MPI Application Development Using the Analysis Tool MARMOT
|
|
|
- Allison Strickland
- 8 years ago
- Views:
Transcription
1 MPI Application Development Using the Analysis Tool MARMOT HLRS High Performance Computing Center Stuttgart Allmandring 30 D Stuttgart Höchstleistungsrechenzentrum Stuttgart

2 Overview General Problems of MPI Programming Related Work Design of MARMOT MARMOT & Applications Performance Results Conclusions Outlook Höchstleistungsrechenzentrum Stuttgart

3 Problems of MPI Programming All problems of serial programming Additional problems: Increased difficulty to verify correctness of program Increased difficulty to debug N parallel processes Portability issues between different MPI implementations and platforms, e.g. with mpich on the Crossgrid testbed: WARNING: MPI_Recv: tag= > 32767! MPI only guarantees tags up to this. THIS implementation allows tags up to versions of LAM-MPI < v 7.0 only guarantee tags up to New problems such as race conditions and deadlocks Höchstleistungsrechenzentrum Stuttgart

4 Related Work Parallel Debuggers, e.g. totalview, DDT, p2d2 Debug version of MPI Library Post-mortem analysis of trace files Special verification tools for runtime analysis MPI-CHECK Limited to Fortran Umpire First version limited to shared memory platforms Distributed memory version in preparation Not publicly available MARMOT Höchstleistungsrechenzentrum Stuttgart

5 Höchstleistungsrechenzentrum Stuttgart Design of MARMOT

6 What is MARMOT? Tool for the development of MPI applications Automatic runtime analysis of the application: Detect incorrect use of MPI Detect non-portable constructs Detect possible race conditions and deadlocks MARMOT does not require source code modifications, just relinking C and Fortran binding of MPI -1.2 is supported Höchstleistungsrechenzentrum Stuttgart

7 Design of MARMOT Application or Test Program Profiling Interface MARMOT core tool Debug Server (additional process) MPI library Höchstleistungsrechenzentrum Stuttgart

8 Examples of Server Checks: verification between the nodes, control of program Everything that requires a global view Control the execution flow, trace the MPI calls on each node throughout the whole application Signal conditions, e.g. deadlocks (with traceback on each node.) Check matching send/receive pairs for consistency Check collective calls for consistency Output of human readable log file Höchstleistungsrechenzentrum Stuttgart
 Check matching send/receive pairs for consistency Check collective calls for consistency Output of human")
9 Examples of Client Checks: verification on the local nodes Verification of proper construction and usage of MPI resources such as communicators, groups, datatypes etc., for example Verification of MPI_Request usage invalid recycling of active request invalid use of unregistered request warning if number of requests is zero warning if all requests are MPI_REQUEST_NULL Check for pending messages and active requests in MPI_Finalize Verification of all other arguments such as ranks, tags, etc Höchstleistungsrechenzentrum Stuttgart

10 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart
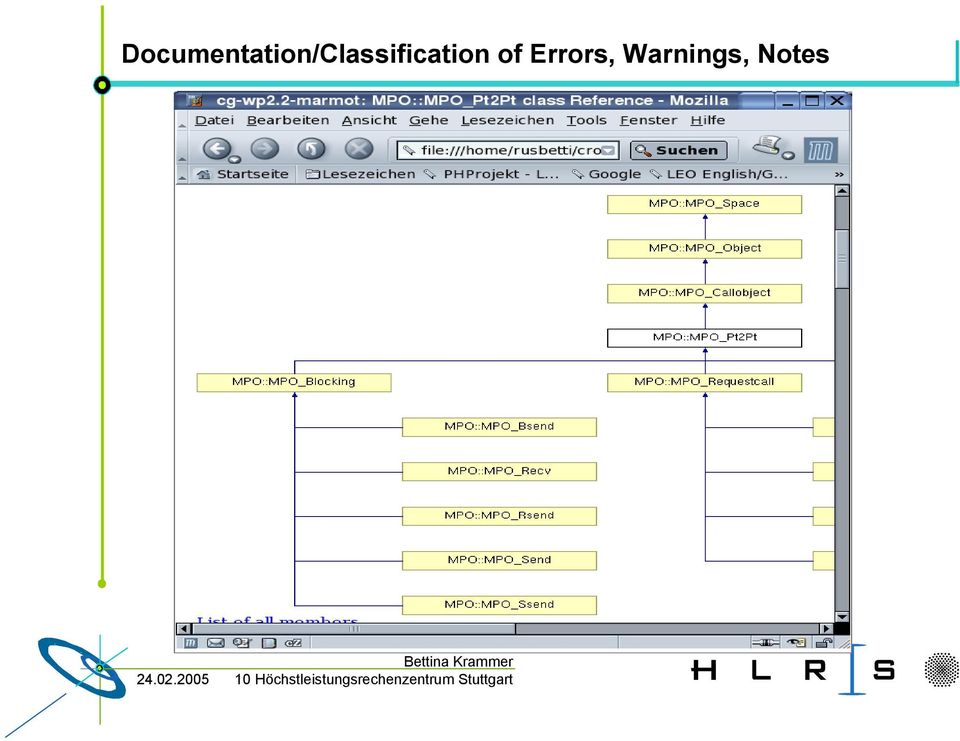
11 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart
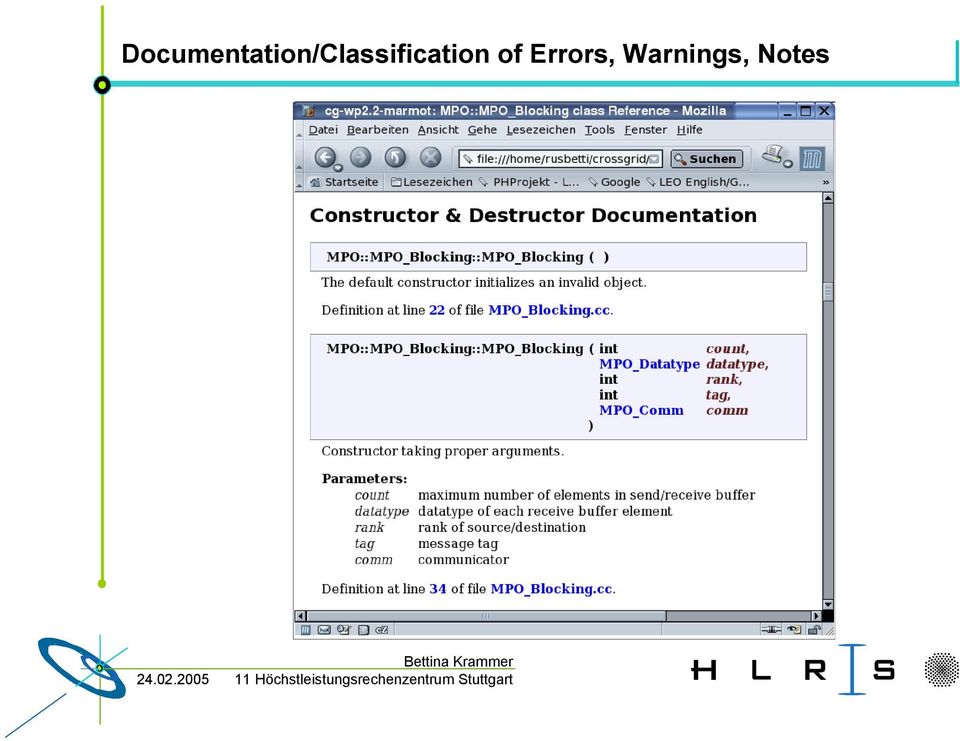
12 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart
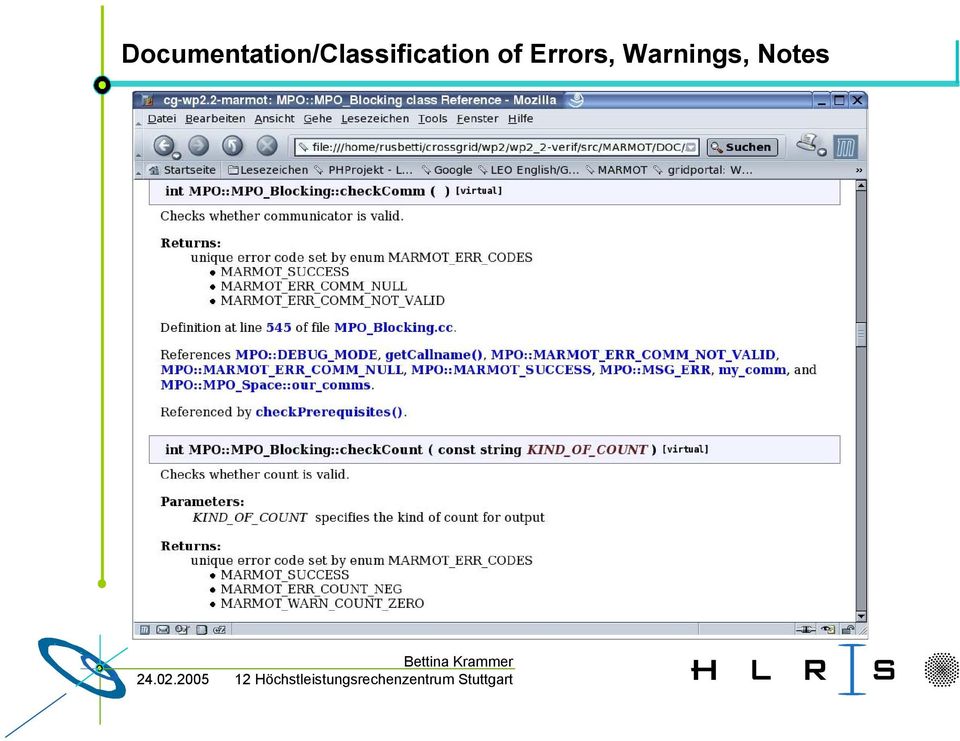
13 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart

14 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart

15 Documentation/Classification of Errors, Warnings, Notes Höchstleistungsrechenzentrum Stuttgart

16 Höchstleistungsrechenzentrum Stuttgart MARMOT & Applications

17 MARMOT within CrossGrid Name Application B_Stream Aladin, DaveF MM5 STEM ANN Blood flow simulation Flood simulation Air pollution modeling High Energy Physics Höchstleistungsrechenzentrum Stuttgart Language C Fortran90 Fortran77 C # lines million MHz (40 TB/sec) 75 KHz (75 GB/sec) 5 KHz (5 GB/sec) 100 Hz level data 3 recording - PCs & offline analysis level 1 - special hardware (100 MB/sec) level 2 - embedded processors
 75 KHz (75 GB/sec) 5 KHz (5 GB/sec) 100 Hz level data 3 recording - PCs & offline analysis")
18 Example: B_Stream (blood flow simulation, tube) Running the application without/with MARMOT: mpirun -np 3 B_Stream 500. tube mpirun -np 4 B_Stream_marmot 500. tube Application seems to run without problems Höchstleistungsrechenzentrum Stuttgart

19 Example: B_Stream (blood flow simulation, tube) 54 rank 1 performs MPI_Cart_shift 55 rank 2 performs MPI_Cart_shift 56 rank 0 performs MPI_Send 57 rank 1 performs MPI_Recv WARNING: MPI_Recv: Use of MPI_ANY_SOURCE may cause race conditions! 58 rank 2 performs MPI_Recv WARNING: MPI_Recv: Use of MPI_ANY_SOURCE may cause race conditions! 59 rank 0 performs MPI_Send 60 rank 1 performs MPI_Recv WARNING: MPI_Recv: Use of MPI_ANY_SOURCE may cause race conditions! 61 rank 0 performs MPI_Send 62 rank 1 performs MPI_Bcast 63 rank 2 performs MPI_Recv WARNING: MPI_Recv: Use of MPI_ANY_SOURCE may cause race conditions! 64 rank 0 performs MPI_Pack 65 rank 2 performs MPI_Bcast 66 rank 0 performs MPI_Pack Höchstleistungsrechenzentrum Stuttgart

20 Example: B_Stream (blood flow simulation, tube-stenosis) Without MARMOT: mpirun -np 3 B_Stream 500. tube-stenosis Application is hanging With MARMOT: mpirun -np 4 B_Stream_marmot 500. tube-stenosis Deadlock found Höchstleistungsrechenzentrum Stuttgart

21 Example: B_Stream (blood flow simulation, tube-stenosis) 9310 rank 1 performs MPI_Sendrecv 9311 rank 2 performs MPI_Sendrecv 9312 rank 0 performs MPI_Barrier 9313 rank 1 performs MPI_Barrier 9314 rank 2 performs MPI_Barrier 9315 rank 1 performs MPI_Sendrecv 9316 rank 2 performs MPI_Sendrecv 9317 rank 0 performs MPI_Sendrecv 9318 rank 1 performs MPI_Sendrecv 9319 rank 0 performs MPI_Sendrecv 9320 rank 2 performs MPI_Sendrecv 9321 rank 0 performs MPI_Barrier 9322 rank 1 performs MPI_Barrier 9323 rank 2 performs MPI_Barrier 9324 rank 1 performs MPI_Comm_rank 9325 rank 1 performs MPI_Bcast 9326 rank 2 performs MPI_Comm_rank 9327 rank 2 performs MPI_Bcast 9328 rank 0 performs MPI_Sendrecv WARNING: all clients are pending! Höchstleistungsrechenzentrum Stuttgart
22 Example: B_Stream (blood flow simulation, tube-stenosis) deadlock: traceback on node 0 timestamp= 9304: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9307: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 1, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9309: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 1, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 2, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9312: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9317: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 1, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9319: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 1, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 2, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9321: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9328: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 1, recvtag = 1, comm = self-defined communicator, *status) Höchstleistungsrechenzentrum Stuttgart
23 Example: B_Stream (blood flow simulation, tube-stenosis) deadlock: traceback on node 1 timestamp= 9306: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 0, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 2, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9310: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9313: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9315: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 0, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 2, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9318: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9322: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9324: MPI_Comm_rank(comm = MPI_COMM_WORLD, *rank) timestamp= 9325: MPI_Bcast(*buffer, count = 3, datatype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) Höchstleistungsrechenzentrum Stuttgart
24 Example: B_Stream (blood flow simulation, tube-stenosis) deadlock: traceback on node 2 timestamp= 9308: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 1, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9311: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 0, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 1, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9314: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9316: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 1, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9320: MPI_Sendrecv(*sendbuf, sendcount = 7220, sendtype = MPI_DOUBLE, dest = 0, sendtag = 1, *recvbuf, recvcount = 7220, recvtype = MPI_DOUBLE, source = 1, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9323: MPI_Barrier(comm = MPI_COMM_WORLD) timestamp= 9326: MPI_Comm_rank(comm = MPI_COMM_WORLD, *rank) timestamp= 9327: MPI_Bcast(*buffer, count = 3, datatype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) Höchstleistungsrechenzentrum Stuttgart
25 Example: B_Stream (blood flow simulation, bifurcation) Without MARMOT: mpirun -np 3 B_Stream 500. bifurcation /usr/local/mpich /ch_shmem/bin/mpirun: line 1: 2753 Speicherzugriffsfehler /home/rusbetti/b_streamorg/bin/b_stream "500." "bifurcation" With MARMOT: mpirun -np 4 B_Stream_marmot 500. bifurcation Problem found at collective call MPI_Gather Höchstleistungsrechenzentrum Stuttgart
26 Example: B_Stream (blood flow simulation, bifurcation) 9319 rank 2 performs MPI_Sendrecv 9320 rank 1 performs MPI_Sendrecv 9321 rank 1 performs MPI_Barrier 9322 rank 2 performs MPI_Barrier 9323 rank 0 performs MPI_Barrier 9324 rank 0 performs MPI_Comm_rank 9325 rank 1 performs MPI_Comm_rank 9326 rank 2 performs MPI_Comm_rank 9327 rank 0 performs MPI_Bcast 9328 rank 1 performs MPI_Bcast 9329 rank 2 performs MPI_Bcast 9330 rank 0 performs MPI_Bcast 9331 rank 1 performs MPI_Bcast 9332 rank 2 performs MPI_Bcast 9333 rank 0 performs MPI_Gather 9334 rank 1 performs MPI_Gather 9335 rank 2 performs MPI_Gather /usr/local/mpich /ch_shmem/bin/mpirun: line 1: Speicherzugriffsfehler /home/rusbetti/b_stream/bin/b_stream_marmot "500." "bifurcation" Höchstleistungsrechenzentrum Stuttgart
27 Example: B_Stream (blood flow simulation, bifurcation) 9336 rank 1 performs MPI_Sendrecv 9337 rank 2 performs MPI_Sendrecv 9338 rank 1 performs MPI_Sendrecv WARNING: all clients are pending! Höchstleistungsrechenzentrum Stuttgart
28 Example: B_Stream (blood flow simulation, bifurcation) Last calls on node 0: timestamp= 9327: MPI_Bcast(*buffer, count = 3, datatype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) timestamp= 9330: MPI_Bcast(*buffer, count = 3, datatype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) timestamp= 9333: MPI_Gather(*sendbuf, sendcount = , sendtype = MPI_DOUBLE, *recvbuf, recvcount = , recvtype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) Last calls on node 1: timestamp= 9334: MPI_Gather(*sendbuf, sendcount = , sendtype = MPI_DOUBLE, *recvbuf, recvcount = , recvtype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) timestamp= 9336: MPI_Sendrecv(*sendbuf, sendcount = 13455, sendtype = MPI_DOUBLE, dest = 0, sendtag = 1, *recvbuf, recvcount = 13455, recvtype = MPI_DOUBLE, source = 2, recvtag = 1, comm = self-defined communicator, *status) timestamp= 9338: MPI_Sendrecv(*sendbuf, sendcount = 13455, sendtype = MPI_DOUBLE, dest = 2, sendtag = 1, *recvbuf, recvcount = 13455, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) Last calls on node 2: timestamp= 9332: MPI_Bcast(*buffer, count = 3, datatype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) timestamp= 9335: MPI_Gather(*sendbuf, sendcount = , sendtype = MPI_DOUBLE, *recvbuf, recvcount = , recvtype = MPI_DOUBLE, root = 0, comm = MPI_COMM_WORLD) timestamp= 9337: MPI_Sendrecv(*sendbuf, sendcount = 13455, sendtype = MPI_DOUBLE, dest = 1, sendtag = 1, *recvbuf, recvcount = 13455, recvtype = MPI_DOUBLE, source = 0, recvtag = 1, comm = self-defined communicator, *status) Höchstleistungsrechenzentrum Stuttgart
29 Example: B_Stream (B_Stream.cpp) #ifdef PARALLEl MPI_Barrier (MPI_COMM_WORLD); MPI_Reduce (&nr_fluids, &tot_nr_fluids, 1, MPI_DOUBLE, MPI_SUM, 0,MPI_COMM_WORLD); #else #endif //Calculation of porosity if (ge.me == 0) { Porosity = ((double) tot_nr_fluids) / (ge.global_dim[0] * ge.global_dim[1] * ge.global_dim[2]); } Porosity = ((double) tot_nr_fluids) / (ge.global_dim[0] * ge.global_dim[1] * ge.global_dim[2]); Höchstleistungsrechenzentrum Stuttgart
30 Performance with Real Applications Höchstleistungsrechenzentrum Stuttgart
31 CrossGrid Application: WP 1.4: Air pollution modelling Air pollution modeling with STEM-II model Transport equation solved with Petrov- Crank-Nikolson-Galerkin method Chemistry and Mass transfer are integrated using semi-implicit Euler and pseudoanalytical methods lines of Fortran code 12 different MPI calls: MPI_Init, MPI_Comm_size, MPI_Comm_rank, MPI_Type_extent, MPI_Type_struct, MPI_Type_commit, MPI_Type_hvector, MPI_Bcast, MPI_Scatterv, MPI_Barrier, MPI_Gatherv, MPI_Finalize Höchstleistungsrechenzentrum Stuttgart
32 STEM application on an IA32 cluster with Myrinet 80 Time [s] Processors native MPI MARMOT Höchstleistungsrechenzentrum Stuttgart
33 CrossGrid Application: WP 1.3: High Energy Physics level 1 - special hardware 40 MHz (40 TB/sec) level 2 - embedded processors level 3 - PCs 75 KHz (75 GB/sec) 5 KHz (5 GB/sec) 100 Hz data recording & offline analysis (100 MB/sec) Filtering of real-time data with neural networks (ANN application) lines of C code 11 different MPI calls: MPI_Init, MPI_Comm_size, MPI_Comm_rank, MPI_Get_processor_name, MPI_Barrier, MPI_Gather, MPI_Recv, MPI_Send, MPI_Bcast, MPI_Reduce, MPI_Finalize Höchstleistungsrechenzentrum Stuttgart
34 HEP application on an IA32 cluster with Myrinet Time [s] native MPI MARMOT Processors Höchstleistungsrechenzentrum Stuttgart
35 CrossGrid Application: WP 1.1: Medical Application Calculation of blood flow with Lattice- Boltzmann method Stripped down application with 6500 lines of C code 14 different MPI calls: MPI_Init, MPI_Comm_rank, MPI_Comm_size, MPI_Pack, MPI_Bcast, MPI_Unpack, MPI_Cart_create, MPI_Cart_shift, MPI_Send, MPI_Recv, MPI_Barrier, MPI_Reduce, MPI_Sendrecv, MPI_Finalize Höchstleistungsrechenzentrum Stuttgart
36 Medical application on an IA32 cluster with Myrinet 0,6 Time per Iteration [s] 0,5 0,4 0,3 0,2 0, Processors native MPI MARMOT Höchstleistungsrechenzentrum Stuttgart
37 Message statistics with native MPI Höchstleistungsrechenzentrum Stuttgart
38 Message statistics with MARMOT Höchstleistungsrechenzentrum Stuttgart
39 Medical application on an IA32 cluster with Myrinet without barrier Time per Iteration [s] 0,6 0,5 0,4 0,3 0,2 0, Processors native MPI MARMOT MARMOT without barrier Höchstleistungsrechenzentrum Stuttgart
40 Barrier with native MPI Höchstleistungsrechenzentrum Stuttgart
41 Barrier with MARMOT Höchstleistungsrechenzentrum Stuttgart
42 CrossGrid Application: WP 1.2: Flood monitoring forecasting simulation Flood simulation Fortran applications tested with MARMOT: Aladin, DaveF, MM5 9 different MPI Calls: MPI_INIT, MPI_COMM_SIZE, MPI_COMM_RANK, MPI_GET_PROCESSOR_NAME, MPI_BCAST, MPI_SEND, MPI_RECV, MPI_BARRIER, MPI_FINALIZE Höchstleistungsrechenzentrum Stuttgart
43 Conclusion Full MPI 1.2 implemented C and Fortran binding is supported Used for several Fortran and C benchmarks (NASPB) and applications (Crossgrid Project and others) Tests on different platforms, using different compilers and MPI implementations, e.g. IA32/IA64 clusters (Intel, g++ compiler) with mpich IBM Regatta NEC SX5, SX6, Hitachi SR8000, Cray T3e, Höchstleistungsrechenzentrum Stuttgart
44 Impact and Exploitation MARMOT is mentioned in the U.S. DoD High Performance Computing Modernization Program (HPCMP) Programming Environment and Training (PET) project as one of two freely available tools (MPI-Check and MARMOT) for the development of portable MPI programs. Contact with tool developers of the other 2 known verification tools like MARMOT (MPI-Check, umpire) Contact with users outside CrossGrid MARMOT has been presented at various conferences and publications Höchstleistungsrechenzentrum Stuttgart
45 Future Work Scalability and general performance improvements Better user interface to present problems and warnings Extended documentation Extended functionality: more tests to verify collective calls (parts of) MPI-2 Hybrid programming Höchstleistungsrechenzentrum Stuttgart
46 Thanks for your attention Additional information and download: Höchstleistungsrechenzentrum Stuttgart
MARMOT- MPI Analysis and Checking Tool Demo with blood flow simulation. Bettina Krammer, Matthias Müller krammer@hlrs.de, mueller@hlrs.
 MARMOT- MPI Analysis and Checking Tool Demo with blood flow simulation Bettina Krammer, Matthias Müller krammer@hlrs.de, mueller@hlrs.de HLRS High Performance Computing Center Stuttgart Allmandring 30
MARMOT- MPI Analysis and Checking Tool Demo with blood flow simulation Bettina Krammer, Matthias Müller krammer@hlrs.de, mueller@hlrs.de HLRS High Performance Computing Center Stuttgart Allmandring 30
Session 2: MUST. Correctness Checking
 Center for Information Services and High Performance Computing (ZIH) Session 2: MUST Correctness Checking Dr. Matthias S. Müller (RWTH Aachen University) Tobias Hilbrich (Technische Universität Dresden)
Center for Information Services and High Performance Computing (ZIH) Session 2: MUST Correctness Checking Dr. Matthias S. Müller (RWTH Aachen University) Tobias Hilbrich (Technische Universität Dresden)
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015. Hermann Härtig
 LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015 Hermann Härtig ISSUES starting points independent Unix processes and block synchronous execution who does it load migration mechanism
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015 Hermann Härtig ISSUES starting points independent Unix processes and block synchronous execution who does it load migration mechanism
MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop
 MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop Joachim Protze and Felix Münchhalfen IT Center RWTH Aachen University February 2014 Content MPI Usage Errors Error Classes Avoiding
MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop Joachim Protze and Felix Münchhalfen IT Center RWTH Aachen University February 2014 Content MPI Usage Errors Error Classes Avoiding
Lightning Introduction to MPI Programming
 Lightning Introduction to MPI Programming May, 2015 What is MPI? Message Passing Interface A standard, not a product First published 1994, MPI-2 published 1997 De facto standard for distributed-memory
Lightning Introduction to MPI Programming May, 2015 What is MPI? Message Passing Interface A standard, not a product First published 1994, MPI-2 published 1997 De facto standard for distributed-memory
Lecture 6: Introduction to MPI programming. Lecture 6: Introduction to MPI programming p. 1
 Lecture 6: Introduction to MPI programming Lecture 6: Introduction to MPI programming p. 1 MPI (message passing interface) MPI is a library standard for programming distributed memory MPI implementation(s)
Lecture 6: Introduction to MPI programming Lecture 6: Introduction to MPI programming p. 1 MPI (message passing interface) MPI is a library standard for programming distributed memory MPI implementation(s)
HP-MPI User s Guide. 11th Edition. Manufacturing Part Number : B6060-96024 September 2007
 HP-MPI User s Guide 11th Edition Manufacturing Part Number : B6060-96024 September 2007 Copyright 1979-2007 Hewlett-Packard Development Company, L.P. Table 1 Revision history Edition MPN Description Eleventh
HP-MPI User s Guide 11th Edition Manufacturing Part Number : B6060-96024 September 2007 Copyright 1979-2007 Hewlett-Packard Development Company, L.P. Table 1 Revision history Edition MPN Description Eleventh
High performance computing systems. Lab 1
 High performance computing systems Lab 1 Dept. of Computer Architecture Faculty of ETI Gdansk University of Technology Paweł Czarnul For this exercise, study basic MPI functions such as: 1. for MPI management:
High performance computing systems Lab 1 Dept. of Computer Architecture Faculty of ETI Gdansk University of Technology Paweł Czarnul For this exercise, study basic MPI functions such as: 1. for MPI management:
MPI-Checker Static Analysis for MPI
 MPI-Checker Static Analysis for MPI Alexander Droste, Michael Kuhn, Thomas Ludwig November 15, 2015 Motivation 2 / 39 Why is runtime analysis in HPC challenging? Large amount of resources are used State
MPI-Checker Static Analysis for MPI Alexander Droste, Michael Kuhn, Thomas Ludwig November 15, 2015 Motivation 2 / 39 Why is runtime analysis in HPC challenging? Large amount of resources are used State
To connect to the cluster, simply use a SSH or SFTP client to connect to:
 RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
Message Passing with MPI
 Message Passing with MPI Hristo Iliev (Христо Илиев) PPCES 2012, 2013 Christian Iwainsky PPCES 2011 Rechen- und Kommunikationszentrum (RZ) Agenda Motivation MPI Part 1 Concepts Point-to-point communication
Message Passing with MPI Hristo Iliev (Христо Илиев) PPCES 2012, 2013 Christian Iwainsky PPCES 2011 Rechen- und Kommunikationszentrum (RZ) Agenda Motivation MPI Part 1 Concepts Point-to-point communication
RA MPI Compilers Debuggers Profiling. March 25, 2009
 RA MPI Compilers Debuggers Profiling March 25, 2009 Examples and Slides To download examples on RA 1. mkdir class 2. cd class 3. wget http://geco.mines.edu/workshop/class2/examples/examples.tgz 4. tar
RA MPI Compilers Debuggers Profiling March 25, 2009 Examples and Slides To download examples on RA 1. mkdir class 2. cd class 3. wget http://geco.mines.edu/workshop/class2/examples/examples.tgz 4. tar
Linux tools for debugging and profiling MPI codes
 Competence in High Performance Computing Linux tools for debugging and profiling MPI codes Werner Krotz-Vogel, Pallas GmbH MRCCS September 02000 Pallas GmbH Hermülheimer Straße 10 D-50321
Competence in High Performance Computing Linux tools for debugging and profiling MPI codes Werner Krotz-Vogel, Pallas GmbH MRCCS September 02000 Pallas GmbH Hermülheimer Straße 10 D-50321
Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005
 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005... 1
Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005... 1
HPCC - Hrothgar Getting Started User Guide MPI Programming
 HPCC - Hrothgar Getting Started User Guide MPI Programming High Performance Computing Center Texas Tech University HPCC - Hrothgar 2 Table of Contents 1. Introduction... 3 2. Setting up the environment...
HPCC - Hrothgar Getting Started User Guide MPI Programming High Performance Computing Center Texas Tech University HPCC - Hrothgar 2 Table of Contents 1. Introduction... 3 2. Setting up the environment...
Introduction to Hybrid Programming
 Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Parallelization: Binary Tree Traversal
 By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
Introduction to grid technologies, parallel and cloud computing. Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber
 Introduction to grid technologies, parallel and cloud computing Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber OUTLINES Grid Computing Parallel programming technologies (MPI- Open MP-Cuda )
Introduction to grid technologies, parallel and cloud computing Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber OUTLINES Grid Computing Parallel programming technologies (MPI- Open MP-Cuda )
Message Passing Interface (MPI)
") Message Passing Interface (MPI) Jalel Chergui Isabelle Dupays Denis Girou Pierre-François Lavallée Dimitri Lecas Philippe Wautelet MPI Plan I 1 Introduction... 7 1.1 Availability and updating... 8 1.2
Message Passing Interface (MPI) Jalel Chergui Isabelle Dupays Denis Girou Pierre-François Lavallée Dimitri Lecas Philippe Wautelet MPI Plan I 1 Introduction... 7 1.1 Availability and updating... 8 1.2
Parallel Programming with MPI on the Odyssey Cluster
 Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
Debugging with TotalView
 Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
Tim Cramer 17.03.2015 IT Center der RWTH Aachen University Why to use a Debugger? If your program goes haywire, you may... ( wand (... buy a magic... read the source code again and again and...... enrich
LS-DYNA Scalability on Cray Supercomputers. Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp.
 LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
Application Performance Tools on Discover
 Application Performance Tools on Discover Tyler Simon 21 May 2009 Overview 1. ftnchek - static Fortran code analysis 2. Cachegrind - source annotation for cache use 3. Ompp - OpenMP profiling 4. IPM MPI
Application Performance Tools on Discover Tyler Simon 21 May 2009 Overview 1. ftnchek - static Fortran code analysis 2. Cachegrind - source annotation for cache use 3. Ompp - OpenMP profiling 4. IPM MPI
Performance and scalability of MPI on PC clusters
 CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 24; 16:79 17 (DOI: 1.12/cpe.749) Performance Performance and scalability of MPI on PC clusters Glenn R. Luecke,,
CONCURRENCY AND COMPUTATION: PRACTICE AND EXPERIENCE Concurrency Computat.: Pract. Exper. 24; 16:79 17 (DOI: 1.12/cpe.749) Performance Performance and scalability of MPI on PC clusters Glenn R. Luecke,,
Introduction to MPI Programming!
 Introduction to MPI Programming! Rocks-A-Palooza II! Lab Session! 2006 UC Regents! 1! Modes of Parallel Computing! SIMD - Single Instruction Multiple Data!!processors are lock-stepped : each processor
Introduction to MPI Programming! Rocks-A-Palooza II! Lab Session! 2006 UC Regents! 1! Modes of Parallel Computing! SIMD - Single Instruction Multiple Data!!processors are lock-stepped : each processor
How To Visualize Performance Data In A Computer Program
 Performance Visualization Tools 1 Performance Visualization Tools Lecture Outline : Following Topics will be discussed Characteristics of Performance Visualization technique Commercial and Public Domain
Performance Visualization Tools 1 Performance Visualization Tools Lecture Outline : Following Topics will be discussed Characteristics of Performance Visualization technique Commercial and Public Domain
University of Notre Dame
 University of Notre Dame MPI Tutorial Part 1 Introduction Laboratory for Scientific Computing Fall 1998 http://www.lam-mpi.org/tutorials/nd/ lam@lam-mpi.org Fall 1998 1 Tutorial Instructors M.D. McNally
University of Notre Dame MPI Tutorial Part 1 Introduction Laboratory for Scientific Computing Fall 1998 http://www.lam-mpi.org/tutorials/nd/ lam@lam-mpi.org Fall 1998 1 Tutorial Instructors M.D. McNally
Message Passing Interface (MPI)
") Message Passing Interface (MPI) Jalel Chergui Isabelle Dupays Denis Girou Pierre-François Lavallée Dimitri Lecas Philippe Wautelet MPI Plan I 1 Introduction... 7 1.1 Availability and updating... 7 1.2
Message Passing Interface (MPI) Jalel Chergui Isabelle Dupays Denis Girou Pierre-François Lavallée Dimitri Lecas Philippe Wautelet MPI Plan I 1 Introduction... 7 1.1 Availability and updating... 7 1.2
Load Balancing. computing a file with grayscales. granularity considerations static work load assignment with MPI
 Load Balancing 1 the Mandelbrot set computing a file with grayscales 2 Static Work Load Assignment granularity considerations static work load assignment with MPI 3 Dynamic Work Load Balancing scheduling
Load Balancing 1 the Mandelbrot set computing a file with grayscales 2 Static Work Load Assignment granularity considerations static work load assignment with MPI 3 Dynamic Work Load Balancing scheduling
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed Systems 15-319, spring 2010 11 th Lecture, Feb 16 th Majd F. Sakr Lecture Motivation Understand Distributed Systems Concepts Understand the concepts / ideas
Introduction to Cloud Computing Distributed Systems 15-319, spring 2010 11 th Lecture, Feb 16 th Majd F. Sakr Lecture Motivation Understand Distributed Systems Concepts Understand the concepts / ideas
MPICH FOR SCI-CONNECTED CLUSTERS
 Autumn Meeting 99 of AK Scientific Computing MPICH FOR SCI-CONNECTED CLUSTERS Joachim Worringen AGENDA Introduction, Related Work & Motivation Implementation Performance Work in Progress Summary MESSAGE-PASSING
Autumn Meeting 99 of AK Scientific Computing MPICH FOR SCI-CONNECTED CLUSTERS Joachim Worringen AGENDA Introduction, Related Work & Motivation Implementation Performance Work in Progress Summary MESSAGE-PASSING
High-Performance Computing: Architecture and APIs
 High-Performance Computing: Architecture and APIs Douglas Fuller ASU Fulton High Performance Computing Why HPC? Capacity computing Do similar jobs, but lots of them. Capability computing Run programs we
High-Performance Computing: Architecture and APIs Douglas Fuller ASU Fulton High Performance Computing Why HPC? Capacity computing Do similar jobs, but lots of them. Capability computing Run programs we
Parallel Computing. Parallel shared memory computing with OpenMP
 Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Dynamic Software Testing of MPI Applications with Umpire
 Dynamic Software Testing of MPI Applications with Umpire Jeffrey S. Vetter Bronis R. de Supinski Center for Applied Scientific Computing Lawrence Livermore National Laboratory Livermore, California, USA
Dynamic Software Testing of MPI Applications with Umpire Jeffrey S. Vetter Bronis R. de Supinski Center for Applied Scientific Computing Lawrence Livermore National Laboratory Livermore, California, USA
- An Essential Building Block for Stable and Reliable Compute Clusters
 Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Ferdinand Geier ParTec Cluster Competence Center GmbH, V. 1.4, March 2005 Cluster Middleware - An Essential Building Block for Stable and Reliable Compute Clusters Contents: Compute Clusters a Real Alternative
Outline. Project. Bestandteile der Veranstaltung. Termine. Optimierung von Multi-Core Systemen. Prof. Dr. Sabine Glesner
 Outline Project Optimierung von Multi-Core Systemen Lecture 1 Prof. Dr. Sabine Glesner SS 2012 Technische Universität Berlin Termine Bestandteile Anmeldung Prüfungsmodalitäten Bewertung Prof. Glesner Optimierung
Outline Project Optimierung von Multi-Core Systemen Lecture 1 Prof. Dr. Sabine Glesner SS 2012 Technische Universität Berlin Termine Bestandteile Anmeldung Prüfungsmodalitäten Bewertung Prof. Glesner Optimierung
Advanced MPI. Hybrid programming, profiling and debugging of MPI applications. Hristo Iliev RZ. Rechen- und Kommunikationszentrum (RZ)
") Advanced MPI Hybrid programming, profiling and debugging of MPI applications Hristo Iliev RZ Rechen- und Kommunikationszentrum (RZ) Agenda Halos (ghost cells) Hybrid programming Profiling of MPI applications
Advanced MPI Hybrid programming, profiling and debugging of MPI applications Hristo Iliev RZ Rechen- und Kommunikationszentrum (RZ) Agenda Halos (ghost cells) Hybrid programming Profiling of MPI applications
OpenMP & MPI CISC 879. Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware
 OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
Agenda. Using HPC Wales 2
 Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
MPI / ClusterTools Update and Plans
 HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
HPC Technical Training Seminar July 7, 2008 October 26, 2007 2 nd HLRS Parallel Tools Workshop Sun HPC ClusterTools 7+: A Binary Distribution of Open MPI MPI / ClusterTools Update and Plans Len Wisniewski
PERFORMANCE ANALYSIS OF MESSAGE PASSING INTERFACE COLLECTIVE COMMUNICATION ON INTEL XEON QUAD-CORE GIGABIT ETHERNET AND INFINIBAND CLUSTERS
 Journal of Computer Science, 9 (4): 455-462, 2013 ISSN 1549-3636 2013 doi:10.3844/jcssp.2013.455.462 Published Online 9 (4) 2013 (http://www.thescipub.com/jcs.toc) PERFORMANCE ANALYSIS OF MESSAGE PASSING
Journal of Computer Science, 9 (4): 455-462, 2013 ISSN 1549-3636 2013 doi:10.3844/jcssp.2013.455.462 Published Online 9 (4) 2013 (http://www.thescipub.com/jcs.toc) PERFORMANCE ANALYSIS OF MESSAGE PASSING
Load Balancing MPI Algorithm for High Throughput Applications
 Load Balancing MPI Algorithm for High Throughput Applications Igor Grudenić, Stjepan Groš, Nikola Bogunović Faculty of Electrical Engineering and, University of Zagreb Unska 3, 10000 Zagreb, Croatia {igor.grudenic,
Load Balancing MPI Algorithm for High Throughput Applications Igor Grudenić, Stjepan Groš, Nikola Bogunović Faculty of Electrical Engineering and, University of Zagreb Unska 3, 10000 Zagreb, Croatia {igor.grudenic,
Memory Debugging with TotalView on AIX and Linux/Power
 S cico m P Austin Aug 2004 Memory Debugging with TotalView on AIX and Linux/Power Chris Gottbrath Memory Debugging in AIX and Linux-Power Clusters Intro: Define the problem and terms What are Memory bugs?
S cico m P Austin Aug 2004 Memory Debugging with TotalView on AIX and Linux/Power Chris Gottbrath Memory Debugging in AIX and Linux-Power Clusters Intro: Define the problem and terms What are Memory bugs?
Improved LS-DYNA Performance on Sun Servers
 8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
8 th International LS-DYNA Users Conference Computing / Code Tech (2) Improved LS-DYNA Performance on Sun Servers Youn-Seo Roh, Ph.D. And Henry H. Fong Sun Microsystems, Inc. Abstract Current Sun platforms
Basic Concepts in Parallelization
 1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
Supercomputing 2004 - Status und Trends (Conference Report) Peter Wegner
 Peter Wegner") (Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
(Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
Performance Monitoring of Parallel Scientific Applications
 Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
MPI-based Approaches for Java
 Java for High Performance Computing MPI-based Approaches for Java http://www.hpjava.org/courses/arl Instructor: Bryan Carpenter Pervasive Technology Labs Indiana University MPI: The Message Passing Interface
Java for High Performance Computing MPI-based Approaches for Java http://www.hpjava.org/courses/arl Instructor: Bryan Carpenter Pervasive Technology Labs Indiana University MPI: The Message Passing Interface
Kommunikation in HPC-Clustern
 Kommunikation in HPC-Clustern Communication/Computation Overlap in MPI W. Rehm and T. Höfler Department of Computer Science TU Chemnitz http://www.tu-chemnitz.de/informatik/ra 11.11.2005 Outline 1 2 Optimize
Kommunikation in HPC-Clustern Communication/Computation Overlap in MPI W. Rehm and T. Höfler Department of Computer Science TU Chemnitz http://www.tu-chemnitz.de/informatik/ra 11.11.2005 Outline 1 2 Optimize
McMPI. Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk
 McMPI Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk Outline Yet another MPI library? Managed-code, C#, Windows McMPI, design and implementation details Object-orientation,
McMPI Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk Outline Yet another MPI library? Managed-code, C#, Windows McMPI, design and implementation details Object-orientation,
MOSIX: High performance Linux farm
 MOSIX: High performance Linux farm Paolo Mastroserio [mastroserio@na.infn.it] Francesco Maria Taurino [taurino@na.infn.it] Gennaro Tortone [tortone@na.infn.it] Napoli Index overview on Linux farm farm
MOSIX: High performance Linux farm Paolo Mastroserio [mastroserio@na.infn.it] Francesco Maria Taurino [taurino@na.infn.it] Gennaro Tortone [tortone@na.infn.it] Napoli Index overview on Linux farm farm
MPI Implementation Analysis - A Practical Approach to Network Marketing
 Optimizing MPI Collective Communication by Orthogonal Structures Matthias Kühnemann Fakultät für Informatik Technische Universität Chemnitz 917 Chemnitz, Germany kumat@informatik.tu chemnitz.de Gudula
Optimizing MPI Collective Communication by Orthogonal Structures Matthias Kühnemann Fakultät für Informatik Technische Universität Chemnitz 917 Chemnitz, Germany kumat@informatik.tu chemnitz.de Gudula
Access to the Federal High-Performance Computing-Centers
 Access to the Federal High-Performance Computing-Centers rabenseifner@hlrs.de University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 TOP 500 Nov. List German Sites,
Access to the Federal High-Performance Computing-Centers rabenseifner@hlrs.de University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Slide 1 TOP 500 Nov. List German Sites,
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters
 The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München September 2010 Outline Motivation Periscope architecture Periscope performance analysis
Evaluation of Java Message Passing in High Performance Data Analytics
 Evaluation of Java Message Passing in High Performance Data Analytics Saliya Ekanayake, Geoffrey Fox School of Informatics and Computing Indiana University Bloomington, Indiana, USA {sekanaya, gcf}@indiana.edu
Evaluation of Java Message Passing in High Performance Data Analytics Saliya Ekanayake, Geoffrey Fox School of Informatics and Computing Indiana University Bloomington, Indiana, USA {sekanaya, gcf}@indiana.edu
BLM 413E - Parallel Programming Lecture 3
 BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
Parallel I/O on Mira Venkat Vishwanath and Kevin Harms
 Parallel I/O on Mira Venkat Vishwanath and Kevin Harms Argonne Na*onal Laboratory venkat@anl.gov ALCF-2 I/O Infrastructure Mira BG/Q Compute Resource Tukey Analysis Cluster 48K Nodes 768K Cores 10 PFlops
Parallel I/O on Mira Venkat Vishwanath and Kevin Harms Argonne Na*onal Laboratory venkat@anl.gov ALCF-2 I/O Infrastructure Mira BG/Q Compute Resource Tukey Analysis Cluster 48K Nodes 768K Cores 10 PFlops
Parallelizing Heavyweight Debugging Tools with MPIecho
 Parallelizing Heavyweight Debugging Tools with MPIecho Barry Rountree rountree@llnl.gov Martin Schulz schulzm@llnl.gov Guy Cobb University of Colorado guy.cobb@gmail.com Bronis R. de Supinski bronis@llnl.gov
Parallelizing Heavyweight Debugging Tools with MPIecho Barry Rountree rountree@llnl.gov Martin Schulz schulzm@llnl.gov Guy Cobb University of Colorado guy.cobb@gmail.com Bronis R. de Supinski bronis@llnl.gov
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Performance Tool Support for MPI-2 on Linux 1
 Performance Tool Support for MPI-2 on Linux 1 Kathryn Mohror and Karen L. Karavanic Portland State University {kathryn, karavan}@cs.pdx.edu Abstract Programmers of message-passing codes for clusters of
Performance Tool Support for MPI-2 on Linux 1 Kathryn Mohror and Karen L. Karavanic Portland State University {kathryn, karavan}@cs.pdx.edu Abstract Programmers of message-passing codes for clusters of
A Case Study - Scaling Legacy Code on Next Generation Platforms
 Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 00 (2015) 000 000 www.elsevier.com/locate/procedia 24th International Meshing Roundtable (IMR24) A Case Study - Scaling Legacy
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Debugging and Profiling Lab. Carlos Rosales, Kent Milfeld and Yaakoub Y. El Kharma carlos@tacc.utexas.edu
 Debugging and Profiling Lab Carlos Rosales, Kent Milfeld and Yaakoub Y. El Kharma carlos@tacc.utexas.edu Setup Login to Ranger: - ssh -X username@ranger.tacc.utexas.edu Make sure you can export graphics
Debugging and Profiling Lab Carlos Rosales, Kent Milfeld and Yaakoub Y. El Kharma carlos@tacc.utexas.edu Setup Login to Ranger: - ssh -X username@ranger.tacc.utexas.edu Make sure you can export graphics
Virtual Machines. www.viplavkambli.com
 1 Virtual Machines A virtual machine (VM) is a "completely isolated guest operating system installation within a normal host operating system". Modern virtual machines are implemented with either software
1 Virtual Machines A virtual machine (VM) is a "completely isolated guest operating system installation within a normal host operating system". Modern virtual machines are implemented with either software
Streamline Computing Linux Cluster User Training. ( Nottingham University)
") 1 Streamline Computing Linux Cluster User Training ( Nottingham University) 3 User Training Agenda System Overview System Access Description of Cluster Environment Code Development Job Schedulers Running
1 Streamline Computing Linux Cluster User Training ( Nottingham University) 3 User Training Agenda System Overview System Access Description of Cluster Environment Code Development Job Schedulers Running
Introduction. Reading. Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF. CMSC 818Z - S99 (lect 5)
") Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
Introduction Reading Today MPI & OpenMP papers Tuesday Commutativity Analysis & HPF 1 Programming Assignment Notes Assume that memory is limited don t replicate the board on all nodes Need to provide load
Developing Parallel Applications with the Eclipse Parallel Tools Platform
 Developing Parallel Applications with the Eclipse Parallel Tools Platform Greg Watson IBM STG grw@us.ibm.com Parallel Tools Platform Enabling Parallel Application Development Best practice tools for experienced
Developing Parallel Applications with the Eclipse Parallel Tools Platform Greg Watson IBM STG grw@us.ibm.com Parallel Tools Platform Enabling Parallel Application Development Best practice tools for experienced
Allinea Performance Reports User Guide. Version 6.0.6
 Allinea Performance Reports User Guide Version 6.0.6 Contents Contents 1 1 Introduction 4 1.1 Online Resources...................................... 4 2 Installation 5 2.1 Linux/Unix Installation...................................
Allinea Performance Reports User Guide Version 6.0.6 Contents Contents 1 1 Introduction 4 1.1 Online Resources...................................... 4 2 Installation 5 2.1 Linux/Unix Installation...................................
HPC Applications Scalability. Gilad@hpcadvisorycouncil.com
 HPC Applications Scalability Gilad@hpcadvisorycouncil.com Applications Best Practices LAMMPS - Large-scale Atomic/Molecular Massively Parallel Simulator D. E. Shaw Research Desmond NWChem MPQC - Massively
HPC Applications Scalability Gilad@hpcadvisorycouncil.com Applications Best Practices LAMMPS - Large-scale Atomic/Molecular Massively Parallel Simulator D. E. Shaw Research Desmond NWChem MPQC - Massively
The CNMS Computer Cluster
 The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.
 Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.") Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
System Software for High Performance Computing. Joe Izraelevitz
 System Software for High Performance Computing Joe Izraelevitz Agenda Overview of Supercomputers Blue Gene/Q System LoadLeveler Job Scheduler General Parallel File System HPC at UR What is a Supercomputer?
System Software for High Performance Computing Joe Izraelevitz Agenda Overview of Supercomputers Blue Gene/Q System LoadLeveler Job Scheduler General Parallel File System HPC at UR What is a Supercomputer?
Parallel and Distributed Computing Programming Assignment 1
 Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Libmonitor: A Tool for First-Party Monitoring
 Libmonitor: A Tool for First-Party Monitoring Mark W. Krentel Dept. of Computer Science Rice University 6100 Main St., Houston, TX 77005 krentel@rice.edu ABSTRACT Libmonitor is a library that provides
Libmonitor: A Tool for First-Party Monitoring Mark W. Krentel Dept. of Computer Science Rice University 6100 Main St., Houston, TX 77005 krentel@rice.edu ABSTRACT Libmonitor is a library that provides
Big Data Analytics. Tools and Techniques
 Big Data Analytics Basic concepts of analyzing very large amounts of data Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Big Data Analytics Basic concepts of analyzing very large amounts of data Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Distributed communication-aware load balancing with TreeMatch in Charm++
 Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
Distributed communication-aware load balancing with TreeMatch in Charm++ The 9th Scheduling for Large Scale Systems Workshop, Lyon, France Emmanuel Jeannot Guillaume Mercier Francois Tessier In collaboration
IBM LoadLeveler for Linux delivers job scheduling for IBM pseries and IBM xseries platforms running Linux
 Software Announcement May 11, 2004 IBM LoadLeveler for Linux delivers job scheduling for IBM pseries and IBM xseries platforms running Linux Overview LoadLeveler for Linux is a versatile workload management
Software Announcement May 11, 2004 IBM LoadLeveler for Linux delivers job scheduling for IBM pseries and IBM xseries platforms running Linux Overview LoadLeveler for Linux is a versatile workload management
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises
 Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
Parallel Programming for Multi-Core, Distributed Systems, and GPUs Exercises Pierre-Yves Taunay Research Computing and Cyberinfrastructure 224A Computer Building The Pennsylvania State University University
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
11 th International LS-DYNA Users Conference Session # LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton 3, Onur Celebioglu
CHAPTER FIVE RESULT ANALYSIS
 CHAPTER FIVE RESULT ANALYSIS 5.1 Chapter Introduction 5.2 Discussion of Results 5.3 Performance Comparisons 5.4 Chapter Summary 61 5.1 Chapter Introduction This chapter outlines the results obtained from
CHAPTER FIVE RESULT ANALYSIS 5.1 Chapter Introduction 5.2 Discussion of Results 5.3 Performance Comparisons 5.4 Chapter Summary 61 5.1 Chapter Introduction This chapter outlines the results obtained from
Multi-core CPUs, Clusters, and Grid Computing: a Tutorial
 Multi-core CPUs, Clusters, and Grid Computing: a Tutorial Michael Creel Department of Economics and Economic History Edifici B, Universitat Autònoma de Barcelona 08193 Bellaterra (Barcelona) Spain michael.creel@uab.es
Multi-core CPUs, Clusters, and Grid Computing: a Tutorial Michael Creel Department of Economics and Economic History Edifici B, Universitat Autònoma de Barcelona 08193 Bellaterra (Barcelona) Spain michael.creel@uab.es
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation
 The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory. The Nation s Premier Laboratory for Land Forces UNCLASSIFIED
 Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory 21 st Century Research Continuum Theory Theory embodied in computation Hypotheses tested through experiment SCIENTIFIC METHODS
Dr. Raju Namburu Computational Sciences Campaign U.S. Army Research Laboratory 21 st Century Research Continuum Theory Theory embodied in computation Hypotheses tested through experiment SCIENTIFIC METHODS
DB2 Connect for NT and the Microsoft Windows NT Load Balancing Service
 DB2 Connect for NT and the Microsoft Windows NT Load Balancing Service Achieving Scalability and High Availability Abstract DB2 Connect Enterprise Edition for Windows NT provides fast and robust connectivity
DB2 Connect for NT and the Microsoft Windows NT Load Balancing Service Achieving Scalability and High Availability Abstract DB2 Connect Enterprise Edition for Windows NT provides fast and robust connectivity
HPC Software Requirements to Support an HPC Cluster Supercomputer
 HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
HPC Software Requirements to Support an HPC Cluster Supercomputer Susan Kraus, Cray Cluster Solutions Software Product Manager Maria McLaughlin, Cray Cluster Solutions Product Marketing Cray Inc. WP-CCS-Software01-0417
Implementing MPI-IO Shared File Pointers without File System Support
 Implementing MPI-IO Shared File Pointers without File System Support Robert Latham, Robert Ross, Rajeev Thakur, Brian Toonen Mathematics and Computer Science Division Argonne National Laboratory Argonne,
Implementing MPI-IO Shared File Pointers without File System Support Robert Latham, Robert Ross, Rajeev Thakur, Brian Toonen Mathematics and Computer Science Division Argonne National Laboratory Argonne,
PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN
 1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction
1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction

Release Notes for Open Grid Scheduler/Grid Engine. Version: Grid Engine 2011.11
 Release Notes for Open Grid Scheduler/Grid Engine Version: Grid Engine 2011.11 New Features Berkeley DB Spooling Directory Can Be Located on NFS The Berkeley DB spooling framework has been enhanced such
Release Notes for Open Grid Scheduler/Grid Engine Version: Grid Engine 2011.11 New Features Berkeley DB Spooling Directory Can Be Located on NFS The Berkeley DB spooling framework has been enhanced such
End-user Tools for Application Performance Analysis Using Hardware Counters
 1 End-user Tools for Application Performance Analysis Using Hardware Counters K. London, J. Dongarra, S. Moore, P. Mucci, K. Seymour, T. Spencer Abstract One purpose of the end-user tools described in
1 End-user Tools for Application Performance Analysis Using Hardware Counters K. London, J. Dongarra, S. Moore, P. Mucci, K. Seymour, T. Spencer Abstract One purpose of the end-user tools described in
A Framework For Application Performance Understanding and Prediction
 A Framework For Application Performance Understanding and Prediction Laura Carrington Ph.D. Lab (Performance Modeling & Characterization) at the 1 About us An NSF lab see www.sdsc.edu/ The mission of the
A Framework For Application Performance Understanding and Prediction Laura Carrington Ph.D. Lab (Performance Modeling & Characterization) at the 1 About us An NSF lab see www.sdsc.edu/ The mission of the
High Performance Computing in Aachen
 High Performance Computing in Aachen Christian Iwainsky iwainsky@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Produktivitätstools unter Linux Sep 16, RWTH Aachen University
High Performance Computing in Aachen Christian Iwainsky iwainsky@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Produktivitätstools unter Linux Sep 16, RWTH Aachen University
Tools for Performance Debugging HPC Applications. David Skinner deskinner@lbl.gov
 Tools for Performance Debugging HPC Applications David Skinner deskinner@lbl.gov Tools for Performance Debugging Practice Where to find tools Specifics to NERSC and Hopper Principles Topics in performance
Tools for Performance Debugging HPC Applications David Skinner deskinner@lbl.gov Tools for Performance Debugging Practice Where to find tools Specifics to NERSC and Hopper Principles Topics in performance
PMI: A Scalable Parallel Process-Management Interface for Extreme-Scale Systems
 PMI: A Scalable Parallel Process-Management Interface for Extreme-Scale Systems Pavan Balaji 1, Darius Buntinas 1, David Goodell 1, William Gropp 2, Jayesh Krishna 1, Ewing Lusk 1, and Rajeev Thakur 1
PMI: A Scalable Parallel Process-Management Interface for Extreme-Scale Systems Pavan Balaji 1, Darius Buntinas 1, David Goodell 1, William Gropp 2, Jayesh Krishna 1, Ewing Lusk 1, and Rajeev Thakur 1
How To Write Portable Programs In C
 Writing Portable Programs COS 217 1 Goals of Today s Class Writing portable programs in C Sources of heterogeneity Data types, evaluation order, byte order, char set, Reading period and final exam Important
Writing Portable Programs COS 217 1 Goals of Today s Class Writing portable programs in C Sources of heterogeneity Data types, evaluation order, byte order, char set, Reading period and final exam Important
Shared Parallel File System
 Shared Parallel File System Fangbin Liu fliu@science.uva.nl System and Network Engineering University of Amsterdam Shared Parallel File System Introduction of the project The PVFS2 parallel file system
Shared Parallel File System Fangbin Liu fliu@science.uva.nl System and Network Engineering University of Amsterdam Shared Parallel File System Introduction of the project The PVFS2 parallel file system
The Asterope compute cluster
 The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
The Asterope compute cluster ÅA has a small cluster named asterope.abo.fi with 8 compute nodes Each node has 2 Intel Xeon X5650 processors (6-core) with a total of 24 GB RAM 2 NVIDIA Tesla M2050 GPGPU
Building a Parallel Computer from Cheap PCs: SMILE Cluster Experiences
 Building a Parallel Computer from Cheap PCs: SMILE Cluster Experiences Putchong Uthayopas, Thara Angskun, Jullawadee Maneesilp Parallel Research Group Computer and Network Systems Research Laboratory,
Building a Parallel Computer from Cheap PCs: SMILE Cluster Experiences Putchong Uthayopas, Thara Angskun, Jullawadee Maneesilp Parallel Research Group Computer and Network Systems Research Laboratory,
Parallel Debugging with DDT
 Parallel Debugging with DDT Nate Woody 3/10/2009 www.cac.cornell.edu 1 Debugging Debugging is a methodical process of finding and reducing the number of bugs, or defects, in a computer program or a piece
Parallel Debugging with DDT Nate Woody 3/10/2009 www.cac.cornell.edu 1 Debugging Debugging is a methodical process of finding and reducing the number of bugs, or defects, in a computer program or a piece