Carlo Cavazzoni, HPC department, CINECA
|
|
|
- Cuthbert Harper
- 8 years ago
- Views:
Transcription
1 CINECA HPC Infrastructure: state of the art and road map Carlo Cavazzoni, HPC department, CINECA

2 Installed HPC Engines Eurora (Eurotech) FERMI, (IBM BGQ) PLX, (IBM DataPlex) hybrid cluster 64 nodes 1024 SandyBridge cores 64 K20 GPU 64 Xeon PHI coprocessor 150 TFlops peak nodes PowerA2 cores 2PFlops peak Hybrid cluster 274 nodes 3288 Westmere cores 548 nvidia M2070 (Fermi) 300TFlops peak
")
3 Architecture: 10 BGQ Frame Model: IBM-BG/Q Processor Type: IBM PowerA2, 1.6 GHz Computing Cores: Computing Nodes: RAM: 1GByte / core Internal Network: 5D Torus Disk Space: 2PByte of scratch space Peak Performance: 2PFlop/s CINECA PRACE Tier-0 System Available for ISCRA & PRACE call for projects

4 The PRACE RI provides access to distributed persistent pan-european world class HPC computing and data management resources and services. Expertise in efficient use of the resources is available through participating centers throughout Europe. Available resources are announced for each Call for Proposals.. European Tier 0 Tier 1 Tier 2 National Local Peer reviewed open access PRACE Projects (Tier-0) PRACE Preparatory (Tier-0) DECI Projects (Tier-1)

5 2. Single Chip Module 3. Compute card: One chip module, 16 GB DDR3 Memory, 4. Node Card: 32 Compute Cards, Optical Modules, Link Chips, Torus 1. Chip: 16 P cores 5b. IO drawer: 8 IO cards w/16 GB 8 PCIe Gen2 x8 slots 7. System: 20PF/s 5a. Midplane: 16 Node Cards 6. Rack: 2 Midplanes

6 BG/Q I/O architecture PCI_E IB IB BG/Q compute racks BG/Q IO Switch File system servers IB SAN

7 I/O drawers PCIe I/O nodes 8 I/O nodes At least one I/O node for each partition/job Minimum partition/job size: 64 nodes, 1024 cores

8 PowerA2 chip, basic info 64bit RISC Processor Power instruction set (Power1 Power7, PowerPC) 4 Floating Point units per core & 4 way MT 16 cores (17th Processor core for system functions) 1.6GHz 32MByte cache system-on-a-chip design 16GByte of RAM at 1.33GHz Peak Perf gigaflops power draw of 55 watts 45 nanometer copper/soi process (same as Power7) Water Cooled

9 PowerA2 FPU Each FPU on each core has four pipelines execute scalar floating point instructions four-wide SIMD instructions two-wide complex arithmetic SIMD inst. six-stage pipeline maximum of eight concurrent floating point operations per clock plus a load and a store. 9

10 EURORA #1 in The Green500 List June 2013 What EURORA stant for? EURopean many integrated core Architecture What is EURORA? Prototype Project Founded by PRACE 2IP EU project Grant agreement number: RI Co-designed by CINECA and EUROTECH Where is EURORA? EURORA is installed at CINECA When EURORA has been installed? March 2013 Who is using EURORA? All Italian and EU researchers through PRACE Prototype grant access program 3,200MFLOPS/W 30KW

11 Why EURORA? (project objectives) Address Today HPC Constraints: Flops/Watt, Flops/m2, Flops/Dollar. Efficient Cooling Technology: hot water cooling (free cooling); measure power efficiency, evaluate (PUE & TCO). Improve Application Performances: at the same rate as in the past (~Moore s Law); new programming models. Evaluate Hybrid (accelerated) Technology: Intel Xeon Phi; NVIDIA Kepler. Custom Interconnection Technology: 3D Torus network (FPGA); evaluation of accelerator-toaccelerator communications.
 Technology: Intel Xeon Phi; NVIDIA Kepler.")
12 EURORA prototype configuration 64 compute cards 128 Xeon SandyBridge (2.1GHz, 95W and 3.1GHz, 150W) 16GByte DDR3 1600MHz per node 160GByte SSD per node 1 FPGA (Altera Stratix V) per node IB QDR interconnect 3D Torus interconnect 128 Accelerator cards (NVIDA K20 and INTEL PHI)
 per node IB QDR interconnect 3D Torus")
13 Node card K20 Xeon PHI 13
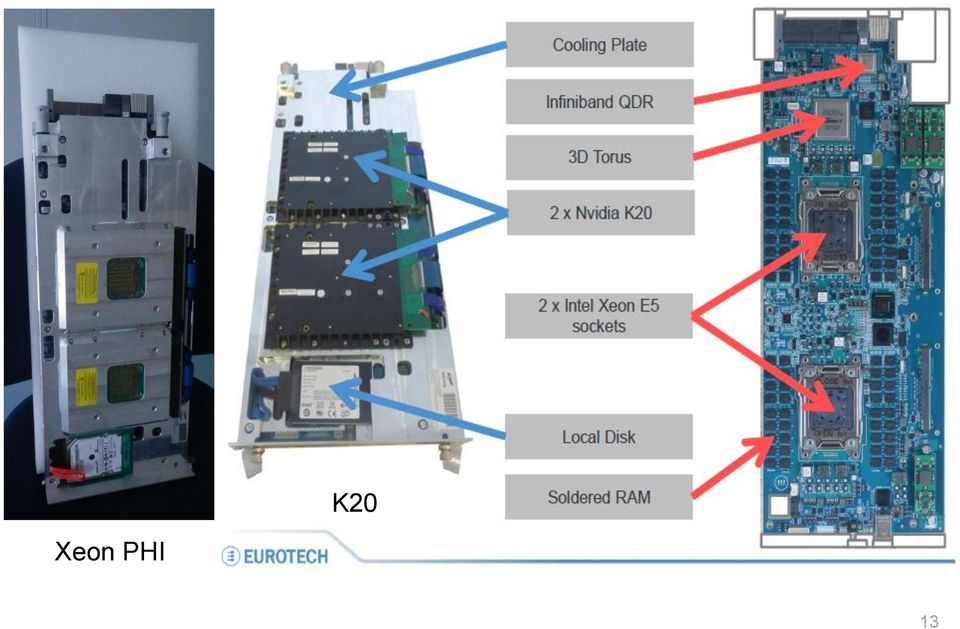
14 Node Energy Efficiency Decreases! 14

15 HPC Service

16 HPC Engines HPC Services FERMI (IBM BGQ) Eurora (Eurotech hybrid) PLX (IBM x86+gpu) HPC Workloads PRACE LISA Projects Agreements #12 Top500 2PFlops peak cores 163Tbyte RAM Power 1.6GHz #1 Green PFlops peak 1024 x86 cores 64 Intel PHI 64 NVIDIA K20 0.3PFlops peak ~3500 x86 procs 548 NVIDIA GPU 20 NVIDIA Quadro 16 Fat nodes ISCRA Data Processing Workloads FERMI High througput Training viz Labs Big mem PLX DB Industry Web serv. HPC Data store Data mover Data mover processing Tape 1.5PB Repository 1.8PByte Workspace 3.6PByte NUBES Cloud serv. We b FEC Archive FTP External Data Sources HPC Cloud Nubes FEC PLX Store PRACE EUDAT Labs Projects Network Custom IB Gbe Fibre FERMI EURORA EURORA PLX Store Nubes Infrastructure Internet Store

17 CINECA services High Performance Computing Computational workflow Storage Data analytics Data preservation (long term) Data access (web/app) Remote Visualization HPC Training HPC Consulting HPC Hosting Monitoring and Metering For academia and industry

18 Road Map


19 (data centric) Infrastructure (Q3 2014) External Data Sources Cloud service SaaS APP PRACE EUDAT Other Data Sources Laboratories Core Data Store New storage Human Brain Prj Repository 5PByte Tape 5+ PByte Internal data sources Core Data Processing viz Big mem Data mover We b Archive Analytics APP DB We b serv. processing FTP New analytics Workspace 3.6PByte Scale-Out Data Processing FERMI X86 Cluster Parallel APP

20 New Tier 1 CINECA Procurement Q Requisiti di alto livello del sistema Potenza elettrica assorbita: 400KW Dimensione fisica del sistema: 5 racks Potenza di picco del sistema (CPU+GPU): nell'ordine di 1PFlops Potenza di picco del sistema (solo CPU): nell'ordine di 300TFlops
: nell'ordine di")
21 Tier 1 CINECA Requisiti di alto livello del sistema Architettura CPU: Intel Xeon Ivy Bridge Numero di core per CPU: >3GHz, oppure 2.4GHz La scelta della frequenza ed il numero di core dipende dal TDP del socket, dalla densità del sistema e dalla capacità di raffreddamento Numero di server: , ( Peak perf = 600 * 2socket * 12core * 3GHz * 8Flop/clk = 345TFlops ) Il numero di server del sistema potrà dipendere dal costo o dalla geometria della configurazione in termini di numero di nodi solo CPU e numero di nodi CPU+GPU Architettura GPU: Nvidia K40 Numero di GPU: >500 ( Peak perf = 700 * 1.43TFlops = 1PFlops ) Il numero di schede GPU del sistema potrà dipendere dal costo o dalla geometria della configurazione in termini di numero di nodi solo CPU e numero di nodi CPU+GPU
22 Tier 1 CINECA Requisiti di alto livello del sistema Vendor identificati: IBM, Eurotech DRAM Memory: 1GByte/core Verrà richiesta la possibilità di avere un sottoinsieme di nodi con una quantità di memoria più elevata Memoria non volatile locale: >500GByte SSD/HD a seconda del costo e dalla configurazione del sistema Cooling: sistema di raffreddamento a liquido con opzione di free cooling Spazio disco scratch: >300TByte (provided by CINECA)
23 Roadmap 50PFlops Power consumption EURORA 50KW, PLX 350 KW, BGQ 1000KW + ENI EURORA or PLX upgrade 400KW; BGQ 1000KW, Data repository 200KW; - ENI R&D Eurora EuroExa STM / ARM board EuroExa STM / ARM prototype PCP Proto 1PF in a rack EuroExa STM / ARM PF platform ETP proto towards exascale board Deployment Eurora industrial prototype 150 TF Eurora or PLX upgrade 1PF peak, 350TF scalar multi petaflop system Tier-0 50PF Tier-1 towards exascale Time line
24 Roadmap to Exascale (architectural trends)
25 HPC Architectures two model Hybrid: Server class processors: Server class nodes Special purpose nodes Accelerator devices: Nvidia Intel AMD FPGA Homogeneus: Server class node: Standar processors Special porpouse nodes Special purpose processors
26 Architectural trends Peak Performance FPU Performance Number of FPUs App. Parallelism Moore law Dennard law Moore + Dennard Amdahl's law
27 Programming Models fundamental paradigm: Message passing Multi-threads Consolidated standard: MPI & OpenMP New task based programming model Special purpose for accelerators: CUDA Intel offload directives OpenACC, OpenCL, Ecc NO consolidated standard Scripting: python
28 But! 14nm VLSI 0.54 nm Si lattice 300 atoms! There will be still 4~6 cycles (or technology generations) left until we reach 11 ~ 5.5 nm technologies, at which we will reach downscaling limit, in some year between (H. Iwai, IWJT2008).
29 Thank you

30 Dennard scaling law (downscaling) new VLSI gen. old VLSI gen. L = L / 2 V = V / 2 F = F * 2 D = 1 / L 2 = 4D P = P do not hold anymore! The core frequency and performance do not grow following the Moore s law any longer L = L / 2 V = ~V F = ~F * 2 D = 1 / L 2 = 4 * D P = 4 * P The power crisis! Increase the number of cores to maintain the architectures evolution on the Moore s law Programming crisis!
31 Moore s Law Economic and market law Stacy Smith, Intel s chief financial officer, later gave some more detail on the economic benefits of staying on the Moore s Law race. The cost per chip is going down more than the capital intensity is going up, Smith said, suggesting Intel s profit margins should not suffer because of heavy capital spending. This is the economic beauty of Moore s Law. And Intel has a good handle on the next production shift, shrinking circuitry to 10 nanometers. Holt said the company has test chips running on that technology. We are projecting similar kinds of improvements in cost out to 10 nanometers, he said. So, despite the challenges, Holt could not be induced to say there s any looming end to Moore s Law, the invention race that has been a key driver of electronics innovation since first defined by Intel s co-founder in the mid-1960s. From WSJ It is all about the number of chips per Si wafer!

32 What about Applications? In a massively parallel context, an upper limit for the scalability of parallel applications is determined by the fraction of the overall execution time spent in non-scalable operations (Amdahl's law). maximum speedup tends to 1 / ( 1 P ) P= parallel fraction core P = serial fraction=
 Xeon + MIC Arm (homo) only arm chip, but Nvidia/Arm (hybrid) arm+nvidia Fujitsu (homo) sparc high density low power China (homo/hybrid) with Intel only Room for AMD")
33 HPC Architectures two model Hybrid, but Homogeneus, but What 100PFlops system we will see my guess IBM (hybrid) Power8+Nvidia GPU Cray (homo/hybrid) with Intel only! Intel (hybrid) Xeon + MIC Arm (homo) only arm chip, but Nvidia/Arm (hybrid) arm+nvidia Fujitsu (homo) sparc high density low power China (homo/hybrid) with Intel only Room for AMD console chips
34 Chip Architecture Strongly market driven Mobile, Tv set, Screens Video/Image processing Intel ARM NVIDIA Power AMD New arch to compete with ARM Less Xeon, but PHI Main focus on low power mobile chip Qualcomm, Texas inst., Nvidia, ST, ecc new HPC market, server maket GPU alone will not last long ARM+GPU, Power+GPU Embedded market Power+GPU, only chance for HPC Console market Still some chance for HPC
Evoluzione dell Infrastruttura di Calcolo e Data Analytics per la ricerca
 Evoluzione dell Infrastruttura di Calcolo e Data Analytics per la ricerca Carlo Cavazzoni CINECA Supercomputing Application & Innovation www.cineca.it 21 Aprile 2015 FERMI Name: Fermi Architecture: BlueGene/Q
Evoluzione dell Infrastruttura di Calcolo e Data Analytics per la ricerca Carlo Cavazzoni CINECA Supercomputing Application & Innovation www.cineca.it 21 Aprile 2015 FERMI Name: Fermi Architecture: BlueGene/Q
How Cineca supports IT
 How Cineca supports IT Topics CINECA: an overview Systems and Services for Higher Education HPC for Research Activities and Industries Cineca: the Consortium Not For Profit Founded in 1969 HPC FERMI: TOP500
How Cineca supports IT Topics CINECA: an overview Systems and Services for Higher Education HPC for Research Activities and Industries Cineca: the Consortium Not For Profit Founded in 1969 HPC FERMI: TOP500
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Resource Scheduling Best Practice in Hybrid Clusters
 Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Resource Scheduling Best Practice in Hybrid Clusters C. Cavazzoni a, A. Federico b, D. Galetti a, G. Morelli b, A. Pieretti
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Resource Scheduling Best Practice in Hybrid Clusters C. Cavazzoni a, A. Federico b, D. Galetti a, G. Morelli b, A. Pieretti
How To Build A Supermicro Computer With A 32 Core Power Core (Powerpc) And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (
 And A 32-Core (Powerpc) (Powerpowerpter) (I386) (Amd) (Microcore) (Supermicro) (") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 7 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK
 HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
HETEROGENEOUS HPC, ARCHITECTURE OPTIMIZATION, AND NVLINK Steve Oberlin CTO, Accelerated Computing US to Build Two Flagship Supercomputers SUMMIT SIERRA Partnership for Science 100-300 PFLOPS Peak Performance
Cloud Data Center Acceleration 2015
 Cloud Data Center Acceleration 2015 Agenda! Computer & Storage Trends! Server and Storage System - Memory and Homogenous Architecture - Direct Attachment! Memory Trends! Acceleration Introduction! FPGA
Cloud Data Center Acceleration 2015 Agenda! Computer & Storage Trends! Server and Storage System - Memory and Homogenous Architecture - Direct Attachment! Memory Trends! Acceleration Introduction! FPGA
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes. Anthony Kenisky, VP of North America Sales
 Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
Appro Supercomputer Solutions Best Practices Appro 2012 Deployment Successes Anthony Kenisky, VP of North America Sales About Appro Over 20 Years of Experience 1991 2000 OEM Server Manufacturer 2001-2007
HPC Update: Engagement Model
 HPC Update: Engagement Model MIKE VILDIBILL Director, Strategic Engagements Sun Microsystems mikev@sun.com Our Strategy Building a Comprehensive HPC Portfolio that Delivers Differentiated Customer Value
HPC Update: Engagement Model MIKE VILDIBILL Director, Strategic Engagements Sun Microsystems mikev@sun.com Our Strategy Building a Comprehensive HPC Portfolio that Delivers Differentiated Customer Value
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing
 Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Accelerating Simulation & Analysis with Hybrid GPU Parallelization and Cloud Computing Innovation Intelligence Devin Jensen August 2012 Altair Knows HPC Altair is the only company that: makes HPC tools
Pedraforca: ARM + GPU prototype
 www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
www.bsc.es Pedraforca: ARM + GPU prototype Filippo Mantovani Workshop on exascale and PRACE prototypes Barcelona, 20 May 2014 Overview Goals: Test the performance, scalability, and energy efficiency of
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial
 ISC 13 Tutorial") Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial Bill Barth, Kent Milfeld, Dan Stanzione Tommy Minyard Texas Advanced Computing Center Jim Jeffers, Intel June 2013, Leipzig, Germany
Using the Intel Xeon Phi (with the Stampede Supercomputer) ISC 13 Tutorial Bill Barth, Kent Milfeld, Dan Stanzione Tommy Minyard Texas Advanced Computing Center Jim Jeffers, Intel June 2013, Leipzig, Germany
Kriterien für ein PetaFlop System
 Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
Kriterien für ein PetaFlop System Rainer Keller, HLRS :: :: :: Context: Organizational HLRS is one of the three national supercomputing centers in Germany. The national supercomputing centers are working
FLOW-3D Performance Benchmark and Profiling. September 2012
 FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
FLOW-3D Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: FLOW-3D, Dell, Intel, Mellanox Compute
Italian Scientific Big Data Initiative
 Italian Scientific Big Data Initiative Sanzio Bassini Director of Supercomputing Application & Innovation Department S.Bassini@cineca.it Casalecchio di Reno (BO) Via Magnanelli 6/3, 40033 Casalecchio di
Italian Scientific Big Data Initiative Sanzio Bassini Director of Supercomputing Application & Innovation Department S.Bassini@cineca.it Casalecchio di Reno (BO) Via Magnanelli 6/3, 40033 Casalecchio di
FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25
 FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25 December 2014 FPGAs in the news» Catapult» Accelerate BING» 2x search acceleration:» ½ the number of servers»
FPGA Acceleration using OpenCL & PCIe Accelerators MEW 25 December 2014 FPGAs in the news» Catapult» Accelerate BING» 2x search acceleration:» ½ the number of servers»
 Introduction History Design Blue Gene/Q Job Scheduler Filesystem Power usage Performance Summary Sequoia is a petascale Blue Gene/Q supercomputer Being constructed by IBM for the National Nuclear Security
Introduction History Design Blue Gene/Q Job Scheduler Filesystem Power usage Performance Summary Sequoia is a petascale Blue Gene/Q supercomputer Being constructed by IBM for the National Nuclear Security
Seeking Opportunities for Hardware Acceleration in Big Data Analytics
 Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER
 CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
CORRIGENDUM TO TENDER FOR HIGH PERFORMANCE SERVER Tender Notice No. 3/2014-15 dated 29.12.2014 (IIT/CE/ENQ/COM/HPC/2014-15/569) Tender Submission Deadline Last date for submission of sealed bids is extended
A quick tutorial on Intel's Xeon Phi Coprocessor
 A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1)
") COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
COMP/CS 605: Intro to Parallel Computing Lecture 01: Parallel Computing Overview (Part 1) Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University
Sun Constellation System: The Open Petascale Computing Architecture
 CAS2K7 13 September, 2007 Sun Constellation System: The Open Petascale Computing Architecture John Fragalla Senior HPC Technical Specialist Global Systems Practice Sun Microsystems, Inc. 25 Years of Technical
CAS2K7 13 September, 2007 Sun Constellation System: The Open Petascale Computing Architecture John Fragalla Senior HPC Technical Specialist Global Systems Practice Sun Microsystems, Inc. 25 Years of Technical
Energy efficient computing on Embedded and Mobile devices. Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez
 Energy efficient computing on Embedded and Mobile devices Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez A brief look at the (outdated) Top500 list Most systems are built
Energy efficient computing on Embedded and Mobile devices Nikola Rajovic, Nikola Puzovic, Lluis Vilanova, Carlos Villavieja, Alex Ramirez A brief look at the (outdated) Top500 list Most systems are built
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Overview of HPC systems and software available within
 Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Overview of HPC systems and software available within Overview Available HPC Systems Ba Cy-Tera Available Visualization Facilities Software Environments HPC System at Bibliotheca Alexandrina SUN cluster
Stovepipes to Clouds. Rick Reid Principal Engineer SGI Federal. 2013 by SGI Federal. Published by The Aerospace Corporation with permission.
 Stovepipes to Clouds Rick Reid Principal Engineer SGI Federal 2013 by SGI Federal. Published by The Aerospace Corporation with permission. Agenda Stovepipe Characteristics Why we Built Stovepipes Cluster
Stovepipes to Clouds Rick Reid Principal Engineer SGI Federal 2013 by SGI Federal. Published by The Aerospace Corporation with permission. Agenda Stovepipe Characteristics Why we Built Stovepipes Cluster
Running on Blue Gene/Q at Argonne Leadership Computing Facility (ALCF)
") Running on Blue Gene/Q at Argonne Leadership Computing Facility (ALCF) ALCF Resources: Machines & Storage Mira (Production) IBM Blue Gene/Q 49,152 nodes / 786,432 cores 768 TB of memory Peak flop rate:
Running on Blue Gene/Q at Argonne Leadership Computing Facility (ALCF) ALCF Resources: Machines & Storage Mira (Production) IBM Blue Gene/Q 49,152 nodes / 786,432 cores 768 TB of memory Peak flop rate:
Supercomputing Resources in BSC, RES and PRACE
 www.bsc.es Supercomputing Resources in BSC, RES and PRACE Sergi Girona, BSC-CNS Barcelona, 23 Septiembre 2015 ICTS 2014, un paso adelante para la RES Past RES members and resources BSC-CNS (MareNostrum)
www.bsc.es Supercomputing Resources in BSC, RES and PRACE Sergi Girona, BSC-CNS Barcelona, 23 Septiembre 2015 ICTS 2014, un paso adelante para la RES Past RES members and resources BSC-CNS (MareNostrum)
Copyright 2013, Oracle and/or its affiliates. All rights reserved.
 1 Oracle SPARC Server for Enterprise Computing Dr. Heiner Bauch Senior Account Architect 19. April 2013 2 The following is intended to outline our general product direction. It is intended for information
1 Oracle SPARC Server for Enterprise Computing Dr. Heiner Bauch Senior Account Architect 19. April 2013 2 The following is intended to outline our general product direction. It is intended for information
The PHI solution. Fujitsu Industry Ready Intel XEON-PHI based solution. SC2013 - Denver
 1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
1 The PHI solution Fujitsu Industry Ready Intel XEON-PHI based solution SC2013 - Denver Industrial Application Challenges Most of existing scientific and technical applications Are written for legacy execution
Hadoop on the Gordon Data Intensive Cluster
 Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
Hadoop on the Gordon Data Intensive Cluster Amit Majumdar, Scientific Computing Applications Mahidhar Tatineni, HPC User Services San Diego Supercomputer Center University of California San Diego Dec 18,
High Performance. CAEA elearning Series. Jonathan G. Dudley, Ph.D. 06/09/2015. 2015 CAE Associates
 High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting
 Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting Introduction Big Data Analytics needs: Low latency data access Fast computing Power efficiency Latest
Emerging storage and HPC technologies to accelerate big data analytics Jerome Gaysse JG Consulting Introduction Big Data Analytics needs: Low latency data access Fast computing Power efficiency Latest
Infrastructure Matters: POWER8 vs. Xeon x86
 Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Advisory Infrastructure Matters: POWER8 vs. Xeon x86 Executive Summary This report compares IBM s new POWER8-based scale-out Power System to Intel E5 v2 x86- based scale-out systems. A follow-on report
Mississippi State University High Performance Computing Collaboratory Brief Overview. Trey Breckenridge Director, HPC
 Mississippi State University High Performance Computing Collaboratory Brief Overview Trey Breckenridge Director, HPC Mississippi State University Public university (Land Grant) founded in 1878 Traditional
Mississippi State University High Performance Computing Collaboratory Brief Overview Trey Breckenridge Director, HPC Mississippi State University Public university (Land Grant) founded in 1878 Traditional
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Visit to the National University for Defense Technology Changsha, China. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Visit to the National University for Defense Technology Changsha, China Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 3, 2013 On May 28-29, 2013, I had the opportunity to attend
Visit to the National University for Defense Technology Changsha, China Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 3, 2013 On May 28-29, 2013, I had the opportunity to attend
Overview of HPC Resources at Vanderbilt
 Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
Overview of HPC Resources at Vanderbilt Will French Senior Application Developer and Research Computing Liaison Advanced Computing Center for Research and Education June 10, 2015 2 Computing Resources
ECDF Infrastructure Refresh - Requirements Consultation Document
 Edinburgh Compute & Data Facility - December 2014 ECDF Infrastructure Refresh - Requirements Consultation Document Introduction In order to sustain the University s central research data and computing
Edinburgh Compute & Data Facility - December 2014 ECDF Infrastructure Refresh - Requirements Consultation Document Introduction In order to sustain the University s central research data and computing
Data Center and Cloud Computing Market Landscape and Challenges
 Data Center and Cloud Computing Market Landscape and Challenges Manoj Roge, Director Wired & Data Center Solutions Xilinx Inc. #OpenPOWERSummit 1 Outline Data Center Trends Technology Challenges Solution
Data Center and Cloud Computing Market Landscape and Challenges Manoj Roge, Director Wired & Data Center Solutions Xilinx Inc. #OpenPOWERSummit 1 Outline Data Center Trends Technology Challenges Solution
Headline in Arial Bold 30pt. The Need For Speed. Rick Reid Principal Engineer SGI
 Headline in Arial Bold 30pt The Need For Speed Rick Reid Principal Engineer SGI Commodity Systems Linux Red Hat SUSE SE-Linux X86-64 Intel Xeon AMD Scalable Programming Model MPI Global Data Access NFS
Headline in Arial Bold 30pt The Need For Speed Rick Reid Principal Engineer SGI Commodity Systems Linux Red Hat SUSE SE-Linux X86-64 Intel Xeon AMD Scalable Programming Model MPI Global Data Access NFS
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
RWTH GPU Cluster. Sandra Wienke wienke@rz.rwth-aachen.de November 2012. Rechen- und Kommunikationszentrum (RZ) Fotos: Christian Iwainsky
 Fotos: Christian Iwainsky") RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
RWTH GPU Cluster Fotos: Christian Iwainsky Sandra Wienke wienke@rz.rwth-aachen.de November 2012 Rechen- und Kommunikationszentrum (RZ) The RWTH GPU Cluster GPU Cluster: 57 Nvidia Quadro 6000 (Fermi) innovative
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION
 DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
DIABLO TECHNOLOGIES MEMORY CHANNEL STORAGE AND VMWARE VIRTUAL SAN : VDI ACCELERATION A DIABLO WHITE PAPER AUGUST 2014 Ricky Trigalo Director of Business Development Virtualization, Diablo Technologies
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Agenda. HPC Software Stack. HPC Post-Processing Visualization. Case Study National Scientific Center. European HPC Benchmark Center Montpellier PSSC
 HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
HPC Architecture End to End Alexandre Chauvin Agenda HPC Software Stack Visualization National Scientific Center 2 Agenda HPC Software Stack Alexandre Chauvin Typical HPC Software Stack Externes LAN Typical
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC
 OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
OpenPOWER Outlook AXEL KOEHLER SR. SOLUTION ARCHITECT HPC Driving industry innovation The goal of the OpenPOWER Foundation is to create an open ecosystem, using the POWER Architecture to share expertise,
Build an Energy Efficient Supercomputer from Items You can Find in Your Home (Sort of)!
!") Build an Energy Efficient Supercomputer from Items You can Find in Your Home (Sort of)! Marty Deneroff Chief Technology Officer Green Wave Systems, Inc. deneroff@grnwv.com 1 Using COTS Intellectual Property,
Build an Energy Efficient Supercomputer from Items You can Find in Your Home (Sort of)! Marty Deneroff Chief Technology Officer Green Wave Systems, Inc. deneroff@grnwv.com 1 Using COTS Intellectual Property,
HP ProLiant BL660c Gen9 and Microsoft SQL Server 2014 technical brief
 Technical white paper HP ProLiant BL660c Gen9 and Microsoft SQL Server 2014 technical brief Scale-up your Microsoft SQL Server environment to new heights Table of contents Executive summary... 2 Introduction...
Technical white paper HP ProLiant BL660c Gen9 and Microsoft SQL Server 2014 technical brief Scale-up your Microsoft SQL Server environment to new heights Table of contents Executive summary... 2 Introduction...
ANALYSIS OF SUPERCOMPUTER DESIGN
 ANALYSIS OF SUPERCOMPUTER DESIGN CS/ECE 566 Parallel Processing Fall 2011 1 Anh Huy Bui Nilesh Malpekar Vishnu Gajendran AGENDA Brief introduction of supercomputer Supercomputer design concerns and analysis
ANALYSIS OF SUPERCOMPUTER DESIGN CS/ECE 566 Parallel Processing Fall 2011 1 Anh Huy Bui Nilesh Malpekar Vishnu Gajendran AGENDA Brief introduction of supercomputer Supercomputer design concerns and analysis
Part I Courses Syllabus
 Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Review of SC13; Look Ahead to HPC in 2014. Addison Snell addison@intersect360.com
 Review of SC13; Look Ahead to HPC in 2014 Addison Snell addison@intersect360.com New at Intersect360 Research HPC500 user organization, www.hpc500.com Goal: 500 users worldwide, demographically representative
Review of SC13; Look Ahead to HPC in 2014 Addison Snell addison@intersect360.com New at Intersect360 Research HPC500 user organization, www.hpc500.com Goal: 500 users worldwide, demographically representative
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 19 13:00-13:30 Welcome
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 19 13:00-13:30 Welcome
Data Sheet FUJITSU Server PRIMERGY CX400 M1 Multi-Node Server Enclosure
 Data Sheet FUJITSU Server PRIMERGY CX400 M1 Multi-Node Server Enclosure Data Sheet FUJITSU Server PRIMERGY CX400 M1 Multi-Node Server Enclosure Scale-Out Smart for HPC, Cloud and Hyper-Converged Computing
Data Sheet FUJITSU Server PRIMERGY CX400 M1 Multi-Node Server Enclosure Data Sheet FUJITSU Server PRIMERGY CX400 M1 Multi-Node Server Enclosure Scale-Out Smart for HPC, Cloud and Hyper-Converged Computing
Xeon+FPGA Platform for the Data Center
 Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
PRIMERGY server-based High Performance Computing solutions
 PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
PRIMERGY server-based High Performance Computing solutions PreSales - May 2010 - HPC Revenue OS & Processor Type Increasing standardization with shift in HPC to x86 with 70% in 2008.. HPC revenue by operating
2015 Global Technology conference. Diane Bryant Senior Vice President & General Manager Data Center Group Intel Corporation
 2015 Global Technology conference Diane Bryant Senior Vice President & General Manager Data Center Group Intel Corporation Risk Factors The above statements and any others in this document that refer to
2015 Global Technology conference Diane Bryant Senior Vice President & General Manager Data Center Group Intel Corporation Risk Factors The above statements and any others in this document that refer to
Cloud Servers in the Datacenter: The Evolution of Density-Optimized
 Cloud Servers in the Datacenter: The Evolution of Density-Optimized Jean S. Bozman Research Vice President IDC Enterprise Platforms Group October 24, 2013 Copyright 2010 IDC. Reproduction is forbidden
Cloud Servers in the Datacenter: The Evolution of Density-Optimized Jean S. Bozman Research Vice President IDC Enterprise Platforms Group October 24, 2013 Copyright 2010 IDC. Reproduction is forbidden
Graphics Cards and Graphics Processing Units. Ben Johnstone Russ Martin November 15, 2011
 Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Graphics Cards and Graphics Processing Units Ben Johnstone Russ Martin November 15, 2011 Contents Graphics Processing Units (GPUs) Graphics Pipeline Architectures 8800-GTX200 Fermi Cayman Performance Analysis
Data Centric Systems (DCS)
") Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
Data Centric Systems (DCS) Architecture and Solutions for High Performance Computing, Big Data and High Performance Analytics High Performance Computing with Data Centric Systems 1 Data Centric Systems
SOSCIP Platforms. SOSCIP Platforms
 SOSCIP Platforms SOSCIP Platforms 1 SOSCIP HPC Platforms Blue Gene/Q Cloud Analytics Agile Large Memory System 2 SOSCIP Platforms Blue Gene/Q Platform 3 top500.org Rank Site System Cores Rmax (TFlop/s)
SOSCIP Platforms SOSCIP Platforms 1 SOSCIP HPC Platforms Blue Gene/Q Cloud Analytics Agile Large Memory System 2 SOSCIP Platforms Blue Gene/Q Platform 3 top500.org Rank Site System Cores Rmax (TFlop/s)
ECLIPSE Best Practices Performance, Productivity, Efficiency. March 2009
 ECLIPSE Best Practices Performance, Productivity, Efficiency March 29 ECLIPSE Performance, Productivity, Efficiency The following research was performed under the HPC Advisory Council activities HPC Advisory
ECLIPSE Best Practices Performance, Productivity, Efficiency March 29 ECLIPSE Performance, Productivity, Efficiency The following research was performed under the HPC Advisory Council activities HPC Advisory
Hyperscale. The new frontier for HPC. Philippe Trautmann. HPC/POD Sales Manager EMEA March 13th, 2011
 Hyperscale The new frontier for HPC Philippe Trautmann HPC/POD Sales Manager EMEA March 13th, 2011 Hyperscale the new frontier for HPC New HPC customer requirements demand a shift in technology and market
Hyperscale The new frontier for HPC Philippe Trautmann HPC/POD Sales Manager EMEA March 13th, 2011 Hyperscale the new frontier for HPC New HPC customer requirements demand a shift in technology and market
Current Status of FEFS for the K computer
 Current Status of FEFS for the K computer Shinji Sumimoto Fujitsu Limited Apr.24 2012 LUG2012@Austin Outline RIKEN and Fujitsu are jointly developing the K computer * Development continues with system
Current Status of FEFS for the K computer Shinji Sumimoto Fujitsu Limited Apr.24 2012 LUG2012@Austin Outline RIKEN and Fujitsu are jointly developing the K computer * Development continues with system
FPGA Accelerator Virtualization in an OpenPOWER cloud. Fei Chen, Yonghua Lin IBM China Research Lab
 FPGA Accelerator Virtualization in an OpenPOWER cloud Fei Chen, Yonghua Lin IBM China Research Lab Trend of Acceleration Technology Acceleration in Cloud is Taking Off Used FPGA to accelerate Bing search
FPGA Accelerator Virtualization in an OpenPOWER cloud Fei Chen, Yonghua Lin IBM China Research Lab Trend of Acceleration Technology Acceleration in Cloud is Taking Off Used FPGA to accelerate Bing search
High Performance Computing in CST STUDIO SUITE
 High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
High Performance Computing in CST STUDIO SUITE Felix Wolfheimer GPU Computing Performance Speedup 18 16 14 12 10 8 6 4 2 0 Promo offer for EUC participants: 25% discount for K40 cards Speedup of Solver
PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of
 PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of Directors PRACE aisbl, a persistent pan-european supercomputing
PRACE: access to Tier-0 systems and enabling the access to ExaScale systems Dr. Sergi Girona Managing Director and Chair of the PRACE Board of Directors PRACE aisbl, a persistent pan-european supercomputing
Boost Database Performance with the Cisco UCS Storage Accelerator
 Boost Database Performance with the Cisco UCS Storage Accelerator Performance Brief February 213 Highlights Industry-leading Performance and Scalability Offloading full or partial database structures to
Boost Database Performance with the Cisco UCS Storage Accelerator Performance Brief February 213 Highlights Industry-leading Performance and Scalability Offloading full or partial database structures to
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Experiences With Mobile Processors for Energy Efficient HPC
 Experiences With Mobile Processors for Energy Efficient HPC Nikola Rajovic, Alejandro Rico, James Vipond, Isaac Gelado, Nikola Puzovic, Alex Ramirez Barcelona Supercomputing Center Universitat Politècnica
Experiences With Mobile Processors for Energy Efficient HPC Nikola Rajovic, Alejandro Rico, James Vipond, Isaac Gelado, Nikola Puzovic, Alex Ramirez Barcelona Supercomputing Center Universitat Politècnica
LS DYNA Performance Benchmarks and Profiling. January 2009
 LS DYNA Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center The
LS DYNA Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox HPC Advisory Council Cluster Center The
ECLIPSE Performance Benchmarks and Profiling. January 2009
 ECLIPSE Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox, Schlumberger HPC Advisory Council Cluster
ECLIPSE Performance Benchmarks and Profiling January 2009 Note The following research was performed under the HPC Advisory Council activities AMD, Dell, Mellanox, Schlumberger HPC Advisory Council Cluster
SUN HARDWARE FROM ORACLE: PRICING FOR EDUCATION
 SUN HARDWARE FROM ORACLE: PRICING FOR EDUCATION AFFORDABLE, RELIABLE, AND GREAT PRICES FOR EDUCATION Optimized Sun systems run Oracle and other leading operating and virtualization platforms with greater
SUN HARDWARE FROM ORACLE: PRICING FOR EDUCATION AFFORDABLE, RELIABLE, AND GREAT PRICES FOR EDUCATION Optimized Sun systems run Oracle and other leading operating and virtualization platforms with greater
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
Supercomputing 2004 - Status und Trends (Conference Report) Peter Wegner
 Peter Wegner") (Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
(Conference Report) Peter Wegner SC2004 conference Top500 List BG/L Moors Law, problems of recent architectures Solutions Interconnects Software Lattice QCD machines DESY @SC2004 QCDOC Conclusions Technical
AppliedMicro s X-Gene: Minimizing Power in Data-Center Servers
 AppliedMicro s X-Gene: Minimizing Power in Data-Center Servers By Linley Gwennap Principal Analyst, The Linley Group July 2012 www.linleygroup.com AppliedMicro s X-Gene: Minimizing Power in Data-Center
AppliedMicro s X-Gene: Minimizing Power in Data-Center Servers By Linley Gwennap Principal Analyst, The Linley Group July 2012 www.linleygroup.com AppliedMicro s X-Gene: Minimizing Power in Data-Center
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS
 AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS") A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
A GPU COMPUTING PLATFORM (SAGA) AND A CFD CODE ON GPU FOR AEROSPACE APPLICATIONS SUDHAKARAN.G APCF, AERO, VSSC, ISRO 914712564742 g_suhakaran@vssc.gov.in THOMAS.C.BABU APCF, AERO, VSSC, ISRO 914712565833
PCI Express Impact on Storage Architectures and Future Data Centers. Ron Emerick, Oracle Corporation
 PCI Express Impact on Storage Architectures and Future Data Centers Ron Emerick, Oracle Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies
PCI Express Impact on Storage Architectures and Future Data Centers Ron Emerick, Oracle Corporation SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies
Fujitsu PRIMERGY Servers Portfolio
 Fujitsu Servers Portfolio Complete server solutions that drive your success shaping tomorrow with you Higher IT efficiency and reduced total cost of ownership Fujitsu Micro and Tower Servers MX130 S2 TX100
Fujitsu Servers Portfolio Complete server solutions that drive your success shaping tomorrow with you Higher IT efficiency and reduced total cost of ownership Fujitsu Micro and Tower Servers MX130 S2 TX100
GTC Presentation March 19, 2013. Copyright 2012 Penguin Computing, Inc. All rights reserved
 GTC Presentation March 19, 2013 Copyright 2012 Penguin Computing, Inc. All rights reserved Session S3552 Room 113 S3552 - Using Tesla GPUs, Reality Server and Penguin Computing's Cloud for Visualizing
GTC Presentation March 19, 2013 Copyright 2012 Penguin Computing, Inc. All rights reserved Session S3552 Room 113 S3552 - Using Tesla GPUs, Reality Server and Penguin Computing's Cloud for Visualizing
The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
 WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
WS on Models, Algorithms and Methodologies for Hierarchical Parallelism in new HPC Systems The High Performance Internet of Things: using GVirtuS for gluing cloud computing and ubiquitous connected devices
www.thinkparq.com www.beegfs.com
 www.thinkparq.com www.beegfs.com KEY ASPECTS Maximum Flexibility Maximum Scalability BeeGFS supports a wide range of Linux distributions such as RHEL/Fedora, SLES/OpenSuse or Debian/Ubuntu as well as a
www.thinkparq.com www.beegfs.com KEY ASPECTS Maximum Flexibility Maximum Scalability BeeGFS supports a wide range of Linux distributions such as RHEL/Fedora, SLES/OpenSuse or Debian/Ubuntu as well as a
SGI High Performance Computing
 SGI High Performance Computing Accelerate time to discovery, innovation, and profitability 2014 SGI SGI Company Proprietary 1 Typical Use Cases for SGI HPC Products Large scale-out, distributed memory
SGI High Performance Computing Accelerate time to discovery, innovation, and profitability 2014 SGI SGI Company Proprietary 1 Typical Use Cases for SGI HPC Products Large scale-out, distributed memory
High Performance Computing, an Introduction to
 High Performance ing, an Introduction to Nicolas Renon, Ph. D, Research Engineer in Scientific ations CALMIP - DTSI Université Paul Sabatier University of Toulouse (nicolas.renon@univ-tlse3.fr) Michel
High Performance ing, an Introduction to Nicolas Renon, Ph. D, Research Engineer in Scientific ations CALMIP - DTSI Université Paul Sabatier University of Toulouse (nicolas.renon@univ-tlse3.fr) Michel
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age
 Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Scalable and High Performance Computing for Big Data Analytics in Understanding the Human Dynamics in the Mobile Age Xuan Shi GRA: Bowei Xue University of Arkansas Spatiotemporal Modeling of Human Dynamics
Michael Kagan. michael@mellanox.com
 Virtualization in Data Center The Network Perspective Michael Kagan CTO, Mellanox Technologies michael@mellanox.com Outline Data Center Transition Servers S as a Service Network as a Service IO as a Service
Virtualization in Data Center The Network Perspective Michael Kagan CTO, Mellanox Technologies michael@mellanox.com Outline Data Center Transition Servers S as a Service Network as a Service IO as a Service
HPC Cloud. Focus on your research. Floris Sluiter Project leader SARA
 HPC Cloud Focus on your research Floris Sluiter Project leader SARA Why an HPC Cloud? Christophe Blanchet, IDB - Infrastructure Distributing Biology: Big task to port them all to your favorite architecture
HPC Cloud Focus on your research Floris Sluiter Project leader SARA Why an HPC Cloud? Christophe Blanchet, IDB - Infrastructure Distributing Biology: Big task to port them all to your favorite architecture
Cosmological simulations on High Performance Computers
 Cosmological simulations on High Performance Computers Cosmic Web Morphology and Topology Cosmological workshop meeting Warsaw, 12-17 July 2011 Maciej Cytowski Interdisciplinary Centre for Mathematical
Cosmological simulations on High Performance Computers Cosmic Web Morphology and Topology Cosmological workshop meeting Warsaw, 12-17 July 2011 Maciej Cytowski Interdisciplinary Centre for Mathematical
HP Moonshot: An Accelerator for Hyperscale Workloads
 HP Moonshot: An Accelerator for Hyperscale Workloads Sponsored by HP, see HP Moonshot for more information www.hp.com/go/moonshot Executive Summary Hyperscale data center customers have specialized workloads,
HP Moonshot: An Accelerator for Hyperscale Workloads Sponsored by HP, see HP Moonshot for more information www.hp.com/go/moonshot Executive Summary Hyperscale data center customers have specialized workloads,
INDIAN INSTITUTE OF TECHNOLOGY KANPUR Department of Mechanical Engineering
 INDIAN INSTITUTE OF TECHNOLOGY KANPUR Department of Mechanical Engineering Enquiry No: Enq/IITK/ME/JB/02 Enquiry Date: 14/12/15 Last Date of Submission: 21/12/15 Formal quotations are invited for HPC cluster.
INDIAN INSTITUTE OF TECHNOLOGY KANPUR Department of Mechanical Engineering Enquiry No: Enq/IITK/ME/JB/02 Enquiry Date: 14/12/15 Last Date of Submission: 21/12/15 Formal quotations are invited for HPC cluster.
How to Deploy OpenStack on TH-2 Supercomputer Yusong Tan, Bao Li National Supercomputing Center in Guangzhou April 10, 2014
 How to Deploy OpenStack on TH-2 Supercomputer Yusong Tan, Bao Li National Supercomputing Center in Guangzhou April 10, 2014 2014 年 云 计 算 效 率 与 能 耗 暨 第 一 届 国 际 云 计 算 咨 询 委 员 会 中 国 高 峰 论 坛 Contents Background
How to Deploy OpenStack on TH-2 Supercomputer Yusong Tan, Bao Li National Supercomputing Center in Guangzhou April 10, 2014 2014 年 云 计 算 效 率 与 能 耗 暨 第 一 届 国 际 云 计 算 咨 询 委 员 会 中 国 高 峰 论 坛 Contents Background
Interconnect Your Future Enabling the Best Datacenter Return on Investment. TOP500 Supercomputers, June 2016
 Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, June 2016 Mellanox Leadership in High Performance Computing Most Deployed Interconnect in High Performance
Interconnect Your Future Enabling the Best Datacenter Return on Investment TOP500 Supercomputers, June 2016 Mellanox Leadership in High Performance Computing Most Deployed Interconnect in High Performance
Scientific Computing Data Management Visions
 Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
Scientific Computing Data Management Visions ELI-Tango Workshop Szeged, 24-25 February 2015 Péter Szász Group Leader Scientific Computing Group ELI-ALPS Scientific Computing Group Responsibilities Data
Evaluation Report: HP Blade Server and HP MSA 16GFC Storage Evaluation
 Evaluation Report: HP Blade Server and HP MSA 16GFC Storage Evaluation Evaluation report prepared under contract with HP Executive Summary The computing industry is experiencing an increasing demand for
Evaluation Report: HP Blade Server and HP MSA 16GFC Storage Evaluation Evaluation report prepared under contract with HP Executive Summary The computing industry is experiencing an increasing demand for
How To Write An Article On An Hp Appsystem For Spera Hana
 Technical white paper HP AppSystem for SAP HANA Distributed architecture with 3PAR StoreServ 7400 storage Table of contents Executive summary... 2 Introduction... 2 Appliance components... 3 3PAR StoreServ
Technical white paper HP AppSystem for SAP HANA Distributed architecture with 3PAR StoreServ 7400 storage Table of contents Executive summary... 2 Introduction... 2 Appliance components... 3 3PAR StoreServ
Data Sheet FUJITSU Server PRIMERGY CX272 S1 Dual socket server node for PRIMERGY CX420 cluster server
 Data Sheet FUJITSU Server PRIMERGY CX272 S1 Dual socket node for PRIMERGY CX420 cluster Data Sheet FUJITSU Server PRIMERGY CX272 S1 Dual socket node for PRIMERGY CX420 cluster Strong Performance and Cluster
Data Sheet FUJITSU Server PRIMERGY CX272 S1 Dual socket node for PRIMERGY CX420 cluster Data Sheet FUJITSU Server PRIMERGY CX272 S1 Dual socket node for PRIMERGY CX420 cluster Strong Performance and Cluster
Case Study on Productivity and Performance of GPGPUs
 Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Server Consolidation for SAP ERP on IBM ex5 enterprise systems with Intel Xeon Processors:
 Server Consolidation for SAP ERP on IBM ex5 enterprise systems with Intel Xeon Processors: Lowering Total Cost of Ownership An Alinean White Paper Published by: Alinean, Inc. 201 S. Orange Ave Suite 1210
Server Consolidation for SAP ERP on IBM ex5 enterprise systems with Intel Xeon Processors: Lowering Total Cost of Ownership An Alinean White Paper Published by: Alinean, Inc. 201 S. Orange Ave Suite 1210