Web Crawling with Apache Nutch
|
|
|
- Sandra Johnston
- 8 years ago
- Views:
Transcription
1 Web Crawling with Apache Nutch Sebastian Nagel ApacheCon EU

2 About Me computational linguist software developer at Exorbyte (Konstanz, Germany) search and data matching prepare data for indexing, cleansing noisy data, web crawling Nutch user since Nutch committer and PMC

3 Nutch History 2002 started by Doug Cutting and Mike Caffarella open source web-scale crawler and search engine 2004/05 MapReduce and distributed file system in Nutch 2005 Apache incubator, sub-project of Lucene 2006 Hadoop split from Nutch, Nutch based on Hadoop 2007 use Tika for MimeType detection, Tika Parser start NutchBase,, 2012 released 2.0 based on Gora use Solr for indexing 2010 Nutch top-level project 2012/13 ElasticSearch indexer (2.x), pluggable indexing back-ends (1.x) graduate tlp 2.1 incubator Hadoop Tika Gora use Solr
, pluggable indexing back-ends (1.x) graduate tlp 2.1 2.2.1 @sourceforge incubator Hadoop Tika Gora 2.0 2.2 2002 2009 2015 0.5 0.7 0.8 0.4 0.6 0.7.2 0.9 1.")
4 What is Nutch now? an extensible and scalable web crawler based on Hadoop runs on top of scalable: billions of pages possible some overhead (if scale is not a requirement) not ideal for low latency customizable / extensible plugin architecture pluggable protocols (document access) URL filters + normalizers parsing: document formats + meta data extraction indexing back-ends mostly used to feed a search index but also data mining
 URL filters + normalizers parsing: document formats +")
5 Nutch Community mature Apache project 6 active committers maintain two branches (1.x and 2.x) friends (Apache) projects Nutch delegates work to Hadoop: scalability, job execution, data serialization (1.x) Tika: detecting and parsing multiple document formats Solr, ElasticSearch: make crawled content searchable Gora (and HBase, Cassandra, ): data storage (2.x) crawler-commons: robots.txt parsing steady user base, majority of users uses 1.x runs small scale crawls (< 1M pages) uses Solr for indexing and search
: data storage (2.x) crawler-commons: robots.txt parsing steady user base, majority of users uses 1.")
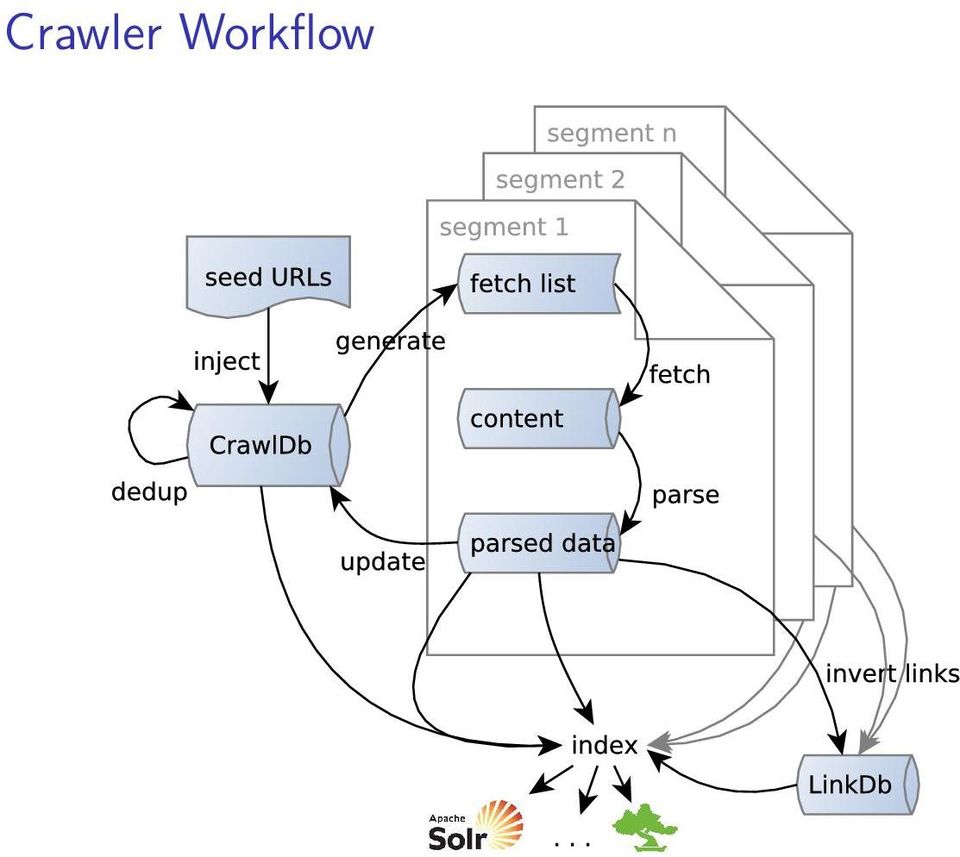
6 Crawler Workflow 0. initialize CrawlDb, inject seed URLs repeat generate-fetch-update cycle n times: 1. generate fetch list: select URLs from CrawlDb for fetching 2. fetch URLs from fetch list 3. parse documents: extract content, metadata and links 4. update CrawlDb status, score and signature, add new URLs inlined or at the end of one crawler run (once for multiple cycles): 5. invert links: map anchor texts to documents the links point to 6. (calculate link rank on web graph, update CrawlDb scores) 7. deduplicate documents by signature 8. index document content, meta data, and anchor texts
 7.")
7 Crawler Workflow
8 Workflow Execution every step is implemented as one (or more) MapReduce job shell script to run the workflow (bin/crawl) bin/nutch to run individual tools inject, generate, fetch, parse, updatedb, invertlinks, index, many analysis and debugging tools local mode works out-of-the-box (bin package) useful for testing and debugging (pseudo-)distributed mode parallelization, monitor crawls with MapReduce web UI recompile and deploy job file with configuration changes
distributed mode parallelization, monitor crawls with MapReduce web UI recompile and deploy job file with")
9 Features of selected Tools Fetcher multi-threaded, high throughput but always be polite respect robots rules (robots.txt and robots directives) limit load on crawled servers, guaranteed delays between access to same host, IP, or domain WebGraph iterative link analysis on the level of documents, sites, or domains most other tools are either quite trivial and/or rely heavily on plugins

10 Extensible via Plugins Plugins basics each Plugin implements one (or more) extension points plugins are activated on demand (property plugin.includes) multiple active plugins per ext. point chained : sequentially applied (filters and normalizers) automatically selected (protocols and parser) Extension points and available plugins URL filter include/exclude URLs from crawling plugins: regex, prefix, suffix, domain URL normalizer canonicalize URL regex, domain, querystring

11 Plugins (continued) protocols http, https, ftp, file protocol plugins take care for robots.txt rules parser need to parse various document types now mostly delegated to Tika (plugin parse-tika) legacy: parse-html, feed, zip parse filter extract additional meta data change extracted plain text plugins: headings, metatags indexing filter add/fill indexed fields url, title, content, anchor, boost, digest, type, host, often in combination with parse filter to extract field content plugins: basic, more, anchor, metadata,

12 Plugins (continued) index writer connect to indexing back-ends send/write additions / updates / deletions plugins: Solr, ElasticSearch scoring filter pass score to outlinks (in 1.x: quite a few hops) change scores in CrawlDb via inlinks can do magic: limit crawl by depth, focused crawling, OPIC (On-line Page Importance Computation, [1]) online: good strategy to crawl relevant content first scores also ok for ranking but seeds (and docs close to them) are favored scores get out of control for long-running continuous crawls LinkRank link rank calculation done separately on WebGraph scores are fed back to CrawlDb Complete list of plugins:
![x: quite a few hops) change scores in CrawlDb via inlinks can do magic: limit crawl by depth, focused crawling, OPIC (On-line Page Importance Computation, [1]) online:](/docs-images/40/2746853/images/page_12.jpg "good strategy to crawl relevant content first scores also ok for ranking but seeds (and docs close to them) are favored scores get out of control for long-running")
13 Pluggable classes Extensible interfaces (pluggable class implementations) fetch schedule decide whether to add URL to fetch list set next fetch time and re-fetch intervals default implementation: fixed re-fetch interval available: interval adaptive to document change frequency signature calculation used for deduplication and not-modified detection MD5 sum of binary document or plain text TextProfile based on filtered word frequency list

14 Data Structures and Storage in Nutch 1.x All data is stored as map url,someobject in Hadoop map or sequence files Data structures (directories) and stored values: CrawlDb: all information of URL/document to run and schedule crawling current status (injected, linked, fetched, gone, ) score, next fetch time, last modified time signature (for deduplication) meta data (container for arbitrary data) LinkDb: incoming links (URLs and anchor texts) WebGraph: map files to hold outlinks, inlinks, node scores
 meta data (container for arbitrary data) LinkDb:")
15 Data Structures (1.x): Segments Segments store all data related to fetch and parse of a single batch of URLs (one generate-fetch-update cycle) crawl_generate: list of URLs to be fetched with politeness requirements (host-level blocking): all URLs of one host (or IP) must be in one partition to implement host-level blocking in one single JVM inside one partition URLs are shuffled: URLs of one host are spread over whole partition to minimize blocking during fetch crawl_fetch: status from fetch (e.g., success, failed, robots denied) content: fetched binary content and meta data (HTTP header) parse_data: extracted meta data, outlinks and anchor texts parse_text: plain-text content crawl_parse: outlinks, scores, signatures, meta data, used to update CrawlDb

16 Storage and Data Flow in Nutch 1.x

17 Storage in Nutch 2.x One big table (WebTable) all information about one URL/document in a single row: status, metadata, binary content, extracted plain-text, inlink anchors, inspired by BigTable paper [3] and rise of NoSQL data stores Apache Gora used for storage layer abstraction OTD (object-to-datastore) for NoSQL data stores HBase, Cassandra, DynamoDb, Avro, Accumulo, data serialization with Avro back-end specific object-datastore mappings
![content, extracted plain-text, inlink anchors, inspired by BigTable paper [3] and rise of NoSQL data stores](/docs-images/40/2746853/images/page_17.jpg "Apache Gora used for storage layer abstraction OTD (object-to-datastore) for NoSQL data stores HBase,")
18 Benefits of Nutch 2.x Benefits less steps in crawler workflow simplify Nutch code base easy to access data from other applications access storage directly or via Gora and schema plugins and MapReduce processing shared with 1.x

19 Performance and Efficiency 2.x? Objective: should be more performant (in terms of latency) no need to rewrite whole CrawlDb for each smaller update adaptable to more instant workflows (cf. [5]) however benchmark by Julien Nioche [4] shows that Nutch 2.x is slower than 1.x by a factor of 2.5 not a problem of HBase and Cassandra but due to Gora layer will hopefully be improved with Nutch 2.3 and recent Gora version which supports filtered scans still fast at scale
![adaptable to more instant workflows (cf. [5]) however benchmark by Julien Nioche [4] shows that Nutch 2.](/docs-images/40/2746853/images/page_19.jpg "x is slower than 1.x by a factor of 2.")
20 and Drawbacks? Drawbacks need to install and maintain datastore higher hardware requirements Impact on Nutch as software project 2.x planned as replacement, however still not as stable as 1.x 1.x has more users need to maintain two branches keep in sync, transfer patches

 based on CrawlDb only no need to pull document signatures and scores from index no special implementations for indexing back-ends (Solr, etc.")
21 News Common Crawl moves to Nutch (2013) public data on Amazon S3 billions of web pages Generic deduplication (1.x) based on CrawlDb only no need to pull document signatures and scores from index no special implementations for indexing back-ends (Solr, etc.) Nutch participated in GSoC 2014
: Create a Wicket-based Web Application for Nutch Nutch Server and REST API Web App client to")
22 Nutch Web App. GSoC 2014 (Fjodor Vershinin): Create a Wicket-based Web Application for Nutch Nutch Server and REST API Web App client to run and schedule crawls only Nutch 2.x (for now) needs completion: change configuration, analytics (logs),
23 What s coming next? Nutch 1.x is still alive! but we hope to release 2.3 soon with performance improvements from recent Gora release Fix bugs, improve usability our bottleneck: review patches, get them committed try hard to keep 1.x and 2.x in sync Pending new features sitemap protocol canonical links
24 What s coming next? (mid- and long-term) Move to Hadoop 2.x and new MapReduce API complete Rest API and Web App port it back to 1.x use graph library (Giraph) for link rank computation switch from batch processing to streaming Storm / Spark /? parts of the workflow
25 Thanks and acknowledgments to Julien Nioche, Lewis John McGibbney, Andrzej Białecki, Chris Mattmann, Doug Cutting, Mike Cafarella for inspirations and material from previous Nutch presentations and to all Nutch committers for review and comments on early versions of theses slides.
26 References [1] Abiteboul, Serge; Preda, Mihai; Cobena, Gregory, 2003: Adaptive on-line page importance computation. In: Proceedings of the 12th International Conference on World Wide Web, WWW 03, pp , ACM, New York, NY, USA, [2] Białecki, Andrzej, 2012: Nutch search engine. In: White, Tom (ed.) Hadoop: The Definitive Guide, pp , O Reilly. [3] Chang, Fay; Dean, Jeffrey; Ghemawat, Sanjay; Hsieh, Wilson C.; Wallach, Deborah A.; Burrows, Mike; Chandra, Tushar; Fikes, Andrew; Gruber, Robert E., 2006: Bigtable: A distributed storage system for structured data. In: Proceedings of the 7th Conference on USENIX Symposium on Operating Systems Design and Implementation (OSDI 06), vol. 7, pp , [4] Nioche, Julien, 2013, Nutch fight! 1.7 vs Blog post, [5] Peng, Daniel Dabek, Frank, 2010: Large-scale incremental processing using distributed transactions and notifications. In: 9th USENIX Symposium on Operating Systems Design and Implementation, pp. 4 6,
27 Questions?
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Scalable Computing with Hadoop
 Scalable Computing with Hadoop Doug Cutting cutting@apache.org dcutting@yahoo-inc.com 5/4/06 Seek versus Transfer B-Tree requires seek per access unless to recent, cached page so can buffer & pre-sort
Scalable Computing with Hadoop Doug Cutting cutting@apache.org dcutting@yahoo-inc.com 5/4/06 Seek versus Transfer B-Tree requires seek per access unless to recent, cached page so can buffer & pre-sort
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Future Prospects of Scalable Cloud Computing
 Future Prospects of Scalable Cloud Computing Keijo Heljanko Department of Information and Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 7.3-2012 1/17 Future Cloud Topics Beyond
Future Prospects of Scalable Cloud Computing Keijo Heljanko Department of Information and Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 7.3-2012 1/17 Future Cloud Topics Beyond
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Distributed Lucene : A distributed free text index for Hadoop
 Distributed Lucene : A distributed free text index for Hadoop Mark H. Butler and James Rutherford HP Laboratories HPL-2008-64 Keyword(s): distributed, high availability, free text, parallel, search Abstract:
Distributed Lucene : A distributed free text index for Hadoop Mark H. Butler and James Rutherford HP Laboratories HPL-2008-64 Keyword(s): distributed, high availability, free text, parallel, search Abstract:
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Web and Data Analysis. Minkoo Seo June 2015
 Web and Data Analysis Minkoo Seo June 2015 About R user since 2011 Wrote this book Software Engineer at Google Korea http://mkseo.pe.kr/ These views are mine and mine alone and do not reflect the views
Web and Data Analysis Minkoo Seo June 2015 About R user since 2011 Wrote this book Software Engineer at Google Korea http://mkseo.pe.kr/ These views are mine and mine alone and do not reflect the views
Big Data and Hadoop with components like Flume, Pig, Hive and Jaql
 Abstract- Today data is increasing in volume, variety and velocity. To manage this data, we have to use databases with massively parallel software running on tens, hundreds, or more than thousands of servers.
Abstract- Today data is increasing in volume, variety and velocity. To manage this data, we have to use databases with massively parallel software running on tens, hundreds, or more than thousands of servers.
Search and Real-Time Analytics on Big Data
 Search and Real-Time Analytics on Big Data Sewook Wee, Ryan Tabora, Jason Rutherglen Accenture & Think Big Analytics Strata New York October, 2012 Big Data: data becomes your core asset. It realizes its
Search and Real-Time Analytics on Big Data Sewook Wee, Ryan Tabora, Jason Rutherglen Accenture & Think Big Analytics Strata New York October, 2012 Big Data: data becomes your core asset. It realizes its
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
What is Analytic Infrastructure and Why Should You Care?
 What is Analytic Infrastructure and Why Should You Care? Robert L Grossman University of Illinois at Chicago and Open Data Group grossman@uic.edu ABSTRACT We define analytic infrastructure to be the services,
What is Analytic Infrastructure and Why Should You Care? Robert L Grossman University of Illinois at Chicago and Open Data Group grossman@uic.edu ABSTRACT We define analytic infrastructure to be the services,
American International Journal of Research in Science, Technology, Engineering & Mathematics
 American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
Finding the Needle in a Big Data Haystack. Wolfgang Hoschek (@whoschek) JAX 2014
 JAX 2014") Finding the Needle in a Big Data Haystack Wolfgang Hoschek (@whoschek) JAX 2014 1 About Wolfgang Software Engineer @ Cloudera Search Platform Team Previously CERN, Lawrence Berkeley National Laboratory,
Finding the Needle in a Big Data Haystack Wolfgang Hoschek (@whoschek) JAX 2014 1 About Wolfgang Software Engineer @ Cloudera Search Platform Team Previously CERN, Lawrence Berkeley National Laboratory,
Storage of Structured Data: BigTable and HBase. New Trends In Distributed Systems MSc Software and Systems
 Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
Storage of Structured Data: BigTable and HBase 1 HBase and BigTable HBase is Hadoop's counterpart of Google's BigTable BigTable meets the need for a highly scalable storage system for structured data Provides
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Big Data Drupal. Commercial Open Source Big Data Tool Chain
 Big Data Drupal Commercial Open Source Big Data Tool Chain How did I prepare? MapReduce Field Work About Me Nicholas Roberts 10+ years web Webmaster, Project & Product Manager Australian Sonoma County
Big Data Drupal Commercial Open Source Big Data Tool Chain How did I prepare? MapReduce Field Work About Me Nicholas Roberts 10+ years web Webmaster, Project & Product Manager Australian Sonoma County
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Slave. Master. Research Scholar, Bharathiar University
 Volume 3, Issue 7, July 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper online at: www.ijarcsse.com Study on Basically, and Eventually
Volume 3, Issue 7, July 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper online at: www.ijarcsse.com Study on Basically, and Eventually
Big Data and Hadoop with Components like Flume, Pig, Hive and Jaql
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 7, July 2014, pg.759
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 3, Issue. 7, July 2014, pg.759
Apache Lucene. Searching the Web and Everything Else. Daniel Naber Mindquarry GmbH ID 380
 Apache Lucene Searching the Web and Everything Else Daniel Naber Mindquarry GmbH ID 380 AGENDA 2 > What's a search engine > Lucene Java Features Code example > Solr Features Integration > Nutch Features
Apache Lucene Searching the Web and Everything Else Daniel Naber Mindquarry GmbH ID 380 AGENDA 2 > What's a search engine > Lucene Java Features Code example > Solr Features Integration > Nutch Features
Sector vs. Hadoop. A Brief Comparison Between the Two Systems
 Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Sector vs. Hadoop A Brief Comparison Between the Two Systems Background Sector is a relatively new system that is broadly comparable to Hadoop, and people want to know what are the differences. Is Sector
Large-Scale TCP Packet Flow Analysis for Common Protocols Using Apache Hadoop
 Large-Scale TCP Packet Flow Analysis for Common Protocols Using Apache Hadoop R. David Idol Department of Computer Science University of North Carolina at Chapel Hill david.idol@unc.edu http://www.cs.unc.edu/~mxrider
Large-Scale TCP Packet Flow Analysis for Common Protocols Using Apache Hadoop R. David Idol Department of Computer Science University of North Carolina at Chapel Hill david.idol@unc.edu http://www.cs.unc.edu/~mxrider
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: bdg@qburst.com Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
Dominik Wagenknecht Accenture
 Dominik Wagenknecht Accenture Improving Mainframe Performance with Hadoop October 17, 2014 Organizers General Partner Top Media Partner Media Partner Supporters About me Dominik Wagenknecht Accenture Vienna
Dominik Wagenknecht Accenture Improving Mainframe Performance with Hadoop October 17, 2014 Organizers General Partner Top Media Partner Media Partner Supporters About me Dominik Wagenknecht Accenture Vienna
NoSQL Roadshow Berlin Kai Spichale
 Full-text Search with NoSQL Technologies NoSQL Roadshow Berlin Kai Spichale 25.04.2013 About me Kai Spichale Software Engineer at adesso AG Author in professional journals, conference speaker adesso is
Full-text Search with NoSQL Technologies NoSQL Roadshow Berlin Kai Spichale 25.04.2013 About me Kai Spichale Software Engineer at adesso AG Author in professional journals, conference speaker adesso is
Building Multilingual Search Index using open source framework
 Building Multilingual Search Index using open source framework ABSTRACT Arjun Atreya V 1 Swapnil Chaudhari 1 Pushpak Bhattacharyya 1 Ganesh Ramakrishnan 1 (1) Deptartment of CSE, IIT Bombay {arjun, swapnil,
Building Multilingual Search Index using open source framework ABSTRACT Arjun Atreya V 1 Swapnil Chaudhari 1 Pushpak Bhattacharyya 1 Ganesh Ramakrishnan 1 (1) Deptartment of CSE, IIT Bombay {arjun, swapnil,
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam sastry.vedantam@oracle.com
 Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam sastry.vedantam@oracle.com Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
Using MySQL for Big Data Advantage Integrate for Insight Sastry Vedantam sastry.vedantam@oracle.com Agenda The rise of Big Data & Hadoop MySQL in the Big Data Lifecycle MySQL Solutions for Big Data Q&A
Chase Wu New Jersey Ins0tute of Technology
 CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
CS 698: Special Topics in Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Ins0tute of Technology Some of the slides have been provided through the courtesy of Dr. Ching-Yung Lin at
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com sujee@elephantscale.com Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Tools for Web Archiving: The Java/Open Source Tools to Crawl, Access & Search the Web. NLA Gordon Mohr March 28, 2012
 Tools for Web Archiving: The Java/Open Source Tools to Crawl, Access & Search the Web NLA Gordon Mohr March 28, 2012 Overview The tools: Heritrix crawler Wayback browse access Lucene/Hadoop utilities:
Tools for Web Archiving: The Java/Open Source Tools to Crawl, Access & Search the Web NLA Gordon Mohr March 28, 2012 Overview The tools: Heritrix crawler Wayback browse access Lucene/Hadoop utilities:
Mark Bennett. Search and the Virtual Machine
 Mark Bennett Search and the Virtual Machine Agenda Intro / Business Drivers What to do with Search + Virtual What Makes Search Fast (or Slow!) Virtual Platforms Test Results Trends / Wrap Up / Q & A Business
Mark Bennett Search and the Virtual Machine Agenda Intro / Business Drivers What to do with Search + Virtual What Makes Search Fast (or Slow!) Virtual Platforms Test Results Trends / Wrap Up / Q & A Business
MapReduce Jeffrey Dean and Sanjay Ghemawat. Background context
 MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
MapReduce Jeffrey Dean and Sanjay Ghemawat Background context BIG DATA!! o Large-scale services generate huge volumes of data: logs, crawls, user databases, web site content, etc. o Very useful to be able
Analysis of Web Archives. Vinay Goel Senior Data Engineer
 Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
Analysis of Web Archives Vinay Goel Senior Data Engineer Internet Archive Established in 1996 501(c)(3) non profit organization 20+ PB (compressed) of publicly accessible archival material Technology partner
CloudSearch: A Custom Search Engine based on Apache Hadoop, Apache Nutch and Apache Solr
 CloudSearch: A Custom Search Engine based on Apache Hadoop, Apache Nutch and Apache Solr Lambros Charissis, Wahaj Ali University of Crete {lcharisis, ali}@csd.uoc.gr Abstract. Implementing a performant
CloudSearch: A Custom Search Engine based on Apache Hadoop, Apache Nutch and Apache Solr Lambros Charissis, Wahaj Ali University of Crete {lcharisis, ali}@csd.uoc.gr Abstract. Implementing a performant
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing
 YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
YARN, the Apache Hadoop Platform for Streaming, Realtime and Batch Processing Eric Charles [http://echarles.net] @echarles Datalayer [http://datalayer.io] @datalayerio FOSDEM 02 Feb 2014 NoSQL DevRoom
Optimization of Distributed Crawler under Hadoop
 MATEC Web of Conferences 22, 0202 9 ( 2015) DOI: 10.1051/ matecconf/ 2015220202 9 C Owned by the authors, published by EDP Sciences, 2015 Optimization of Distributed Crawler under Hadoop Xiaochen Zhang*
MATEC Web of Conferences 22, 0202 9 ( 2015) DOI: 10.1051/ matecconf/ 2015220202 9 C Owned by the authors, published by EDP Sciences, 2015 Optimization of Distributed Crawler under Hadoop Xiaochen Zhang*
Big Data and Apache Hadoop s MapReduce
 Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Big Data and Apache Hadoop s MapReduce Michael Hahsler Computer Science and Engineering Southern Methodist University January 23, 2012 Michael Hahsler (SMU/CSE) Hadoop/MapReduce January 23, 2012 1 / 23
Hadoop-based Open Source ediscovery: FreeEed. (Easy as popcorn)
") + Hadoop-based Open Source ediscovery: FreeEed (Easy as popcorn) + Hello! 2 Sujee Maniyam & Mark Kerzner Founders @ Elephant Scale consulting and training around Hadoop, Big Data technologies Enterprise
+ Hadoop-based Open Source ediscovery: FreeEed (Easy as popcorn) + Hello! 2 Sujee Maniyam & Mark Kerzner Founders @ Elephant Scale consulting and training around Hadoop, Big Data technologies Enterprise
Upcoming Announcements
 Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC jmarkham@hortonworks.com Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
Enterprise Hadoop Enterprise Hadoop Jeff Markham Technical Director, APAC jmarkham@hortonworks.com Page 1 Upcoming Announcements April 2 Hortonworks Platform 2.1 A continued focus on innovation within
What's New in SAS Data Management
 Paper SAS034-2014 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC; Mike Frost, SAS Institute Inc., Cary, NC, Mike Ames, SAS Institute Inc., Cary ABSTRACT The latest releases
Paper SAS034-2014 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC; Mike Frost, SAS Institute Inc., Cary, NC, Mike Ames, SAS Institute Inc., Cary ABSTRACT The latest releases
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
So today we shall continue our discussion on the search engines and web crawlers. (Refer Slide Time: 01:02)
") Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Internet Technology Prof. Indranil Sengupta Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture No #39 Search Engines and Web Crawler :: Part 2 So today we
Analysing Large Web Log Files in a Hadoop Distributed Cluster Environment
 Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
Analysing Large Files in a Hadoop Distributed Cluster Environment S Saravanan, B Uma Maheswari Department of Computer Science and Engineering, Amrita School of Engineering, Amrita Vishwa Vidyapeetham,
ZingMe Practice For Building Scalable PHP Website. By Chau Nguyen Nhat Thanh ZingMe Technical Manager Web Technical - VNG
 ZingMe Practice For Building Scalable PHP Website By Chau Nguyen Nhat Thanh ZingMe Technical Manager Web Technical - VNG Agenda About ZingMe Scaling PHP application Scalability definition Scaling up vs
ZingMe Practice For Building Scalable PHP Website By Chau Nguyen Nhat Thanh ZingMe Technical Manager Web Technical - VNG Agenda About ZingMe Scaling PHP application Scalability definition Scaling up vs
Towards Smart and Intelligent SDN Controller
 Towards Smart and Intelligent SDN Controller - Through the Generic, Extensible, and Elastic Time Series Data Repository (TSDR) YuLing Chen, Dell Inc. Rajesh Narayanan, Dell Inc. Sharon Aicler, Cisco Systems
Towards Smart and Intelligent SDN Controller - Through the Generic, Extensible, and Elastic Time Series Data Repository (TSDR) YuLing Chen, Dell Inc. Rajesh Narayanan, Dell Inc. Sharon Aicler, Cisco Systems
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
Distributed Computing and Big Data: Hadoop and MapReduce
 Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Distributed Computing and Big Data: Hadoop and MapReduce Bill Keenan, Director Terry Heinze, Architect Thomson Reuters Research & Development Agenda R&D Overview Hadoop and MapReduce Overview Use Case:
Like what you hear? Tweet it using: #Sec360
 Like what you hear? Tweet it using: #Sec360 HADOOP SECURITY Like what you hear? Tweet it using: #Sec360 HADOOP SECURITY About Robert: School: UW Madison, U St. Thomas Programming: 15 years, C, C++, Java
Like what you hear? Tweet it using: #Sec360 HADOOP SECURITY Like what you hear? Tweet it using: #Sec360 HADOOP SECURITY About Robert: School: UW Madison, U St. Thomas Programming: 15 years, C, C++, Java
On the Varieties of Clouds for Data Intensive Computing
 On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
On the Varieties of Clouds for Data Intensive Computing Robert L. Grossman University of Illinois at Chicago and Open Data Group Yunhong Gu University of Illinois at Chicago Abstract By a cloud we mean
HBase Schema Design. NoSQL Ma4ers, Cologne, April 2013. Lars George Director EMEA Services
 HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
HBase Schema Design NoSQL Ma4ers, Cologne, April 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera ConsulFng on Hadoop projects (everywhere) Apache Commi4er HBase and Whirr
Hosting Transaction Based Applications on Cloud
 Proc. of Int. Conf. on Multimedia Processing, Communication& Info. Tech., MPCIT Hosting Transaction Based Applications on Cloud A.N.Diggikar 1, Dr. D.H.Rao 2 1 Jain College of Engineering, Belgaum, India
Proc. of Int. Conf. on Multimedia Processing, Communication& Info. Tech., MPCIT Hosting Transaction Based Applications on Cloud A.N.Diggikar 1, Dr. D.H.Rao 2 1 Jain College of Engineering, Belgaum, India
Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive
 Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive E. Laxmi Lydia 1,Dr. M.Ben Swarup 2 1 Associate Professor, Department of Computer Science and Engineering, Vignan's Institute
Big Data Analysis using Hadoop components like Flume, MapReduce, Pig and Hive E. Laxmi Lydia 1,Dr. M.Ben Swarup 2 1 Associate Professor, Department of Computer Science and Engineering, Vignan's Institute
Implementation Issues of A Cloud Computing Platform
 Implementation Issues of A Cloud Computing Platform Bo Peng, Bin Cui and Xiaoming Li Department of Computer Science and Technology, Peking University {pb,bin.cui,lxm}@pku.edu.cn Abstract Cloud computing
Implementation Issues of A Cloud Computing Platform Bo Peng, Bin Cui and Xiaoming Li Department of Computer Science and Technology, Peking University {pb,bin.cui,lxm}@pku.edu.cn Abstract Cloud computing
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Unified Batch & Stream Processing Platform
 Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
Unified Batch & Stream Processing Platform Himanshu Bari Director Product Management Most Big Data Use Cases Are About Improving/Re-write EXISTING solutions To KNOWN problems Current Solutions Were Built
Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com)
") Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com) About Me Parallel Programming since 1989 High-Performance Scientific Computing 1989-2005, Data-Intensive Computing 2005 -... Hadoop Solutions
Hadoop Usage At Yahoo! Milind Bhandarkar (milindb@yahoo-inc.com) About Me Parallel Programming since 1989 High-Performance Scientific Computing 1989-2005, Data-Intensive Computing 2005 -... Hadoop Solutions
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com
 Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
Hadoop at Yahoo! Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since Feb
www.basho.com Technical Overview Simple, Scalable, Object Storage Software
 www.basho.com Technical Overview Simple, Scalable, Object Storage Software Table of Contents Table of Contents... 1 Introduction & Overview... 1 Architecture... 2 How it Works... 2 APIs and Interfaces...
www.basho.com Technical Overview Simple, Scalable, Object Storage Software Table of Contents Table of Contents... 1 Introduction & Overview... 1 Architecture... 2 How it Works... 2 APIs and Interfaces...
Hadoop: Distributed Data Processing. Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010
 Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Hadoop: Distributed Data Processing Amr Awadallah Founder/CTO, Cloudera, Inc. ACM Data Mining SIG Thursday, January 25 th, 2010 Outline Scaling for Large Data Processing What is Hadoop? HDFS and MapReduce
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Optimizing Apache Nutch For Domain Specific Crawling at Large Scale
 2015 IEEE International Conference on Big Data (Big Data) Optimizing Apache Nutch For Domain Specific Crawling at Large Scale Luis A. Lopez 1, Ruth Duerr 2, Siri Jodha Singh Khalsa 3 NSIDC 1, The Ronin
2015 IEEE International Conference on Big Data (Big Data) Optimizing Apache Nutch For Domain Specific Crawling at Large Scale Luis A. Lopez 1, Ruth Duerr 2, Siri Jodha Singh Khalsa 3 NSIDC 1, The Ronin
Automated Data Ingestion. Bernhard Disselhoff Enterprise Sales Engineer
 Automated Data Ingestion Bernhard Disselhoff Enterprise Sales Engineer Agenda Pentaho Overview Templated dynamic ETL workflows Pentaho Data Integration (PDI) Use Cases Pentaho Overview Overview What we
Automated Data Ingestion Bernhard Disselhoff Enterprise Sales Engineer Agenda Pentaho Overview Templated dynamic ETL workflows Pentaho Data Integration (PDI) Use Cases Pentaho Overview Overview What we
StratioDeep. An integration layer between Cassandra and Spark. Álvaro Agea Herradón Antonio Alcocer Falcón
 StratioDeep An integration layer between Cassandra and Spark Álvaro Agea Herradón Antonio Alcocer Falcón StratioDeep An integration layer between Cassandra and Spark Álvaro Agea Herradón Antonio Alcocer
StratioDeep An integration layer between Cassandra and Spark Álvaro Agea Herradón Antonio Alcocer Falcón StratioDeep An integration layer between Cassandra and Spark Álvaro Agea Herradón Antonio Alcocer
HDFS Federation. Sanjay Radia Founder and Architect @ Hortonworks. Page 1
 HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
HDFS Federation Sanjay Radia Founder and Architect @ Hortonworks Page 1 About Me Apache Hadoop Committer and Member of Hadoop PMC Architect of core-hadoop @ Yahoo - Focusing on HDFS, MapReduce scheduler,
A brief introduction of IBM s work around Hadoop - BigInsights
 A brief introduction of IBM s work around Hadoop - BigInsights Yuan Hong Wang Manager, Analytics Infrastructure Development China Development Lab, IBM yhwang@cn.ibm.com Adding IBM Value To Hadoop Role
A brief introduction of IBM s work around Hadoop - BigInsights Yuan Hong Wang Manager, Analytics Infrastructure Development China Development Lab, IBM yhwang@cn.ibm.com Adding IBM Value To Hadoop Role
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
Hadoop: The Definitive Guide
 FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
FOURTH EDITION Hadoop: The Definitive Guide Tom White Beijing Cambridge Famham Koln Sebastopol Tokyo O'REILLY Table of Contents Foreword Preface xvii xix Part I. Hadoop Fundamentals 1. Meet Hadoop 3 Data!
Search and Information Retrieval
 Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Search and Information Retrieval Search on the Web 1 is a daily activity for many people throughout the world Search and communication are most popular uses of the computer Applications involving search
Integration of Apache Hive and HBase
 Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 About Me User and committer of Hadoop since 2007 Contributor to Apache Hadoop, HBase, Hive and Gora Joined
Real-time Streaming Analysis for Hadoop and Flume. Aaron Kimball odiago, inc. OSCON Data 2011
 Real-time Streaming Analysis for Hadoop and Flume Aaron Kimball odiago, inc. OSCON Data 2011 The plan Background: Flume introduction The need for online analytics Introducing FlumeBase Demo! FlumeBase
Real-time Streaming Analysis for Hadoop and Flume Aaron Kimball odiago, inc. OSCON Data 2011 The plan Background: Flume introduction The need for online analytics Introducing FlumeBase Demo! FlumeBase
Associate Professor, Department of CSE, Shri Vishnu Engineering College for Women, Andhra Pradesh, India 2
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu
 Yabo (Arber) Xu") Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
Lecture 4 Introduction to Hadoop & GAE Cloud Application Development (SE808, School of Software, Sun Yat-Sen University) Yabo (Arber) Xu Outline Introduction to Hadoop The Hadoop ecosystem Related projects
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Building Scalable Big Data Infrastructure Using Open Source Software. Sam William sampd@stumbleupon.
 Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new