COSCO 2015 Heterogeneous Computing Programming
|
|
|
- Myra Carter
- 8 years ago
- Views:
Transcription
1 COSCO 2015 Heterogeneous Computing Programming Michael Meyer, Shunsuke Ishikuro Supporters: Kazuaki Sasamoto, Ryunosuke Murakami July 24th, 2015

2 Heterogeneous Computing Programming 1. Overview 2. Methodology 3. Example and Evaluation 4. Conclusion

3 Heterogeneous Computing Programming 1. Overview 2. Methodology 3. Example and Evaluation 4. Conclusion

4 Heterogeneous Architecture- What is it diverse in character or content. Different Types in one package Types of? Different Types of Cores Different Types of Processing(GPU and CPU) Different Functions(CPU and Memory) Different Communication Mediums(Optical and Electric and RF or sensors)
 Different Communication")
5 Heterogeneous Architecture- Different Types of Cores CELL Uses SPEs for Floating-Point calculations Power Processing Element is used for all other major functions

6 Heterogeneous Architecture- Different Types of Processing(GPU and CPU)

7 Heterogeneous Architecture- Different Functions(CPU and Memory)

8 Heterogeneous Architecture- Communication Mediums(Optical and Electric and RF or sensors)

9 Heterogeneous Computing Programming 1. Overview 2. Methodology 3. Example and Evaluation 4. Conclusion

10 2. Methodology Parallel Computing Hardware Software OpenCL s Approach Basic idea Programming Model Development Environment

11 Parallel Computing

12 Why Parallel? Serial A problem can be divided to small tasks Parallel

13 Hardware: Flynn s Taxonomy

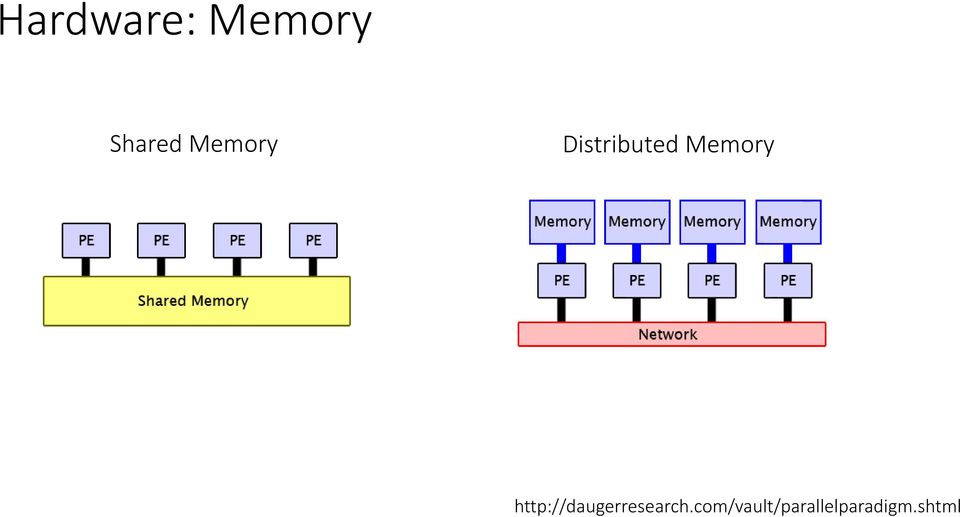
14 Hardware: Memory Shared Memory Distributed Memory
15 Hardware: Accelerator Host GPU DSP FPGA

16 Software Sequential Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Multi Core Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Sum Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum

17 Software: 1. Analysis Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum Task A Task B Task C Task D Sum

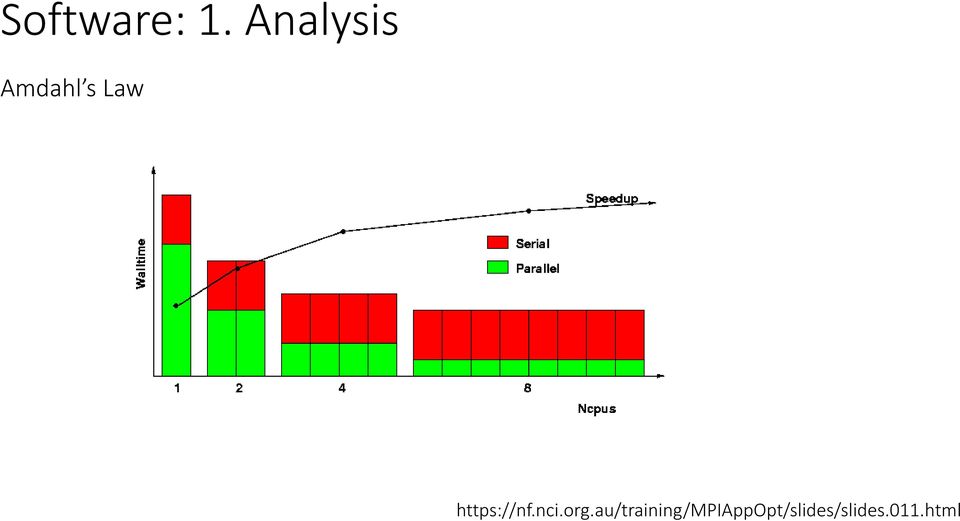
18 Software: 1. Analysis Amdahl s Law
19 Software: 2. Algorithm Data Parallelism Task Parallelism Task A Task B Task C Task D Task A Task A Task A Task A Task A Task B Task C Task D Task B Task B Task B Task B Task A Task B Task C Task D Sum Task C Task C Task C Task C Task A Task B Task C Task D Task D Task D Task D Task D

20 Software: 3. Programming OS API pthread Framework OpenMP, CUDA, OpenCL

21 OpenCL s Approach
22 Basic Idea
23 Basic Idea OpenCL Device Host OpenCL Device OpenCL Device
24 Basic Idea OpenCL Device Host OpenCL Device OpenCL Device Common API Portable Optimization
25 OpenCL C, OpenCL runtime OpenCL C Language C/C++ OpenCL Runtime Library Host OpenCL Device OpenCL C Language OpenCL Device OpenCL C Language OpenCL Device
26 OpenCL Device OpenCL Device Compute Unit Processing Element Host
27 Programming Model OpenCL Device Command Queue Work Group #0 #1 #2 Work item #0 #1 #2 #3 #4
28 Memory Model OpenCL Device Global Memory Compute Unit Processing Element Local Memory Constant Memory Private Private Private Private Private
29 Comparison OpenMP vs OpenCL OpenMP: Multiprocessors OpenCL: Multiprocessors and Accelerators CUDA vs OpenCL CUDA: only for NVIDIA GPU OpenCL: Supporting AMD, Intel and NVIDIA GPU
30 Comparison HSA vs OpenCL HSA: Framework for hardware vendors OpenCL: Better development environment and materials
31 Development Environment Intel Intel Multicore Processor + Intel OpenCL SDK NVIDIA NVIDIA GPU + CUDA Apple Intel Mac + Xcode Altera Altera PCIe FPGA + Altera SDK For OpenCL
32 Heterogeneous Computing Programming 1. Overview 2. Methodology 3. Example and Evaluation 4. Conclusion
33 Hello World See the program list handout hello.cl: Kernel code which works on OpenCL Device hello.cpp: Host program which works on a host machine
34 hello.cl Run on OpenCL Device #pragma OPENCL EXTENSION cl_khr_byte_addressable_store : enable kernel void hello( global char* string) { string[0] = 'H'; string[1] = 'e'; string[2] = 'l'; string[3] = 'l'; string[4] = 'o'; string[5] = ','; string[6] = ' '; string[7] = 'W'; string[8] = 'o'; string[9] = 'r'; string[10] = 'l'; string[11] = 'd'; string[12] = '!'; string[13] = ' 0'; }
35 hello.cpp FILE *fp; char filename[] = "./hello.cl"; char *source_str; size_t source_size; /* カーネルを 含 むソースコードをロード / Load kernel code */ fp = fopen(filename, "r");
36 hello.cpp /* プラットフォーム デバイスの 情 報 の 取 得 / Get device information */ ret = clgetplatformids(1, &platform_id, &ret_num_platforms); ret = clgetdeviceids( platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, &ret_num_devices); /* OpenCLコンテキストの 作 成 / Create OpenCL Context */ context = clcreatecontext( NULL, 1, &device_id, NULL, NULL, &ret); There is no platform dependency
37 hello.cpp /* OpenCLカーネルを 実 行 / Execute an OpenCL Kernel */ ret = clenqueuetask(command_queue, kernel, 0, NULL,NULL); /* メモリバッファから 結 果 を 取 得 / Get result data from memory buffer */ ret = clenqueuereadbuffer(command_queue, memobj, CL_TRUE, 0, MEM_SIZE * sizeof(char),string, 0, NULL, NULL); /* 結 果 の 表 示 / Display the result */ puts(string);
38 Hello World: Build and Run Build (NVIDIA) $ g++ I/usr/local/cuda/include o hello hello.cpp lopencl Run $./hello Hello World!
39 Image Processing Edge Filter

40 FFT: Fourier Transformation W = exp( 2πi n )
41 FFT: Inverse Fourier Transformation Inverse Trans
42 start Generate Twiddle Factors FFT Core FFT Core start Transpose Matrix FFT Core Filter Loop count < log 2 N Butterfly Calc FFT Core (Inverse) Transpose Matrix FFT Core (Inverse) Normalize if (Inverse) end end
43 FFT: Source Code See the program list handout fft.cl: Kernel code which works on OpenCL Device fft.cpp: Host program which works on a host machine
44 FFT: Evaluation Tesla C2050(NVIDIA) Number of workitems and execution time(ms) num of workitems membuf_write spinfactor bitreverse butterfly normalize highpassfilter membuf read
45 Conclusion Heterogeneous computing is one of parallel computing methods. Parallel computing needs knowledge of Hardware and software characteristics. OpenCL framework helps heterogeneous computing with portable API.
46 References 株 式 会 社 フィックスターズ, 改 訂 新 版 OpenCL 入 門, インプレスジャパン, Khronos OpenCL Working Group, OpenCL 詳 説, カットシステム, Blaise Barney, Lawrence Livermore National Laboratory, Introduction to Parallel Computing, Wikipedia, Flynn's taxonomy, Dauger Research, Parallel Programming Paradigms, NCI NATIONAL FACILITY, MPI Applications Course Overview,
Introducing PgOpenCL A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child
 Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introducing A New PostgreSQL Procedural Language Unlocking the Power of the GPU! By Tim Child Bio Tim Child 35 years experience of software development Formerly VP Oracle Corporation VP BEA Systems Inc.
Introduction to OpenCL Programming. Training Guide
 Introduction to OpenCL Programming Training Guide Publication #: 137-41768-10 Rev: A Issue Date: May, 2010 Introduction to OpenCL Programming PID: 137-41768-10 Rev: A May, 2010 2010 Advanced Micro Devices
Introduction to OpenCL Programming Training Guide Publication #: 137-41768-10 Rev: A Issue Date: May, 2010 Introduction to OpenCL Programming PID: 137-41768-10 Rev: A May, 2010 2010 Advanced Micro Devices
HIGH PERFORMANCE CONSULTING COURSE OFFERINGS
 Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
Performance 1(6) HIGH PERFORMANCE CONSULTING COURSE OFFERINGS LEARN TO TAKE ADVANTAGE OF POWERFUL GPU BASED ACCELERATOR TECHNOLOGY TODAY 2006 2013 Nvidia GPUs Intel CPUs CONTENTS Acronyms and Terminology...
OpenCL for programming shared memory multicore CPUs
 Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
Akhtar Ali, Usman Dastgeer and Christoph Kessler. OpenCL on shared memory multicore CPUs. Proc. MULTIPROG-212 Workshop at HiPEAC-212, Paris, Jan. 212. OpenCL for programming shared memory multicore CPUs
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 37 Course outline Introduction to GPU hardware
Accelerating sequential computer vision algorithms using OpenMP and OpenCL on commodity parallel hardware
 Accelerating sequential computer vision algorithms using OpenMP and OpenCL on commodity parallel hardware 25 August 2014 Copyright 2001 2014 by NHL Hogeschool and Van de Loosdrecht Machine Vision BV All
Accelerating sequential computer vision algorithms using OpenMP and OpenCL on commodity parallel hardware 25 August 2014 Copyright 2001 2014 by NHL Hogeschool and Van de Loosdrecht Machine Vision BV All
Experiences on using GPU accelerators for data analysis in ROOT/RooFit
 Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Experiences on using GPU accelerators for data analysis in ROOT/RooFit Sverre Jarp, Alfio Lazzaro, Julien Leduc, Yngve Sneen Lindal, Andrzej Nowak European Organization for Nuclear Research (CERN), Geneva,
Introduction to GPU Programming Languages
 CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
CSC 391/691: GPU Programming Fall 2011 Introduction to GPU Programming Languages Copyright 2011 Samuel S. Cho http://www.umiacs.umd.edu/ research/gpu/facilities.html Maryland CPU/GPU Cluster Infrastructure
Embedded Systems: map to FPGA, GPU, CPU?
 Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
Embedded Systems: map to FPGA, GPU, CPU? Jos van Eijndhoven jos@vectorfabrics.com Bits&Chips Embedded systems Nov 7, 2013 # of transistors Moore s law versus Amdahl s law Computational Capacity Hardware
GPU System Architecture. Alan Gray EPCC The University of Edinburgh
 GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
GPU System Architecture EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? GPU-CPU comparison Architectural reasons for GPU performance advantages GPU accelerated systems
Mitglied der Helmholtz-Gemeinschaft. OpenCL Basics. Parallel Computing on GPU and CPU. Willi Homberg. 23. März 2011
 Mitglied der Helmholtz-Gemeinschaft OpenCL Basics Parallel Computing on GPU and CPU Willi Homberg Agenda Introduction OpenCL architecture Platform model Execution model Memory model Programming model Platform
Mitglied der Helmholtz-Gemeinschaft OpenCL Basics Parallel Computing on GPU and CPU Willi Homberg Agenda Introduction OpenCL architecture Platform model Execution model Memory model Programming model Platform
Programming models for heterogeneous computing. Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga
 Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Programming models for heterogeneous computing Manuel Ujaldón Nvidia CUDA Fellow and A/Prof. Computer Architecture Department University of Malaga Talk outline [30 slides] 1. Introduction [5 slides] 2.
Multi-core Programming System Overview
 Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming System Overview Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-Threading Performance on Commodity Multi-Core Processors
 Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
Multi-Threading Performance on Commodity Multi-Core Processors Jie Chen and William Watson III Scientific Computing Group Jefferson Lab 12000 Jefferson Ave. Newport News, VA 23606 Organization Introduction
HPC Wales Skills Academy Course Catalogue 2015
 HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
HPC Wales Skills Academy Course Catalogue 2015 Overview The HPC Wales Skills Academy provides a variety of courses and workshops aimed at building skills in High Performance Computing (HPC). Our courses
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it
 Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
Overview on Modern Accelerators and Programming Paradigms Ivan Giro7o igiro7o@ictp.it Informa(on & Communica(on Technology Sec(on (ICTS) Interna(onal Centre for Theore(cal Physics (ICTP) Mul(ple Socket
OpenCL Optimization. San Jose 10/2/2009 Peng Wang, NVIDIA
 OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
OpenCL Optimization San Jose 10/2/2009 Peng Wang, NVIDIA Outline Overview The CUDA architecture Memory optimization Execution configuration optimization Instruction optimization Summary Overall Optimization
Case Study on Productivity and Performance of GPGPUs
 Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Case Study on Productivity and Performance of GPGPUs Sandra Wienke wienke@rz.rwth-aachen.de ZKI Arbeitskreis Supercomputing April 2012 Rechen- und Kommunikationszentrum (RZ) RWTH GPU-Cluster 56 Nvidia
Intro to GPU computing. Spring 2015 Mark Silberstein, 048661, Technion 1
 Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Intro to GPU computing Spring 2015 Mark Silberstein, 048661, Technion 1 Serial vs. parallel program One instruction at a time Multiple instructions in parallel Spring 2015 Mark Silberstein, 048661, Technion
Course materials. In addition to these slides, C++ API header files, a set of exercises, and solutions, the following are useful:
 Course materials In addition to these slides, C++ API header files, a set of exercises, and solutions, the following are useful: OpenCL C 1.2 Reference Card OpenCL C++ 1.2 Reference Card These cards will
Course materials In addition to these slides, C++ API header files, a set of exercises, and solutions, the following are useful: OpenCL C 1.2 Reference Card OpenCL C++ 1.2 Reference Card These cards will
Program Grid and HPC5+ workshop
 Program Grid and HPC5+ workshop 24-30, Bahman 1391 Tuesday Wednesday 9.00-9.45 9.45-10.30 Break 11.00-11.45 11.45-12.30 Lunch 14.00-17.00 Workshop Rouhani Karimi MosalmanTabar Karimi G+MMT+K Opening IPM_Grid
Program Grid and HPC5+ workshop 24-30, Bahman 1391 Tuesday Wednesday 9.00-9.45 9.45-10.30 Break 11.00-11.45 11.45-12.30 Lunch 14.00-17.00 Workshop Rouhani Karimi MosalmanTabar Karimi G+MMT+K Opening IPM_Grid
Part I Courses Syllabus
 Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Part I Courses Syllabus This document provides detailed information about the basic courses of the MHPC first part activities. The list of courses is the following 1.1 Scientific Programming Environment
Implementation of Stereo Matching Using High Level Compiler for Parallel Computing Acceleration
 Implementation of Stereo Matching Using High Level Compiler for Parallel Computing Acceleration Jinglin Zhang, Jean François Nezan, Jean-Gabriel Cousin, Erwan Raffin To cite this version: Jinglin Zhang,
Implementation of Stereo Matching Using High Level Compiler for Parallel Computing Acceleration Jinglin Zhang, Jean François Nezan, Jean-Gabriel Cousin, Erwan Raffin To cite this version: Jinglin Zhang,
Introduction GPU Hardware GPU Computing Today GPU Computing Example Outlook Summary. GPU Computing. Numerical Simulation - from Models to Software
 GPU Computing Numerical Simulation - from Models to Software Andreas Barthels JASS 2009, Course 2, St. Petersburg, Russia Prof. Dr. Sergey Y. Slavyanov St. Petersburg State University Prof. Dr. Thomas
GPU Computing Numerical Simulation - from Models to Software Andreas Barthels JASS 2009, Course 2, St. Petersburg, Russia Prof. Dr. Sergey Y. Slavyanov St. Petersburg State University Prof. Dr. Thomas
OpenACC Basics Directive-based GPGPU Programming
 OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
OpenACC Basics Directive-based GPGPU Programming Sandra Wienke, M.Sc. wienke@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Rechen- und Kommunikationszentrum (RZ) PPCES,
Optimization. NVIDIA OpenCL Best Practices Guide. Version 1.0
 Optimization NVIDIA OpenCL Best Practices Guide Version 1.0 August 10, 2009 NVIDIA OpenCL Best Practices Guide REVISIONS Original release: July 2009 ii August 16, 2009 Table of Contents Preface... v What
Optimization NVIDIA OpenCL Best Practices Guide Version 1.0 August 10, 2009 NVIDIA OpenCL Best Practices Guide REVISIONS Original release: July 2009 ii August 16, 2009 Table of Contents Preface... v What
Lecture 3. Optimising OpenCL performance
 Lecture 3 Optimising OpenCL performance Based on material by Benedict Gaster and Lee Howes (AMD), Tim Mattson (Intel) and several others. - Page 1 Agenda Heterogeneous computing and the origins of OpenCL
Lecture 3 Optimising OpenCL performance Based on material by Benedict Gaster and Lee Howes (AMD), Tim Mattson (Intel) and several others. - Page 1 Agenda Heterogeneous computing and the origins of OpenCL
GPU Computing - CUDA
 GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
GPU Computing - CUDA A short overview of hardware and programing model Pierre Kestener 1 1 CEA Saclay, DSM, Maison de la Simulation Saclay, June 12, 2012 Atelier AO and GPU 1 / 37 Content Historical perspective
GPU Architectures. A CPU Perspective. Data Parallelism: What is it, and how to exploit it? Workload characteristics
 GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Architectures A CPU Perspective Derek Hower AMD Research 5/21/2013 Goals Data Parallelism: What is it, and how to exploit it? Workload characteristics Execution Models / GPU Architectures MIMD (SPMD),
GPU Hardware and Programming Models. Jeremy Appleyard, September 2015
 GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
GPU Hardware and Programming Models Jeremy Appleyard, September 2015 A brief history of GPUs In this talk Hardware Overview Programming Models Ask questions at any point! 2 A Brief History of GPUs 3 Once
Introduction to GPU Computing
 Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Matthis Hauschild Universität Hamburg Fakultät für Mathematik, Informatik und Naturwissenschaften Technische Aspekte Multimodaler Systeme December 4, 2014 M. Hauschild - 1 Table of Contents 1. Architecture
Introduction to Cloud Computing
 Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Introduction to Cloud Computing Parallel Processing I 15 319, spring 2010 7 th Lecture, Feb 2 nd Majd F. Sakr Lecture Motivation Concurrency and why? Different flavors of parallel computing Get the basic
Le langage OCaml et la programmation des GPU
 Le langage OCaml et la programmation des GPU GPU programming with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte Le projet OpenGPU : un an plus tard Ecole Polytechnique - 8 juin 2011 Outline
Le langage OCaml et la programmation des GPU GPU programming with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte Le projet OpenGPU : un an plus tard Ecole Polytechnique - 8 juin 2011 Outline
5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model
 5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model C99, C++, F2003 Compilers Optimizing Vectorizing Parallelizing Graphical parallel tools PGDBG debugger PGPROF profiler Intel, AMD, NVIDIA
5x in 5 hours Porting SEISMIC_CPML using the PGI Accelerator Model C99, C++, F2003 Compilers Optimizing Vectorizing Parallelizing Graphical parallel tools PGDBG debugger PGPROF profiler Intel, AMD, NVIDIA
Course Development of Programming for General-Purpose Multicore Processors
 Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
Course Development of Programming for General-Purpose Multicore Processors Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University Richmond, VA 23284 wzhang4@vcu.edu
OpenCL Programming for the CUDA Architecture. Version 2.3
 OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
OpenCL Programming for the CUDA Architecture Version 2.3 8/31/2009 In general, there are multiple ways of implementing a given algorithm in OpenCL and these multiple implementations can have vastly different
Parallel Computing. Shared memory parallel programming with OpenMP
 Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
Parallel Computing Shared memory parallel programming with OpenMP Thorsten Grahs, 27.04.2015 Table of contents Introduction Directives Scope of data Synchronization 27.04.2015 Thorsten Grahs Parallel Computing
Next Generation GPU Architecture Code-named Fermi
 Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
Next Generation GPU Architecture Code-named Fermi The Soul of a Supercomputer in the Body of a GPU Why is NVIDIA at Super Computing? Graphics is a throughput problem paint every pixel within frame time
College of William & Mary Department of Computer Science
 Technical Report WM-CS-2010-03 College of William & Mary Department of Computer Science WM-CS-2010-03 Implementing the Dslash Operator in OpenCL Andy Kowalski, Xipeng Shen {kowalski,xshen}@cs.wm.edu Department
Technical Report WM-CS-2010-03 College of William & Mary Department of Computer Science WM-CS-2010-03 Implementing the Dslash Operator in OpenCL Andy Kowalski, Xipeng Shen {kowalski,xshen}@cs.wm.edu Department
Performance Analysis for GPU Accelerated Applications
 Center for Information Services and High Performance Computing (ZIH) Performance Analysis for GPU Accelerated Applications Working Together for more Insight Willersbau, Room A218 Tel. +49 351-463 - 39871
Center for Information Services and High Performance Computing (ZIH) Performance Analysis for GPU Accelerated Applications Working Together for more Insight Willersbau, Room A218 Tel. +49 351-463 - 39871
Trends in High-Performance Computing for Power Grid Applications
 Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
Trends in High-Performance Computing for Power Grid Applications Franz Franchetti ECE, Carnegie Mellon University www.spiral.net Co-Founder, SpiralGen www.spiralgen.com This talk presents my personal views
 Cross-Platform GP with Organic Vectory BV Project Services Consultancy Services Expertise Markets 3D Visualization Architecture/Design Computing Embedded Software GIS Finance George van Venrooij Organic
Cross-Platform GP with Organic Vectory BV Project Services Consultancy Services Expertise Markets 3D Visualization Architecture/Design Computing Embedded Software GIS Finance George van Venrooij Organic
10- High Performance Compu5ng
 10- High Performance Compu5ng (Herramientas Computacionales Avanzadas para la Inves6gación Aplicada) Rafael Palacios, Fernando de Cuadra MRE Contents Implemen8ng computa8onal tools 1. High Performance
10- High Performance Compu5ng (Herramientas Computacionales Avanzadas para la Inves6gación Aplicada) Rafael Palacios, Fernando de Cuadra MRE Contents Implemen8ng computa8onal tools 1. High Performance
High Efficiency Video Coding (HEVC) or H.265 is a next generation video coding standard developed by ITU-T (VCEG) and ISO/IEC (MPEG).
 or H.265 is a next generation video coding standard developed by ITU-T (VCEG) and ISO/IEC (MPEG).") HEVC - Introduction High Efficiency Video Coding (HEVC) or H.265 is a next generation video coding standard developed by ITU-T (VCEG) and ISO/IEC (MPEG). HEVC / H.265 reduces bit-rate requirement by 50%
HEVC - Introduction High Efficiency Video Coding (HEVC) or H.265 is a next generation video coding standard developed by ITU-T (VCEG) and ISO/IEC (MPEG). HEVC / H.265 reduces bit-rate requirement by 50%
Parallel Programming Survey
 Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Christian Terboven 02.09.2014 / Aachen, Germany Stand: 26.08.2014 Version 2.3 IT Center der RWTH Aachen University Agenda Overview: Processor Microarchitecture Shared-Memory
Turbomachinery CFD on many-core platforms experiences and strategies
 Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
Turbomachinery CFD on many-core platforms experiences and strategies Graham Pullan Whittle Laboratory, Department of Engineering, University of Cambridge MUSAF Colloquium, CERFACS, Toulouse September 27-29
VOCL: An Optimized Environment for Transparent Virtualization of Graphics Processing Units
 VOCL: An Optimized Environment for Transparent Virtualization of Graphics Processing Units Shucai Xiao Pavan Balaji Qian Zhu 3 Rajeev Thakur Susan Coghlan 4 Heshan Lin Gaojin Wen 5 Jue Hong 5 Wu-chun Feng
VOCL: An Optimized Environment for Transparent Virtualization of Graphics Processing Units Shucai Xiao Pavan Balaji Qian Zhu 3 Rajeev Thakur Susan Coghlan 4 Heshan Lin Gaojin Wen 5 Jue Hong 5 Wu-chun Feng
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X
 NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v5.5 July 2013 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v5.5 July 2013 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
OpenACC 2.0 and the PGI Accelerator Compilers
 OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
OpenACC 2.0 and the PGI Accelerator Compilers Michael Wolfe The Portland Group michael.wolfe@pgroup.com This presentation discusses the additions made to the OpenACC API in Version 2.0. I will also present
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs
 A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
A general-purpose virtualization service for HPC on cloud computing: an application to GPUs R.Montella, G.Coviello, G.Giunta* G. Laccetti #, F. Isaila, J. Garcia Blas *Department of Applied Science University
BLM 413E - Parallel Programming Lecture 3
 BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
BLM 413E - Parallel Programming Lecture 3 FSMVU Bilgisayar Mühendisliği Öğr. Gör. Musa AYDIN 14.10.2015 2015-2016 M.A. 1 Parallel Programming Models Parallel Programming Models Overview There are several
How OpenCL enables easy access to FPGA performance?
 How OpenCL enables easy access to FPGA performance? Suleyman Demirsoy Agenda Introduction OpenCL Overview S/W Flow H/W Architecture Product Information & design flow Applications Additional Collateral
How OpenCL enables easy access to FPGA performance? Suleyman Demirsoy Agenda Introduction OpenCL Overview S/W Flow H/W Architecture Product Information & design flow Applications Additional Collateral
Xeon+FPGA Platform for the Data Center
 Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
Xeon+FPGA Platform for the Data Center ISCA/CARL 2015 PK Gupta, Director of Cloud Platform Technology, DCG/CPG Overview Data Center and Workloads Xeon+FPGA Accelerator Platform Applications and Eco-system
Debugging in Heterogeneous Environments with TotalView. ECMWF HPC Workshop 30 th October 2014
 Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
Debugging in Heterogeneous Environments with TotalView ECMWF HPC Workshop 30 th October 2014 Agenda Introduction Challenges TotalView overview Advanced features Current work and future plans 2014 Rogue
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville CS 594 Lecture Notes March 4, 2015 1/18 Outline! Introduction - Hardware
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs
 Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Optimizing a 3D-FWT code in a cluster of CPUs+GPUs Gregorio Bernabé Javier Cuenca Domingo Giménez Universidad de Murcia Scientific Computing and Parallel Programming Group XXIX Simposium Nacional de la
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi
 Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
Performance Evaluation of NAS Parallel Benchmarks on Intel Xeon Phi ICPP 6 th International Workshop on Parallel Programming Models and Systems Software for High-End Computing October 1, 2013 Lyon, France
E6895 Advanced Big Data Analytics Lecture 14:! NVIDIA GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
E6895 Advanced Big Data Analytics Lecture 14: NVIDIA GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist,
GPUs for Scientific Computing
 GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
GPUs for Scientific Computing p. 1/16 GPUs for Scientific Computing Mike Giles mike.giles@maths.ox.ac.uk Oxford-Man Institute of Quantitative Finance Oxford University Mathematical Institute Oxford e-research
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X
 NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v6.5 August 2014 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
NVIDIA CUDA GETTING STARTED GUIDE FOR MAC OS X DU-05348-001_v6.5 August 2014 Installation and Verification on Mac OS X TABLE OF CONTENTS Chapter 1. Introduction...1 1.1. System Requirements... 1 1.2. About
MAQAO Performance Analysis and Optimization Tool
 MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
MAQAO Performance Analysis and Optimization Tool Andres S. CHARIF-RUBIAL andres.charif@uvsq.fr Performance Evaluation Team, University of Versailles S-Q-Y http://www.maqao.org VI-HPS 18 th Grenoble 18/22
Medical Image Processing on the GPU. Past, Present and Future. Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.
 Medical Image Processing on the GPU Past, Present and Future Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.edu Outline Motivation why do we need GPUs? Past - how was GPU programming
Medical Image Processing on the GPU Past, Present and Future Anders Eklund, PhD Virginia Tech Carilion Research Institute andek@vtc.vt.edu Outline Motivation why do we need GPUs? Past - how was GPU programming
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Qingyu Meng, Alan Humphrey, Martin Berzins Thanks to: John Schmidt and J. Davison de St. Germain, SCI Institute Justin Luitjens
Graphic Processing Units: a possible answer to High Performance Computing?
 4th ABINIT Developer Workshop RESIDENCE L ESCANDILLE AUTRANS HPC & Graphic Processing Units: a possible answer to High Performance Computing? Luigi Genovese ESRF - Grenoble 26 March 2009 http://inac.cea.fr/l_sim/
4th ABINIT Developer Workshop RESIDENCE L ESCANDILLE AUTRANS HPC & Graphic Processing Units: a possible answer to High Performance Computing? Luigi Genovese ESRF - Grenoble 26 March 2009 http://inac.cea.fr/l_sim/
Using Mobile Processors for Cost Effective Live Video Streaming to the Internet
 Using Mobile Processors for Cost Effective Live Video Streaming to the Internet Hans-Joachim Gelke Tobias Kammacher Institute of Embedded Systems Source: Apple Inc. Agenda 1. Typical Application 2. Available
Using Mobile Processors for Cost Effective Live Video Streaming to the Internet Hans-Joachim Gelke Tobias Kammacher Institute of Embedded Systems Source: Apple Inc. Agenda 1. Typical Application 2. Available
Introduction to GP-GPUs. Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1
 Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Introduction to GP-GPUs Advanced Computer Architectures, Cristina Silvano, Politecnico di Milano 1 GPU Architectures: How do we reach here? NVIDIA Fermi, 512 Processing Elements (PEs) 2 What Can It Do?
Xilinx SDAccel. A Unified Development Environment for Tomorrow s Data Center. By Loring Wirbel Senior Analyst. November 2014. www.linleygroup.
 Xilinx SDAccel A Unified Development Environment for Tomorrow s Data Center By Loring Wirbel Senior Analyst November 2014 www.linleygroup.com Copyright 2014 The Linley Group, Inc. This paper examines Xilinx
Xilinx SDAccel A Unified Development Environment for Tomorrow s Data Center By Loring Wirbel Senior Analyst November 2014 www.linleygroup.com Copyright 2014 The Linley Group, Inc. This paper examines Xilinx
CUDA Basics. Murphy Stein New York University
 CUDA Basics Murphy Stein New York University Overview Device Architecture CUDA Programming Model Matrix Transpose in CUDA Further Reading What is CUDA? CUDA stands for: Compute Unified Device Architecture
CUDA Basics Murphy Stein New York University Overview Device Architecture CUDA Programming Model Matrix Transpose in CUDA Further Reading What is CUDA? CUDA stands for: Compute Unified Device Architecture
Evaluation of CUDA Fortran for the CFD code Strukti
 Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Evaluation of CUDA Fortran for the CFD code Strukti Practical term report from Stephan Soller High performance computing center Stuttgart 1 Stuttgart Media University 2 High performance computing center
Keeneland Enabling Heterogeneous Computing for the Open Science Community Philip C. Roth Oak Ridge National Laboratory
 Keeneland Enabling Heterogeneous Computing for the Open Science Community Philip C. Roth Oak Ridge National Laboratory with contributions from the Keeneland project team and partners 2 NSF Office of Cyber
Keeneland Enabling Heterogeneous Computing for the Open Science Community Philip C. Roth Oak Ridge National Laboratory with contributions from the Keeneland project team and partners 2 NSF Office of Cyber
Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA
 Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA Dissertation submitted in partial fulfillment of the requirements for the degree of Master of Technology, Computer Engineering by Amol
Accelerating Intensity Layer Based Pencil Filter Algorithm using CUDA Dissertation submitted in partial fulfillment of the requirements for the degree of Master of Technology, Computer Engineering by Amol
Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures
 Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy Perspectives of GPU Computing in Physics
Design and Optimization of a Portable Lattice Boltzmann Code for Heterogeneous Architectures E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy Perspectives of GPU Computing in Physics
PARALLEL JAVASCRIPT. Norm Rubin (NVIDIA) Jin Wang (Georgia School of Technology)
 Jin Wang (Georgia School of Technology)") PARALLEL JAVASCRIPT Norm Rubin (NVIDIA) Jin Wang (Georgia School of Technology) JAVASCRIPT Not connected with Java Scheme and self (dressed in c clothing) Lots of design errors (like automatic semicolon
PARALLEL JAVASCRIPT Norm Rubin (NVIDIA) Jin Wang (Georgia School of Technology) JAVASCRIPT Not connected with Java Scheme and self (dressed in c clothing) Lots of design errors (like automatic semicolon
An Introduction to Parallel Computing/ Programming
 An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
An Introduction to Parallel Computing/ Programming Vicky Papadopoulou Lesta Astrophysics and High Performance Computing Research Group (http://ahpc.euc.ac.cy) Dep. of Computer Science and Engineering European
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
A quick tutorial on Intel's Xeon Phi Coprocessor
 A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
A quick tutorial on Intel's Xeon Phi Coprocessor www.cism.ucl.ac.be damien.francois@uclouvain.be Architecture Setup Programming The beginning of wisdom is the definition of terms. * Name Is a... As opposed
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter
 Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
Parallel Image Processing with CUDA A case study with the Canny Edge Detection Filter Daniel Weingaertner Informatics Department Federal University of Paraná - Brazil Hochschule Regensburg 02.05.2011 Daniel
SYCL for OpenCL. Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014. Copyright Khronos Group 2014 - Page 1
 SYCL for OpenCL Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014 Copyright Khronos Group 2014 - Page 1 Where is OpenCL today? OpenCL: supported by a very wide range of platforms
SYCL for OpenCL Andrew Richards, CEO Codeplay & Chair SYCL Working group GDC, March 2014 Copyright Khronos Group 2014 - Page 1 Where is OpenCL today? OpenCL: supported by a very wide range of platforms
Altera SDK for OpenCL
 Altera SDK for OpenCL Best Practices Guide Subscribe OCL003-15.0.0 101 Innovation Drive San Jose, CA 95134 www.altera.com TOC-2 Contents...1-1 Introduction...1-1 FPGA Overview...1-1 Pipelines... 1-2 Single
Altera SDK for OpenCL Best Practices Guide Subscribe OCL003-15.0.0 101 Innovation Drive San Jose, CA 95134 www.altera.com TOC-2 Contents...1-1 Introduction...1-1 FPGA Overview...1-1 Pipelines... 1-2 Single
WebCL for Hardware-Accelerated Web Applications. Won Jeon, Tasneem Brutch, and Simon Gibbs
 WebCL for Hardware-Accelerated Web Applications Won Jeon, Tasneem Brutch, and Simon Gibbs What is WebCL? WebCL is a JavaScript binding to OpenCL. WebCL enables significant acceleration of compute-intensive
WebCL for Hardware-Accelerated Web Applications Won Jeon, Tasneem Brutch, and Simon Gibbs What is WebCL? WebCL is a JavaScript binding to OpenCL. WebCL enables significant acceleration of compute-intensive
FLOATING-POINT ARITHMETIC IN AMD PROCESSORS MICHAEL SCHULTE AMD RESEARCH JUNE 2015
 FLOATING-POINT ARITHMETIC IN AMD PROCESSORS MICHAEL SCHULTE AMD RESEARCH JUNE 2015 AGENDA The Kaveri Accelerated Processing Unit (APU) The Graphics Core Next Architecture and its Floating-Point Arithmetic
FLOATING-POINT ARITHMETIC IN AMD PROCESSORS MICHAEL SCHULTE AMD RESEARCH JUNE 2015 AGENDA The Kaveri Accelerated Processing Unit (APU) The Graphics Core Next Architecture and its Floating-Point Arithmetic
Enhancing Cloud-based Servers by GPU/CPU Virtualization Management
 Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
Enhancing Cloud-based Servers by GPU/CPU Virtualiz Management Tin-Yu Wu 1, Wei-Tsong Lee 2, Chien-Yu Duan 2 Department of Computer Science and Inform Engineering, Nal Ilan University, Taiwan, ROC 1 Department
CUDA programming on NVIDIA GPUs
 p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
p. 1/21 on NVIDIA GPUs Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford-Man Institute for Quantitative Finance Oxford eresearch Centre p. 2/21 Overview hardware view
OpenCL. Administrivia. From Monday. Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011. Assignment 5 Posted. Project
 Administrivia OpenCL Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 5 Posted Due Friday, 03/25, at 11:59pm Project One page pitch due Sunday, 03/20, at 11:59pm 10 minute pitch
Administrivia OpenCL Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 5 Posted Due Friday, 03/25, at 11:59pm Project One page pitch due Sunday, 03/20, at 11:59pm 10 minute pitch
ultra fast SOM using CUDA
 ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
ultra fast SOM using CUDA SOM (Self-Organizing Map) is one of the most popular artificial neural network algorithms in the unsupervised learning category. Sijo Mathew Preetha Joy Sibi Rajendra Manoj A
Parallel Computing. Parallel shared memory computing with OpenMP
 Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing Parallel shared memory computing with OpenMP Thorsten Grahs, 14.07.2014 Table of contents Introduction Directives Scope of data Synchronization OpenMP vs. MPI OpenMP & MPI 14.07.2014
Parallel Computing for Data Science
 Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Parallel Computing for Data Science With Examples in R, C++ and CUDA Norman Matloff University of California, Davis USA (g) CRC Press Taylor & Francis Group Boca Raton London New York CRC Press is an imprint
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data
 Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Graphical Processing Units to Accelerate Orthorectification, Atmospheric Correction and Transformations for Big Data Amanda O Connor, Bryan Justice, and A. Thomas Harris IN52A. Big Data in the Geosciences:
Lecture 11: Multi-Core and GPU. Multithreading. Integration of multiple processor cores on a single chip.
 Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Lecture 11: Multi-Core and GPU Multi-core computers Multithreading GPUs General Purpose GPUs Zebo Peng, IDA, LiTH 1 Multi-Core System Integration of multiple processor cores on a single chip. To provide
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework Examples Software crisis
An Open-source Framework for Integrating Heterogeneous Resources in Private Clouds
 An Open-source Framework for Integrating Heterogeneous Resources in Private Clouds Julio Proaño, Carmen Carrión and Blanca Caminero Albacete Research Institute of Informatics (I3A), University of Castilla-La
An Open-source Framework for Integrating Heterogeneous Resources in Private Clouds Julio Proaño, Carmen Carrión and Blanca Caminero Albacete Research Institute of Informatics (I3A), University of Castilla-La
OpenACC Programming and Best Practices Guide
 OpenACC Programming and Best Practices Guide June 2015 2015 openacc-standard.org. All Rights Reserved. Contents 1 Introduction 3 Writing Portable Code........................................... 3 What
OpenACC Programming and Best Practices Guide June 2015 2015 openacc-standard.org. All Rights Reserved. Contents 1 Introduction 3 Writing Portable Code........................................... 3 What
Coping with Complexity: CPUs, GPUs and Real-world Applications
 Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
Coping with Complexity: CPUs, GPUs and Real-world Applications Leonel Sousa, Frederico Pratas, Svetislav Momcilovic and Aleksandar Ilic 9 th Scheduling for Large Scale Systems Workshop Lyon, France July
ST810 Advanced Computing
 ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
ST810 Advanced Computing Lecture 17: Parallel computing part I Eric B. Laber Hua Zhou Department of Statistics North Carolina State University Mar 13, 2013 Outline computing Hardware computing overview
~ Greetings from WSU CAPPLab ~
 ~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
~ Greetings from WSU CAPPLab ~ Multicore with SMT/GPGPU provides the ultimate performance; at WSU CAPPLab, we can help! Dr. Abu Asaduzzaman, Assistant Professor and Director Wichita State University (WSU)
Parallel Computing for Digital Signal Processing on Mobile Device GPUs
 HTW Berlin (University of Applied Sciences) WS 2013 / 2014 Media and Computing (Master) Faculty of Business Sciences II Master s Thesis Parallel Computing for Digital Signal Processing on Mobile Device
HTW Berlin (University of Applied Sciences) WS 2013 / 2014 Media and Computing (Master) Faculty of Business Sciences II Master s Thesis Parallel Computing for Digital Signal Processing on Mobile Device
MapReduce on GPUs. Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu
 1 MapReduce on GPUs Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu 2 MapReduce MAP Shuffle Reduce 3 Hadoop Open-source MapReduce framework from Apache, written in Java Used by Yahoo!, Facebook, Ebay,
1 MapReduce on GPUs Amit Sabne, Ahmad Mujahid Mohammed Razip, Kun Xu 2 MapReduce MAP Shuffle Reduce 3 Hadoop Open-source MapReduce framework from Apache, written in Java Used by Yahoo!, Facebook, Ebay,
SPEEDUP - optimization and porting of path integral MC Code to new computing architectures
 SPEEDUP - optimization and porting of path integral MC Code to new computing architectures V. Slavnić, A. Balaž, D. Stojiljković, A. Belić, A. Bogojević Scientific Computing Laboratory, Institute of Physics
SPEEDUP - optimization and porting of path integral MC Code to new computing architectures V. Slavnić, A. Balaž, D. Stojiljković, A. Belić, A. Bogojević Scientific Computing Laboratory, Institute of Physics
Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems
 Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems M. Carro 1,2, S. Tamarit 2, G. Vigueras 1, J. Mariño 2 1 IMDEA Software Institute,
Rule-Based Program Transformation for Hybrid Architectures CSW Workshop Towards Portable Libraries for Hybrid Systems M. Carro 1,2, S. Tamarit 2, G. Vigueras 1, J. Mariño 2 1 IMDEA Software Institute,