Data mining on the rocks T. Ruhe for the IceCube collaboration, K. Morik GREAT workshop on Astrostatistics and data mining 2011
|
|
|
- Ilene Turner
- 7 years ago
- Views:
Transcription
1 Data mining on the rocks T. Ruhe for the IceCube collaboration, K. Morik GREAT workshop on Astrostatistics and data mining 2011

2 Outline: - IceCube, detector and detection principle - Signal and Background - Feature Selection and Performance - Feature Selection stability - Random Forest, training and testing - Summary and Outlook

3 IceCube: The detector - completed in December located at the geographic South Pole Digital Optical Modules on 86 strings - instrumented volume of 1 km 3 - subdetectors DeepCore and IceTop



4 IceCube detection principle: Cherenkov light detected by Digital Optical Modules (DOMs)

5 IceCube-operation: - IceCube has taken data in various configurations - This study: 59-strings - Pacman-like geometry - reconstruction based on timing information by the DOMS

6 Signal and Background: Fakultät Physik Signal: atmospheric v (+ v from astrophysical sources) ~ events in days of IC-59 Backgr.: (misreconstructed) atmospheric muons ~ x 10 6 events in days of IC-59 Signal to Background ratio: 1.46 x 10-3 Application of Precuts: Signal: events in days of IC-59 Backgr.: 1.68 x 10 6 events in days of IC-59 Ratio = 6.2 x 10-3

7 RapidMiner: - Formerly known as YALE (Yet Another Learning Environment) - Developed at TU Dortmund University (group of K. Morik) - Operator based - Open Source, written in java - Weka operators are fully included - Quite intuitive to use (personal opinion)

8 Preselection of parameters: 1. Check for consistency (data vs. simulation) Eliminate if missing in one (reduction ~ out of ~2600) 2. Check for missing values (nans, infs) Eliminate if number of missing values exceeds 30% (reduction to 1408 attributes) 3. Eliminate the obvious (Azimuth, Time, galactic coordinates...) (reduction to 612 attributes) 4. Eliminate highly correlated (ρ = 1.0 ) and constant parameters Final set of 477 parameters
 3. Eliminate the obvious (Azimuth, Time, galactic coordinates...) (reduction to 612 attributes) 4.")
9 MRMR-Feature Selection: - Maximum-Relevance-Minimum-Redundancy - iteratively adds to a set F j a feature according to a quality criterion Q: Q = rel( y, x) red ( x, x ) x - Relevance and Redundancy automatically map to linear correlation, F-test score or mutual information (depending on attribute and class type) F j Q = x rel( y, x) red( x, x ) F j
 F j Q = x rel( y, x) red( x,")
10 Feature Selection and Performance: - MRMR Feature Selection - Random Forest (from the Weka package) Fakultät Physik n trees matched to n Attr. such that: n trees = 10 x n Attr - Naive Bayes - k-nn, k =5, weighted vote, mixed Eucledian distance - 10-fold cross validation x 10 5 simulated signal and background events

11 Fakultät Physik

12 Stability of the MRMR Selection: Jaccard Index: Kuncheva s Index: B A B A J = ) ( ), ( 2 B A r k B A k n k k rn B A I C = = = =
, ( 2 B A r k B A k n k k rn")
13 Removing further correlations: - after MRMR still some correlated attributes Study the performance if further correlations are removed

14 Training and Testing a Random Forest: trees, Weka Random Forest x 10 5 simulated signal events x 10 5 simulated background events - 5-fold cross validation x 10 4 signal and background events for training Avoid possible overfitting

15 Fakultät Physik
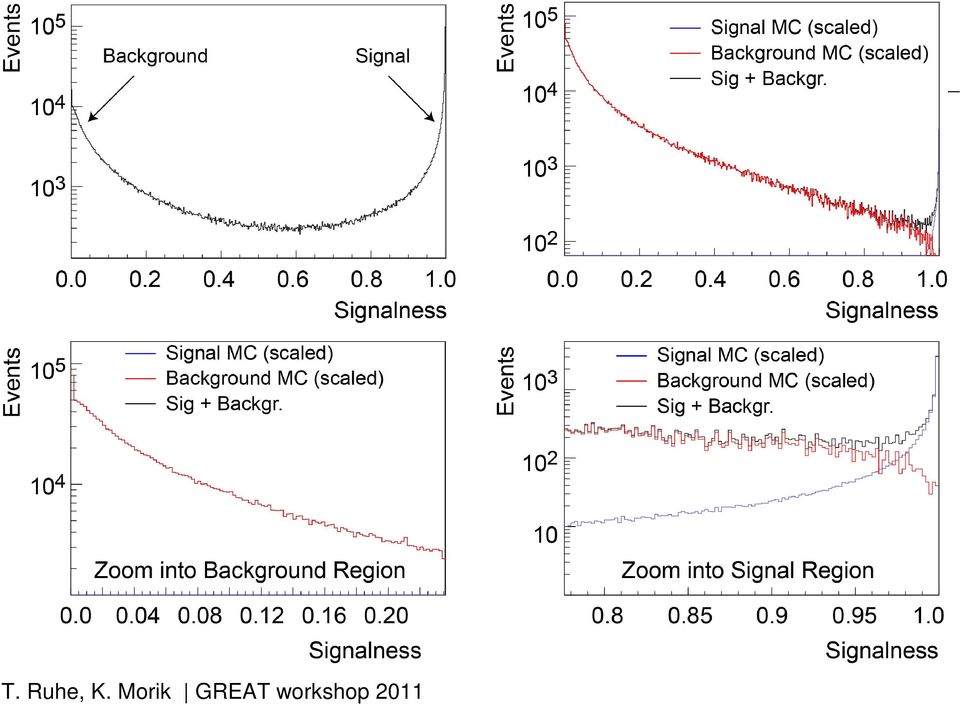
16 Forest Performance and Results: Fakultät Physik Background computed using a conservative estimate Cut Exp. Bckgr. Ev. Exp. Sig. Ev. Est. Pur. [%]
![Ev. Est. Pur. [%] 0.990 311 5079 94.2 0.992 263 4864 94.9 0.](/docs-images/47/20448018/images/page_16.jpg "994 215 4606 95.5 0.996 139 4271 96.8 0.998 118 3804 97.0 1.")
17 Summary and Outlook: - influence of detailed FS on training of multivariate classifiers has been studied - MRMR is stable if n Attr most stable performance of the forest when attributes with ρ > 0.9 removed prior to MRMR - Random Forest trained and tested - > 3000 events are found, Purity routinely > 95 % - Not fully optimized - hope to achieve even better with a fully optimized classifier

18 Backup Slides

19 The Random Forest: - Developed by Leo Breiman (2001) - Utilizes ensemble of decision trees Forest - No boosting between individual trees - Average used for final classification - No overtraining! (see: Machine Learning, 45, 5 32 (2001)) - Here: Rapidminer toolkit (developed in Dortmund)
) - Here: Rapidminer toolkit")
20 Atmospheric neutrinos: A detailed understanding of the atmospheric neutrino spectrum is crucial for the detection of an astrophysical flux.

Data Mining Ice Cubes Tim Ruhe, Katharina Morik ADASS XXI, Paris 2011
 Data Mining Ice Cubes Tim Ruhe, Katharina Morik ADASS XXI, Paris 2011 Outline: - IceCube - RapidMiner - Feature Selection - Random Forest training and application - Summary and outlook The IceCube detector:
Data Mining Ice Cubes Tim Ruhe, Katharina Morik ADASS XXI, Paris 2011 Outline: - IceCube - RapidMiner - Feature Selection - Random Forest training and application - Summary and outlook The IceCube detector:
Monday Morning Data Mining
 Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Monday Morning Data Mining Tim Ruhe Statistische Methoden der Datenanalyse Outline: - data mining - IceCube - Data mining in IceCube Computer Scientists are different... Fakultät Physik Fakultät Physik
Big Data Analytics in Astrophysics. Katharina Morik, Informatik 8, TU Dortmund
 Big Data Analytics in Astrophysics Katharina Morik, Informatik 8, TU Dortmund Overview Short introduction to the Collaborative Research Center SFB 876 Zooming into one of its projects: C3 Astrophysical
Big Data Analytics in Astrophysics Katharina Morik, Informatik 8, TU Dortmund Overview Short introduction to the Collaborative Research Center SFB 876 Zooming into one of its projects: C3 Astrophysical
Model Combination. 24 Novembre 2009
 Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Model Combination 24 Novembre 2009 Datamining 1 2009-2010 Plan 1 Principles of model combination 2 Resampling methods Bagging Random Forests Boosting 3 Hybrid methods Stacking Generic algorithm for mulistrategy
Data Mining. Nonlinear Classification
 Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Nonlinear Classification Classes may not be separable by a linear boundary Suppose we randomly generate a data set as follows: X has range between 0 to 15
Applied Multivariate Analysis - Big data analytics
 Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix nathalie.villa@toulouse.inra.fr http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
Applied Multivariate Analysis - Big data analytics Nathalie Villa-Vialaneix nathalie.villa@toulouse.inra.fr http://www.nathalievilla.org M1 in Economics and Economics and Statistics Toulouse School of
MHI3000 Big Data Analytics for Health Care Final Project Report
 MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
MHI3000 Big Data Analytics for Health Care Final Project Report Zhongtian Fred Qiu (1002274530) http://gallery.azureml.net/details/81ddb2ab137046d4925584b5095ec7aa 1. Data pre-processing The data given
Using multiple models: Bagging, Boosting, Ensembles, Forests
 Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Using multiple models: Bagging, Boosting, Ensembles, Forests Bagging Combining predictions from multiple models Different models obtained from bootstrap samples of training data Average predictions or
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 10 Sajjad Haider Fall 2012 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Content-Based Recommendation
 Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Content-Based Recommendation Content-based? Item descriptions to identify items that are of particular interest to the user Example Example Comparing with Noncontent based Items User-based CF Searches
Chapter 6. The stacking ensemble approach
 82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
82 This chapter proposes the stacking ensemble approach for combining different data mining classifiers to get better performance. Other combination techniques like voting, bagging etc are also described
Decision Trees from large Databases: SLIQ
 Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
Decision Trees from large Databases: SLIQ C4.5 often iterates over the training set How often? If the training set does not fit into main memory, swapping makes C4.5 unpractical! SLIQ: Sort the values
CS570 Data Mining Classification: Ensemble Methods
 CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
CS570 Data Mining Classification: Ensemble Methods Cengiz Günay Dept. Math & CS, Emory University Fall 2013 Some slides courtesy of Han-Kamber-Pei, Tan et al., and Li Xiong Günay (Emory) Classification:
Comparison of Data Mining Techniques used for Financial Data Analysis
 Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
Comparison of Data Mining Techniques used for Financial Data Analysis Abhijit A. Sawant 1, P. M. Chawan 2 1 Student, 2 Associate Professor, Department of Computer Technology, VJTI, Mumbai, INDIA Abstract
Data Mining Practical Machine Learning Tools and Techniques
 Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Ensemble learning Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 8 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Combining multiple models Bagging The basic idea
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Knowledge Discovery and Data Mining Unit # 11 Sajjad Haider Fall 2013 1 Supervised Learning Process Data Collection/Preparation Data Cleaning Discretization Supervised/Unuspervised Identification of right
Ensemble Methods. Knowledge Discovery and Data Mining 2 (VU) (707.004) Roman Kern. KTI, TU Graz 2015-03-05
 (707.004) Roman Kern. KTI, TU Graz 2015-03-05") Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Ensemble Methods Knowledge Discovery and Data Mining 2 (VU) (707004) Roman Kern KTI, TU Graz 2015-03-05 Roman Kern (KTI, TU Graz) Ensemble Methods 2015-03-05 1 / 38 Outline 1 Introduction 2 Classification
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
MS1b Statistical Data Mining
 MS1b Statistical Data Mining Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Administrivia and Introduction Course Structure Syllabus Introduction to
MS1b Statistical Data Mining Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Administrivia and Introduction Course Structure Syllabus Introduction to
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Low-energy point source searches with IceCube
 EPJ Web of Conferences 116, 04004 (2016) DOI: 10.1051/epjconf/201611604004 C Owned by the authors, published by EDP Sciences, 2016 Low-energy point source searches with IceCube Sebastian Euler 1,a, David
EPJ Web of Conferences 116, 04004 (2016) DOI: 10.1051/epjconf/201611604004 C Owned by the authors, published by EDP Sciences, 2016 Low-energy point source searches with IceCube Sebastian Euler 1,a, David
Data Mining Analysis (breast-cancer data)
") Data Mining Analysis (breast-cancer data) Jung-Ying Wang Register number: D9115007, May, 2003 Abstract In this AI term project, we compare some world renowned machine learning tools. Including WEKA data
Data Mining Analysis (breast-cancer data) Jung-Ying Wang Register number: D9115007, May, 2003 Abstract In this AI term project, we compare some world renowned machine learning tools. Including WEKA data
Introduction to Machine Learning Lecture 1. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu
 Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Introduction to Machine Learning Lecture 1 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Introduction Logistics Prerequisites: basics concepts needed in probability and statistics
Getting Even More Out of Ensemble Selection
 Getting Even More Out of Ensemble Selection Quan Sun Department of Computer Science The University of Waikato Hamilton, New Zealand qs12@cs.waikato.ac.nz ABSTRACT Ensemble Selection uses forward stepwise
Getting Even More Out of Ensemble Selection Quan Sun Department of Computer Science The University of Waikato Hamilton, New Zealand qs12@cs.waikato.ac.nz ABSTRACT Ensemble Selection uses forward stepwise
Predicting borrowers chance of defaulting on credit loans
 Predicting borrowers chance of defaulting on credit loans Junjie Liang (junjie87@stanford.edu) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Predicting borrowers chance of defaulting on credit loans Junjie Liang (junjie87@stanford.edu) Abstract Credit score prediction is of great interests to banks as the outcome of the prediction algorithm
Why Ensembles Win Data Mining Competitions
 Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
Why Ensembles Win Data Mining Competitions A Predictive Analytics Center of Excellence (PACE) Tech Talk November 14, 2012 Dean Abbott Abbott Analytics, Inc. Blog: http://abbottanalytics.blogspot.com URL:
Beating the MLB Moneyline
 Beating the MLB Moneyline Leland Chen llxchen@stanford.edu Andrew He andu@stanford.edu 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
Beating the MLB Moneyline Leland Chen llxchen@stanford.edu Andrew He andu@stanford.edu 1 Abstract Sports forecasting is a challenging task that has similarities to stock market prediction, requiring time-series
IceCube Project Monthly Report July 2007
 IceCube Project Monthly Report July 2007 Accomplishments The Data Acquisition (DAQ) software processed 1.50 billion events during 2.69 million live seconds in the month of July. The DAQ uptime percentage
IceCube Project Monthly Report July 2007 Accomplishments The Data Acquisition (DAQ) software processed 1.50 billion events during 2.69 million live seconds in the month of July. The DAQ uptime percentage
Supervised Feature Selection & Unsupervised Dimensionality Reduction
 Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Supervised Feature Selection & Unsupervised Dimensionality Reduction Feature Subset Selection Supervised: class labels are given Select a subset of the problem features Why? Redundant features much or
Predicting Student Persistence Using Data Mining and Statistical Analysis Methods
 Predicting Student Persistence Using Data Mining and Statistical Analysis Methods Koji Fujiwara Office of Institutional Research and Effectiveness Bemidji State University & Northwest Technical College
Predicting Student Persistence Using Data Mining and Statistical Analysis Methods Koji Fujiwara Office of Institutional Research and Effectiveness Bemidji State University & Northwest Technical College
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier
 A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
A Study Of Bagging And Boosting Approaches To Develop Meta-Classifier G.T. Prasanna Kumari Associate Professor, Dept of Computer Science and Engineering, Gokula Krishna College of Engg, Sullurpet-524121,
PoS(ICRC2015)707. FACT - First Energy Spectrum from a SiPM Cherenkov Telescope
707. FACT - First Energy Spectrum from a SiPM Cherenkov Telescope") from a SiPM Cherenkov Telescope F. Temme a, M. L. Ahnen b, M. Balbo c, M. Bergmann d, A. Biland b, C. Bockermann e, T. Bretz b, K. A. Brügge a, J. Buss a, D. Dorner d, S. Einecke a, J. Freiwald a, C. Hempfling
from a SiPM Cherenkov Telescope F. Temme a, M. L. Ahnen b, M. Balbo c, M. Bergmann d, A. Biland b, C. Bockermann e, T. Bretz b, K. A. Brügge a, J. Buss a, D. Dorner d, S. Einecke a, J. Freiwald a, C. Hempfling
Introduction to Machine Learning and Data Mining. Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk
 Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
Introduction to Machine Learning and Data Mining Prof. Dr. Igor Trajkovski trajkovski@nyus.edu.mk Ensembles 2 Learning Ensembles Learn multiple alternative definitions of a concept using different training
The Operational Value of Social Media Information. Social Media and Customer Interaction
 The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
Machine learning for algo trading
 Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Machine learning for algo trading An introduction for nonmathematicians Dr. Aly Kassam Overview High level introduction to machine learning A machine learning bestiary What has all this got to do with
Data Mining in CRM & Direct Marketing. Jun Du The University of Western Ontario jdu43@uwo.ca
 Data Mining in CRM & Direct Marketing Jun Du The University of Western Ontario jdu43@uwo.ca Outline Why CRM & Marketing Goals in CRM & Marketing Models and Methodologies Case Study: Response Model Case
Data Mining in CRM & Direct Marketing Jun Du The University of Western Ontario jdu43@uwo.ca Outline Why CRM & Marketing Goals in CRM & Marketing Models and Methodologies Case Study: Response Model Case
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Predict the Popularity of YouTube Videos Using Early View Data
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION
 CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION MATIJA STEVANOVIC PhD Student JENS MYRUP PEDERSEN Associate Professor Department of Electronic Systems Aalborg University,
CYBER SCIENCE 2015 AN ANALYSIS OF NETWORK TRAFFIC CLASSIFICATION FOR BOTNET DETECTION MATIJA STEVANOVIC PhD Student JENS MYRUP PEDERSEN Associate Professor Department of Electronic Systems Aalborg University,
HT2015: SC4 Statistical Data Mining and Machine Learning
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
Gerry Hobbs, Department of Statistics, West Virginia University
 Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Decision Trees as a Predictive Modeling Method Gerry Hobbs, Department of Statistics, West Virginia University Abstract Predictive modeling has become an important area of interest in tasks such as credit
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Knowledge Discovery and Data Mining Unit # 6 Sajjad Haider Fall 2014 1 Evaluating the Accuracy of a Classifier Holdout, random subsampling, crossvalidation, and the bootstrap are common techniques for
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr
 Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
New Ensemble Combination Scheme
 New Ensemble Combination Scheme Namhyoung Kim, Youngdoo Son, and Jaewook Lee, Member, IEEE Abstract Recently many statistical learning techniques are successfully developed and used in several areas However,
New Ensemble Combination Scheme Namhyoung Kim, Youngdoo Son, and Jaewook Lee, Member, IEEE Abstract Recently many statistical learning techniques are successfully developed and used in several areas However,
Fraud Detection for Online Retail using Random Forests
 Fraud Detection for Online Retail using Random Forests Eric Altendorf, Peter Brende, Josh Daniel, Laurent Lessard Abstract As online commerce becomes more common, fraud is an increasingly important concern.
Fraud Detection for Online Retail using Random Forests Eric Altendorf, Peter Brende, Josh Daniel, Laurent Lessard Abstract As online commerce becomes more common, fraud is an increasingly important concern.
KNIME TUTORIAL. Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it
 KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Market Basket Analysis Exercise: Customer Segmentation Exercise:
KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Market Basket Analysis Exercise: Customer Segmentation Exercise:
Ensemble Approach for the Classification of Imbalanced Data
 Ensemble Approach for the Classification of Imbalanced Data Vladimir Nikulin 1, Geoffrey J. McLachlan 1, and Shu Kay Ng 2 1 Department of Mathematics, University of Queensland v.nikulin@uq.edu.au, gjm@maths.uq.edu.au
Ensemble Approach for the Classification of Imbalanced Data Vladimir Nikulin 1, Geoffrey J. McLachlan 1, and Shu Kay Ng 2 1 Department of Mathematics, University of Queensland v.nikulin@uq.edu.au, gjm@maths.uq.edu.au
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007
 Todd Holloway Lecture for B551 Nov. 27, 2007") Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007 Naïve Bayes Components ML vs. MAP Benefits Feature Preparation Filtering Decay Extended Examples
Introduction to Bayesian Classification (A Practical Discussion) Todd Holloway Lecture for B551 Nov. 27, 2007 Naïve Bayes Components ML vs. MAP Benefits Feature Preparation Filtering Decay Extended Examples
An Introduction to Data Mining
 An Introduction to Intel Beijing wei.heng@intel.com January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
An Introduction to Intel Beijing wei.heng@intel.com January 17, 2014 Outline 1 DW Overview What is Notable Application of Conference, Software and Applications Major Process in 2 Major Tasks in Detail
BIOINF 585 Fall 2015 Machine Learning for Systems Biology & Clinical Informatics http://www.ccmb.med.umich.edu/node/1376
 Course Director: Dr. Kayvan Najarian (DCM&B, kayvan@umich.edu) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Course Director: Dr. Kayvan Najarian (DCM&B, kayvan@umich.edu) Lectures: Labs: Mondays and Wednesdays 9:00 AM -10:30 AM Rm. 2065 Palmer Commons Bldg. Wednesdays 10:30 AM 11:30 AM (alternate weeks) Rm.
Ensuring Collective Availability in Volatile Resource Pools via Forecasting
 Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak andrzejak[at]zib.de Derrick Kondo David P. Anderson Zuse Institute Berlin (ZIB) INRIA UC Berkeley Motivation
Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak andrzejak[at]zib.de Derrick Kondo David P. Anderson Zuse Institute Berlin (ZIB) INRIA UC Berkeley Motivation
Classification of Bad Accounts in Credit Card Industry
 Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Classification of Bad Accounts in Credit Card Industry Chengwei Yuan December 12, 2014 Introduction Risk management is critical for a credit card company to survive in such competing industry. In addition
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R
 Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Practical Data Science with Azure Machine Learning, SQL Data Mining, and R Overview This 4-day class is the first of the two data science courses taught by Rafal Lukawiecki. Some of the topics will be
Microsoft Azure Machine learning Algorithms
 Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
Microsoft Azure Machine learning Algorithms Tomaž KAŠTRUN @tomaz_tsql Tomaz.kastrun@gmail.com http://tomaztsql.wordpress.com Our Sponsors Speaker info https://tomaztsql.wordpress.com Agenda Focus on explanation
LCs for Binary Classification
 Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Linear Classifiers A linear classifier is a classifier such that classification is performed by a dot product beteen the to vectors representing the document and the category, respectively. Therefore it
Welcome to this presentation on Driving LEDs AC-DC Power Supplies, part of OSRAM Opto Semiconductors LED Fundamentals series. In this presentation we
 Welcome to this presentation on Driving LEDs AC-DC Power Supplies, part of OSRAM Opto Semiconductors LED Fundamentals series. In this presentation we will look at: - the typical circuit structure of AC-DC
Welcome to this presentation on Driving LEDs AC-DC Power Supplies, part of OSRAM Opto Semiconductors LED Fundamentals series. In this presentation we will look at: - the typical circuit structure of AC-DC
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods
 Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
Mining Direct Marketing Data by Ensembles of Weak Learners and Rough Set Methods Jerzy B laszczyński 1, Krzysztof Dembczyński 1, Wojciech Kot lowski 1, and Mariusz Paw lowski 2 1 Institute of Computing
Distributed forests for MapReduce-based machine learning
 Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Distributed forests for MapReduce-based machine learning Ryoji Wakayama, Ryuei Murata, Akisato Kimura, Takayoshi Yamashita, Yuji Yamauchi, Hironobu Fujiyoshi Chubu University, Japan. NTT Communication
Azure Machine Learning, SQL Data Mining and R
 Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
Azure Machine Learning, SQL Data Mining and R Day-by-day Agenda Prerequisites No formal prerequisites. Basic knowledge of SQL Server Data Tools, Excel and any analytical experience helps. Best of all:
TURKISH ORACLE USER GROUP
 TURKISH ORACLE USER GROUP Data Mining in 30 Minutes Husnu Sensoy Global Maksimum Data & Information Tech. Founder VLDB Expert Agenda Who am I? Different problems of Data Mining In database data mining?!?
TURKISH ORACLE USER GROUP Data Mining in 30 Minutes Husnu Sensoy Global Maksimum Data & Information Tech. Founder VLDB Expert Agenda Who am I? Different problems of Data Mining In database data mining?!?
Advanced Ensemble Strategies for Polynomial Models
 Advanced Ensemble Strategies for Polynomial Models Pavel Kordík 1, Jan Černý 2 1 Dept. of Computer Science, Faculty of Information Technology, Czech Technical University in Prague, 2 Dept. of Computer
Advanced Ensemble Strategies for Polynomial Models Pavel Kordík 1, Jan Černý 2 1 Dept. of Computer Science, Faculty of Information Technology, Czech Technical University in Prague, 2 Dept. of Computer
MACHINE LEARNING IN HIGH ENERGY PHYSICS
 MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
MACHINE LEARNING IN HIGH ENERGY PHYSICS LECTURE #1 Alex Rogozhnikov, 2015 INTRO NOTES 4 days two lectures, two practice seminars every day this is introductory track to machine learning kaggle competition!
T(CR)3IC Testbed for Coherent Radio Cherenkov Radiation from Cosmic-Ray Induced Cascades
3IC Testbed for Coherent Radio Cherenkov Radiation from Cosmic-Ray Induced Cascades") T(CR)3IC Testbed for Coherent Radio Cherenkov Radiation from Cosmic-Ray Induced Cascades R. Milinčić1, P. Gorham1, C. Hebert1, S. Matsuno1, P. Miočinović1, M. Rosen1, D. Saltzberg2, G. Varner1 1 University
T(CR)3IC Testbed for Coherent Radio Cherenkov Radiation from Cosmic-Ray Induced Cascades R. Milinčić1, P. Gorham1, C. Hebert1, S. Matsuno1, P. Miočinović1, M. Rosen1, D. Saltzberg2, G. Varner1 1 University
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms
 Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
Fine Particulate Matter Concentration Level Prediction by using Tree-based Ensemble Classification Algorithms Yin Zhao School of Mathematical Sciences Universiti Sains Malaysia (USM) Penang, Malaysia Yahya
Data Mining Techniques Chapter 6: Decision Trees
 Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
Data Mining Techniques Chapter 6: Decision Trees What is a classification decision tree?.......................................... 2 Visualizing decision trees...................................................
The Artificial Prediction Market
 The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
The Artificial Prediction Market Adrian Barbu Department of Statistics Florida State University Joint work with Nathan Lay, Siemens Corporate Research 1 Overview Main Contributions A mathematical theory
Better credit models benefit us all
 Better credit models benefit us all Agenda Credit Scoring - Overview Random Forest - Overview Random Forest outperform logistic regression for credit scoring out of the box Interaction term hypothesis
Better credit models benefit us all Agenda Credit Scoring - Overview Random Forest - Overview Random Forest outperform logistic regression for credit scoring out of the box Interaction term hypothesis
How To Perform An Ensemble Analysis
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Charu C. Aggarwal IBM T J Watson Research Center Yorktown, NY 10598 Outlier Ensembles Keynote, Outlier Detection and Description Workshop, 2013 Based on the ACM SIGKDD Explorations Position Paper: Outlier
Introducing diversity among the models of multi-label classification ensemble
 Introducing diversity among the models of multi-label classification ensemble Lena Chekina, Lior Rokach and Bracha Shapira Ben-Gurion University of the Negev Dept. of Information Systems Engineering and
Introducing diversity among the models of multi-label classification ensemble Lena Chekina, Lior Rokach and Bracha Shapira Ben-Gurion University of the Negev Dept. of Information Systems Engineering and
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j
 Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Analysis of kiva.com Microlending Service! Hoda Eydgahi Julia Ma Andy Bardagjy December 9, 2010 MAS.622j What is Kiva? An organization that allows people to lend small amounts of money via the Internet
Implementation of Breiman s Random Forest Machine Learning Algorithm
 Implementation of Breiman s Random Forest Machine Learning Algorithm Frederick Livingston Abstract This research provides tools for exploring Breiman s Random Forest algorithm. This paper will focus on
Implementation of Breiman s Random Forest Machine Learning Algorithm Frederick Livingston Abstract This research provides tools for exploring Breiman s Random Forest algorithm. This paper will focus on
Data Mining Classification: Decision Trees
 Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Classification: Decision Trees Classification Decision Trees: what they are and how they work Hunt s (TDIDT) algorithm How to select the best split How to handle Inconsistent data Continuous
Data Mining Techniques for Prognosis in Pancreatic Cancer
 Data Mining Techniques for Prognosis in Pancreatic Cancer by Stuart Floyd A Thesis Submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUE In partial fulfillment of the requirements for the Degree
Data Mining Techniques for Prognosis in Pancreatic Cancer by Stuart Floyd A Thesis Submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUE In partial fulfillment of the requirements for the Degree
Knowledge Discovery and Data Mining. Bootstrap review. Bagging Important Concepts. Notes. Lecture 19 - Bagging. Tom Kelsey. Notes
 Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Knowledge Discovery and Data Mining Lecture 19 - Bagging Tom Kelsey School of Computer Science University of St Andrews http://tom.host.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-19-B &
Data Mining for Knowledge Management. Classification
 1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
1 Data Mining for Knowledge Management Classification Themis Palpanas University of Trento http://disi.unitn.eu/~themis Data Mining for Knowledge Management 1 Thanks for slides to: Jiawei Han Eamonn Keogh
E-commerce Transaction Anomaly Classification
 E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
Data Mining for Business Intelligence. Concepts, Techniques, and Applications in Microsoft Office Excel with XLMiner. 2nd Edition
 Brochure More information from http://www.researchandmarkets.com/reports/2170926/ Data Mining for Business Intelligence. Concepts, Techniques, and Applications in Microsoft Office Excel with XLMiner. 2nd
Brochure More information from http://www.researchandmarkets.com/reports/2170926/ Data Mining for Business Intelligence. Concepts, Techniques, and Applications in Microsoft Office Excel with XLMiner. 2nd
Solid State Detectors = Semi-Conductor based Detectors
 Solid State Detectors = Semi-Conductor based Detectors Materials and their properties Energy bands and electronic structure Charge transport and conductivity Boundaries: the p-n junction Charge collection
Solid State Detectors = Semi-Conductor based Detectors Materials and their properties Energy bands and electronic structure Charge transport and conductivity Boundaries: the p-n junction Charge collection
IceCube Project Monthly Report April 2006
 22-Jan-10 IceCube Project Monthly Report April 2006 Accomplishments A review of the IceCube data acquisition, on line, and experiment control systems was completed in April. The committee included a member
22-Jan-10 IceCube Project Monthly Report April 2006 Accomplishments A review of the IceCube data acquisition, on line, and experiment control systems was completed in April. The committee included a member
Evaluation Tools for the Performance of a NESTOR Test Detector
 Evaluation Tools for the Performance of a NESTOR Test Detector G. Bourlis, A. Leisos, S. E. Tzamarias and A. Tsirigotis Particle and Astroparticle Physics Group School of Science and Technology Hellenic
Evaluation Tools for the Performance of a NESTOR Test Detector G. Bourlis, A. Leisos, S. E. Tzamarias and A. Tsirigotis Particle and Astroparticle Physics Group School of Science and Technology Hellenic
Neural Networks and Support Vector Machines
 INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
INF5390 - Kunstig intelligens Neural Networks and Support Vector Machines Roar Fjellheim INF5390-13 Neural Networks and SVM 1 Outline Neural networks Perceptrons Neural networks Support vector machines
RAPIDMINER FREE SOFTWARE FOR DATA MINING, ANALYTICS AND BUSINESS INTELLIGENCE. Luigi Grimaudo 178627 Database And Data Mining Research Group
 RAPIDMINER FREE SOFTWARE FOR DATA MINING, ANALYTICS AND BUSINESS INTELLIGENCE Luigi Grimaudo 178627 Database And Data Mining Research Group Summary RapidMiner project Strengths How to use RapidMiner Operator
RAPIDMINER FREE SOFTWARE FOR DATA MINING, ANALYTICS AND BUSINESS INTELLIGENCE Luigi Grimaudo 178627 Database And Data Mining Research Group Summary RapidMiner project Strengths How to use RapidMiner Operator
CART 6.0 Feature Matrix
 CART 6.0 Feature Matri Enhanced Descriptive Statistics Full summary statistics Brief summary statistics Stratified summary statistics Charts and histograms Improved User Interface New setup activity window
CART 6.0 Feature Matri Enhanced Descriptive Statistics Full summary statistics Brief summary statistics Stratified summary statistics Charts and histograms Improved User Interface New setup activity window
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Data Mining Part 5. Prediction 5.7 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Linear Regression Other Regression Models References Introduction Introduction Numerical prediction is
Scalable Machine Learning to Exploit Big Data for Knowledge Discovery
 Scalable Machine Learning to Exploit Big Data for Knowledge Discovery Una-May O Reilly MIT MIT ILP-EPOCH Taiwan Symposium Big Data: Technologies and Applications Lots of Data Everywhere Knowledge Mining
Scalable Machine Learning to Exploit Big Data for Knowledge Discovery Una-May O Reilly MIT MIT ILP-EPOCH Taiwan Symposium Big Data: Technologies and Applications Lots of Data Everywhere Knowledge Mining
A Property and Casualty Insurance Predictive Modeling Process in SAS
 Paper 11422-2016 A Property and Casualty Insurance Predictive Modeling Process in SAS Mei Najim, Sedgwick Claim Management Services ABSTRACT Predictive analytics is an area that has been developing rapidly
Paper 11422-2016 A Property and Casualty Insurance Predictive Modeling Process in SAS Mei Najim, Sedgwick Claim Management Services ABSTRACT Predictive analytics is an area that has been developing rapidly
Sentiment analysis using emoticons
 Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Sentiment analysis using emoticons Royden Kayhan Lewis Moharreri Steven Royden Ware Lewis Kayhan Steven Moharreri Ware Department of Computer Science, Ohio State University Problem definition Our aim was
Predictive Data modeling for health care: Comparative performance study of different prediction models
 Predictive Data modeling for health care: Comparative performance study of different prediction models Shivanand Hiremath hiremat.nitie@gmail.com National Institute of Industrial Engineering (NITIE) Vihar
Predictive Data modeling for health care: Comparative performance study of different prediction models Shivanand Hiremath hiremat.nitie@gmail.com National Institute of Industrial Engineering (NITIE) Vihar
How To Solve The Kd Cup 2010 Challenge
 A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
A Lightweight Solution to the Educational Data Mining Challenge Kun Liu Yan Xing Faculty of Automation Guangdong University of Technology Guangzhou, 510090, China catch0327@yahoo.com yanxing@gdut.edu.cn
COPYRIGHTED MATERIAL. Contents. List of Figures. Acknowledgments
 Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
Contents List of Figures Foreword Preface xxv xxiii xv Acknowledgments xxix Chapter 1 Fraud: Detection, Prevention, and Analytics! 1 Introduction 2 Fraud! 2 Fraud Detection and Prevention 10 Big Data for
On Cross-Validation and Stacking: Building seemingly predictive models on random data
 On Cross-Validation and Stacking: Building seemingly predictive models on random data ABSTRACT Claudia Perlich Media6 New York, NY 10012 claudia@media6degrees.com A number of times when using cross-validation
On Cross-Validation and Stacking: Building seemingly predictive models on random data ABSTRACT Claudia Perlich Media6 New York, NY 10012 claudia@media6degrees.com A number of times when using cross-validation
Boosting. riedmiller@informatik.uni-freiburg.de
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Real Time Data Analytics Loom to Make Proactive Tread for Pyrexia
 Real Time Data Analytics Loom to Make Proactive Tread for Pyrexia V.Sathya Preiya 1, M.Sangeetha 2, S.T.Santhanalakshmi 3 Associate Professor, Dept. of Computer Science and Engineering, Panimalar Engineering
Real Time Data Analytics Loom to Make Proactive Tread for Pyrexia V.Sathya Preiya 1, M.Sangeetha 2, S.T.Santhanalakshmi 3 Associate Professor, Dept. of Computer Science and Engineering, Panimalar Engineering
M1 in Economics and Economics and Statistics Applied multivariate Analysis - Big data analytics Worksheet 3 - Random Forest
 Nathalie Villa-Vialaneix Année 2014/2015 M1 in Economics and Economics and Statistics Applied multivariate Analysis - Big data analytics Worksheet 3 - Random Forest This worksheet s aim is to learn how
Nathalie Villa-Vialaneix Année 2014/2015 M1 in Economics and Economics and Statistics Applied multivariate Analysis - Big data analytics Worksheet 3 - Random Forest This worksheet s aim is to learn how
BIDM Project. Predicting the contract type for IT/ITES outsourcing contracts
 BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
BIDM Project Predicting the contract type for IT/ITES outsourcing contracts N a n d i n i G o v i n d a r a j a n ( 6 1 2 1 0 5 5 6 ) The authors believe that data modelling can be used to predict if an
Comparison of machine learning methods for intelligent tutoring systems
 Comparison of machine learning methods for intelligent tutoring systems Wilhelmiina Hämäläinen 1 and Mikko Vinni 1 Department of Computer Science, University of Joensuu, P.O. Box 111, FI-80101 Joensuu
Comparison of machine learning methods for intelligent tutoring systems Wilhelmiina Hämäläinen 1 and Mikko Vinni 1 Department of Computer Science, University of Joensuu, P.O. Box 111, FI-80101 Joensuu