Data cleaning and Data preprocessing
|
|
|
- Alberta Barber
- 8 years ago
- Views:
Transcription
1 Data cleaning and Data preprocessing Nguyen Hung Son This presentation was prepared on the basis of the following public materials: 1. Jiawei Han and Micheline Kamber, Data mining, concept and techniques 2. Gregory Piatetsky-Shapiro, kdnuggest, preprocessing 1

2 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 2

3 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data noisy: containing errors or outliers inconsistent: containing discrepancies in codes or names No quality data, no quality mining results! Quality decisions must be based on quality data Data warehouse needs consistent integration of quality data preprocessing 3

4 Data Understanding: Relevance What data is available for the task? Is this data relevant? Is additional relevant data available? How much historical data is available? Who is the data expert? preprocessing 4

5 Data Understanding: Quantity Number of instances (records, objects) Rule of thumb: 5,000 or more desired if less, results are less reliable; use special methods (boosting, ) Number of attributes (fields) Rule of thumb: for each attribute, 10 or more instances If more fields, use feature reduction and selection Number of targets Rule of thumb: >100 for each class if very unbalanced, use stratified sampling preprocessing 5

6 Multi-Dimensional Measure of Data Quality A well-accepted multidimensional view: Accuracy Completeness Consistency Timeliness Believability Value added Interpretability Accessibility Broad categories: intrinsic, contextual, representational, and accessibility. preprocessing 6

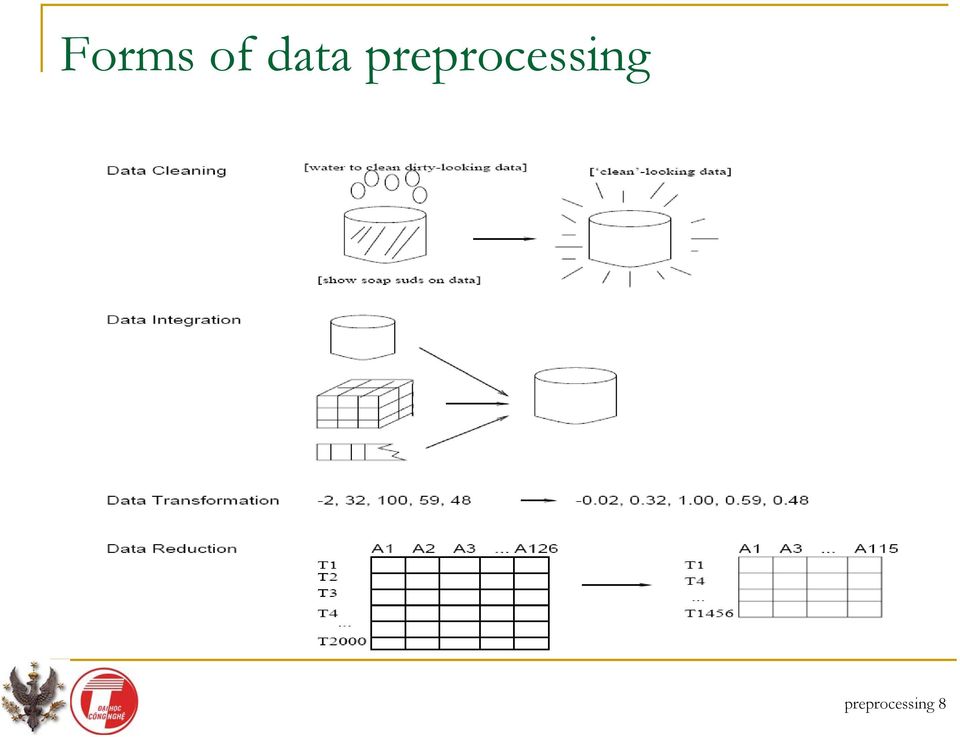
7 Major Tasks in Data Preprocessing Data cleaning Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies Data integration Integration of multiple databases, data cubes, or files Data transformation Normalization and aggregation Data reduction Obtains reduced representation in volume but produces the same or similar analytical results Data discretization Part of data reduction but with particular importance, especially for numerical data preprocessing 7

8 Forms of data preprocessing preprocessing 8
9 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 9

10 Data Cleaning Data cleaning tasks Data acquisition and metadata Fill in missing values Unified date format Converting nominal to numeric Identify outliers and smooth out noisy data Correct inconsistent data preprocessing 10

11 Data Cleaning: Acquisition Data can be in DBMS ODBC, JDBC protocols Data in a flat file Fixed-column format Delimited format: tab, comma,, other E.g. C4.5 and Weka arff use comma-delimited data Attention: Convert field delimiters inside strings Verify the number of fields before and after preprocessing 11

12 Data Cleaning: Example Original data (fixed column format) # Clean data ,199706, ,8014,5722,,# ,111,03,000101,0,04,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0300, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0300, preprocessing 12

13 Data Cleaning: Metadata Field types: binary, nominal (categorical), ordinal, numeric, For nominal fields: tables translating codes to full descriptions Field role: input : inputs for modeling target : output id/auxiliary : keep, but not use for modeling ignore : don t use for modeling weight : instance weight Field descriptions preprocessing 13

14 Data Cleaning: Reformatting Convert data to a standard format (e.g. arff or csv) Missing values Unified date format Binning of numeric data Fix errors and outliers Convert nominal fields whose values have order to numeric. Q: Why? A: to be able to use > and < comparisons on these fields) preprocessing 14
 Missing values Unified date format Binning of numeric data Fix")
15 Missing Data Data is not always available E.g., many tuples have no recorded value for several attributes, such as customer income in sales data Missing data may be due to equipment malfunction inconsistent with other recorded data and thus deleted data not entered due to misunderstanding certain data may not be considered important at the time of entry not register history or changes of the data Missing data may need to be inferred. preprocessing 15

16 How to Handle Missing Data? Ignore the tuple: usually done when class label is missing (assuming the tasks in classification not effective when the percentage of missing values per attribute varies considerably. Fill in the missing value manually: tedious + infeasible? Use a global constant to fill in the missing value: e.g., unknown, a new class?! Imputation: Use the attribute mean to fill in the missing value, or use the attribute mean for all samples belonging to the same class to fill in the missing value: smarter Use the most probable value to fill in the missing value: inference-based such as Bayesian formula or decision tree preprocessing 16

17 Data Cleaning: Unified Date Format We want to transform all dates to the same format internally Some systems accept dates in many formats e.g. Sep 24, 2003, 9/24/03, , etc dates are transformed internally to a standard value Frequently, just the year (YYYY) is sufficient For more details, we may need the month, the day, the hour, etc Representing date as YYYYMM or YYYYMMDD can be OK, but has problems Q: What are the problems with YYYYMMDD dates? A: Ignoring for now the Looming Y10K (year 10,000 crisis ) YYYYMMDD does not preserve intervals: /= This can introduce bias into models preprocessing 17
 YYYYMMDD does not preserve intervals: 20040201-20040131 /= 20040131 20040130 This can introduce bias")
18 Unified Date Format Options To preserve intervals, we can use Unix system date: Number of seconds since 1970 Number of days since Jan 1, 1960 (SAS) Problem: values are non-obvious don t help intuition and knowledge discovery harder to verify, easier to make an error preprocessing 18

19 KSP Date Format days_starting_jan_1-0.5 KSP Date = YYYY _if_leap_year Preserves intervals (almost) The year and quarter are obvious Sep 24, 2003 is ( )/365= (round to 4 digits) Consistent with date starting at noon Can be extended to include time preprocessing 19
/365= 2003.")
20 Y2K issues: 2 digit Year 2-digit year in old data legacy of Y2K E.g. Q: Year 02 is it 1902 or 2002? A: Depends on context (e.g. child birthday or year of house construction) Typical approach: CUTOFF year, e.g. 30 if YY < CUTOFF, then 20YY, else 19YY preprocessing 20

21 Conversion: Nominal to Numeric Some tools can deal with nominal values internally Other methods (neural nets, regression, nearest neighbor) require only numeric inputs To use nominal fields in such methods need to convert them to a numeric value Q: Why not ignore nominal fields altogether? A: They may contain valuable information Different strategies for binary, ordered, multi-valued nominal fields preprocessing 21
22 Conversion: Binary to Numeric Binary fields E.g. Gender=M, F Convert to Field_0_1 with 0, 1 values e.g. Gender = M Gender_0_1 = 0 Gender = F Gender_0_1 = 1 preprocessing 22
23 Conversion: Ordered to Numeric Ordered attributes (e.g. Grade) can be converted to numbers preserving natural order, e.g. A 4.0 A- 3.7 B+ 3.3 B 3.0 Q: Why is it important to preserve natural order? A: To allow meaningful comparisons, e.g. Grade > 3.5 preprocessing 23
24 Conversion: Nominal, Few Values Multi-valued, unordered attributes with small (rule of thumb < 20) no. of values e.g. Color=Red, Orange, Yellow,, Violet for each value v create a binary flag variable C_v, which is 1 if Color=v, 0 otherwise ID Color 371 red 433 yellow ID C_re d C_orange C_yello w 0 1 preprocessing 24
25 Conversion: Nominal, Many Values Examples: US State Code (50 values) Profession Code (7,000 values, but only few frequent) Q: How to deal with such fields? A: Ignore ID-like fields whose values are unique for each record For other fields, group values naturally : e.g. 50 US States 3 or 5 regions Profession select most frequent ones, group the rest Create binary flag-fields for selected values preprocessing 25
26 Noisy Data Noise: random error or variance in a measured variable Incorrect attribute values may due to faulty data collection instruments data entry problems data transmission problems technology limitation inconsistency in naming convention Other data problems which requires data cleaning duplicate records incomplete data inconsistent data preprocessing 26
27 How to Handle Noisy Data? Binning method: first sort data and partition into (equi-depth) bins then one can smooth by bin means, smooth by bin median, smooth by bin boundaries, etc. Clustering detect and remove outliers Combined computer and human inspection detect suspicious values and check by human Regression smooth by fitting the data into regression functions preprocessing 27
28 Simple Discretization Methods: Binning Equal-width (distance) partitioning: It divides the range into N intervals of equal size: uniform grid if A and B are the lowest and highest values of the attribute, the width of intervals will be: W = (B-A)/N. The most straightforward But outliers may dominate presentation Skewed data is not handled well. Equal-depth (frequency) partitioning: It divides the range into N intervals, each containing approximately same number of samples Good data scaling Managing categorical attributes can be tricky. preprocessing 28
29 Binning Methods for Data Smoothing * Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 * Partition into (equi-depth) bins: - Bin 1: 4, 8, 9, 15 - Bin 2: 21, 21, 24, 25 - Bin 3: 26, 28, 29, 34 * Smoothing by bin means: - Bin 1: 9, 9, 9, 9 - Bin 2: 23, 23, 23, 23 - Bin 3: 29, 29, 29, 29 * Smoothing by bin boundaries: - Bin 1: 4, 4, 4, 15 - Bin 2: 21, 21, 25, 25 - Bin 3: 26, 26, 26, 34 preprocessing 29
30 Cluster Analysis preprocessing 30
31 Regression y Y1 Y1 y = x + 1 X1 x preprocessing 31
32 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 32
33 Data Integration Data integration: combines data from multiple sources into a coherent store Schema integration integrate metadata from different sources Entity identification problem: identify real world entities from multiple data sources, e.g., A.cust-id B.cust-# Detecting and resolving data value conflicts for the same real world entity, attribute values from different sources are different possible reasons: different representations, different scales, e.g., metric vs. British units preprocessing 33
34 Handling Redundant Data in Data Integration Redundant data occur often when integration of multiple databases The same attribute may have different names in different databases One attribute may be a derived attribute in another table, e.g., annual revenue Redundant data may be able to be detected by correlational analysis Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality preprocessing 34
35 Data Transformation Smoothing: remove noise from data Aggregation: summarization, data cube construction Generalization: concept hierarchy climbing Normalization: scaled to fall within a small, specified range min-max normalization z-score normalization normalization by decimal scaling Attribute/feature construction New attributes constructed from the given ones preprocessing 35
36 Data Transformation: Normalization min-max normalization v mina v' = ( new_ maxa new_ mina) + new_ min maxa mina z-score normalization v mean A v ' = stand _ dev A normalization by decimal scaling v v 10 '= Where j is the smallest integer such that Max( )<1 j v' A preprocessing 36
37 Unbalanced Target Distribution Sometimes, classes have very unequal frequency Attrition prediction: 97% stay, 3% attrite (in a month) medical diagnosis: 90% healthy, 10% disease ecommerce: 99% don t buy, 1% buy Security: >99.99% of Americans are not terrorists Similar situation with multiple classes Majority class classifier can be 97% correct, but useless preprocessing 37
38 Handling Unbalanced Data With two classes: let positive targets be a minority Separate raw held-aside set (e.g. 30% of data) and raw train put aside raw held-aside and don t use it till the final model Select remaining positive targets (e.g. 70% of all targets) from raw train Join with equal number of negative targets from raw train, and randomly sort it. Separate randomized balanced set into balanced train and balanced test preprocessing 38
39 Building Balanced Train Sets Targets Non-Targets Raw Held Y.... N N N Balanced set Balanced Train Balanced Test preprocessing 39
40 Learning with Unbalanced Data Build models on balanced train/test sets Estimate the final results (lift curve) on the raw held set Can generalize balancing to multiple classes stratified sampling Ensure that each class is represented with approximately equal proportions in train and test preprocessing 40
41 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 41
42 Data Reduction Strategies Warehouse may store terabytes of data: Complex data analysis/mining may take a very long time to run on the complete data set Data reduction Obtains a reduced representation of the data set that is much smaller in volume but yet produces the same (or almost the same) analytical results Data reduction strategies Data cube aggregation Dimensionality reduction Numerosity reduction Discretization and concept hierarchy generation preprocessing 42
43 Data Cube Aggregation The lowest level of a data cube the aggregated data for an individual entity of interest e.g., a customer in a phone calling data warehouse. Multiple levels of aggregation in data cubes Further reduce the size of data to deal with Reference appropriate levels Use the smallest representation which is enough to solve the task Queries regarding aggregated information should be answered using data cube, when possible preprocessing 43
44 Dimensionality Reduction Feature selection (i.e., attribute subset selection): Select a minimum set of features such that the probability distribution of different classes given the values for those features is as close as possible to the original distribution given the values of all features reduce # of patterns in the patterns, easier to understand Heuristic methods (due to exponential # of choices): step-wise forward selection step-wise backward elimination combining forward selection and backward elimination decision-tree induction preprocessing 44
45 Example of Decision Tree Induction Initial attribute set: {A1, A2, A3, A4, A5, A6} A4? A1? A6? Class 1 Class 2 Class 1 Class 2 > Reduced attribute set: {A1, A4, A6} preprocessing 45
46 Attribute Selection There are 2 d possible sub-features of d features First: Remove attributes with no or little variability Examine the number of distinct field values Rule of thumb: remove a field where almost all values are the same (e.g. null), except possibly in minp % or less of all records. minp could be 0.5% or more generally less than 5% of the number of targets of the smallest class What is good N? Rule of thumb -- keep top 50 fields preprocessing 46
47 Data Compression String compression There are extensive theories and well-tuned algorithms Typically lossless But only limited manipulation is possible without expansion Audio/video compression Typically lossy compression, with progressive refinement Sometimes small fragments of signal can be reconstructed without reconstructing the whole Time sequence is not audio Typically short and vary slowly with time preprocessing 47
48 Data Compression Original Data lossless Compressed Data Original Data Approximated lossy preprocessing 48
49 Wavelet Transforms Discrete wavelet transform (DWT): linear signal processing Compressed approximation: store only a small fraction of the strongest of the wavelet coefficients Similar to discrete Fourier transform (DFT), but better lossy compression, localized in space Method: Length, L, must be an integer power of 2 (padding with 0s, when necessary) Each transform has 2 functions: smoothing, difference Haar2 Applies to pairs of data, resulting in two set of data of length L/2 Applies two functions recursively, until reaches the desired length Daubechie4 preprocessing 49
50 Principal Component Analysis Given N data vectors from k-dimensions, find c <= k orthogonal vectors that can be best used to represent data The original data set is reduced to one consisting of N data vectors on c principal components (reduced dimensions) Each data vector is a linear combination of the c principal component vectors Works for numeric data only Used when the number of dimensions is large preprocessing 50
51 Principal Component Analysis X2 Y2 Y1 X1 preprocessing 51
52 Numerosity Reduction Parametric methods Assume the data fits some model, estimate model parameters, store only the parameters, and discard the data (except possible outliers) Log-linear models: obtain value at a point in m-d space as the product on appropriate marginal subspaces Non-parametric methods Do not assume models Major families: histograms, clustering, sampling preprocessing 52
53 Regression and Log-Linear Models Linear regression: Data are modeled to fit a straight line Often uses the least-square method to fit the line Multiple regression: allows a response variable Y to be modeled as a linear function of multidimensional feature vector Log-linear model: approximates discrete multidimensional probability distributions preprocessing 53
54 Regress Analysis and Log-Linear Models Linear regression: Y = α + β X Two parameters, α and β specify the line and are to be estimated by using the data at hand. using the least squares criterion to the known values of Y1, Y2,, X1, X2,. Multiple regression: Y = b0 + b1 X1 + b2 X2. Many nonlinear functions can be transformed into the above. Log-linear models: The multi-way table of joint probabilities is approximated by a product of lower-order tables. Probability: p(a, b, c, d) = αab βacχad δbcd preprocessing 54
55 Histograms A popular data reduction technique 40 Divide data into buckets and store average (sum) for each bucket Can be constructed 20 optimally in one 15 dimension using dynamic 10 programming Related to quantization problems preprocessing 55
56 Clustering Partition data set into clusters, and one can store cluster representation only Can be very effective if data is clustered but not if data is smeared Can have hierarchical clustering and be stored in multidimensional index tree structures There are many choices of clustering definitions and clustering algorithms, further detailed in Chapter 8 preprocessing 56
57 Sampling Allow a mining algorithm to run in complexity that is potentially sub-linear to the size of the data Choose a representative subset of the data Simple random sampling may have very poor performance in the presence of skew Develop adaptive sampling methods Stratified sampling: Approximate the percentage of each class (or subpopulation of interest) in the overall database Used in conjunction with skewed data Sampling may not reduce database I/Os (page at a time). preprocessing 57
58 Sampling preprocessing 58 SRSWOR (simple random sample without replacement) SRSWR Raw Data
59 Sampling Raw Data Cluster/Stratified Sample preprocessing 59
60 Hierarchical Reduction Use multi-resolution structure with different degrees of reduction Hierarchical clustering is often performed but tends to define partitions of data sets rather than clusters Parametric methods are usually not amenable to hierarchical representation Hierarchical aggregation An index tree hierarchically divides a data set into partitions by value range of some attributes Each partition can be considered as a bucket Thus an index tree with aggregates stored at each node is a hierarchical histogram preprocessing 60
61 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 61
62 Discretization Three types of attributes: Nominal values from an unordered set Ordinal values from an ordered set Continuous real numbers Discretization: divide the range of a continuous attribute into intervals Some classification algorithms only accept categorical attributes. Reduce data size by discretization Prepare for further analysis preprocessing 62
63 Discretization and Concept hierachy Discretization reduce the number of values for a given continuous attribute by dividing the range of the attribute into intervals. Interval labels can then be used to replace actual data values. Concept hierarchies reduce the data by collecting and replacing low level concepts (such as numeric values for the attribute age) by higher level concepts (such as young, middle-aged, or senior). preprocessing 63
64 Discretization and concept hierarchy generation for numeric data Binning (see sections before) Histogram analysis (see sections before) Clustering analysis (see sections before) Entropy-based discretization Segmentation by natural partitioning preprocessing 64
65 Entropy-Based Discretization Given a set of samples S, if S is partitioned into two intervals S1 and S2 using boundary T, the entropy after partitioning is S EST S Ent S (, ) = 1 ( S ) S Ent ( S2 ) The boundary that minimizes the entropy function over all possible boundaries is selected as a binary discretization. The process is recursively applied to partitions obtained until some stopping criterion is met, e.g., Ent( S) E( T, S) > δ Experiments show that it may reduce data size and improve classification accuracy preprocessing 65
66 Segmentation by natural partitioning rule can be used to segment numeric data into relatively uniform, natural intervals. * If an interval covers 3, 6, 7 or 9 distinct values at the most significant digit, partition the range into 3 equi-width intervals * If it covers 2, 4, or 8 distinct values at the most significant digit, partition the range into 4 intervals * If it covers 1, 5, or 10 distinct values at the most significant digit, partition the range into 5 intervals preprocessing 66
67 Example of rule count Step 1: -$351 -$159 profit $1,838 $4,700 Min Low (i.e, 5%-tile) High(i.e, 95%-0 tile) Max Step 2: msd=1,000 Low=-$1,000 High=$2,000 Step 3: (-$1,000 - $2,000) (-$1,000-0) (0 -$ 1,000) ($1,000 - $2,000) Step 4: (-$4000 -$5,000) (-$400-0) (0 - $1,000) ($1,000 - $2, 000) ($2,000 - $5, 000) (-$ $300) (-$ $200) (-$ $100) (-$100-0) (0 - $200) ($200 - $400) ($400 - $600) ($600 - $800) ($800 - $1,000) ($1,000 - $1,200) ($1,200 - $1,400) ($1,400 - $1,600) ($1,600 - $1,800) ($1,800 - $2,000) ($2,000 - $3,000) ($3,000 - $4,000) ($4,000 - $5,000) preprocessing 67
68 Concept hierarchy generation for categorical data Specification of a partial ordering of attributes explicitly at the schema level by users or experts Specification of a portion of a hierarchy by explicit data grouping Specification of a set of attributes, but not of their partial ordering Specification of only a partial set of attributes preprocessing 68
69 Specification of a set of attributes Concept hierarchy can be automatically generated based on the number of distinct values per attribute in the given attribute set. The attribute with the most distinct values is placed at the lowest level of the hierarchy. country province_or_ state city street 15 distinct values 65 distinct values 3567 distinct values 674,339 distinct values preprocessing 69
70 Outline Introduction Data cleaning Data integration and transformation Data reduction Discretization and concept hierarchy generation Summary preprocessing 70
71 Summary Data preparation is a big issue for both warehousing and mining Data preparation includes Data cleaning and data integration Data reduction and feature selection Discretization A lot a methods have been developed but still an active area of research preprocessing 71
72 Good data preparation is key to producing valid and reliable models preprocessing 72
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 3: DATA TRANSFORMATION AND DIMENSIONALITY REDUCTION Chapter 3: Data Preprocessing Data Preprocessing: An Overview Data Quality Major
Data Mining: Data Preprocessing. I211: Information infrastructure II
 Data Mining: Data Preprocessing I211: Information infrastructure II 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property or characteristic of an object
Data Mining: Data Preprocessing I211: Information infrastructure II 10 What is Data? Collection of data objects and their attributes Attributes An attribute is a property or characteristic of an object
Data Preprocessing. Week 2
 Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
Data Preprocessing Week 2 Topics Data Types Data Repositories Data Preprocessing Present homework assignment #1 Team Homework Assignment #2 Read pp. 227 240, pp. 250 250, and pp. 259 263 the text book.
Data Exploration and Preprocessing. Data Mining and Text Mining (UIC 583 @ Politecnico di Milano)
") Data Exploration and Preprocessing Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Data Exploration and Preprocessing Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Medical Information Management & Mining. You Chen Jan,15, 2013 You.chen@vanderbilt.edu
 Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Medical Information Management & Mining You Chen Jan,15, 2013 You.chen@vanderbilt.edu 1 Trees Building Materials Trees cannot be used to build a house directly. How can we transform trees to building materials?
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
Data Mining Part 5. Prediction 5.1 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Classification vs. Numeric Prediction Prediction Process Data Preparation Comparing Prediction Methods References Classification
IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH
 IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH Kalinka Mihaylova Kaloyanova St. Kliment Ohridski University of Sofia, Faculty of Mathematics and Informatics Sofia 1164, Bulgaria
IMPROVING DATA INTEGRATION FOR DATA WAREHOUSE: A DATA MINING APPROACH Kalinka Mihaylova Kaloyanova St. Kliment Ohridski University of Sofia, Faculty of Mathematics and Informatics Sofia 1164, Bulgaria
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
International Journal of Computer Science Trends and Technology (IJCST) Volume 2 Issue 3, May-Jun 2014
 Volume 2 Issue 3, May-Jun 2014") RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
ETL PROCESS IN DATA WAREHOUSE
 ETL PROCESS IN DATA WAREHOUSE OUTLINE ETL : Extraction, Transformation, Loading Capture/Extract Scrub or data cleansing Transform Load and Index ETL OVERVIEW Extraction Transformation Loading ETL ETL is
ETL PROCESS IN DATA WAREHOUSE OUTLINE ETL : Extraction, Transformation, Loading Capture/Extract Scrub or data cleansing Transform Load and Index ETL OVERVIEW Extraction Transformation Loading ETL ETL is
Customer Classification And Prediction Based On Data Mining Technique
 Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Customer Classification And Prediction Based On Data Mining Technique Ms. Neethu Baby 1, Mrs. Priyanka L.T 2 1 M.E CSE, Sri Shakthi Institute of Engineering and Technology, Coimbatore 2 Assistant Professor
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
Knowledge Discovery and Data Mining. Structured vs. Non-Structured Data
 Knowledge Discovery and Data Mining Unit # 2 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric or alphanumeric values.
Knowledge Discovery and Data Mining Unit # 2 1 Structured vs. Non-Structured Data Most business databases contain structured data consisting of well-defined fields with numeric or alphanumeric values.
IBM SPSS Direct Marketing 22
 IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
Mario Guarracino. Data warehousing
 Data warehousing Introduction Since the mid-nineties, it became clear that the databases for analysis and business intelligence need to be separate from operational. In this lecture we will review the
Data warehousing Introduction Since the mid-nineties, it became clear that the databases for analysis and business intelligence need to be separate from operational. In this lecture we will review the
Data Mining: Concepts and Techniques. Jiawei Han. Micheline Kamber. Simon Fräser University К MORGAN KAUFMANN PUBLISHERS. AN IMPRINT OF Elsevier
 Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
Data Mining: Concepts and Techniques Jiawei Han Micheline Kamber Simon Fräser University К MORGAN KAUFMANN PUBLISHERS AN IMPRINT OF Elsevier Contents Foreword Preface xix vii Chapter I Introduction I I.
COM CO P 5318 Da t Da a t Explora Explor t a ion and Analysis y Chapte Chapt r e 3
 COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
COMP 5318 Data Exploration and Analysis Chapter 3 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping
BUSINESS ANALYTICS. Data Pre-processing. Lecture 3. Information Systems and Machine Learning Lab. University of Hildesheim.
 Tomáš Horváth BUSINESS ANALYTICS Lecture 3 Data Pre-processing Information Systems and Machine Learning Lab University of Hildesheim Germany Overview The aim of this lecture is to describe some data pre-processing
Tomáš Horváth BUSINESS ANALYTICS Lecture 3 Data Pre-processing Information Systems and Machine Learning Lab University of Hildesheim Germany Overview The aim of this lecture is to describe some data pre-processing
Principles of Data Mining by Hand&Mannila&Smyth
 Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Data Mining: A Preprocessing Engine
 Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 8/05/2005 1 What is data exploration? A preliminary
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
STATISTICA Formula Guide: Logistic Regression. Table of Contents
 : Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
: Table of Contents... 1 Overview of Model... 1 Dispersion... 2 Parameterization... 3 Sigma-Restricted Model... 3 Overparameterized Model... 4 Reference Coding... 4 Model Summary (Summary Tab)... 5 Summary
The Scientific Data Mining Process
 Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
Chapter 4 The Scientific Data Mining Process When I use a word, Humpty Dumpty said, in rather a scornful tone, it means just what I choose it to mean neither more nor less. Lewis Carroll [87, p. 214] In
COMP3420: Advanced Databases and Data Mining. Classification and prediction: Introduction and Decision Tree Induction
 COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
COMP3420: Advanced Databases and Data Mining Classification and prediction: Introduction and Decision Tree Induction Lecture outline Classification versus prediction Classification A two step process Supervised
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland
 State of the Art. Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland") Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Data Mining and Knowledge Discovery in Databases (KDD) State of the Art Prof. Dr. T. Nouri Computer Science Department FHNW Switzerland 1 Conference overview 1. Overview of KDD and data mining 2. Data
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree
 Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
A Survey on Pre-processing and Post-processing Techniques in Data Mining
 , pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
, pp. 99-128 http://dx.doi.org/10.14257/ijdta.2014.7.4.09 A Survey on Pre-processing and Post-processing Techniques in Data Mining Divya Tomar and Sonali Agarwal Indian Institute of Information Technology,
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 01 : 06/10/2015 Practical informations: Teacher: Alberto Ceselli (alberto.ceselli@unimi.it)
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 01 : 06/10/2015 Practical informations: Teacher: Alberto Ceselli (alberto.ceselli@unimi.it)
OLAP and Data Mining. Data Warehousing and End-User Access Tools. Introducing OLAP. Introducing OLAP
 Data Warehousing and End-User Access Tools OLAP and Data Mining Accompanying growth in data warehouses is increasing demands for more powerful access tools providing advanced analytical capabilities. Key
Data Warehousing and End-User Access Tools OLAP and Data Mining Accompanying growth in data warehouses is increasing demands for more powerful access tools providing advanced analytical capabilities. Key
Decision Trees What Are They?
 Decision Trees What Are They? Introduction...1 Using Decision Trees with Other Modeling Approaches...5 Why Are Decision Trees So Useful?...8 Level of Measurement... 11 Introduction Decision trees are a
Decision Trees What Are They? Introduction...1 Using Decision Trees with Other Modeling Approaches...5 Why Are Decision Trees So Useful?...8 Level of Measurement... 11 Introduction Decision trees are a
Clustering & Visualization
 Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
Chapter 5 Clustering & Visualization Clustering in high-dimensional databases is an important problem and there are a number of different clustering paradigms which are applicable to high-dimensional data.
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING
 EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
What is Data Mining? MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling. MS4424 Data Mining & Modelling
 MS4424 Data Mining & Modelling MS4424 Data Mining & Modelling Lecturer : Dr Iris Yeung Room No : P7509 Tel No : 2788 8566 Email : msiris@cityu.edu.hk 1 Aims To introduce the basic concepts of data mining
MS4424 Data Mining & Modelling MS4424 Data Mining & Modelling Lecturer : Dr Iris Yeung Room No : P7509 Tel No : 2788 8566 Email : msiris@cityu.edu.hk 1 Aims To introduce the basic concepts of data mining
Clustering. Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016
 Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Clustering Danilo Croce Web Mining & Retrieval a.a. 2015/201 16/03/2016 1 Supervised learning vs. unsupervised learning Supervised learning: discover patterns in the data that relate data attributes with
Standardization and Its Effects on K-Means Clustering Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Research Journal of Applied Sciences, Engineering and Technology 6(7): 399-3303, 03 ISSN: 040-7459; e-issn: 040-7467 Maxwell Scientific Organization, 03 Submitted: January 3, 03 Accepted: February 5, 03
Lecture 6 - Data Mining Processes
 Lecture 6 - Data Mining Processes Dr. Songsri Tangsripairoj Dr.Benjarath Pupacdi Faculty of ICT, Mahidol University 1 Cross-Industry Standard Process for Data Mining (CRISP-DM) Example Application: Telephone
Lecture 6 - Data Mining Processes Dr. Songsri Tangsripairoj Dr.Benjarath Pupacdi Faculty of ICT, Mahidol University 1 Cross-Industry Standard Process for Data Mining (CRISP-DM) Example Application: Telephone
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
Data analysis process
 Data analysis process Data collection and preparation Collect data Prepare codebook Set up structure of data Enter data Screen data for errors Exploration of data Descriptive Statistics Graphs Analysis
Data analysis process Data collection and preparation Collect data Prepare codebook Set up structure of data Enter data Screen data for errors Exploration of data Descriptive Statistics Graphs Analysis
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Data Mining: Overview. What is Data Mining?
 Data Mining: Overview What is Data Mining? Recently * coined term for confluence of ideas from statistics and computer science (machine learning and database methods) applied to large databases in science,
Data Mining: Overview What is Data Mining? Recently * coined term for confluence of ideas from statistics and computer science (machine learning and database methods) applied to large databases in science,
Data Mining: Exploring Data. Lecture Notes for Chapter 3. Introduction to Data Mining
 Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
Data Mining: Exploring Data Lecture Notes for Chapter 3 Introduction to Data Mining by Tan, Steinbach, Kumar What is data exploration? A preliminary exploration of the data to better understand its characteristics.
WebFOCUS RStat. RStat. Predict the Future and Make Effective Decisions Today. WebFOCUS RStat
 Information Builders enables agile information solutions with business intelligence (BI) and integration technologies. WebFOCUS the most widely utilized business intelligence platform connects to any enterprise
Information Builders enables agile information solutions with business intelligence (BI) and integration technologies. WebFOCUS the most widely utilized business intelligence platform connects to any enterprise
The Science and Art of Market Segmentation Using PROC FASTCLUS Mark E. Thompson, Forefront Economics Inc, Beaverton, Oregon
 The Science and Art of Market Segmentation Using PROC FASTCLUS Mark E. Thompson, Forefront Economics Inc, Beaverton, Oregon ABSTRACT Effective business development strategies often begin with market segmentation,
The Science and Art of Market Segmentation Using PROC FASTCLUS Mark E. Thompson, Forefront Economics Inc, Beaverton, Oregon ABSTRACT Effective business development strategies often begin with market segmentation,
Data Mining Algorithms Part 1. Dejan Sarka
 Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Data Mining Algorithms Part 1 Dejan Sarka Join the conversation on Twitter: @DevWeek #DW2015 Instructor Bio Dejan Sarka (dsarka@solidq.com) 30 years of experience SQL Server MVP, MCT, 13 books 7+ courses
Learning Example. Machine learning and our focus. Another Example. An example: data (loan application) The data and the goal
 The data and the goal") Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
Learning Example Chapter 18: Learning from Examples 22c:145 An emergency room in a hospital measures 17 variables (e.g., blood pressure, age, etc) of newly admitted patients. A decision is needed: whether
IBM SPSS Data Preparation 22
 IBM SPSS Data Preparation 22 Note Before using this information and the product it supports, read the information in Notices on page 33. Product Information This edition applies to version 22, release
IBM SPSS Data Preparation 22 Note Before using this information and the product it supports, read the information in Notices on page 33. Product Information This edition applies to version 22, release
IBM SPSS Neural Networks 22
 IBM SPSS Neural Networks 22 Note Before using this information and the product it supports, read the information in Notices on page 21. Product Information This edition applies to version 22, release 0,
IBM SPSS Neural Networks 22 Note Before using this information and the product it supports, read the information in Notices on page 21. Product Information This edition applies to version 22, release 0,
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Index Contents Page No. Introduction . Data Mining & Knowledge Discovery
 Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
DATA MINING TECHNIQUES AND APPLICATIONS
 DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
DATA MINING TECHNIQUES AND APPLICATIONS Mrs. Bharati M. Ramageri, Lecturer Modern Institute of Information Technology and Research, Department of Computer Application, Yamunanagar, Nigdi Pune, Maharashtra,
Data Exploration Data Visualization
 Data Exploration Data Visualization What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping to select
Data Exploration Data Visualization What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include Helping to select
IBM SPSS Direct Marketing 19
 IBM SPSS Direct Marketing 19 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This document contains proprietary information of SPSS
IBM SPSS Direct Marketing 19 Note: Before using this information and the product it supports, read the general information under Notices on p. 105. This document contains proprietary information of SPSS
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr
 Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Data Mining 5. Cluster Analysis
 Data Mining 5. Cluster Analysis 5.2 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Data Structures Interval-Valued (Numeric) Variables Binary Variables Categorical Variables Ordinal Variables Variables
Data Mining 5. Cluster Analysis 5.2 Fall 2009 Instructor: Dr. Masoud Yaghini Outline Data Structures Interval-Valued (Numeric) Variables Binary Variables Categorical Variables Ordinal Variables Variables
KNIME TUTORIAL. Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it
 KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Market Basket Analysis Exercise: Customer Segmentation Exercise:
KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Market Basket Analysis Exercise: Customer Segmentation Exercise:
(b) How data mining is different from knowledge discovery in databases (KDD)? Explain.
 How data mining is different from knowledge discovery in databases (KDD)? Explain.") Q2. (a) List and describe the five primitives for specifying a data mining task. Data Mining Task Primitives (b) How data mining is different from knowledge discovery in databases (KDD)? Explain. IETE
Q2. (a) List and describe the five primitives for specifying a data mining task. Data Mining Task Primitives (b) How data mining is different from knowledge discovery in databases (KDD)? Explain. IETE
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
A Property & Casualty Insurance Predictive Modeling Process in SAS
 Paper AA-02-2015 A Property & Casualty Insurance Predictive Modeling Process in SAS 1.0 ABSTRACT Mei Najim, Sedgwick Claim Management Services, Chicago, Illinois Predictive analytics has been developing
Paper AA-02-2015 A Property & Casualty Insurance Predictive Modeling Process in SAS 1.0 ABSTRACT Mei Najim, Sedgwick Claim Management Services, Chicago, Illinois Predictive analytics has been developing
Data Mining Techniques
 15.564 Information Technology I Business Intelligence Outline Operational vs. Decision Support Systems What is Data Mining? Overview of Data Mining Techniques Overview of Data Mining Process Data Warehouses
15.564 Information Technology I Business Intelligence Outline Operational vs. Decision Support Systems What is Data Mining? Overview of Data Mining Techniques Overview of Data Mining Process Data Warehouses
1. What are the uses of statistics in data mining? Statistics is used to Estimate the complexity of a data mining problem. Suggest which data mining
 1. What are the uses of statistics in data mining? Statistics is used to Estimate the complexity of a data mining problem. Suggest which data mining techniques are most likely to be successful, and Identify
1. What are the uses of statistics in data mining? Statistics is used to Estimate the complexity of a data mining problem. Suggest which data mining techniques are most likely to be successful, and Identify
In this presentation, you will be introduced to data mining and the relationship with meaningful use.
 In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
In this presentation, you will be introduced to data mining and the relationship with meaningful use. Data mining refers to the art and science of intelligent data analysis. It is the application of machine
Importance or the Role of Data Warehousing and Data Mining in Business Applications
 Journal of The International Association of Advanced Technology and Science Importance or the Role of Data Warehousing and Data Mining in Business Applications ATUL ARORA ANKIT MALIK Abstract Information
Journal of The International Association of Advanced Technology and Science Importance or the Role of Data Warehousing and Data Mining in Business Applications ATUL ARORA ANKIT MALIK Abstract Information
Data Mining with SAS. Mathias Lanner mathias.lanner@swe.sas.com. Copyright 2010 SAS Institute Inc. All rights reserved.
 Data Mining with SAS Mathias Lanner mathias.lanner@swe.sas.com Copyright 2010 SAS Institute Inc. All rights reserved. Agenda Data mining Introduction Data mining applications Data mining techniques SEMMA
Data Mining with SAS Mathias Lanner mathias.lanner@swe.sas.com Copyright 2010 SAS Institute Inc. All rights reserved. Agenda Data mining Introduction Data mining applications Data mining techniques SEMMA
BIDM Project. Predicting the contract type for IT/ITES outsourcing contracts
 BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Foundations of Business Intelligence: Databases and Information Management
 Foundations of Business Intelligence: Databases and Information Management Content Problems of managing data resources in a traditional file environment Capabilities and value of a database management
Foundations of Business Intelligence: Databases and Information Management Content Problems of managing data resources in a traditional file environment Capabilities and value of a database management
Data mining and statistical models in marketing campaigns of BT Retail
 Data mining and statistical models in marketing campaigns of BT Retail Francesco Vivarelli and Martyn Johnson Database Exploitation, Segmentation and Targeting group BT Retail Pp501 Holborn centre 120
Data mining and statistical models in marketing campaigns of BT Retail Francesco Vivarelli and Martyn Johnson Database Exploitation, Segmentation and Targeting group BT Retail Pp501 Holborn centre 120
Rule based Classification of BSE Stock Data with Data Mining
 International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 4, Number 1 (2012), pp. 1-9 International Research Publication House http://www.irphouse.com Rule based Classification
International Journal of Information Sciences and Application. ISSN 0974-2255 Volume 4, Number 1 (2012), pp. 1-9 International Research Publication House http://www.irphouse.com Rule based Classification
Data Mining Using SAS Enterprise Miner Randall Matignon, Piedmont, CA
 Data Mining Using SAS Enterprise Miner Randall Matignon, Piedmont, CA An Overview of SAS Enterprise Miner The following article is in regards to Enterprise Miner v.4.3 that is available in SAS v9.1.3.
Data Mining Using SAS Enterprise Miner Randall Matignon, Piedmont, CA An Overview of SAS Enterprise Miner The following article is in regards to Enterprise Miner v.4.3 that is available in SAS v9.1.3.
Silvermine House Steenberg Office Park, Tokai 7945 Cape Town, South Africa Telephone: +27 21 702 4666 www.spss-sa.com
 SPSS-SA Silvermine House Steenberg Office Park, Tokai 7945 Cape Town, South Africa Telephone: +27 21 702 4666 www.spss-sa.com SPSS-SA Training Brochure 2009 TABLE OF CONTENTS 1 SPSS TRAINING COURSES FOCUSING
SPSS-SA Silvermine House Steenberg Office Park, Tokai 7945 Cape Town, South Africa Telephone: +27 21 702 4666 www.spss-sa.com SPSS-SA Training Brochure 2009 TABLE OF CONTENTS 1 SPSS TRAINING COURSES FOCUSING
A THEORETICAL COMPARISON OF DATA MASKING TECHNIQUES FOR NUMERICAL MICRODATA
 A THEORETICAL COMPARISON OF DATA MASKING TECHNIQUES FOR NUMERICAL MICRODATA Krish Muralidhar University of Kentucky Rathindra Sarathy Oklahoma State University Agency Internal User Unmasked Result Subjects
A THEORETICAL COMPARISON OF DATA MASKING TECHNIQUES FOR NUMERICAL MICRODATA Krish Muralidhar University of Kentucky Rathindra Sarathy Oklahoma State University Agency Internal User Unmasked Result Subjects
Data Mining Analytics for Business Intelligence and Decision Support
 Data Mining Analytics for Business Intelligence and Decision Support Chid Apte, T.J. Watson Research Center, IBM Research Division Knowledge Discovery and Data Mining (KDD) techniques are used for analyzing
Data Mining Analytics for Business Intelligence and Decision Support Chid Apte, T.J. Watson Research Center, IBM Research Division Knowledge Discovery and Data Mining (KDD) techniques are used for analyzing
Building Data Cubes and Mining Them. Jelena Jovanovic Email: jeljov@fon.bg.ac.yu
 Building Data Cubes and Mining Them Jelena Jovanovic Email: jeljov@fon.bg.ac.yu KDD Process KDD is an overall process of discovering useful knowledge from data. Data mining is a particular step in the
Building Data Cubes and Mining Them Jelena Jovanovic Email: jeljov@fon.bg.ac.yu KDD Process KDD is an overall process of discovering useful knowledge from data. Data mining is a particular step in the
Copyright 2007 Ramez Elmasri and Shamkant B. Navathe. Slide 29-1
 Slide 29-1 Chapter 29 Overview of Data Warehousing and OLAP Chapter 29 Outline Purpose of Data Warehousing Introduction, Definitions, and Terminology Comparison with Traditional Databases Characteristics
Slide 29-1 Chapter 29 Overview of Data Warehousing and OLAP Chapter 29 Outline Purpose of Data Warehousing Introduction, Definitions, and Terminology Comparison with Traditional Databases Characteristics
Data Analysis Tools. Tools for Summarizing Data
 Data Analysis Tools This section of the notes is meant to introduce you to many of the tools that are provided by Excel under the Tools/Data Analysis menu item. If your computer does not have that tool
Data Analysis Tools This section of the notes is meant to introduce you to many of the tools that are provided by Excel under the Tools/Data Analysis menu item. If your computer does not have that tool
DATA WAREHOUSING AND OLAP TECHNOLOGY
 DATA WAREHOUSING AND OLAP TECHNOLOGY Manya Sethi MCA Final Year Amity University, Uttar Pradesh Under Guidance of Ms. Shruti Nagpal Abstract DATA WAREHOUSING and Online Analytical Processing (OLAP) are
DATA WAREHOUSING AND OLAP TECHNOLOGY Manya Sethi MCA Final Year Amity University, Uttar Pradesh Under Guidance of Ms. Shruti Nagpal Abstract DATA WAREHOUSING and Online Analytical Processing (OLAP) are
E-Intelligence form design and Data Preprocessing in Health Care
 E-Intelligence form design and Data Preprocessing in Health Care by Padma Pedarla A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Applied
E-Intelligence form design and Data Preprocessing in Health Care by Padma Pedarla A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Applied
Applied Data Mining Analysis: A Step-by-Step Introduction Using Real-World Data Sets
 Applied Data Mining Analysis: A Step-by-Step Introduction Using Real-World Data Sets http://info.salford-systems.com/jsm-2015-ctw August 2015 Salford Systems Course Outline Demonstration of two classification
Applied Data Mining Analysis: A Step-by-Step Introduction Using Real-World Data Sets http://info.salford-systems.com/jsm-2015-ctw August 2015 Salford Systems Course Outline Demonstration of two classification
Data Mining Jargon. Bob Muenchen The Statistical Consulting Center
 Data Mining Jargon Bob Muenchen The Statistical Consulting Center Data mining is the automated search for useful patterns in data. It uses tools from many different disciplines, each of which uses its
Data Mining Jargon Bob Muenchen The Statistical Consulting Center Data mining is the automated search for useful patterns in data. It uses tools from many different disciplines, each of which uses its
The Data Mining Process
 Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Sequence for Determining Necessary Data. Wrong: Catalog everything you have, and decide what data is important. Right: Work backward from the solution, define the problem explicitly, and map out the data
Data Mining: An Introduction
 Data Mining: An Introduction Michael J. A. Berry and Gordon A. Linoff. Data Mining Techniques for Marketing, Sales and Customer Support, 2nd Edition, 2004 Data mining What promotions should be targeted
Data Mining: An Introduction Michael J. A. Berry and Gordon A. Linoff. Data Mining Techniques for Marketing, Sales and Customer Support, 2nd Edition, 2004 Data mining What promotions should be targeted
Big Data & Scripting Part II Streaming Algorithms
 Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
Big Data & Scripting Part II Streaming Algorithms 1, 2, a note on sampling and filtering sampling: (randomly) choose a representative subset filtering: given some criterion (e.g. membership in a set),
Foundations of Business Intelligence: Databases and Information Management
 Foundations of Business Intelligence: Databases and Information Management Problem: HP s numerous systems unable to deliver the information needed for a complete picture of business operations, lack of
Foundations of Business Intelligence: Databases and Information Management Problem: HP s numerous systems unable to deliver the information needed for a complete picture of business operations, lack of
Data Mining and Visualization
 Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Data Mining and Visualization Jeremy Walton NAG Ltd, Oxford Overview Data mining components Functionality Example application Quality control Visualization Use of 3D Example application Market research
Introduction to Data Mining
 Introduction to Data Mining 1 Why Data Mining? Explosive Growth of Data Data collection and data availability Automated data collection tools, Internet, smartphones, Major sources of abundant data Business:
Introduction to Data Mining 1 Why Data Mining? Explosive Growth of Data Data collection and data availability Automated data collection tools, Internet, smartphones, Major sources of abundant data Business:
A fast, powerful data mining workbench designed for small to midsize organizations
 FACT SHEET SAS Desktop Data Mining for Midsize Business A fast, powerful data mining workbench designed for small to midsize organizations What does SAS Desktop Data Mining for Midsize Business do? Business
FACT SHEET SAS Desktop Data Mining for Midsize Business A fast, powerful data mining workbench designed for small to midsize organizations What does SAS Desktop Data Mining for Midsize Business do? Business
DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM M. Mayilvaganan 1, S. Aparna 2 1 Associate
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM M. Mayilvaganan 1, S. Aparna 2 1 Associate
A Review of Data Mining Techniques
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 4, April 2014,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 4, April 2014,
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/2004 Hierarchical
NEW MEXICO Grade 6 MATHEMATICS STANDARDS
 PROCESS STANDARDS To help New Mexico students achieve the Content Standards enumerated below, teachers are encouraged to base instruction on the following Process Standards: Problem Solving Build new mathematical
PROCESS STANDARDS To help New Mexico students achieve the Content Standards enumerated below, teachers are encouraged to base instruction on the following Process Standards: Problem Solving Build new mathematical
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Classification and Prediction
 Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Classification and Prediction Slides for Data Mining: Concepts and Techniques Chapter 7 Jiawei Han and Micheline Kamber Intelligent Database Systems Research Lab School of Computing Science Simon Fraser
Chapter 5 Business Intelligence: Data Warehousing, Data Acquisition, Data Mining, Business Analytics, and Visualization
 Turban, Aronson, and Liang Decision Support Systems and Intelligent Systems, Seventh Edition Chapter 5 Business Intelligence: Data Warehousing, Data Acquisition, Data Mining, Business Analytics, and Visualization
Turban, Aronson, and Liang Decision Support Systems and Intelligent Systems, Seventh Edition Chapter 5 Business Intelligence: Data Warehousing, Data Acquisition, Data Mining, Business Analytics, and Visualization
Classification of Bad Accounts in Credit Card Industry
 Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition