Dirichlet Processes A gentle tutorial
|
|
|
- Gillian Stokes
- 8 years ago
- Views:
Transcription
1 Dirichlet Processes A gentle tutorial SELECT Lab Meeting October 14, 2008 Khalid El-Arini

2 Motivation We are given a data set, and are told that it was generated from a mixture of Gaussian distributions. Unfortunately, no one has any idea how many Gaussians produced the data. 2

3 Motivation We are given a data set, and are told that it was generated from a mixture of Gaussian distributions. Unfortunately, no one has any idea how many Gaussians produced the data. 3

4 Motivation We are given a data set, and are told that it was generated from a mixture of Gaussian distributions. Unfortunately, no one has any idea how many Gaussians produced the data. 4

5 What to do? We can guess the number of clusters, run Expectation Maximization (EM) for Gaussian Mixture Models, look at the results, and then try again We can run hierarchical agglomerative clustering, and cut the tree at a visually appealing level We want to cluster the data in a statistically principled manner, without resorting to hacks. 5

6 Other motivating examples Brain Imaging: Model an unknown number of spatial activation patterns in fmri images [Kim and Smyth, NIPS 2006] Topic Modeling: Model an unknown number of topics across several corpora of documents [Teh et al. 2006] 6
![and Smyth, NIPS 2006] Topic Modeling: Model an unknown](/docs-images/40/198766/images/page_6.jpg "number of topics across several corpora of documents [Teh et")
7 Overview Dirichlet distribution, and Dirichlet Process introduction Dirichlet Processes from different perspectives Samples from a Dirichlet Process Chinese Restaurant Process representation Stick Breaking Formal Definition Dirichlet Process Mixtures Inference 7

8 The Dirichlet Distribution Let We write: P (µ 1 ; µ 2 ; : : : ; µ m ) = (P k k ) Q k ( k ) my k=1 µ k 1 k Samples from the distribution lie in the m-1 dimensional probability simplex 8

9 The Dirichlet Distribution Let We write: Distribution over possible parameter vectors for a multinomial distribution, and is the conjugate prior for the multinomial. Beta distribution is the special case of a Dirichlet for 2 dimensions. Thus, it is in fact a distribution over distributions. 9

10 Dirichlet Process A Dirichlet Process is also a distribution over distributions. Let G be Dirichlet Process distributed: G 0 is a base distribution G ~ DP(α, G 0 ) α is a positive scaling parameter G is a random probability measure that has the same support as G 0 10
 α is a positive scaling parameter G is a random")
11 Dirichlet Process Consider Gaussian G 0 G ~ DP(α, G 0 ) 11

12 Dirichlet Process G ~ DP(α, G 0 ) G 0 is continuous, so the probability that any two samples are equal is precisely zero. However, G is a discrete distribution, made up of a countably infinite number of point masses [Blackwell] 12 Therefore, there is always a non-zero probability of two samples colliding

13 Overview Dirichlet distribution, and Dirichlet Process introduction Dirichlet Processes from different perspectives Samples from a Dirichlet Process Chinese Restaurant Process representation Stick Breaking Formal Definition Dirichlet Process Mixtures Inference 13

14 Samples from a Dirichlet Process G ~ DP(α, G 0 ) X n G ~ G for n = {1,, N} (iid given G) G Marginalizing out G introduces dependencies between the X n variables X n N 14

15 Samples from a Dirichlet Process Assume we view these variables in a specific order, and are interested in the behavior of X n given the previous n - 1 observations. Let there be K unique values for the variables: 15

16 Samples from a Dirichlet Process Chain rule P(partition) P(draws) Notice that the above formulation of the joint distribution does not depend on the order we consider the variables. 16

17 Samples from a Dirichlet Process Let there be K unique values for the variables: Can rewrite as: 17

18 Blackwell-MacQueen Urn Scheme G ~ DP(α, G 0 ) X n G ~ G Assume that G 0 is a distribution over colors, and that each X n represents the color of a single ball placed in the urn. Start with an empty urn. On step n: With probability proportional to α, draw X n ~ G 0, and add a ball of that color to the urn. With probability proportional to n 1 (i.e., the number of balls currently in the urn), pick a ball at random from the urn. Record its color as X n, and return the ball into the urn, along with a new one of the same color. [Blackwell and Macqueen, 1973] 18
, pick a ball at random from the urn.")
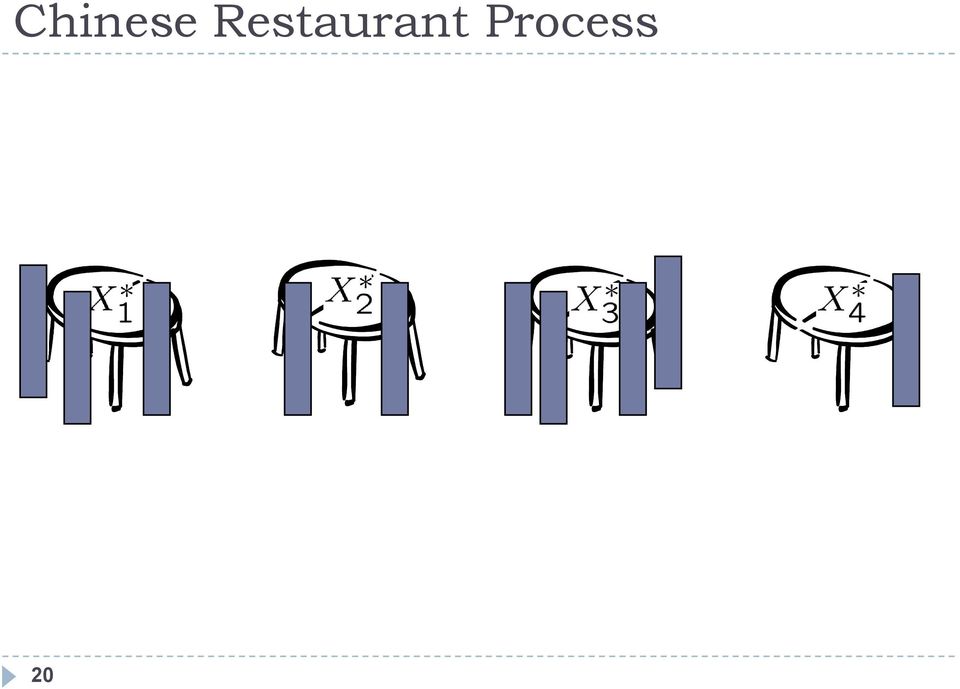
19 Chinese Restaurant Process Consider a restaurant with infinitely many tables, where the X n s represent the patrons of the restaurant. From the above conditional probability distribution, we can see that a customer is more likely to sit at a table if there are already many people sitting there. However, with probability proportional to α, the customer will sit at a new table. Also known as the clustering effect, and can be seen in the setting of social clubs. [Aldous] 19

20 Chinese Restaurant Process 20
21 Stick Breaking So far, we ve just mentioned properties of a distribution G drawn from a Dirichlet Process In 1994, Sethuraman developed a constructive way of forming G, known as stick breaking 21
22 Stick Breaking 1. Draw X 1 * from G 0 2. Draw v 1 from Beta(1, α) 3. π 1 = v 1 4. Draw X 2 * from G 0 5. Draw v 2 from Beta(1, α) 6. π 2 = v 2 (1 v 1 ) 22
, then for any finite set of partitions of A: A 1 A 2 A 3 A 4 A 5 A 6")
23 Formal Definition (not constructive) Let α be a positive, real-valued scalar Let G 0 be a non-atomic probability distribution over support set A If G ~ DP(α, G 0 ), then for any finite set of partitions of A: A 1 A 2 A 3 A 4 A 5 A 6 A 7 23
24 Overview Dirichlet distribution, and Dirichlet Process introduction Dirichlet Processes from different perspectives Samples from a Dirichlet Process Chinese Restaurant Process representation Stick Breaking Formal Definition Dirichlet Process Mixtures Inference 24
25 Finite Mixture Models A finite mixture model assumes that the data come from a mixture of a finite number of distributions. α π ~ Dirichlet(α/K,, α/k) π Component labels G 0 c n ~ Multinomial(π) c n η * k η k ~ G 0 k=1 K y n c n, η 1, η K ~ F( η cn ) y n 25 n=1 N
26 Infinite Mixture Models An infinite mixture model assumes that the data come from a mixture of an infinite number of distributions α π G 0 π ~ Dirichlet(α/K,, α/k) c n ~ Multinomial(π) c n η * k k=1 K η k ~ G 0 y n c n, η 1, η K ~ F( η cn ) 26 y n n=1 N Take limit as K goes to Note: the N data points still come from at most N different components [Rasmussen 2000]
27 Dirichlet Process Mixture G η n y n G 0 α countably infinite number of point masses draw N times from G to get parameters for different mixture components If η n were drawn from, e.g., a Gaussian, no two values would be the same, but since they are drawn from a Dirichlet Process-distributed distribution, we expect a clustering of the η n n=1 N # unique values for η n = # mixture components 27
28 CRP Mixture 28
29 Overview Dirichlet distribution, and Dirichlet Process introduction Dirichlet Processes from different perspectives Samples from a Dirichlet Process Chinese Restaurant Process representation Stick Breaking Formal Definition Dirichlet Process Mixtures Inference 29
30 Inference for Dirichlet Process Mixtures Expectation Maximization (EM) is generally used for inference in a mixture model, but G is nonparametric, making EM difficult G η n G 0 α Markov Chain Monte Carlo techniques [Neal 2000] Variational Inference [Blei and Jordan 2006] y n n=1 N 30
31 Aside: Monte Carlo Methods [Basic Integration] We want to compute the integral, where f(x) is a probability density function. In other words, we want E f [h(x)]. We can approximate this as: where X 1, X 2,, X N are sampled from f. By the law of large numbers, 31 [Lafferty and Wasserman]
 Goal is to generate a Markov chain X 1, X 2,, whose stationary distribution is f.")
32 Aside: Monte Carlo Methods [What if we don t know how to sample from f?] Importance Sampling Markov Chain Monte Carlo (MCMC) Goal is to generate a Markov chain X 1, X 2,, whose stationary distribution is f. If so, then 1 N NX i=1 h(x i ) p! I (under certain conditions) 32
![Aside: Monte Carlo Methods [MCMC I: Metropolis-Hastings Algorithm] Goal: Generate a Markov chain with stationary distribution f(x) Initialization: Let q(y x) be an arbitrary distribution that we know](/docs-images/19/198766/images/33-0.png "how to sample from. We call q the proposal distribution. Arbitrarily choose X 0. Assume we have generated X 0, X 1,, X i.")
33 Aside: Monte Carlo Methods [MCMC I: Metropolis-Hastings Algorithm] Goal: Generate a Markov chain with stationary distribution f(x) Initialization: Let q(y x) be an arbitrary distribution that we know how to sample from. We call q the proposal distribution. Arbitrarily choose X 0. Assume we have generated X 0, X 1,, X i. To simplifies generate to: X i+1 : Generate a proposal value Y ~ q(y X i ) Evaluate r r(x i, Y) where: A common choice is N(x, b 2 ) for b > 0 If q is symmetric, 33 Set: with probability r with probability 1-r [Lafferty and Wasserman]
34 Aside: Monte Carlo Methods [MCMC II: Gibbs Sampling] Goal: Generate a Markov chain with stationary distribution f(x, y) [Easily extendable to higher dimensions.] Assumption: We know how to sample from the conditional distributions f X Y (x y) and f Y X (y x) Initialization: Arbitrarily choose X 0, Y 0. Assume we have generated (X 0, Y 0 ),, (X i, Y i ). To generate (X i+1, Y i+1 ): X i+1 ~ f X Y (x Y i ) Y i+1 ~ f Y X (y X i+1 ) If not, then we run one iteration of Metropolis-Hastings each time we need to sample from a conditional. 34 [Lafferty and Wasserman]
35 MCMC for Dirichlet Process Mixtures [Overview] We would like to sample from the posterior distribution: 35 P(η 1,, η N y 1, y N ) If we could, we would be able to determine: how many distinct components are likely contributing to our data. what the parameters are for each component. [Neal 2000] is an excellent resource describing several MCMC algorithms for solving this problem. We will briefly take a look at two of them. G η n y n n=1 N G 0 α
36 MCMC for Dirichlet Process Mixtures [Infinite Mixture Model representation] MCMC algorithms that are based on the infinite mixture model representation of Dirichlet Process Mixtures are found to be simpler to implement and converge faster than those based on the direct representation. Thus, rather than sampling for η 1,, η N directly, we will instead sample for the component indicators c 1,, c N, as well as the component parameters η * c, for all c in {c 1,, c N } α π c n y n n=1 N G 0 η * k k=1 36 [Neal 2000]
![MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Conjugate Priors] Assume current state of Markov chain consists of c 1,, c N, as well as the component parameters η * c, for all c in {c 1,, c](/docs-images/19/198766/images/37-0.png "N }. To generate the next sample: 1. For i = 1,,N: If c i is currently a singleton, remove η * c i from the state.")
37 MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Conjugate Priors] Assume current state of Markov chain consists of c 1,, c N, as well as the component parameters η * c, for all c in {c 1,, c N }. To generate the next sample: 1. For i = 1,,N: If c i is currently a singleton, remove η * c i from the state. Draw a new value for c i from the conditional distribution: for existing c for new c 37 If the new c i is not associated with any other observation, draw a value for η * c i from: [Neal 2000, Algorithm 2]
![MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Conjugate Priors] 2.](/docs-images/19/198766/images/38-0.png "For all c in {c 1,, c N }: Draw a new value for η * c from the posterior distribution based on the prior G 0 and all the data points currently associated with component")
38 MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Conjugate Priors] 2. For all c in {c 1,, c N }: Draw a new value for η * c from the posterior distribution based on the prior G 0 and all the data points currently associated with component c: This algorithm breaks down when G 0 is not a conjugate prior. 38 [Neal 2000, Algorithm 2]
39 MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Auxiliary Parameters] Recall from the Gibbs sampling overview: if we do not know how to sample from the conditional distributions, we can interleave one or more Metropolis-Hastings steps. We can apply this technique when G 0 is not a conjugate prior, but it can lead to convergence issues [Neal 2000, Algorithms 5-7] Instead, we will use auxiliary parameters. Previously, the state of our Markov chain consisted of c 1,, c N, as well as component parameters η * c, for all c in {c 1,, c N }. When updating c i, we either: choose an existing component c from c -i (i.e., all c j such that j i). choose a brand new component. In the previous algorithm, this involved integrating with respect to G 0, which is difficult in the non-conjugate case. 39 [Neal 2000, Algorithm 8]
40 MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Auxiliary Parameters] When updating c i, we either: choose an existing component c from c -i (i.e., all c j such that j i). choose a brand new component. Let K -i be the number of distinct components c in c -i. WLOG, let these components c -i have values in {1,, K -i }. Instead of integrating over G 0, we will add m auxiliary parameters, each corresponding to a new component independently drawn from G 0 : [η * K -i +1,, η * K -i +m ] Recall that the probability of selecting a new component is proportional to α. Here, we divide α equally among the m auxiliary components. 40 [Neal 2000, Algorithm 8]
41 MCMC for Dirichlet Process Mixtures [Gibbs Sampling with Auxiliary Parameters] Probability: (proportional to) α/3 α/3 α/3 Components: η * 1 η * 2 η * 3 η * 4 η * 5 η * 6 η * 7 Each is a fresh draw from G 0 Data: y 1 y 2 y 3 y 4 y 5 y 6 y 7 This takes care of sampling for c i in the non-conjugate case. A Metropolis-Hastings step can be used to sample η * c. 41 c j : ? See Neal s paper for more details. [Neal 2000, Algorithm 8]
42 Conclusion We now have a statistically principled mechanism for solving our original problem. This was intended as a general and fairly high level overview of Dirichlet Processes. Topics left out include Hierarchical Dirichlet Processes, variational inference for Dirichlet Processes, and many more. Teh s MLSS 07 tutorial provides a much deeper and more detailed take on DPs highly recommended! 42
43 Acknowledgments Much thanks goes to David Blei. Some material for this presentation was inspired by slides from Teg Grenager, Zoubin Ghahramani, and Yee Whye Teh 43
44 References David Blackwell and James B. MacQueen. Ferguson Distributions via Polya Urn Schemes. Annals of Statistics 1(2), 1973, David M. Blei and Michael I. Jordan. Variational inference for Dirichlet process mixtures. Bayesian Analysis 1(1), Thomas S. Ferguson. A Bayesian Analysis of Some Nonparametric Problems Annals of Statistics 1(2), 1973, Zoubin Gharamani. Non-parametric Bayesian Methods. UAI Tutorial July Teg Grenager. Chinese Restaurants and Stick Breaking: An Introduction to the Dirichlet Process R.M. Neal. Markov chain sampling methods for Dirichlet process mixture models. Journal of Computational and Graphical Statistics, 9: , C.E. Rasmussen. The Infinite Gaussian Mixture Model. Advances in Neural Information Processing Systems 12, (Eds.) Solla, S. A., T. K. Leen and K. R. Müller, MIT Press (2000). Y.W. Teh. Dirichlet Processes. Machine Learning Summer School 2007 Tutorial and Practical Course. Y.W. Teh, M.I. Jordan, M.J. Beal and D.M. Blei. Hierarchical Dirichlet Processes. J. American Statistical Association 101(476): ,
Dirichlet Process. Yee Whye Teh, University College London
 Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
Dirichlet Process Yee Whye Teh, University College London Related keywords: Bayesian nonparametrics, stochastic processes, clustering, infinite mixture model, Blackwell-MacQueen urn scheme, Chinese restaurant
HT2015: SC4 Statistical Data Mining and Machine Learning
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
Bayesian Statistics: Indian Buffet Process
 Bayesian Statistics: Indian Buffet Process Ilker Yildirim Department of Brain and Cognitive Sciences University of Rochester Rochester, NY 14627 August 2012 Reference: Most of the material in this note
Bayesian Statistics: Indian Buffet Process Ilker Yildirim Department of Brain and Cognitive Sciences University of Rochester Rochester, NY 14627 August 2012 Reference: Most of the material in this note
Dirichlet Process Gaussian Mixture Models: Choice of the Base Distribution
 Görür D, Rasmussen CE. Dirichlet process Gaussian mixture models: Choice of the base distribution. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 5(4): 615 66 July 010/DOI 10.1007/s11390-010-1051-1 Dirichlet
Görür D, Rasmussen CE. Dirichlet process Gaussian mixture models: Choice of the base distribution. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 5(4): 615 66 July 010/DOI 10.1007/s11390-010-1051-1 Dirichlet
The Chinese Restaurant Process
 COS 597C: Bayesian nonparametrics Lecturer: David Blei Lecture # 1 Scribes: Peter Frazier, Indraneel Mukherjee September 21, 2007 In this first lecture, we begin by introducing the Chinese Restaurant Process.
COS 597C: Bayesian nonparametrics Lecturer: David Blei Lecture # 1 Scribes: Peter Frazier, Indraneel Mukherjee September 21, 2007 In this first lecture, we begin by introducing the Chinese Restaurant Process.
Tutorial on Markov Chain Monte Carlo
 Tutorial on Markov Chain Monte Carlo Kenneth M. Hanson Los Alamos National Laboratory Presented at the 29 th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Technology,
Tutorial on Markov Chain Monte Carlo Kenneth M. Hanson Los Alamos National Laboratory Presented at the 29 th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Technology,
Microclustering: When the Cluster Sizes Grow Sublinearly with the Size of the Data Set
 Microclustering: When the Cluster Sizes Grow Sublinearly with the Size of the Data Set Jeffrey W. Miller Brenda Betancourt Abbas Zaidi Hanna Wallach Rebecca C. Steorts Abstract Most generative models for
Microclustering: When the Cluster Sizes Grow Sublinearly with the Size of the Data Set Jeffrey W. Miller Brenda Betancourt Abbas Zaidi Hanna Wallach Rebecca C. Steorts Abstract Most generative models for
Machine Learning and Data Analysis overview. Department of Cybernetics, Czech Technical University in Prague. http://ida.felk.cvut.
 Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
Machine Learning and Data Analysis overview Jiří Kléma Department of Cybernetics, Czech Technical University in Prague http://ida.felk.cvut.cz psyllabus Lecture Lecturer Content 1. J. Kléma Introduction,
Gaussian Processes to Speed up Hamiltonian Monte Carlo
 Gaussian Processes to Speed up Hamiltonian Monte Carlo Matthieu Lê Murray, Iain http://videolectures.net/mlss09uk_murray_mcmc/ Rasmussen, Carl Edward. "Gaussian processes to speed up hybrid Monte Carlo
Gaussian Processes to Speed up Hamiltonian Monte Carlo Matthieu Lê Murray, Iain http://videolectures.net/mlss09uk_murray_mcmc/ Rasmussen, Carl Edward. "Gaussian processes to speed up hybrid Monte Carlo
Topic models for Sentiment analysis: A Literature Survey
 Topic models for Sentiment analysis: A Literature Survey Nikhilkumar Jadhav 123050033 June 26, 2014 In this report, we present the work done so far in the field of sentiment analysis using topic models.
Topic models for Sentiment analysis: A Literature Survey Nikhilkumar Jadhav 123050033 June 26, 2014 In this report, we present the work done so far in the field of sentiment analysis using topic models.
Nonparametric Factor Analysis with Beta Process Priors
 Nonparametric Factor Analysis with Beta Process Priors John Paisley Lawrence Carin Department of Electrical & Computer Engineering Duke University, Durham, NC 7708 jwp4@ee.duke.edu lcarin@ee.duke.edu Abstract
Nonparametric Factor Analysis with Beta Process Priors John Paisley Lawrence Carin Department of Electrical & Computer Engineering Duke University, Durham, NC 7708 jwp4@ee.duke.edu lcarin@ee.duke.edu Abstract
An Alternative Prior Process for Nonparametric Bayesian Clustering
 An Alternative Prior Process for Nonparametric Bayesian Clustering Hanna M. Wallach Department of Computer Science University of Massachusetts Amherst Shane T. Jensen Department of Statistics The Wharton
An Alternative Prior Process for Nonparametric Bayesian Clustering Hanna M. Wallach Department of Computer Science University of Massachusetts Amherst Shane T. Jensen Department of Statistics The Wharton
Introduction to Markov Chain Monte Carlo
 Introduction to Markov Chain Monte Carlo Monte Carlo: sample from a distribution to estimate the distribution to compute max, mean Markov Chain Monte Carlo: sampling using local information Generic problem
Introduction to Markov Chain Monte Carlo Monte Carlo: sample from a distribution to estimate the distribution to compute max, mean Markov Chain Monte Carlo: sampling using local information Generic problem
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 6 Three Approaches to Classification Construct
Statistics Graduate Courses
 Statistics Graduate Courses STAT 7002--Topics in Statistics-Biological/Physical/Mathematics (cr.arr.).organized study of selected topics. Subjects and earnable credit may vary from semester to semester.
Statistics Graduate Courses STAT 7002--Topics in Statistics-Biological/Physical/Mathematics (cr.arr.).organized study of selected topics. Subjects and earnable credit may vary from semester to semester.
The Dirichlet-Multinomial and Dirichlet-Categorical models for Bayesian inference
 The Dirichlet-Multinomial and Dirichlet-Categorical models for Bayesian inference Stephen Tu tu.stephenl@gmail.com 1 Introduction This document collects in one place various results for both the Dirichlet-multinomial
The Dirichlet-Multinomial and Dirichlet-Categorical models for Bayesian inference Stephen Tu tu.stephenl@gmail.com 1 Introduction This document collects in one place various results for both the Dirichlet-multinomial
Efficient Bayesian Methods for Clustering
 Efficient Bayesian Methods for Clustering Katherine Ann Heller B.S., Computer Science, Applied Mathematics and Statistics, State University of New York at Stony Brook, USA (2000) M.S., Computer Science,
Efficient Bayesian Methods for Clustering Katherine Ann Heller B.S., Computer Science, Applied Mathematics and Statistics, State University of New York at Stony Brook, USA (2000) M.S., Computer Science,
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Gaussian Processes in Machine Learning
 Gaussian Processes in Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics, 72076 Tübingen, Germany carl@tuebingen.mpg.de WWW home page: http://www.tuebingen.mpg.de/ carl
Gaussian Processes in Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics, 72076 Tübingen, Germany carl@tuebingen.mpg.de WWW home page: http://www.tuebingen.mpg.de/ carl
BayesX - Software for Bayesian Inference in Structured Additive Regression
 BayesX - Software for Bayesian Inference in Structured Additive Regression Thomas Kneib Faculty of Mathematics and Economics, University of Ulm Department of Statistics, Ludwig-Maximilians-University Munich
BayesX - Software for Bayesian Inference in Structured Additive Regression Thomas Kneib Faculty of Mathematics and Economics, University of Ulm Department of Statistics, Ludwig-Maximilians-University Munich
Online Model-Based Clustering for Crisis Identification in Distributed Computing
 Online Model-Based Clustering for Crisis Identification in Distributed Computing Dawn Woodard School of Operations Research and Information Engineering & Dept. of Statistical Science, Cornell University
Online Model-Based Clustering for Crisis Identification in Distributed Computing Dawn Woodard School of Operations Research and Information Engineering & Dept. of Statistical Science, Cornell University
Inference on Phase-type Models via MCMC
 Inference on Phase-type Models via MCMC with application to networks of repairable redundant systems Louis JM Aslett and Simon P Wilson Trinity College Dublin 28 th June 202 Toy Example : Redundant Repairable
Inference on Phase-type Models via MCMC with application to networks of repairable redundant systems Louis JM Aslett and Simon P Wilson Trinity College Dublin 28 th June 202 Toy Example : Redundant Repairable
Computing with Finite and Infinite Networks
 Computing with Finite and Infinite Networks Ole Winther Theoretical Physics, Lund University Sölvegatan 14 A, S-223 62 Lund, Sweden winther@nimis.thep.lu.se Abstract Using statistical mechanics results,
Computing with Finite and Infinite Networks Ole Winther Theoretical Physics, Lund University Sölvegatan 14 A, S-223 62 Lund, Sweden winther@nimis.thep.lu.se Abstract Using statistical mechanics results,
Bayes and Naïve Bayes. cs534-machine Learning
 Bayes and aïve Bayes cs534-machine Learning Bayes Classifier Generative model learns Prediction is made by and where This is often referred to as the Bayes Classifier, because of the use of the Bayes rule
Bayes and aïve Bayes cs534-machine Learning Bayes Classifier Generative model learns Prediction is made by and where This is often referred to as the Bayes Classifier, because of the use of the Bayes rule
The Basics of Graphical Models
 The Basics of Graphical Models David M. Blei Columbia University October 3, 2015 Introduction These notes follow Chapter 2 of An Introduction to Probabilistic Graphical Models by Michael Jordan. Many figures
The Basics of Graphical Models David M. Blei Columbia University October 3, 2015 Introduction These notes follow Chapter 2 of An Introduction to Probabilistic Graphical Models by Michael Jordan. Many figures
Efficient Cluster Detection and Network Marketing in a Nautural Environment
 A Probabilistic Model for Online Document Clustering with Application to Novelty Detection Jian Zhang School of Computer Science Cargenie Mellon University Pittsburgh, PA 15213 jian.zhang@cs.cmu.edu Zoubin
A Probabilistic Model for Online Document Clustering with Application to Novelty Detection Jian Zhang School of Computer Science Cargenie Mellon University Pittsburgh, PA 15213 jian.zhang@cs.cmu.edu Zoubin
Selection Sampling from Large Data sets for Targeted Inference in Mixture Modeling
 Selection Sampling from Large Data sets for Targeted Inference in Mixture Modeling Ioanna Manolopoulou, Cliburn Chan and Mike West December 29, 2009 Abstract One of the challenges of Markov chain Monte
Selection Sampling from Large Data sets for Targeted Inference in Mixture Modeling Ioanna Manolopoulou, Cliburn Chan and Mike West December 29, 2009 Abstract One of the challenges of Markov chain Monte
Bayesian Statistics in One Hour. Patrick Lam
 Bayesian Statistics in One Hour Patrick Lam Outline Introduction Bayesian Models Applications Missing Data Hierarchical Models Outline Introduction Bayesian Models Applications Missing Data Hierarchical
Bayesian Statistics in One Hour Patrick Lam Outline Introduction Bayesian Models Applications Missing Data Hierarchical Models Outline Introduction Bayesian Models Applications Missing Data Hierarchical
CHAPTER 2 Estimating Probabilities
 CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
CHAPTER 2 Estimating Probabilities Machine Learning Copyright c 2016. Tom M. Mitchell. All rights reserved. *DRAFT OF January 24, 2016* *PLEASE DO NOT DISTRIBUTE WITHOUT AUTHOR S PERMISSION* This is a
Learning Gaussian process models from big data. Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu
 Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
Learning Gaussian process models from big data Alan Qi Purdue University Joint work with Z. Xu, F. Yan, B. Dai, and Y. Zhu Machine learning seminar at University of Cambridge, July 4 2012 Data A lot of
Bayesian Machine Learning (ML): Modeling And Inference in Big Data. Zhuhua Cai Google, Rice University caizhua@gmail.com
: Modeling And Inference in Big Data. Zhuhua Cai Google, Rice University caizhua@gmail.com") Bayesian Machine Learning (ML): Modeling And Inference in Big Data Zhuhua Cai Google Rice University caizhua@gmail.com 1 Syllabus Bayesian ML Concepts (Today) Bayesian ML on MapReduce (Next morning) Bayesian
Bayesian Machine Learning (ML): Modeling And Inference in Big Data Zhuhua Cai Google Rice University caizhua@gmail.com 1 Syllabus Bayesian ML Concepts (Today) Bayesian ML on MapReduce (Next morning) Bayesian
Sampling via Moment Sharing: A New Framework for Distributed Bayesian Inference for Big Data
 Sampling via Moment Sharing: A New Framework for Distributed Bayesian Inference for Big Data (Oxford) in collaboration with: Minjie Xu, Jun Zhu, Bo Zhang (Tsinghua) Balaji Lakshminarayanan (Gatsby) Bayesian
Sampling via Moment Sharing: A New Framework for Distributed Bayesian Inference for Big Data (Oxford) in collaboration with: Minjie Xu, Jun Zhu, Bo Zhang (Tsinghua) Balaji Lakshminarayanan (Gatsby) Bayesian
An Introduction to Using WinBUGS for Cost-Effectiveness Analyses in Health Economics
 Slide 1 An Introduction to Using WinBUGS for Cost-Effectiveness Analyses in Health Economics Dr. Christian Asseburg Centre for Health Economics Part 1 Slide 2 Talk overview Foundations of Bayesian statistics
Slide 1 An Introduction to Using WinBUGS for Cost-Effectiveness Analyses in Health Economics Dr. Christian Asseburg Centre for Health Economics Part 1 Slide 2 Talk overview Foundations of Bayesian statistics
Visualization of Collaborative Data
 Visualization of Collaborative Data Guobiao Mei University of California, Riverside gmei@cs.ucr.edu Christian R. Shelton University of California, Riverside cshelton@cs.ucr.edu Abstract Collaborative data
Visualization of Collaborative Data Guobiao Mei University of California, Riverside gmei@cs.ucr.edu Christian R. Shelton University of California, Riverside cshelton@cs.ucr.edu Abstract Collaborative data
Introduction to Monte Carlo. Astro 542 Princeton University Shirley Ho
 Introduction to Monte Carlo Astro 542 Princeton University Shirley Ho Agenda Monte Carlo -- definition, examples Sampling Methods (Rejection, Metropolis, Metropolis-Hasting, Exact Sampling) Markov Chains
Introduction to Monte Carlo Astro 542 Princeton University Shirley Ho Agenda Monte Carlo -- definition, examples Sampling Methods (Rejection, Metropolis, Metropolis-Hasting, Exact Sampling) Markov Chains
Basics of Statistical Machine Learning
 CS761 Spring 2013 Advanced Machine Learning Basics of Statistical Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu Modern machine learning is rooted in statistics. You will find many familiar
CS761 Spring 2013 Advanced Machine Learning Basics of Statistical Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu Modern machine learning is rooted in statistics. You will find many familiar
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Estimating Incentive and Selection Effects in Medigap Insurance. Market: An Application with Dirichlet Process Mixture Model
 Estimating Incentive and Selection Effects in Medigap Insurance Market: An Application with Dirichlet Process Mixture Model Xuequn Hu Department of Economics University of South Florida Email: xhu8@usf.edu
Estimating Incentive and Selection Effects in Medigap Insurance Market: An Application with Dirichlet Process Mixture Model Xuequn Hu Department of Economics University of South Florida Email: xhu8@usf.edu
Nonparametric Bayesian Co-clustering Ensembles
 Nonparametric Bayesian Co-clustering Ensembles Pu Wang Kathryn B. Lasey Carlotta Domeniconi Michael I. Jordan Abstract A nonparametric Bayesian approach to co-clustering ensembles is presented. Similar
Nonparametric Bayesian Co-clustering Ensembles Pu Wang Kathryn B. Lasey Carlotta Domeniconi Michael I. Jordan Abstract A nonparametric Bayesian approach to co-clustering ensembles is presented. Similar
Spatial Statistics Chapter 3 Basics of areal data and areal data modeling
 Spatial Statistics Chapter 3 Basics of areal data and areal data modeling Recall areal data also known as lattice data are data Y (s), s D where D is a discrete index set. This usually corresponds to data
Spatial Statistics Chapter 3 Basics of areal data and areal data modeling Recall areal data also known as lattice data are data Y (s), s D where D is a discrete index set. This usually corresponds to data
Probabilistic Models for Big Data. Alex Davies and Roger Frigola University of Cambridge 13th February 2014
 Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
Probabilistic Models for Big Data Alex Davies and Roger Frigola University of Cambridge 13th February 2014 The State of Big Data Why probabilistic models for Big Data? 1. If you don t have to worry about
An HDP-HMM for Systems with State Persistence
 Emily B. Fox ebfox@mit.edu Department of EECS, Massachusetts Institute of Technology, Cambridge, MA 9 Erik B. Sudderth sudderth@eecs.berkeley.edu Department of EECS, University of California, Berkeley,
Emily B. Fox ebfox@mit.edu Department of EECS, Massachusetts Institute of Technology, Cambridge, MA 9 Erik B. Sudderth sudderth@eecs.berkeley.edu Department of EECS, University of California, Berkeley,
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Gaussian Mixture Models Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Gaussian Mixture Models Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Preferences in college applications a nonparametric Bayesian analysis of top-10 rankings
 Preferences in college applications a nonparametric Bayesian analysis of top-0 rankings Alnur Ali Microsoft Redmond, WA alnurali@microsoft.com Marina Meilă Dept of Statistics, University of Washington
Preferences in college applications a nonparametric Bayesian analysis of top-0 rankings Alnur Ali Microsoft Redmond, WA alnurali@microsoft.com Marina Meilă Dept of Statistics, University of Washington
Data Mining: An Overview. David Madigan http://www.stat.columbia.edu/~madigan
 Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
Machine Learning for Data Science (CS4786) Lecture 1
 Lecture 1") Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Machine Learning for Data Science (CS4786) Lecture 1 Tu-Th 10:10 to 11:25 AM Hollister B14 Instructors : Lillian Lee and Karthik Sridharan ROUGH DETAILS ABOUT THE COURSE Diagnostic assignment 0 is out:
Optimising and Adapting the Metropolis Algorithm
 Optimising and Adapting the Metropolis Algorithm by Jeffrey S. Rosenthal 1 (February 2013; revised March 2013 and May 2013 and June 2013) 1 Introduction Many modern scientific questions involve high dimensional
Optimising and Adapting the Metropolis Algorithm by Jeffrey S. Rosenthal 1 (February 2013; revised March 2013 and May 2013 and June 2013) 1 Introduction Many modern scientific questions involve high dimensional
More details on the inputs, functionality, and output can be found below.
 Overview: The SMEEACT (Software for More Efficient, Ethical, and Affordable Clinical Trials) web interface (http://research.mdacc.tmc.edu/smeeactweb) implements a single analysis of a two-armed trial comparing
Overview: The SMEEACT (Software for More Efficient, Ethical, and Affordable Clinical Trials) web interface (http://research.mdacc.tmc.edu/smeeactweb) implements a single analysis of a two-armed trial comparing
Multivariate Normal Distribution
 Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
Multivariate Normal Distribution Lecture 4 July 21, 2011 Advanced Multivariate Statistical Methods ICPSR Summer Session #2 Lecture #4-7/21/2011 Slide 1 of 41 Last Time Matrices and vectors Eigenvalues
PS 271B: Quantitative Methods II. Lecture Notes
 PS 271B: Quantitative Methods II Lecture Notes Langche Zeng zeng@ucsd.edu The Empirical Research Process; Fundamental Methodological Issues 2 Theory; Data; Models/model selection; Estimation; Inference.
PS 271B: Quantitative Methods II Lecture Notes Langche Zeng zeng@ucsd.edu The Empirical Research Process; Fundamental Methodological Issues 2 Theory; Data; Models/model selection; Estimation; Inference.
Computational Statistics for Big Data
 Lancaster University Computational Statistics for Big Data Author: 1 Supervisors: Paul Fearnhead 1 Emily Fox 2 1 Lancaster University 2 The University of Washington September 1, 2015 Abstract The amount
Lancaster University Computational Statistics for Big Data Author: 1 Supervisors: Paul Fearnhead 1 Emily Fox 2 1 Lancaster University 2 The University of Washington September 1, 2015 Abstract The amount
Combining Visual and Auditory Data Exploration for finding structure in high-dimensional data
 Combining Visual and Auditory Data Exploration for finding structure in high-dimensional data Thomas Hermann Mark H. Hansen Helge Ritter Faculty of Technology Bell Laboratories Faculty of Technology Bielefeld
Combining Visual and Auditory Data Exploration for finding structure in high-dimensional data Thomas Hermann Mark H. Hansen Helge Ritter Faculty of Technology Bell Laboratories Faculty of Technology Bielefeld
Bayesian Image Super-Resolution
 Bayesian Image Super-Resolution Michael E. Tipping and Christopher M. Bishop Microsoft Research, Cambridge, U.K..................................................................... Published as: Bayesian
Bayesian Image Super-Resolution Michael E. Tipping and Christopher M. Bishop Microsoft Research, Cambridge, U.K..................................................................... Published as: Bayesian
Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization. Learning Goals. GENOME 560, Spring 2012
 Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization GENOME 560, Spring 2012 Data are interesting because they help us understand the world Genomics: Massive Amounts
Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization GENOME 560, Spring 2012 Data are interesting because they help us understand the world Genomics: Massive Amounts
Bayesian Clustering for Email Campaign Detection
 Peter Haider haider@cs.uni-potsdam.de Tobias Scheffer scheffer@cs.uni-potsdam.de University of Potsdam, Department of Computer Science, August-Bebel-Strasse 89, 14482 Potsdam, Germany Abstract We discuss
Peter Haider haider@cs.uni-potsdam.de Tobias Scheffer scheffer@cs.uni-potsdam.de University of Potsdam, Department of Computer Science, August-Bebel-Strasse 89, 14482 Potsdam, Germany Abstract We discuss
Infinite Hidden Conditional Random Fields for Human Behavior Analysis
 170 IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 24, NO. 1, JANUARY 2013 Infinite Hidden Conditional Random Fields for Human Behavior Analysis Konstantinos Bousmalis, Student Member,
170 IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 24, NO. 1, JANUARY 2013 Infinite Hidden Conditional Random Fields for Human Behavior Analysis Konstantinos Bousmalis, Student Member,
Supervised Learning (Big Data Analytics)
") Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Supervised Learning (Big Data Analytics) Vibhav Gogate Department of Computer Science The University of Texas at Dallas Practical advice Goal of Big Data Analytics Uncover patterns in Data. Can be used
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Estimation and comparison of multiple change-point models
 Journal of Econometrics 86 (1998) 221 241 Estimation and comparison of multiple change-point models Siddhartha Chib* John M. Olin School of Business, Washington University, 1 Brookings Drive, Campus Box
Journal of Econometrics 86 (1998) 221 241 Estimation and comparison of multiple change-point models Siddhartha Chib* John M. Olin School of Business, Washington University, 1 Brookings Drive, Campus Box
AClass: An online algorithm for generative classification
 AClass: An online algorithm for generative classification Vikash K. Mansinghka MIT BCS and CSAIL vkm@mit.edu Daniel M. Roy MIT CSAIL droy@mit.edu Ryan Rifkin Honda Research USA rrifkin@honda-ri.com Josh
AClass: An online algorithm for generative classification Vikash K. Mansinghka MIT BCS and CSAIL vkm@mit.edu Daniel M. Roy MIT CSAIL droy@mit.edu Ryan Rifkin Honda Research USA rrifkin@honda-ri.com Josh
Pricing and calibration in local volatility models via fast quantization
 Pricing and calibration in local volatility models via fast quantization Parma, 29 th January 2015. Joint work with Giorgia Callegaro and Martino Grasselli Quantization: a brief history Birth: back to
Pricing and calibration in local volatility models via fast quantization Parma, 29 th January 2015. Joint work with Giorgia Callegaro and Martino Grasselli Quantization: a brief history Birth: back to
The HB. How Bayesian methods have changed the face of marketing research. Summer 2004
 The HB How Bayesian methods have changed the face of marketing research. 20 Summer 2004 Reprinted with permission from Marketing Research, Summer 2004, published by the American Marketing Association.
The HB How Bayesian methods have changed the face of marketing research. 20 Summer 2004 Reprinted with permission from Marketing Research, Summer 2004, published by the American Marketing Association.
Modeling Transfer Learning in Human Categorization with the Hierarchical Dirichlet Process
 Modeling Transfer Learning in Human Categorization with the Hierarchical Dirichlet Process Kevin R. Canini kevin@cs.berkeley.edu Computer Science Division, University of California, Berkeley, CA 94720
Modeling Transfer Learning in Human Categorization with the Hierarchical Dirichlet Process Kevin R. Canini kevin@cs.berkeley.edu Computer Science Division, University of California, Berkeley, CA 94720
STAT3016 Introduction to Bayesian Data Analysis
 STAT3016 Introduction to Bayesian Data Analysis Course Description The Bayesian approach to statistics assigns probability distributions to both the data and unknown parameters in the problem. This way,
STAT3016 Introduction to Bayesian Data Analysis Course Description The Bayesian approach to statistics assigns probability distributions to both the data and unknown parameters in the problem. This way,
Gibbs Sampling and Online Learning Introduction
 Statistical Techniques in Robotics (16-831, F14) Lecture#10(Tuesday, September 30) Gibbs Sampling and Online Learning Introduction Lecturer: Drew Bagnell Scribes: {Shichao Yang} 1 1 Sampling Samples are
Statistical Techniques in Robotics (16-831, F14) Lecture#10(Tuesday, September 30) Gibbs Sampling and Online Learning Introduction Lecturer: Drew Bagnell Scribes: {Shichao Yang} 1 1 Sampling Samples are
SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING
 AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
AAS 07-228 SPECIAL PERTURBATIONS UNCORRELATED TRACK PROCESSING INTRODUCTION James G. Miller * Two historical uncorrelated track (UCT) processing approaches have been employed using general perturbations
Bayesian networks - Time-series models - Apache Spark & Scala
 Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
Bayesian networks - Time-series models - Apache Spark & Scala Dr John Sandiford, CTO Bayes Server Data Science London Meetup - November 2014 1 Contents Introduction Bayesian networks Latent variables Anomaly
Statistical machine learning, high dimension and big data
 Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
Statistical machine learning, high dimension and big data S. Gaïffas 1 14 mars 2014 1 CMAP - Ecole Polytechnique Agenda for today Divide and Conquer principle for collaborative filtering Graphical modelling,
Learning outcomes. Knowledge and understanding. Competence and skills
 Syllabus Master s Programme in Statistics and Data Mining 120 ECTS Credits Aim The rapid growth of databases provides scientists and business people with vast new resources. This programme meets the challenges
Syllabus Master s Programme in Statistics and Data Mining 120 ECTS Credits Aim The rapid growth of databases provides scientists and business people with vast new resources. This programme meets the challenges
Reinforcement Learning with Factored States and Actions
 Journal of Machine Learning Research 5 (2004) 1063 1088 Submitted 3/02; Revised 1/04; Published 8/04 Reinforcement Learning with Factored States and Actions Brian Sallans Austrian Research Institute for
Journal of Machine Learning Research 5 (2004) 1063 1088 Submitted 3/02; Revised 1/04; Published 8/04 Reinforcement Learning with Factored States and Actions Brian Sallans Austrian Research Institute for
Bayesian Inference on a Cox Process Associated with a Dirichlet Process
 International Journal of Computer Applications 97 8887 Volume 9 - No. 8, June ayesian Inference on a Cox Process Associated with a Dirichlet Process Larissa Valmy LAMIA EA Université des Antilles-Guyane
International Journal of Computer Applications 97 8887 Volume 9 - No. 8, June ayesian Inference on a Cox Process Associated with a Dirichlet Process Larissa Valmy LAMIA EA Université des Antilles-Guyane
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics
 Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Tensor Methods for Machine Learning, Computer Vision, and Computer Graphics Part I: Factorizations and Statistical Modeling/Inference Amnon Shashua School of Computer Science & Eng. The Hebrew University
Parallelization Strategies for Multicore Data Analysis
 Parallelization Strategies for Multicore Data Analysis Wei-Chen Chen 1 Russell Zaretzki 2 1 University of Tennessee, Dept of EEB 2 University of Tennessee, Dept. Statistics, Operations, and Management
Parallelization Strategies for Multicore Data Analysis Wei-Chen Chen 1 Russell Zaretzki 2 1 University of Tennessee, Dept of EEB 2 University of Tennessee, Dept. Statistics, Operations, and Management
Structured Learning and Prediction in Computer Vision. Contents
 Foundations and Trends R in Computer Graphics and Vision Vol. 6, Nos. 3 4 (2010) 185 365 c 2011 S. Nowozin and C. H. Lampert DOI: 10.1561/0600000033 Structured Learning and Prediction in Computer Vision
Foundations and Trends R in Computer Graphics and Vision Vol. 6, Nos. 3 4 (2010) 185 365 c 2011 S. Nowozin and C. H. Lampert DOI: 10.1561/0600000033 Structured Learning and Prediction in Computer Vision
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay
 Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Information Theory and Coding Prof. S. N. Merchant Department of Electrical Engineering Indian Institute of Technology, Bombay Lecture - 17 Shannon-Fano-Elias Coding and Introduction to Arithmetic Coding
Probabilistic Modelling, Machine Learning, and the Information Revolution
 Probabilistic Modelling, Machine Learning, and the Information Revolution Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Probabilistic Modelling, Machine Learning, and the Information Revolution Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Master s Theory Exam Spring 2006
 Spring 2006 This exam contains 7 questions. You should attempt them all. Each question is divided into parts to help lead you through the material. You should attempt to complete as much of each problem
Spring 2006 This exam contains 7 questions. You should attempt them all. Each question is divided into parts to help lead you through the material. You should attempt to complete as much of each problem
Reliability estimators for the components of series and parallel systems: The Weibull model
 Reliability estimators for the components of series and parallel systems: The Weibull model Felipe L. Bhering 1, Carlos Alberto de Bragança Pereira 1, Adriano Polpo 2 1 Department of Statistics, University
Reliability estimators for the components of series and parallel systems: The Weibull model Felipe L. Bhering 1, Carlos Alberto de Bragança Pereira 1, Adriano Polpo 2 1 Department of Statistics, University
Logistic Regression (1/24/13)
") STA63/CBB540: Statistical methods in computational biology Logistic Regression (/24/3) Lecturer: Barbara Engelhardt Scribe: Dinesh Manandhar Introduction Logistic regression is model for regression used
STA63/CBB540: Statistical methods in computational biology Logistic Regression (/24/3) Lecturer: Barbara Engelhardt Scribe: Dinesh Manandhar Introduction Logistic regression is model for regression used
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
10-601. Machine Learning. http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
 10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
10-601 Machine Learning http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html Course data All up-to-date info is on the course web page: http://www.cs.cmu.edu/afs/cs/academic/class/10601-f10/index.html
Robert Collins CSE598G. More on Mean-shift. R.Collins, CSE, PSU CSE598G Spring 2006
 More on Mean-shift R.Collins, CSE, PSU Spring 2006 Recall: Kernel Density Estimation Given a set of data samples x i ; i=1...n Convolve with a kernel function H to generate a smooth function f(x) Equivalent
More on Mean-shift R.Collins, CSE, PSU Spring 2006 Recall: Kernel Density Estimation Given a set of data samples x i ; i=1...n Convolve with a kernel function H to generate a smooth function f(x) Equivalent
Latent Dirichlet Markov Allocation for Sentiment Analysis
 Latent Dirichlet Markov Allocation for Sentiment Analysis Ayoub Bagheri Isfahan University of Technology, Isfahan, Iran Intelligent Database, Data Mining and Bioinformatics Lab, Electrical and Computer
Latent Dirichlet Markov Allocation for Sentiment Analysis Ayoub Bagheri Isfahan University of Technology, Isfahan, Iran Intelligent Database, Data Mining and Bioinformatics Lab, Electrical and Computer
Black Box Variational Inference
 Rajesh Ranganath Sean Gerrish David M. Blei Princeton University, 35 Olden St., Princeton, NJ 08540 frajeshr,sgerrish,bleig@cs.princeton.edu Abstract Variational inference has become a widely used method
Rajesh Ranganath Sean Gerrish David M. Blei Princeton University, 35 Olden St., Princeton, NJ 08540 frajeshr,sgerrish,bleig@cs.princeton.edu Abstract Variational inference has become a widely used method
Learning with Local and Global Consistency
 Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency
 Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Learning with Local and Global Consistency Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf Max Planck Institute for Biological Cybernetics, 7276 Tuebingen, Germany
Bayesian Predictive Profiles with Applications to Retail Transaction Data
 Bayesian Predictive Profiles with Applications to Retail Transaction Data Igor V. Cadez Information and Computer Science University of California Irvine, CA 92697-3425, U.S.A. icadez@ics.uci.edu Padhraic
Bayesian Predictive Profiles with Applications to Retail Transaction Data Igor V. Cadez Information and Computer Science University of California Irvine, CA 92697-3425, U.S.A. icadez@ics.uci.edu Padhraic
Principles of Data Mining by Hand&Mannila&Smyth
 Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Principles of Data Mining by Hand&Mannila&Smyth Slides for Textbook Ari Visa,, Institute of Signal Processing Tampere University of Technology October 4, 2010 Data Mining: Concepts and Techniques 1 Differences
Big Data, Statistics, and the Internet
 Big Data, Statistics, and the Internet Steven L. Scott April, 4 Steve Scott (Google) Big Data, Statistics, and the Internet April, 4 / 39 Summary Big data live on more than one machine. Computing takes
Big Data, Statistics, and the Internet Steven L. Scott April, 4 Steve Scott (Google) Big Data, Statistics, and the Internet April, 4 / 39 Summary Big data live on more than one machine. Computing takes
OPRE 6201 : 2. Simplex Method
 OPRE 6201 : 2. Simplex Method 1 The Graphical Method: An Example Consider the following linear program: Max 4x 1 +3x 2 Subject to: 2x 1 +3x 2 6 (1) 3x 1 +2x 2 3 (2) 2x 2 5 (3) 2x 1 +x 2 4 (4) x 1, x 2
OPRE 6201 : 2. Simplex Method 1 The Graphical Method: An Example Consider the following linear program: Max 4x 1 +3x 2 Subject to: 2x 1 +3x 2 6 (1) 3x 1 +2x 2 3 (2) 2x 2 5 (3) 2x 1 +x 2 4 (4) x 1, x 2
Faculty of Science School of Mathematics and Statistics
 Faculty of Science School of Mathematics and Statistics MATH5836 Data Mining and its Business Applications Semester 1, 2014 CRICOS Provider No: 00098G MATH5836 Course Outline Information about the course
Faculty of Science School of Mathematics and Statistics MATH5836 Data Mining and its Business Applications Semester 1, 2014 CRICOS Provider No: 00098G MATH5836 Course Outline Information about the course
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set
 EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
arxiv:1402.4293v1 [stat.ml] 18 Feb 2014
![arxiv:1402.4293v1 [stat.ml] 18 Feb 2014](/thumbs/29/13735295.jpg "arxiv:1402.4293v1 [stat.ml] 18 Feb 2014") The Random Forest Kernel and creating other kernels for big data from random partitions arxiv:1402.4293v1 [stat.ml] 18 Feb 2014 Alex Davies Dept of Engineering, University of Cambridge Cambridge, UK Zoubin
The Random Forest Kernel and creating other kernels for big data from random partitions arxiv:1402.4293v1 [stat.ml] 18 Feb 2014 Alex Davies Dept of Engineering, University of Cambridge Cambridge, UK Zoubin
Course: Model, Learning, and Inference: Lecture 5
 Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
Course: Model, Learning, and Inference: Lecture 5 Alan Yuille Department of Statistics, UCLA Los Angeles, CA 90095 yuille@stat.ucla.edu Abstract Probability distributions on structured representation.
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 4: LINEAR MODELS FOR CLASSIFICATION Introduction In the previous chapter, we explored a class of regression models having particularly simple analytical
Handling attrition and non-response in longitudinal data
 Longitudinal and Life Course Studies 2009 Volume 1 Issue 1 Pp 63-72 Handling attrition and non-response in longitudinal data Harvey Goldstein University of Bristol Correspondence. Professor H. Goldstein
Longitudinal and Life Course Studies 2009 Volume 1 Issue 1 Pp 63-72 Handling attrition and non-response in longitudinal data Harvey Goldstein University of Bristol Correspondence. Professor H. Goldstein
Approximating the Partition Function by Deleting and then Correcting for Model Edges
 Approximating the Partition Function by Deleting and then Correcting for Model Edges Arthur Choi and Adnan Darwiche Computer Science Department University of California, Los Angeles Los Angeles, CA 995
Approximating the Partition Function by Deleting and then Correcting for Model Edges Arthur Choi and Adnan Darwiche Computer Science Department University of California, Los Angeles Los Angeles, CA 995
Neural Networks: a replacement for Gaussian Processes?
 Neural Networks: a replacement for Gaussian Processes? Matthew Lilley and Marcus Frean Victoria University of Wellington, P.O. Box 600, Wellington, New Zealand marcus@mcs.vuw.ac.nz http://www.mcs.vuw.ac.nz/
Neural Networks: a replacement for Gaussian Processes? Matthew Lilley and Marcus Frean Victoria University of Wellington, P.O. Box 600, Wellington, New Zealand marcus@mcs.vuw.ac.nz http://www.mcs.vuw.ac.nz/
A Learning Based Method for Super-Resolution of Low Resolution Images
 A Learning Based Method for Super-Resolution of Low Resolution Images Emre Ugur June 1, 2004 emre.ugur@ceng.metu.edu.tr Abstract The main objective of this project is the study of a learning based method
A Learning Based Method for Super-Resolution of Low Resolution Images Emre Ugur June 1, 2004 emre.ugur@ceng.metu.edu.tr Abstract The main objective of this project is the study of a learning based method
Self Organizing Maps: Fundamentals
 Self Organizing Maps: Fundamentals Introduction to Neural Networks : Lecture 16 John A. Bullinaria, 2004 1. What is a Self Organizing Map? 2. Topographic Maps 3. Setting up a Self Organizing Map 4. Kohonen
Self Organizing Maps: Fundamentals Introduction to Neural Networks : Lecture 16 John A. Bullinaria, 2004 1. What is a Self Organizing Map? 2. Topographic Maps 3. Setting up a Self Organizing Map 4. Kohonen