How To Write A Database In Java With A New Data Type In Itunes.Com
|
|
|
- Randolph Marshall
- 3 years ago
- Views:
Transcription
1 Dynamic generation of web service APIs and interfaces through compilation of JSON Marisa Yeung, Nayan Deep Vemula and Sandy Siththanandan Team 4 COEN 259 Compilers Professor Ming Hwa Wang Santa Clara University Santa Clara, CA

2 Abstract The goal is to dynamically create APIs for the entry of new and modified data object types on the fly. This will be achieved through the compilation and analysis of incoming JSON objects, implemented using the ANTLR framework in Java. By recognizing when the key value pairs have been augmented with new elements, the required schema and documentation will be generated that will enable automatic adaptation of the interfaces to the database as well as the API for front end use in web development and other application end points.

3 Introduction The vision of a Semantic Web of the future requires development of technologies which can ease and automate the digestion and annotation of meaningful structural properties in the mass loads of data being produced in our information systems without requiring up front specification and freezing of concept ontologies. The systems need to be not only easy for people to implement and understand but also 'understandable' to the machines so we can offload higher level needs to them like pinpointing answers to subtle and complex queries. Full stack application development still involves intense amounts of effort on the part of large teams of highly technical software engineering staff. Many share the vision of enabling application development by laymen to the software field that domain experts might be able to easily specify their needs and create systems that can organize their information and processes. If these mechanisms were more easily harnessed, with lower barriers to entry, the information systems of the future could better grow, contain and manage the nuanced needs of the international community that all use the World Wide Web. Our objective is to see how we might contribute to this effort, by developing an attempt to intelligently solve a particular aspect of difficulty in application development. Specifically, during agile application development, it may happen that data schemas need to evolve from their initial specifications. This causes difficulties on many fronts, including things like needing to reconsider and re implement how the data will be input to the database, as well as communicating the new requirements for consumers of the data objects. We aim to investigate and prototype a framework which will recognize the evolution of data objects as they are first encountered, and propagate those changes to the components that require modifications to handle the changes. We will approach this problem through parsing JSON objects as they are input into the system plus augmented actions via compilation techniques learned in this course. We hope to generate code that will enable an application to adapt to these data schema changes, accepting the new data forms without effort on the part of the consumer or producer of the application, and presenting front end interfaces which communicate the new fields in the complex data types. We are aware of systems that exist such as CASE tools or object modeling initialization in frameworks which are supposed to enable ease of development, but as far as we know, these require up front describe once design. We would like to advance the capability to adapt the data system as the user becomes aware of new requirements. Also we would like this tool to be simple and lightweight, so that it might be useful and interesting to non technical people, for all kinds of as yet to be imagined use cases. Since JSON syntax is quite human readable, compared to other approaches which have involved XML or newly specified languages for

4 declaration of the data model, we think this may be a boon in the understandability of this approach. For now, we limit our scope to prototyping with JSON objects, input into the Neo4J graph database, and attempting one context of client generation, with the possibility of different kinds of front end generation depending on what we can achieve in our time frame. Beyond this proof of concept, there is also the possibility of parsing other data interchange formats so that alternative systems can be compiled. With further enhancements, we would aim to be able to recognize redundancies and inconsistencies in data modelling by different users, to try to merge models within organizations, or even across organizations to recognize isomorphic complex data types and ontologies in spite of variations in terminology. Theoretical bases and literature review The history of computer engineering shows a slow but steady climb upwards from the base metal of binary bits to assembly code to higher level languages, all for the purpose of enabling humans to direct the operations of the machines to solve our problems. We have not yet reached the day when we can describe our needs in human languages, but many attempts are made to delineate new communication protocols for the implementation of complex computations. With the Internet growing more massive with every second and more human needs touched by technological requirements every day, we definitely need to develop ever more sophisticated ways to manage this data. Existing research that attempts to ease specification of information systems include several examples that approach the problem by delineating new XML based modeling languages, and in more recent work, RDF and OWL languages. In [Ortiz Cornejo, et. al] they describe their use of WSML (Web Site Modeling Language) and WAML (Web Application Markup Language) which declare properties of the various components and tasks required to implement a web information system, from which code is generated for a functional system. Investigations into ways to enable the Semantic Web, which envisions that promise of a web where the machines can do more work for us, have mostly covered the ground of pre defining ontologies of terminologies and types, in the hope that all information and search needs can be anticipated and foundations and templates laid down ahead of time. As it often turns out, peoples' needs shift and they are not fully aware of what they need until they are in the midst of a project. Also the process of crafting ontologies is an intensive, expensive and exclusive operation with gatekeepers basically controlling the establishment of types. Thus users at large do not have enough of a voice in defining what is important to be included in our conceptual systems.

5 Some approaches examine how ideas like tagging might aid in annotating data types and improve search. In [Andreas Heß, Christian Maaß and Francis Dierick] they discuss the need for automating and aiding the bottom up approach to data annotation using machine learning techniques so that consistent tagging systems are established. Others have attempted to create resources such as meta metadata wrapper types which are coded by developers as tools to enable other users to take in and mash up myriad external data sources. Once wrapped, they present predictable and unified interfaces. These techniques serve as a band aid to shore up the creation of patchwork systems that are somewhat searchable and manageable, but they do not look ahead enough to how we might really ensure semantic meaning beyond one off tag hits or accepting the existing metadata provided by information sources. We would like to create our system so that structural information is an inherent and continually tracking part of data as it is input into the system. Properties can be attached to many different aspects of the graph database to aid in future analysis of the relationships between types and track how they evolve and settle into 'canonical types' over time rather than trying to guarantee understanding of them up front. Even if such settling may be discovered, our system should continue to be flexible and adaptable to variations in peoples' needs and use cases. With more meta structural information carried along, we may someday be able to recognize and grade probabilistic matches in data types to give a little more, albeit fuzzy, information than is explicitly declared. Goals Our goal is to design something that can adapt to whatever data the user provides. The existing systems requires the users to specify what kind of data they want to store in a database. Based on that, the database schema is designed. Whenever a user wants to add additional fields to the data, the schema of the database has to be updated to store the new format manually. The advantage of our approach is that it lets users not specify what type of data they want to store. They just enter the data and ignore the other details. This is possible by making changes to the database schema on the fly every time a new type of data is encountered automatically. The disadvantage is that there will not be any strict ordering of data. In traditional relational database systems, tables are used to describe the schema and data is stored in the tables created for that data. Since we make changes to the schema automatically, the data in our approach may not be organized. For example, if a user wants to store a list of movies she wants to watch. She enters the movie details and stores the data. The next time she enters

6 some other movie details and forgets to add a particular field or adds an extra field. Now, the schema may be updated to store this new kind of data or it is not stored in the place where the previous movies were stored. The other hypothesis is to take the best of both worlds i.e, traditional RDBS and the approach we are taking. Since the core problem we are solving is updating the schema automatically, we can create some rules to identify the type of data to be stored. For example, if the user stores a list of movies, based on the key name like actors etc., the system identifies it as a movie. The same thing applies for books and music by identifying the keys like author, composer, tracklist etc. Built into our tool will be rules for organizing the data, parsing the incoming data, and identifying the type of data. It will then store the data in the correct place just like traditional relational database tables. This approach helps also in searching the data very easily. Methodology The flexibility to change the database at any time without manual work specific to the required change is achieved by a) using a graph database instead of a relational database and b) generating code to make the appropriate modifications. Modifications to the graph include adding or removing nodes, relationships, properties or labels. Front End Interface In keeping with the goal of developing tools for laypeople, we will be developing a user interface for the user to manage their database and submit new data. The creation and modification of the database will be done by example, no formal schema or abstracted description is required. The user will also be able to view a representation of the current state of their database. The records created by the user will be stored in JSON format and handed off to the back end for processing. Back End Logic Because JSON allows types and nesting, we need a parser to generate the right code for a given type, and a given situation. The back end will have a JSON scanner and parser which process the incoming data and builds a parse tree. The scanning, parsing and tree building will be done using the compiler

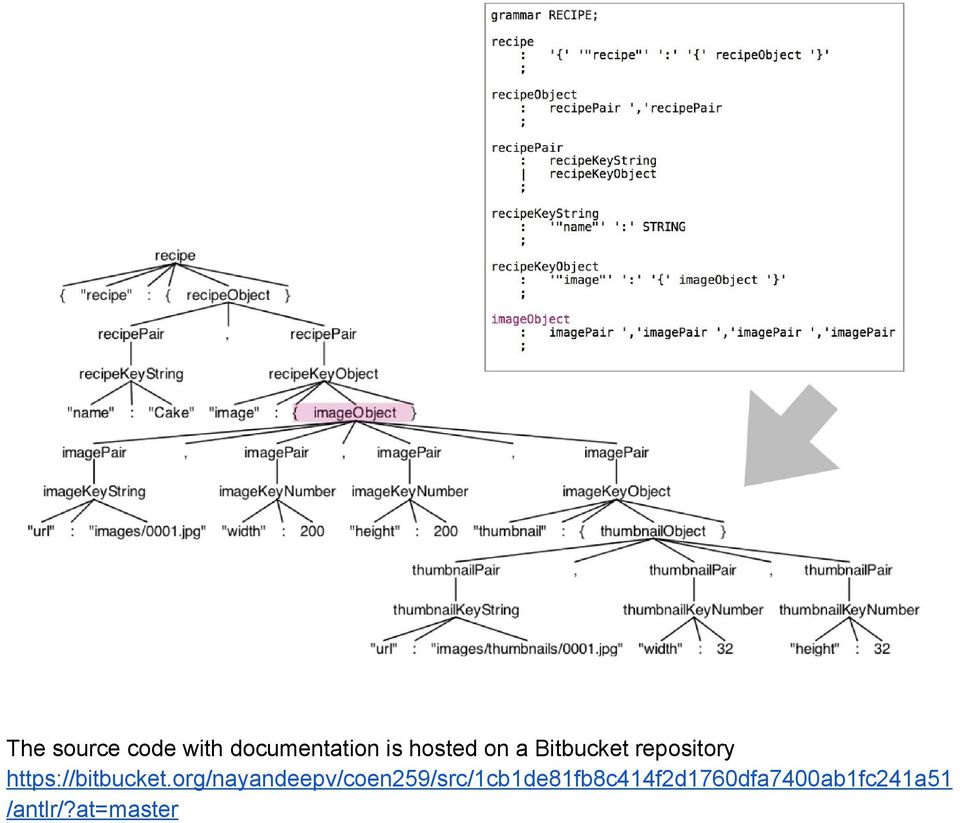
7 generator ANTLR. ANTLR uses a parsing technology developed by Terence Parr (the creator of ANTLR) called Adaptive LL(*). It is a recursive descent parser with the added ability to parse non left recursive grammar (Parr 2014). The parse tree contains the data submitted by the user, and will be used to translate the data into code that updates the database. The code generation will be implemented by extending the ANTLR generated tree walking mechanism called a listener, which is implemented in Java. Visiting nodes of the tree triggers the actions we specified in the listener. For example, upon encountering a certain key value pair, we may want to generate a node in the database, and so we determine the appropriate query given the data. The actions we want to take to modify the database require knowledge of the state and structure of the database. For example, if a user submits a record in which all the corresponding node types already exist in the graph, except for one key value pair, the code generated should create that node and do nothing for the rest. The structure of the data dictates the structure of the resulting graph, therefore we can create graphs by example instead of by a formal schema. Neo4j graphs have nodes which can have labels and properties. Graphs also have relationships which organize the nodes. JSON may consist of an object with string value pairs, and/or arrays which are lists of values. The value can be a string, number, object, array, true, false or null. Our application will provide the appropriate mapping, as well as the appropriate actions to take given the particular data submitted.

8 Implementation The project requires the following packages installed on a linux machine : openjdk or Oracle JDK ANTLR Neo4j server PHP Setting the classpath for ANTLR and generating parser for JSON files: $ export CLASSPATH=.:./antlr 4.5 complete.jar $ java jar./antlr 4.5 complete.jar JSON.g4 ANTLR generated the Parser and Lexer for JSON grammar declared in JSON.g4. $ javac *.java The above command compiles all the files created by ANTLR. The Source code is organized as follows. It is written in Java Source Folder: coen259/antlr Contains Grammar generation code coen259/antlr/processingincomingjson.sh Generates new grammar by parsing the JSON file given by the user. coen259/neo4j Contains the neo4j server jar files coen259/www Contains the php code and HTML files for the users to enter data. Grammar Generation Implementation: The grammar generation for new json objects is implemented in Grammargen.java The java code to insert data into the database is present in QueryGen.java The following are the steps involved. The json file is given as an argument to the shell script file. It generates a new grammar for it and uses ANTLR to generate the Lexer and Parser for the file. If a new type of data comes, it generates the grammar for it and compares with the existing ones to check if it is a data type already stored in the database or a new kind of data. It returns valid if a grammar exists for the data, otherwise it stores the new grammar generated and keeps track of it from the next time.

9 Flow chart :


10 Data analysis and discussion Output generation : Store data By using QueryGen, the code to store the data is generated. It takes the json file we need to compile as the first argument and the name of the java file to save the generated code to store the data. $ java QueryGen movies.json MovieClass.java Generate grammar for new data objects The following commands need to be run only for the first time. $ chmod a+x processincomingjson.sh $ java jar./antlr 4.5 complete.jar ALTJSON.g4 $ javac ALTJSON*.java $ javac NewJsonTool.java $ javac GrammarGen.java The shell script processingincomingjson generates a new grammar for the incoming data objects using ANTLR. It takes a new json file as an argument. $./processincomingjson movies.json

11 If the json has never been seen before, it will create a new dir called book gen You can create new json files that have a different filename but same value for the first pair (ie book). $./processincomingjson BadMovie.json If it doesn't have the same fields etc as the first movie, it will be found to be invalid. If it does, it will be found valid. $./processincomingjson GoodMovie.json We can open movies.g4 to check the grammar generated by the script. This grammar can be used to compare if the data object already exists or it is something new. If it is something new, the data type is stored and recognized from the next time. The compiling of JSON files helps users not specify what type of data to be stored. This is possible by generating grammar for various kinds of data objects and comparing with the existing ones to see if the data is a mere update to existing data or a new kind of data. For example, if the user stores a list of movies, based on the key name like actors etc., the system identifies it as a movie. The same thing applies for books and music by identifying the keys like author, composer, tracklist etc. In the abnormal cases, this approach may take a lot of time to store data into the database when compared to the current approaches. This is because, we need to check what kind of data to be inserted by generating the grammar and then comparing it with the existing ones. Even for updating the existing data, it may take a lot of time which is not acceptable for common end users. Also, it becomes very difficult to track if the data is overwritten by new data because the new data is not organized and if there are any typos made by the end users, the data is stored as new data. The grammar generated for various data types must be stored in an external server and backups have to be taken very frequently. Otherwise, if the grammar cannot be fetched, the programs treat it as a new data object and stores it in the database. This creates a lot of issues like validity of the grammar i.e which one is the correct type of grammar and which one is incorrect. Conclusion We conclude that dynamically creating APIs for new and modified data objects by compiling JSON fastens application development process. This approach also eliminates the redundancy of writing JSON parsing code in various languages especially when the application is being developed for various platforms.

12 We have seen that it works only when we use Neo4j database to store the data. We can check if we can somehow try other traditional RDBMS databases like MySQL etc., in the future. However, our approach can be used to write new data to any kind of database with little modification. Bibliography Heß, A., Maaß, C., and Dierick, F. From Web 2.0 to Semantic Web: A Semi Automated Approach. Lycos Europe GmbH, G ütersloh, Germany; Kerne, A., Qu, Y., Webb, A. M., Damaraju, S., Lupfer, N., Mathur, A. Meta Metadata: A Metadata Semantics Language for Collection Representation Applications. CIKM 10, October 26 30, 2010, Toronto, Ontario, Canada; Ortiz Cornejo, A. I., Cuayáhuitl, H., and Perez Corona, C. WISBuilder: A Framework for Facilitating Development of Web Based Information Systems. Proceedings of the 16th IEEE International Conference on Electronics, Communications and Computers (CONIELECOMP 2006). Parr, T., Fisher, K., and Harwell, S. Adaptive LL(*) Parsing: The Power of Dynamic Analysis. OOPSLA 2014, Portland, Oregon; 10/2014. Sarasa Cabezuelo, A. and Sierra, J. Grammar Driven Development of JSON Processing Applications. Proceedings of the 2013 Federated Conference on Computer Science and Information Systems pp ; Stuckenschmidt, H. Compiling Complex Terminologies for Efficient Query Answering on the Semantic Web. ACM WWW2003, May 20 24, 2003, Budapest, Hungary. Appendices The Grammar generation flow chart

13

14 The source code with documentation is hosted on a Bitbucket repository /antlr/?at=master
An Eclipse Plug-In for Visualizing Java Code Dependencies on Relational Databases
 An Eclipse Plug-In for Visualizing Java Code Dependencies on Relational Databases Paul L. Bergstein, Priyanka Gariba, Vaibhavi Pisolkar, and Sheetal Subbanwad Dept. of Computer and Information Science,
An Eclipse Plug-In for Visualizing Java Code Dependencies on Relational Databases Paul L. Bergstein, Priyanka Gariba, Vaibhavi Pisolkar, and Sheetal Subbanwad Dept. of Computer and Information Science,
Lightweight Data Integration using the WebComposition Data Grid Service
 Lightweight Data Integration using the WebComposition Data Grid Service Ralph Sommermeier 1, Andreas Heil 2, Martin Gaedke 1 1 Chemnitz University of Technology, Faculty of Computer Science, Distributed
Lightweight Data Integration using the WebComposition Data Grid Service Ralph Sommermeier 1, Andreas Heil 2, Martin Gaedke 1 1 Chemnitz University of Technology, Faculty of Computer Science, Distributed
Firewall Builder Architecture Overview
 Firewall Builder Architecture Overview Vadim Zaliva Vadim Kurland Abstract This document gives brief, high level overview of existing Firewall Builder architecture.
Firewall Builder Architecture Overview Vadim Zaliva Vadim Kurland Abstract This document gives brief, high level overview of existing Firewall Builder architecture.
DIABLO VALLEY COLLEGE CATALOG 2014-2015
 COMPUTER SCIENCE COMSC The computer science department offers courses in three general areas, each targeted to serve students with specific needs: 1. General education students seeking a computer literacy
COMPUTER SCIENCE COMSC The computer science department offers courses in three general areas, each targeted to serve students with specific needs: 1. General education students seeking a computer literacy
So today we shall continue our discussion on the search engines and web crawlers. (Refer Slide Time: 01:02)
") Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Oracle SQL Developer for Database Developers. An Oracle White Paper June 2007
 Oracle SQL Developer for Database Developers An Oracle White Paper June 2007 Oracle SQL Developer for Database Developers Introduction...3 Audience...3 Key Benefits...3 Architecture...4 Key Features...4
Oracle SQL Developer for Database Developers An Oracle White Paper June 2007 Oracle SQL Developer for Database Developers Introduction...3 Audience...3 Key Benefits...3 Architecture...4 Key Features...4
Introduction to XML Applications
 EMC White Paper Introduction to XML Applications Umair Nauman Abstract: This document provides an overview of XML Applications. This is not a comprehensive guide to XML Applications and is intended for
EMC White Paper Introduction to XML Applications Umair Nauman Abstract: This document provides an overview of XML Applications. This is not a comprehensive guide to XML Applications and is intended for
Chapter 1: Introduction
 Chapter 1: Introduction Database System Concepts, 5th Ed. See www.db book.com for conditions on re use Chapter 1: Introduction Purpose of Database Systems View of Data Database Languages Relational Databases
Chapter 1: Introduction Database System Concepts, 5th Ed. See www.db book.com for conditions on re use Chapter 1: Introduction Purpose of Database Systems View of Data Database Languages Relational Databases
How to Design and Create Your Own Custom Ext Rep
 Combinatorial Block Designs 2009-04-15 Outline Project Intro External Representation Design Database System Deployment System Overview Conclusions 1. Since the project is a specific application in Combinatorial
Combinatorial Block Designs 2009-04-15 Outline Project Intro External Representation Design Database System Deployment System Overview Conclusions 1. Since the project is a specific application in Combinatorial
ONTOLOGY-BASED MULTIMEDIA AUTHORING AND INTERFACING TOOLS 3 rd Hellenic Conference on Artificial Intelligence, Samos, Greece, 5-8 May 2004
 ONTOLOGY-BASED MULTIMEDIA AUTHORING AND INTERFACING TOOLS 3 rd Hellenic Conference on Artificial Intelligence, Samos, Greece, 5-8 May 2004 By Aristomenis Macris (e-mail: arism@unipi.gr), University of
ONTOLOGY-BASED MULTIMEDIA AUTHORING AND INTERFACING TOOLS 3 rd Hellenic Conference on Artificial Intelligence, Samos, Greece, 5-8 May 2004 By Aristomenis Macris (e-mail: arism@unipi.gr), University of
Zoomer: An Automated Web Application Change Localization Tool
 Journal of Communication and Computer 9 (2012) 913-919 D DAVID PUBLISHING Zoomer: An Automated Web Application Change Localization Tool Wenhua Wang 1 and Yu Lei 2 1. Marin Software Company, San Francisco,
Journal of Communication and Computer 9 (2012) 913-919 D DAVID PUBLISHING Zoomer: An Automated Web Application Change Localization Tool Wenhua Wang 1 and Yu Lei 2 1. Marin Software Company, San Francisco,
Automatic Text Analysis Using Drupal
 Automatic Text Analysis Using Drupal By Herman Chai Computer Engineering California Polytechnic State University, San Luis Obispo Advised by Dr. Foaad Khosmood June 14, 2013 Abstract Natural language processing
Automatic Text Analysis Using Drupal By Herman Chai Computer Engineering California Polytechnic State University, San Luis Obispo Advised by Dr. Foaad Khosmood June 14, 2013 Abstract Natural language processing
Oracle SQL Developer for Database Developers. An Oracle White Paper September 2008
 Oracle SQL Developer for Database Developers An Oracle White Paper September 2008 Oracle SQL Developer for Database Developers Introduction...3 Audience...3 Key Benefits...3 Architecture...4 Key Features...4
Oracle SQL Developer for Database Developers An Oracle White Paper September 2008 Oracle SQL Developer for Database Developers Introduction...3 Audience...3 Key Benefits...3 Architecture...4 Key Features...4
WIRIS quizzes web services Getting started with PHP and Java
 WIRIS quizzes web services Getting started with PHP and Java Document Release: 1.3 2011 march, Maths for More www.wiris.com Summary This document provides client examples for PHP and Java. Contents WIRIS
WIRIS quizzes web services Getting started with PHP and Java Document Release: 1.3 2011 march, Maths for More www.wiris.com Summary This document provides client examples for PHP and Java. Contents WIRIS
Annotation for the Semantic Web during Website Development
 Annotation for the Semantic Web during Website Development Peter Plessers, Olga De Troyer Vrije Universiteit Brussel, Department of Computer Science, WISE, Pleinlaan 2, 1050 Brussel, Belgium {Peter.Plessers,
Annotation for the Semantic Web during Website Development Peter Plessers, Olga De Troyer Vrije Universiteit Brussel, Department of Computer Science, WISE, Pleinlaan 2, 1050 Brussel, Belgium {Peter.Plessers,
Integrating VoltDB with Hadoop
 The NewSQL database you ll never outgrow Integrating with Hadoop Hadoop is an open source framework for managing and manipulating massive volumes of data. is an database for handling high velocity data.
The NewSQL database you ll never outgrow Integrating with Hadoop Hadoop is an open source framework for managing and manipulating massive volumes of data. is an database for handling high velocity data.
Using Database Metadata and its Semantics to Generate Automatic and Dynamic Web Entry Forms
 Using Database Metadata and its Semantics to Generate Automatic and Dynamic Web Entry Forms Mohammed M. Elsheh and Mick J. Ridley Abstract Automatic and dynamic generation of Web applications is the future
Using Database Metadata and its Semantics to Generate Automatic and Dynamic Web Entry Forms Mohammed M. Elsheh and Mick J. Ridley Abstract Automatic and dynamic generation of Web applications is the future
Software Package Document exchange (SPDX ) Tools. Version 1.2. Copyright 2011-2014 The Linux Foundation. All other rights are expressly reserved.
 Tools. Version 1.2. Copyright 2011-2014 The Linux Foundation. All other rights are expressly reserved.") Software Package Document exchange (SPDX ) Tools Version 1.2 This document last updated March 18, 2014. Please send your comments and suggestions for this document to: spdx-tech@fossbazzar.org Copyright
Software Package Document exchange (SPDX ) Tools Version 1.2 This document last updated March 18, 2014. Please send your comments and suggestions for this document to: spdx-tech@fossbazzar.org Copyright
D3.3.1: Sematic tagging and open data publication tools
 COMPETITIVINESS AND INNOVATION FRAMEWORK PROGRAMME CIP-ICT-PSP-2013-7 Pilot Type B WP3 Service platform integration and deployment in cloud infrastructure D3.3.1: Sematic tagging and open data publication
COMPETITIVINESS AND INNOVATION FRAMEWORK PROGRAMME CIP-ICT-PSP-2013-7 Pilot Type B WP3 Service platform integration and deployment in cloud infrastructure D3.3.1: Sematic tagging and open data publication
Adam Rauch Partner, LabKey Software adam@labkey.com. Extending LabKey Server Part 1: Retrieving and Presenting Data
 Adam Rauch Partner, LabKey Software adam@labkey.com Extending LabKey Server Part 1: Retrieving and Presenting Data Extending LabKey Server LabKey Server is a large system that combines an extensive set
Adam Rauch Partner, LabKey Software adam@labkey.com Extending LabKey Server Part 1: Retrieving and Presenting Data Extending LabKey Server LabKey Server is a large system that combines an extensive set
Enforcing Data Quality Rules for a Synchronized VM Log Audit Environment Using Transformation Mapping Techniques
 Enforcing Data Quality Rules for a Synchronized VM Log Audit Environment Using Transformation Mapping Techniques Sean Thorpe 1, Indrajit Ray 2, and Tyrone Grandison 3 1 Faculty of Engineering and Computing,
Enforcing Data Quality Rules for a Synchronized VM Log Audit Environment Using Transformation Mapping Techniques Sean Thorpe 1, Indrajit Ray 2, and Tyrone Grandison 3 1 Faculty of Engineering and Computing,
estatistik.core: COLLECTING RAW DATA FROM ERP SYSTEMS
 WP. 2 ENGLISH ONLY UNITED NATIONS STATISTICAL COMMISSION and ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS Work Session on Statistical Data Editing (Bonn, Germany, 25-27 September
WP. 2 ENGLISH ONLY UNITED NATIONS STATISTICAL COMMISSION and ECONOMIC COMMISSION FOR EUROPE CONFERENCE OF EUROPEAN STATISTICIANS Work Session on Statistical Data Editing (Bonn, Germany, 25-27 September
An Ontology-based e-learning System for Network Security
 An Ontology-based e-learning System for Network Security Yoshihito Takahashi, Tomomi Abiko, Eriko Negishi Sendai National College of Technology a0432@ccedu.sendai-ct.ac.jp Goichi Itabashi Graduate School
An Ontology-based e-learning System for Network Security Yoshihito Takahashi, Tomomi Abiko, Eriko Negishi Sendai National College of Technology a0432@ccedu.sendai-ct.ac.jp Goichi Itabashi Graduate School
Relational Database Basics Review
 Relational Database Basics Review IT 4153 Advanced Database J.G. Zheng Spring 2012 Overview Database approach Database system Relational model Database development 2 File Processing Approaches Based on
Relational Database Basics Review IT 4153 Advanced Database J.G. Zheng Spring 2012 Overview Database approach Database system Relational model Database development 2 File Processing Approaches Based on
Software Design April 26, 2013
 Software Design April 26, 2013 1. Introduction 1.1.1. Purpose of This Document This document provides a high level description of the design and implementation of Cypress, an open source certification
Software Design April 26, 2013 1. Introduction 1.1.1. Purpose of This Document This document provides a high level description of the design and implementation of Cypress, an open source certification
What is a database? COSC 304 Introduction to Database Systems. Database Introduction. Example Problem. Databases in the Real-World
 COSC 304 Introduction to Systems Introduction Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca What is a database? A database is a collection of logically related data for
COSC 304 Introduction to Systems Introduction Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca What is a database? A database is a collection of logically related data for
XML: ITS ROLE IN TCP/IP PRESENTATION LAYER (LAYER 6)
") 51-40-05 DATA COMMUNICATIONS MANAGEMENT XML: ITS ROLE IN TCP/IP PRESENTATION LAYER (LAYER 6) Judith Myerson INSIDE Breaking the Barrier; Product Integration; Translation for All Browsers; Dynamic XML Servers;
51-40-05 DATA COMMUNICATIONS MANAGEMENT XML: ITS ROLE IN TCP/IP PRESENTATION LAYER (LAYER 6) Judith Myerson INSIDE Breaking the Barrier; Product Integration; Translation for All Browsers; Dynamic XML Servers;
Explorer's Guide to the Semantic Web
 Explorer's Guide to the Semantic Web THOMAS B. PASSIN 11 MANNING Greenwich (74 w. long.) contents preface xiii acknowledgments xv about this booh xvii The Semantic Web 1 1.1 What is the Semantic Web? 3
Explorer's Guide to the Semantic Web THOMAS B. PASSIN 11 MANNING Greenwich (74 w. long.) contents preface xiii acknowledgments xv about this booh xvii The Semantic Web 1 1.1 What is the Semantic Web? 3
II. PREVIOUS RELATED WORK
 An extended rule framework for web forms: adding to metadata with custom rules to control appearance Atia M. Albhbah and Mick J. Ridley Abstract This paper proposes the use of rules that involve code to
An extended rule framework for web forms: adding to metadata with custom rules to control appearance Atia M. Albhbah and Mick J. Ridley Abstract This paper proposes the use of rules that involve code to
Graph-Based Linking and Visualization for Legislation Documents (GLVD) Dincer Gultemen & Tom van Engers
 Dincer Gultemen & Tom van Engers") Graph-Based Linking and Visualization for Legislation Documents (GLVD) Dincer Gultemen & Tom van Engers Demand of Parliaments Semi-structured information and semantic technologies Inter-institutional business
Graph-Based Linking and Visualization for Legislation Documents (GLVD) Dincer Gultemen & Tom van Engers Demand of Parliaments Semi-structured information and semantic technologies Inter-institutional business
Using WebLOAD to Monitor Your Production Environment
 Using WebLOAD to Monitor Your Production Environment Your pre launch performance test scripts can be reused for post launch monitoring to verify application performance. This reuse can save time, money
Using WebLOAD to Monitor Your Production Environment Your pre launch performance test scripts can be reused for post launch monitoring to verify application performance. This reuse can save time, money
YouTrack MPS case study
 YouTrack MPS case study A case study of JetBrains YouTrack use of MPS Valeria Adrianova, Maxim Mazin, Václav Pech What is YouTrack YouTrack is an innovative, web-based, keyboard-centric issue and project
YouTrack MPS case study A case study of JetBrains YouTrack use of MPS Valeria Adrianova, Maxim Mazin, Václav Pech What is YouTrack YouTrack is an innovative, web-based, keyboard-centric issue and project
How semantic technology can help you do more with production data. Doing more with production data
 How semantic technology can help you do more with production data Doing more with production data EPIM and Digital Energy Journal 2013-04-18 David Price, TopQuadrant London, UK dprice at topquadrant dot
How semantic technology can help you do more with production data Doing more with production data EPIM and Digital Energy Journal 2013-04-18 David Price, TopQuadrant London, UK dprice at topquadrant dot
Understanding Infrastructure as Code. By Michael Wittig and Andreas Wittig
 Understanding Infrastructure as Code By Michael Wittig and Andreas Wittig In this article, excerpted from Amazon Web Service in Action, we will explain Infrastructure as Code. Infrastructure as Code describes
Understanding Infrastructure as Code By Michael Wittig and Andreas Wittig In this article, excerpted from Amazon Web Service in Action, we will explain Infrastructure as Code. Infrastructure as Code describes
Implementing Ontology-based Information Sharing in Product Lifecycle Management
 Implementing Ontology-based Information Sharing in Product Lifecycle Management Dillon McKenzie-Veal, Nathan W. Hartman, and John Springer College of Technology, Purdue University, West Lafayette, Indiana
Implementing Ontology-based Information Sharing in Product Lifecycle Management Dillon McKenzie-Veal, Nathan W. Hartman, and John Springer College of Technology, Purdue University, West Lafayette, Indiana
FileMaker 11. ODBC and JDBC Guide
 FileMaker 11 ODBC and JDBC Guide 2004 2010 FileMaker, Inc. All Rights Reserved. FileMaker, Inc. 5201 Patrick Henry Drive Santa Clara, California 95054 FileMaker is a trademark of FileMaker, Inc. registered
FileMaker 11 ODBC and JDBC Guide 2004 2010 FileMaker, Inc. All Rights Reserved. FileMaker, Inc. 5201 Patrick Henry Drive Santa Clara, California 95054 FileMaker is a trademark of FileMaker, Inc. registered
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.035, Fall 2005 Handout 7 Scanner Parser Project Wednesday, September 7 DUE: Wednesday, September 21 This
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.035, Fall 2005 Handout 7 Scanner Parser Project Wednesday, September 7 DUE: Wednesday, September 21 This
NoSQL and Agility. Why Document and Graph Stores Rock November 12th, 2015 COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED
 NoSQL and Agility Why Document and Graph Stores Rock November 12th, 2015 COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED Description We have all heard about how NoSQL databases are being adopted
NoSQL and Agility Why Document and Graph Stores Rock November 12th, 2015 COPYRIGHT 2015 MARKLOGIC CORPORATION. ALL RIGHTS RESERVED Description We have all heard about how NoSQL databases are being adopted
XpoLog Center Suite Log Management & Analysis platform
 XpoLog Center Suite Log Management & Analysis platform Summary: 1. End to End data management collects and indexes data in any format from any machine / device in the environment. 2. Logs Monitoring -
XpoLog Center Suite Log Management & Analysis platform Summary: 1. End to End data management collects and indexes data in any format from any machine / device in the environment. 2. Logs Monitoring -
10CS73:Web Programming
 10CS73:Web Programming Question Bank Fundamentals of Web: 1.What is WWW? 2. What are domain names? Explain domain name conversion with diagram 3.What are the difference between web browser and web server
10CS73:Web Programming Question Bank Fundamentals of Web: 1.What is WWW? 2. What are domain names? Explain domain name conversion with diagram 3.What are the difference between web browser and web server
Secure Semantic Web Service Using SAML
 Secure Semantic Web Service Using SAML JOO-YOUNG LEE and KI-YOUNG MOON Information Security Department Electronics and Telecommunications Research Institute 161 Gajeong-dong, Yuseong-gu, Daejeon KOREA
Secure Semantic Web Service Using SAML JOO-YOUNG LEE and KI-YOUNG MOON Information Security Department Electronics and Telecommunications Research Institute 161 Gajeong-dong, Yuseong-gu, Daejeon KOREA
Designing a Semantic Repository
 Designing a Semantic Repository Integrating architectures for reuse and integration Overview Cory Casanave Cory-c (at) modeldriven.org ModelDriven.org May 2007 The Semantic Metadata infrastructure will
Designing a Semantic Repository Integrating architectures for reuse and integration Overview Cory Casanave Cory-c (at) modeldriven.org ModelDriven.org May 2007 The Semantic Metadata infrastructure will
Parsing Technology and its role in Legacy Modernization. A Metaware White Paper
 Parsing Technology and its role in Legacy Modernization A Metaware White Paper 1 INTRODUCTION In the two last decades there has been an explosion of interest in software tools that can automate key tasks
Parsing Technology and its role in Legacy Modernization A Metaware White Paper 1 INTRODUCTION In the two last decades there has been an explosion of interest in software tools that can automate key tasks
Combining SAWSDL, OWL DL and UDDI for Semantically Enhanced Web Service Discovery
 Combining SAWSDL, OWL DL and UDDI for Semantically Enhanced Web Service Discovery Dimitrios Kourtesis, Iraklis Paraskakis SEERC South East European Research Centre, Greece Research centre of the University
Combining SAWSDL, OWL DL and UDDI for Semantically Enhanced Web Service Discovery Dimitrios Kourtesis, Iraklis Paraskakis SEERC South East European Research Centre, Greece Research centre of the University
Novel Data Extraction Language for Structured Log Analysis
 Novel Data Extraction Language for Structured Log Analysis P.W.D.C. Jayathilake 99X Technology, Sri Lanka. ABSTRACT This paper presents the implementation of a new log data extraction language. Theoretical
Novel Data Extraction Language for Structured Log Analysis P.W.D.C. Jayathilake 99X Technology, Sri Lanka. ABSTRACT This paper presents the implementation of a new log data extraction language. Theoretical
Introduction to Database Systems
 Introduction to Database Systems A database is a collection of related data. It is a collection of information that exists over a long period of time, often many years. The common use of the term database
Introduction to Database Systems A database is a collection of related data. It is a collection of information that exists over a long period of time, often many years. The common use of the term database
Simplifying e Business Collaboration by providing a Semantic Mapping Platform
 Simplifying e Business Collaboration by providing a Semantic Mapping Platform Abels, Sven 1 ; Sheikhhasan Hamzeh 1 ; Cranner, Paul 2 1 TIE Nederland BV, 1119 PS Amsterdam, Netherlands 2 University of Sunderland,
Simplifying e Business Collaboration by providing a Semantic Mapping Platform Abels, Sven 1 ; Sheikhhasan Hamzeh 1 ; Cranner, Paul 2 1 TIE Nederland BV, 1119 PS Amsterdam, Netherlands 2 University of Sunderland,
Scope. Cognescent SBI Semantic Business Intelligence
 Cognescent SBI Semantic Business Intelligence Scope...1 Conceptual Diagram...2 Datasources...3 Core Concepts...3 Resources...3 Occurrence (SPO)...4 Links...4 Statements...4 Rules...4 Types...4 Mappings...5
Cognescent SBI Semantic Business Intelligence Scope...1 Conceptual Diagram...2 Datasources...3 Core Concepts...3 Resources...3 Occurrence (SPO)...4 Links...4 Statements...4 Rules...4 Types...4 Mappings...5
Semantic Web Services for e-learning: Engineering and Technology Domain
 Web s for e-learning: Engineering and Technology Domain Krupali Shah and Jayant Gadge Abstract E learning has gained its importance over the traditional classroom learning techniques in past few decades.
Web s for e-learning: Engineering and Technology Domain Krupali Shah and Jayant Gadge Abstract E learning has gained its importance over the traditional classroom learning techniques in past few decades.
CAMDIT: A Toolkit for Integrating Heterogeneous Medical Data for improved Health Care Service Provisioning
 CAMDIT: A Toolkit for Integrating Heterogeneous Medical Data for improved Health Care Service Provisioning 1 Ipadeola Abayomi, 2 Ahmed Ameen Department of Computer Science University of Ilorin, Kwara State.
CAMDIT: A Toolkit for Integrating Heterogeneous Medical Data for improved Health Care Service Provisioning 1 Ipadeola Abayomi, 2 Ahmed Ameen Department of Computer Science University of Ilorin, Kwara State.
Drupal CMS for marketing sites
 Drupal CMS for marketing sites Intro Sample sites: End to End flow Folder Structure Project setup Content Folder Data Store (Drupal CMS) Importing/Exporting Content Database Migrations Backend Config Unit
Drupal CMS for marketing sites Intro Sample sites: End to End flow Folder Structure Project setup Content Folder Data Store (Drupal CMS) Importing/Exporting Content Database Migrations Backend Config Unit
An Ontology Model for Organizing Information Resources Sharing on Personal Web
 An Ontology Model for Organizing Information Resources Sharing on Personal Web Istiadi 1, and Azhari SN 2 1 Department of Electrical Engineering, University of Widyagama Malang, Jalan Borobudur 35, Malang
An Ontology Model for Organizing Information Resources Sharing on Personal Web Istiadi 1, and Azhari SN 2 1 Department of Electrical Engineering, University of Widyagama Malang, Jalan Borobudur 35, Malang
SQLMutation: A tool to generate mutants of SQL database queries
 SQLMutation: A tool to generate mutants of SQL database queries Javier Tuya, Mª José Suárez-Cabal, Claudio de la Riva University of Oviedo (SPAIN) {tuya cabal claudio} @ uniovi.es Abstract We present a
SQLMutation: A tool to generate mutants of SQL database queries Javier Tuya, Mª José Suárez-Cabal, Claudio de la Riva University of Oviedo (SPAIN) {tuya cabal claudio} @ uniovi.es Abstract We present a
THE SEMANTIC WEB AND IT`S APPLICATIONS
 15-16 September 2011, BULGARIA 1 Proceedings of the International Conference on Information Technologies (InfoTech-2011) 15-16 September 2011, Bulgaria THE SEMANTIC WEB AND IT`S APPLICATIONS Dimitar Vuldzhev
15-16 September 2011, BULGARIA 1 Proceedings of the International Conference on Information Technologies (InfoTech-2011) 15-16 September 2011, Bulgaria THE SEMANTIC WEB AND IT`S APPLICATIONS Dimitar Vuldzhev
Oct 15, 2004 www.dcs.bbk.ac.uk/~gmagoulas/teaching.html 3. Internet : the vast collection of interconnected networks that all use the TCP/IP protocols
 E-Commerce Infrastructure II: the World Wide Web The Internet and the World Wide Web are two separate but related things Oct 15, 2004 www.dcs.bbk.ac.uk/~gmagoulas/teaching.html 1 Outline The Internet and
E-Commerce Infrastructure II: the World Wide Web The Internet and the World Wide Web are two separate but related things Oct 15, 2004 www.dcs.bbk.ac.uk/~gmagoulas/teaching.html 1 Outline The Internet and
Linked Data Interface, Semantics and a T-Box Triple Store for Microsoft SharePoint
 Linked Data Interface, Semantics and a T-Box Triple Store for Microsoft SharePoint Christian Fillies 1 and Frauke Weichhardt 1 1 Semtation GmbH, Geschw.-Scholl-Str. 38, 14771 Potsdam, Germany {cfillies,
Linked Data Interface, Semantics and a T-Box Triple Store for Microsoft SharePoint Christian Fillies 1 and Frauke Weichhardt 1 1 Semtation GmbH, Geschw.-Scholl-Str. 38, 14771 Potsdam, Germany {cfillies,
Command Line Interface Specification Linux Mac
 Command Line Interface Specification Linux Mac Online Backup Client version 4.1.x and higher 1. Introduction These modifications make it possible to access the BackupAgent Client software from the command
Command Line Interface Specification Linux Mac Online Backup Client version 4.1.x and higher 1. Introduction These modifications make it possible to access the BackupAgent Client software from the command
Pattern Insight Clone Detection
 Pattern Insight Clone Detection TM The fastest, most effective way to discover all similar code segments What is Clone Detection? Pattern Insight Clone Detection is a powerful pattern discovery technology
Pattern Insight Clone Detection TM The fastest, most effective way to discover all similar code segments What is Clone Detection? Pattern Insight Clone Detection is a powerful pattern discovery technology
Pre-authentication XXE vulnerability in the Services Drupal module
 Pre-authentication XXE vulnerability in the Services Drupal module Security advisory 24/04/2015 Renaud Dubourguais www.synacktiv.com 14 rue Mademoiselle 75015 Paris 1. Vulnerability description 1.1. The
Pre-authentication XXE vulnerability in the Services Drupal module Security advisory 24/04/2015 Renaud Dubourguais www.synacktiv.com 14 rue Mademoiselle 75015 Paris 1. Vulnerability description 1.1. The
K@ A collaborative platform for knowledge management
 White Paper K@ A collaborative platform for knowledge management Quinary SpA www.quinary.com via Pietrasanta 14 20141 Milano Italia t +39 02 3090 1500 f +39 02 3090 1501 Copyright 2004 Quinary SpA Index
White Paper K@ A collaborative platform for knowledge management Quinary SpA www.quinary.com via Pietrasanta 14 20141 Milano Italia t +39 02 3090 1500 f +39 02 3090 1501 Copyright 2004 Quinary SpA Index
Short notes on webpage programming languages
 Short notes on webpage programming languages What is HTML? HTML is a language for describing web pages. HTML stands for Hyper Text Markup Language HTML is a markup language A markup language is a set of
Short notes on webpage programming languages What is HTML? HTML is a language for describing web pages. HTML stands for Hyper Text Markup Language HTML is a markup language A markup language is a set of
Sophisticated Indicators for the Modern Threat Landscape: An Introduction to OpenIOC
 WHITE PAPER Sophisticated Indicators for the Modern Threat Landscape: An Introduction to OpenIOC www.openioc.org OpenIOC 1 Table of Contents Introduction... 3 IOCs & OpenIOC... 4 IOC Functionality... 5
WHITE PAPER Sophisticated Indicators for the Modern Threat Landscape: An Introduction to OpenIOC www.openioc.org OpenIOC 1 Table of Contents Introduction... 3 IOCs & OpenIOC... 4 IOC Functionality... 5
REDUCING THE COST OF GROUND SYSTEM DEVELOPMENT AND MISSION OPERATIONS USING AUTOMATED XML TECHNOLOGIES. Jesse Wright Jet Propulsion Laboratory,
 REDUCING THE COST OF GROUND SYSTEM DEVELOPMENT AND MISSION OPERATIONS USING AUTOMATED XML TECHNOLOGIES Colette Wilklow MS 301-240, Pasadena, CA phone + 1 818 354-4674 fax + 1 818 393-4100 email: colette.wilklow@jpl.nasa.gov
REDUCING THE COST OF GROUND SYSTEM DEVELOPMENT AND MISSION OPERATIONS USING AUTOMATED XML TECHNOLOGIES Colette Wilklow MS 301-240, Pasadena, CA phone + 1 818 354-4674 fax + 1 818 393-4100 email: colette.wilklow@jpl.nasa.gov
Federated, Generic Configuration Management for Engineering Data
 Federated, Generic Configuration Management for Engineering Data Dr. Rainer Romatka Boeing GPDIS_2013.ppt 1 Presentation Outline I Summary Introduction Configuration Management Overview CM System Requirements
Federated, Generic Configuration Management for Engineering Data Dr. Rainer Romatka Boeing GPDIS_2013.ppt 1 Presentation Outline I Summary Introduction Configuration Management Overview CM System Requirements
Security Issues for the Semantic Web
 Security Issues for the Semantic Web Dr. Bhavani Thuraisingham Program Director Data and Applications Security The National Science Foundation Arlington, VA On leave from The MITRE Corporation Bedford,
Security Issues for the Semantic Web Dr. Bhavani Thuraisingham Program Director Data and Applications Security The National Science Foundation Arlington, VA On leave from The MITRE Corporation Bedford,
McAfee Network Threat Response (NTR) 4.0
 4.0") McAfee Network Threat Response (NTR) 4.0 Configuring Automated Reporting and Alerting Automated reporting is supported with introduction of NTR 4.0 and designed to send automated reports via existing SMTP
McAfee Network Threat Response (NTR) 4.0 Configuring Automated Reporting and Alerting Automated reporting is supported with introduction of NTR 4.0 and designed to send automated reports via existing SMTP
Combining Static and Dynamic Data in Code Visualization
 Combining Static and Dynamic Data in Code Visualization David Eng Sable Research Group McGill University, Montreal flynn@sable.mcgill.ca ABSTRACT The task of developing, tuning, and debugging compiler
Combining Static and Dynamic Data in Code Visualization David Eng Sable Research Group McGill University, Montreal flynn@sable.mcgill.ca ABSTRACT The task of developing, tuning, and debugging compiler
An Oracle White Paper June 2014. RESTful Web Services for the Oracle Database Cloud - Multitenant Edition
 An Oracle White Paper June 2014 RESTful Web Services for the Oracle Database Cloud - Multitenant Edition 1 Table of Contents Introduction to RESTful Web Services... 3 Architecture of Oracle Database Cloud
An Oracle White Paper June 2014 RESTful Web Services for the Oracle Database Cloud - Multitenant Edition 1 Table of Contents Introduction to RESTful Web Services... 3 Architecture of Oracle Database Cloud
Localizing dynamic websites created from open source content management systems
 Localizing dynamic websites created from open source content management systems memoqfest 2012, May 10, 2012, Budapest Daniel Zielinski Martin Beuster Loctimize GmbH [daniel martin]@loctimize.com www.loctimize.com
Localizing dynamic websites created from open source content management systems memoqfest 2012, May 10, 2012, Budapest Daniel Zielinski Martin Beuster Loctimize GmbH [daniel martin]@loctimize.com www.loctimize.com
XML DATA INTEGRATION SYSTEM
 XML DATA INTEGRATION SYSTEM Abdelsalam Almarimi The Higher Institute of Electronics Engineering Baniwalid, Libya Belgasem_2000@Yahoo.com ABSRACT This paper describes a proposal for a system for XML data
XML DATA INTEGRATION SYSTEM Abdelsalam Almarimi The Higher Institute of Electronics Engineering Baniwalid, Libya Belgasem_2000@Yahoo.com ABSRACT This paper describes a proposal for a system for XML data
Flash. Using Flash to Teach Mathematics. The competition
 Using Flash to Teach Mathematics G. Donald Allen Department of Mathematics Texas A&M University College Station, TX 77843-3368 dallen@math.tamu.edu Flash Flash is the ultra-hot animation tool from Macromedia
Using Flash to Teach Mathematics G. Donald Allen Department of Mathematics Texas A&M University College Station, TX 77843-3368 dallen@math.tamu.edu Flash Flash is the ultra-hot animation tool from Macromedia
A generic approach for data integration using RDF, OWL and XML
 A generic approach for data integration using RDF, OWL and XML Miguel A. Macias-Garcia, Victor J. Sosa-Sosa, and Ivan Lopez-Arevalo Laboratory of Information Technology (LTI) CINVESTAV-TAMAULIPAS Km 6
A generic approach for data integration using RDF, OWL and XML Miguel A. Macias-Garcia, Victor J. Sosa-Sosa, and Ivan Lopez-Arevalo Laboratory of Information Technology (LTI) CINVESTAV-TAMAULIPAS Km 6
Service Oriented Architecture
 Service Oriented Architecture Charlie Abela Department of Artificial Intelligence charlie.abela@um.edu.mt Last Lecture Web Ontology Language Problems? CSA 3210 Service Oriented Architecture 2 Lecture Outline
Service Oriented Architecture Charlie Abela Department of Artificial Intelligence charlie.abela@um.edu.mt Last Lecture Web Ontology Language Problems? CSA 3210 Service Oriented Architecture 2 Lecture Outline
1 File Processing Systems
 COMP 378 Database Systems Notes for Chapter 1 of Database System Concepts Introduction A database management system (DBMS) is a collection of data and an integrated set of programs that access that data.
COMP 378 Database Systems Notes for Chapter 1 of Database System Concepts Introduction A database management system (DBMS) is a collection of data and an integrated set of programs that access that data.
72. Ontology Driven Knowledge Discovery Process: a proposal to integrate Ontology Engineering and KDD
 72. Ontology Driven Knowledge Discovery Process: a proposal to integrate Ontology Engineering and KDD Paulo Gottgtroy Auckland University of Technology Paulo.gottgtroy@aut.ac.nz Abstract This paper is
72. Ontology Driven Knowledge Discovery Process: a proposal to integrate Ontology Engineering and KDD Paulo Gottgtroy Auckland University of Technology Paulo.gottgtroy@aut.ac.nz Abstract This paper is
White Paper. Java versus Ruby Frameworks in Practice STATE OF THE ART SOFTWARE DEVELOPMENT 1
 White Paper Java versus Ruby Frameworks in Practice STATE OF THE ART SOFTWARE DEVELOPMENT 1 INTRODUCTION...3 FRAMEWORKS AND LANGUAGES...3 SECURITY AND UPGRADES...4 Major Upgrades...4 Minor Upgrades...5
White Paper Java versus Ruby Frameworks in Practice STATE OF THE ART SOFTWARE DEVELOPMENT 1 INTRODUCTION...3 FRAMEWORKS AND LANGUAGES...3 SECURITY AND UPGRADES...4 Major Upgrades...4 Minor Upgrades...5
A MEDIATION LAYER FOR HETEROGENEOUS XML SCHEMAS
 A MEDIATION LAYER FOR HETEROGENEOUS XML SCHEMAS Abdelsalam Almarimi 1, Jaroslav Pokorny 2 Abstract This paper describes an approach for mediation of heterogeneous XML schemas. Such an approach is proposed
A MEDIATION LAYER FOR HETEROGENEOUS XML SCHEMAS Abdelsalam Almarimi 1, Jaroslav Pokorny 2 Abstract This paper describes an approach for mediation of heterogeneous XML schemas. Such an approach is proposed
Media Upload and Sharing Website using HBASE
 A-PDF Merger DEMO : Purchase from www.a-pdf.com to remove the watermark Media Upload and Sharing Website using HBASE Tushar Mahajan Santosh Mukherjee Shubham Mathur Agenda Motivation for the project Introduction
A-PDF Merger DEMO : Purchase from www.a-pdf.com to remove the watermark Media Upload and Sharing Website using HBASE Tushar Mahajan Santosh Mukherjee Shubham Mathur Agenda Motivation for the project Introduction
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.035, Spring 2013 Handout Scanner-Parser Project Thursday, Feb 7 DUE: Wednesday, Feb 20, 9:00 pm This project
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.035, Spring 2013 Handout Scanner-Parser Project Thursday, Feb 7 DUE: Wednesday, Feb 20, 9:00 pm This project
Builder User Guide. Version 6.0.1. Visual Rules Suite - Builder. Bosch Software Innovations
 Visual Rules Suite - Builder Builder User Guide Version 6.0.1 Bosch Software Innovations Americas: Bosch Software Innovations Corp. 161 N. Clark Street Suite 3500 Chicago, Illinois 60601/USA Tel. +1 312
Visual Rules Suite - Builder Builder User Guide Version 6.0.1 Bosch Software Innovations Americas: Bosch Software Innovations Corp. 161 N. Clark Street Suite 3500 Chicago, Illinois 60601/USA Tel. +1 312
Developing Eclipse Plug-ins* Learning Objectives. Any Eclipse product is composed of plug-ins
 Developing Eclipse Plug-ins* Wolfgang Emmerich Professor of Distributed Computing University College London http://sse.cs.ucl.ac.uk * Based on M. Pawlowski et al: Fundamentals of Eclipse Plug-in and RCP
Developing Eclipse Plug-ins* Wolfgang Emmerich Professor of Distributed Computing University College London http://sse.cs.ucl.ac.uk * Based on M. Pawlowski et al: Fundamentals of Eclipse Plug-in and RCP
Supporting Change-Aware Semantic Web Services
 Supporting Change-Aware Semantic Web Services Annika Hinze Department of Computer Science, University of Waikato, New Zealand a.hinze@cs.waikato.ac.nz Abstract. The Semantic Web is not only evolving into
Supporting Change-Aware Semantic Web Services Annika Hinze Department of Computer Science, University of Waikato, New Zealand a.hinze@cs.waikato.ac.nz Abstract. The Semantic Web is not only evolving into
Oracle BI EE Implementation on Netezza. Prepared by SureShot Strategies, Inc.
 Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
Oracle BI EE Implementation on Netezza Prepared by SureShot Strategies, Inc. The goal of this paper is to give an insight to Netezza architecture and implementation experience to strategize Oracle BI EE
TZWorks Windows Event Log Viewer (evtx_view) Users Guide
 Users Guide") TZWorks Windows Event Log Viewer (evtx_view) Users Guide Abstract evtx_view is a standalone, GUI tool used to extract and parse Event Logs and display their internals. The tool allows one to export all
TZWorks Windows Event Log Viewer (evtx_view) Users Guide Abstract evtx_view is a standalone, GUI tool used to extract and parse Event Logs and display their internals. The tool allows one to export all
Design Patterns in Parsing
 Abstract Axel T. Schreiner Department of Computer Science Rochester Institute of Technology 102 Lomb Memorial Drive Rochester NY 14623-5608 USA ats@cs.rit.edu Design Patterns in Parsing James E. Heliotis
Abstract Axel T. Schreiner Department of Computer Science Rochester Institute of Technology 102 Lomb Memorial Drive Rochester NY 14623-5608 USA ats@cs.rit.edu Design Patterns in Parsing James E. Heliotis
Web Application Security
 E-SPIN PROFESSIONAL BOOK Vulnerability Management Web Application Security ALL THE PRACTICAL KNOW HOW AND HOW TO RELATED TO THE SUBJECT MATTERS. COMBATING THE WEB VULNERABILITY THREAT Editor s Summary
E-SPIN PROFESSIONAL BOOK Vulnerability Management Web Application Security ALL THE PRACTICAL KNOW HOW AND HOW TO RELATED TO THE SUBJECT MATTERS. COMBATING THE WEB VULNERABILITY THREAT Editor s Summary
Changes for Release 3.0 from Release 2.1.1
 Oracle SQL Developer Oracle TimesTen In-Memory Database Support Release Notes Release 3.0 E18439-03 February 2011 This document provides late-breaking information as well as information that is not yet
Oracle SQL Developer Oracle TimesTen In-Memory Database Support Release Notes Release 3.0 E18439-03 February 2011 This document provides late-breaking information as well as information that is not yet
Automating Security Testing. Mark Fallon Senior Release Manager Oracle
 Automating Security Testing Mark Fallon Senior Release Manager Oracle Some Ground Rules There are no silver bullets You can not test security into a product Testing however, can help discover a large percentage
Automating Security Testing Mark Fallon Senior Release Manager Oracle Some Ground Rules There are no silver bullets You can not test security into a product Testing however, can help discover a large percentage
Modern PL/SQL Code Checking and Dependency Analysis
 Modern PL/SQL Code Checking and Dependency Analysis Philipp Salvisberg Senior Principal Consultant BASEL BERN BRUGG LAUSANNE ZÜRICH DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. HAMBURG MUNICH STUTTGART VIENNA
Modern PL/SQL Code Checking and Dependency Analysis Philipp Salvisberg Senior Principal Consultant BASEL BERN BRUGG LAUSANNE ZÜRICH DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. HAMBURG MUNICH STUTTGART VIENNA
Image Search by MapReduce
 Image Search by MapReduce COEN 241 Cloud Computing Term Project Final Report Team #5 Submitted by: Lu Yu Zhe Xu Chengcheng Huang Submitted to: Prof. Ming Hwa Wang 09/01/2015 Preface Currently, there s
Image Search by MapReduce COEN 241 Cloud Computing Term Project Final Report Team #5 Submitted by: Lu Yu Zhe Xu Chengcheng Huang Submitted to: Prof. Ming Hwa Wang 09/01/2015 Preface Currently, there s
www.novell.com/documentation Policy Guide Access Manager 3.1 SP5 January 2013
 www.novell.com/documentation Policy Guide Access Manager 3.1 SP5 January 2013 Legal Notices Novell, Inc., makes no representations or warranties with respect to the contents or use of this documentation,
www.novell.com/documentation Policy Guide Access Manager 3.1 SP5 January 2013 Legal Notices Novell, Inc., makes no representations or warranties with respect to the contents or use of this documentation,
2. Advance Certificate Course in Information Technology
 Introduction: 2. Advance Certificate Course in Information Technology In the modern world, information is power. Acquiring information, storing, updating, processing, sharing, distributing etc. are essentials
Introduction: 2. Advance Certificate Course in Information Technology In the modern world, information is power. Acquiring information, storing, updating, processing, sharing, distributing etc. are essentials
SOA, case Google. Faculty of technology management 07.12.2009 Information Technology Service Oriented Communications CT30A8901.
 Faculty of technology management 07.12.2009 Information Technology Service Oriented Communications CT30A8901 SOA, case Google Written by: Sampo Syrjäläinen, 0337918 Jukka Hilvonen, 0337840 1 Contents 1.
Faculty of technology management 07.12.2009 Information Technology Service Oriented Communications CT30A8901 SOA, case Google Written by: Sampo Syrjäläinen, 0337918 Jukka Hilvonen, 0337840 1 Contents 1.
Programming Project 1: Lexical Analyzer (Scanner)
") CS 331 Compilers Fall 2015 Programming Project 1: Lexical Analyzer (Scanner) Prof. Szajda Due Tuesday, September 15, 11:59:59 pm 1 Overview of the Programming Project Programming projects I IV will direct
CS 331 Compilers Fall 2015 Programming Project 1: Lexical Analyzer (Scanner) Prof. Szajda Due Tuesday, September 15, 11:59:59 pm 1 Overview of the Programming Project Programming projects I IV will direct
Comparing Microsoft SQL Server 2005 Replication and DataXtend Remote Edition for Mobile and Distributed Applications
 Comparing Microsoft SQL Server 2005 Replication and DataXtend Remote Edition for Mobile and Distributed Applications White Paper Table of Contents Overview...3 Replication Types Supported...3 Set-up &
Comparing Microsoft SQL Server 2005 Replication and DataXtend Remote Edition for Mobile and Distributed Applications White Paper Table of Contents Overview...3 Replication Types Supported...3 Set-up &
Web Services for Management Perl Library VMware ESX Server 3.5, VMware ESX Server 3i version 3.5, and VMware VirtualCenter 2.5
 Technical Note Web Services for Management Perl Library VMware ESX Server 3.5, VMware ESX Server 3i version 3.5, and VMware VirtualCenter 2.5 In the VMware Infrastructure (VI) Perl Toolkit 1.5, VMware
Technical Note Web Services for Management Perl Library VMware ESX Server 3.5, VMware ESX Server 3i version 3.5, and VMware VirtualCenter 2.5 In the VMware Infrastructure (VI) Perl Toolkit 1.5, VMware
MISTI An Integrated Web Content Management System
 MISTI An Integrated Web Content Management System Qiang Lin, Ph.D Abstract-- The Multi-Industry Supply-chain Transaction Infrastructure (MISTI) has been developed to facilitate today s business-to-business
MISTI An Integrated Web Content Management System Qiang Lin, Ph.D Abstract-- The Multi-Industry Supply-chain Transaction Infrastructure (MISTI) has been developed to facilitate today s business-to-business
How to Improve Database Connectivity With the Data Tools Platform. John Graham (Sybase Data Tooling) Brian Payton (IBM Information Management)
 Brian Payton (IBM Information Management)") How to Improve Database Connectivity With the Data Tools Platform John Graham (Sybase Data Tooling) Brian Payton (IBM Information Management) 1 Agenda DTP Overview Creating a Driver Template Creating a
How to Improve Database Connectivity With the Data Tools Platform John Graham (Sybase Data Tooling) Brian Payton (IBM Information Management) 1 Agenda DTP Overview Creating a Driver Template Creating a
File S1: Supplementary Information of CloudDOE
 File S1: Supplementary Information of CloudDOE Table of Contents 1. Prerequisites of CloudDOE... 2 2. An In-depth Discussion of Deploying a Hadoop Cloud... 2 Prerequisites of deployment... 2 Table S1.
File S1: Supplementary Information of CloudDOE Table of Contents 1. Prerequisites of CloudDOE... 2 2. An In-depth Discussion of Deploying a Hadoop Cloud... 2 Prerequisites of deployment... 2 Table S1.
FIPA agent based network distributed control system
 FIPA agent based network distributed control system V.Gyurjyan, D. Abbott, G. Heyes, E. Jastrzembski, C. Timmer, E. Wolin TJNAF, Newport News, VA 23606, USA A control system with the capabilities to combine
FIPA agent based network distributed control system V.Gyurjyan, D. Abbott, G. Heyes, E. Jastrzembski, C. Timmer, E. Wolin TJNAF, Newport News, VA 23606, USA A control system with the capabilities to combine