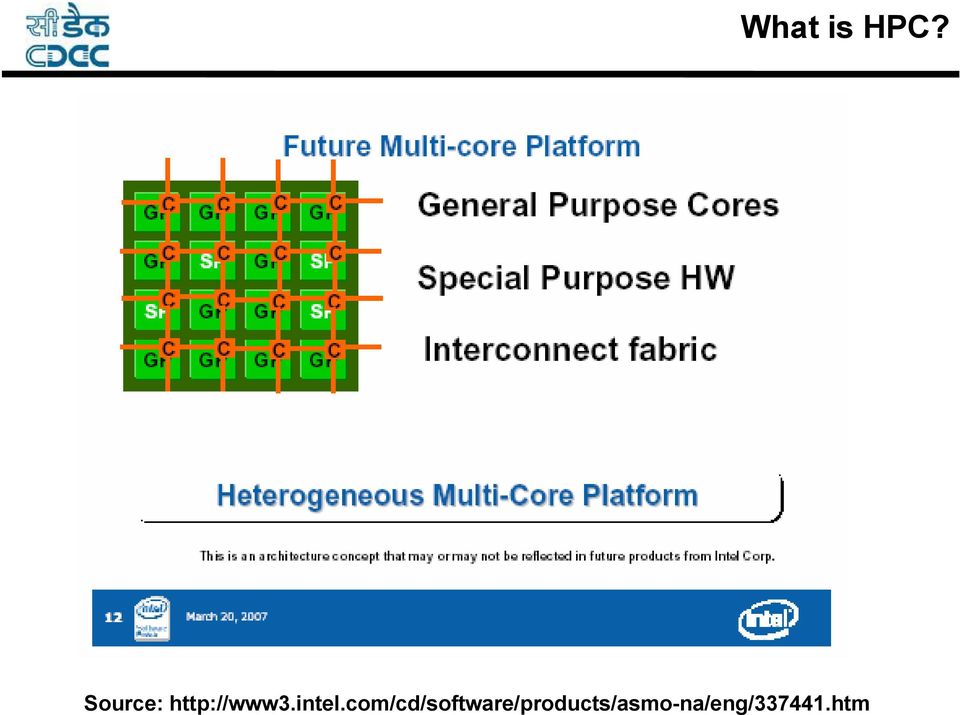
What is High Performance Computing?
|
|
|
- Julius Haynes
- 7 years ago
- Views:
Transcription
1 What is High Performance Computing? V. Sundararajan Scientific and Engineering Computing Group Centre for Development of Advanced Computing Pune

2 Plan Why HPC? Parallel Architectures Current Machines Issues Arguments against Parallel Computing Introduction to MPI A Simple example

3 Definition Supercomputing Parallel computing: Parallel Supercomputers High Performance Computing: includes computers, networks, algorithms and environments to make such systems usable. (range from small cluster of PCs to fastest supercomputers)

4 Source:

5 Increased Cores add value Physical Limits of single processor speed 2007 (Predicted by Paul Messina in 1997) Pentium 3600 MHz <0.3 ns Light travels 30 cm in 1 ns Signal is already 10% of its speed Red-Shift: Reduction in clock speed

6 Why HPC? To simulate a bio-molecule of atoms Non-bond energy term ~ 10 8 operations For 1 microsecond simulation ~ 10 9 steps ~ operations On a 500 MFLOPS machine (5x10 8 operations per second) takes 2x10 9 secs (About 60 years) (This may be on a machine of 5000 MFLOPS peak) Need to do large no of simulations for even larger molecules
 takes 2x10 9 secs (About 60 years) (This may be on a machine of")
7 Why HPC? Biggest CCSD(T) calculation: David A. Dixon, ( ) Hydrocarbon Fuels: Combustion - Need Heats of Formation to predict reaction equilibria and bond energies; octane(c8h18); aug-cc-pvqz= 1468 basis functions, 50 electrons; Used NWChem on 1400 Itanium-2 processors (2 and 4 GB/proc) on the EMSL MSCF Linux cluster. Took 23 hours to complete (3.5 yr on a desktop machine).
; aug-cc-pvqz= 1468 basis functions, 50 electrons; Used NWChem on 1400 Itanium-2")
8 Parallel Architectures 1. Single Instruction Single Data (SISD) Sequential machines. 2. Multiple Instructions Single Data (MISD) 3. Single Instruction Multiple Data (SIMD) Array of processors with single control unit. Connection Machine (CM - 5) 4. Multiple Instructions Multiple Data (MIMD) Several Processors with several Instructions and Data Stream. All the recent parallel machines
 4.")
9 Tightly Coupled MIMD Shared Memory Centralised (Uniform Access) Load/Store Memory INTERCONNECTION NETWORK P P P Symmetric Multiprocessors P - Processor

10 Loosely Coupled MIMD Message Interconnection Network Receive Message M M M Load/ store P P P Distributed Message-Passing Machines Also Called Message Passing Architecture Send Message M - Memory P - Processor

11 Shared Memory : Scalable up to about 64 or 128 processors but costly Memory contention problem Synchronisation problem Easy to code Distributed Memory : Architectures Scalable up to larger no. of processors Message passing overheads Latency hiding Difficult to code

12 Cluster of Computers Programming Environment (Java, C, F95, MPI, OpenMP) Other Subsystems User Interface (Database, OLTP) Single System Image Infrastructure OS Node OS Node OS Node Commodity Interconnect

13 Source:

14 Source:

15 Source:
16 Simulation Techniques N-body simulations Finite difference Finite Element Pattern evolution Classic methods - Do Large scale problems Faster New class of Solutions

17 Parallel Problem Solving Methodologies Data parallelism Pipelining Functional parallelism

18 Parallel Programming Models 1. Directives to Compiler (OpenMP, threads) 2. Using Parallel libraries (SCALAPACK, PARPACK) 3. Message passing (MPI)

19 Programming Style SPMD : Single program multiple Data. Each processor executes the same program but with different data. MPMD : Multiple programs, multiple data. Each processor executes a different program. Usually this is a master slave model.

20 Performance Issues 1. Speed up = Time for sequential code Time for parallel code S P = Ts Tp 1 < S P < P Sp 2. Efficiency E P = 0 < E P < 1 p E P = 1 => S P = P 100% efficient

21 Communication Overheads Latency Startup time for each message transaction 1 µs Bandwidth The rate at which the messages are transmitted across the nodes / processors 10 Gbits / Sec.
22 Strongest argument Amdahl s Law 1 S = f + (1-f) / P f = Sequential part of the code. Ex. f = 0.1 assume P = 10 processes 1 S = (0.9) / 10 1 = (0.09) As P S 10 Whatever we do, 10 is the maximum speedup possible.
23 What is MPI? An industry-wide standard protocol for passing messages between parallel processors. Small: Require only six library functions to write any parallel code Large: There are more than 200 functions in MPI-2
24 What is MPI? It uses communicator a handle to identify a set of processes and topology for different pattern of communication A communicator is a collection of processes that can send messages to each other. A topology is a structure imposed on the processes in a communicator that allows the processes to be addressed in different ways Can be called by Fortran, C or C++ codes
25 Small MPI MPI_Init MPI_Comm_size MPI_Comm_rank MPI_Send MPI_Recv MPI_Finalize
26 MPI_Init Initialize the MPI execution environment Synopsis include "mpif.h" Call MPI_Init(Error) Output Parameter Error Error value (integer) 0 means no error Default communicator MPI_COMM_WORLD is initialised
27 MPI_Comm_size Determines the size of the group associated with a communictor Synopsis include "mpif.h Call MPI_Comm_size ( MPI_COMM_WORLD,size,Error) Input Parameter MPI_COMM_WORLD default communicator (handle) Output Parameter size - number of processes in the group of communicator MPI_COMM_WORLD (integer) Error Error value (integer)
28 MPI_Comm_rank Determines the rank of the calling process in the communicator Synopsis include "mpif.h" Call MPI_Comm_rank ( MPI_COMM_WORLD, myid, Error ) Input Parameters MPI_COMM_WORLD default communicator (handle) Output Parameter myid - rank of the calling process in group of communicator MPI_COMM_WORLD (integer) Error Error value (integer)
29 MPI_Send Performs a basic send Synopsis include "mpif.h" Call MPI_Send( buf, count, datatype, dest, tag, MPI_Comm_World,Error) Input Parameters buf count datatype dest tag comm Output Parameter Error initial address of send buffer (choice) number of elements in send buffer (nonnegative integer) data type of each send buffer element (handle) rank of destination (integer) message tag (integer) communicator (handle) Error value (integer) Notes This routine may block until the message is received.
30 MPI_Recv Basic receive Synopsis include "mpif.h" Call MPI_Recv(buf, count, datatype, source, tag, MPI_Comm_World, status, Error ) Output Parameters buf status Error Input Parameters count datatype source tag initial address of receive buffer (choice) status object (Status) Error value (integer) maximum number of elements in receive buffer (integer) datatype of each receive buffer element (handle) rank of source (integer) message tag (integer)
31 MPI_Comm_World communicator (handle) Notes The count argument indicates the maximum length of a message; the actual number can be determined with MPI_Get_count.
32 MPI_Finalize Terminates MPI execution environment Synopsis include "mpif.h" Call MPI_Finalize() Notes All processes must call this routine before exit. The number of processes running after this routine is called is undefined; it is best not to perform anything more than a return after calling MPI_Finalize.
33 Examples Summation Calculation of pi Matrix Multiplication
34 Sequential Flow Start Input Do the Computation Output Stop
35 Parallel using MPI Start Start Input Do the Computation Output Stop Input Divide the Work Communicate input Do the computation Collect the results Output Stop
36 Simple Example Let us consider summation of real numbers between 0 and 1. To compute i x i for (i=1,2, ) This may sound trivial but, useful in illustrating the practical aspects of parallel program development Total computation of operations to be done On a PC, it would take roughly 500 secs assuming 2 GFLOPS sustained performance Can we speed this up and finish in 1/8 th on 8 processors
37 Sequential Code program summation Implicit none double precision x,xsum integer i,iseed xsum=0.0 do i=1, x=float(mod(i,10))/ xsum=xsum+x enddo print *, xsum=,xsum stop end
38 Parallel Code SPMD style program summation Implicit none double precision x,xsum integer i xsum=0.0 do i=1, x=float(mod(i,10))/ xsum=xsum+x enddo print *, xsum=,xsum stop end program summation include mpif.h Implicit none double precision x,xsum,tsum integer i Integer myid,nprocs,ierr Call MPI_INIT(IERR) Call MPI_COMM_RANK(MPI_COMM_WORLD,myid,IERR) Call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs,IERR) xsum=0.0 do i=myid+1, ,nprocs x=float(mod(i,10))/ xsum=xsum+x enddo Call MPI_REDUCE(xsum,tsum,1,MPI_DOUBLE_PRECISION, MPI_SUM,0,MPI_COMM_WORLD,IERR) If(myid.eq.0) print *, tsum=,tsum stop end
39 Sequential vs Parallel Sequential Design algorithm step by step and write the code assuming single process to be executed f90 o sum.exe sum.f gcc o sum.exe sum.c Only one executable created sum.exe Executes a single process Single point of failure Good tools available for debugging Parallel Redesign the same algorithm with the distribution of work assuming many processes to be executed simultaneously mpif90 o sum.exe sum.f mpicc o sum.exe sum.f Only one executable created mpirun np 8 sum.exe Executes 8 processes simultaneously Cooperative operations but, multiple points of failure; Tools are still evolving towards debugging parallel executions.
40 A Quote to conclude James Bailey (New Era in Computation Ed. Metropolis & Rota) We are all still trained to believe that orderly, sequential processes are more likely to be true. As we were reshaping our computers, so simultaneously were they reshaping us. May be when things happen in this world, they actually happen in parallel
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
High Performance Computing
 High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
High Performance Computing Trey Breckenridge Computing Systems Manager Engineering Research Center Mississippi State University What is High Performance Computing? HPC is ill defined and context dependent.
Lecture 6: Introduction to MPI programming. Lecture 6: Introduction to MPI programming p. 1
 Lecture 6: Introduction to MPI programming Lecture 6: Introduction to MPI programming p. 1 MPI (message passing interface) MPI is a library standard for programming distributed memory MPI implementation(s)
Lecture 6: Introduction to MPI programming Lecture 6: Introduction to MPI programming p. 1 MPI (message passing interface) MPI is a library standard for programming distributed memory MPI implementation(s)
Parallelization: Binary Tree Traversal
 By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
By Aaron Weeden and Patrick Royal Shodor Education Foundation, Inc. August 2012 Introduction: According to Moore s law, the number of transistors on a computer chip doubles roughly every two years. First
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015. Hermann Härtig
 LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015 Hermann Härtig ISSUES starting points independent Unix processes and block synchronous execution who does it load migration mechanism
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2015 Hermann Härtig ISSUES starting points independent Unix processes and block synchronous execution who does it load migration mechanism
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Basic Concepts in Parallelization
 1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
1 Basic Concepts in Parallelization Ruud van der Pas Senior Staff Engineer Oracle Solaris Studio Oracle Menlo Park, CA, USA IWOMP 2010 CCS, University of Tsukuba Tsukuba, Japan June 14-16, 2010 2 Outline
High performance computing systems. Lab 1
 High performance computing systems Lab 1 Dept. of Computer Architecture Faculty of ETI Gdansk University of Technology Paweł Czarnul For this exercise, study basic MPI functions such as: 1. for MPI management:
High performance computing systems Lab 1 Dept. of Computer Architecture Faculty of ETI Gdansk University of Technology Paweł Czarnul For this exercise, study basic MPI functions such as: 1. for MPI management:
Lightning Introduction to MPI Programming
 Lightning Introduction to MPI Programming May, 2015 What is MPI? Message Passing Interface A standard, not a product First published 1994, MPI-2 published 1997 De facto standard for distributed-memory
Lightning Introduction to MPI Programming May, 2015 What is MPI? Message Passing Interface A standard, not a product First published 1994, MPI-2 published 1997 De facto standard for distributed-memory
To connect to the cluster, simply use a SSH or SFTP client to connect to:
 RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
Parallel Programming with MPI on the Odyssey Cluster
 Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
Parallel Programming with MPI on the Odyssey Cluster Plamen Krastev Office: Oxford 38, Room 204 Email: plamenkrastev@fas.harvard.edu FAS Research Computing Harvard University Objectives: To introduce you
HPCC - Hrothgar Getting Started User Guide MPI Programming
 HPCC - Hrothgar Getting Started User Guide MPI Programming High Performance Computing Center Texas Tech University HPCC - Hrothgar 2 Table of Contents 1. Introduction... 3 2. Setting up the environment...
HPCC - Hrothgar Getting Started User Guide MPI Programming High Performance Computing Center Texas Tech University HPCC - Hrothgar 2 Table of Contents 1. Introduction... 3 2. Setting up the environment...
Chapter 2 Parallel Architecture, Software And Performance
 Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Chapter 2 Parallel Architecture, Software And Performance UCSB CS140, T. Yang, 2014 Modified from texbook slides Roadmap Parallel hardware Parallel software Input and output Performance Parallel program
Introduction to grid technologies, parallel and cloud computing. Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber
 Introduction to grid technologies, parallel and cloud computing Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber OUTLINES Grid Computing Parallel programming technologies (MPI- Open MP-Cuda )
Introduction to grid technologies, parallel and cloud computing Alaa Osama Allam Saida Saad Mohamed Mohamed Ibrahim Gaber OUTLINES Grid Computing Parallel programming technologies (MPI- Open MP-Cuda )
LS-DYNA Scalability on Cray Supercomputers. Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp.
 LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
LS-DYNA Scalability on Cray Supercomputers Tin-Ting Zhu, Cray Inc. Jason Wang, Livermore Software Technology Corp. WP-LS-DYNA-12213 www.cray.com Table of Contents Abstract... 3 Introduction... 3 Scalability
MPI Application Development Using the Analysis Tool MARMOT
 MPI Application Development Using the Analysis Tool MARMOT HLRS High Performance Computing Center Stuttgart Allmandring 30 D-70550 Stuttgart http://www.hlrs.de 24.02.2005 1 Höchstleistungsrechenzentrum
MPI Application Development Using the Analysis Tool MARMOT HLRS High Performance Computing Center Stuttgart Allmandring 30 D-70550 Stuttgart http://www.hlrs.de 24.02.2005 1 Höchstleistungsrechenzentrum
Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005
 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005... 1
Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005 Compute Cluster Server Lab 3: Debugging the parallel MPI programs in Microsoft Visual Studio 2005... 1
Introduction to Hybrid Programming
 Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
Introduction to Hybrid Programming Hristo Iliev Rechen- und Kommunikationszentrum aixcelerate 2012 / Aachen 10. Oktober 2012 Version: 1.1 Rechen- und Kommunikationszentrum (RZ) Motivation for hybrid programming
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics
 22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
22S:295 Seminar in Applied Statistics High Performance Computing in Statistics Luke Tierney Department of Statistics & Actuarial Science University of Iowa August 30, 2007 Luke Tierney (U. of Iowa) HPC
Building an Inexpensive Parallel Computer
 Res. Lett. Inf. Math. Sci., (2000) 1, 113-118 Available online at http://www.massey.ac.nz/~wwiims/rlims/ Building an Inexpensive Parallel Computer Lutz Grosz and Andre Barczak I.I.M.S., Massey University
Res. Lett. Inf. Math. Sci., (2000) 1, 113-118 Available online at http://www.massey.ac.nz/~wwiims/rlims/ Building an Inexpensive Parallel Computer Lutz Grosz and Andre Barczak I.I.M.S., Massey University
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
10- High Performance Compu5ng
 10- High Performance Compu5ng (Herramientas Computacionales Avanzadas para la Inves6gación Aplicada) Rafael Palacios, Fernando de Cuadra MRE Contents Implemen8ng computa8onal tools 1. High Performance
10- High Performance Compu5ng (Herramientas Computacionales Avanzadas para la Inves6gación Aplicada) Rafael Palacios, Fernando de Cuadra MRE Contents Implemen8ng computa8onal tools 1. High Performance
Interconnect Efficiency of Tyan PSC T-630 with Microsoft Compute Cluster Server 2003
 Interconnect Efficiency of Tyan PSC T-630 with Microsoft Compute Cluster Server 2003 Josef Pelikán Charles University in Prague, KSVI Department, Josef.Pelikan@mff.cuni.cz Abstract 1 Interconnect quality
Interconnect Efficiency of Tyan PSC T-630 with Microsoft Compute Cluster Server 2003 Josef Pelikán Charles University in Prague, KSVI Department, Josef.Pelikan@mff.cuni.cz Abstract 1 Interconnect quality
Session 2: MUST. Correctness Checking
 Center for Information Services and High Performance Computing (ZIH) Session 2: MUST Correctness Checking Dr. Matthias S. Müller (RWTH Aachen University) Tobias Hilbrich (Technische Universität Dresden)
Center for Information Services and High Performance Computing (ZIH) Session 2: MUST Correctness Checking Dr. Matthias S. Müller (RWTH Aachen University) Tobias Hilbrich (Technische Universität Dresden)
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
Computer Architecture TDTS10
 why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
why parallelism? Performance gain from increasing clock frequency is no longer an option. Outline Computer Architecture TDTS10 Superscalar Processors Very Long Instruction Word Processors Parallel computers
OpenMP & MPI CISC 879. Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware
 OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
OpenMP & MPI CISC 879 Tristan Vanderbruggen & John Cavazos Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction OpenMP MPI Model Language extension: directives-based
The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud.
 White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
White Paper 021313-3 Page 1 : A Software Framework for Parallel Programming* The Fastest Way to Parallel Programming for Multicore, Clusters, Supercomputers and the Cloud. ABSTRACT Programming for Multicore,
An Introduction to Parallel Computing/ Programming
 An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
A Lab Course on Computer Architecture
 A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
A Lab Course on Computer Architecture Pedro López José Duato Depto. de Informática de Sistemas y Computadores Facultad de Informática Universidad Politécnica de Valencia Camino de Vera s/n, 46071 - Valencia,
Client/Server Computing Distributed Processing, Client/Server, and Clusters
 Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Client/Server Computing Distributed Processing, Client/Server, and Clusters Chapter 13 Client machines are generally single-user PCs or workstations that provide a highly userfriendly interface to the
Introduction to MPI Programming!
 Introduction to MPI Programming! Rocks-A-Palooza II! Lab Session! 2006 UC Regents! 1! Modes of Parallel Computing! SIMD - Single Instruction Multiple Data!!processors are lock-stepped : each processor
Introduction to MPI Programming! Rocks-A-Palooza II! Lab Session! 2006 UC Regents! 1! Modes of Parallel Computing! SIMD - Single Instruction Multiple Data!!processors are lock-stepped : each processor
Performance of the JMA NWP models on the PC cluster TSUBAME.
 Performance of the JMA NWP models on the PC cluster TSUBAME. K.Takenouchi 1), S.Yokoi 1), T.Hara 1) *, T.Aoki 2), C.Muroi 1), K.Aranami 1), K.Iwamura 1), Y.Aikawa 1) 1) Japan Meteorological Agency (JMA)
Performance of the JMA NWP models on the PC cluster TSUBAME. K.Takenouchi 1), S.Yokoi 1), T.Hara 1) *, T.Aoki 2), C.Muroi 1), K.Aranami 1), K.Iwamura 1), Y.Aikawa 1) 1) Japan Meteorological Agency (JMA)
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Parallel Computation Most slides adapted from David Patterson. Some from Mohomed Younis Parallel Computers Definition: A parallel computer is a collection of processing
CMSC 611: Advanced Computer Architecture Parallel Computation Most slides adapted from David Patterson. Some from Mohomed Younis Parallel Computers Definition: A parallel computer is a collection of processing
MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop
 MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop Joachim Protze and Felix Münchhalfen IT Center RWTH Aachen University February 2014 Content MPI Usage Errors Error Classes Avoiding
MPI Runtime Error Detection with MUST For the 13th VI-HPS Tuning Workshop Joachim Protze and Felix Münchhalfen IT Center RWTH Aachen University February 2014 Content MPI Usage Errors Error Classes Avoiding
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems
 David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
David Rioja Redondo Telecommunication Engineer Englobe Technologies and Systems About me David Rioja Redondo Telecommunication Engineer - Universidad de Alcalá >2 years building and managing clusters UPM
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters
 The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
The Double-layer Master-Slave Model : A Hybrid Approach to Parallel Programming for Multicore Clusters User s Manual for the HPCVL DMSM Library Gang Liu and Hartmut L. Schmider High Performance Computing
Agenda. Using HPC Wales 2
 Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
Using HPC Wales Agenda Infrastructure : An Overview of our Infrastructure Logging in : Command Line Interface and File Transfer Linux Basics : Commands and Text Editors Using Modules : Managing Software
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Parallel Programming
 Parallel Programming Parallel Architectures Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Parallel Architectures Acknowledgements Prof. Felix
Parallel Programming Parallel Architectures Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Parallel Architectures Acknowledgements Prof. Felix
Introduction to Cloud Computing
 Introduction to Cloud Computing Distributed Systems 15-319, spring 2010 11 th Lecture, Feb 16 th Majd F. Sakr Lecture Motivation Understand Distributed Systems Concepts Understand the concepts / ideas
Introduction to Cloud Computing Distributed Systems 15-319, spring 2010 11 th Lecture, Feb 16 th Majd F. Sakr Lecture Motivation Understand Distributed Systems Concepts Understand the concepts / ideas
Multicore Parallel Computing with OpenMP
 Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
Multicore Parallel Computing with OpenMP Tan Chee Chiang (SVU/Academic Computing, Computer Centre) 1. OpenMP Programming The death of OpenMP was anticipated when cluster systems rapidly replaced large
High Performance Computing. Course Notes 2007-2008. HPC Fundamentals
 High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
High Performance Computing Course Notes 2007-2008 2008 HPC Fundamentals Introduction What is High Performance Computing (HPC)? Difficult to define - it s a moving target. Later 1980s, a supercomputer performs
MOSIX: High performance Linux farm
 MOSIX: High performance Linux farm Paolo Mastroserio [mastroserio@na.infn.it] Francesco Maria Taurino [taurino@na.infn.it] Gennaro Tortone [tortone@na.infn.it] Napoli Index overview on Linux farm farm
MOSIX: High performance Linux farm Paolo Mastroserio [mastroserio@na.infn.it] Francesco Maria Taurino [taurino@na.infn.it] Gennaro Tortone [tortone@na.infn.it] Napoli Index overview on Linux farm farm
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
1 Bull, 2011 Bull Extreme Computing Table of Contents HPC Overview. Cluster Overview. FLOPS. 2 Bull, 2011 Bull Extreme Computing HPC Overview Ares, Gerardo, HPC Team HPC concepts HPC: High Performance
White Paper The Numascale Solution: Extreme BIG DATA Computing
 White Paper The Numascale Solution: Extreme BIG DATA Computing By: Einar Rustad ABOUT THE AUTHOR Einar Rustad is CTO of Numascale and has a background as CPU, Computer Systems and HPC Systems De-signer
White Paper The Numascale Solution: Extreme BIG DATA Computing By: Einar Rustad ABOUT THE AUTHOR Einar Rustad is CTO of Numascale and has a background as CPU, Computer Systems and HPC Systems De-signer
McMPI. Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk
 McMPI Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk Outline Yet another MPI library? Managed-code, C#, Windows McMPI, design and implementation details Object-orientation,
McMPI Managed-code MPI library in Pure C# Dr D Holmes, EPCC dholmes@epcc.ed.ac.uk Outline Yet another MPI library? Managed-code, C#, Windows McMPI, design and implementation details Object-orientation,
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Advanced Computer Architecture
 Advanced Computer Architecture Institute for Multimedia and Software Engineering Conduction of Exercises: Institute for Multimedia eda and Software Engineering g BB 315c, Tel: 379-1174 E-mail: marius.rosu@uni-due.de
Advanced Computer Architecture Institute for Multimedia and Software Engineering Conduction of Exercises: Institute for Multimedia eda and Software Engineering g BB 315c, Tel: 379-1174 E-mail: marius.rosu@uni-due.de
Tutorial-4a: Parallel (multi-cpu) Computing
 Computing") HTTP://WWW.HEP.LU.SE/COURSES/MNXB01 Introduction to Programming and Computing for Scientists (2015 HT) Tutorial-4a: Parallel (multi-cpu) Computing Balazs Konya (Lund University) Programming for Scientists
HTTP://WWW.HEP.LU.SE/COURSES/MNXB01 Introduction to Programming and Computing for Scientists (2015 HT) Tutorial-4a: Parallel (multi-cpu) Computing Balazs Konya (Lund University) Programming for Scientists
numascale White Paper The Numascale Solution: Extreme BIG DATA Computing Hardware Accellerated Data Intensive Computing By: Einar Rustad ABSTRACT
 numascale Hardware Accellerated Data Intensive Computing White Paper The Numascale Solution: Extreme BIG DATA Computing By: Einar Rustad www.numascale.com Supemicro delivers 108 node system with Numascale
numascale Hardware Accellerated Data Intensive Computing White Paper The Numascale Solution: Extreme BIG DATA Computing By: Einar Rustad www.numascale.com Supemicro delivers 108 node system with Numascale
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Introduction to High Performance Cluster Computing. Cluster Training for UCL Part 1
 Introduction to High Performance Cluster Computing Cluster Training for UCL Part 1 What is HPC HPC = High Performance Computing Includes Supercomputing HPCC = High Performance Cluster Computing Note: these
Introduction to High Performance Cluster Computing Cluster Training for UCL Part 1 What is HPC HPC = High Performance Computing Includes Supercomputing HPCC = High Performance Cluster Computing Note: these
Lecture 23: Multiprocessors
 Lecture 23: Multiprocessors Today s topics: RAID Multiprocessor taxonomy Snooping-based cache coherence protocol 1 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks
Lecture 23: Multiprocessors Today s topics: RAID Multiprocessor taxonomy Snooping-based cache coherence protocol 1 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks
Supercomputing applied to Parallel Network Simulation
 Supercomputing applied to Parallel Network Simulation David Cortés-Polo Research, Technological Innovation and Supercomputing Centre of Extremadura, CenitS. Trujillo, Spain david.cortes@cenits.es Summary
Supercomputing applied to Parallel Network Simulation David Cortés-Polo Research, Technological Innovation and Supercomputing Centre of Extremadura, CenitS. Trujillo, Spain david.cortes@cenits.es Summary
64-Bit versus 32-Bit CPUs in Scientific Computing
 64-Bit versus 32-Bit CPUs in Scientific Computing Axel Kohlmeyer Lehrstuhl für Theoretische Chemie Ruhr-Universität Bochum March 2004 1/25 Outline 64-Bit and 32-Bit CPU Examples
64-Bit versus 32-Bit CPUs in Scientific Computing Axel Kohlmeyer Lehrstuhl für Theoretische Chemie Ruhr-Universität Bochum March 2004 1/25 Outline 64-Bit and 32-Bit CPU Examples
Symmetric Multiprocessing
 Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
Multicore Computing A multi-core processor is a processing system composed of two or more independent cores. One can describe it as an integrated circuit to which two or more individual processors (called
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Multi-core architectures. Jernej Barbic 15-213, Spring 2007 May 3, 2007
 Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
Multi-core architectures Jernej Barbic 15-213, Spring 2007 May 3, 2007 1 Single-core computer 2 Single-core CPU chip the single core 3 Multi-core architectures This lecture is about a new trend in computer
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp
 Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp Welcome! Who am I? William (Bill) Gropp Professor of Computer Science One of the Creators of
Designing and Building Applications for Extreme Scale Systems CS598 William Gropp www.cs.illinois.edu/~wgropp Welcome! Who am I? William (Bill) Gropp Professor of Computer Science One of the Creators of
RA MPI Compilers Debuggers Profiling. March 25, 2009
 RA MPI Compilers Debuggers Profiling March 25, 2009 Examples and Slides To download examples on RA 1. mkdir class 2. cd class 3. wget http://geco.mines.edu/workshop/class2/examples/examples.tgz 4. tar
RA MPI Compilers Debuggers Profiling March 25, 2009 Examples and Slides To download examples on RA 1. mkdir class 2. cd class 3. wget http://geco.mines.edu/workshop/class2/examples/examples.tgz 4. tar
PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN
 1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction
1 PARALLEL & CLUSTER COMPUTING CS 6260 PROFESSOR: ELISE DE DONCKER BY: LINA HUSSEIN Introduction What is cluster computing? Classification of Cluster Computing Technologies: Beowulf cluster Construction
Performance Monitoring of Parallel Scientific Applications
 Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
Performance Monitoring of Parallel Scientific Applications Abstract. David Skinner National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory This paper introduces an infrastructure
Optimization on Huygens
 Optimization on Huygens Wim Rijks wimr@sara.nl Contents Introductory Remarks Support team Optimization strategy Amdahls law Compiler options An example Optimization Introductory Remarks Modern day supercomputers
Optimization on Huygens Wim Rijks wimr@sara.nl Contents Introductory Remarks Support team Optimization strategy Amdahls law Compiler options An example Optimization Introductory Remarks Modern day supercomputers
Experiences with HPC on Windows
 Experiences with on Christian Terboven terboven@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University Server Computing Summit 2008 April 7 11, HPI/Potsdam Experiences with on
Experiences with on Christian Terboven terboven@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University Server Computing Summit 2008 April 7 11, HPI/Potsdam Experiences with on
MPICH FOR SCI-CONNECTED CLUSTERS
 Autumn Meeting 99 of AK Scientific Computing MPICH FOR SCI-CONNECTED CLUSTERS Joachim Worringen AGENDA Introduction, Related Work & Motivation Implementation Performance Work in Progress Summary MESSAGE-PASSING
Autumn Meeting 99 of AK Scientific Computing MPICH FOR SCI-CONNECTED CLUSTERS Joachim Worringen AGENDA Introduction, Related Work & Motivation Implementation Performance Work in Progress Summary MESSAGE-PASSING
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.
 Paul Sack 20 September, 2002. sack@stud.ntnu.no www.stud.ntnu.") Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
Paul s Norwegian Vacation (or Experiences with Cluster Computing ) Paul Sack 20 September, 2002 sack@stud.ntnu.no www.stud.ntnu.no/ sack/ Outline Background information Work on clusters Profiling tools
Middleware and Distributed Systems. Introduction. Dr. Martin v. Löwis
 Middleware and Distributed Systems Introduction Dr. Martin v. Löwis 14 3. Software Engineering What is Middleware? Bauer et al. Software Engineering, Report on a conference sponsored by the NATO SCIENCE
Middleware and Distributed Systems Introduction Dr. Martin v. Löwis 14 3. Software Engineering What is Middleware? Bauer et al. Software Engineering, Report on a conference sponsored by the NATO SCIENCE
QUADRICS IN LINUX CLUSTERS
 QUADRICS IN LINUX CLUSTERS John Taylor Motivation QLC 21/11/00 Quadrics Cluster Products Performance Case Studies Development Activities Super-Cluster Performance Landscape CPLANT ~600 GF? 128 64 32 16
QUADRICS IN LINUX CLUSTERS John Taylor Motivation QLC 21/11/00 Quadrics Cluster Products Performance Case Studies Development Activities Super-Cluster Performance Landscape CPLANT ~600 GF? 128 64 32 16
The CNMS Computer Cluster
 The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
The CNMS Computer Cluster This page describes the CNMS Computational Cluster, how to access it, and how to use it. Introduction (2014) The latest block of the CNMS Cluster (2010) Previous blocks of the
PARALLEL PROGRAMMING
 PARALLEL PROGRAMMING TECHNIQUES AND APPLICATIONS USING NETWORKED WORKSTATIONS AND PARALLEL COMPUTERS 2nd Edition BARRY WILKINSON University of North Carolina at Charlotte Western Carolina University MICHAEL
PARALLEL PROGRAMMING TECHNIQUES AND APPLICATIONS USING NETWORKED WORKSTATIONS AND PARALLEL COMPUTERS 2nd Edition BARRY WILKINSON University of North Carolina at Charlotte Western Carolina University MICHAEL
Recommended hardware system configurations for ANSYS users
 Recommended hardware system configurations for ANSYS users The purpose of this document is to recommend system configurations that will deliver high performance for ANSYS users across the entire range
Recommended hardware system configurations for ANSYS users The purpose of this document is to recommend system configurations that will deliver high performance for ANSYS users across the entire range
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR
 LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
LBM BASED FLOW SIMULATION USING GPU COMPUTING PROCESSOR Frédéric Kuznik, frederic.kuznik@insa lyon.fr 1 Framework Introduction Hardware architecture CUDA overview Implementation details A simple case:
High Performance. CAEA elearning Series. Jonathan G. Dudley, Ph.D. 06/09/2015. 2015 CAE Associates
 High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
High Performance Computing (HPC) CAEA elearning Series Jonathan G. Dudley, Ph.D. 06/09/2015 2015 CAE Associates Agenda Introduction HPC Background Why HPC SMP vs. DMP Licensing HPC Terminology Types of
Dynamic Load Balancing in CP2K
 Dynamic Load Balancing in CP2K Pradeep Shivadasan August 19, 2014 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2014 Abstract CP2K is a widely used atomistic simulation
Dynamic Load Balancing in CP2K Pradeep Shivadasan August 19, 2014 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2014 Abstract CP2K is a widely used atomistic simulation
Large Scale Simulation on Clusters using COMSOL 4.2
 Large Scale Simulation on Clusters using COMSOL 4.2 Darrell W. Pepper 1 Xiuling Wang 2 Steven Senator 3 Joseph Lombardo 4 David Carrington 5 with David Kan and Ed Fontes 6 1 DVP-USAFA-UNLV, 2 Purdue-Calumet,
Large Scale Simulation on Clusters using COMSOL 4.2 Darrell W. Pepper 1 Xiuling Wang 2 Steven Senator 3 Joseph Lombardo 4 David Carrington 5 with David Kan and Ed Fontes 6 1 DVP-USAFA-UNLV, 2 Purdue-Calumet,
and RISC Optimization Techniques for the Hitachi SR8000 Architecture
 1 KONWIHR Project: Centre of Excellence for High Performance Computing Pseudo-Vectorization and RISC Optimization Techniques for the Hitachi SR8000 Architecture F. Deserno, G. Hager, F. Brechtefeld, G.
1 KONWIHR Project: Centre of Excellence for High Performance Computing Pseudo-Vectorization and RISC Optimization Techniques for the Hitachi SR8000 Architecture F. Deserno, G. Hager, F. Brechtefeld, G.
Client/Server and Distributed Computing
 Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Adapted from:operating Systems: Internals and Design Principles, 6/E William Stallings CS571 Fall 2010 Client/Server and Distributed Computing Dave Bremer Otago Polytechnic, N.Z. 2008, Prentice Hall Traditional
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Eighth Edition By William Stallings Operating System Exploits the hardware resources of one or more processors Provides
White Paper The Numascale Solution: Affordable BIG DATA Computing
 White Paper The Numascale Solution: Affordable BIG DATA Computing By: John Russel PRODUCED BY: Tabor Custom Publishing IN CONJUNCTION WITH: ABSTRACT Big Data applications once limited to a few exotic disciplines
White Paper The Numascale Solution: Affordable BIG DATA Computing By: John Russel PRODUCED BY: Tabor Custom Publishing IN CONJUNCTION WITH: ABSTRACT Big Data applications once limited to a few exotic disciplines
Annotation to the assignments and the solution sheet. Note the following points
 Computer rchitecture 2 / dvanced Computer rchitecture Seite: 1 nnotation to the assignments and the solution sheet This is a multiple choice examination, that means: Solution approaches are not assessed
Computer rchitecture 2 / dvanced Computer rchitecture Seite: 1 nnotation to the assignments and the solution sheet This is a multiple choice examination, that means: Solution approaches are not assessed
Parallel and Distributed Computing Programming Assignment 1
 Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Parallel and Distributed Computing Programming Assignment 1 Due Monday, February 7 For programming assignment 1, you should write two C programs. One should provide an estimate of the performance of ping-pong
Analysis and Implementation of Cluster Computing Using Linux Operating System
 IOSR Journal of Computer Engineering (IOSRJCE) ISSN: 2278-0661 Volume 2, Issue 3 (July-Aug. 2012), PP 06-11 Analysis and Implementation of Cluster Computing Using Linux Operating System Zinnia Sultana
IOSR Journal of Computer Engineering (IOSRJCE) ISSN: 2278-0661 Volume 2, Issue 3 (July-Aug. 2012), PP 06-11 Analysis and Implementation of Cluster Computing Using Linux Operating System Zinnia Sultana
Universidad Simón Bolívar
 Cardinale, Yudith Figueira, Carlos Hernández, Emilio Baquero, Eduardo Berbín, Luis Bouza, Roberto Gamess, Eric García, Pedro Universidad Simón Bolívar In 1999, a couple of projects from USB received funding
Cardinale, Yudith Figueira, Carlos Hernández, Emilio Baquero, Eduardo Berbín, Luis Bouza, Roberto Gamess, Eric García, Pedro Universidad Simón Bolívar In 1999, a couple of projects from USB received funding
Software Development around a Millisecond
 Introduction Software Development around a Millisecond Geoffrey Fox In this column we consider software development methodologies with some emphasis on those relevant for large scale scientific computing.
Introduction Software Development around a Millisecond Geoffrey Fox In this column we consider software development methodologies with some emphasis on those relevant for large scale scientific computing.
Lecture 1: the anatomy of a supercomputer
 Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
Where a calculator on the ENIAC is equipped with 18,000 vacuum tubes and weighs 30 tons, computers of the future may have only 1,000 vacuum tubes and perhaps weigh 1½ tons. Popular Mechanics, March 1949
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation
 The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
The Assessment of Benchmarks Executed on Bare-Metal and Using Para-Virtualisation Mark Baker, Garry Smith and Ahmad Hasaan SSE, University of Reading Paravirtualization A full assessment of paravirtualization
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
How To Visualize Performance Data In A Computer Program
 Performance Visualization Tools 1 Performance Visualization Tools Lecture Outline : Following Topics will be discussed Characteristics of Performance Visualization technique Commercial and Public Domain
Performance Visualization Tools 1 Performance Visualization Tools Lecture Outline : Following Topics will be discussed Characteristics of Performance Visualization technique Commercial and Public Domain
LSN 2 Computer Processors
 LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
LSN 2 Computer Processors Department of Engineering Technology LSN 2 Computer Processors Microprocessors Design Instruction set Processor organization Processor performance Bandwidth Clock speed LSN 2
Performance Analysis and Optimization Tool
 Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Analysis Team, University of Versailles http://www.maqao.org Introduction Performance Analysis Develop
Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Analysis Team, University of Versailles http://www.maqao.org Introduction Performance Analysis Develop
Many-task applications in use today with a look toward the future
 Many-task applications in use today with a look toward the future Alan Gara IBM Research Lots of help form Mark Megerian, IBM 1 Outline Review of Many-Task motivations on supercomputers and observations
Many-task applications in use today with a look toward the future Alan Gara IBM Research Lots of help form Mark Megerian, IBM 1 Outline Review of Many-Task motivations on supercomputers and observations
Seeking Opportunities for Hardware Acceleration in Big Data Analytics
 Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Seeking Opportunities for Hardware Acceleration in Big Data Analytics Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto Who
Performance Metrics and Scalability Analysis. Performance Metrics and Scalability Analysis
 Performance Metrics and Scalability Analysis 1 Performance Metrics and Scalability Analysis Lecture Outline Following Topics will be discussed Requirements in performance and cost Performance metrics Work
Performance Metrics and Scalability Analysis 1 Performance Metrics and Scalability Analysis Lecture Outline Following Topics will be discussed Requirements in performance and cost Performance metrics Work
Parallel Computing. Parallel shared memory computing with OpenMP
 Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster
 Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster Gabriele Jost and Haoqiang Jin NAS Division, NASA Ames Research Center, Moffett Field, CA 94035-1000 {gjost,hjin}@nas.nasa.gov