Introduction to Text Mining. Module 2: Information Extraction in GATE
|
|
|
- Abel Sparks
- 8 years ago
- Views:
Transcription
1 Introduction to Text Mining Module 2: Information Extraction in GATE The University of Sheffield, This work is licenced under the Creative Commons Attribution-NonCommercial-ShareAlike Licence

2 Aims of this module This module follows from Module 1, which introduces the concepts of text mining, information extraction (and its evaluation), and gives an overview of the GATE architecture Here we introduce the applications for Named Entity Recognition, term extraction and event detection developed in GATE for ARCOMEM We also discuss some alternative approaches using Machine Learning

3 Research Directions Addressed In ARCOMEM., we advance state of the art in adaptation of language processing resources to new domains and languages, especially in the domain of social media Development of new methodologies for language processing on social media and particularly on degraded texts (tweets etc) Development of new event recognition components for GATE, using new linguistic techniques and resources, and experiments with ML in particular, event recognition for social media is a new direction Investigate how entities and events can be effectively used for opinion mining, topic detection, and crawling

4 ARCOMEM offline processing architecture GATE components

5 Entity Recognition The application for Entity Recognition is based on (modified versions of) ANNIE and TermRaider It consists of a set of Processing Resources (PRs) executed sequentially over the corpus of documents Document Pre-processing Linguistic Pre-processing Named Entity Recognition Term Extraction RDF generation

6 Document annotated by ANNIE

7 Named Entity Recognition Adapted default ANNIE NE system to deal with specific aspects of social media (e.g. formatting issues of forums and tweets, relaxed use of English) More about processing social media in Module 4 Terms and NEs are assimilated (e.g. a term is removed if it's part of a longer NE) and output as Entities Entities are then used as input for the Event recognition module

8 Document Pre-processing Separate the body of the content from the rest, for facebook pages and tweets, using information from the original document metadata (HTML/XML tags), so that only the relevant parts of the document are annotated. Use the Boilerpipe plugin to separate other kinds of noncontent information (javascript, navigational links etc) from the content we want to analyse

9 The Boilerpipe PR in GATE In a closed domain, you can often write some JAPE rules to separate real document content from headers, footers, menus etc. In many cases, or when dealing with texts of different kinds or in different formats, it can get much trickier Boilerpipe PR provides algorithms to separate the surplus clutter (boilerplate, templates) from the main textual content of a web page. Applies the Boilerpipe Library to a GATE document in order to annotate the content, the boilerpipe, or both. Due to the way in which the library works, not all features from the library are currently available through the GATE PR

10 Original HTML document
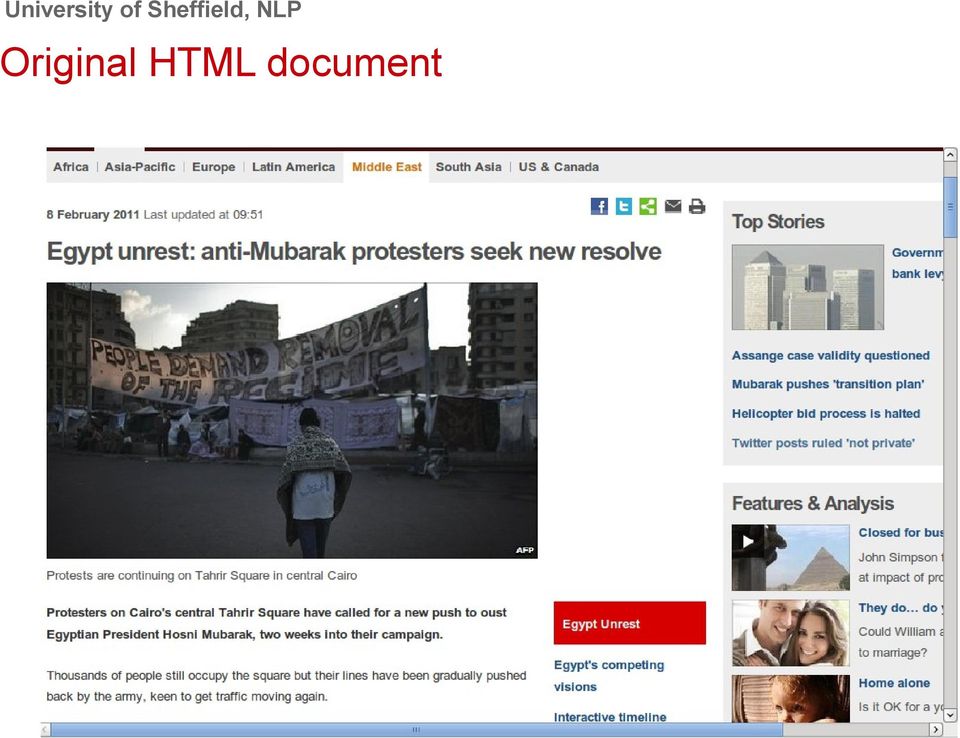

11 Processed Document Only the Content parts are used for further analysis

12 Linguistic Pre-Processing We use the following PRs: Tokeniser Sentence Splitter Language Identification POS tagger Morphological analyser For social media such as twitter, we use a specially adapted version of some of these (see Module 4)

13 Named Entity Recognition The following entity types are recognised by the NER component, corresponding to the data model Persons (e.g. artists, politicians, web 2.0 users) Organizations (e.g. companies, music bands, political parties) Locations (e.g. cities, countries) Dates and times (of events and content publication) NER consists of: Gazetteer lookup JAPE grammars Co-reference


14 Document annotated with Gazetteer Lookups

15 Document annotated with NEs


16 Document annotated with co-references items in the co-reference chain

17 TermRaider GATE plugin for detecting single and multi-word terms Based on a simple web service developed in the NeOn project - now extended to run in GATE, with visualisation tools, and extended functionality (new scoring systems, and an adaptation for German. Runs in GATE Developer (GUI) or on the command-line with RDF and CSV output Terms are ranked according to three possible scoring systems: tf.idf = term frequency (nbr of times the term occurs in the corpus) divided by document frequency (nbr of documents in which the term occurs) augmented tf.idf = after scoring tf.idf, the scores of hypernyms are boosted by the scores of hyponyms Kyoto domain relevance = document frequency (1 + nbr of hyponyms in the corpus), Bosma and Vossen 2010
 divided by document frequency (nbr of documents in which the term occurs) augmented tf.idf = after scoring tf.")
18 TermRaider: Methodology After linguistic pre-processing (tokenisation, lemmatisation, POS tagging etc.), nouns and noun phrases are identified as initial term candidates Noun phrases include post-modifiers such as prepositional phrases, and are marked with head information for determining hyponymy. Nested nouns and noun phrases are all marked as candidates. Term candidates are then scored in 3 ways. The results can be viewed in the GATE GUI, exported as RDF according to the ARCOMEM data model, or saved as CSV files The viewer can be used to adjust the cutoff parameter. This is used to determine the score threshold for a term to be considered valid Terms can also be shown as a tag cloud


19 Term candidates in a document
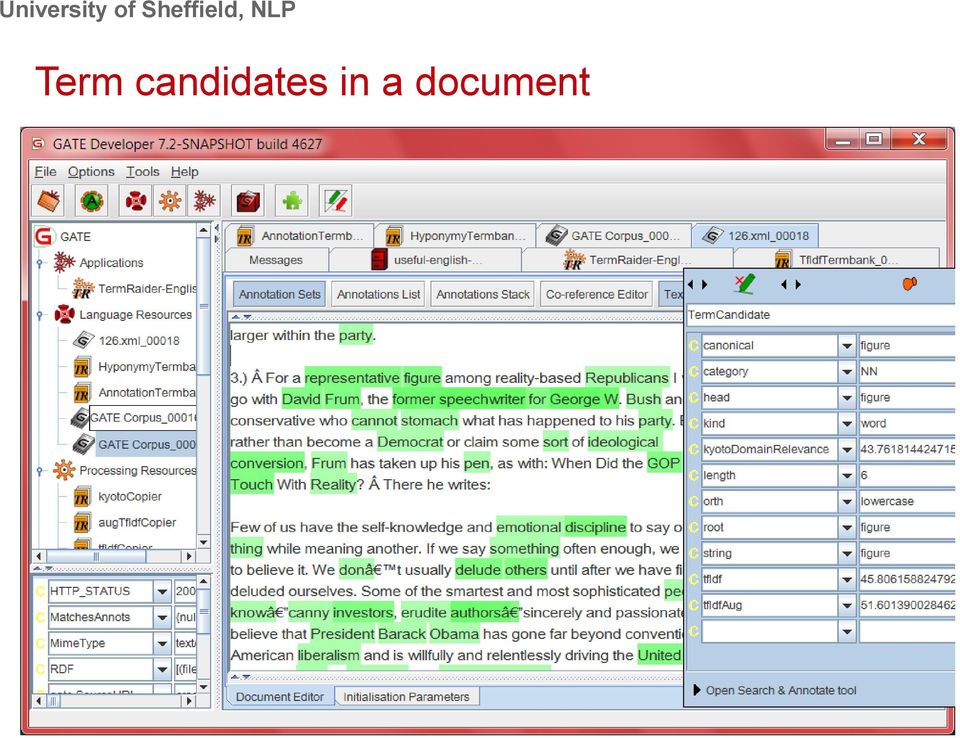
20 Try TermRaider in GATE Load the TermRaider plugin in GATE (click the plugin icon) Load a corpus (around documents on a similar topic is ideal, e.g. the US elections) Load TermRaider from the Ready-made Applications and run it on the corpus Note: this is the default TermRaider which is a little different from the one used in ARCOMEM (and not optimised for social media) Inspect the results (click on SingleWord, MultiWord or Candidate Term in the document viewer)
 Inspect the")

21 Top terms from Greek Financial Crisis corpus
22 Terms can be exported as a tag cloud
23 Viewing termbanks in GATE Double click on any termbank in GATE to view the list of terms Expand the tree to view the documents where the term was found Click the frequency tab to show a sortable list of term, term frequency and document frequency in the corpus Click the term cloud tab to view the term clouds. Drag the slider towards cloudy to show more terms, or towards sunny to show fewer terms Term clouds can be sorted by type: term frequency, term score or document frequency
24 German Entity Extraction Adaptation of TermRaider for German texts (uses some different pre-processing) System for German NER is based on ANNIE (with similar functionality), and uses German-specific resources (TreeTagger for lemmatisation and POS tagging, tailored gazetteers and grammars)
25 Entities in the Rock am Ring forum
26 How to process documents in multiple languages In GATE, you can set a processing resource in your application to run or not depending on certain circumstances You can have several different PRs loaded, and let the system automatically choose which one to run, for each document. This is very helpful when you have texts in multiple languages, or of different types, which might require different kinds of processing For example, if you have a mixture of German and English documents in your corpus, you might have some PRs which are language-dependent and some which are not You can set up the application to run the relevant PRs on the right documents automatically.
27 What if a single document is in multiple languages? We can run TextCat over each sentence separately and label it with the language We can then use a plugin in GATE called the Segment Processing PR This enables us to process labelled sections of a document independently, one at a time, and merges back the individual sections once they've been processed Useful for when you want annotations in different sections to be independent of each other when you only want to process certain sections within a document processing multiple languages within a single document
28 How to run ANNIE conditionally Load ANNIE with defaults and add the TextCat PR Now let's make the PRs conditional We only want ANNIE to run on English documents, not German ones For each PR after the TextCat PR in the pipeline, we can click on the yellow dot and set it to run only if the value of the feature lang is english Only the English one should have annotations
29 The application should look like this
30 What if we want to process the German too? If we want to process both German and English documents with differerent resources, we have a couple of options 1. We can just call some language-specific PRs conditionally, and use the language-neutral PRs on all documents 2. We can call differerent applications from within the main application
31 Running both applications conditionally Load ANNIE with defaults Load the German IE application from Ready-made applications Create a new conditional corpus pipeline Load a TextCat PR and add it to the new pipeline created Add the ANNIE and German applications to the pipeline (in either order) after the TextCat Set ANNIE to run on English documents and the German app to run on German ones Save the main application and run it on your corpus

32 Running applications conditionally
33 Expression of events Events can be expressed by: verbal predicates and their arguments (e.g. The committee dismissed the proposal ); noun phrases headed by nominalizations (e.g. economic growth ); adjective-noun combinations (e.g. governmental measure ; public money ); event-referring nouns (e.g. crisis, cash injection ).
34 Rule-based event extraction in GATE Recognition of entities and the relations between them in order to find domain-specific events and situations. In a (semi-)closed domain, this approach is preferable to an open IE-based approach which holds no preconceptions about the kinds of entities and relations possible. Application for event recognition is designed to follow the entity recognition application, so no linguistic pre-processing is necessary Basic approach involves finding event-indicative seed words (e.g. downturn might indicate an economic event) and some linguistic relaation to existing entities (e.g. Greece ) in the sentence.
35 Event extraction application The application in GATE consists of the following Processing Resources: event gazetteer verb phrase chunker event recognition JAPE grammars RDF generation As with the NE recognition module, a German version is also available, and conditional processors decide, based on the language identified for each sentence, which version to run.

36 Events annotated in GATE
37 Recognising TimeML Events TimeML is a robust specification language for events and temporal expressions in natural language. There have been a number of evaluation challenges associated with event recognition using TimeML, which provide a source of annotated data for experimentation The guidelines are a little different to our generic event definition in ARCOMEM, but they make a useful experimentation ground for us
38 TIMEML specification 7 classes of event specfied: Reporting: action of a person or organisation declaring or narrating an event (e.g. "say") Perception: physical perception of another event (e.g. "see", "hear") Aspectual: aspectual predication of another event (e.g. "start", "continue") I_Action: intensional action (e.g. "try") I_State: intensional state (e.g. "feel", "hope") State: circumstance in which something holds the truth (e.g. "war", "in danger") Occurrence: events that describe things that happen (e.g. "erupt", "arrive"). Of these, I_Action and Occurrence are most relevant for ARCOMEM
39 ML application in GATE for TimeML event detection We use the PAUM algorithm (Perceptron with Uneven Margins) as it's most suitable and efficient for this kind of classification task You can also use SVM, which is slightly better, but much slower We use lemmatised tokens, POS tags and gazetteer lookup as input for the Machine Learning. Based on this linguistic information, an input vector is constructed for each token, as we iterate through the tokens in each document (including word, number, punctuation and other symbols) to see if the current token belongs to an information entity or not. Since in event recognition the context of the token is usually as important as the token itself, the features in the input vector come not only from the current token, but also from preceding and following ones.
40 Feature weighting scheme We use the reciprocal scheme, which weights the surrounding tokens reciprocally to the distance to the token in the centre of the context window. This reflects the intuition that the nearer a neighbouring token is, the more important it is for classifying the given token. Our previous experiments have shown that such a weighting scheme typically obtains better results than the commonly used equal weighting of features. Best results so far have been obtained with a window size of 4, which means the algorithm uses features derived from 9 tokens (4 preceding, current, and 4 following)
41 Evaluation Current results using PAUM are almost equivalent to state-ofthe-art systems in the latest TimeML evaluation in terms of F1- measure. In terms of recall, it actually outperforms existing state-of-theart by several percentage points (achieving 84.99%) There is still plenty of scope for further experimentation with additional features
42 Summary We have introduced applications in GATE for NER, term and event extraction, including an alternative application for event recognition using Machine Learning. Module 3 will look at opinion mining, while Module 4 wlil deal with the specific adaptations or text mining on social media, including the TwitIE system
43 Further materials T. Risse, S. Dietze, D. Maynard and N. Tahmasebi. Using Events for Content Appraisal and Selection in Web Archives. In Proceedings of DeRiVE 2011: Workshop in conjunction with the 10th International Semantic Web Conference 2011, October 2011, Bonn, Germany. S. Dietze, D. Maynard, E. Demidova, T. Risse, W. Peters, K. Doka, Y. Stavrakas. Preservation of Social Web Content based on Entity Extraction and Consolidation. International Workshop on Semantic Digital Archives (SDA 2012), Paphos, Cyprus, September 2012, Vol. 912 CEUR-WS.org (2012), p Y. Li, K. Bontcheva and H. Cunningham. Adapting SVM for Data Sparseness and Imbalance: A Case Study on Information Extraction. Natural Language Engineering, 15(02), , T. Risse, W. Peters, P. Senellart, D. Maynard. Documenting Contemporary Society by Preserving Relevant Information from Twitter. In 'Twitter and Society', edited by K. Weller, A. Bruns, J. Burgess, M. Mahrt and C. Puschmann. (forthcoming 2013). D. Maynard, K. Bontcheva. Natural Language Processing. In J. Lehmann and J. Voelker editors, Perspectives of Ontology Learning. IOS Press (forthcoming 2013)
Introduction to IE with GATE
 Introduction to IE with GATE based on Material from Hamish Cunningham, Kalina Bontcheva (University of Sheffield) Melikka Khosh Niat 8. Dezember 2010 1 What is IE? 2 GATE 3 ANNIE 4 Annotation and Evaluation
Introduction to IE with GATE based on Material from Hamish Cunningham, Kalina Bontcheva (University of Sheffield) Melikka Khosh Niat 8. Dezember 2010 1 What is IE? 2 GATE 3 ANNIE 4 Annotation and Evaluation
Semantic annotation of requirements for automatic UML class diagram generation
 www.ijcsi.org 259 Semantic annotation of requirements for automatic UML class diagram generation Soumaya Amdouni 1, Wahiba Ben Abdessalem Karaa 2 and Sondes Bouabid 3 1 University of tunis High Institute
www.ijcsi.org 259 Semantic annotation of requirements for automatic UML class diagram generation Soumaya Amdouni 1, Wahiba Ben Abdessalem Karaa 2 and Sondes Bouabid 3 1 University of tunis High Institute
SVM Based Learning System For Information Extraction
 SVM Based Learning System For Information Extraction Yaoyong Li, Kalina Bontcheva, and Hamish Cunningham Department of Computer Science, The University of Sheffield, Sheffield, S1 4DP, UK {yaoyong,kalina,hamish}@dcs.shef.ac.uk
SVM Based Learning System For Information Extraction Yaoyong Li, Kalina Bontcheva, and Hamish Cunningham Department of Computer Science, The University of Sheffield, Sheffield, S1 4DP, UK {yaoyong,kalina,hamish}@dcs.shef.ac.uk
Interactive Dynamic Information Extraction
 Interactive Dynamic Information Extraction Kathrin Eichler, Holmer Hemsen, Markus Löckelt, Günter Neumann, and Norbert Reithinger Deutsches Forschungszentrum für Künstliche Intelligenz - DFKI, 66123 Saarbrücken
Interactive Dynamic Information Extraction Kathrin Eichler, Holmer Hemsen, Markus Löckelt, Günter Neumann, and Norbert Reithinger Deutsches Forschungszentrum für Künstliche Intelligenz - DFKI, 66123 Saarbrücken
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis
 Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Towards SoMEST Combining Social Media Monitoring with Event Extraction and Timeline Analysis Yue Dai, Ernest Arendarenko, Tuomo Kakkonen, Ding Liao School of Computing University of Eastern Finland {yvedai,
Web Document Clustering
 Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
Web Document Clustering Lab Project based on the MDL clustering suite http://www.cs.ccsu.edu/~markov/mdlclustering/ Zdravko Markov Computer Science Department Central Connecticut State University New Britain,
How to make Ontologies self-building from Wiki-Texts
 How to make Ontologies self-building from Wiki-Texts Bastian HAARMANN, Frederike GOTTSMANN, and Ulrich SCHADE Fraunhofer Institute for Communication, Information Processing & Ergonomics Neuenahrer Str.
How to make Ontologies self-building from Wiki-Texts Bastian HAARMANN, Frederike GOTTSMANN, and Ulrich SCHADE Fraunhofer Institute for Communication, Information Processing & Ergonomics Neuenahrer Str.
SOCIS: Scene of Crime Information System - IGR Review Report
 SOCIS: Scene of Crime Information System - IGR Review Report Katerina Pastra, Horacio Saggion, Yorick Wilks June 2003 1 Introduction This report reviews the work done by the University of Sheffield on
SOCIS: Scene of Crime Information System - IGR Review Report Katerina Pastra, Horacio Saggion, Yorick Wilks June 2003 1 Introduction This report reviews the work done by the University of Sheffield on
The role of multimedia in archiving community memories
 The role of multimedia in archiving community memories Jonathon S. Hare, David P. Dupplaw, Wendy Hall, Paul H. Lewis, and Kirk Martinez Electronics and Computer Science, University of Southampton, Southampton,
The role of multimedia in archiving community memories Jonathon S. Hare, David P. Dupplaw, Wendy Hall, Paul H. Lewis, and Kirk Martinez Electronics and Computer Science, University of Southampton, Southampton,
ARABIC PERSON NAMES RECOGNITION BY USING A RULE BASED APPROACH
 Journal of Computer Science 9 (7): 922-927, 2013 ISSN: 1549-3636 2013 doi:10.3844/jcssp.2013.922.927 Published Online 9 (7) 2013 (http://www.thescipub.com/jcs.toc) ARABIC PERSON NAMES RECOGNITION BY USING
Journal of Computer Science 9 (7): 922-927, 2013 ISSN: 1549-3636 2013 doi:10.3844/jcssp.2013.922.927 Published Online 9 (7) 2013 (http://www.thescipub.com/jcs.toc) ARABIC PERSON NAMES RECOGNITION BY USING
Technical Report. The KNIME Text Processing Feature:
 Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Technical Report The KNIME Text Processing Feature: An Introduction Dr. Killian Thiel Dr. Michael Berthold Killian.Thiel@uni-konstanz.de Michael.Berthold@uni-konstanz.de Copyright 2012 by KNIME.com AG
Named Entity Recognition Experiments on Turkish Texts
 Named Entity Recognition Experiments on Dilek Küçük 1 and Adnan Yazıcı 2 1 TÜBİTAK - Uzay Institute, Ankara - Turkey dilek.kucuk@uzay.tubitak.gov.tr 2 Dept. of Computer Engineering, METU, Ankara - Turkey
Named Entity Recognition Experiments on Dilek Küçük 1 and Adnan Yazıcı 2 1 TÜBİTAK - Uzay Institute, Ankara - Turkey dilek.kucuk@uzay.tubitak.gov.tr 2 Dept. of Computer Engineering, METU, Ankara - Turkey
An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them
 An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them Vangelis Karkaletsis and Constantine D. Spyropoulos NCSR Demokritos, Institute of Informatics & Telecommunications,
An Open Platform for Collecting Domain Specific Web Pages and Extracting Information from Them Vangelis Karkaletsis and Constantine D. Spyropoulos NCSR Demokritos, Institute of Informatics & Telecommunications,
C o p yr i g ht 2015, S A S I nstitute Inc. A l l r i g hts r eser v ed. INTRODUCTION TO SAS TEXT MINER
 INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
GATE Mímir and cloud services. Multi-paradigm indexing and search tool Pay-as-you-go large-scale annotation
 GATE Mímir and cloud services Multi-paradigm indexing and search tool Pay-as-you-go large-scale annotation GATE Mímir GATE Mímir is an indexing system for GATE documents. Mímir can index: Text: the original
GATE Mímir and cloud services Multi-paradigm indexing and search tool Pay-as-you-go large-scale annotation GATE Mímir GATE Mímir is an indexing system for GATE documents. Mímir can index: Text: the original
Question Answering and Multilingual CLEF 2008
 Dublin City University at QA@CLEF 2008 Sisay Fissaha Adafre Josef van Genabith National Center for Language Technology School of Computing, DCU IBM CAS Dublin sadafre,josef@computing.dcu.ie Abstract We
Dublin City University at QA@CLEF 2008 Sisay Fissaha Adafre Josef van Genabith National Center for Language Technology School of Computing, DCU IBM CAS Dublin sadafre,josef@computing.dcu.ie Abstract We
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks
 A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
A Knowledge-Poor Approach to BioCreative V DNER and CID Tasks Firoj Alam 1, Anna Corazza 2, Alberto Lavelli 3, and Roberto Zanoli 3 1 Dept. of Information Eng. and Computer Science, University of Trento,
<is web> Information Systems & Semantic Web University of Koblenz Landau, Germany
 Information Systems University of Koblenz Landau, Germany Exploiting Spatial Context in Images Using Fuzzy Constraint Reasoning Carsten Saathoff & Agenda Semantic Web: Our Context Knowledge Annotation
Information Systems University of Koblenz Landau, Germany Exploiting Spatial Context in Images Using Fuzzy Constraint Reasoning Carsten Saathoff & Agenda Semantic Web: Our Context Knowledge Annotation
Micro blogs Oriented Word Segmentation System
 Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Micro blogs Oriented Word Segmentation System Yijia Liu, Meishan Zhang, Wanxiang Che, Ting Liu, Yihe Deng Research Center for Social Computing and Information Retrieval Harbin Institute of Technology,
Challenges in developing opinion mining tools for social media
 Challenges in developing opinion mining tools for social media Diana Maynard, Kalina Bontcheva, Dominic Rout Department of Computer Science University of Sheffield Regent Court, Sheffield, S1 4DP, UK diana@dcs.shef.ac.uk
Challenges in developing opinion mining tools for social media Diana Maynard, Kalina Bontcheva, Dominic Rout Department of Computer Science University of Sheffield Regent Court, Sheffield, S1 4DP, UK diana@dcs.shef.ac.uk
Schema documentation for types1.2.xsd
 Generated with oxygen XML Editor Take care of the environment, print only if necessary! 8 february 2011 Table of Contents : ""...........................................................................................................
Generated with oxygen XML Editor Take care of the environment, print only if necessary! 8 february 2011 Table of Contents : ""...........................................................................................................
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System
 Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Extracting Opinions and Facts for Business Intelligence
 Extracting Opinions and Facts for Business Intelligence Horacio Saggion, Adam Funk Department of Computer Science University of Sheffield Regent Court 211 Portobello Street Sheffield - S1 5DP {H.Saggion,A.Funk}@dcs.shef.ac.uk
Extracting Opinions and Facts for Business Intelligence Horacio Saggion, Adam Funk Department of Computer Science University of Sheffield Regent Court 211 Portobello Street Sheffield - S1 5DP {H.Saggion,A.Funk}@dcs.shef.ac.uk
Combining Ontological Knowledge and Wrapper Induction techniques into an e-retail System 1
 Combining Ontological Knowledge and Wrapper Induction techniques into an e-retail System 1 Maria Teresa Pazienza, Armando Stellato and Michele Vindigni Department of Computer Science, Systems and Management,
Combining Ontological Knowledge and Wrapper Induction techniques into an e-retail System 1 Maria Teresa Pazienza, Armando Stellato and Michele Vindigni Department of Computer Science, Systems and Management,
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Text Generation for Abstractive Summarization
 Text Generation for Abstractive Summarization Pierre-Etienne Genest, Guy Lapalme RALI-DIRO Université de Montréal P.O. Box 6128, Succ. Centre-Ville Montréal, Québec Canada, H3C 3J7 {genestpe,lapalme}@iro.umontreal.ca
Text Generation for Abstractive Summarization Pierre-Etienne Genest, Guy Lapalme RALI-DIRO Université de Montréal P.O. Box 6128, Succ. Centre-Ville Montréal, Québec Canada, H3C 3J7 {genestpe,lapalme}@iro.umontreal.ca
Brill s rule-based PoS tagger
 Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
How To Write A Summary Of A Review
 PRODUCT REVIEW RANKING SUMMARIZATION N.P.Vadivukkarasi, Research Scholar, Department of Computer Science, Kongu Arts and Science College, Erode. Dr. B. Jayanthi M.C.A., M.Phil., Ph.D., Associate Professor,
PRODUCT REVIEW RANKING SUMMARIZATION N.P.Vadivukkarasi, Research Scholar, Department of Computer Science, Kongu Arts and Science College, Erode. Dr. B. Jayanthi M.C.A., M.Phil., Ph.D., Associate Professor,
Intelligent Analysis of User Interactions in a Collaborative Software Engineering Context
 Intelligent Analysis of User Interactions in a Collaborative Software Engineering Context Alejandro Corbellini 1,2, Silvia Schiaffino 1,2, Daniela Godoy 1,2 1 ISISTAN Research Institute, UNICEN University,
Intelligent Analysis of User Interactions in a Collaborative Software Engineering Context Alejandro Corbellini 1,2, Silvia Schiaffino 1,2, Daniela Godoy 1,2 1 ISISTAN Research Institute, UNICEN University,
POSBIOTM-NER: A Machine Learning Approach for. Bio-Named Entity Recognition
 POSBIOTM-NER: A Machine Learning Approach for Bio-Named Entity Recognition Yu Song, Eunji Yi, Eunju Kim, Gary Geunbae Lee, Department of CSE, POSTECH, Pohang, Korea 790-784 Soo-Jun Park Bioinformatics
POSBIOTM-NER: A Machine Learning Approach for Bio-Named Entity Recognition Yu Song, Eunji Yi, Eunju Kim, Gary Geunbae Lee, Department of CSE, POSTECH, Pohang, Korea 790-784 Soo-Jun Park Bioinformatics
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework
 Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Effective Data Retrieval Mechanism Using AML within the Web Based Join Framework Usha Nandini D 1, Anish Gracias J 2 1 ushaduraisamy@yahoo.co.in 2 anishgracias@gmail.com Abstract A vast amount of assorted
Special Topics in Computer Science
 Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
IT services for analyses of various data samples
 IT services for analyses of various data samples Ján Paralič, František Babič, Martin Sarnovský, Peter Butka, Cecília Havrilová, Miroslava Muchová, Michal Puheim, Martin Mikula, Gabriel Tutoky Technical
IT services for analyses of various data samples Ján Paralič, František Babič, Martin Sarnovský, Peter Butka, Cecília Havrilová, Miroslava Muchová, Michal Puheim, Martin Mikula, Gabriel Tutoky Technical
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project
 Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Bridging CAQDAS with text mining: Text analyst s toolbox for Big Data: Science in the Media Project Ahmet Suerdem Istanbul Bilgi University; LSE Methodology Dept. Science in the media project is funded
Chapter 8. Final Results on Dutch Senseval-2 Test Data
 Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Mining a Corpus of Job Ads
 Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
Mining a Corpus of Job Ads Workshop Strings and Structures Computational Biology & Linguistics Jürgen Jürgen Hermes Hermes Sprachliche Linguistic Data Informationsverarbeitung Processing Institut Department
An Interactive De-Identification-System
 An Interactive De-Identification-System Katrin Tomanek 1, Philipp Daumke 1, Frank Enders 1, Jens Huber 1, Katharina Theres 2 and Marcel Müller 2 1 Averbis GmbH, Freiburg/Germany http://www.averbis.com
An Interactive De-Identification-System Katrin Tomanek 1, Philipp Daumke 1, Frank Enders 1, Jens Huber 1, Katharina Theres 2 and Marcel Müller 2 1 Averbis GmbH, Freiburg/Germany http://www.averbis.com
Morphological Analysis and Named Entity Recognition for your Lucene / Solr Search Applications
 Morphological Analysis and Named Entity Recognition for your Lucene / Solr Search Applications Berlin Berlin Buzzwords 2011, Dr. Christoph Goller, IntraFind AG Outline IntraFind AG Indexing Morphological
Morphological Analysis and Named Entity Recognition for your Lucene / Solr Search Applications Berlin Berlin Buzzwords 2011, Dr. Christoph Goller, IntraFind AG Outline IntraFind AG Indexing Morphological
Natural Language to Relational Query by Using Parsing Compiler
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 3, March 2015,
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features
 , pp.273-280 http://dx.doi.org/10.14257/ijdta.2015.8.4.27 Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features Lirong Qiu School of Information Engineering, MinzuUniversity of
, pp.273-280 http://dx.doi.org/10.14257/ijdta.2015.8.4.27 Tibetan-Chinese Bilingual Sentences Alignment Method based on Multiple Features Lirong Qiu School of Information Engineering, MinzuUniversity of
Ontology-based information extraction for market monitoring and technology watch
 Ontology-based information extraction for market monitoring and technology watch Diana Maynard 1, Milena Yankova 1, Alexandros Kourakis 2, Antonis Kokossis 2 1 Department of Computer Science, University
Ontology-based information extraction for market monitoring and technology watch Diana Maynard 1, Milena Yankova 1, Alexandros Kourakis 2, Antonis Kokossis 2 1 Department of Computer Science, University
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts
 MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
MIRACLE at VideoCLEF 2008: Classification of Multilingual Speech Transcripts Julio Villena-Román 1,3, Sara Lana-Serrano 2,3 1 Universidad Carlos III de Madrid 2 Universidad Politécnica de Madrid 3 DAEDALUS
Finding Advertising Keywords on Web Pages
 Finding Advertising Keywords on Web Pages Wen-tau Yih Microsoft Research 1 Microsoft Way Redmond, WA 98052 scottyih@microsoft.com Joshua Goodman Microsoft Research 1 Microsoft Way Redmond, WA 98052 joshuago@microsoft.com
Finding Advertising Keywords on Web Pages Wen-tau Yih Microsoft Research 1 Microsoft Way Redmond, WA 98052 scottyih@microsoft.com Joshua Goodman Microsoft Research 1 Microsoft Way Redmond, WA 98052 joshuago@microsoft.com
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
GrammAds: Keyword and Ad Creative Generator for Online Advertising Campaigns
 GrammAds: Keyword and Ad Creative Generator for Online Advertising Campaigns Stamatina Thomaidou 1,2, Konstantinos Leymonis 1,2, Michalis Vazirgiannis 1,2,3 Presented by: Fragkiskos Malliaros 2 1 : Athens
GrammAds: Keyword and Ad Creative Generator for Online Advertising Campaigns Stamatina Thomaidou 1,2, Konstantinos Leymonis 1,2, Michalis Vazirgiannis 1,2,3 Presented by: Fragkiskos Malliaros 2 1 : Athens
SINAI at WEPS-3: Online Reputation Management
 SINAI at WEPS-3: Online Reputation Management M.A. García-Cumbreras, M. García-Vega F. Martínez-Santiago and J.M. Peréa-Ortega University of Jaén. Departamento de Informática Grupo Sistemas Inteligentes
SINAI at WEPS-3: Online Reputation Management M.A. García-Cumbreras, M. García-Vega F. Martínez-Santiago and J.M. Peréa-Ortega University of Jaén. Departamento de Informática Grupo Sistemas Inteligentes
Web Mining. Margherita Berardi LACAM. Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it
 Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
Web Mining Margherita Berardi LACAM Dipartimento di Informatica Università degli Studi di Bari berardi@di.uniba.it Bari, 24 Aprile 2003 Overview Introduction Knowledge discovery from text (Web Content
ONLINE RESUME PARSING SYSTEM USING TEXT ANALYTICS
 ONLINE RESUME PARSING SYSTEM USING TEXT ANALYTICS Divyanshu Chandola 1, Aditya Garg 2, Ankit Maurya 3, Amit Kushwaha 4 1 Student, Department of Information Technology, ABES Engineering College, Uttar Pradesh,
ONLINE RESUME PARSING SYSTEM USING TEXT ANALYTICS Divyanshu Chandola 1, Aditya Garg 2, Ankit Maurya 3, Amit Kushwaha 4 1 Student, Department of Information Technology, ABES Engineering College, Uttar Pradesh,
DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7
 DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7 UNDER THE GUIDANCE Dr. N.P. DHAVALE, DGM, INFINET Department SUBMITTED TO INSTITUTE FOR DEVELOPMENT AND RESEARCH IN BANKING TECHNOLOGY
DATA MINING TOOL FOR INTEGRATED COMPLAINT MANAGEMENT SYSTEM WEKA 3.6.7 UNDER THE GUIDANCE Dr. N.P. DHAVALE, DGM, INFINET Department SUBMITTED TO INSTITUTE FOR DEVELOPMENT AND RESEARCH IN BANKING TECHNOLOGY
Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach.
 Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach. Pranali Chilekar 1, Swati Ubale 2, Pragati Sonkambale 3, Reema Panarkar 4, Gopal Upadhye 5 1 2 3 4 5
Sentiment analysis on news articles using Natural Language Processing and Machine Learning Approach. Pranali Chilekar 1, Swati Ubale 2, Pragati Sonkambale 3, Reema Panarkar 4, Gopal Upadhye 5 1 2 3 4 5
31 Case Studies: Java Natural Language Tools Available on the Web
 31 Case Studies: Java Natural Language Tools Available on the Web Chapter Objectives Chapter Contents This chapter provides a number of sources for open source and free atural language understanding software
31 Case Studies: Java Natural Language Tools Available on the Web Chapter Objectives Chapter Contents This chapter provides a number of sources for open source and free atural language understanding software
IBM SPSS Direct Marketing 23
 IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
IBM SPSS Direct Marketing 23 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 23, release
Semantic Search in E-Discovery. David Graus & Zhaochun Ren
 Semantic Search in E-Discovery David Graus & Zhaochun Ren This talk Introduction David Graus! Understanding e-mail traffic David Graus! Topic discovery & tracking in social media Zhaochun Ren 2 Intro Semantic
Semantic Search in E-Discovery David Graus & Zhaochun Ren This talk Introduction David Graus! Understanding e-mail traffic David Graus! Topic discovery & tracking in social media Zhaochun Ren 2 Intro Semantic
ViewerPro enables traders to automatically capture the impact of news on their trading portfolios
 ViewerPro enables traders to automatically capture the impact of news on their trading portfolios Integrate Emerging News into Trading Strategies With ViewerPro, you can automatically identify the impacts
ViewerPro enables traders to automatically capture the impact of news on their trading portfolios Integrate Emerging News into Trading Strategies With ViewerPro, you can automatically identify the impacts
IBM SPSS Direct Marketing 22
 IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
IBM SPSS Direct Marketing 22 Note Before using this information and the product it supports, read the information in Notices on page 25. Product Information This edition applies to version 22, release
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter
 VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
VCU-TSA at Semeval-2016 Task 4: Sentiment Analysis in Twitter Gerard Briones and Kasun Amarasinghe and Bridget T. McInnes, PhD. Department of Computer Science Virginia Commonwealth University Richmond,
Structural Health Monitoring Tools (SHMTools)
") Structural Health Monitoring Tools (SHMTools) Getting Started LANL/UCSD Engineering Institute LA-CC-14-046 c Copyright 2014, Los Alamos National Security, LLC All rights reserved. May 30, 2014 Contents
Structural Health Monitoring Tools (SHMTools) Getting Started LANL/UCSD Engineering Institute LA-CC-14-046 c Copyright 2014, Los Alamos National Security, LLC All rights reserved. May 30, 2014 Contents
Term extraction for user profiling: evaluation by the user
 Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Term extraction for user profiling: evaluation by the user Suzan Verberne 1, Maya Sappelli 1,2, Wessel Kraaij 1,2 1 Institute for Computing and Information Sciences, Radboud University Nijmegen 2 TNO,
Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery
 Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery Jan Paralic, Peter Smatana Technical University of Kosice, Slovakia Center for
Transformation of Free-text Electronic Health Records for Efficient Information Retrieval and Support of Knowledge Discovery Jan Paralic, Peter Smatana Technical University of Kosice, Slovakia Center for
Kybots, knowledge yielding robots German Rigau IXA group, UPV/EHU http://ixa.si.ehu.es
 KYOTO () Intelligent Content and Semantics Knowledge Yielding Ontologies for Transition-Based Organization http://www.kyoto-project.eu/ Kybots, knowledge yielding robots German Rigau IXA group, UPV/EHU
KYOTO () Intelligent Content and Semantics Knowledge Yielding Ontologies for Transition-Based Organization http://www.kyoto-project.eu/ Kybots, knowledge yielding robots German Rigau IXA group, UPV/EHU
Active Learning SVM for Blogs recommendation
 Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Active Learning SVM for Blogs recommendation Xin Guan Computer Science, George Mason University Ⅰ.Introduction In the DH Now website, they try to review a big amount of blogs and articles and find the
Text Analytics Beginner s Guide. Extracting Meaning from Unstructured Data
 Text Analytics Beginner s Guide Extracting Meaning from Unstructured Data Contents Text Analytics 3 Use Cases 7 Terms 9 Trends 14 Scenario 15 Resources 24 2 2013 Angoss Software Corporation. All rights
Text Analytics Beginner s Guide Extracting Meaning from Unstructured Data Contents Text Analytics 3 Use Cases 7 Terms 9 Trends 14 Scenario 15 Resources 24 2 2013 Angoss Software Corporation. All rights
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr
 Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Université de Montpellier 2 Hugo Alatrista-Salas : hugo.alatrista-salas@teledetection.fr WEKA Gallirallus Zeland) australis : Endemic bird (New Characteristics Waikato university Weka is a collection
Boosting the Feature Space: Text Classification for Unstructured Data on the Web
 Boosting the Feature Space: Text Classification for Unstructured Data on the Web Yang Song 1, Ding Zhou 1, Jian Huang 2, Isaac G. Councill 2, Hongyuan Zha 1,2, C. Lee Giles 1,2 1 Department of Computer
Boosting the Feature Space: Text Classification for Unstructured Data on the Web Yang Song 1, Ding Zhou 1, Jian Huang 2, Isaac G. Councill 2, Hongyuan Zha 1,2, C. Lee Giles 1,2 1 Department of Computer
An NLP Curator (or: How I Learned to Stop Worrying and Love NLP Pipelines)
") An NLP Curator (or: How I Learned to Stop Worrying and Love NLP Pipelines) James Clarke, Vivek Srikumar, Mark Sammons, Dan Roth Department of Computer Science, University of Illinois, Urbana-Champaign.
An NLP Curator (or: How I Learned to Stop Worrying and Love NLP Pipelines) James Clarke, Vivek Srikumar, Mark Sammons, Dan Roth Department of Computer Science, University of Illinois, Urbana-Champaign.
Knowledge Discovery from patents using KMX Text Analytics
 Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Knowledge Discovery from patents using KMX Text Analytics Dr. Anton Heijs anton.heijs@treparel.com Treparel Abstract In this white paper we discuss how the KMX technology of Treparel can help searchers
Text Analysis beyond Keyword Spotting
 Text Analysis beyond Keyword Spotting Bastian Haarmann, Lukas Sikorski, Ulrich Schade { bastian.haarmann lukas.sikorski ulrich.schade }@fkie.fraunhofer.de Fraunhofer Institute for Communication, Information
Text Analysis beyond Keyword Spotting Bastian Haarmann, Lukas Sikorski, Ulrich Schade { bastian.haarmann lukas.sikorski ulrich.schade }@fkie.fraunhofer.de Fraunhofer Institute for Communication, Information
CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet
 CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet Muhammad Atif Qureshi 1,2, Arjumand Younus 1,2, Colm O Riordan 1,
CIRGIRDISCO at RepLab2014 Reputation Dimension Task: Using Wikipedia Graph Structure for Classifying the Reputation Dimension of a Tweet Muhammad Atif Qureshi 1,2, Arjumand Younus 1,2, Colm O Riordan 1,
Web 3.0 image search: a World First
 Web 3.0 image search: a World First The digital age has provided a virtually free worldwide digital distribution infrastructure through the internet. Many areas of commerce, government and academia have
Web 3.0 image search: a World First The digital age has provided a virtually free worldwide digital distribution infrastructure through the internet. Many areas of commerce, government and academia have
Deposit Identification Utility and Visualization Tool
 Deposit Identification Utility and Visualization Tool Colorado School of Mines Field Session Summer 2014 David Alexander Jeremy Kerr Luke McPherson Introduction Newmont Mining Corporation was founded in
Deposit Identification Utility and Visualization Tool Colorado School of Mines Field Session Summer 2014 David Alexander Jeremy Kerr Luke McPherson Introduction Newmont Mining Corporation was founded in
University of Sheffield, NLP. Case study: (Almost) Real-Time Social Media Analysis of Political Tweets
 Real-Time Social Media Analysis of Political Tweets") Case study: (Almost) Real-Time Social Media Analysis of Political Tweets We are all connected to each other... Information, thoughts and opinions are shared prolifically on the social web these days 72%
Case study: (Almost) Real-Time Social Media Analysis of Political Tweets We are all connected to each other... Information, thoughts and opinions are shared prolifically on the social web these days 72%
Parsing Software Requirements with an Ontology-based Semantic Role Labeler
 Parsing Software Requirements with an Ontology-based Semantic Role Labeler Michael Roth University of Edinburgh mroth@inf.ed.ac.uk Ewan Klein University of Edinburgh ewan@inf.ed.ac.uk Abstract Software
Parsing Software Requirements with an Ontology-based Semantic Role Labeler Michael Roth University of Edinburgh mroth@inf.ed.ac.uk Ewan Klein University of Edinburgh ewan@inf.ed.ac.uk Abstract Software
Er is door mij gebruik gemaakt van dia s uit presentaties van o.a. Anastasios Kesidis, CIL, Athene Griekenland, en Asaf Tzadok, IBM Haifa Research Lab
 IMPACT is supported by the European Community under the FP7 ICT Work Programme. The project is coordinated by the National Library of the Netherlands. Er is door mij gebruik gemaakt van dia s uit presentaties
IMPACT is supported by the European Community under the FP7 ICT Work Programme. The project is coordinated by the National Library of the Netherlands. Er is door mij gebruik gemaakt van dia s uit presentaties
Starting User Guide 11/29/2011
 Table of Content Starting User Guide... 1 Register... 2 Create a new site... 3 Using a Template... 3 From a RSS feed... 5 From Scratch... 5 Edit a site... 6 In a few words... 6 In details... 6 Components
Table of Content Starting User Guide... 1 Register... 2 Create a new site... 3 Using a Template... 3 From a RSS feed... 5 From Scratch... 5 Edit a site... 6 In a few words... 6 In details... 6 Components
Automatic detection of political opinions in Tweets
 Automatic detection of political opinions in Tweets Diana Maynard and Adam Funk Department of Computer Science, University of Sheffield Regent Court, 211 Portobello Street, Sheffield, UK diana@dcs.shef.ac.uk
Automatic detection of political opinions in Tweets Diana Maynard and Adam Funk Department of Computer Science, University of Sheffield Regent Court, 211 Portobello Street, Sheffield, UK diana@dcs.shef.ac.uk
CENG 734 Advanced Topics in Bioinformatics
 CENG 734 Advanced Topics in Bioinformatics Week 9 Text Mining for Bioinformatics: BioCreative II.5 Fall 2010-2011 Quiz #7 1. Draw the decompressed graph for the following graph summary 2. Describe the
CENG 734 Advanced Topics in Bioinformatics Week 9 Text Mining for Bioinformatics: BioCreative II.5 Fall 2010-2011 Quiz #7 1. Draw the decompressed graph for the following graph summary 2. Describe the
Predicting stocks returns correlations based on unstructured data sources
 Predicting stocks returns correlations based on unstructured data sources Mateusz Radzimski, José Luis Sánchez-Cervantes, José Luis López Cuadrado, Ángel García-Crespo Departamento de Informática Universidad
Predicting stocks returns correlations based on unstructured data sources Mateusz Radzimski, José Luis Sánchez-Cervantes, José Luis López Cuadrado, Ángel García-Crespo Departamento de Informática Universidad
Context Grammar and POS Tagging
 Context Grammar and POS Tagging Shian-jung Dick Chen Don Loritz New Technology and Research New Technology and Research LexisNexis LexisNexis Ohio, 45342 Ohio, 45342 dick.chen@lexisnexis.com don.loritz@lexisnexis.com
Context Grammar and POS Tagging Shian-jung Dick Chen Don Loritz New Technology and Research New Technology and Research LexisNexis LexisNexis Ohio, 45342 Ohio, 45342 dick.chen@lexisnexis.com don.loritz@lexisnexis.com
Draft Response for delivering DITA.xml.org DITAweb. Written by Mark Poston, Senior Technical Consultant, Mekon Ltd.
 Draft Response for delivering DITA.xml.org DITAweb Written by Mark Poston, Senior Technical Consultant, Mekon Ltd. Contents Contents... 2 Background... 4 Introduction... 4 Mekon DITAweb... 5 Overview of
Draft Response for delivering DITA.xml.org DITAweb Written by Mark Poston, Senior Technical Consultant, Mekon Ltd. Contents Contents... 2 Background... 4 Introduction... 4 Mekon DITAweb... 5 Overview of
How the Computer Translates. Svetlana Sokolova President and CEO of PROMT, PhD.
 Svetlana Sokolova President and CEO of PROMT, PhD. How the Computer Translates Machine translation is a special field of computer application where almost everyone believes that he/she is a specialist.
Svetlana Sokolova President and CEO of PROMT, PhD. How the Computer Translates Machine translation is a special field of computer application where almost everyone believes that he/she is a specialist.
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
2. Distributed Handwriting Recognition. Abstract. 1. Introduction
 XPEN: An XML Based Format for Distributed Online Handwriting Recognition A.P.Lenaghan, R.R.Malyan, School of Computing and Information Systems, Kingston University, UK {a.lenaghan,r.malyan}@kingston.ac.uk
XPEN: An XML Based Format for Distributed Online Handwriting Recognition A.P.Lenaghan, R.R.Malyan, School of Computing and Information Systems, Kingston University, UK {a.lenaghan,r.malyan}@kingston.ac.uk
Social Media Data Mining and Inference system based on Sentiment Analysis
 Social Media Data Mining and Inference system based on Sentiment Analysis Master of Science Thesis in Applied Information Technology ANA SUFIAN RANJITH ANANTHARAMAN Department of Applied Information Technology
Social Media Data Mining and Inference system based on Sentiment Analysis Master of Science Thesis in Applied Information Technology ANA SUFIAN RANJITH ANANTHARAMAN Department of Applied Information Technology
PoS-tagging Italian texts with CORISTagger
 PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words
 , pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
, pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
Clustering Technique in Data Mining for Text Documents
 Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Clustering Technique in Data Mining for Text Documents Ms.J.Sathya Priya Assistant Professor Dept Of Information Technology. Velammal Engineering College. Chennai. Ms.S.Priyadharshini Assistant Professor
Natural Language Technology for Information Integration in Business Intelligence
 Natural Language Technology for Information Integration in Business Intelligence Diana Maynard 1 and Horacio Saggion 1 and Milena Yankova 21 and Kalina Bontcheva 1 and Wim Peters 1 1 Department of Computer
Natural Language Technology for Information Integration in Business Intelligence Diana Maynard 1 and Horacio Saggion 1 and Milena Yankova 21 and Kalina Bontcheva 1 and Wim Peters 1 1 Department of Computer
Terminology Extraction from Log Files
 Terminology Extraction from Log Files Hassan Saneifar 1,2, Stéphane Bonniol 2, Anne Laurent 1, Pascal Poncelet 1, and Mathieu Roche 1 1 LIRMM - Université Montpellier 2 - CNRS 161 rue Ada, 34392 Montpellier
Terminology Extraction from Log Files Hassan Saneifar 1,2, Stéphane Bonniol 2, Anne Laurent 1, Pascal Poncelet 1, and Mathieu Roche 1 1 LIRMM - Université Montpellier 2 - CNRS 161 rue Ada, 34392 Montpellier
Statistical Machine Translation
 Statistical Machine Translation Some of the content of this lecture is taken from previous lectures and presentations given by Philipp Koehn and Andy Way. Dr. Jennifer Foster National Centre for Language
Statistical Machine Translation Some of the content of this lecture is taken from previous lectures and presentations given by Philipp Koehn and Andy Way. Dr. Jennifer Foster National Centre for Language
Sentiment analysis of Twitter microblogging posts. Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies
 Sentiment analysis of Twitter microblogging posts Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies Introduction Popularity of microblogging services Twitter microblogging posts
Sentiment analysis of Twitter microblogging posts Jasmina Smailović Jožef Stefan Institute Department of Knowledge Technologies Introduction Popularity of microblogging services Twitter microblogging posts
Towards a Visually Enhanced Medical Search Engine
 Towards a Visually Enhanced Medical Search Engine Lavish Lalwani 1,2, Guido Zuccon 1, Mohamed Sharaf 2, Anthony Nguyen 1 1 The Australian e-health Research Centre, Brisbane, Queensland, Australia; 2 The
Towards a Visually Enhanced Medical Search Engine Lavish Lalwani 1,2, Guido Zuccon 1, Mohamed Sharaf 2, Anthony Nguyen 1 1 The Australian e-health Research Centre, Brisbane, Queensland, Australia; 2 The
Sisense. Product Highlights. www.sisense.com
 Sisense Product Highlights Introduction Sisense is a business intelligence solution that simplifies analytics for complex data by offering an end-to-end platform that lets users easily prepare and analyze
Sisense Product Highlights Introduction Sisense is a business intelligence solution that simplifies analytics for complex data by offering an end-to-end platform that lets users easily prepare and analyze
Tractor Manual. 1 What is Tractor? 2 1.1 GATE... 3 1.2 Propositionalizer... 3 1.3 CBIR... 3 1.4 Syntax-Semantics Mapper... 3
 Tractor Manual Stuart C. Shapiro, Daniel R. Schlegel, and Michael Prentice Department of Computer Science and Engineering and Center for Multisource Information Fusion and Center for Cognitive Science
Tractor Manual Stuart C. Shapiro, Daniel R. Schlegel, and Michael Prentice Department of Computer Science and Engineering and Center for Multisource Information Fusion and Center for Cognitive Science
Get results with modern, personalized digital experiences
 Brochure HP TeamSite What s new in TeamSite? The latest release of TeamSite (TeamSite 8) brings significant enhancements in usability and performance: Modern graphical interface: Rely on an easy and intuitive
Brochure HP TeamSite What s new in TeamSite? The latest release of TeamSite (TeamSite 8) brings significant enhancements in usability and performance: Modern graphical interface: Rely on an easy and intuitive
Shallow Parsing with Apache UIMA
 Shallow Parsing with Apache UIMA Graham Wilcock University of Helsinki Finland graham.wilcock@helsinki.fi Abstract Apache UIMA (Unstructured Information Management Architecture) is a framework for linguistic
Shallow Parsing with Apache UIMA Graham Wilcock University of Helsinki Finland graham.wilcock@helsinki.fi Abstract Apache UIMA (Unstructured Information Management Architecture) is a framework for linguistic
A Survey on Product Aspect Ranking
 A Survey on Product Aspect Ranking Charushila Patil 1, Prof. P. M. Chawan 2, Priyamvada Chauhan 3, Sonali Wankhede 4 M. Tech Student, Department of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra,
A Survey on Product Aspect Ranking Charushila Patil 1, Prof. P. M. Chawan 2, Priyamvada Chauhan 3, Sonali Wankhede 4 M. Tech Student, Department of Computer Engineering and IT, VJTI College, Mumbai, Maharashtra,
Sentiment Analysis. D. Skrepetos 1. University of Waterloo. NLP Presenation, 06/17/2015
 Sentiment Analysis D. Skrepetos 1 1 Department of Computer Science University of Waterloo NLP Presenation, 06/17/2015 D. Skrepetos (University of Waterloo) Sentiment Analysis NLP Presenation, 06/17/2015
Sentiment Analysis D. Skrepetos 1 1 Department of Computer Science University of Waterloo NLP Presenation, 06/17/2015 D. Skrepetos (University of Waterloo) Sentiment Analysis NLP Presenation, 06/17/2015
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. ~ Spring~r
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures ~ Spring~r Table of Contents 1. Introduction.. 1 1.1. What is the World Wide Web? 1 1.2. ABrief History of the Web
Domain Adaptive Relation Extraction for Big Text Data Analytics. Feiyu Xu
 Domain Adaptive Relation Extraction for Big Text Data Analytics Feiyu Xu Outline! Introduction to relation extraction and its applications! Motivation of domain adaptation in big text data analytics! Solutions!
Domain Adaptive Relation Extraction for Big Text Data Analytics Feiyu Xu Outline! Introduction to relation extraction and its applications! Motivation of domain adaptation in big text data analytics! Solutions!