spam Detection Jeremy J. Eberhardt University or Minnesota, Morris Follow this and additional
Spam or Not Spam That is the question
 Spam or Not Spam That is the question Ravi Kiran S S and Indriyati Atmosukarto {kiran,indria}@cs.washington.edu Abstract Unsolicited commercial email, commonly known as spam has been known to pollute the
Spam or Not Spam That is the question Ravi Kiran S S and Indriyati Atmosukarto {kiran,indria}@cs.washington.edu Abstract Unsolicited commercial email, commonly known as spam has been known to pollute the
ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift
 ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift Sarah Jane Delany 1 and Pádraig Cunningham 2 and Barry Smyth 3 Abstract. While text classification has been identified for some time
ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift Sarah Jane Delany 1 and Pádraig Cunningham 2 and Barry Smyth 3 Abstract. While text classification has been identified for some time
Naïve Bayesian Anti-spam Filtering Technique for Malay Language
 Naïve Bayesian Anti-spam Filtering Technique for Malay Language Thamarai Subramaniam 1, Hamid A. Jalab 2, Alaa Y. Taqa 3 1,2 Computer System and Technology Department, Faulty of Computer Science and Information
Naïve Bayesian Anti-spam Filtering Technique for Malay Language Thamarai Subramaniam 1, Hamid A. Jalab 2, Alaa Y. Taqa 3 1,2 Computer System and Technology Department, Faulty of Computer Science and Information
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Spam Filtering Based On The Analysis Of Text Information Embedded Into Images
 Journal of Machine Learning Research 7 (2006) 2699-2720 Submitted 3/06; Revised 9/06; Published 12/06 Spam Filtering Based On The Analysis Of Text Information Embedded Into Images Giorgio Fumera Ignazio
Journal of Machine Learning Research 7 (2006) 2699-2720 Submitted 3/06; Revised 9/06; Published 12/06 Spam Filtering Based On The Analysis Of Text Information Embedded Into Images Giorgio Fumera Ignazio
A Personalized Spam Filtering Approach Utilizing Two Separately Trained Filters
 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology A Personalized Spam Filtering Approach Utilizing Two Separately Trained Filters Wei-Lun Teng, Wei-Chung Teng
2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology A Personalized Spam Filtering Approach Utilizing Two Separately Trained Filters Wei-Lun Teng, Wei-Chung Teng
IMPROVING SPAM EMAIL FILTERING EFFICIENCY USING BAYESIAN BACKWARD APPROACH PROJECT
 IMPROVING SPAM EMAIL FILTERING EFFICIENCY USING BAYESIAN BACKWARD APPROACH PROJECT M.SHESHIKALA Assistant Professor, SREC Engineering College,Warangal Email: marthakala08@gmail.com, Abstract- Unethical
IMPROVING SPAM EMAIL FILTERING EFFICIENCY USING BAYESIAN BACKWARD APPROACH PROJECT M.SHESHIKALA Assistant Professor, SREC Engineering College,Warangal Email: marthakala08@gmail.com, Abstract- Unethical
Detecting E-mail Spam Using Spam Word Associations
 Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 p10co977@coed.svnit.ac.in 2 dpr@coed.svnit.ac.in
Detecting E-mail Spam Using Spam Word Associations N.S. Kumar 1, D.P. Rana 2, R.G.Mehta 3 Sardar Vallabhbhai National Institute of Technology, Surat, India 1 p10co977@coed.svnit.ac.in 2 dpr@coed.svnit.ac.in
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift
 ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift Sarah Jane Delany 1 and Pádraig Cunningham 2 Abstract. While text classification has been identified for some time as a promising application
ECUE: A Spam Filter that Uses Machine Learning to Track Concept Drift Sarah Jane Delany 1 and Pádraig Cunningham 2 Abstract. While text classification has been identified for some time as a promising application
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Differential Voting in Case Based Spam Filtering
 Differential Voting in Case Based Spam Filtering Deepak P, Delip Rao, Deepak Khemani Department of Computer Science and Engineering Indian Institute of Technology Madras, India deepakswallet@gmail.com,
Differential Voting in Case Based Spam Filtering Deepak P, Delip Rao, Deepak Khemani Department of Computer Science and Engineering Indian Institute of Technology Madras, India deepakswallet@gmail.com,
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
Immunity from spam: an analysis of an artificial immune system for junk email detection
 Immunity from spam: an analysis of an artificial immune system for junk email detection Terri Oda and Tony White Carleton University, Ottawa ON, Canada terri@zone12.com, arpwhite@scs.carleton.ca Abstract.
Immunity from spam: an analysis of an artificial immune system for junk email detection Terri Oda and Tony White Carleton University, Ottawa ON, Canada terri@zone12.com, arpwhite@scs.carleton.ca Abstract.
SpamNet Spam Detection Using PCA and Neural Networks
 SpamNet Spam Detection Using PCA and Neural Networks Abhimanyu Lad B.Tech. (I.T.) 4 th year student Indian Institute of Information Technology, Allahabad Deoghat, Jhalwa, Allahabad, India abhimanyulad@iiita.ac.in
SpamNet Spam Detection Using PCA and Neural Networks Abhimanyu Lad B.Tech. (I.T.) 4 th year student Indian Institute of Information Technology, Allahabad Deoghat, Jhalwa, Allahabad, India abhimanyulad@iiita.ac.in
A Proposed Algorithm for Spam Filtering Emails by Hash Table Approach
 International Research Journal of Applied and Basic Sciences 2013 Available online at www.irjabs.com ISSN 2251-838X / Vol, 4 (9): 2436-2441 Science Explorer Publications A Proposed Algorithm for Spam Filtering
International Research Journal of Applied and Basic Sciences 2013 Available online at www.irjabs.com ISSN 2251-838X / Vol, 4 (9): 2436-2441 Science Explorer Publications A Proposed Algorithm for Spam Filtering
Spam Filtering with Naive Bayesian Classification
 Spam Filtering with Naive Bayesian Classification Khuong An Nguyen Queens College University of Cambridge L101: Machine Learning for Language Processing MPhil in Advanced Computer Science 09-April-2011
Spam Filtering with Naive Bayesian Classification Khuong An Nguyen Queens College University of Cambridge L101: Machine Learning for Language Processing MPhil in Advanced Computer Science 09-April-2011
Tweaking Naïve Bayes classifier for intelligent spam detection
 682 Tweaking Naïve Bayes classifier for intelligent spam detection Ankita Raturi 1 and Sunil Pranit Lal 2 1 University of California, Irvine, CA 92697, USA. araturi@uci.edu 2 School of Computing, Information
682 Tweaking Naïve Bayes classifier for intelligent spam detection Ankita Raturi 1 and Sunil Pranit Lal 2 1 University of California, Irvine, CA 92697, USA. araturi@uci.edu 2 School of Computing, Information
Partitioned Logistic Regression for Spam Filtering
 Partitioned Logistic Regression for Spam Filtering Ming-wei Chang University of Illinois 201 N Goodwin Ave Urbana, IL, USA mchang21@uiuc.edu Wen-tau Yih Microsoft Research One Microsoft Way Redmond, WA,
Partitioned Logistic Regression for Spam Filtering Ming-wei Chang University of Illinois 201 N Goodwin Ave Urbana, IL, USA mchang21@uiuc.edu Wen-tau Yih Microsoft Research One Microsoft Way Redmond, WA,
Email Classification Using Data Reduction Method
 Email Classification Using Data Reduction Method Rafiqul Islam and Yang Xiang, member IEEE School of Information Technology Deakin University, Burwood 3125, Victoria, Australia Abstract Classifying user
Email Classification Using Data Reduction Method Rafiqul Islam and Yang Xiang, member IEEE School of Information Technology Deakin University, Burwood 3125, Victoria, Australia Abstract Classifying user
Lan, Mingjun and Zhou, Wanlei 2005, Spam filtering based on preference ranking, in Fifth International Conference on Computer and Information
 Lan, Mingjun and Zhou, Wanlei 2005, Spam filtering based on preference ranking, in Fifth International Conference on Computer and Information Technology : CIT 2005 : proceedings : 21-23 September, 2005,
Lan, Mingjun and Zhou, Wanlei 2005, Spam filtering based on preference ranking, in Fifth International Conference on Computer and Information Technology : CIT 2005 : proceedings : 21-23 September, 2005,
Effectiveness and Limitations of Statistical Spam Filters
 Effectiveness and Limitations of Statistical Spam Filters M. Tariq Banday, Lifetime Member, CSI P.G. Department of Electronics and Instrumentation Technology University of Kashmir, Srinagar, India Abstract
Effectiveness and Limitations of Statistical Spam Filters M. Tariq Banday, Lifetime Member, CSI P.G. Department of Electronics and Instrumentation Technology University of Kashmir, Srinagar, India Abstract
How To Filter Spam With A Poa
 A Multiobjective Evolutionary Algorithm for Spam E-mail Filtering A.G. López-Herrera 1, E. Herrera-Viedma 2, F. Herrera 2 1.Dept. of Computer Sciences, University of Jaén, E-23071, Jaén (Spain), aglopez@ujaen.es
A Multiobjective Evolutionary Algorithm for Spam E-mail Filtering A.G. López-Herrera 1, E. Herrera-Viedma 2, F. Herrera 2 1.Dept. of Computer Sciences, University of Jaén, E-23071, Jaén (Spain), aglopez@ujaen.es
Enrique Puertas Sánz Francisco Carrero García Universidad Europea de Madrid Villaviciosa de Odón 28670 Madrid, SPAIN 34 91 211 5611
 José María Gómez Hidalgo Universidad Europea de Madrid Villaviciosa de Odón 28670 Madrid, SPAIN 34 91 211 5670 jmgomez@uem.es Content Based SMS Spam Filtering Guillermo Cajigas Bringas Group R&D - Vodafone
José María Gómez Hidalgo Universidad Europea de Madrid Villaviciosa de Odón 28670 Madrid, SPAIN 34 91 211 5670 jmgomez@uem.es Content Based SMS Spam Filtering Guillermo Cajigas Bringas Group R&D - Vodafone
A Case-Based Approach to Spam Filtering that Can Track Concept Drift
 A Case-Based Approach to Spam Filtering that Can Track Concept Drift Pádraig Cunningham 1, Niamh Nowlan 1, Sarah Jane Delany 2, Mads Haahr 1 1 Department of Computer Science, Trinity College Dublin 2 School
A Case-Based Approach to Spam Filtering that Can Track Concept Drift Pádraig Cunningham 1, Niamh Nowlan 1, Sarah Jane Delany 2, Mads Haahr 1 1 Department of Computer Science, Trinity College Dublin 2 School
A Memory-Based Approach to Anti-Spam Filtering for Mailing Lists
 Information Retrieval, 6, 49 73, 2003 c 2003 Kluwer Academic Publishers. Manufactured in The Netherlands. A Memory-Based Approach to Anti-Spam Filtering for Mailing Lists GEORGIOS SAKKIS gsakis@iit.demokritos.gr
Information Retrieval, 6, 49 73, 2003 c 2003 Kluwer Academic Publishers. Manufactured in The Netherlands. A Memory-Based Approach to Anti-Spam Filtering for Mailing Lists GEORGIOS SAKKIS gsakis@iit.demokritos.gr
Increasing the Accuracy of a Spam-Detecting Artificial Immune System
 Increasing the Accuracy of a Spam-Detecting Artificial Immune System Terri Oda Carleton University terri@zone12.com Tony White Carleton University arpwhite@scs.carleton.ca Abstract- Spam, the electronic
Increasing the Accuracy of a Spam-Detecting Artificial Immune System Terri Oda Carleton University terri@zone12.com Tony White Carleton University arpwhite@scs.carleton.ca Abstract- Spam, the electronic
Not So Naïve Online Bayesian Spam Filter
 Not So Naïve Online Bayesian Spam Filter Baojun Su Institute of Artificial Intelligence College of Computer Science Zhejiang University Hangzhou 310027, China freizsu@gmail.com Congfu Xu Institute of Artificial
Not So Naïve Online Bayesian Spam Filter Baojun Su Institute of Artificial Intelligence College of Computer Science Zhejiang University Hangzhou 310027, China freizsu@gmail.com Congfu Xu Institute of Artificial
An Efficient Three-phase Email Spam Filtering Technique
 An Efficient Three-phase Email Filtering Technique Tarek M. Mahmoud 1 *, Alaa Ismail El-Nashar 2 *, Tarek Abd-El-Hafeez 3 *, Marwa Khairy 4 * 1, 2, 3 Faculty of science, Computer Sci. Dept., Minia University,
An Efficient Three-phase Email Filtering Technique Tarek M. Mahmoud 1 *, Alaa Ismail El-Nashar 2 *, Tarek Abd-El-Hafeez 3 *, Marwa Khairy 4 * 1, 2, 3 Faculty of science, Computer Sci. Dept., Minia University,
A Collaborative Approach for Spam Detection
 A Collaborative Approach for Spam Detection Pedro Sousa, Artur Machado, Miguel Rocha Dept. of Informatics University of Minho Braga, Portugal pns@di.uminho.pt, ajpcm1@gmail.com, mrocha@di.uminho.pt Paulo
A Collaborative Approach for Spam Detection Pedro Sousa, Artur Machado, Miguel Rocha Dept. of Informatics University of Minho Braga, Portugal pns@di.uminho.pt, ajpcm1@gmail.com, mrocha@di.uminho.pt Paulo
An incremental cluster-based approach to spam filtering
 Available online at www.sciencedirect.com Expert Systems with Applications Expert Systems with Applications 34 (2008) 1599 1608 www.elsevier.com/locate/eswa An incremental cluster-based approach to spam
Available online at www.sciencedirect.com Expert Systems with Applications Expert Systems with Applications 34 (2008) 1599 1608 www.elsevier.com/locate/eswa An incremental cluster-based approach to spam
Journal of Information Technology Impact
 Journal of Information Technology Impact Vol. 8, No., pp. -0, 2008 Probability Modeling for Improving Spam Filtering Parameters S. C. Chiemeke University of Benin Nigeria O. B. Longe 2 University of Ibadan
Journal of Information Technology Impact Vol. 8, No., pp. -0, 2008 Probability Modeling for Improving Spam Filtering Parameters S. C. Chiemeke University of Benin Nigeria O. B. Longe 2 University of Ibadan
Representation of Electronic Mail Filtering Profiles: A User Study
 Representation of Electronic Mail Filtering Profiles: A User Study Michael J. Pazzani Department of Information and Computer Science University of California, Irvine Irvine, CA 92697 +1 949 824 5888 pazzani@ics.uci.edu
Representation of Electronic Mail Filtering Profiles: A User Study Michael J. Pazzani Department of Information and Computer Science University of California, Irvine Irvine, CA 92697 +1 949 824 5888 pazzani@ics.uci.edu
Machine Learning for Naive Bayesian Spam Filter Tokenization
 Machine Learning for Naive Bayesian Spam Filter Tokenization Michael Bevilacqua-Linn December 20, 2003 Abstract Background Traditional client level spam filters rely on rule based heuristics. While these
Machine Learning for Naive Bayesian Spam Filter Tokenization Michael Bevilacqua-Linn December 20, 2003 Abstract Background Traditional client level spam filters rely on rule based heuristics. While these
Learning to classify e-mail
 Information Sciences 177 (2007) 2167 2187 www.elsevier.com/locate/ins Learning to classify e-mail Irena Koprinska *, Josiah Poon, James Clark, Jason Chan School of Information Technologies, The University
Information Sciences 177 (2007) 2167 2187 www.elsevier.com/locate/ins Learning to classify e-mail Irena Koprinska *, Josiah Poon, James Clark, Jason Chan School of Information Technologies, The University
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier. Santosh Tirunagari : 245577
 T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
T-61.3050 : Email Classification as Spam or Ham using Naive Bayes Classifier Santosh Tirunagari : 245577 January 20, 2011 Abstract This term project gives a solution how to classify an email as spam or
Sender and Receiver Addresses as Cues for Anti-Spam Filtering Chih-Chien Wang
 Sender and Receiver Addresses as Cues for Anti-Spam Filtering Chih-Chien Wang Graduate Institute of Information Management National Taipei University 69, Sec. 2, JianGuo N. Rd., Taipei City 104-33, Taiwan
Sender and Receiver Addresses as Cues for Anti-Spam Filtering Chih-Chien Wang Graduate Institute of Information Management National Taipei University 69, Sec. 2, JianGuo N. Rd., Taipei City 104-33, Taiwan
Anti-Spam Filter Based on Naïve Bayes, SVM, and KNN model
 AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
AI TERM PROJECT GROUP 14 1 Anti-Spam Filter Based on,, and model Yun-Nung Chen, Che-An Lu, Chao-Yu Huang Abstract spam email filters are a well-known and powerful type of filters. We construct different
How To Filter Spam Image From A Picture By Color Or Color
 Image Content-Based Email Spam Image Filtering Jianyi Wang and Kazuki Katagishi Abstract With the population of Internet around the world, email has become one of the main methods of communication among
Image Content-Based Email Spam Image Filtering Jianyi Wang and Kazuki Katagishi Abstract With the population of Internet around the world, email has become one of the main methods of communication among
Good Word Attacks on Statistical Spam Filters
 Good Word Attacks on Statistical Spam Filters Daniel Lowd Dept. of Computer Science and Engineering University of Washington Seattle, WA 98195-2350 lowd@cs.washington.edu Christopher Meek Microsoft Research
Good Word Attacks on Statistical Spam Filters Daniel Lowd Dept. of Computer Science and Engineering University of Washington Seattle, WA 98195-2350 lowd@cs.washington.edu Christopher Meek Microsoft Research
An Evaluation of Statistical Spam Filtering Techniques
 An Evaluation of Statistical Spam Filtering Techniques Le Zhang, Jingbo Zhu, Tianshun Yao Natural Language Processing Laboratory Institute of Computer Software & Theory Northeastern University, China ejoy@xinhuanet.com,
An Evaluation of Statistical Spam Filtering Techniques Le Zhang, Jingbo Zhu, Tianshun Yao Natural Language Processing Laboratory Institute of Computer Software & Theory Northeastern University, China ejoy@xinhuanet.com,
The Enron Corpus: A New Dataset for Email Classification Research
 The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
The Enron Corpus: A New Dataset for Email Classification Research Bryan Klimt and Yiming Yang Language Technologies Institute Carnegie Mellon University Pittsburgh, PA 15213-8213, USA {bklimt,yiming}@cs.cmu.edu
Filtering Spams using the Minimum Description Length Principle
 Filtering Spams using the Minimum Description Length Principle ABSTRACT Tiago A. Almeida, Akebo Yamakami School of Electrical and Computer Engineering University of Campinas UNICAMP 13083 970, Campinas,
Filtering Spams using the Minimum Description Length Principle ABSTRACT Tiago A. Almeida, Akebo Yamakami School of Electrical and Computer Engineering University of Campinas UNICAMP 13083 970, Campinas,
A Game Theoretical Framework for Adversarial Learning
 A Game Theoretical Framework for Adversarial Learning Murat Kantarcioglu University of Texas at Dallas Richardson, TX 75083, USA muratk@utdallas Chris Clifton Purdue University West Lafayette, IN 47907,
A Game Theoretical Framework for Adversarial Learning Murat Kantarcioglu University of Texas at Dallas Richardson, TX 75083, USA muratk@utdallas Chris Clifton Purdue University West Lafayette, IN 47907,
Asymmetric Gradient Boosting with Application to Spam Filtering
 Asymmetric Gradient Boosting with Application to Spam Filtering Jingrui He Carnegie Mellon University 5 Forbes Avenue Pittsburgh, PA 523 USA jingruih@cs.cmu.edu ABSTRACT In this paper, we propose a new
Asymmetric Gradient Boosting with Application to Spam Filtering Jingrui He Carnegie Mellon University 5 Forbes Avenue Pittsburgh, PA 523 USA jingruih@cs.cmu.edu ABSTRACT In this paper, we propose a new
A Comparison of Event Models for Naive Bayes Text Classification
 A Comparison of Event Models for Naive Bayes Text Classification Andrew McCallum mccallum@justresearch.com Just Research 4616 Henry Street Pittsburgh, PA 15213 Kamal Nigam knigam@cs.cmu.edu School of Computer
A Comparison of Event Models for Naive Bayes Text Classification Andrew McCallum mccallum@justresearch.com Just Research 4616 Henry Street Pittsburgh, PA 15213 Kamal Nigam knigam@cs.cmu.edu School of Computer
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier
 A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
Efficient Spam Email Filtering using Adaptive Ontology
 Efficient Spam Email Filtering using Adaptive Ontology Seongwook Youn and Dennis McLeod Computer Science Department, University of Southern California Los Angeles, CA 90089, USA {syoun, mcleod}@usc.edu
Efficient Spam Email Filtering using Adaptive Ontology Seongwook Youn and Dennis McLeod Computer Science Department, University of Southern California Los Angeles, CA 90089, USA {syoun, mcleod}@usc.edu
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
Towards better accuracy for Spam predictions
 Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 czhao@cs.toronto.edu Abstract Spam identification is crucial
Towards better accuracy for Spam predictions Chengyan Zhao Department of Computer Science University of Toronto Toronto, Ontario, Canada M5S 2E4 czhao@cs.toronto.edu Abstract Spam identification is crucial
Image Spam Filtering by Content Obscuring Detection
 Image Spam Filtering by Content Obscuring Detection Battista Biggio, Giorgio Fumera, Ignazio Pillai, Fabio Roli Dept. of Electrical and Electronic Eng., University of Cagliari Piazza d Armi, 09123 Cagliari,
Image Spam Filtering by Content Obscuring Detection Battista Biggio, Giorgio Fumera, Ignazio Pillai, Fabio Roli Dept. of Electrical and Electronic Eng., University of Cagliari Piazza d Armi, 09123 Cagliari,
On Attacking Statistical Spam Filters
 On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Paper review by Deepak Chinavle
On Attacking Statistical Spam Filters Gregory L. Wittel and S. Felix Wu Department of Computer Science University of California, Davis One Shields Avenue, Davis, CA 95616 USA Paper review by Deepak Chinavle
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Learning to Recognize Missing E-mail Attachments
 Learning to Recognize Missing E-mail Attachments Technical Report TUD KE 2009-05 Marco Ghiglieri, Johannes Fürnkranz Knowledge Engineering Group, Technische Universität Darmstadt Knowledge Engineering
Learning to Recognize Missing E-mail Attachments Technical Report TUD KE 2009-05 Marco Ghiglieri, Johannes Fürnkranz Knowledge Engineering Group, Technische Universität Darmstadt Knowledge Engineering
An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them
 An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them Vangelis Karkaletsis and Constantine D. Spyropoulos NCSR Demokritos, Institute of Informatics & Telecommunications,
An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them Vangelis Karkaletsis and Constantine D. Spyropoulos NCSR Demokritos, Institute of Informatics & Telecommunications,
Shafzon@yahool.com. Keywords - Algorithm, Artificial immune system, E-mail Classification, Non-Spam, Spam
 An Improved AIS Based E-mail Classification Technique for Spam Detection Ismaila Idris Dept of Cyber Security Science, Fed. Uni. Of Tech. Minna, Niger State Idris.ismaila95@gmail.com Abdulhamid Shafi i
An Improved AIS Based E-mail Classification Technique for Spam Detection Ismaila Idris Dept of Cyber Security Science, Fed. Uni. Of Tech. Minna, Niger State Idris.ismaila95@gmail.com Abdulhamid Shafi i
Getting Even More Out of Ensemble Selection
 Getting Even More Out of Ensemble Selection Quan Sun Department of Computer Science The University of Waikato Hamilton, New Zealand qs12@cs.waikato.ac.nz ABSTRACT Ensemble Selection uses forward stepwise
Getting Even More Out of Ensemble Selection Quan Sun Department of Computer Science The University of Waikato Hamilton, New Zealand qs12@cs.waikato.ac.nz ABSTRACT Ensemble Selection uses forward stepwise
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Feature Subset Selection in E-mail Spam Detection
 Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
Feature Subset Selection in E-mail Spam Detection Amir Rajabi Behjat, Universiti Technology MARA, Malaysia IT Security for the Next Generation Asia Pacific & MEA Cup, Hong Kong 14-16 March, 2012 Feature
Predicting the Stock Market with News Articles
 Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Predicting the Stock Market with News Articles Kari Lee and Ryan Timmons CS224N Final Project Introduction Stock market prediction is an area of extreme importance to an entire industry. Stock price is
Dr. D. Y. Patil College of Engineering, Ambi,. University of Pune, M.S, India University of Pune, M.S, India
 Volume 4, Issue 6, June 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Effective Email
Volume 4, Issue 6, June 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Effective Email
The Optimality of Naive Bayes
 The Optimality of Naive Bayes Harry Zhang Faculty of Computer Science University of New Brunswick Fredericton, New Brunswick, Canada email: hzhang@unbca E3B 5A3 Abstract Naive Bayes is one of the most
The Optimality of Naive Bayes Harry Zhang Faculty of Computer Science University of New Brunswick Fredericton, New Brunswick, Canada email: hzhang@unbca E3B 5A3 Abstract Naive Bayes is one of the most
Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing and Developing E-mail Classifier
 International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
International Journal of Recent Technology and Engineering (IJRTE) ISSN: 2277-3878, Volume-1, Issue-6, January 2013 Artificial Neural Network, Decision Tree and Statistical Techniques Applied for Designing
1 Introductory Comments. 2 Bayesian Probability
 Introductory Comments First, I would like to point out that I got this material from two sources: The first was a page from Paul Graham s website at www.paulgraham.com/ffb.html, and the second was a paper
Introductory Comments First, I would like to point out that I got this material from two sources: The first was a page from Paul Graham s website at www.paulgraham.com/ffb.html, and the second was a paper
Using Biased Discriminant Analysis for Email Filtering
 Using Biased Discriminant Analysis for Email Filtering Juan Carlos Gomez 1 and Marie-Francine Moens 2 1 ITESM, Eugenio Garza Sada 2501, Monterrey NL 64849, Mexico juancarlos.gomez@invitados.itesm.mx 2
Using Biased Discriminant Analysis for Email Filtering Juan Carlos Gomez 1 and Marie-Francine Moens 2 1 ITESM, Eugenio Garza Sada 2501, Monterrey NL 64849, Mexico juancarlos.gomez@invitados.itesm.mx 2
Relaxed Online SVMs for Spam Filtering
 Relaxed Online SVMs for Spam Filtering D. Sculley Tufts University Department of Computer Science 161 College Ave., Medford, MA USA dsculleycs.tufts.edu Gabriel M. Wachman Tufts University Department of
Relaxed Online SVMs for Spam Filtering D. Sculley Tufts University Department of Computer Science 161 College Ave., Medford, MA USA dsculleycs.tufts.edu Gabriel M. Wachman Tufts University Department of
A Comparison of Event Models for Naive Bayes Anti-Spam E-Mail Filtering
 A Comparison of Event Models for Naive Bayes Anti-Spam E-Mail Filtering Karl-Michael Schneider University of Passau Department of General Linguistics Innstr. 40, D-94032 Passau schneide@phil.uni passau.de
A Comparison of Event Models for Naive Bayes Anti-Spam E-Mail Filtering Karl-Michael Schneider University of Passau Department of General Linguistics Innstr. 40, D-94032 Passau schneide@phil.uni passau.de
A Three-Way Decision Approach to Email Spam Filtering
 A Three-Way Decision Approach to Email Spam Filtering Bing Zhou, Yiyu Yao, and Jigang Luo Department of Computer Science, University of Regina Regina, Saskatchewan, Canada S4S 0A2 {zhou200b,yyao,luo226}@cs.uregina.ca
A Three-Way Decision Approach to Email Spam Filtering Bing Zhou, Yiyu Yao, and Jigang Luo Department of Computer Science, University of Regina Regina, Saskatchewan, Canada S4S 0A2 {zhou200b,yyao,luo226}@cs.uregina.ca
Filtering Spam E-Mail from Mixed Arabic and English Messages: A Comparison of Machine Learning Techniques
 52 The International Arab Journal of Information Technology, Vol. 6, No. 1, January 2009 Filtering Spam E-Mail from Mixed Arabic and English Messages: A Comparison of Machine Learning Techniques Alaa El-Halees
52 The International Arab Journal of Information Technology, Vol. 6, No. 1, January 2009 Filtering Spam E-Mail from Mixed Arabic and English Messages: A Comparison of Machine Learning Techniques Alaa El-Halees
Cosdes: A Collaborative Spam Detection System with a Novel E- Mail Abstraction Scheme
 IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 9 (September 2012), PP 55-60 Cosdes: A Collaborative Spam Detection System with a Novel E- Mail Abstraction Scheme
IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719, Volume 2, Issue 9 (September 2012), PP 55-60 Cosdes: A Collaborative Spam Detection System with a Novel E- Mail Abstraction Scheme
Email Filters that use Spammy Words Only
 Email Filters that use Spammy Words Only Vasanth Elavarasan Department of Computer Science University of Texas at Austin Advisors: Mohamed Gouda Department of Computer Science University of Texas at Austin
Email Filters that use Spammy Words Only Vasanth Elavarasan Department of Computer Science University of Texas at Austin Advisors: Mohamed Gouda Department of Computer Science University of Texas at Austin
Roulette Sampling for Cost-Sensitive Learning
 Roulette Sampling for Cost-Sensitive Learning Victor S. Sheng and Charles X. Ling Department of Computer Science, University of Western Ontario, London, Ontario, Canada N6A 5B7 {ssheng,cling}@csd.uwo.ca
Roulette Sampling for Cost-Sensitive Learning Victor S. Sheng and Charles X. Ling Department of Computer Science, University of Western Ontario, London, Ontario, Canada N6A 5B7 {ssheng,cling}@csd.uwo.ca
A Content based Spam Filtering Using Optical Back Propagation Technique
 A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT
A Content based Spam Filtering Using Optical Back Propagation Technique Sarab M. Hameed 1, Noor Alhuda J. Mohammed 2 Department of Computer Science, College of Science, University of Baghdad - Iraq ABSTRACT