System Software for Big Data Computing. Cho-Li Wang The University of Hong Kong
|
|
|
- Jocelin Thornton
- 8 years ago
- Views:
Transcription
1 System Software for Big Data Computing Cho-Li Wang The University of Hong Kong

2 HKU High-Performance Computing Lab. Total # of cores: 3004 CPU GPU cores RAM Size: 8.34 TB Disk storage: 130 TB Peak computing power: TFlops GPU-Cluster (Nvidia M2050, Tianhe-1a ): 7.62 Tflops 31.45TFlops (X12 in 3.5 years) T 3.1T 20T CS Gideon-II & CC MDRP Clusters
: 7.62 Tflops 31.45TFlops (X12 in 3.")
3 Big Data: The "3Vs" Model High Volume (amount of data) High Velocity (speed of data in and out) High Variety (range of data types and sources) 2.5 x : 800,000 petabytes (would fill a stack of DVDs reaching from the earth to the moon and back) By 2020, that pile of DVDs would stretch half way to Mars.
 By 2020, that pile of DVDs would stretch half")
4 Our Research Heterogeneous Manycore Computing (CPUs+ GUPs) Big Data Computing on Future Manycore Chips Multi-granularity Computation Migration

5 JAPONICA : Java with Auto- Parallelization ON GraphIcs Coprocessing Architecture (1) Heterogeneous Manycore Computing (CPUs+ GUPs)


6 CPUs GPU Heterogeneous Manycore Architecture 6
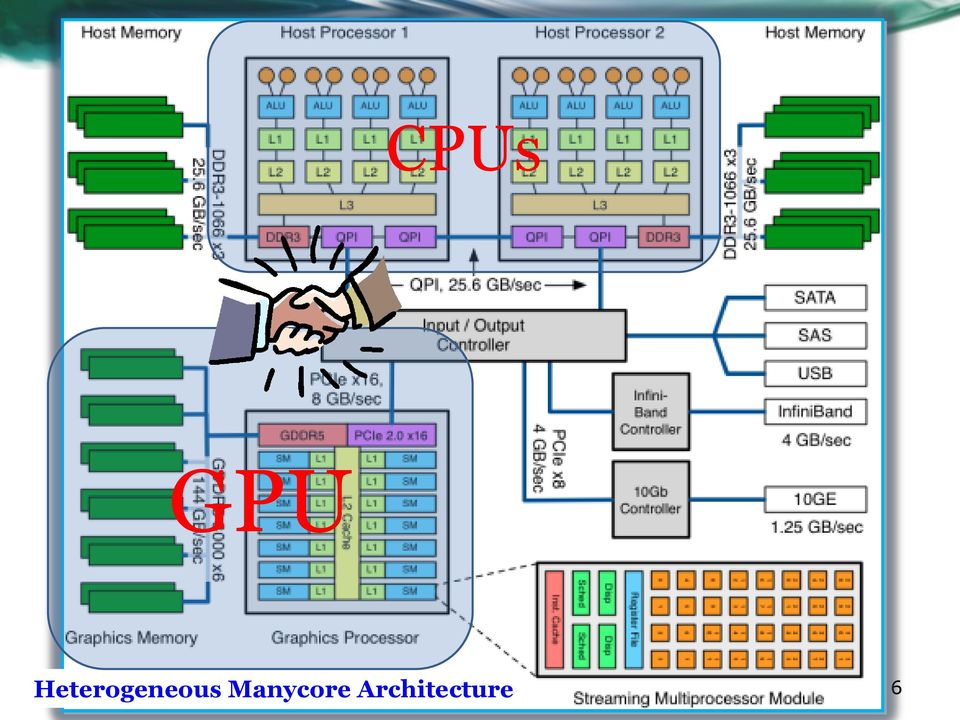
7 New GPU & Coprocessors Vendor Model Launch Date Fab. (nm) #Accelerator Cores (Max.) GPU Clock (MHz) TDP (watts) Memory Bandwidth (GB/s) Programming Model Remarks Intel Sandy Bridge Ivy Bridge 2011Q Q HD graphics 3000 EUs (8 threads/eu) 16 HD graphics 4000 EUs (8 threads/eu) L3: 8MB Sys mem (DDR3) L3: 8MB Sys mem (DDR3) 21 OpenCL 25.6 Bandwidth is system DDR3 memory bandwidth Xeon Phi 2012H x86 cores (with a 512-bit vector unit) GB GDDR5 320 OpenMP#, OpenCL*, OpenACC% Less sensitive to branch divergent workloads AMD Brazos Q2 40 Trinity 2012Q Evergreen shader cores Northern Islands cores L2: 1MB Sys mem (DDR3) L2: 4MB Sys mem (DDR3) 21 OpenCL, C++AMP 25 APU Nvidia Fermi 2010Q1 40 Kepler (GK110) 2012Q Cuda cores (16 SMs) 2880 Cuda cores / L1: 48KB L2: 768KB 6GB 148 6GB GDDR CUDA, OpenCL, OpenACC 3X Perf/Watt, Dynamic Parallelism, HyperQ 7
 600-1100 300 8GB GDDR5 320 OpenMP#, OpenCL*, OpenACC% Less sensitive to branch divergent")
8 #1 in Top500 (11/2012): Oak Ridge National Lab. 18,688 AMD Opteron core CPUs (32GB DDR3). 18,688 Nvidia Tesla K20X GPUs Total RAM size: over 710 TB Total Storage: 10 PB. Peak Performance: 27 Petaflop/s o GPU: CPU = TF/s: TF/s = 9.3 : 1 Linpack: Petaflop/s Power Consumption: 8.2 MW Titan compute board: 4 AMD Opteron + 4 NVIDIA Tesla K20X GPUs NVIDIA Tesla K20X (Kepler GK110) GPU: 2688 CUDA cores 8

9 Design Challenge: GPU Can t Handle Dynamic Loops GPU = SIMD/Vector Data Dependency Issues (RAW, WAW) Solutions? Static loops for(i=0; i<n; i++) { C[i] = A[i] + B[i]; } Dynamic loops for(i=0; i<n; i++) { A[ w[i] ] = 3 * A[ r[i] ]; } 9 Non-deterministic data dependencies inhibit exploitation of inherent parallelism; only DO-ALL loops or embarrassingly parallel workload gets admitted to GPUs. 9
![Static loops for(i=0; i<n; i++) { C[i] = A[i] + B[i]; } Dynamic loops for(i=0; i<n; i++) { A[ w[i]](/docs-images/43/4186978/images/page_9.jpg "] = 3 * A[ r[i] ]; } 9 Non-deterministic data dependencies inhibit exploitation of inherent")

10 Dynamic loops are common in scientific and engineering applications Source: Z. Shen, Z. Li, and P. Yew, "An Empirical Study on Array Subscripts and Data Dependencies" 10


11 GPU-TLS : Thread-level Speculation on GPU Incremental parallelization o sliding window style execution. Efficient dependency checking schemes Deferred update o Speculative updates are stored in the write buffer of each thread until the commit time. 3 phases of execution Phase I Phase II Phase III Speculative execution Dependency checking Commit intra-thread RAW valid inter-thread RAW in GPU true inter-thread RAW GPU: lock-step execution in the same warp (32 threads per warp). 11

12 JAPONICA : Profile-Guided Work Dispatching Dynamic Profiling Parallel High Scheduler Dependency density Medium Highly parallel Inter-iteration dependence: -- Read-After-Write (RAW) -- Write-After-Read (WAR) -- Write-After-Write (WAW) Low/None Massively parallel 8 high-speed x86 cores Multi-core CPU 64 x86 cores 2880 cores Many-core coprocessors 12

13 JAPONICA : System Architecture Sequential Java Code with user annotation Code Translation JavaR Static Dep. Analysis DO-ALL Parallelizer CPU-Multi threads No dependence GPU-Many threads Uncertain CUDA kernels & CPU Multi-threads Task Sharing High DD : CPU single core Low DD : CPU+GPU-TLS 0 : CPU multithreads + GPU Dependency Density Analysis Intra-warp Dep. Check RAW Profiler (on GPU) GPU-TLS Inter-warp Dep. Check Speculator Task Scheduler : CPU-GPU Co-Scheduling Task Stealing CPU queue: low, high, 0 GPU queue: low, 0 Profiling Results WAW/WAR Privatization Program Dependence Graph (PDG) one loop CUDA kernels with GPU-TLS Privatization & CPU Single-thread Assign the tasks among CPU & GPU according to their dependency density (DD) CPU Communication GPU 13
 one")
14 (2) Crocodiles: Cloud Runtime with Object Coherence On Dynamic tiles

15 General Purpose Manycore Tile-based architecture: Cores are connected through a 2D networkon-a-chip


16 GbE PCI-E Memory Controller 鳄 HKU (01/ /2015) Crocodiles: Cloud Runtime with Object Coherence On Dynamic tiles for future 1000-core tiled processors PCI-E GbE Memory Controller RAM RAM RAM RAM ZONE 2 ZONE 1 ZONE 4 ZONE 3 Memory Controller GbE PCI-E DRAM Controller PCI-E GbE 16

.")
17 Dynamic Zoning o o o o Multi-tenant Cloud Architecture Partition varies over time, mimic Data center on a Chip. Performance isolation On-demand scaling. Power efficiency (high flops/watt).

 Gap of DRAM Density & Speed (b) DRAM Latency Not Improved Memory density has doubled nearly every two years, while performance has improved slowly (e.g.")
18 Design Challenge: Off-chip Memory Wall Problem DRAM performance (latency) improved slowly over the past 40 years. (a) Gap of DRAM Density & Speed (b) DRAM Latency Not Improved Memory density has doubled nearly every two years, while performance has improved slowly (e.g. still 100+ of core clock cycles per memory access)

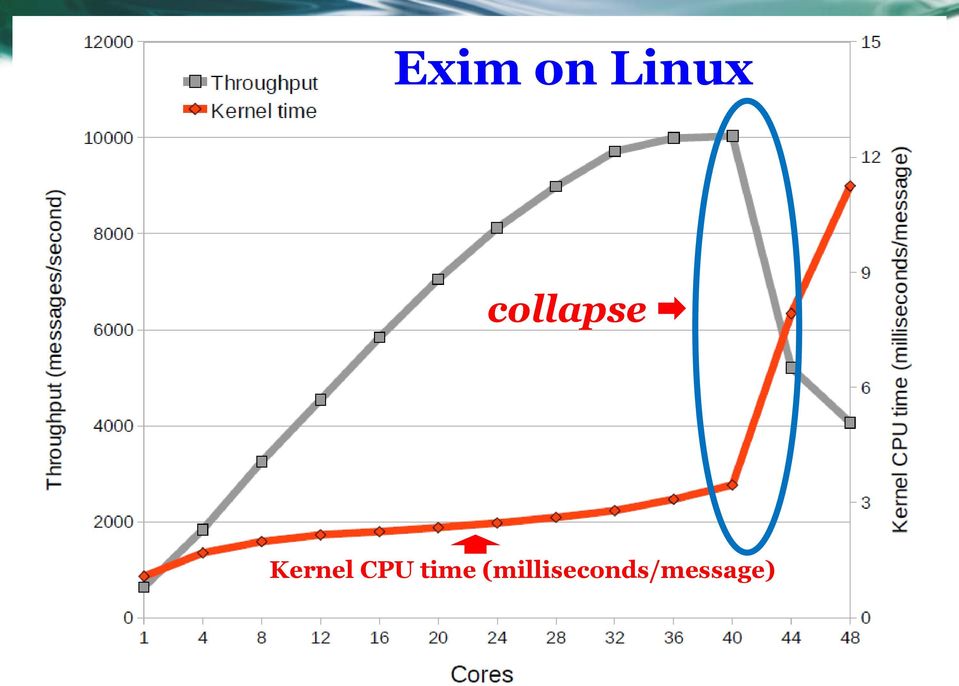
19 Lock Contention in Multicore System Physical memory allocation performance sorted by function. As more cores are added more processing time is spent contending for locks. Lock Contention

20 Exim on Linux collapse Kernel CPU time (milliseconds/message)
21 Challenges and Potential Solutions Cache-aware design o o Data Locality/Working Set getting critical! Compiler or runtime techniques to improve data reuse Stop multitasking o o Context switching breaks data locality Time Sharing Space Sharing 马 其 顿 方 阵 众 核 操 作 系 统 : Next-generation Operating System for 1000-core processor 21
22 Thanks! For more information: C.L. Wang s webpage:

23
")
24 Multi-granularity Computation Migration Granularity Coarse WAVNet Desktop Cloud G-JavaMPI Fine Small JESSICA2 SOD Large System scale (Size of state) 24

25 WAVNet: Live VM Migration over WAN A P2P Cloud with Live VM Migration over WAN Virtualized LAN over the Internet High penetration via NAT hole punching Establish direct host-to-host connection Free from proxies, able to traverse most NATs Key Members VM VM Zheming Xu, Sheng Di, Weida Zhang, Luwei Cheng, and Cho-Li Wang, WAVNet: Wide-Area Network Virtualization Technique for Virtual Private Cloud, 2011 International Conference on Parallel Processing (ICPP2011) 25
26 WAVNet: Experiments at Pacific Rim Areas 北 京 高 能 物 理 所 IHEP, Beijing 日 本 产 业 技 术 综 合 研 究 所 (AIST, Japan) SDSC, San Diego 深 圳 先 进 院 (SIAT) 中 央 研 究 院 (Sinica, Taiwan) 香 港 大 学 (HKU) 静 宜 大 学 (Providence University) 26 26
27 JESSICA2: Distributed Java Virtual Machine A Multithreaded Java Program Java Enabled Single System Image Computing Architecture Thread Migration Portable Java Frame JIT Compiler Mode JESSICA2 JVM JESSICA2 JVM JESSICA2 JVM JESSICA2 JVM JESSICA2 JVM JESSICA2 JVM Master Worker Worker Worker 27 27
28 History and Roadmap of JESSICA Project JESSICA V1.0 ( ) Execution mode: Interpreter Mode JVM kernel modification (Kaffe JVM) Global heap: built on top of TreadMarks (Lazy Release Consistency + homeless) JESSICA V2.0 ( ) Execution mode: JIT-Compiler Mode JVM kernel modification Lazy release consistency + migrating-home protocol JESSICA V3.0 (2008~2010) Built above JVM (via JVMTI) Support Large Object Space JESSICA v.4 (2010~) Japonica : Automatic loop parallization and speculative execution on GPU and multicore CPU TrC-DC : a software transactional memory system on cluster with distributed clocks (not discussed) King Tin LAM, Past Members Chenggang Zhang J1 and J2 received a total of 1107 source code downloads Kinson Chan Ricky Ma 28
fetching Cloud node Mobile node")
29 Stack-on-Demand (SOD) Stack frame A Method Stack frame A Program Counter Local variables Method Area Stack frame A Program Counter Local variables Stack frame B Program Counter Heap Area Rebuilt Method Area Local variables Heap Area Object (Pre-)fetching Cloud node Mobile node objects
30 Elastic Execution Model via SOD (a) Remote Method Call (b) Mimic thread migration (c) Task Roaming : like a mobile agent roaming over the network or workflow With such flexible or composable execution paths, SOD enables agile and elastic exploitation of distributed resources (storage), a Big Data Solution! Lightweight, Portable, Adaptable 30

31 Stack-on-demand (SOD) Live migration Method Area Code Stacks Heap Method Area Code Stack segments JVM ios Partial Heap Small footprint Load balancer Thread migration (JESSICA2) Cloud service provider duplicate VM instances for scaling JVM process Mobile client Multi-thread Java process Internet JVM comm. JVM trigger live migration guest OS Xen VM guest OS Xen VM Xen-aware host OS Overloaded Desktop PC Load balancer excloud : Integrated Solution for Multigranularity Migration Ricky K. K. Ma, King Tin Lam, Cho-Li Wang, "excloud: Transparent Runtime Support for Scaling Mobile Applications," 2011 IEEE International Conference on Cloud and Service Computing (CSC2011),. (Best Paper Award)
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Enabling Technologies for Distributed Computing
 Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
Enabling Technologies for Distributed Computing Dr. Sanjay P. Ahuja, Ph.D. Fidelity National Financial Distinguished Professor of CIS School of Computing, UNF Multi-core CPUs and Multithreading Technologies
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
Enabling Technologies for Distributed and Cloud Computing
 Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Enabling Technologies for Distributed and Cloud Computing Dr. Sanjay P. Ahuja, Ph.D. 2010-14 FIS Distinguished Professor of Computer Science School of Computing, UNF Multi-core CPUs and Multithreading
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing
 Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
GPU Hardware and Programming Models. Jeremy Appleyard, September 2015
 GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
GPU Parallel Computing Architecture and CUDA Programming Model
 GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
GPU Parallel Computing Architecture and CUDA Programming Model John Nickolls Outline Why GPU Computing? GPU Computing Architecture Multithreading and Arrays Data Parallel Problem Decomposition Parallel
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK
 HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
Case Study on Productivity and Performance of GPGPUs
 Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Multi-core Programming System Overview
 Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Scaling from Datacenter to Client
 Scaling from Datacenter to Client KeunSoo Jo Sr. Manager Memory Product Planning Samsung Semiconductor Audio-Visual Sponsor Outline SSD Market Overview & Trends - Enterprise What brought us to NVMe Technology
Scaling from Datacenter to Client KeunSoo Jo Sr. Manager Memory Product Planning Samsung Semiconductor Audio-Visual Sponsor Outline SSD Market Overview & Trends - Enterprise What brought us to NVMe Technology
GPU Computing - CUDA
 GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters. from One Stop Systems (OSS)
 Clusters. from One Stop Systems (OSS)") PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters from One Stop Systems (OSS) PCIe Over Cable PCIe provides greater performance 8 7 6 5 GBytes/s 4
PCIe Over Cable Provides Greater Performance for Less Cost for High Performance Computing (HPC) Clusters from One Stop Systems (OSS) PCIe Over Cable PCIe provides greater performance 8 7 6 5 GBytes/s 4
A quick tutorial on Intel's Xeon Phi Coprocessor
 A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0
 PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0 15 th January 2014 Al Chrosny Director, Software Engineering TreeAge Software, Inc. achrosny@treeage.com Andrew Munzer Director, Training and Customer
PERFORMANCE ENHANCEMENTS IN TreeAge Pro 2014 R1.0 15 th January 2014 Al Chrosny Director, Software Engineering TreeAge Software, Inc. achrosny@treeage.com Andrew Munzer Director, Training and Customer
Improving System Scalability of OpenMP Applications Using Large Page Support
 Improving Scalability of OpenMP Applications on Multi-core Systems Using Large Page Support Ranjit Noronha and Dhabaleswar K. Panda Network Based Computing Laboratory (NBCL) The Ohio State University Outline
Improving Scalability of OpenMP Applications on Multi-core Systems Using Large Page Support Ranjit Noronha and Dhabaleswar K. Panda Network Based Computing Laboratory (NBCL) The Ohio State University Outline
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Overview of HPC Resources at Vanderbilt
 Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
Embedded Systems: map to FPGA, GPU, CPU?
 Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies
 Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies Kurt Klemperer, Principal System Performance Engineer kklemperer@blackboard.com Agenda Session Length:
Virtualization Technologies and Blackboard: The Future of Blackboard Software on Multi-Core Technologies Kurt Klemperer, Principal System Performance Engineer kklemperer@blackboard.com Agenda Session Length:
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Experiences on using GPU accelerators for data analysis in ROOT/RooFit
 Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server
 Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server Technology brief Introduction... 2 GPU-based computing... 2 ProLiant SL390s GPU-enabled architecture... 2 Optimizing
Optimizing GPU-based application performance for the HP for the HP ProLiant SL390s G7 server Technology brief Introduction... 2 GPU-based computing... 2 ProLiant SL390s GPU-enabled architecture... 2 Optimizing
MapReduce on GPUs. Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu
 1 MapReduce on GPUs Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu 2 MapReduce MAP Shuffle Reduce 3 Hadoop Open-source MapReduce framework from Apache, written in Java Used by Yahoo!, Facebook, Ebay,
1 MapReduce on GPUs Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu 2 MapReduce MAP Shuffle Reduce 3 Hadoop Open-source MapReduce framework from Apache, written in Java Used by Yahoo!, Facebook, Ebay,
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs
 Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
HPC-related R&D in 863 Program
 HPC-related R&D in 863 Program Depei Qian Sino-German Joint Software Institute (JSI) Beihang University Aug. 27, 2010 Outline The 863 key project on HPC and Grid Status and Next 5 years 863 efforts on
HPC-related R&D in 863 Program Depei Qian Sino-German Joint Software Institute (JSI) Beihang University Aug. 27, 2010 Outline The 863 key project on HPC and Grid Status and Next 5 years 863 efforts on
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Data Centers and Cloud Computing
 Data Centers and Cloud Computing CS377 Guest Lecture Tian Guo 1 Data Centers and Cloud Computing Intro. to Data centers Virtualization Basics Intro. to Cloud Computing Case Study: Amazon EC2 2 Data Centers
Data Centers and Cloud Computing CS377 Guest Lecture Tian Guo 1 Data Centers and Cloud Computing Intro. to Data centers Virtualization Basics Intro. to Cloud Computing Case Study: Amazon EC2 2 Data Centers
Mixed Precision Iterative Refinement Methods Energy Efficiency on Hybrid Hardware Platforms
 Mixed Precision Iterative Refinement Methods Energy Efficiency on Hybrid Hardware Platforms Björn Rocker Hamburg, June 17th 2010 Engineering Mathematics and Computing Lab (EMCL) KIT University of the State
Mixed Precision Iterative Refinement Methods Energy Efficiency on Hybrid Hardware Platforms Björn Rocker Hamburg, June 17th 2010 Engineering Mathematics and Computing Lab (EMCL) KIT University of the State
Stream Processing on GPUs Using Distributed Multimedia Middleware
 Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Stream Processing on GPUs Using Distributed Multimedia Middleware Michael Repplinger 1,2, and Philipp Slusallek 1,2 1 Computer Graphics Lab, Saarland University, Saarbrücken, Germany 2 German Research
Cloud Computing in Action - for Better Service and Better Life
 Cloud Computing in Action - for Better Service and Better Life Dr. P. T. Ho Deputy Director, Computer Centre The University of Hong Kong IET ICT Conference 2012, 14 September 2012, Hong Kong 1 2 Agenda
Cloud Computing in Action - for Better Service and Better Life Dr. P. T. Ho Deputy Director, Computer Centre The University of Hong Kong IET ICT Conference 2012, 14 September 2012, Hong Kong 1 2 Agenda
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs
 A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
Introduction to GPGPU. Tiziano Diamanti t.diamanti@cineca.it
 t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
t.diamanti@cineca.it Agenda From GPUs to GPGPUs GPGPU architecture CUDA programming model Perspective projection Vectors that connect the vanishing point to every point of the 3D model will intersecate
HP Workstations graphics card options
 Family data sheet HP Workstations graphics card options Quick reference guide Leading-edge professional graphics February 2013 A full range of graphics cards to meet your performance needs compare features
Family data sheet HP Workstations graphics card options Quick reference guide Leading-edge professional graphics February 2013 A full range of graphics cards to meet your performance needs compare features
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
Chapter 14 Virtual Machines
 Operating Systems: Internals and Design Principles Chapter 14 Virtual Machines Eighth Edition By William Stallings Virtual Machines (VM) Virtualization technology enables a single PC or server to simultaneously
Operating Systems: Internals and Design Principles Chapter 14 Virtual Machines Eighth Edition By William Stallings Virtual Machines (VM) Virtualization technology enables a single PC or server to simultaneously
Visit to the National University for Defense Technology Changsha, China. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Visit to the National University for Defense Technology Changsha, China Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 3, 2013 On May 28-29, 2013, I had the opportunity to attend
Visit to the National University for Defense Technology Changsha, China Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 3, 2013 On May 28-29, 2013, I had the opportunity to attend
HP Workstations graphics card options
 Family data sheet HP Workstations graphics card options Quick reference guide Leading-edge professional graphics March 2014 A full range of graphics cards to meet your performance needs compare features
Family data sheet HP Workstations graphics card options Quick reference guide Leading-edge professional graphics March 2014 A full range of graphics cards to meet your performance needs compare features
Stingray Traffic Manager Sizing Guide
 STINGRAY TRAFFIC MANAGER SIZING GUIDE 1 Stingray Traffic Manager Sizing Guide Stingray Traffic Manager version 8.0, December 2011. For internal and partner use. Introduction The performance of Stingray
STINGRAY TRAFFIC MANAGER SIZING GUIDE 1 Stingray Traffic Manager Sizing Guide Stingray Traffic Manager version 8.0, December 2011. For internal and partner use. Introduction The performance of Stingray
Amazon EC2 Product Details Page 1 of 5
 Amazon EC2 Product Details Page 1 of 5 Amazon EC2 Functionality Amazon EC2 presents a true virtual computing environment, allowing you to use web service interfaces to launch instances with a variety of
Amazon EC2 Product Details Page 1 of 5 Amazon EC2 Functionality Amazon EC2 presents a true virtual computing environment, allowing you to use web service interfaces to launch instances with a variety of
CUDA in the Cloud Enabling HPC Workloads in OpenStack With special thanks to Andrew Younge (Indiana Univ.) and Massimo Bernaschi (IAC-CNR)
 and Massimo Bernaschi (IAC-CNR)") CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu With special thanks to Andrew Younge (Indiana Univ.) and Massimo
CUDA in the Cloud Enabling HPC Workloads in OpenStack John Paul Walters Computer Scien5st, USC Informa5on Sciences Ins5tute jwalters@isi.edu With special thanks to Andrew Younge (Indiana Univ.) and Massimo
Parallel Firewalls on General-Purpose Graphics Processing Units
 Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
Parallel Firewalls on General-Purpose Graphics Processing Units Manoj Singh Gaur and Vijay Laxmi Kamal Chandra Reddy, Ankit Tharwani, Ch.Vamshi Krishna, Lakshminarayanan.V Department of Computer Engineering
NVIDIA CUDA Software and GPU Parallel Computing Architecture. David B. Kirk, Chief Scientist
 NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
NVIDIA CUDA Software and GPU Parallel Computing Architecture David B. Kirk, Chief Scientist Outline Applications of GPU Computing CUDA Programming Model Overview Programming in CUDA The Basics How to Get
Cloud Data Center Acceleration 2015
 Cloud Data Center Acceleration 2015 Agenda! Computer & Storage Trends! Server and Storage System - Memory and Homogenous Architecture - Direct Attachment! Memory Trends! Acceleration Introduction! FPGA
Cloud Data Center Acceleration 2015 Agenda! Computer & Storage Trends! Server and Storage System - Memory and Homogenous Architecture - Direct Attachment! Memory Trends! Acceleration Introduction! FPGA
Memory Architecture and Management in a NoC Platform
 Architecture and Management in a NoC Platform Axel Jantsch Xiaowen Chen Zhonghai Lu Chaochao Feng Abdul Nameed Yuang Zhang Ahmed Hemani DATE 2011 Overview Motivation State of the Art Data Management Engine
Architecture and Management in a NoC Platform Axel Jantsch Xiaowen Chen Zhonghai Lu Chaochao Feng Abdul Nameed Yuang Zhang Ahmed Hemani DATE 2011 Overview Motivation State of the Art Data Management Engine
Introduction to GPU Computing
 Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Chapter 2 Parallel Architecture, Software And Performance
 Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Turbomachinery CFD on many-core platforms experiences and strategies
 Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Performance Characteristics of Large SMP Machines
 Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
Performance Characteristics of Large SMP Machines Dirk Schmidl, Dieter an Mey, Matthias S. Müller schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) Agenda Investigated Hardware Kernel Benchmark
This Unit: Putting It All Together. CIS 501 Computer Architecture. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 11: Putting It All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Amir Roth with contributions by Milo
Kalray MPPA Massively Parallel Processing Array
 Kalray MPPA Massively Parallel Processing Array Next-Generation Accelerated Computing February 2015 2015 Kalray, Inc. All Rights Reserved February 2015 1 Accelerated Computing 2015 Kalray, Inc. All Rights
Kalray MPPA Massively Parallel Processing Array Next-Generation Accelerated Computing February 2015 2015 Kalray, Inc. All Rights Reserved February 2015 1 Accelerated Computing 2015 Kalray, Inc. All Rights
Xeon+FPGA Platform for the Data Center
 Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
NVIDIA GeForce GTX 580 GPU Datasheet
 NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
NVIDIA GeForce GTX 580 GPU Datasheet NVIDIA GeForce GTX 580 GPU Datasheet 3D Graphics Full Microsoft DirectX 11 Shader Model 5.0 support: o NVIDIA PolyMorph Engine with distributed HW tessellation engines
RWTH GPU Cluster. Sandra Wienke wienke@rz.rwth-aachen.de November 2012. Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
Evaluation of CUDA Fortran for the CFD code Strukti
 Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
OpenCL Optimization. San Jose 10/2/2009 Peng Wang, NVIDIA
 OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU
 Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Benchmark Hadoop and Mars: MapReduce on cluster versus on GPU Heshan Li, Shaopeng Wang The Johns Hopkins University 3400 N. Charles Street Baltimore, Maryland 21218 {heshanli, shaopeng}@cs.jhu.edu 1 Overview
Copyright 2013, Oracle and/or its affiliates. All rights reserved.
 1 Oracle SPARC Server for Enterprise Computing Dr. Heiner Bauch Senior Account Architect 19. April 2013 2 The following is intended to outline our general product direction. It is intended for information
1 Oracle SPARC Server for Enterprise Computing Dr. Heiner Bauch Senior Account Architect 19. April 2013 2 The following is intended to outline our general product direction. It is intended for information
Parallel Computing. Benson Muite. benson.muite@ut.ee http://math.ut.ee/ benson. https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage
 Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
Parallel Computing Benson Muite benson.muite@ut.ee http://math.ut.ee/ benson https://courses.cs.ut.ee/2014/paralleel/fall/main/homepage 3 November 2014 Hadoop, Review Hadoop Hadoop History Hadoop Framework
In-Memory Databases Algorithms and Data Structures on Modern Hardware. Martin Faust David Schwalb Jens Krüger Jürgen Müller
 In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
In-Memory Databases Algorithms and Data Structures on Modern Hardware Martin Faust David Schwalb Jens Krüger Jürgen Müller The Free Lunch Is Over 2 Number of transistors per CPU increases Clock frequency
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes. Anthony Kenisky, VP of North America Sales
 Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
OpenMP Programming on ScaleMP
 OpenMP Programming on ScaleMP Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
OpenMP Programming on ScaleMP Dirk Schmidl schmidl@rz.rwth-aachen.de Rechen- und Kommunikationszentrum (RZ) MPI vs. OpenMP MPI distributed address space explicit message passing typically code redesign
A Scalable VISC Processor Platform for Modern Client and Cloud Workloads
 A Scalable VISC Processor Platform for Modern Client and Cloud Workloads Mohammad Abdallah Founder, President and CTO Soft Machines Linley Processor Conference October 7, 2015 Agenda Soft Machines Background
A Scalable VISC Processor Platform for Modern Client and Cloud Workloads Mohammad Abdallah Founder, President and CTO Soft Machines Linley Processor Conference October 7, 2015 Agenda Soft Machines Background
Programming Techniques for Supercomputers: Multicore processors. There is no way back Modern multi-/manycore chips Basic Compute Node Architecture
 Programming Techniques for Supercomputers: Multicore processors There is no way back Modern multi-/manycore chips Basic ompute Node Architecture SimultaneousMultiThreading (SMT) Prof. Dr. G. Wellein (a,b),
Programming Techniques for Supercomputers: Multicore processors There is no way back Modern multi-/manycore chips Basic ompute Node Architecture SimultaneousMultiThreading (SMT) Prof. Dr. G. Wellein (a,b),
Informatica Ultra Messaging SMX Shared-Memory Transport
 White Paper Informatica Ultra Messaging SMX Shared-Memory Transport Breaking the 100-Nanosecond Latency Barrier with Benchmark-Proven Performance This document contains Confidential, Proprietary and Trade
White Paper Informatica Ultra Messaging SMX Shared-Memory Transport Breaking the 100-Nanosecond Latency Barrier with Benchmark-Proven Performance This document contains Confidential, Proprietary and Trade
FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25
 FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25 December 2014 FPGAs in the news» Catapult» Accelerate BING» 2x search acceleration:» ½ the number of servers»
FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25 December 2014 FPGAs in the news» Catapult» Accelerate BING» 2x search acceleration:» ½ the number of servers»
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
Introduction to GPU Architecture
 Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
Introduction to GPU Architecture Ofer Rosenberg, PMTS SW, OpenCL Dev. Team AMD Based on From Shader Code to a Teraflop: How GPU Shader Cores Work, By Kayvon Fatahalian, Stanford University Content 1. Three
ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop. Emily Apsey Performance Engineer
 ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop Emily Apsey Performance Engineer Presentation Overview What it takes to successfully virtualize ArcGIS Pro in Citrix XenApp and XenDesktop - Shareable
ArcGIS Pro: Virtualizing in Citrix XenApp and XenDesktop Emily Apsey Performance Engineer Presentation Overview What it takes to successfully virtualize ArcGIS Pro in Citrix XenApp and XenDesktop - Shareable
PSE Molekulardynamik
 OpenMP, bigger Applications 12.12.2014 Outline Schedule Presentations: Worksheet 4 OpenMP Multicore Architectures Membrane, Crystallization Preparation: Worksheet 5 2 Schedule 10.10.2014 Intro 1 WS 24.10.2014
OpenMP, bigger Applications 12.12.2014 Outline Schedule Presentations: Worksheet 4 OpenMP Multicore Architectures Membrane, Crystallization Preparation: Worksheet 5 2 Schedule 10.10.2014 Intro 1 WS 24.10.2014
How To Build A Supermicro Computer With A 32 Core Power Core (Powerpc) And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (
 And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
High Performance Computing in CST STUDIO SUITE
 High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
Computer Graphics Hardware An Overview
 Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
Computer Graphics Hardware An Overview Graphics System Monitor Input devices CPU/Memory GPU Raster Graphics System Raster: An array of picture elements Based on raster-scan TV technology The screen (and
LSI SAS inside 60% of servers. 21 million LSI SAS & MegaRAID solutions shipped over last 3 years. 9 out of 10 top server vendors use MegaRAID
 The vast majority of the world s servers count on LSI SAS & MegaRAID Trust us, build the LSI credibility in storage, SAS, RAID Server installed base = 36M LSI SAS inside 60% of servers 21 million LSI SAS
The vast majority of the world s servers count on LSI SAS & MegaRAID Trust us, build the LSI credibility in storage, SAS, RAID Server installed base = 36M LSI SAS inside 60% of servers 21 million LSI SAS
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER
 CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries
 Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
Performance Evaluations of Graph Database using CUDA and OpenMP Compatible Libraries Shin Morishima 1 and Hiroki Matsutani 1,2,3 1Keio University, 3 14 1 Hiyoshi, Kohoku ku, Yokohama, Japan 2National Institute
HPC performance applications on Virtual Clusters
 Panagiotis Kritikakos EPCC, School of Physics & Astronomy, University of Edinburgh, Scotland - UK pkritika@epcc.ed.ac.uk 4 th IC-SCCE, Athens 7 th July 2010 This work investigates the performance of (Java)
Panagiotis Kritikakos EPCC, School of Physics & Astronomy, University of Edinburgh, Scotland - UK pkritika@epcc.ed.ac.uk 4 th IC-SCCE, Athens 7 th July 2010 This work investigates the performance of (Java)
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
A Holistic Model of the Energy-Efficiency of Hypervisors
 A Holistic Model of the -Efficiency of Hypervisors in an HPC Environment Mateusz Guzek,Sebastien Varrette, Valentin Plugaru, Johnatan E. Pecero and Pascal Bouvry SnT & CSC, University of Luxembourg, Luxembourg
A Holistic Model of the -Efficiency of Hypervisors in an HPC Environment Mateusz Guzek,Sebastien Varrette, Valentin Plugaru, Johnatan E. Pecero and Pascal Bouvry SnT & CSC, University of Luxembourg, Luxembourg
Infrastructure Matters: POWER8 vs. Xeon x86
 Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
 More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
More on Pipelining and Pipelines in Real Machines CS 333 Fall 2006 Main Ideas Data Hazards RAW WAR WAW More pipeline stall reduction techniques Branch prediction» static» dynamic bimodal branch prediction
AMD WHITE PAPER GETTING STARTED WITH SEQUENCEL. AMD Embedded Solutions 1
 AMD WHITE PAPER GETTING STARTED WITH SEQUENCEL AMD Embedded Solutions 1 Optimizing Parallel Processing Performance and Coding Efficiency with AMD APUs and Texas Multicore Technologies SequenceL Auto-parallelizing
AMD WHITE PAPER GETTING STARTED WITH SEQUENCEL AMD Embedded Solutions 1 Optimizing Parallel Processing Performance and Coding Efficiency with AMD APUs and Texas Multicore Technologies SequenceL Auto-parallelizing
Overview of HPC systems and software available within
 Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers
 Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers Haohuan Fu haohuan@tsinghua.edu.cn High Performance Geo-Computing (HPGC) Group Center for Earth System Science Tsinghua University
Unleashing the Performance Potential of GPUs for Atmospheric Dynamic Solvers Haohuan Fu haohuan@tsinghua.edu.cn High Performance Geo-Computing (HPGC) Group Center for Earth System Science Tsinghua University