Advanced Introduction to Machine Learning CMU-10715
|
|
|
- Theodore Byron Davidson
- 7 years ago
- Views:
Transcription
1 Advanced Introduction to Machine Learning CMU Support Vector Machines Barnabás Póczos, 2014 Fall
2 Linear classifiers which line is better? 2
3 Pick the one with the largest margin! w x + b > 0 Class 1 w Class 2 w x + b < 0 Data: Margin 3
4 Scaling Plus-Plane Classifier Boundary Minus-Plane Classification rule: Classify as.. +1 if w x+ b 1 1 if w x+ b 1 Universe explodes if -1 < w x+ b < 1 How large is the margin of this classifier? Goal: Find the maximum margin classifier 4
5 Computing the margin width x + M =Margin Width = 2 w w x - Let x + and x - be such that w x + + b = +1 w x - + b = -1 x + = x - + λ w x + x - = M=? (Margin) Maximize M minimize w w! 5
 (Quadratic cost function, linear")
6 The Primal Hard SVM This is a QP problem (m-dimensional) (Quadratic cost function, linear constraints) 6
7 Quadratic Programming Find Subject to and to Efficient Algorithms exist for QP. They often solve the dual problem instead of the primal. 7

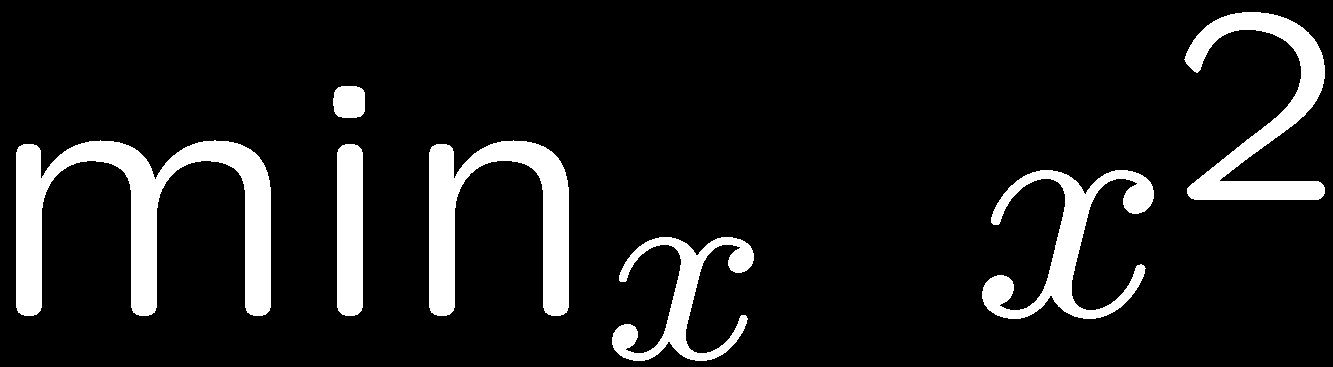
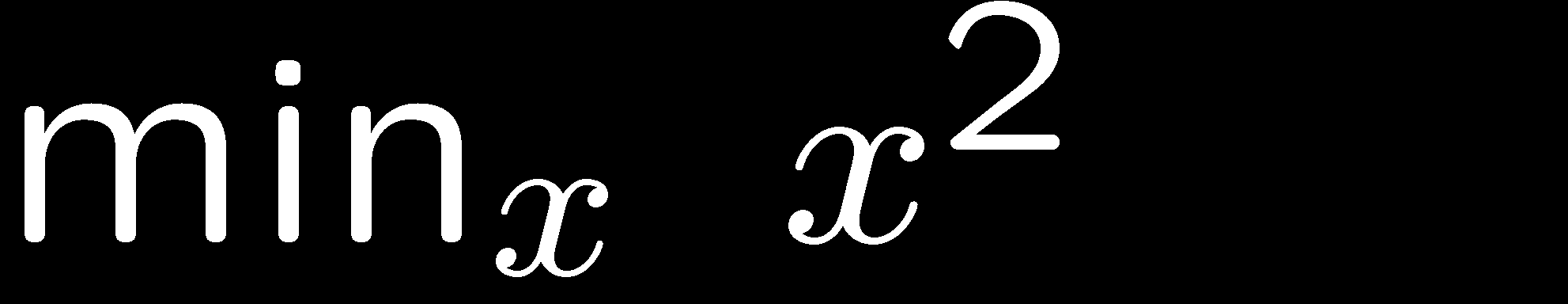
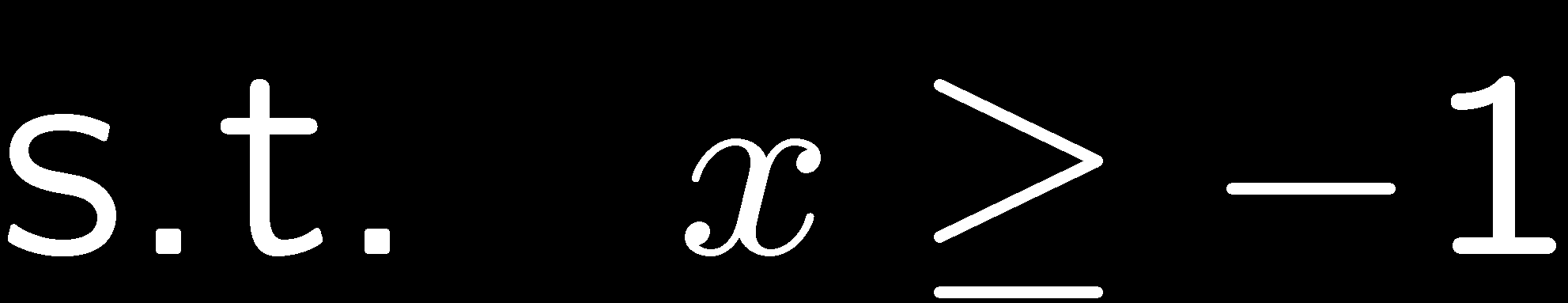
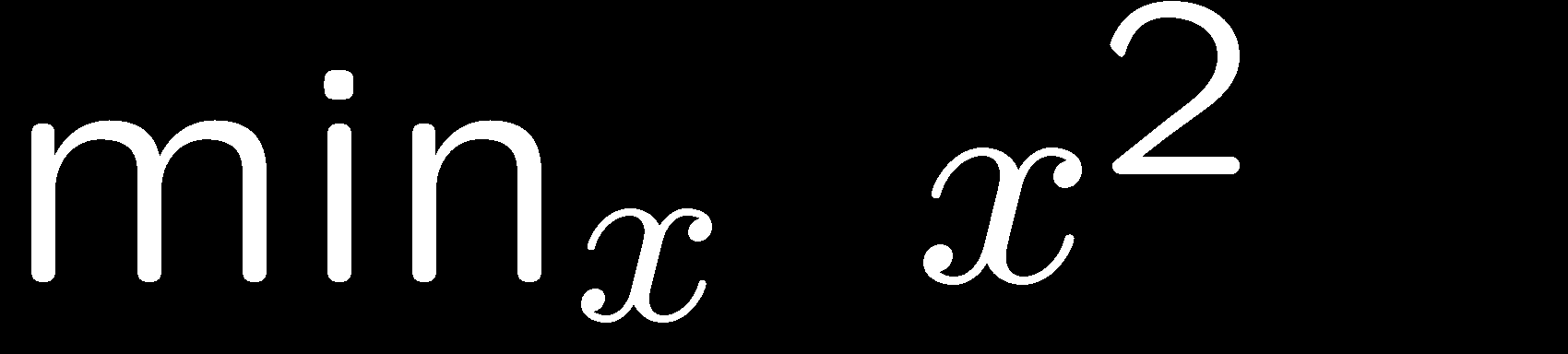

8 Constrained Optimization 8

9 Lagrange Multiplier Moving the constraint to objective function Lagrangian: Solve: Constraint is active when α > 0 9
10 Lagrange Multiplier Dual Variables Solving: When α > 0, constraint is tight 10
11 Primal problem: From Primal to Dual Lagrange function: 11
12 The Lagrange Problem The Lagrange problem: Proof cont. 12
13 The Dual Problem Proof cont. 13
")
14 The Dual Hard SVM Quadratic Programming (n-dimensional) Lemma 14
15 The Problem with Hard SVM It assumes samples are linearly separable... What can we do if data is not linearly separable??? 15
16 Hard 1-dimensional Dataset If the data set is notlinearly separable, then adding new features (mapping the data to a larger feature space) the data might become linearly separable 16
17 Hard 1-dimensional Dataset Make up a new feature! Sort of computed from original feature(s) z k = ( x k, x 2 k ) Separable! MAGIC! x=0 Now drop this augmented data into our linear SVM. 17
18 Feature mapping ngeneral! points in an n-1dimensional space is always linearly separable by a hyperspace! it is good to map the data to high dimensional spaces Having ntraining data, is it always enough to map the data into a feature space with dimension n-1? Nope... We have to think about the test data as well! Even if we don t know how many test data we have and what they are... We might want to map our data to a huge ( ) dimensional feature space Overfitting? Generalization error?... We don t care now... 18
19 How to do feature mapping? Use features of features of features of features. 19
20 The Problem with Hard SVM It assumes samples are linearly separable... Solutions: 1. Use feature transformation to a larger space each training samples are linearly separable in the feature space Hard SVM can be applied overfitting Soft margin SVM instead of Hard SVM Slack variables... We will discuss them now 20

21 Hard SVM The Hard SVM problem can be rewritten: where Misclassification, or inside the margin Correct classification and outside of the margin 21
22 From Hard to Soft constraints Instead of using hard constraints (points are linearly separable) We can try solve the soft version of it:. Introduce a λ parameter! (Your loss is only 1 instead of if you misclassify an instance) where Misclassification Correct classification 22
23 Problems with l 0-1 loss It is not convex in yf(x) It is not convex in w, either and we only like convex functions... Let us approximate it with convex functions! 23

24 Approximation of the Heaviside step function Picture is taken from R. Herbrich 24
25 Approximations of l 0-1 loss Piecewise linear approximations (hinge loss, l lin ) Quadratic approximation (l quad ) 25

26 The hinge loss approximation of l 0-1 Where, 26
27 The Slack Variables ξ 2 ξ 1 M = 2 w w ξ7 27
28 The Primal Soft SVM problem where Equivalently, 28
29 The Primal Soft SVM problem Equivalently, We can use this form, too... What is the dual form of primal soft SVM? 29
30 The Dual Soft SVM (using hinge loss) where 30
")
31 The Dual Soft SVM (using hinge loss) 31
32 The Dual Soft SVM (using hinge loss) 32
33 SVM classification in the dual space Solve the dual problem 33
34 Why is it called Support Vector Machine? KKT conditions
35 Dual SVM Interpretation: Sparsity α j = 0 α j > 0 α j > 0 α j = 0 Only few α j s can be non-zero : where constraint is tight α j > 0 α j = 0 (<w,x j> + b)y j = 1 Support vectors training points j whose α j s are non-zero 35
36 Support Vectors w.x + b > 0 w.x + b < 0 Linear hyperplane defined by support vectors Moving other points a little doesn t effect the decision boundary γ γ only need to store the support vectors to predict labels of new points 36
37 Support vectors in Soft SVM
38 Support vectors in Soft SVM Margin support vectors Nonmargin support vectors

39 SVM classification in the dual space Without b With b 39

40 SVM with Linear Programs QP: Max margin LP: Min support vectors
41 SVM for Regression 41
42 Ridge Regression Linear regression: Primal: Dual for a given λ:...after some calculations... This can be solved in closed form:
43 Kernel Ridge Regression Algorithm
44 SVM vs. Logistic Regression SVM : Hinge loss Logistic Regression : Log loss ( log conditional likelihood) Log loss Hinge loss 0-1 loss
45 Difference between SVMs and Logistic Regression SVMs Logistic Regression Loss function Hinge loss Log-loss High dimensional features with kernels Yes! No (but there is kernel logistic regression too) Solution sparse Often yes! Almost always no! Semantics of output Margin Real probabilities
46 Constructing Kernels
47 Common Kernels Polynomials of degree d Polynomials of degree up to d Gaussian/Radial kernels Sigmoid 47
48 Designing new kernels from kernels are also kernels. Picture is taken from R. Herbrich
49 Designing new kernels from kernels Picture is taken from R. Herbrich
50 Designing new kernels from kernels
51 Higher Order Polynomials m input features d degree of polynomial grows fast! d = 6, m = 100 about 1.6 billion terms 51
52 Dot Product of Polynomials d=1 d=2 d 52
53 Picture is taken from R. Herbrich
54 The RBF kernel Note: Proof: Note:
55 Overfitting Huge feature space with kernels, what about overfitting??? Maximizing margin leads to sparse set of support vectors Some interesting theory says that SVMs search for simple hypothesis with large margin Often robust to overfitting 55
56 String kernels P-spectrum kernel: P=3: s= statistics t= computation They contain the following substrings of length 3 sta, tat, ati, tis, ist, sti, tic, ics com, omp, mpu, put, uta, tat, ati, tio, ion Common substrings: tat, ati k(s,t)=2
57 Distribution kernels Euclidean: Bhattacharyya's affinity: Mean map:
58 Set kernels Mean map: Intersection kernel: Union complement kernel:
59 What about multiple classes? 59
60 One against all Learn 3 classifiers separately: Class k vs. rest (w k, b k ) k=1,2,3 y = arg max w k.x + b k k But w k s may not be based on the same scale. Note: (aw).x + (ab) is also a solution 60
61 Learn 1 classifier: Multi-class SVM Simultaneously learn 3 sets of weights Margin - gap between correct class and nearest other class y = arg max w (k).x + b (k) 61
62 Learn 1 classifier: Multi-class SVM Simultaneously learn 3 sets of weights y = arg max w (k).x + b (k) Joint optimization: w k s have the same scale. 62

63 Steve Gunn s svm toolbox Results, Iris 2vs13, Linear kernel 63
64 Results, Iris 1vs23, 2 nd order kernel 64
65 Results, Iris 1vs23, 2nd order kernel 65

66 Results, Iris 1vs23, RBF kernel 66

67 Results, Iris 1vs23, RBF kernel 67

68 Results, Iris 1vs23, RBF kernel 68
69 Results, Chessboard, Poly kernel 69
70 Results, Chessboard, Poly kernel 70

71 Results, Chessboard, Poly kernel 71
72 Results, Chessboard, Poly kernel 72
73 Results, Chessboard, poly kernel 73

74 Results, Chessboard, RBF kernel 74
75 Sinc=sin(π x)/ (π x), RBF kernel
76 Sinc=sin(π x)/ (π x), RBF kernel
77 Sinc=sin(π x)/ (π x), RBF kernel
78 Sinc=sin(π x)/ (π x), RBF kernel
79 Sinc=sin(π x)/ (π x), RBF kernel
80 Sinc=sin(π x)/ (π x), RBF kernel
81 Sinc=sin(π x)/ (π x), poly kernel
82 Sinc=sin(π x)/ (π x), poly kernel
83 Sinc=sin(π x)/ (π x), poly kernel
84 Sinc=sin(π x)/ (π x), poly kernel
85 Sinc=sin(π x)/ (π x), poly kernel
86 Sinc=sin(π x)/ (π x), poly kernel
87 What you need to know Dual SVM formulation How it s derived Common kernels Differences between SVMs and logistic regression 87
88 Thanks for your attention 88
Support Vector Machine (SVM)
") Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
A Simple Introduction to Support Vector Machines
 A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
Support Vector Machines Explained
 March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Support Vector Machines
 Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Support Vector Machines Charlie Frogner 1 MIT 2011 1 Slides mostly stolen from Ryan Rifkin (Google). Plan Regularization derivation of SVMs. Analyzing the SVM problem: optimization, duality. Geometric
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Support Vector Machines for Classification and Regression
 UNIVERSITY OF SOUTHAMPTON Support Vector Machines for Classification and Regression by Steve R. Gunn Technical Report Faculty of Engineering, Science and Mathematics School of Electronics and Computer
UNIVERSITY OF SOUTHAMPTON Support Vector Machines for Classification and Regression by Steve R. Gunn Technical Report Faculty of Engineering, Science and Mathematics School of Electronics and Computer
Search Taxonomy. Web Search. Search Engine Optimization. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Information Retrieval INFO 4300 / CS 4300! Retrieval models Older models» Boolean retrieval» Vector Space model Probabilistic Models» BM25» Language models Web search» Learning to Rank Search Taxonomy!
Several Views of Support Vector Machines
 Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Several Views of Support Vector Machines Ryan M. Rifkin Honda Research Institute USA, Inc. Human Intention Understanding Group 2007 Tikhonov Regularization We are considering algorithms of the form min
Big Data - Lecture 1 Optimization reminders
 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Big Data - Lecture 1 Optimization reminders S. Gadat Toulouse, Octobre 2014 Schedule Introduction Major issues Examples Mathematics
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S
 e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) To go the other way, you need to diagonalize S 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Lecture 2: The SVM classifier
 Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Lecture 2: The SVM classifier C19 Machine Learning Hilary 2015 A. Zisserman Review of linear classifiers Linear separability Perceptron Support Vector Machine (SVM) classifier Wide margin Cost function
Support Vector Machine. Tutorial. (and Statistical Learning Theory)
") Support Vector Machine (and Statistical Learning Theory) Tutorial Jason Weston NEC Labs America 4 Independence Way, Princeton, USA. jasonw@nec-labs.com 1 Support Vector Machines: history SVMs introduced
Support Vector Machine (and Statistical Learning Theory) Tutorial Jason Weston NEC Labs America 4 Independence Way, Princeton, USA. jasonw@nec-labs.com 1 Support Vector Machines: history SVMs introduced
Artificial Neural Networks and Support Vector Machines. CS 486/686: Introduction to Artificial Intelligence
 Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Artificial Neural Networks and Support Vector Machines CS 486/686: Introduction to Artificial Intelligence 1 Outline What is a Neural Network? - Perceptron learners - Multi-layer networks What is a Support
Duality in General Programs. Ryan Tibshirani Convex Optimization 10-725/36-725
 Duality in General Programs Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: duality in linear programs Given c R n, A R m n, b R m, G R r n, h R r : min x R n c T x max u R m, v R r b T
Duality in General Programs Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: duality in linear programs Given c R n, A R m n, b R m, G R r n, h R r : min x R n c T x max u R m, v R r b T
Distributed Machine Learning and Big Data
 Distributed Machine Learning and Big Data Sourangshu Bhattacharya Dept. of Computer Science and Engineering, IIT Kharagpur. http://cse.iitkgp.ac.in/~sourangshu/ August 21, 2015 Sourangshu Bhattacharya
Distributed Machine Learning and Big Data Sourangshu Bhattacharya Dept. of Computer Science and Engineering, IIT Kharagpur. http://cse.iitkgp.ac.in/~sourangshu/ August 21, 2015 Sourangshu Bhattacharya
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Support Vector Machines
 CS229 Lecture notes Andrew Ng Part V Support Vector Machines This set of notes presents the Support Vector Machine (SVM) learning algorithm. SVMs are among the best (and many believe are indeed the best)
CS229 Lecture notes Andrew Ng Part V Support Vector Machines This set of notes presents the Support Vector Machine (SVM) learning algorithm. SVMs are among the best (and many believe are indeed the best)
Lecture 2: August 29. Linear Programming (part I)
") 10-725: Convex Optimization Fall 2013 Lecture 2: August 29 Lecturer: Barnabás Póczos Scribes: Samrachana Adhikari, Mattia Ciollaro, Fabrizio Lecci Note: LaTeX template courtesy of UC Berkeley EECS dept.
10-725: Convex Optimization Fall 2013 Lecture 2: August 29 Lecturer: Barnabás Póczos Scribes: Samrachana Adhikari, Mattia Ciollaro, Fabrizio Lecci Note: LaTeX template courtesy of UC Berkeley EECS dept.
Neural Networks and Support Vector Machines
 INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
Lecture 6: Logistic Regression
 Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
A fast multi-class SVM learning method for huge databases
 www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
www.ijcsi.org 544 A fast multi-class SVM learning method for huge databases Djeffal Abdelhamid 1, Babahenini Mohamed Chaouki 2 and Taleb-Ahmed Abdelmalik 3 1,2 Computer science department, LESIA Laboratory,
Making Sense of the Mayhem: Machine Learning and March Madness
 Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
Machine Learning Logistic Regression
 Machine Learning Logistic Regression Jeff Howbert Introduction to Machine Learning Winter 2012 1 Logistic regression Name is somewhat misleading. Really a technique for classification, not regression.
Machine Learning Logistic Regression Jeff Howbert Introduction to Machine Learning Winter 2012 1 Logistic regression Name is somewhat misleading. Really a technique for classification, not regression.
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Predict Influencers in the Social Network
 Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, lyzhou@stanford.edu Department of Electrical Engineering, Stanford University Abstract Given two persons
Predict Influencers in the Social Network Ruishan Liu, Yang Zhao and Liuyu Zhou Email: rliu2, yzhao2, lyzhou@stanford.edu Department of Electrical Engineering, Stanford University Abstract Given two persons
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
DUOL: A Double Updating Approach for Online Learning
 : A Double Updating Approach for Online Learning Peilin Zhao School of Comp. Eng. Nanyang Tech. University Singapore 69798 zhao6@ntu.edu.sg Steven C.H. Hoi School of Comp. Eng. Nanyang Tech. University
: A Double Updating Approach for Online Learning Peilin Zhao School of Comp. Eng. Nanyang Tech. University Singapore 69798 zhao6@ntu.edu.sg Steven C.H. Hoi School of Comp. Eng. Nanyang Tech. University
AdaBoost. Jiri Matas and Jan Šochman. Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz
 AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
AdaBoost Jiri Matas and Jan Šochman Centre for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Presentation Outline: AdaBoost algorithm Why is of interest? How it works? Why
Classification algorithm in Data mining: An Overview
 Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Classification algorithm in Data mining: An Overview S.Neelamegam #1, Dr.E.Ramaraj *2 #1 M.phil Scholar, Department of Computer Science and Engineering, Alagappa University, Karaikudi. *2 Professor, Department
Introduction to nonparametric regression: Least squares vs. Nearest neighbors
 Introduction to nonparametric regression: Least squares vs. Nearest neighbors Patrick Breheny October 30 Patrick Breheny STA 621: Nonparametric Statistics 1/16 Introduction For the remainder of the course,
Introduction to nonparametric regression: Least squares vs. Nearest neighbors Patrick Breheny October 30 Patrick Breheny STA 621: Nonparametric Statistics 1/16 Introduction For the remainder of the course,
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Going For Large Scale Going For Large Scale 1
Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Going For Large Scale Going For Large Scale 1
Machine Learning Final Project Spam Email Filtering
 Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Machine Learning Final Project Spam Email Filtering March 2013 Shahar Yifrah Guy Lev Table of Content 1. OVERVIEW... 3 2. DATASET... 3 2.1 SOURCE... 3 2.2 CREATION OF TRAINING AND TEST SETS... 4 2.3 FEATURE
Nonlinear Optimization: Algorithms 3: Interior-point methods
 Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris Jean-Philippe.Vert@mines.org Nonlinear optimization c 2006 Jean-Philippe Vert,
Nonlinear Optimization: Algorithms 3: Interior-point methods INSEAD, Spring 2006 Jean-Philippe Vert Ecole des Mines de Paris Jean-Philippe.Vert@mines.org Nonlinear optimization c 2006 Jean-Philippe Vert,
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Nonlinear Programming Methods.S2 Quadratic Programming
 Nonlinear Programming Methods.S2 Quadratic Programming Operations Research Models and Methods Paul A. Jensen and Jonathan F. Bard A linearly constrained optimization problem with a quadratic objective
Nonlinear Programming Methods.S2 Quadratic Programming Operations Research Models and Methods Paul A. Jensen and Jonathan F. Bard A linearly constrained optimization problem with a quadratic objective
CSC 411: Lecture 07: Multiclass Classification
 CSC 411: Lecture 07: Multiclass Classification Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 1, 2016 Urtasun, Zemel, Fidler (UofT) CSC 411: 07-Multiclass
CSC 411: Lecture 07: Multiclass Classification Class based on Raquel Urtasun & Rich Zemel s lectures Sanja Fidler University of Toronto Feb 1, 2016 Urtasun, Zemel, Fidler (UofT) CSC 411: 07-Multiclass
Machine Learning in Spam Filtering
 Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Machine Learning in Spam Filtering A Crash Course in ML Konstantin Tretyakov kt@ut.ee Institute of Computer Science, University of Tartu Overview Spam is Evil ML for Spam Filtering: General Idea, Problems.
Online learning of multi-class Support Vector Machines
 IT 12 061 Examensarbete 30 hp November 2012 Online learning of multi-class Support Vector Machines Xuan Tuan Trinh Institutionen för informationsteknologi Department of Information Technology Abstract
IT 12 061 Examensarbete 30 hp November 2012 Online learning of multi-class Support Vector Machines Xuan Tuan Trinh Institutionen för informationsteknologi Department of Information Technology Abstract
Semi-Supervised Support Vector Machines and Application to Spam Filtering
 Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Lecture 3. Linear Programming. 3B1B Optimization Michaelmas 2015 A. Zisserman. Extreme solutions. Simplex method. Interior point method
 Lecture 3 3B1B Optimization Michaelmas 2015 A. Zisserman Linear Programming Extreme solutions Simplex method Interior point method Integer programming and relaxation The Optimization Tree Linear Programming
Lecture 3 3B1B Optimization Michaelmas 2015 A. Zisserman Linear Programming Extreme solutions Simplex method Interior point method Integer programming and relaxation The Optimization Tree Linear Programming
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Fóra Gyula Krisztián. Predictive analysis of financial time series
 Eötvös Loránd University Faculty of Science Fóra Gyula Krisztián Predictive analysis of financial time series BSc Thesis Supervisor: Lukács András Department of Computer Science Budapest, June 2014 Acknowledgements
Eötvös Loránd University Faculty of Science Fóra Gyula Krisztián Predictive analysis of financial time series BSc Thesis Supervisor: Lukács András Department of Computer Science Budapest, June 2014 Acknowledgements
Machine learning for algo trading
 Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Lecture 3: Linear methods for classification
 Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
Lecture 3: Linear methods for classification Rafael A. Irizarry and Hector Corrada Bravo February, 2010 Today we describe four specific algorithms useful for classification problems: linear regression,
4.1 Introduction - Online Learning Model
 Computational Learning Foundations Fall semester, 2010 Lecture 4: November 7, 2010 Lecturer: Yishay Mansour Scribes: Elad Liebman, Yuval Rochman & Allon Wagner 1 4.1 Introduction - Online Learning Model
Computational Learning Foundations Fall semester, 2010 Lecture 4: November 7, 2010 Lecturer: Yishay Mansour Scribes: Elad Liebman, Yuval Rochman & Allon Wagner 1 4.1 Introduction - Online Learning Model
MAXIMIZING RETURN ON DIRECT MARKETING CAMPAIGNS
 MAXIMIZING RETURN ON DIRET MARKETING AMPAIGNS IN OMMERIAL BANKING S 229 Project: Final Report Oleksandra Onosova INTRODUTION Recent innovations in cloud computing and unified communications have made a
MAXIMIZING RETURN ON DIRET MARKETING AMPAIGNS IN OMMERIAL BANKING S 229 Project: Final Report Oleksandra Onosova INTRODUTION Recent innovations in cloud computing and unified communications have made a
Multiclass Classification. 9.520 Class 06, 25 Feb 2008 Ryan Rifkin
 Multiclass Classification 9.520 Class 06, 25 Feb 2008 Ryan Rifkin It is a tale Told by an idiot, full of sound and fury, Signifying nothing. Macbeth, Act V, Scene V What Is Multiclass Classification? Each
Multiclass Classification 9.520 Class 06, 25 Feb 2008 Ryan Rifkin It is a tale Told by an idiot, full of sound and fury, Signifying nothing. Macbeth, Act V, Scene V What Is Multiclass Classification? Each
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 22, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 22, 2014 1 /
A User s Guide to Support Vector Machines
 A User s Guide to Support Vector Machines Asa Ben-Hur Department of Computer Science Colorado State University Jason Weston NEC Labs America Princeton, NJ 08540 USA Abstract The Support Vector Machine
A User s Guide to Support Vector Machines Asa Ben-Hur Department of Computer Science Colorado State University Jason Weston NEC Labs America Princeton, NJ 08540 USA Abstract The Support Vector Machine
Linear Programming Notes V Problem Transformations
 Linear Programming Notes V Problem Transformations 1 Introduction Any linear programming problem can be rewritten in either of two standard forms. In the first form, the objective is to maximize, the material
Linear Programming Notes V Problem Transformations 1 Introduction Any linear programming problem can be rewritten in either of two standard forms. In the first form, the objective is to maximize, the material
Support-Vector Networks
 Machine Learning, 20, 273-297 (1995) 1995 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. Support-Vector Networks CORINNA CORTES VLADIMIR VAPNIK AT&T Bell Labs., Holmdel, NJ 07733,
Machine Learning, 20, 273-297 (1995) 1995 Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. Support-Vector Networks CORINNA CORTES VLADIMIR VAPNIK AT&T Bell Labs., Holmdel, NJ 07733,
Logistic Regression. Jia Li. Department of Statistics The Pennsylvania State University. Logistic Regression
 Logistic Regression Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Logistic Regression Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets
 Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets Ricardo Ramos Guerra Jörg Stork Master in Automation and IT Faculty of Computer Science and Engineering
Case Study Report: Building and analyzing SVM ensembles with Bagging and AdaBoost on big data sets Ricardo Ramos Guerra Jörg Stork Master in Automation and IT Faculty of Computer Science and Engineering
Logistic Regression. Vibhav Gogate The University of Texas at Dallas. Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld.
 Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Logistic Regression Vibhav Gogate The University of Texas at Dallas Some Slides from Carlos Guestrin, Luke Zettlemoyer and Dan Weld. Generative vs. Discriminative Classifiers Want to Learn: h:x Y X features
Mathematical Models of Supervised Learning and their Application to Medical Diagnosis
 Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Adapting Codes and Embeddings for Polychotomies
 Adapting Codes and Embeddings for Polychotomies Gunnar Rätsch, Alexander J. Smola RSISE, CSL, Machine Learning Group The Australian National University Canberra, 2 ACT, Australia Gunnar.Raetsch, Alex.Smola
Adapting Codes and Embeddings for Polychotomies Gunnar Rätsch, Alexander J. Smola RSISE, CSL, Machine Learning Group The Australian National University Canberra, 2 ACT, Australia Gunnar.Raetsch, Alex.Smola
10. Proximal point method
 L. Vandenberghe EE236C Spring 2013-14) 10. Proximal point method proximal point method augmented Lagrangian method Moreau-Yosida smoothing 10-1 Proximal point method a conceptual algorithm for minimizing
L. Vandenberghe EE236C Spring 2013-14) 10. Proximal point method proximal point method augmented Lagrangian method Moreau-Yosida smoothing 10-1 Proximal point method a conceptual algorithm for minimizing
Active Learning with Boosting for Spam Detection
 Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Active Learning with Boosting for Spam Detection Nikhila Arkalgud Last update: March 22, 2008 Active Learning with Boosting for Spam Detection Last update: March 22, 2008 1 / 38 Outline 1 Spam Filters
Machine Learning. CUNY Graduate Center, Spring 2013. Professor Liang Huang. huang@cs.qc.cuny.edu
 Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Machine Learning CUNY Graduate Center, Spring 2013 Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning Logistics Lectures M 9:30-11:30 am Room 4419 Personnel
Probabilistic Linear Classification: Logistic Regression. Piyush Rai IIT Kanpur
 Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
Probabilistic Linear Classification: Logistic Regression Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 18, 2016 Probabilistic Machine Learning (CS772A) Probabilistic Linear Classification:
E-commerce Transaction Anomaly Classification
 E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
An Introduction to Machine Learning
 An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune,
An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune,
KEITH LEHNERT AND ERIC FRIEDRICH
 MACHINE LEARNING CLASSIFICATION OF MALICIOUS NETWORK TRAFFIC KEITH LEHNERT AND ERIC FRIEDRICH 1. Introduction 1.1. Intrusion Detection Systems. In our society, information systems are everywhere. They
MACHINE LEARNING CLASSIFICATION OF MALICIOUS NETWORK TRAFFIC KEITH LEHNERT AND ERIC FRIEDRICH 1. Introduction 1.1. Intrusion Detection Systems. In our society, information systems are everywhere. They
Beating the NCAA Football Point Spread
 Beating the NCAA Football Point Spread Brian Liu Mathematical & Computational Sciences Stanford University Patrick Lai Computer Science Department Stanford University December 10, 2010 1 Introduction Over
Beating the NCAA Football Point Spread Brian Liu Mathematical & Computational Sciences Stanford University Patrick Lai Computer Science Department Stanford University December 10, 2010 1 Introduction Over
Introduction to Online Learning Theory
 Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Introduction to Online Learning Theory Wojciech Kot lowski Institute of Computing Science, Poznań University of Technology IDSS, 04.06.2013 1 / 53 Outline 1 Example: Online (Stochastic) Gradient Descent
Maximum Margin Clustering
 Maximum Margin Clustering Linli Xu James Neufeld Bryce Larson Dale Schuurmans University of Waterloo University of Alberta Abstract We propose a new method for clustering based on finding maximum margin
Maximum Margin Clustering Linli Xu James Neufeld Bryce Larson Dale Schuurmans University of Waterloo University of Alberta Abstract We propose a new method for clustering based on finding maximum margin
Server Load Prediction
 Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
Server Load Prediction Suthee Chaidaroon (unsuthee@stanford.edu) Joon Yeong Kim (kim64@stanford.edu) Jonghan Seo (jonghan@stanford.edu) Abstract Estimating server load average is one of the methods that
A Tutorial on Support Vector Machines for Pattern Recognition
 c,, 1 43 () Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. A Tutorial on Support Vector Machines for Pattern Recognition CHRISTOPHER J.C. BURGES Bell Laboratories, Lucent Technologies
c,, 1 43 () Kluwer Academic Publishers, Boston. Manufactured in The Netherlands. A Tutorial on Support Vector Machines for Pattern Recognition CHRISTOPHER J.C. BURGES Bell Laboratories, Lucent Technologies
Introduction to Logistic Regression
 OpenStax-CNX module: m42090 1 Introduction to Logistic Regression Dan Calderon This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License 3.0 Abstract Gives introduction
OpenStax-CNX module: m42090 1 Introduction to Logistic Regression Dan Calderon This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License 3.0 Abstract Gives introduction
Trading regret rate for computational efficiency in online learning with limited feedback
 Trading regret rate for computational efficiency in online learning with limited feedback Shai Shalev-Shwartz TTI-C Hebrew University On-line Learning with Limited Feedback Workshop, 2009 June 2009 Shai
Trading regret rate for computational efficiency in online learning with limited feedback Shai Shalev-Shwartz TTI-C Hebrew University On-line Learning with Limited Feedback Workshop, 2009 June 2009 Shai
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
Foundations of Machine Learning On-Line Learning. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu
 Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Applications of Support Vector-Based Learning
 Applications of Support Vector-Based Learning Róbert Ormándi The supervisors are Prof. János Csirik and Dr. Márk Jelasity Research Group on Artificial Intelligence of the University of Szeged and the Hungarian
Applications of Support Vector-Based Learning Róbert Ormándi The supervisors are Prof. János Csirik and Dr. Márk Jelasity Research Group on Artificial Intelligence of the University of Szeged and the Hungarian
Simple and efficient online algorithms for real world applications
 Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Simple and efficient online algorithms for real world applications Università degli Studi di Milano Milano, Italy Talk @ Centro de Visión por Computador Something about me PhD in Robotics at LIRA-Lab,
Proximal mapping via network optimization
 L. Vandenberghe EE236C (Spring 23-4) Proximal mapping via network optimization minimum cut and maximum flow problems parametric minimum cut problem application to proximal mapping Introduction this lecture:
L. Vandenberghe EE236C (Spring 23-4) Proximal mapping via network optimization minimum cut and maximum flow problems parametric minimum cut problem application to proximal mapping Introduction this lecture:
Network Intrusion Detection using Semi Supervised Support Vector Machine
 Network Intrusion Detection using Semi Supervised Support Vector Machine Jyoti Haweliya Department of Computer Engineering Institute of Engineering & Technology, Devi Ahilya University Indore, India ABSTRACT
Network Intrusion Detection using Semi Supervised Support Vector Machine Jyoti Haweliya Department of Computer Engineering Institute of Engineering & Technology, Devi Ahilya University Indore, India ABSTRACT
Big Data Analytics: Optimization and Randomization
 Big Data Analytics: Optimization and Randomization Tianbao Yang, Qihang Lin, Rong Jin Tutorial@SIGKDD 2015 Sydney, Australia Department of Computer Science, The University of Iowa, IA, USA Department of
Big Data Analytics: Optimization and Randomization Tianbao Yang, Qihang Lin, Rong Jin Tutorial@SIGKDD 2015 Sydney, Australia Department of Computer Science, The University of Iowa, IA, USA Department of
Linear Programming Notes VII Sensitivity Analysis
 Linear Programming Notes VII Sensitivity Analysis 1 Introduction When you use a mathematical model to describe reality you must make approximations. The world is more complicated than the kinds of optimization
Linear Programming Notes VII Sensitivity Analysis 1 Introduction When you use a mathematical model to describe reality you must make approximations. The world is more complicated than the kinds of optimization
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Linear Models for Classification
 Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
Linear Models for Classification Sumeet Agarwal, EEL709 (Most figures from Bishop, PRML) Approaches to classification Discriminant function: Directly assigns each data point x to a particular class Ci
Question 2 Naïve Bayes (16 points)
") Question 2 Naïve Bayes (16 points) About 2/3 of your email is spam so you downloaded an open source spam filter based on word occurrences that uses the Naive Bayes classifier. Assume you collected the
Question 2 Naïve Bayes (16 points) About 2/3 of your email is spam so you downloaded an open source spam filter based on word occurrences that uses the Naive Bayes classifier. Assume you collected the
Content-Based Recommendation
 Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Data Mining. Supervised Methods. Ciro Donalek donalek@astro.caltech.edu. Ay/Bi 199ab: Methods of Computa@onal Sciences hcp://esci101.blogspot.
 Data Mining Supervised Methods Ciro Donalek donalek@astro.caltech.edu Supervised Methods Summary Ar@ficial Neural Networks Mul@layer Perceptron Support Vector Machines SoLwares Supervised Models: Supervised
Data Mining Supervised Methods Ciro Donalek donalek@astro.caltech.edu Supervised Methods Summary Ar@ficial Neural Networks Mul@layer Perceptron Support Vector Machines SoLwares Supervised Models: Supervised
Local classification and local likelihoods
 Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Early defect identification of semiconductor processes using machine learning
 STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
Classification of Bad Accounts in Credit Card Industry
 Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of high resolution satellite images
 Thesis for the degree of Master of Science in Engineering Physics Classification of high resolution satellite images Anders Karlsson Laboratoire de Systèmes d Information Géographique Ecole Polytéchnique
Thesis for the degree of Master of Science in Engineering Physics Classification of high resolution satellite images Anders Karlsson Laboratoire de Systèmes d Information Géographique Ecole Polytéchnique
Online (and Offline) on an Even Tighter Budget
 on an Even Tighter Budget") Online (and Offline) on an Even Tighter Budget Jason Weston NEC Laboratories America, Princeton, NJ, USA jasonw@nec-labs.com Antoine Bordes NEC Laboratories America, Princeton, NJ, USA antoine@nec-labs.com
Online (and Offline) on an Even Tighter Budget Jason Weston NEC Laboratories America, Princeton, NJ, USA jasonw@nec-labs.com Antoine Bordes NEC Laboratories America, Princeton, NJ, USA antoine@nec-labs.com
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Increasing for all. Convex for all. ( ) Increasing for all (remember that the log function is only defined for ). ( ) Concave for all.
 Increasing for all (remember that the log function is only defined for ). ( ) Concave for all.") 1. Differentiation The first derivative of a function measures by how much changes in reaction to an infinitesimal shift in its argument. The largest the derivative (in absolute value), the faster is evolving.
1. Differentiation The first derivative of a function measures by how much changes in reaction to an infinitesimal shift in its argument. The largest the derivative (in absolute value), the faster is evolving.
Pattern Analysis. Logistic Regression. 12. Mai 2009. Joachim Hornegger. Chair of Pattern Recognition Erlangen University
 Pattern Analysis Logistic Regression 12. Mai 2009 Joachim Hornegger Chair of Pattern Recognition Erlangen University Pattern Analysis 2 / 43 1 Logistic Regression Posteriors and the Logistic Function Decision
Pattern Analysis Logistic Regression 12. Mai 2009 Joachim Hornegger Chair of Pattern Recognition Erlangen University Pattern Analysis 2 / 43 1 Logistic Regression Posteriors and the Logistic Function Decision
A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION
 1 A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION Dimitri Bertsekas M.I.T. FEBRUARY 2003 2 OUTLINE Convexity issues in optimization Historical remarks Our treatment of the subject Three unifying lines of
1 A NEW LOOK AT CONVEX ANALYSIS AND OPTIMIZATION Dimitri Bertsekas M.I.T. FEBRUARY 2003 2 OUTLINE Convexity issues in optimization Historical remarks Our treatment of the subject Three unifying lines of
Decision Support Systems
 Decision Support Systems 50 (2011) 602 613 Contents lists available at ScienceDirect Decision Support Systems journal homepage: www.elsevier.com/locate/dss Data mining for credit card fraud: A comparative
Decision Support Systems 50 (2011) 602 613 Contents lists available at ScienceDirect Decision Support Systems journal homepage: www.elsevier.com/locate/dss Data mining for credit card fraud: A comparative
Data clustering optimization with visualization
 Page 1 Data clustering optimization with visualization Fabien Guillaume MASTER THESIS IN SOFTWARE ENGINEERING DEPARTMENT OF INFORMATICS UNIVERSITY OF BERGEN NORWAY DEPARTMENT OF COMPUTER ENGINEERING BERGEN
Page 1 Data clustering optimization with visualization Fabien Guillaume MASTER THESIS IN SOFTWARE ENGINEERING DEPARTMENT OF INFORMATICS UNIVERSITY OF BERGEN NORWAY DEPARTMENT OF COMPUTER ENGINEERING BERGEN