CSCI2100B Data Structures Hashing
|
|
|
- Liliana Cobb
- 7 years ago
- Views:
Transcription
1 CSCI2100B Data Structures Hashing Irwin King Department of Computer Science & Engineering The Chinese University of Hong Kong
2 Introduction Hashing is a technique used for performing insertions, deletions and finds in constant average time. Tree operations that require any ordering information among the elements are not supported efficiently. See several methods of implementing the hash table. Compare these methods analytically. Show numerous applications of hashing. Compare hash tables with binary search trees.
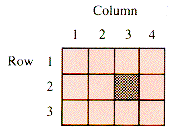
3 Rectangular Arrays
4 Row- and Column-Major Ordering How does one index an entry in an array? Entry [i,j] goes to position ni+j for row-major ordering and i+jm for column-major ordering when the rows are numbered from 0 to m-1 and the columns from 0 to n-1 and entry [0,0] is at position 0.
5 Row- and Column-Major Example

6 Example


7 Implementation Example
8 More Implementation Example
9 3D Array Implementation
10 3-D Array Implementation
11 Problem In some applications the full use of the whole array is seldom. This leads to sparse array or matrix representation. For example, population count in a 2-D grid map.
12 An Access Table One method to eliminate the multiplications needed in calculating the index to an entry is to use an access table. The array will contain the values 0, n, 2 n, 3 n,..., (m-1) n. Then for all references to the rectangular array, the index for [i,j] is calculated by taking the entry in position i of the auxiliary table, adding j, and going to the resulting position. Again we see a trade-off between space used and execution speed.
13 Example
14 Example

15 Example
16 Tables: A New Abstract Data Type Functions: a function is defined in terms of two sets and a correspondence from elements of the first set to elements of the second. If f is a function from a set A to a set B, then f assigns to each element of A a unique elements of B. The set A is called the domain of f, and the set B is called the codomain of f. The subset of B containing just those element that occur as values of f is called the range of f.
17 Example For a table, we call the domain the index set, and we call the codomain the base type or value type. For example, to index into the cell [2,3] the offset value may be 13 if the matrix size is [10,10].
18 An Abstract Data Type A table with index set I and base type T is a function from I into T together with the following operations. Table access: Evaluate the function at any index in I. Table assignment: Modify the function by changing its value at a specified index in I to the new value specified in the assignment.
19 An Abstract Data Type Insertion: Adjoin a new element x to the index set I and define a corresponding value of the function at x. Deletion: Delete an element x from the index set I and restrict the function to the resulting smaller domain.
20 Why Hash Table? Often, array indices are not natural identifiers for items that are to be stored, accessed, and retrieved. For example, let s try to store the list in an array. beef bellpepper blackpepper dillweed onion potato olive salt cumin carrot mushroom tomatopaste
21 Problem While it is true that STORE and RETRIEVE are O(1) operations for arrays, that is only so if the indices are known and the value in the target of a STORE can be discarded. Without a complete set in hand it cannot be known that potato has index 10 in the sorted list of items.
22 Solution Use item as a KEY--Because an index integer is not known on the entry of one of the items, it would be helpful if the item itself could be used as a key to index the cell where it will be stored.
23 Solution A solution would be to convert the keys (the list items, here) into unique integers and use them as array indices. A function that does so is called a hash function. The conversion process is called hashing The storage structure is called a hash table or scatterstorage.
24 Example Solution We may sum up the ASCII value from each character in the key, e.g., a = 1, b=2,, z = 26, so beef = =18. Item HF1(Item) Item HF1(Item) beef 18 carrot 75 onion 67 salt 52 cumin 60 blackpepper 105 dillweed 74 olive 63 bellpepper 107 tomatopaste 145 potato 87 mushroom 122
25 Introduction to Hashing Hashing is a technique used for performing insertions, deletions and finds in constant average time. Tree operations that require any ordering information among the elements are not supported efficiently. See several methods of implementing the hash table. Compare these methods analytically. Show numerous applications of hashing. Compare hash tables with binary search trees.
26 General Idea Hash table data structure is merely an array of some fixed size, containing the keys. A key is a string with an associated value (for instance, salary information). Each key is mapped into some number in the range 0 to H_SIZE - 1 and placed in the appropriate cell. f : key value
27 General Idea The mapping is called a hash function, which ideally should be simple to compute and should ensure that any two distinct keys get different cells. This is difficult to achieve in reality since there are a finite number of cells and a virtually inexhaustible supply of keys. We seek a hash function that distributes the keys evenly among the cells.
28 Issues Choosing the hashing function How to make sure that one has selected a good function for the application Collision handling How to handle conflict when two keys have the same location Deletion handling How to deal with the table when items are being removed

29 Example
30 Hash Tables We can continue to exploit table lookup even in situations where the key is no longer an index that can be used directly as in array indexing. What we can do is to set up a one-to-one correspondence between the keys by which we wish to retrieve information and indices that we can use to access an array.
31 Hash Tables The idea of a hash table is to allow many of the different possible keys that might occur to be mapped to the same location in an array under the action of the index function. Others have called scatter-storage or keytransformation.
32 Hash Function A hash function that takes a key and maps it to some index in the array. Often, two records may want to go to the same location. Therefore, a collision may occur and a collision procedure must be devised to handle this.
33 Choosing a Hash Function The two principal criteria in selecting a hash function are that it should be easy and quick to compute and that it should achieve an even distribution of the keys that actually occur across the range of indices.
34 Hash Function If the input keys are integers, then simply returning key mod H_SIZE is generally a reasonable strategy. For example, student ID mod would be a reasonable strategy. It is usually a good idea to ensure that the table size is prime. When the input keys are random integers, then this function is simple to compute and also distributes the keys evenly.
35 A Simple Hash Function INDEX hash( char *key, unsigned int H_SIZE ) { unsigned int hash_val = 0; /*1*/ while( *key!= '\0' ) /*2*/ hash_val += *key++; /*3*/ return( hash_val % H_SIZE ); }
36 Another Hash Function INDEX hash( char *key, unsigned int H_SIZE ) { return ( ( key[0] + 27*key[1] + 729*key[2] ) % H_SIZE ); }
37 Notes Assuming key has at least two characters plus the NULL terminator. 27 represents the number of letters in the English alphabet, plus the blank. 729 is 272. This function only examines the first three characters, but if these are random, and the table size is 10,007, as before, then we would expect a reasonably equitable distribution.
38 Quick Analysis Unfortunately, English is not random. Although there are = 17,576 possible combinations of three characters (ignoring blanks), a check of a reasonably large on-line dictionary reveals that the number of different combinations is actually only 2,851. Even if none of these combinations collide, only 28% of the table can actually be hashed to.
39 A Good Hash Function INDEX hash( char *key, unsigned int H_SIZE ) { unsigned int hash_val = O; /*1*/ while( *key!= '\0' ) /*2*/ hash_val = ( hash_val << 5 ) + *key++; /*3*/ return( hash_val % H_SIZE ); }
40 Notes This hash function involves all characters in the key. It computes Key _ Size 1 i = 0 Key[Key _ Size i] 32 i The code computes a polynomial function (of 32) by use of Horner's rule. For instance, another way of computing h k = k k k 3 is by the formula h k = ((k 3 ) * 27 + k 2 ) * 27 + k 1. Horner's rule extends this to an nth degree polynomial.
41 Notes It is common to not use all the characters. The length and properties of the keys would influence the choice. The hash function might include a couple of characters from each field.
42 Truncation Ignore part of the key, and use the remaining part directly as the index (considering non-numeric fields as their numerical codes). Example: If the keys are eight-digit integers and the hash table has 1000 locations, then the first, second, and fifth digits from the right make the hash function, so that maps to 394. Truncation is a very fast method, but it often fails to distribute the keys evenly through the table.
43 Folding Partition the key into several parts and combine the parts in a convenient way (often using addition or multiplication) to obtain the index. For example, maps to = 1100, which is then truncated to 100.
44 Modular Arithmetic Convert the key to an integer (using the preceding devices as desired), divide by the size of the index range, and take the reminder as the result. For example, abcd = mod 100 = 62.
45 Collision Resolution Open Hashing (Separate Chaining) Linear probing Quadratic probing Double hashing Closed Hashing (Open Addressing) Rehashing
46 Open Hashing The first strategy, commonly known as either open hashing, or separate chaining, is to keep a list of all elements that hash to the same value. We assume for this section that the keys are the first 10 perfect squares and that the hashing function is simply hash(x) = x mod 10. (The table size is not prime, but is used here for simplicity.)
47 Open Hashing Example
48 Find in Open Hashing Find We use the hash function to determine which list to traverse. We then traverse this list in the normal manner, returning the position where the item is found.
49 Insert in Open Hashing Insert we traverse down the appropriate list to check whether the element is already in place. If the element turns out to be new, it is inserted either at the front of the list or at the end of the list. Sometimes new elements are inserted at the front of the list, since it is convenient and also because frequently it happens that recently inserted elements are the most likely to be accessed in the near future.
50 Deletion in Open Hashing Deletion The deletion routine is a straightforward implementation of deletion in a linked list. First perform a FIND operation and then perform a delete operation of an item in a linked list.
51 Advantages of Linked Storage Considerable space may be saved. It allows simple and efficient collision handling. It is no longer necessary that the size of the hash table exceed the number of records. Deletion becomes a quick and easy task in a chained hash table.
52 Disadvantage of Linked Storage All the links require space. If the records are small this space usage is large when compared with the records.
53 Closed Hashing (Open Addressing) Open hashing has the disadvantage of requiring pointers. This tends to slow the algorithm: The time required to allocate new cells. It requires the implementation of a second data structure. In a closed hashing system, if a collision occurs, alternate cells are tried until an empty cell is found.
54 Closed Hashing For example, cells h 0(x), h 1 (x), h 2 (x),... are tried in succession where h i (x) = (hash(x) + f(i)) mod H_SIZE, with f(0) = 0. The function, f, is the collision resolution strategy. Because all the data goes inside the table, a bigger table is needed for closed hashing than for open hashing. Generally, the load factor should be below l = 0.5 for closed hashing.
55 Insertion Operation Outline An array must be declared that will hold the hash table. Initializing all locations in the array to show that they are empty. To insert a record into the hash table, the hash function for the key is first calculated. If the corresponding location is empty, then the record can be inserted, or else if the keys are equal, then insertion of the new record would not be allowed. In this case, it becomes necessary to resolve the collision.
56 Find Operation Outline To retrieve the record with a given key is entirely similar. The hash function for the key is computed. If the desired record is in the corresponding location, then the retrieval has succeeded; otherwise, while the location is nonempty and not all locations have been examined, follow the same steps used for collision resolution. If an empty position is found, or h 0 have been considered, then no record with the given key is in the table, and the search in unsuccessful.
57 Linear Probing The simplest method to resolve a collision is to start with the hash address (the location where the collision occurred) and do a sequential search for the desired key or an empty location. The problem with the above method is that the data become clustered: Records start to appear in long strings of adjacent positions with gaps between the strings.
58 Example
59 Problems The time to search for an empty cell may be long. The problem of primary clustering is essentially one of instability. If a few keys happen randomly to be near each other, then it becomes more and more likely that other keys will join in the cluster. Furthermore, the distribution will become progressively more unbalanced.
60 Analysis It can be shown that the expected number of probes using linear probing is roughly Insertions and unsuccessful searches 1 2 (1+1/(1 λ)2 ) Successful searched 1 (1+1/(1 λ)) 2 λ, of a hash table is the ratio of the number of elements in the hash table to the table size.
61 Analysis We assume a very large table and that each probe is independent of the previous probes. The expected number of probes in an unsuccessful search. The number of probes for a successful search = the number of probes required when the particular element was inserted. When an element is inserted, it is done as a result of an unsuccessful search. We can use the cost of an unsuccessful search to compute the average cost of a successful search. Since the fraction of empty cells is 1 - λ, the number of cells we expect to probe is 1/(1- λ).
62 Probes vs. Load Factor Dashed curves-- linear probing Solid curvesrandom collision resolution S-successful U-unsuccessful I-insert What it is saying is that the linear probing is not a very good method to handle collision.
63 Notes If λ = 0.75, then the formula above indicates that 8.5 probes are expected for an insertion in linear probing. If λ = 0.9, then 50 probes are expected. This compares with 4 and 10 probes for the respective load factors if clustering were not a problem. We see from these formulas that linear probing can be a bad idea if the table is expected to be more than half full. If λ = 0.5, however, only 2.5 probes for insertion and only 1.5 probes are required for a successful search.
64 Quadratic Probing Quadratic probing avoid the primary clustering problem of linear probing. If there is a collision at hash address H, the method call quadratic probing looks in the table at locations h+1, h+4, h+9,, that is, at locations h + i 2 (mod hashsize) for i=1, 2,... This reduces clustering, but it is not obvious that it will probe all locations in the table, and in fact it does not.
65 Observation Theorem-- If quadratic probing is used and the table size is prime, then a new element can always be inserted if the table is at least half empty. (see book for more details)
66 Example
67 Notes If the table is even one more than half full, the insertion could fail (although this is extremely unlikely). It is also crucial that the table size be prime. If the table size is not prime, the number of alternate locations can be severely reduced. Standard deletion cannot be performed in a closed hash table, because the cell might have caused a collision to go past it. Closed hash tables require lazy deletion.
68 About Lazy Deletion Deletion in a hash table is not an easy task. One method to delete an entry is to invent another special key, to be placed in any deleted position. This special key would indicate that this position is free to receive an insertion when desired but that is should not be used to terminate the search for some other item in the table.
69 Key-Dependent Increments Rather than having the increment depend on the number of probes already made, we can let it be some simple function of the key itself. For example, we could truncate the key to a single character and use its code as the increment.
70 Random Probing Use a pseudorandom number generator to obtain the increment. The generator used should be one that always generates the same sequence provided it starts with the same seed. This method is excellent in avoiding clustering, but is likely to be slower than the others.
71 Double Hashing For double hashing, one popular choice is f(i) = i * h 2(x). We apply a second hash function to x and probe at a distance h 2 (x), 2 h 2 (x),..., and so on. A poor choice of h 2(x) would be disastrous. The function must never evaluate to zero. Make sure all cells can be probed.
72 Double Hashing For instance, the obvious choice h 2(x) = x mod 9 would not help if 99 were inserted into the input in the previous examples. A function such as h 2(x) = R - (x mod R), with R a prime smaller than H_SIZE, will work well. One may continue to perform triple hashing, and so on.
73 Example h 2 (x) = R - (x mod R), R = 7
74 Rehashing When the table gets too full, the running time for the operations will deteriorate, specially when there are too many removals intermixed with insertions. Solution Build another table that is about twice as big (with associated new hash function). Scan down the entire original hash table, computing the new hash value for each element and inserting it in the new table.
75 Example Table size = 7 Insert 13, 15, 24, and 6. h(x) = x mod 7.
76 Closed Hash Table, Insert 23 After 23 is inserted, the resulting table will be over 70% full. A new table is created with size = 17 since this is the first prime that is twice as large as the old table size. The new hash function is then h(x) = x mod 17.
77 After Rehashing The old table is scanned, and elements 6, 15, 23, 24, and 13 are inserted into the new table. The running time is O(n). It is expensive. It should not be done so frequently.
78 Extendible Hashing What happens when the amount of data is too large to fit in main memory and must be stored on the disk? How can we minimize the disk access? Suppose that our data consists of several 6 bit integers. The root of the tree contains 4 pointers determined by the leading two bits of the data.
79 Example
80 Extendible Hashing Each leaf has up to m = 4 elements. D represents the number of bits used by the root, which is sometimes known as the directory. The number of entries in the directory is thus 2D dl (the number of leading bits that all the elements of some leaf l have in common. dl will depend on the particular leave.
81 Example, insert This will go into the third leaf and cause a split. Now, the leaves are now determined by the first 3 bits.
82 Example, insert
83 Notes It is possible that several directory splits will be required if the elements in a leaf agree in more than D+1 leading bits. For example, , , and are inserted, the directory size must be increased to 4. The possibility of duplicate keys. This algorithm does not work when there are more than m duplicates. It is important for the bits to be fairly random.
84 Summary Hash tables can be used to implement the insert and find operations in constant average time. It is especially important to pay attention to details such as load factor when using hash tables. It is also important to choose the hash function carefully when the key is not a short string or integer.
85 Summary For open hashing, the load factor should be close to 1. For closed hashing, the load factor should not exceed 0.5, unless this is completely unavoidable. Using a hash table, it is not possible to find the minimum element. It is not possible to search efficiently for a string unless the exact string is known.
86 Summary Compilers use hash tables to keep track of declared variables in source code. The data structure is known as a symbol table. A hash table is useful for any graph theory problem where the nodes have real names instead of numbers. A third common use of hash tables is in programs that play games. Another use of hashing is in online spelling checkers.
Review of Hashing: Integer Keys
 CSE 326 Lecture 13: Much ado about Hashing Today s munchies to munch on: Review of Hashing Collision Resolution by: Separate Chaining Open Addressing $ Linear/Quadratic Probing $ Double Hashing Rehashing
CSE 326 Lecture 13: Much ado about Hashing Today s munchies to munch on: Review of Hashing Collision Resolution by: Separate Chaining Open Addressing $ Linear/Quadratic Probing $ Double Hashing Rehashing
Chapter Objectives. Chapter 9. Sequential Search. Search Algorithms. Search Algorithms. Binary Search
 Chapter Objectives Chapter 9 Search Algorithms Data Structures Using C++ 1 Learn the various search algorithms Explore how to implement the sequential and binary search algorithms Discover how the sequential
Chapter Objectives Chapter 9 Search Algorithms Data Structures Using C++ 1 Learn the various search algorithms Explore how to implement the sequential and binary search algorithms Discover how the sequential
DATA STRUCTURES USING C
 DATA STRUCTURES USING C QUESTION BANK UNIT I 1. Define data. 2. Define Entity. 3. Define information. 4. Define Array. 5. Define data structure. 6. Give any two applications of data structures. 7. Give
DATA STRUCTURES USING C QUESTION BANK UNIT I 1. Define data. 2. Define Entity. 3. Define information. 4. Define Array. 5. Define data structure. 6. Give any two applications of data structures. 7. Give
Hash Tables. Computer Science E-119 Harvard Extension School Fall 2012 David G. Sullivan, Ph.D. Data Dictionary Revisited
 Hash Tables Computer Science E-119 Harvard Extension School Fall 2012 David G. Sullivan, Ph.D. Data Dictionary Revisited We ve considered several data structures that allow us to store and search for data
Hash Tables Computer Science E-119 Harvard Extension School Fall 2012 David G. Sullivan, Ph.D. Data Dictionary Revisited We ve considered several data structures that allow us to store and search for data
Universal hashing. In other words, the probability of a collision for two different keys x and y given a hash function randomly chosen from H is 1/m.
 Universal hashing No matter how we choose our hash function, it is always possible to devise a set of keys that will hash to the same slot, making the hash scheme perform poorly. To circumvent this, we
Universal hashing No matter how we choose our hash function, it is always possible to devise a set of keys that will hash to the same slot, making the hash scheme perform poorly. To circumvent this, we
CSE373: Data Structures & Algorithms Lecture 14: Hash Collisions. Linda Shapiro Spring 2016
 CSE373: Data Structures & Algorithms Lecture 14: Hash Collisions Linda Shapiro Spring 2016 Announcements Friday: Review List and go over answers to Practice Problems 2 Hash Tables: Review Aim for constant-time
CSE373: Data Structures & Algorithms Lecture 14: Hash Collisions Linda Shapiro Spring 2016 Announcements Friday: Review List and go over answers to Practice Problems 2 Hash Tables: Review Aim for constant-time
CSE 326, Data Structures. Sample Final Exam. Problem Max Points Score 1 14 (2x7) 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.
 2 18 (3x6) 3 4 4 7 5 9 6 16 7 8 8 4 9 8 10 4 Total 92.") Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
Name: Email ID: CSE 326, Data Structures Section: Sample Final Exam Instructions: The exam is closed book, closed notes. Unless otherwise stated, N denotes the number of elements in the data structure
Physical Data Organization
 Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
Physical Data Organization Database design using logical model of the database - appropriate level for users to focus on - user independence from implementation details Performance - other major factor
1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++
 The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++") Answer the following 1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++ 2) Which data structure is needed to convert infix notations to postfix notations? Stack 3) The
Answer the following 1) The postfix expression for the infix expression A+B*(C+D)/F+D*E is ABCD+*F/DE*++ 2) Which data structure is needed to convert infix notations to postfix notations? Stack 3) The
Symbol Tables. Introduction
 Symbol Tables Introduction A compiler needs to collect and use information about the names appearing in the source program. This information is entered into a data structure called a symbol table. The
Symbol Tables Introduction A compiler needs to collect and use information about the names appearing in the source program. This information is entered into a data structure called a symbol table. The
5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.
![5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.](/thumbs/40/21353779.jpg "5. A full binary tree with n leaves contains [A] n nodes. [B] log n 2 nodes. [C] 2n 1 nodes. [D] n 2 nodes.") 1. The advantage of.. is that they solve the problem if sequential storage representation. But disadvantage in that is they are sequential lists. [A] Lists [B] Linked Lists [A] Trees [A] Queues 2. The
1. The advantage of.. is that they solve the problem if sequential storage representation. But disadvantage in that is they are sequential lists. [A] Lists [B] Linked Lists [A] Trees [A] Queues 2. The
Record Storage and Primary File Organization
 Record Storage and Primary File Organization 1 C H A P T E R 4 Contents Introduction Secondary Storage Devices Buffering of Blocks Placing File Records on Disk Operations on Files Files of Unordered Records
Record Storage and Primary File Organization 1 C H A P T E R 4 Contents Introduction Secondary Storage Devices Buffering of Blocks Placing File Records on Disk Operations on Files Files of Unordered Records
recursion, O(n), linked lists 6/14
, linked lists 6/14") recursion, O(n), linked lists 6/14 recursion reducing the amount of data to process and processing a smaller amount of data example: process one item in a list, recursively process the rest of the list
recursion, O(n), linked lists 6/14 recursion reducing the amount of data to process and processing a smaller amount of data example: process one item in a list, recursively process the rest of the list
Chapter 13: Query Processing. Basic Steps in Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Krishna Institute of Engineering & Technology, Ghaziabad Department of Computer Application MCA-213 : DATA STRUCTURES USING C
 Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
Tutorial#1 Q 1:- Explain the terms data, elementary item, entity, primary key, domain, attribute and information? Also give examples in support of your answer? Q 2:- What is a Data Type? Differentiate
The Taxman Game. Robert K. Moniot September 5, 2003
 The Taxman Game Robert K. Moniot September 5, 2003 1 Introduction Want to know how to beat the taxman? Legally, that is? Read on, and we will explore this cute little mathematical game. The taxman game
The Taxman Game Robert K. Moniot September 5, 2003 1 Introduction Want to know how to beat the taxman? Legally, that is? Read on, and we will explore this cute little mathematical game. The taxman game
Lecture 1: Data Storage & Index
 Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
Lecture 1: Data Storage & Index R&G Chapter 8-11 Concurrency control Query Execution and Optimization Relational Operators File & Access Methods Buffer Management Disk Space Management Recovery Manager
ALGEBRA. sequence, term, nth term, consecutive, rule, relationship, generate, predict, continue increase, decrease finite, infinite
 ALGEBRA Pupils should be taught to: Generate and describe sequences As outcomes, Year 7 pupils should, for example: Use, read and write, spelling correctly: sequence, term, nth term, consecutive, rule,
ALGEBRA Pupils should be taught to: Generate and describe sequences As outcomes, Year 7 pupils should, for example: Use, read and write, spelling correctly: sequence, term, nth term, consecutive, rule,
Data Structures in Java. Session 15 Instructor: Bert Huang http://www1.cs.columbia.edu/~bert/courses/3134
 Data Structures in Java Session 15 Instructor: Bert Huang http://www1.cs.columbia.edu/~bert/courses/3134 Announcements Homework 4 on website No class on Tuesday Midterm grades almost done Review Indexing
Data Structures in Java Session 15 Instructor: Bert Huang http://www1.cs.columbia.edu/~bert/courses/3134 Announcements Homework 4 on website No class on Tuesday Midterm grades almost done Review Indexing
Dynamic Programming. Lecture 11. 11.1 Overview. 11.2 Introduction
 Lecture 11 Dynamic Programming 11.1 Overview Dynamic Programming is a powerful technique that allows one to solve many different types of problems in time O(n 2 ) or O(n 3 ) for which a naive approach
Lecture 11 Dynamic Programming 11.1 Overview Dynamic Programming is a powerful technique that allows one to solve many different types of problems in time O(n 2 ) or O(n 3 ) for which a naive approach
1. The memory address of the first element of an array is called A. floor address B. foundation addressc. first address D.
 1. The memory address of the first element of an array is called A. floor address B. foundation addressc. first address D. base address 2. The memory address of fifth element of an array can be calculated
1. The memory address of the first element of an array is called A. floor address B. foundation addressc. first address D. base address 2. The memory address of fifth element of an array can be calculated
Lecture Notes on Binary Search Trees
 Lecture Notes on Binary Search Trees 15-122: Principles of Imperative Computation Frank Pfenning André Platzer Lecture 17 October 23, 2014 1 Introduction In this lecture, we will continue considering associative
Lecture Notes on Binary Search Trees 15-122: Principles of Imperative Computation Frank Pfenning André Platzer Lecture 17 October 23, 2014 1 Introduction In this lecture, we will continue considering associative
Sample Questions Csci 1112 A. Bellaachia
 Sample Questions Csci 1112 A. Bellaachia Important Series : o S( N) 1 2 N N i N(1 N) / 2 i 1 o Sum of squares: N 2 N( N 1)(2N 1) N i for large N i 1 6 o Sum of exponents: N k 1 k N i for large N and k
Sample Questions Csci 1112 A. Bellaachia Important Series : o S( N) 1 2 N N i N(1 N) / 2 i 1 o Sum of squares: N 2 N( N 1)(2N 1) N i for large N i 1 6 o Sum of exponents: N k 1 k N i for large N and k
Binary Search Trees. A Generic Tree. Binary Trees. Nodes in a binary search tree ( B-S-T) are of the form. P parent. Key. Satellite data L R
 are of the form. P parent. Key. Satellite data L R") Binary Search Trees A Generic Tree Nodes in a binary search tree ( B-S-T) are of the form P parent Key A Satellite data L R B C D E F G H I J The B-S-T has a root node which is the only node whose parent
Binary Search Trees A Generic Tree Nodes in a binary search tree ( B-S-T) are of the form P parent Key A Satellite data L R B C D E F G H I J The B-S-T has a root node which is the only node whose parent
10CS35: Data Structures Using C
 CS35: Data Structures Using C QUESTION BANK REVIEW OF STRUCTURES AND POINTERS, INTRODUCTION TO SPECIAL FEATURES OF C OBJECTIVE: Learn : Usage of structures, unions - a conventional tool for handling a
CS35: Data Structures Using C QUESTION BANK REVIEW OF STRUCTURES AND POINTERS, INTRODUCTION TO SPECIAL FEATURES OF C OBJECTIVE: Learn : Usage of structures, unions - a conventional tool for handling a
COMP 250 Fall 2012 lecture 2 binary representations Sept. 11, 2012
 Binary numbers The reason humans represent numbers using decimal (the ten digits from 0,1,... 9) is that we have ten fingers. There is no other reason than that. There is nothing special otherwise about
Binary numbers The reason humans represent numbers using decimal (the ten digits from 0,1,... 9) is that we have ten fingers. There is no other reason than that. There is nothing special otherwise about
Efficient Data Structures for Decision Diagrams
 Artificial Intelligence Laboratory Efficient Data Structures for Decision Diagrams Master Thesis Nacereddine Ouaret Professor: Supervisors: Boi Faltings Thomas Léauté Radoslaw Szymanek Contents Introduction...
Artificial Intelligence Laboratory Efficient Data Structures for Decision Diagrams Master Thesis Nacereddine Ouaret Professor: Supervisors: Boi Faltings Thomas Léauté Radoslaw Szymanek Contents Introduction...
Chapter 4: Computer Codes
 Slide 1/30 Learning Objectives In this chapter you will learn about: Computer data Computer codes: representation of data in binary Most commonly used computer codes Collating sequence 36 Slide 2/30 Data
Slide 1/30 Learning Objectives In this chapter you will learn about: Computer data Computer codes: representation of data in binary Most commonly used computer codes Collating sequence 36 Slide 2/30 Data
APP INVENTOR. Test Review
 APP INVENTOR Test Review Main Concepts App Inventor Lists Creating Random Numbers Variables Searching and Sorting Data Linear Search Binary Search Selection Sort Quick Sort Abstraction Modulus Division
APP INVENTOR Test Review Main Concepts App Inventor Lists Creating Random Numbers Variables Searching and Sorting Data Linear Search Binary Search Selection Sort Quick Sort Abstraction Modulus Division
Chapter 13. Chapter Outline. Disk Storage, Basic File Structures, and Hashing
 Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Chapter 13 Disk Storage, Basic File Structures, and Hashing Copyright 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline Disk Storage Devices Files of Records Operations on Files Unordered Files
Files. Files. Files. Files. Files. File Organisation. What s it all about? What s in a file?
 Files What s it all about? Information being stored about anything important to the business/individual keeping the files. The simple concepts used in the operation of manual files are often a good guide
Files What s it all about? Information being stored about anything important to the business/individual keeping the files. The simple concepts used in the operation of manual files are often a good guide
Data Structures and Data Manipulation
 Data Structures and Data Manipulation What the Specification Says: Explain how static data structures may be used to implement dynamic data structures; Describe algorithms for the insertion, retrieval
Data Structures and Data Manipulation What the Specification Says: Explain how static data structures may be used to implement dynamic data structures; Describe algorithms for the insertion, retrieval
Lecture 2: Data Structures Steven Skiena. http://www.cs.sunysb.edu/ skiena
 Lecture 2: Data Structures Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794 4400 http://www.cs.sunysb.edu/ skiena String/Character I/O There are several approaches
Lecture 2: Data Structures Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794 4400 http://www.cs.sunysb.edu/ skiena String/Character I/O There are several approaches
Fundamental Algorithms
 Fundamental Algorithms Chapter 7: Hash Tables Michael Bader Winter 2014/15 Chapter 7: Hash Tables, Winter 2014/15 1 Generalised Search Problem Definition (Search Problem) Input: a sequence or set A of
Fundamental Algorithms Chapter 7: Hash Tables Michael Bader Winter 2014/15 Chapter 7: Hash Tables, Winter 2014/15 1 Generalised Search Problem Definition (Search Problem) Input: a sequence or set A of
File System Management
 Lecture 7: Storage Management File System Management Contents Non volatile memory Tape, HDD, SSD Files & File System Interface Directories & their Organization File System Implementation Disk Space Allocation
Lecture 7: Storage Management File System Management Contents Non volatile memory Tape, HDD, SSD Files & File System Interface Directories & their Organization File System Implementation Disk Space Allocation
PES Institute of Technology-BSC QUESTION BANK
 PES Institute of Technology-BSC Faculty: Mrs. R.Bharathi CS35: Data Structures Using C QUESTION BANK UNIT I -BASIC CONCEPTS 1. What is an ADT? Briefly explain the categories that classify the functions
PES Institute of Technology-BSC Faculty: Mrs. R.Bharathi CS35: Data Structures Using C QUESTION BANK UNIT I -BASIC CONCEPTS 1. What is an ADT? Briefly explain the categories that classify the functions
MATH 10034 Fundamental Mathematics IV
 MATH 0034 Fundamental Mathematics IV http://www.math.kent.edu/ebooks/0034/funmath4.pdf Department of Mathematical Sciences Kent State University January 2, 2009 ii Contents To the Instructor v Polynomials.
MATH 0034 Fundamental Mathematics IV http://www.math.kent.edu/ebooks/0034/funmath4.pdf Department of Mathematical Sciences Kent State University January 2, 2009 ii Contents To the Instructor v Polynomials.
Raima Database Manager Version 14.0 In-memory Database Engine
 + Raima Database Manager Version 14.0 In-memory Database Engine By Jeffrey R. Parsons, Senior Engineer January 2016 Abstract Raima Database Manager (RDM) v14.0 contains an all new data storage engine optimized
+ Raima Database Manager Version 14.0 In-memory Database Engine By Jeffrey R. Parsons, Senior Engineer January 2016 Abstract Raima Database Manager (RDM) v14.0 contains an all new data storage engine optimized
BM307 File Organization
 BM307 File Organization Gazi University Computer Engineering Department 9/24/2014 1 Index Sequential File Organization Binary Search Interpolation Search Self-Organizing Sequential Search Direct File Organization
BM307 File Organization Gazi University Computer Engineering Department 9/24/2014 1 Index Sequential File Organization Binary Search Interpolation Search Self-Organizing Sequential Search Direct File Organization
Welcome to Basic Math Skills!
 Basic Math Skills Welcome to Basic Math Skills! Most students find the math sections to be the most difficult. Basic Math Skills was designed to give you a refresher on the basics of math. There are lots
Basic Math Skills Welcome to Basic Math Skills! Most students find the math sections to be the most difficult. Basic Math Skills was designed to give you a refresher on the basics of math. There are lots
Tables so far. set() get() delete() BST Average O(lg n) O(lg n) O(lg n) Worst O(n) O(n) O(n) RB Tree Average O(lg n) O(lg n) O(lg n)
 get() delete() BST Average O(lg n) O(lg n) O(lg n) Worst O(n) O(n) O(n) RB Tree Average O(lg n) O(lg n) O(lg n)") Hash Tables Tables so far set() get() delete() BST Average O(lg n) O(lg n) O(lg n) Worst O(n) O(n) O(n) RB Tree Average O(lg n) O(lg n) O(lg n) Worst O(lg n) O(lg n) O(lg n) Table naïve array implementation
Hash Tables Tables so far set() get() delete() BST Average O(lg n) O(lg n) O(lg n) Worst O(n) O(n) O(n) RB Tree Average O(lg n) O(lg n) O(lg n) Worst O(lg n) O(lg n) O(lg n) Table naïve array implementation
A Comparison of Dictionary Implementations
 A Comparison of Dictionary Implementations Mark P Neyer April 10, 2009 1 Introduction A common problem in computer science is the representation of a mapping between two sets. A mapping f : A B is a function
A Comparison of Dictionary Implementations Mark P Neyer April 10, 2009 1 Introduction A common problem in computer science is the representation of a mapping between two sets. A mapping f : A B is a function
2.5 Zeros of a Polynomial Functions
 .5 Zeros of a Polynomial Functions Section.5 Notes Page 1 The first rule we will talk about is Descartes Rule of Signs, which can be used to determine the possible times a graph crosses the x-axis and
.5 Zeros of a Polynomial Functions Section.5 Notes Page 1 The first rule we will talk about is Descartes Rule of Signs, which can be used to determine the possible times a graph crosses the x-axis and
INTRODUCTION The collection of data that makes up a computerized database must be stored physically on some computer storage medium.
 Chapter 4: Record Storage and Primary File Organization 1 Record Storage and Primary File Organization INTRODUCTION The collection of data that makes up a computerized database must be stored physically
Chapter 4: Record Storage and Primary File Organization 1 Record Storage and Primary File Organization INTRODUCTION The collection of data that makes up a computerized database must be stored physically
Analysis of Algorithms I: Binary Search Trees
 Analysis of Algorithms I: Binary Search Trees Xi Chen Columbia University Hash table: A data structure that maintains a subset of keys from a universe set U = {0, 1,..., p 1} and supports all three dictionary
Analysis of Algorithms I: Binary Search Trees Xi Chen Columbia University Hash table: A data structure that maintains a subset of keys from a universe set U = {0, 1,..., p 1} and supports all three dictionary
MS SQL Performance (Tuning) Best Practices:
 Best Practices:") MS SQL Performance (Tuning) Best Practices: 1. Don t share the SQL server hardware with other services If other workloads are running on the same server where SQL Server is running, memory and other hardware
MS SQL Performance (Tuning) Best Practices: 1. Don t share the SQL server hardware with other services If other workloads are running on the same server where SQL Server is running, memory and other hardware
Fast Sequential Summation Algorithms Using Augmented Data Structures
 Fast Sequential Summation Algorithms Using Augmented Data Structures Vadim Stadnik vadim.stadnik@gmail.com Abstract This paper provides an introduction to the design of augmented data structures that offer
Fast Sequential Summation Algorithms Using Augmented Data Structures Vadim Stadnik vadim.stadnik@gmail.com Abstract This paper provides an introduction to the design of augmented data structures that offer
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems
 Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Chapter 13 File and Database Systems Outline 13.1 Introduction 13.2 Data Hierarchy 13.3 Files 13.4 File Systems 13.4.1 Directories 13.4. Metadata 13.4. Mounting 13.5 File Organization 13.6 File Allocation
Session 6 Number Theory
 Key Terms in This Session Session 6 Number Theory Previously Introduced counting numbers factor factor tree prime number New in This Session composite number greatest common factor least common multiple
Key Terms in This Session Session 6 Number Theory Previously Introduced counting numbers factor factor tree prime number New in This Session composite number greatest common factor least common multiple
Base Conversion written by Cathy Saxton
 Base Conversion written by Cathy Saxton 1. Base 10 In base 10, the digits, from right to left, specify the 1 s, 10 s, 100 s, 1000 s, etc. These are powers of 10 (10 x ): 10 0 = 1, 10 1 = 10, 10 2 = 100,
Base Conversion written by Cathy Saxton 1. Base 10 In base 10, the digits, from right to left, specify the 1 s, 10 s, 100 s, 1000 s, etc. These are powers of 10 (10 x ): 10 0 = 1, 10 1 = 10, 10 2 = 100,
Lecture 12 Doubly Linked Lists (with Recursion)
") Lecture 12 Doubly Linked Lists (with Recursion) In this lecture Introduction to Doubly linked lists What is recursion? Designing a node of a DLL Recursion and Linked Lists o Finding a node in a LL (recursively)
Lecture 12 Doubly Linked Lists (with Recursion) In this lecture Introduction to Doubly linked lists What is recursion? Designing a node of a DLL Recursion and Linked Lists o Finding a node in a LL (recursively)
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay
 Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Practical Survey on Hash Tables. Aurelian Țuțuianu
 Practical Survey on Hash Tables Aurelian Țuțuianu In memoriam Mihai Pătraşcu (17 July 1982 5 June 2012) I have no intention to ever teach computer science. I want to teach the love for computer science,
Practical Survey on Hash Tables Aurelian Țuțuianu In memoriam Mihai Pătraşcu (17 July 1982 5 June 2012) I have no intention to ever teach computer science. I want to teach the love for computer science,
Binary Search Trees. Data in each node. Larger than the data in its left child Smaller than the data in its right child
 Binary Search Trees Data in each node Larger than the data in its left child Smaller than the data in its right child FIGURE 11-6 Arbitrary binary tree FIGURE 11-7 Binary search tree Data Structures Using
Binary Search Trees Data in each node Larger than the data in its left child Smaller than the data in its right child FIGURE 11-6 Arbitrary binary tree FIGURE 11-7 Binary search tree Data Structures Using
1. Define: (a) Variable, (b) Constant, (c) Type, (d) Enumerated Type, (e) Identifier.
 Variable, (b) Constant, (c) Type, (d) Enumerated Type, (e) Identifier.") Study Group 1 Variables and Types 1. Define: (a) Variable, (b) Constant, (c) Type, (d) Enumerated Type, (e) Identifier. 2. What does the byte 00100110 represent? 3. What is the purpose of the declarations
Study Group 1 Variables and Types 1. Define: (a) Variable, (b) Constant, (c) Type, (d) Enumerated Type, (e) Identifier. 2. What does the byte 00100110 represent? 3. What is the purpose of the declarations
DATABASE DESIGN - 1DL400
 DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
DATABASE DESIGN - 1DL400 Spring 2015 A course on modern database systems!! http://www.it.uu.se/research/group/udbl/kurser/dbii_vt15/ Kjell Orsborn! Uppsala Database Laboratory! Department of Information
Name: Class: Date: 9. The compiler ignores all comments they are there strictly for the convenience of anyone reading the program.
 Name: Class: Date: Exam #1 - Prep True/False Indicate whether the statement is true or false. 1. Programming is the process of writing a computer program in a language that the computer can respond to
Name: Class: Date: Exam #1 - Prep True/False Indicate whether the statement is true or false. 1. Programming is the process of writing a computer program in a language that the computer can respond to
Working with whole numbers
 1 CHAPTER 1 Working with whole numbers In this chapter you will revise earlier work on: addition and subtraction without a calculator multiplication and division without a calculator using positive and
1 CHAPTER 1 Working with whole numbers In this chapter you will revise earlier work on: addition and subtraction without a calculator multiplication and division without a calculator using positive and
Storing Measurement Data
 Storing Measurement Data File I/O records or reads data in a file. A typical file I/O operation involves the following process. 1. Create or open a file. Indicate where an existing file resides or where
Storing Measurement Data File I/O records or reads data in a file. A typical file I/O operation involves the following process. 1. Create or open a file. Indicate where an existing file resides or where
Class Notes CS 3137. 1 Creating and Using a Huffman Code. Ref: Weiss, page 433
 Class Notes CS 3137 1 Creating and Using a Huffman Code. Ref: Weiss, page 433 1. FIXED LENGTH CODES: Codes are used to transmit characters over data links. You are probably aware of the ASCII code, a fixed-length
Class Notes CS 3137 1 Creating and Using a Huffman Code. Ref: Weiss, page 433 1. FIXED LENGTH CODES: Codes are used to transmit characters over data links. You are probably aware of the ASCII code, a fixed-length
Chapter 8: Structures for Files. Truong Quynh Chi tqchi@cse.hcmut.edu.vn. Spring- 2013
 Chapter 8: Data Storage, Indexing Structures for Files Truong Quynh Chi tqchi@cse.hcmut.edu.vn Spring- 2013 Overview of Database Design Process 2 Outline Data Storage Disk Storage Devices Files of Records
Chapter 8: Data Storage, Indexing Structures for Files Truong Quynh Chi tqchi@cse.hcmut.edu.vn Spring- 2013 Overview of Database Design Process 2 Outline Data Storage Disk Storage Devices Files of Records
Common Data Structures
 Data Structures 1 Common Data Structures Arrays (single and multiple dimensional) Linked Lists Stacks Queues Trees Graphs You should already be familiar with arrays, so they will not be discussed. Trees
Data Structures 1 Common Data Structures Arrays (single and multiple dimensional) Linked Lists Stacks Queues Trees Graphs You should already be familiar with arrays, so they will not be discussed. Trees
Data Structure with C
 Subject: Data Structure with C Topic : Tree Tree A tree is a set of nodes that either:is empty or has a designated node, called the root, from which hierarchically descend zero or more subtrees, which
Subject: Data Structure with C Topic : Tree Tree A tree is a set of nodes that either:is empty or has a designated node, called the root, from which hierarchically descend zero or more subtrees, which
POLYNOMIAL FUNCTIONS
 POLYNOMIAL FUNCTIONS Polynomial Division.. 314 The Rational Zero Test.....317 Descarte s Rule of Signs... 319 The Remainder Theorem.....31 Finding all Zeros of a Polynomial Function.......33 Writing a
POLYNOMIAL FUNCTIONS Polynomial Division.. 314 The Rational Zero Test.....317 Descarte s Rule of Signs... 319 The Remainder Theorem.....31 Finding all Zeros of a Polynomial Function.......33 Writing a
B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers
 B+ Tree and Hashing B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers B+ Tree Properties Balanced Tree Same height for paths
B+ Tree and Hashing B+ Tree Properties B+ Tree Searching B+ Tree Insertion B+ Tree Deletion Static Hashing Extendable Hashing Questions in pass papers B+ Tree Properties Balanced Tree Same height for paths
New Hash Function Construction for Textual and Geometric Data Retrieval
 Latest Trends on Computers, Vol., pp.483-489, ISBN 978-96-474-3-4, ISSN 79-45, CSCC conference, Corfu, Greece, New Hash Function Construction for Textual and Geometric Data Retrieval Václav Skala, Jan
Latest Trends on Computers, Vol., pp.483-489, ISBN 978-96-474-3-4, ISSN 79-45, CSCC conference, Corfu, Greece, New Hash Function Construction for Textual and Geometric Data Retrieval Václav Skala, Jan
Unit 4.3 - Storage Structures 1. Storage Structures. Unit 4.3
 Storage Structures Unit 4.3 Unit 4.3 - Storage Structures 1 The Physical Store Storage Capacity Medium Transfer Rate Seek Time Main Memory 800 MB/s 500 MB Instant Hard Drive 10 MB/s 120 GB 10 ms CD-ROM
Storage Structures Unit 4.3 Unit 4.3 - Storage Structures 1 The Physical Store Storage Capacity Medium Transfer Rate Seek Time Main Memory 800 MB/s 500 MB Instant Hard Drive 10 MB/s 120 GB 10 ms CD-ROM
File Management. Chapter 12
 Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Chapter 12 File Management File is the basic element of most of the applications, since the input to an application, as well as its output, is usually a file. They also typically outlive the execution
Operating Systems CSE 410, Spring 2004. File Management. Stephen Wagner Michigan State University
 Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Operating Systems CSE 410, Spring 2004 File Management Stephen Wagner Michigan State University File Management File management system has traditionally been considered part of the operating system. Applications
Lecture 2. Binary and Hexadecimal Numbers
 Lecture 2 Binary and Hexadecimal Numbers Purpose: Review binary and hexadecimal number representations Convert directly from one base to another base Review addition and subtraction in binary representations
Lecture 2 Binary and Hexadecimal Numbers Purpose: Review binary and hexadecimal number representations Convert directly from one base to another base Review addition and subtraction in binary representations
The Tower of Hanoi. Recursion Solution. Recursive Function. Time Complexity. Recursive Thinking. Why Recursion? n! = n* (n-1)!
!") The Tower of Hanoi Recursion Solution recursion recursion recursion Recursive Thinking: ignore everything but the bottom disk. 1 2 Recursive Function Time Complexity Hanoi (n, src, dest, temp): If (n >
The Tower of Hanoi Recursion Solution recursion recursion recursion Recursive Thinking: ignore everything but the bottom disk. 1 2 Recursive Function Time Complexity Hanoi (n, src, dest, temp): If (n >
4/1/2017. PS. Sequences and Series FROM 9.2 AND 9.3 IN THE BOOK AS WELL AS FROM OTHER SOURCES. TODAY IS NATIONAL MANATEE APPRECIATION DAY
 PS. Sequences and Series FROM 9.2 AND 9.3 IN THE BOOK AS WELL AS FROM OTHER SOURCES. TODAY IS NATIONAL MANATEE APPRECIATION DAY 1 Oh the things you should learn How to recognize and write arithmetic sequences
PS. Sequences and Series FROM 9.2 AND 9.3 IN THE BOOK AS WELL AS FROM OTHER SOURCES. TODAY IS NATIONAL MANATEE APPRECIATION DAY 1 Oh the things you should learn How to recognize and write arithmetic sequences
Mathematical Induction
 Mathematical Induction (Handout March 8, 01) The Principle of Mathematical Induction provides a means to prove infinitely many statements all at once The principle is logical rather than strictly mathematical,
Mathematical Induction (Handout March 8, 01) The Principle of Mathematical Induction provides a means to prove infinitely many statements all at once The principle is logical rather than strictly mathematical,
- Easy to insert & delete in O(1) time - Don t need to estimate total memory needed. - Hard to search in less than O(n) time
 time - Don t need to estimate total memory needed. - Hard to search in less than O(n) time") Skip Lists CMSC 420 Linked Lists Benefits & Drawbacks Benefits: - Easy to insert & delete in O(1) time - Don t need to estimate total memory needed Drawbacks: - Hard to search in less than O(n) time (binary
Skip Lists CMSC 420 Linked Lists Benefits & Drawbacks Benefits: - Easy to insert & delete in O(1) time - Don t need to estimate total memory needed Drawbacks: - Hard to search in less than O(n) time (binary
MS ACCESS DATABASE DATA TYPES
 MS ACCESS DATABASE DATA TYPES Data Type Use For Size Text Memo Number Text or combinations of text and numbers, such as addresses. Also numbers that do not require calculations, such as phone numbers,
MS ACCESS DATABASE DATA TYPES Data Type Use For Size Text Memo Number Text or combinations of text and numbers, such as addresses. Also numbers that do not require calculations, such as phone numbers,
Summary of important mathematical operations and formulas (from first tutorial):
:") EXCEL Intermediate Tutorial Summary of important mathematical operations and formulas (from first tutorial): Operation Key Addition + Subtraction - Multiplication * Division / Exponential ^ To enter a
EXCEL Intermediate Tutorial Summary of important mathematical operations and formulas (from first tutorial): Operation Key Addition + Subtraction - Multiplication * Division / Exponential ^ To enter a
Chapter 3. if 2 a i then location: = i. Page 40
 Chapter 3 1. Describe an algorithm that takes a list of n integers a 1,a 2,,a n and finds the number of integers each greater than five in the list. Ans: procedure greaterthanfive(a 1,,a n : integers)
Chapter 3 1. Describe an algorithm that takes a list of n integers a 1,a 2,,a n and finds the number of integers each greater than five in the list. Ans: procedure greaterthanfive(a 1,,a n : integers)
CS 2112 Spring 2014. 0 Instructions. Assignment 3 Data Structures and Web Filtering. 0.1 Grading. 0.2 Partners. 0.3 Restrictions
 CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
CS 2112 Spring 2014 Assignment 3 Data Structures and Web Filtering Due: March 4, 2014 11:59 PM Implementing spam blacklists and web filters requires matching candidate domain names and URLs very rapidly
Fast Arithmetic Coding (FastAC) Implementations
 Implementations") Fast Arithmetic Coding (FastAC) Implementations Amir Said 1 Introduction This document describes our fast implementations of arithmetic coding, which achieve optimal compression and higher throughput by
Fast Arithmetic Coding (FastAC) Implementations Amir Said 1 Introduction This document describes our fast implementations of arithmetic coding, which achieve optimal compression and higher throughput by
Number Systems and Radix Conversion
 Number Systems and Radix Conversion Sanjay Rajopadhye, Colorado State University 1 Introduction These notes for CS 270 describe polynomial number systems. The material is not in the textbook, but will
Number Systems and Radix Conversion Sanjay Rajopadhye, Colorado State University 1 Introduction These notes for CS 270 describe polynomial number systems. The material is not in the textbook, but will
TREE BASIC TERMINOLOGIES
 TREE Trees are very flexible, versatile and powerful non-liner data structure that can be used to represent data items possessing hierarchical relationship between the grand father and his children and
TREE Trees are very flexible, versatile and powerful non-liner data structure that can be used to represent data items possessing hierarchical relationship between the grand father and his children and
Sowing Games JEFF ERICKSON
 Games of No Chance MSRI Publications Volume 29, 1996 Sowing Games JEFF ERICKSON Abstract. At the Workshop, John Conway and Richard Guy proposed the class of sowing games, loosely based on the ancient African
Games of No Chance MSRI Publications Volume 29, 1996 Sowing Games JEFF ERICKSON Abstract. At the Workshop, John Conway and Richard Guy proposed the class of sowing games, loosely based on the ancient African
CS104: Data Structures and Object-Oriented Design (Fall 2013) October 24, 2013: Priority Queues Scribes: CS 104 Teaching Team
 October 24, 2013: Priority Queues Scribes: CS 104 Teaching Team") CS104: Data Structures and Object-Oriented Design (Fall 2013) October 24, 2013: Priority Queues Scribes: CS 104 Teaching Team Lecture Summary In this lecture, we learned about the ADT Priority Queue. A
CS104: Data Structures and Object-Oriented Design (Fall 2013) October 24, 2013: Priority Queues Scribes: CS 104 Teaching Team Lecture Summary In this lecture, we learned about the ADT Priority Queue. A
A Non-Linear Schema Theorem for Genetic Algorithms
 A Non-Linear Schema Theorem for Genetic Algorithms William A Greene Computer Science Department University of New Orleans New Orleans, LA 70148 bill@csunoedu 504-280-6755 Abstract We generalize Holland
A Non-Linear Schema Theorem for Genetic Algorithms William A Greene Computer Science Department University of New Orleans New Orleans, LA 70148 bill@csunoedu 504-280-6755 Abstract We generalize Holland
Integer Factorization using the Quadratic Sieve
 Integer Factorization using the Quadratic Sieve Chad Seibert* Division of Science and Mathematics University of Minnesota, Morris Morris, MN 56567 seib0060@morris.umn.edu March 16, 2011 Abstract We give
Integer Factorization using the Quadratic Sieve Chad Seibert* Division of Science and Mathematics University of Minnesota, Morris Morris, MN 56567 seib0060@morris.umn.edu March 16, 2011 Abstract We give
Regular Expressions and Automata using Haskell
 Regular Expressions and Automata using Haskell Simon Thompson Computing Laboratory University of Kent at Canterbury January 2000 Contents 1 Introduction 2 2 Regular Expressions 2 3 Matching regular expressions
Regular Expressions and Automata using Haskell Simon Thompson Computing Laboratory University of Kent at Canterbury January 2000 Contents 1 Introduction 2 2 Regular Expressions 2 3 Matching regular expressions
The Relational Data Model
 CHAPTER 8 The Relational Data Model Database One of the most important applications for computers is storing and managing information. The manner in which information is organized can have a profound effect
CHAPTER 8 The Relational Data Model Database One of the most important applications for computers is storing and managing information. The manner in which information is organized can have a profound effect
QUEUES. Primitive Queue operations. enqueue (q, x): inserts item x at the rear of the queue q
: inserts item x at the rear of the queue q") QUEUES A queue is simply a waiting line that grows by adding elements to its end and shrinks by removing elements from the. Compared to stack, it reflects the more commonly used maxim in real-world, namely,
QUEUES A queue is simply a waiting line that grows by adding elements to its end and shrinks by removing elements from the. Compared to stack, it reflects the more commonly used maxim in real-world, namely,
Sequential Data Structures
 Sequential Data Structures In this lecture we introduce the basic data structures for storing sequences of objects. These data structures are based on arrays and linked lists, which you met in first year
Sequential Data Structures In this lecture we introduce the basic data structures for storing sequences of objects. These data structures are based on arrays and linked lists, which you met in first year
Data Structures and Algorithms!
 Data Structures and Algorithms! The material for this lecture is drawn, in part, from! The Practice of Programming (Kernighan & Pike) Chapter 2! 1 Motivating Quotation!!! Every program depends on algorithms
Data Structures and Algorithms! The material for this lecture is drawn, in part, from! The Practice of Programming (Kernighan & Pike) Chapter 2! 1 Motivating Quotation!!! Every program depends on algorithms
Lecture 11 Doubly Linked Lists & Array of Linked Lists. Doubly Linked Lists
 Lecture 11 Doubly Linked Lists & Array of Linked Lists In this lecture Doubly linked lists Array of Linked Lists Creating an Array of Linked Lists Representing a Sparse Matrix Defining a Node for a Sparse
Lecture 11 Doubly Linked Lists & Array of Linked Lists In this lecture Doubly linked lists Array of Linked Lists Creating an Array of Linked Lists Representing a Sparse Matrix Defining a Node for a Sparse
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Big Data & Scripting Part II Streaming Algorithms 1, Counting Distinct Elements 2, 3, counting distinct elements problem formalization input: stream of elements o from some universe U e.g. ids from a set
Converting a Number from Decimal to Binary
 Converting a Number from Decimal to Binary Convert nonnegative integer in decimal format (base 10) into equivalent binary number (base 2) Rightmost bit of x Remainder of x after division by two Recursive
Converting a Number from Decimal to Binary Convert nonnegative integer in decimal format (base 10) into equivalent binary number (base 2) Rightmost bit of x Remainder of x after division by two Recursive
Data Structures and Algorithms!
 Data Structures and Algorithms! The material for this lecture is drawn, in part, from! The Practice of Programming (Kernighan & Pike) Chapter 2! 1 Motivating Quotation!!! Every program depends on algorithms
Data Structures and Algorithms! The material for this lecture is drawn, in part, from! The Practice of Programming (Kernighan & Pike) Chapter 2! 1 Motivating Quotation!!! Every program depends on algorithms
Regular Languages and Finite Automata
 Regular Languages and Finite Automata 1 Introduction Hing Leung Department of Computer Science New Mexico State University Sep 16, 2010 In 1943, McCulloch and Pitts [4] published a pioneering work on a
Regular Languages and Finite Automata 1 Introduction Hing Leung Department of Computer Science New Mexico State University Sep 16, 2010 In 1943, McCulloch and Pitts [4] published a pioneering work on a
11 Multivariate Polynomials
 CS 487: Intro. to Symbolic Computation Winter 2009: M. Giesbrecht Script 11 Page 1 (These lecture notes were prepared and presented by Dan Roche.) 11 Multivariate Polynomials References: MC: Section 16.6
CS 487: Intro. to Symbolic Computation Winter 2009: M. Giesbrecht Script 11 Page 1 (These lecture notes were prepared and presented by Dan Roche.) 11 Multivariate Polynomials References: MC: Section 16.6
Chapter 6: Physical Database Design and Performance. Database Development Process. Physical Design Process. Physical Database Design
 Chapter 6: Physical Database Design and Performance Modern Database Management 6 th Edition Jeffrey A. Hoffer, Mary B. Prescott, Fred R. McFadden Robert C. Nickerson ISYS 464 Spring 2003 Topic 23 Database
Chapter 6: Physical Database Design and Performance Modern Database Management 6 th Edition Jeffrey A. Hoffer, Mary B. Prescott, Fred R. McFadden Robert C. Nickerson ISYS 464 Spring 2003 Topic 23 Database
Database Design Patterns. Winter 2006-2007 Lecture 24
 Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Database Design Patterns Winter 2006-2007 Lecture 24 Trees and Hierarchies Many schemas need to represent trees or hierarchies of some sort Common way of representing trees: An adjacency list model Each
Efficient representation of integer sets
 Efficient representation of integer sets Marco Almeida Rogério Reis Technical Report Series: DCC-2006-06 Version 1.0 Departamento de Ciência de Computadores & Laboratório de Inteligência Artificial e Ciência
Efficient representation of integer sets Marco Almeida Rogério Reis Technical Report Series: DCC-2006-06 Version 1.0 Departamento de Ciência de Computadores & Laboratório de Inteligência Artificial e Ciência