Big Data Technology CS , Technion, Spring 2013
|
|
|
- Ginger Norman
- 9 years ago
- Views:
Transcription
1 Big Data Technology CS , Technion, Spring 2013 Structured Databases atop Map-Reduce Edward Bortnikov & Ronny Lempel Yahoo! Labs, Haifa

2 Roadmap Previous class MR Implementation This class Query Languages atop MR Beyond MR Database Theory in a Nutshell Query Language Implementation Apache Hive and HCatalog

3 Map-Reduce Critique Too low-level (only engineers can program) Hand-coding for many common operations Data flows extremely rigid (linear) Hard to maintain, extend, and optimize This is exactly what SQL databases have been designed for! Can we reuse some of the good stuff?

4 Database Applications Dichotomy Online Transaction Processing (OLTP) Example: online e-commerce Write-intensive workloads Concurrency control, transactions Optimization goal: latency Data Warehousing/Data Analytics (DW/DA) Example: fraud analysis Read-dominated workloads Optimization goal: throughput
 Example: fraud analysis Read-dominated workloads Optimization goal:")
5 80 s-90 s: One-SQL-Fits-All Online Transaction Processing (OLTP) Read-Write Workload Real-Time Latency-Sensitive Transaction-Oriented Benchmark: TPC-C Analytics BI Tools Latency-Oriented Data Cubes Read-Only Workload Batch Processing Non-Transactional ETL Benchmark: TPC-H SQL DBMS (Oracle, DB2, SQL Server, MySQL, ) ACID transactions Moderate scale (TBs not PBs)
 ACID transactions Moderate")
6 The NoSQL Revolution Split between Analytics and OLTP Google (early 2000 s): Map-Reduce vs Bigtable Open-source: Hadoop MR vs Hbase Started from breaking many things (overhead) Simplified semantics Eliminated transactions Nowadays, returning to basics in many areas Focus for the next 2 weeks: analytics systems

7 Relational Databases in a Nutshell The data is structured Reflects Entities and Relationships ERD = Entity-Relationship Diagram ERD captured by schema Data set = set of tables Table = set of tuples (rows) Row = set of items (columns, attributes) Typically, uniquely addressable by primary key Relational Algebra Theoretical foundation for relational databases

8 Working with Relational Data Create the schema (1 or more tables) DDL Data Definition Language Load data into the tables Often requires ETL (Extract/Transform/Load) tools Query the data DML Data Manipulation Language SQL (Structured Query Language) Implementation of DDL and DML
 Implementation of DDL and")
9 Capturing Relationships De-normalized design Nested data, single table Normalized design Flat data, multiple tables with cross-references Customer Birthday Transactions Customer Id Date Amount Jones 1/1/1980 Id Date Amount /10/ /10/ Wilkinson 1/2/1980 Id Date Amount /10/ Stevens 1/3/1980 Id Date Amount /10/ /11/ Jones /10/ Jones /10/ Wilkinson /10/ Stevens /10/ Stevens /11/ Customer Birthday Jones 1/1/1980 Wilkinson 1/2/1980 Stevens 1/3/1980

10 Database Designer s Dilemma Normalized Design Transparent, easy to maintain and extend Amenable to horizontal scalability Easy to verify referential integrity Non-biased towards specific query workloads Runtime cost: cross-table joins De-normalized design Constrains application semantics Might suffer from modification anomalies Can be optimized for specific workloads, no joins

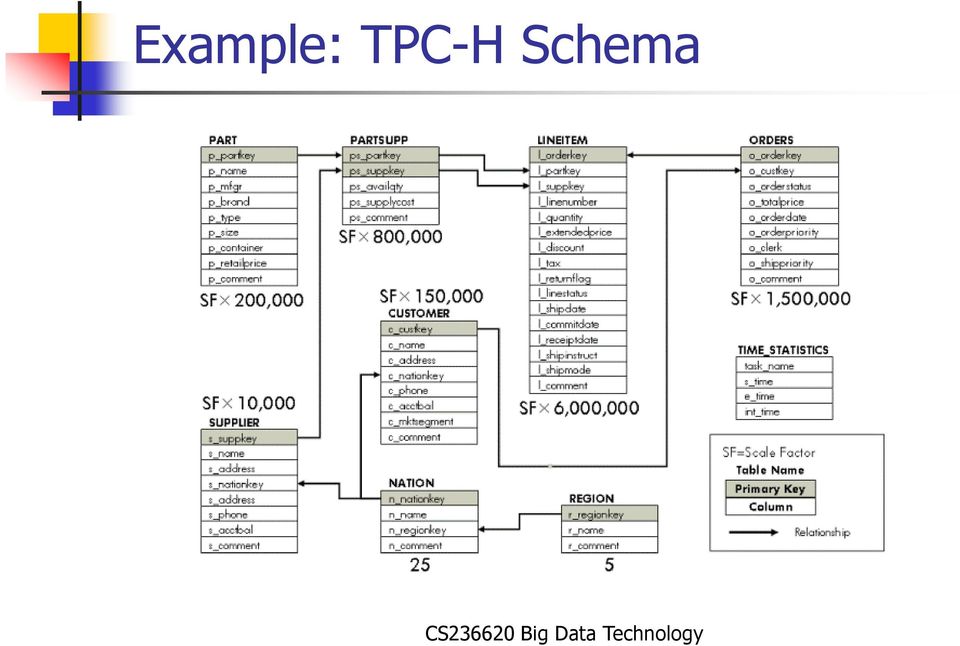
11 Example: TPC-H Schema
12 SQL (Structured Query Language) Declarative programming language Focus on what you want, not how to retrieve Flexible, Great for non-engineers Designed for relational databases Select (read) Insert/Update/Delete (write) Costs Administration (schema management) Query optimization (compiler or manual)
 Costs Administration (schema management) Query optimization")
13 SQL Primitives Project SELECT url FROM pages Filter (Select) SELECT url FROM pages WHERE pagerank > 0.95

14 SQL Primitives Join ( ) SELECT visits.user, pages.category FROM visits, pages WHERE visits.url = pages.url SELECT p1.header, p2.header alias FROM pages p1, pages p2, links l1, links l2 WHERE p1.url=l1.from AND p2.url=l2.to AND l1. id = l2.id

15 SQL Primitives Aggregation SELECT url, COUNT(url) FROM visits GROUP BY url HAVING COUNT(url) > 1000 COUNT, SUM, AVG, STDDEV, MIN, MAX

16 SQL Primitives Sort SELECT cookie, query FROM querylog WHERE date < 1/1/2013 AND date > 1/12/2012 ORDER BY cookie, date

17 SQL Implementation Specific programming language type Machine = [distributed] runtime environment Instruction set = relational operators Receive and return tuple sets Query plan = compiler-generated program Operators + flow of control

18 Query Plan - Aggregation SELECT url, COUNT(url) FROM visits GROUP BY url HAVING COUNT(url) > 1000 Filter by count Aggregate by count Group by url Load visits visits

19 Query Plan - Join SELECT p1.header, p2.header FROM pages p1, pages p2, links l1, links l2 WHERE p1.url=l1.from AND p2.url=l2.to AND l1. id = l2.id Join l1.id = l2.id Join l1.from=p1.url Join l2.to=p2.url Load Load Load Load pages links pages links

20 Dataflow Architectures Query plan = DAG Nodes = relational operators Links = queues Performance boosted through Data parallelism Compute parallelism Pipelining

21 Query Optimization Multiple plans can be logically equivalent Relation algebra allows operator re-ordering Multiple operator implementations possible Goal: pick a plan that minimizes query latency Minimize I/O, communication and computation No-brainer optimizations: push the filters deep Nontrivial optimizations: order of joins Challenge: exponential-size search space
22 SQL versus Map-Reduce SQL Good for structured data Rich declarative API (tool for analysts) Machine optimization, non-transparent to users Map-Reduce Good for structured and unstructured data Simple programmatic API (tool for engineers) Users can optimize their jobs manually Can we enjoy the best of both worlds?
23 Implementation atop Map-Reduce Project, Filter easy (how?) Sort for free (not always required) Aggregation mostly easy (how?) Stream processing (O(1) intermediate state) How to handle TOP-K, AVG, STDDEV? Join? Hint: use multiple Map inputs
24 Join over MR (1) L M-Left M-Left M-Left Sort by key + L Partition by key R R R R Select L.x, R.y From L, R Where L.key = R.key M-Right M-Right M-Right Sort by key + R Partition by key key L key R key R key R key R
25 Join over MR (2) Typical situation: Big Small E.g., Page Accesses (B) User Details (S) Idea: avoid reduce altogether Approach: replicate S to all mappers Use shared files (distributed thru the MR cache) At each mapper: Store in RAM, hashed by join key Scan the B-partition, compute match per record
26 Apache Hive Data warehouse atop Hadoop MR Structured (schema-based) data SQL dialect - HiveQL Select, project, join (2-way), aggregation Accommodates user-defined functions (UDF) [As of recently] fairly weak compiler optimization
27 Apache HCatalog Table and storage management service Shared schema and data type mechanism Table abstraction Users unaware of where/how their data is stored Interoperability across tools Map-Reduce, Hive, Pig (next class)
28 Summary SQL atop MR Good for data warehouses, batch queries The less legacy semantics, the better scalability Bad for interactive ad-hoc queries Batch-oriented (high launch overhead) Scan-oriented, lookups are expensive Intermediate results materialized on DFS Dataflow underexploited (limited pipelining)
29 Next Class Pig Latin a procedural query language Real-time query processing
30 Further Reading A comparison of approaches to large-scale data analysis Map Reduce: A Major Step Backwards
Big Data Technology Pig: Query Language atop Map-Reduce
 Big Data Technology Pig: Query Language atop Map-Reduce Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class MR Implementation This class
Big Data Technology Pig: Query Language atop Map-Reduce Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class MR Implementation This class
Big Data With Hadoop
 With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh [email protected] The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
Using distributed technologies to analyze Big Data
 Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Using distributed technologies to analyze Big Data Abhijit Sharma Innovation Lab BMC Software 1 Data Explosion in Data Center Performance / Time Series Data Incoming data rates ~Millions of data points/
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 Hadoop Ecosystem Overview of this Lecture Module Background Google MapReduce The Hadoop Ecosystem Core components: Hadoop
Programming Hadoop 5-day, instructor-led BD-106. MapReduce Overview. Hadoop Overview
 Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
Programming Hadoop 5-day, instructor-led BD-106 MapReduce Overview The Client Server Processing Pattern Distributed Computing Challenges MapReduce Defined Google's MapReduce The Map Phase of MapReduce
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
extensible record stores document stores key-value stores Rick Cattel s clustering from Scalable SQL and NoSQL Data Stores SIGMOD Record, 2010
 System/ Scale to Primary Secondary Joins/ Integrity Language/ Data Year Paper 1000s Index Indexes Transactions Analytics Constraints Views Algebra model my label 1971 RDBMS O tables sql-like 2003 memcached
System/ Scale to Primary Secondary Joins/ Integrity Language/ Data Year Paper 1000s Index Indexes Transactions Analytics Constraints Views Algebra model my label 1971 RDBMS O tables sql-like 2003 memcached
Lecture 10: HBase! Claudia Hauff (Web Information Systems)! [email protected]
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Processing, 2014/15 Lecture 10: HBase!! Claudia Hauff (Web Information Systems)! [email protected] 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind the
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines
 Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
Big Data Technology Map-Reduce Motivation: Indexing in Search Engines Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Indexing in Search Engines Information Retrieval s two main stages: Indexing process
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 [email protected] www.scch.at Michael Zwick DI
Building Scalable Big Data Infrastructure Using Open Source Software. Sam William sampd@stumbleupon.
 Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
Building Scalable Big Data Infrastructure Using Open Source Software Sam William sampd@stumbleupon. What is StumbleUpon? Help users find content they did not expect to find The best way to discover new
How To Handle Big Data With A Data Scientist
 III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
III Big Data Technologies Today, new technologies make it possible to realize value from Big Data. Big data technologies can replace highly customized, expensive legacy systems with a standard solution
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Internals of Hadoop Application Framework and Distributed File System
 International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
International Journal of Scientific and Research Publications, Volume 5, Issue 7, July 2015 1 Internals of Hadoop Application Framework and Distributed File System Saminath.V, Sangeetha.M.S Abstract- Hadoop
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE
 INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
INTRODUCTION TO APACHE HADOOP MATTHIAS BRÄGER CERN GS-ASE AGENDA Introduction to Big Data Introduction to Hadoop HDFS file system Map/Reduce framework Hadoop utilities Summary BIG DATA FACTS In what timeframe
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Big Data Course Highlights
 Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data Course Highlights The Big Data course will start with the basics of Linux which are required to get started with Big Data and then slowly progress from some of the basics of Hadoop/Big Data (like
Big Data. Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich
 Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Big Data Donald Kossmann & Nesime Tatbul Systems Group ETH Zurich MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce The Hadoop
Big Data Technology Core Hadoop: HDFS-YARN Internals
 Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Big Data Technology Core Hadoop: HDFS-YARN Internals Eshcar Hillel Yahoo! Ronny Lempel Outbrain *Based on slides by Edward Bortnikov & Ronny Lempel Roadmap Previous class Map-Reduce Motivation This class
Data Management in the Cloud
 Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Data Management in the Cloud Ryan Stern [email protected] : Advanced Topics in Distributed Systems Department of Computer Science Colorado State University Outline Today Microsoft Cloud SQL Server
Apache HBase. Crazy dances on the elephant back
 Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
Apache HBase Crazy dances on the elephant back Roman Nikitchenko, 16.10.2014 YARN 2 FIRST EVER DATA OS 10.000 nodes computer Recent technology changes are focused on higher scale. Better resource usage
An Oracle White Paper November 2010. Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics
 An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
An Oracle White Paper November 2010 Leveraging Massively Parallel Processing in an Oracle Environment for Big Data Analytics 1 Introduction New applications such as web searches, recommendation engines,
Can the Elephants Handle the NoSQL Onslaught?
 Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Can the Elephants Handle the NoSQL Onslaught? Avrilia Floratou, Nikhil Teletia David J. DeWitt, Jignesh M. Patel, Donghui Zhang University of Wisconsin-Madison Microsoft Jim Gray Systems Lab Presented
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Big Data Approaches. Making Sense of Big Data. Ian Crosland. Jan 2016
 Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Big Data Approaches Making Sense of Big Data Ian Crosland Jan 2016 Accelerate Big Data ROI Even firms that are investing in Big Data are still struggling to get the most from it. Make Big Data Accessible
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
THE DEVELOPER GUIDE TO BUILDING STREAMING DATA APPLICATIONS
 THE DEVELOPER GUIDE TO BUILDING STREAMING DATA APPLICATIONS WHITE PAPER Successfully writing Fast Data applications to manage data generated from mobile, smart devices and social interactions, and the
THE DEVELOPER GUIDE TO BUILDING STREAMING DATA APPLICATIONS WHITE PAPER Successfully writing Fast Data applications to manage data generated from mobile, smart devices and social interactions, and the
Trafodion Operational SQL-on-Hadoop
 Trafodion Operational SQL-on-Hadoop SophiaConf 2015 Pierre Baudelle, HP EMEA TSC July 6 th, 2015 Hadoop workload profiles Operational Interactive Non-interactive Batch Real-time analytics Operational SQL
Trafodion Operational SQL-on-Hadoop SophiaConf 2015 Pierre Baudelle, HP EMEA TSC July 6 th, 2015 Hadoop workload profiles Operational Interactive Non-interactive Batch Real-time analytics Operational SQL
Xiaoming Gao Hui Li Thilina Gunarathne
 Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
Xiaoming Gao Hui Li Thilina Gunarathne Outline HBase and Bigtable Storage HBase Use Cases HBase vs RDBMS Hands-on: Load CSV file to Hbase table with MapReduce Motivation Lots of Semi structured data Horizontal
SQL VS. NO-SQL. Adapted Slides from Dr. Jennifer Widom from Stanford
 SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
SQL VS. NO-SQL Adapted Slides from Dr. Jennifer Widom from Stanford 55 Traditional Databases SQL = Traditional relational DBMS Hugely popular among data analysts Widely adopted for transaction systems
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 15
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 15 Big Data Management V (Big-data Analytics / Map-Reduce) Chapter 16 and 19: Abideboul et. Al. Demetris
Big Data Analytics Platform @ Nokia
 Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
Big Data Analytics Platform @ Nokia 1 Selecting the Right Tool for the Right Workload Yekesa Kosuru Nokia Location & Commerce Strata + Hadoop World NY - Oct 25, 2012 Agenda Big Data Analytics Platform
This article is the second
 This article is the second of a series by Pythian experts that will regularly be published as the Performance Corner column in the NoCOUG Journal. The main software components of Oracle Big Data Appliance
This article is the second of a series by Pythian experts that will regularly be published as the Performance Corner column in the NoCOUG Journal. The main software components of Oracle Big Data Appliance
Hadoop for MySQL DBAs. Copyright 2011 Cloudera. All rights reserved. Not to be reproduced without prior written consent.
 Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years [email protected] 2 What is Hadoop? An open-source
Hadoop for MySQL DBAs + 1 About me Sarah Sproehnle, Director of Educational Services @ Cloudera Spent 5 years at MySQL At Cloudera for the past 2 years [email protected] 2 What is Hadoop? An open-source
Petabyte Scale Data at Facebook. Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013
 Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Petabyte Scale Data at Facebook Dhruba Borthakur, Engineer at Facebook, SIGMOD, New York, June 2013 Agenda 1 Types of Data 2 Data Model and API for Facebook Graph Data 3 SLTP (Semi-OLTP) and Analytics
Big Data: Using ArcGIS with Apache Hadoop. Erik Hoel and Mike Park
 Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
Big Data: Using ArcGIS with Apache Hadoop Erik Hoel and Mike Park Outline Overview of Hadoop Adding GIS capabilities to Hadoop Integrating Hadoop with ArcGIS Apache Hadoop What is Hadoop? Hadoop is a scalable
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related
 Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Chapter 11 Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Summary Xiangzhe Li Nowadays, there are more and more data everyday about everything. For instance, here are some of the astonishing
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Big Systems, Big Data
 Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Big Systems, Big Data When considering Big Distributed Systems, it can be noted that a major concern is dealing with data, and in particular, Big Data Have general data issues (such as latency, availability,
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Apache Kylin Introduction Dec 8, 2014 @ApacheKylin
 Apache Kylin Introduction Dec 8, 2014 @ApacheKylin Luke Han Sr. Product Manager [email protected] @lukehq Yang Li Architect & Tech Leader [email protected] Agenda What s Apache Kylin? Tech Highlights Performance
Apache Kylin Introduction Dec 8, 2014 @ApacheKylin Luke Han Sr. Product Manager [email protected] @lukehq Yang Li Architect & Tech Leader [email protected] Agenda What s Apache Kylin? Tech Highlights Performance
Impala: A Modern, Open-Source SQL Engine for Hadoop. Marcel Kornacker Cloudera, Inc.
 Impala: A Modern, Open-Source SQL Engine for Hadoop Marcel Kornacker Cloudera, Inc. Agenda Goals; user view of Impala Impala performance Impala internals Comparing Impala to other systems Impala Overview:
Impala: A Modern, Open-Source SQL Engine for Hadoop Marcel Kornacker Cloudera, Inc. Agenda Goals; user view of Impala Impala performance Impala internals Comparing Impala to other systems Impala Overview:
Hadoop Introduction. Olivier Renault Solution Engineer - Hortonworks
 Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Hadoop Introduction Olivier Renault Solution Engineer - Hortonworks Hortonworks A Brief History of Apache Hadoop Apache Project Established Yahoo! begins to Operate at scale Hortonworks Data Platform 2013
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2015 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig
 BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
BIG DATA HANDS-ON WORKSHOP Data Manipulation with Hive and Pig Contents Acknowledgements... 1 Introduction to Hive and Pig... 2 Setup... 2 Exercise 1 Load Avro data into HDFS... 2 Exercise 2 Define an
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: [email protected] Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Moving From Hadoop to Spark
 + Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
+ Moving From Hadoop to Spark Sujee Maniyam Founder / Principal @ www.elephantscale.com [email protected] Bay Area ACM meetup (2015-02-23) + HI, Featured in Hadoop Weekly #109 + About Me : Sujee
Hadoop Job Oriented Training Agenda
 1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
1 Hadoop Job Oriented Training Agenda Kapil CK [email protected] Module 1 M o d u l e 1 Understanding Hadoop This module covers an overview of big data, Hadoop, and the Hortonworks Data Platform. 1.1 Module
Big Data and Analytics by Seema Acharya and Subhashini Chellappan Copyright 2015, WILEY INDIA PVT. LTD. Introduction to Pig
 Introduction to Pig Agenda What is Pig? Key Features of Pig The Anatomy of Pig Pig on Hadoop Pig Philosophy Pig Latin Overview Pig Latin Statements Pig Latin: Identifiers Pig Latin: Comments Data Types
Introduction to Pig Agenda What is Pig? Key Features of Pig The Anatomy of Pig Pig on Hadoop Pig Philosophy Pig Latin Overview Pig Latin Statements Pig Latin: Identifiers Pig Latin: Comments Data Types
Lambda Architecture. Near Real-Time Big Data Analytics Using Hadoop. January 2015. Email: [email protected] Website: www.qburst.com
 Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Lambda Architecture Near Real-Time Big Data Analytics Using Hadoop January 2015 Contents Overview... 3 Lambda Architecture: A Quick Introduction... 4 Batch Layer... 4 Serving Layer... 4 Speed Layer...
Managing Big Data with Hadoop & Vertica. A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database
 Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Managing Big Data with Hadoop & Vertica A look at integration between the Cloudera distribution for Hadoop and the Vertica Analytic Database Copyright Vertica Systems, Inc. October 2009 Cloudera and Vertica
Introduction to Apache Cassandra
 Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Introduction to Apache Cassandra White Paper BY DATASTAX CORPORATION JULY 2013 1 Table of Contents Abstract 3 Introduction 3 Built by Necessity 3 The Architecture of Cassandra 4 Distributing and Replicating
Big Data Analytics. with EMC Greenplum and Hadoop. Big Data Analytics. Ofir Manor Pre Sales Technical Architect EMC Greenplum
 Big Data Analytics with EMC Greenplum and Hadoop Big Data Analytics with EMC Greenplum and Hadoop Ofir Manor Pre Sales Technical Architect EMC Greenplum 1 Big Data and the Data Warehouse Potential All
Big Data Analytics with EMC Greenplum and Hadoop Big Data Analytics with EMC Greenplum and Hadoop Ofir Manor Pre Sales Technical Architect EMC Greenplum 1 Big Data and the Data Warehouse Potential All
Database Scalability and Oracle 12c
 Database Scalability and Oracle 12c Marcelle Kratochvil CTO Piction ACE Director All Data/Any Data [email protected] Warning I will be covering topics and saying things that will cause a rethink in
Database Scalability and Oracle 12c Marcelle Kratochvil CTO Piction ACE Director All Data/Any Data [email protected] Warning I will be covering topics and saying things that will cause a rethink in
Big Data Technology CS 236620, Technion, Spring 2014
 Big Data Technology CS 236620, Technion, Spring 2014 System Design Principles Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Data = Systems We need to Move, Store and Process data Big Data = Big Systems
Big Data Technology CS 236620, Technion, Spring 2014 System Design Principles Edward Bortnikov & Ronny Lempel Yahoo Labs, Haifa Data = Systems We need to Move, Store and Process data Big Data = Big Systems
Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com
 REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
REPORT Splice Machine: SQL-on-Hadoop Evaluation Guide www.splicemachine.com The content of this evaluation guide, including the ideas and concepts contained within, are the property of Splice Machine,
11/18/15 CS 6030. q Hadoop was not designed to migrate data from traditional relational databases to its HDFS. q This is where Hive comes in.
 by shatha muhi CS 6030 1 q Big Data: collections of large datasets (huge volume, high velocity, and variety of data). q Apache Hadoop framework emerged to solve big data management and processing challenges.
by shatha muhi CS 6030 1 q Big Data: collections of large datasets (huge volume, high velocity, and variety of data). q Apache Hadoop framework emerged to solve big data management and processing challenges.
American International Journal of Research in Science, Technology, Engineering & Mathematics
 American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
American International Journal of Research in Science, Technology, Engineering & Mathematics Available online at http://www.iasir.net ISSN (Print): 2328-3491, ISSN (Online): 2328-3580, ISSN (CD-ROM): 2328-3629
Infrastructures for big data
 Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
Infrastructures for big data Rasmus Pagh 1 Today s lecture Three technologies for handling big data: MapReduce (Hadoop) BigTable (and descendants) Data stream algorithms Alternatives to (some uses of)
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect
 Huibert Aalbers Senior Certified Executive IT Architect") The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
The evolution of database technology (II) Huibert Aalbers Senior Certified Executive IT Architect IT Insight podcast This podcast belongs to the IT Insight series You can subscribe to the podcast through
Systems Engineering II. Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de
 Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Systems Engineering II Pramod Bhatotia TU Dresden pramod.bhatotia@tu- dresden.de About me! Since May 2015 2015 2012 Research Group Leader cfaed, TU Dresden PhD Student MPI- SWS Research Intern Microsoft
Unified Big Data Analytics Pipeline. 连 城 [email protected]
 Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 [email protected] What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Data Warehouse Optimization
 Data Warehouse Optimization Embedding Hadoop in Data Warehouse Environments A Whitepaper Rick F. van der Lans Independent Business Intelligence Analyst R20/Consultancy September 2013 Sponsored by Copyright
Data Warehouse Optimization Embedding Hadoop in Data Warehouse Environments A Whitepaper Rick F. van der Lans Independent Business Intelligence Analyst R20/Consultancy September 2013 Sponsored by Copyright
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University [email protected] 14.9-2015 1/36 Google MapReduce A scalable batch processing
Architectures for Big Data Analytics A database perspective
 Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Architectures for Big Data Analytics A database perspective Fernando Velez Director of Product Management Enterprise Information Management, SAP June 2013 Outline Big Data Analytics Requirements Spectrum
Integrating Big Data into the Computing Curricula
 Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Integrating Big Data into the Computing Curricula Yasin Silva, Suzanne Dietrich, Jason Reed, Lisa Tsosie Arizona State University http://www.public.asu.edu/~ynsilva/ibigdata/ 1 Overview Motivation Big
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
Data Warehousing and Analytics Infrastructure at Facebook. Ashish Thusoo & Dhruba Borthakur athusoo,[email protected]
 Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Data Warehousing and Analytics Infrastructure at Facebook Ashish Thusoo & Dhruba Borthakur athusoo,[email protected] Overview Challenges in a Fast Growing & Dynamic Environment Data Flow Architecture,
Oracle Big Data SQL Technical Update
 Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
Oracle Big Data SQL Technical Update Jean-Pierre Dijcks Oracle Redwood City, CA, USA Keywords: Big Data, Hadoop, NoSQL Databases, Relational Databases, SQL, Security, Performance Introduction This technical
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
Application Development. A Paradigm Shift
 Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Application Development for the Cloud: A Paradigm Shift Ramesh Rangachar Intelsat t 2012 by Intelsat. t Published by The Aerospace Corporation with permission. New 2007 Template - 1 Motivation for the
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop
 Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
Facebook s Petabyte Scale Data Warehouse using Hive and Hadoop Why Another Data Warehousing System? Data, data and more data 200GB per day in March 2008 12+TB(compressed) raw data per day today Trends
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
How To Use Big Data For Telco (For A Telco)
") ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
ON-LINE VIDEO ANALYTICS EMBRACING BIG DATA David Vanderfeesten, Bell Labs Belgium ANNO 2012 YOUR DATA IS MONEY BIG MONEY! Your click stream, your activity stream, your electricity consumption, your call
MySQL and Hadoop. Percona Live 2014 Chris Schneider
 MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
MySQL and Hadoop Percona Live 2014 Chris Schneider About Me Chris Schneider, Database Architect @ Groupon Spent the last 10 years building MySQL architecture for multiple companies Worked with Hadoop for
HADOOP. Revised 10/19/2015
 HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
HADOOP Revised 10/19/2015 This Page Intentionally Left Blank Table of Contents Hortonworks HDP Developer: Java... 1 Hortonworks HDP Developer: Apache Pig and Hive... 2 Hortonworks HDP Developer: Windows...
Data-Intensive Programming. Timo Aaltonen Department of Pervasive Computing
 Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Data-Intensive Programming Timo Aaltonen Department of Pervasive Computing Data-Intensive Programming Lecturer: Timo Aaltonen University Lecturer [email protected] Assistants: Henri Terho and Antti
Analytics on Spark & Shark @Yahoo
 Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Analytics on Spark & Shark @Yahoo PRESENTED BY Tim Tully December 3, 2013 Overview Legacy / Current Hadoop Architecture Reflection / Pain Points Why the movement towards Spark / Shark New Hybrid Environment
Associate Professor, Department of CSE, Shri Vishnu Engineering College for Women, Andhra Pradesh, India 2
 Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
Volume 6, Issue 3, March 2016 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Special Issue
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
White Paper: What You Need To Know About Hadoop
 CTOlabs.com White Paper: What You Need To Know About Hadoop June 2011 A White Paper providing succinct information for the enterprise technologist. Inside: What is Hadoop, really? Issues the Hadoop stack
CTOlabs.com White Paper: What You Need To Know About Hadoop June 2011 A White Paper providing succinct information for the enterprise technologist. Inside: What is Hadoop, really? Issues the Hadoop stack
Complete Java Classes Hadoop Syllabus Contact No: 8888022204
 1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
1) Introduction to BigData & Hadoop What is Big Data? Why all industries are talking about Big Data? What are the issues in Big Data? Storage What are the challenges for storing big data? Processing What
AGENDA. What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story. Our BIG DATA Roadmap. Hadoop PDW
 AGENDA What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story Hadoop PDW Our BIG DATA Roadmap BIG DATA? Volume 59% growth in annual WW information 1.2M Zetabytes (10 21 bytes) this
AGENDA What is BIG DATA? What is Hadoop? Why Microsoft? The Microsoft BIG DATA story Hadoop PDW Our BIG DATA Roadmap BIG DATA? Volume 59% growth in annual WW information 1.2M Zetabytes (10 21 bytes) this
Using RDBMS, NoSQL or Hadoop?
 Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Architectural patterns for building real time applications with Apache HBase. Andrew Purtell Committer and PMC, Apache HBase
 Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Architectural patterns for building real time applications with Apache HBase Andrew Purtell Committer and PMC, Apache HBase Who am I? Distributed systems engineer Principal Architect in the Big Data Platform
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM
 A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
A REVIEW PAPER ON THE HADOOP DISTRIBUTED FILE SYSTEM Sneha D.Borkar 1, Prof.Chaitali S.Surtakar 2 Student of B.E., Information Technology, J.D.I.E.T, [email protected] Assistant Professor, Information
Hadoop and Relational Database The Best of Both Worlds for Analytics Greg Battas Hewlett Packard
 Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Hadoop and Relational base The Best of Both Worlds for Analytics Greg Battas Hewlett Packard The Evolution of Analytics Mainframe EDW Proprietary MPP Unix SMP MPP Appliance Hadoop? Questions Is Hadoop
Lofan Abrams Data Services for Big Data Session # 2987
 Lofan Abrams Data Services for Big Data Session # 2987 Big Data Are you ready for blast-off? Big Data, for better or worse: 90% of world s data generated over last two years. ScienceDaily, ScienceDaily
Lofan Abrams Data Services for Big Data Session # 2987 Big Data Are you ready for blast-off? Big Data, for better or worse: 90% of world s data generated over last two years. ScienceDaily, ScienceDaily
F1: A Distributed SQL Database That Scales. Presentation by: Alex Degtiar ([email protected]) 15-799 10/21/2013
 15-799 10/21/2013") F1: A Distributed SQL Database That Scales Presentation by: Alex Degtiar ([email protected]) 15-799 10/21/2013 What is F1? Distributed relational database Built to replace sharded MySQL back-end of AdWords
F1: A Distributed SQL Database That Scales Presentation by: Alex Degtiar ([email protected]) 15-799 10/21/2013 What is F1? Distributed relational database Built to replace sharded MySQL back-end of AdWords
PostgreSQL Business Intelligence & Performance Simon Riggs CTO, 2ndQuadrant PostgreSQL Major Contributor
 PostgreSQL Business Intelligence & Performance Simon Riggs CTO, 2ndQuadrant PostgreSQL Major Contributor The research leading to these results has received funding from the European Union's Seventh Framework
PostgreSQL Business Intelligence & Performance Simon Riggs CTO, 2ndQuadrant PostgreSQL Major Contributor The research leading to these results has received funding from the European Union's Seventh Framework
Relational Processing on MapReduce
 Relational Processing on MapReduce Jerome Simeon IBM Watson Research Content obtained from many sources, notably: Jimmy Lin course on MapReduce. Our Plan Today 1. Recap: Key relational DBMS notes Key Hadoop
Relational Processing on MapReduce Jerome Simeon IBM Watson Research Content obtained from many sources, notably: Jimmy Lin course on MapReduce. Our Plan Today 1. Recap: Key relational DBMS notes Key Hadoop
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?