An online semi automated POS tagger for. Presented By: Pallav Kumar Dutta Indian Institute of Technology Guwahati
|
|
|
- Madison McDonald
- 8 years ago
- Views:
Transcription
1 An online semi automated POS tagger for Assamese Presented By: Pallav Kumar Dutta Indian Institute of Technology Guwahati

2 Topics Overview, Existing Taggers & Methods Basic requirements of POS Tagger Our Approach Future work References

3 Overview of POS tagging

4 Existing Taggers Rule Based - uses a set of rules & contextual info to tag a word. Stochastic Taggers Uses frequency, probability to tag a word.

5 Statistical Approaches Hidden Markov Model (HMM) Maximum Entropy Model (ME) Conditional Random Field (CRF) Memory Based Learning (MBL)
 Memory Based")
6 Basic Requirements of POS tagger Tag Set Corpus

7 Indian Langage tagset Very few are publicly available and motivated by specific research agenda IL tagset developed at IIIT Hyderabad This tagset has adopted a very coarse structure in linguistic analysis, leading to a very flat structure capturing Avoiding singular vs plural distinction, tense distinctions, and almost all the case markers except the Locative case Tag PREP used for POSTP also.

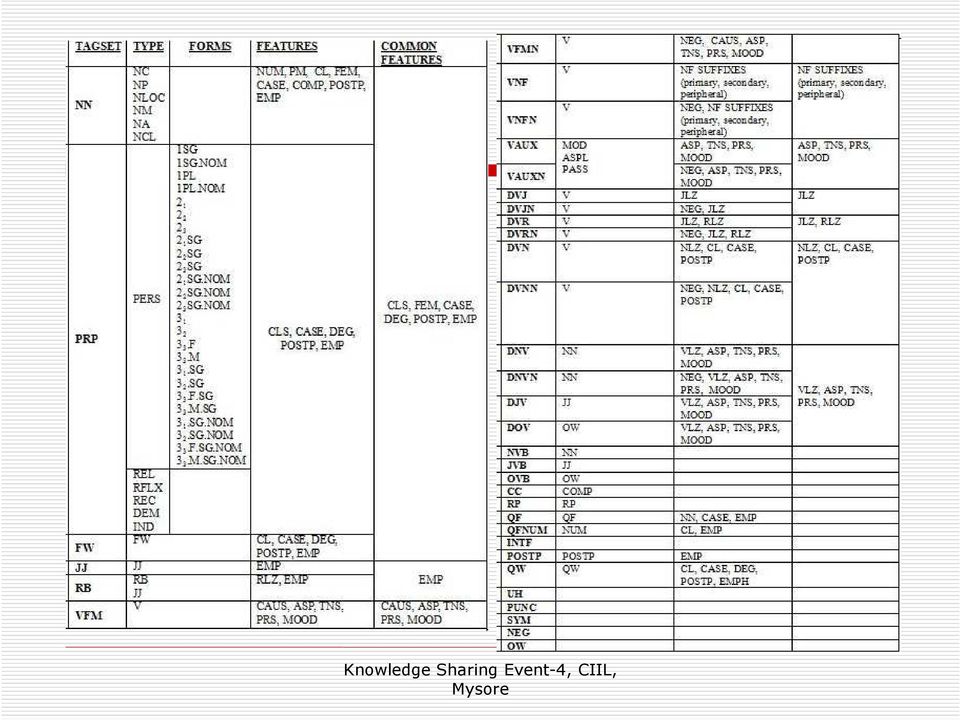
8 Assamese Tagset CC Conjunct NN Noun NVB Noun in Kriyamul PRP Pronoun PUNC Punctuation QF Quantifier QFNUM Number Quantifier QW Question Word RB Adverb RP Particle SYM Symbol UH Interjection INTF Intensifier JJ Adjective NEG Negative VAUX Verb Auxiliary VAUXN Verb Auxiliary Negative

9 Assamese Tagset.. VFM Verb Finite Main VFMN Verb Finite Main Negative VNF Verb Nonfinite VNFN Verb Nonfinite Negative JVB Adjective in Kriyamul POSTP Post Position DJV Deadjectival Verb DNV Denominal Verb DNVN Denominal Verb Negative DVJ Deverbal Adjectival DVJN Deverbal Adjectival Negative DVN Deverbal Nominal DVNN Deverbal Nominal Negative DVR Deverbal Adverbial DVRN Deverbal Adverbial Negative FW Foreign Word OVB Onomatopoetic Word in Kriyamul OW Onomatopoetic Word

10
11 Corpus Generation Unicode supported corpus Training corpus of 1860 sentences (20414 tokens/words) Collected from short stories from famous novels, news paper etc.

12 Our Approach of POS Tagger All statistical approaches require a huge training set. Rely on pattern matching of new instances with what is already available with native speakers providing verification. We have observed that providing simple aids to human improves the productivity tremendously.

13 POS tagger The online tagger. A simple tagger


14 After selecting NN, the following detail analysis page appears

15 POS Tagger Uses Database.

16 Observations Intra & inter domain effects. Sparse data problem Tested with NLTK

17 Future Work We will seek to generalize this process so that it becomes applicable to other NE Languages and we aim to create such a system for at least one more language like Bodo. Bodo training corpus contains 1571 sentences with tokens.

18 References: Fahim Hasan, N UzZaman, Mumit Khan, Comparision of Unigram, Bigram, HMM and Brill s POS Tagging Approaches for some South Asian Languages, [22] N Saharia, D das, U Sharma, Jugal Kalita, Part of Speech Tagger for Assamese Text, Proceedings of the ACL- IJCNLP 2009 Conference, pp Baskaran, S Et al., "Designing a common POS-Tagset Framework for Indian Languages", Proceedings of the 6th Workshop on Asian Language Resources (ALR 6), Hyderabad, pp. 89 Chirag Patel and Karthik Gali, Part-Of-Speech Tagging for Gujarati Using Conditional Random Fields, Proceedings of the IJCNLP-08 Workshop on NLP for Less Privileged Languages, Hyderabad, India, pages A. Dalal, K. Nagaraj, U. Swant, S. Shelke and P. Bhattacharyya, Building Feature Rich POS Tagger for Morphologically Rich Languages: Experience in Hindi. ICON. Sandipan Dandapat, Sudeshna Sarkar, Anupam Basu, Automatic Part-of-Speech Tagging for Bengali: An Approach for Morphologically Rich Languages in a Poor Resource Scenario Proceedings of the ACL 2007 Demo and Poster Sessions, pages Himanshu Agrawal, POS Tagging and Chunking for Indian Languages Proceedings of IJCAI Workshop on Shallow Parsing for South Asian Languages, Hyderabad. Avinesh PVS and Karthik G, Part-Of-Speech Tagging and Chunking Using Conditional Random Fields and Transformation Based Learning, Proceedings of IJCAI Workshop on Shallow Parsing for South Asian Languages, Hyderabad.
, Hyderabad, pp. 89 Chirag Patel and Karthik Gali, 2008.")
19 References (contd.) Delip Rao and David Yarowsky, Part Of Speech tagging and Shallow Parsing for Indian Languages, Proceedings of IJCAI Workshop on Shallow Parsing for South Asian Languages, Hyderabad. T. N Vikram and Shalini R Urs, "Development of prototype Morphological Analyzer for the South Indian Language of Kannada", Asian Digital Libraries. Looking Back 10 Years and Forging New Frontiers. PP Ms Lilabati Saikia Bora,Asamiya Bhasar Ruptattva- First Edition, January 2006,published by M/s Banalata, Panbazar Guwahati-1. (ISBN: ) Satyanath Borah- Bahal Vyakaran, April 2006 Ed, published by B.C. Barua on behalf of Gopal Barua Agency, S.B Road, Guwahati-1 Shrivastava, Agrawal, Mohapatra, Singh and Battacharya, "Morphology based Natural Language Processing tool for Indian languages", paper presented in the 4th Annual Inter Research Institute Student Seminar in Computer Science (IRISS05), April, IIT Kanpur. ( Sirajul Islam Choudhury, L. Sarbajit Singh, S. Borgohain and P. K. Das,, 2004 "Morphological Analyzer for Manipuri: Design and Implementation", Applied Computing, pp Prof. G. C. Goswami, Asamiya Vyakaran Pravesh- Second Edition, April 2003, published by M/s Bina Library, Guwahati-1. Eric Brill, A simple rule-based part of speech tagger, Proceedings of the Third Conference on Applied Natural Language Processing, pp Akshar Bharati, Vineet Chaitanya, Rajeev Sangal Computational Linguistics in India: An overview

20 Thanks

Improving statistical POS tagging using Linguistic feature for Hindi and Telugu
 Improving statistical POS tagging using Linguistic feature for Hindi and Telugu by Phani Gadde, Meher Vijay Yeleti in ICON-2008: International Conference on Natural Language Processing (ICON-2008) Report
Improving statistical POS tagging using Linguistic feature for Hindi and Telugu by Phani Gadde, Meher Vijay Yeleti in ICON-2008: International Conference on Natural Language Processing (ICON-2008) Report
UNKNOWN WORDS ANALYSIS IN POS TAGGING OF SINHALA LANGUAGE
 UNKNOWN WORDS ANALYSIS IN POS TAGGING OF SINHALA LANGUAGE A.J.P.M.P. Jayaweera #1, N.G.J. Dias *2 # Virtusa Pvt. Ltd. No 752, Dr. Danister De Silva Mawatha, Colombo 09, Sri Lanka * Department of Statistics
UNKNOWN WORDS ANALYSIS IN POS TAGGING OF SINHALA LANGUAGE A.J.P.M.P. Jayaweera #1, N.G.J. Dias *2 # Virtusa Pvt. Ltd. No 752, Dr. Danister De Silva Mawatha, Colombo 09, Sri Lanka * Department of Statistics
POS Tagsets and POS Tagging. Definition. Tokenization. Tagset Design. Automatic POS Tagging Bigram tagging. Maximum Likelihood Estimation 1 / 23
 POS Def. Part of Speech POS POS L645 POS = Assigning word class information to words Dept. of Linguistics, Indiana University Fall 2009 ex: the man bought a book determiner noun verb determiner noun 1
POS Def. Part of Speech POS POS L645 POS = Assigning word class information to words Dept. of Linguistics, Indiana University Fall 2009 ex: the man bought a book determiner noun verb determiner noun 1
BILINGUAL TRANSLATION SYSTEM
 BILINGUAL TRANSLATION SYSTEM (FOR ENGLISH AND TAMIL) Dr. S. Saraswathi Associate Professor M. Anusiya P. Kanivadhana S. Sathiya Abstract--- The project aims in developing Bilingual Translation System for
BILINGUAL TRANSLATION SYSTEM (FOR ENGLISH AND TAMIL) Dr. S. Saraswathi Associate Professor M. Anusiya P. Kanivadhana S. Sathiya Abstract--- The project aims in developing Bilingual Translation System for
Web-based Bengali News Corpus for Lexicon Development and POS Tagging
 Web-based Bengali News Corpus for Lexicon Development and POS Tagging Asif Ekbal and Sivaji Bandyopadhyay Abstract Lexicon development and Part of Speech (POS) tagging are very important for almost all
Web-based Bengali News Corpus for Lexicon Development and POS Tagging Asif Ekbal and Sivaji Bandyopadhyay Abstract Lexicon development and Part of Speech (POS) tagging are very important for almost all
PoS-tagging Italian texts with CORISTagger
 PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
PoS-tagging Italian texts with CORISTagger Fabio Tamburini DSLO, University of Bologna, Italy fabio.tamburini@unibo.it Abstract. This paper presents an evolution of CORISTagger [1], an high-performance
Part-of-Speech Tagging for Bengali
 Part-of-Speech Tagging for Bengali Thesis submitted to Indian Institute of Technology, Kharagpur for the award of the degree of Master of Science by Sandipan Dandapat Under the guidance of Prof. Sudeshna
Part-of-Speech Tagging for Bengali Thesis submitted to Indian Institute of Technology, Kharagpur for the award of the degree of Master of Science by Sandipan Dandapat Under the guidance of Prof. Sudeshna
TagMiner: A Semisupervised Associative POS Tagger E ective for Resource Poor Languages
 TagMiner: A Semisupervised Associative POS Tagger E ective for Resource Poor Languages Pratibha Rani, Vikram Pudi, and Dipti Misra Sharma International Institute of Information Technology, Hyderabad, India
TagMiner: A Semisupervised Associative POS Tagger E ective for Resource Poor Languages Pratibha Rani, Vikram Pudi, and Dipti Misra Sharma International Institute of Information Technology, Hyderabad, India
Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic
 Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic by Sigrún Helgadóttir Abstract This paper gives the results of an experiment concerned with training three different taggers on tagged
Testing Data-Driven Learning Algorithms for PoS Tagging of Icelandic by Sigrún Helgadóttir Abstract This paper gives the results of an experiment concerned with training three different taggers on tagged
Stock Market Prediction Using Data Mining
 Stock Market Prediction Using Data Mining 1 Ruchi Desai, 2 Prof.Snehal Gandhi 1 M.E., 2 M.Tech. 1 Computer Department 1 Sarvajanik College of Engineering and Technology, Surat, Gujarat, India Abstract
Stock Market Prediction Using Data Mining 1 Ruchi Desai, 2 Prof.Snehal Gandhi 1 M.E., 2 M.Tech. 1 Computer Department 1 Sarvajanik College of Engineering and Technology, Surat, Gujarat, India Abstract
IMPROVING THE QUALITY OF GUJARATI-HINDI MACHINE TRANSLATION THROUGH PART-OF- SPEECH TAGGING AND STEMMER ASSISTED TRANSLITERATION
 IMPROVING THE QUALITY OF GUJARATI-HINDI MACHINE TRANSLATION THROUGH PART-OF- SPEECH TAGGING AND STEMMER ASSISTED TRANSLITERATION Juhi Ameta 1, Nisheeth Joshi 2 and Iti Mathur 3 1 Department of Computer
IMPROVING THE QUALITY OF GUJARATI-HINDI MACHINE TRANSLATION THROUGH PART-OF- SPEECH TAGGING AND STEMMER ASSISTED TRANSLITERATION Juhi Ameta 1, Nisheeth Joshi 2 and Iti Mathur 3 1 Department of Computer
Open Domain Information Extraction. Günter Neumann, DFKI, 2012
 Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Open Domain Information Extraction Günter Neumann, DFKI, 2012 Improving TextRunner Wu and Weld (2010) Open Information Extraction using Wikipedia, ACL 2010 Fader et al. (2011) Identifying Relations for
Word Completion and Prediction in Hebrew
 Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Experiments with Language Models for בס"ד Word Completion and Prediction in Hebrew 1 Yaakov HaCohen-Kerner, Asaf Applebaum, Jacob Bitterman Department of Computer Science Jerusalem College of Technology
Why language is hard. And what Linguistics has to say about it. Natalia Silveira Participation code: eagles
 Why language is hard And what Linguistics has to say about it Natalia Silveira Participation code: eagles Christopher Natalia Silveira Manning Language processing is so easy for humans that it is like
Why language is hard And what Linguistics has to say about it Natalia Silveira Participation code: eagles Christopher Natalia Silveira Manning Language processing is so easy for humans that it is like
Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words
 , pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
, pp.290-295 http://dx.doi.org/10.14257/astl.2015.111.55 Efficient Techniques for Improved Data Classification and POS Tagging by Monitoring Extraction, Pruning and Updating of Unknown Foreign Words Irfan
Livingston Public Schools Scope and Sequence K 6 Grammar and Mechanics
 Grade and Unit Timeframe Grammar Mechanics K Unit 1 6 weeks Oral grammar naming words K Unit 2 6 weeks Oral grammar Capitalization of a Name action words K Unit 3 6 weeks Oral grammar sentences Sentence
Grade and Unit Timeframe Grammar Mechanics K Unit 1 6 weeks Oral grammar naming words K Unit 2 6 weeks Oral grammar Capitalization of a Name action words K Unit 3 6 weeks Oral grammar sentences Sentence
Special Topics in Computer Science
 Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
Special Topics in Computer Science NLP in a Nutshell CS492B Spring Semester 2009 Jong C. Park Computer Science Department Korea Advanced Institute of Science and Technology INTRODUCTION Jong C. Park, CS
Building a Question Classifier for a TREC-Style Question Answering System
 Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Building a Question Classifier for a TREC-Style Question Answering System Richard May & Ari Steinberg Topic: Question Classification We define Question Classification (QC) here to be the task that, given
Identifying Prepositional Phrases in Chinese Patent Texts with. Rule-based and CRF Methods
 Identifying Prepositional Phrases in Chinese Patent Texts with Rule-based and CRF Methods Hongzheng Li and Yaohong Jin Institute of Chinese Information Processing, Beijing Normal University 19, Xinjiekou
Identifying Prepositional Phrases in Chinese Patent Texts with Rule-based and CRF Methods Hongzheng Li and Yaohong Jin Institute of Chinese Information Processing, Beijing Normal University 19, Xinjiekou
Terminology Extraction from Log Files
 Terminology Extraction from Log Files Hassan Saneifar 1,2, Stéphane Bonniol 2, Anne Laurent 1, Pascal Poncelet 1, and Mathieu Roche 1 1 LIRMM - Université Montpellier 2 - CNRS 161 rue Ada, 34392 Montpellier
Terminology Extraction from Log Files Hassan Saneifar 1,2, Stéphane Bonniol 2, Anne Laurent 1, Pascal Poncelet 1, and Mathieu Roche 1 1 LIRMM - Université Montpellier 2 - CNRS 161 rue Ada, 34392 Montpellier
Comma checking in Danish Daniel Hardt Copenhagen Business School & Villanova University
 Comma checking in Danish Daniel Hardt Copenhagen Business School & Villanova University 1. Introduction This paper describes research in using the Brill tagger (Brill 94,95) to learn to identify incorrect
Comma checking in Danish Daniel Hardt Copenhagen Business School & Villanova University 1. Introduction This paper describes research in using the Brill tagger (Brill 94,95) to learn to identify incorrect
Automating Legal Research through Data Mining
 Automating Legal Research through Data Mining M.F.M Firdhous, Faculty of Information Technology, University of Moratuwa, Moratuwa, Sri Lanka. Mohamed.Firdhous@uom.lk Abstract The term legal research generally
Automating Legal Research through Data Mining M.F.M Firdhous, Faculty of Information Technology, University of Moratuwa, Moratuwa, Sri Lanka. Mohamed.Firdhous@uom.lk Abstract The term legal research generally
Automated Content Analysis of Discussion Transcripts
 Automated Content Analysis of Discussion Transcripts Vitomir Kovanović v.kovanovic@ed.ac.uk Dragan Gašević dgasevic@acm.org School of Informatics, University of Edinburgh Edinburgh, United Kingdom v.kovanovic@ed.ac.uk
Automated Content Analysis of Discussion Transcripts Vitomir Kovanović v.kovanovic@ed.ac.uk Dragan Gašević dgasevic@acm.org School of Informatics, University of Edinburgh Edinburgh, United Kingdom v.kovanovic@ed.ac.uk
POS Tagging 1. POS Tagging. Rule-based taggers Statistical taggers Hybrid approaches
 POS Tagging 1 POS Tagging Rule-based taggers Statistical taggers Hybrid approaches POS Tagging 1 POS Tagging 2 Words taken isolatedly are ambiguous regarding its POS Yo bajo con el hombre bajo a PP AQ
POS Tagging 1 POS Tagging Rule-based taggers Statistical taggers Hybrid approaches POS Tagging 1 POS Tagging 2 Words taken isolatedly are ambiguous regarding its POS Yo bajo con el hombre bajo a PP AQ
Customizing an English-Korean Machine Translation System for Patent Translation *
 Customizing an English-Korean Machine Translation System for Patent Translation * Sung-Kwon Choi, Young-Gil Kim Natural Language Processing Team, Electronics and Telecommunications Research Institute,
Customizing an English-Korean Machine Translation System for Patent Translation * Sung-Kwon Choi, Young-Gil Kim Natural Language Processing Team, Electronics and Telecommunications Research Institute,
Brill s rule-based PoS tagger
 Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
Beáta Megyesi Department of Linguistics University of Stockholm Extract from D-level thesis (section 3) Brill s rule-based PoS tagger Beáta Megyesi Eric Brill introduced a PoS tagger in 1992 that was based
12 FIRST QUARTER. Class Assignments
 August 7- Go over senior dates. Go over school rules. 12 FIRST QUARTER Class Assignments August 8- Overview of the course. Go over class syllabus. Handout textbooks. August 11- Part 2 Chapter 1 Parts of
August 7- Go over senior dates. Go over school rules. 12 FIRST QUARTER Class Assignments August 8- Overview of the course. Go over class syllabus. Handout textbooks. August 11- Part 2 Chapter 1 Parts of
Linguistic Knowledge-driven Approach to Chinese Comparative Elements Extraction
 Linguistic Knowledge-driven Approach to Chinese Comparative Elements Extraction Minjun Park Dept. of Chinese Language and Literature Peking University Beijing, 100871, China karmalet@163.com Yulin Yuan
Linguistic Knowledge-driven Approach to Chinese Comparative Elements Extraction Minjun Park Dept. of Chinese Language and Literature Peking University Beijing, 100871, China karmalet@163.com Yulin Yuan
Context Grammar and POS Tagging
 Context Grammar and POS Tagging Shian-jung Dick Chen Don Loritz New Technology and Research New Technology and Research LexisNexis LexisNexis Ohio, 45342 Ohio, 45342 dick.chen@lexisnexis.com don.loritz@lexisnexis.com
Context Grammar and POS Tagging Shian-jung Dick Chen Don Loritz New Technology and Research New Technology and Research LexisNexis LexisNexis Ohio, 45342 Ohio, 45342 dick.chen@lexisnexis.com don.loritz@lexisnexis.com
Accelerating and Evaluation of Syntactic Parsing in Natural Language Question Answering Systems
 Accelerating and Evaluation of Syntactic Parsing in Natural Language Question Answering Systems cation systems. For example, NLP could be used in Question Answering (QA) systems to understand users natural
Accelerating and Evaluation of Syntactic Parsing in Natural Language Question Answering Systems cation systems. For example, NLP could be used in Question Answering (QA) systems to understand users natural
Terminology Extraction from Log Files
 Terminology Extraction from Log Files Hassan Saneifar, Stéphane Bonniol, Anne Laurent, Pascal Poncelet, Mathieu Roche To cite this version: Hassan Saneifar, Stéphane Bonniol, Anne Laurent, Pascal Poncelet,
Terminology Extraction from Log Files Hassan Saneifar, Stéphane Bonniol, Anne Laurent, Pascal Poncelet, Mathieu Roche To cite this version: Hassan Saneifar, Stéphane Bonniol, Anne Laurent, Pascal Poncelet,
Natural Language Processing
 Natural Language Processing 2 Open NLP (http://opennlp.apache.org/) Java library for processing natural language text Based on Machine Learning tools maximum entropy, perceptron Includes pre-built models
Natural Language Processing 2 Open NLP (http://opennlp.apache.org/) Java library for processing natural language text Based on Machine Learning tools maximum entropy, perceptron Includes pre-built models
LINGSTAT: AN INTERACTIVE, MACHINE-AIDED TRANSLATION SYSTEM*
 LINGSTAT: AN INTERACTIVE, MACHINE-AIDED TRANSLATION SYSTEM* Jonathan Yamron, James Baker, Paul Bamberg, Haakon Chevalier, Taiko Dietzel, John Elder, Frank Kampmann, Mark Mandel, Linda Manganaro, Todd Margolis,
LINGSTAT: AN INTERACTIVE, MACHINE-AIDED TRANSLATION SYSTEM* Jonathan Yamron, James Baker, Paul Bamberg, Haakon Chevalier, Taiko Dietzel, John Elder, Frank Kampmann, Mark Mandel, Linda Manganaro, Todd Margolis,
Learning Morphological Disambiguation Rules for Turkish
 Learning Morphological Disambiguation Rules for Turkish Deniz Yuret Dept. of Computer Engineering Koç University İstanbul, Turkey dyuret@ku.edu.tr Ferhan Türe Dept. of Computer Engineering Koç University
Learning Morphological Disambiguation Rules for Turkish Deniz Yuret Dept. of Computer Engineering Koç University İstanbul, Turkey dyuret@ku.edu.tr Ferhan Türe Dept. of Computer Engineering Koç University
A Primer on Text Analytics
 A Primer on Text Analytics From the Perspective of a Statistics Graduate Student Bradley Turnbull Statistical Learning Group North Carolina State University March 27, 2015 Bradley Turnbull Text Analytics
A Primer on Text Analytics From the Perspective of a Statistics Graduate Student Bradley Turnbull Statistical Learning Group North Carolina State University March 27, 2015 Bradley Turnbull Text Analytics
Search and Data Mining: Techniques. Text Mining Anya Yarygina Boris Novikov
 Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Search and Data Mining: Techniques Text Mining Anya Yarygina Boris Novikov Introduction Generally used to denote any system that analyzes large quantities of natural language text and detects lexical or
Automatic Knowledge Base Construction Systems. Dr. Daisy Zhe Wang CISE Department University of Florida September 3th 2014
 Automatic Knowledge Base Construction Systems Dr. Daisy Zhe Wang CISE Department University of Florida September 3th 2014 1 Text Contains Knowledge 2 Text Contains Automatically Extractable Knowledge 3
Automatic Knowledge Base Construction Systems Dr. Daisy Zhe Wang CISE Department University of Florida September 3th 2014 1 Text Contains Knowledge 2 Text Contains Automatically Extractable Knowledge 3
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System
 Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Architecture of an Ontology-Based Domain- Specific Natural Language Question Answering System Athira P. M., Sreeja M. and P. C. Reghuraj Department of Computer Science and Engineering, Government Engineering
Automatic induction of a PoS tagset for Italian
 Automatic induction of a PoS tagset for Italian R. Bernardi 1, A. Bolognesi 2, C. Seidenari 2, F. Tamburini 2 1 Free University of Bozen-Bolzano, 2 CILTA University of Bologna 1. Project: Italian Corpus
Automatic induction of a PoS tagset for Italian R. Bernardi 1, A. Bolognesi 2, C. Seidenari 2, F. Tamburini 2 1 Free University of Bozen-Bolzano, 2 CILTA University of Bologna 1. Project: Italian Corpus
Using classes has the potential of reducing the problem of sparseness of data by allowing generalizations
 POS Tags and Decision Trees for Language Modeling Peter A. Heeman Department of Computer Science and Engineering Oregon Graduate Institute PO Box 91000, Portland OR 97291 heeman@cse.ogi.edu Abstract Language
POS Tags and Decision Trees for Language Modeling Peter A. Heeman Department of Computer Science and Engineering Oregon Graduate Institute PO Box 91000, Portland OR 97291 heeman@cse.ogi.edu Abstract Language
SENTIMENT ANALYSIS: A STUDY ON PRODUCT FEATURES
 University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations and Theses from the College of Business Administration Business Administration, College of 4-1-2012 SENTIMENT
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations and Theses from the College of Business Administration Business Administration, College of 4-1-2012 SENTIMENT
Quality Assurance of Automatic Annotation of Very Large Corpora: a Study based on Heterogeneous Tagging Systems
 Quality Assurance of Automatic Annotation of Very Large Corpora: a Study based on Heterogeneous Tagging Systems Chu-Ren Huang 1, Lung-Hao Lee 1, Wei-guang Qu 2, Jia-Fei Hong 1, Shiwen Yu 2 1 Institute
Quality Assurance of Automatic Annotation of Very Large Corpora: a Study based on Heterogeneous Tagging Systems Chu-Ren Huang 1, Lung-Hao Lee 1, Wei-guang Qu 2, Jia-Fei Hong 1, Shiwen Yu 2 1 Institute
Semantic annotation of requirements for automatic UML class diagram generation
 www.ijcsi.org 259 Semantic annotation of requirements for automatic UML class diagram generation Soumaya Amdouni 1, Wahiba Ben Abdessalem Karaa 2 and Sondes Bouabid 3 1 University of tunis High Institute
www.ijcsi.org 259 Semantic annotation of requirements for automatic UML class diagram generation Soumaya Amdouni 1, Wahiba Ben Abdessalem Karaa 2 and Sondes Bouabid 3 1 University of tunis High Institute
We have recently developed a video database
 Qibin Sun Infocomm Research A Natural Language-Based Interface for Querying a Video Database Onur Küçüktunç, Uğur Güdükbay, Özgür Ulusoy Bilkent University We have recently developed a video database system,
Qibin Sun Infocomm Research A Natural Language-Based Interface for Querying a Video Database Onur Küçüktunç, Uğur Güdükbay, Özgür Ulusoy Bilkent University We have recently developed a video database system,
10th Grade Language. Goal ISAT% Objective Description (with content limits) Vocabulary Words
 Vocabulary Words") Standard 3: Writing Process 3.1: Prewrite 58-69% 10.LA.3.1.2 Generate a main idea or thesis appropriate to a type of writing. (753.02.b) Items may include a specified purpose, audience, and writing outline.
Standard 3: Writing Process 3.1: Prewrite 58-69% 10.LA.3.1.2 Generate a main idea or thesis appropriate to a type of writing. (753.02.b) Items may include a specified purpose, audience, and writing outline.
Shallow Parsing with PoS Taggers and Linguistic Features
 Journal of Machine Learning Research 2 (2002) 639 668 Submitted 9/01; Published 3/02 Shallow Parsing with PoS Taggers and Linguistic Features Beáta Megyesi Centre for Speech Technology (CTT) Department
Journal of Machine Learning Research 2 (2002) 639 668 Submitted 9/01; Published 3/02 Shallow Parsing with PoS Taggers and Linguistic Features Beáta Megyesi Centre for Speech Technology (CTT) Department
Symbiosis of Evolutionary Techniques and Statistical Natural Language Processing
 1 Symbiosis of Evolutionary Techniques and Statistical Natural Language Processing Lourdes Araujo Dpto. Sistemas Informáticos y Programación, Univ. Complutense, Madrid 28040, SPAIN (email: lurdes@sip.ucm.es)
1 Symbiosis of Evolutionary Techniques and Statistical Natural Language Processing Lourdes Araujo Dpto. Sistemas Informáticos y Programación, Univ. Complutense, Madrid 28040, SPAIN (email: lurdes@sip.ucm.es)
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures 123 11 Opinion Mining In Chap. 9, we studied structured data extraction from Web pages. Such data are usually records
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures 123 11 Opinion Mining In Chap. 9, we studied structured data extraction from Web pages. Such data are usually records
English Grammar Checker
 International l Journal of Computer Sciences and Engineering Open Access Review Paper Volume-4, Issue-3 E-ISSN: 2347-2693 English Grammar Checker Pratik Ghosalkar 1*, Sarvesh Malagi 2, Vatsal Nagda 3,
International l Journal of Computer Sciences and Engineering Open Access Review Paper Volume-4, Issue-3 E-ISSN: 2347-2693 English Grammar Checker Pratik Ghosalkar 1*, Sarvesh Malagi 2, Vatsal Nagda 3,
NLP Programming Tutorial 5 - Part of Speech Tagging with Hidden Markov Models
 NLP Programming Tutorial 5 - Part of Speech Tagging with Hidden Markov Models Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Part of Speech (POS) Tagging Given a sentence X, predict its
NLP Programming Tutorial 5 - Part of Speech Tagging with Hidden Markov Models Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Part of Speech (POS) Tagging Given a sentence X, predict its
Tagging with Hidden Markov Models
 Tagging with Hidden Markov Models Michael Collins 1 Tagging Problems In many NLP problems, we would like to model pairs of sequences. Part-of-speech (POS) tagging is perhaps the earliest, and most famous,
Tagging with Hidden Markov Models Michael Collins 1 Tagging Problems In many NLP problems, we would like to model pairs of sequences. Part-of-speech (POS) tagging is perhaps the earliest, and most famous,
A Mixed Trigrams Approach for Context Sensitive Spell Checking
 A Mixed Trigrams Approach for Context Sensitive Spell Checking Davide Fossati and Barbara Di Eugenio Department of Computer Science University of Illinois at Chicago Chicago, IL, USA dfossa1@uic.edu, bdieugen@cs.uic.edu
A Mixed Trigrams Approach for Context Sensitive Spell Checking Davide Fossati and Barbara Di Eugenio Department of Computer Science University of Illinois at Chicago Chicago, IL, USA dfossa1@uic.edu, bdieugen@cs.uic.edu
BENCHMARKING ARCHITEKTUR WYSOKIEJ WYDAJNOŚCI ALGORYTMAMI PRZETWARZANIA JĘZYKA NATURALNEGO
 Computer Science Vol. 12 2011 Marcin Kuta, Jacek Kitowski BENCHMARKING HIGH PERFORMANCE ARCHITECTURES WITH NATURAL LANGUAGE PROCESSING ALGORITHMS Natural Language Processing algorithms are resource demanding,
Computer Science Vol. 12 2011 Marcin Kuta, Jacek Kitowski BENCHMARKING HIGH PERFORMANCE ARCHITECTURES WITH NATURAL LANGUAGE PROCESSING ALGORITHMS Natural Language Processing algorithms are resource demanding,
Shallow Parsing with Apache UIMA
 Shallow Parsing with Apache UIMA Graham Wilcock University of Helsinki Finland graham.wilcock@helsinki.fi Abstract Apache UIMA (Unstructured Information Management Architecture) is a framework for linguistic
Shallow Parsing with Apache UIMA Graham Wilcock University of Helsinki Finland graham.wilcock@helsinki.fi Abstract Apache UIMA (Unstructured Information Management Architecture) is a framework for linguistic
A POS-based Word Prediction System for the Persian Language
 A POS-based Word Prediction System for the Persian Language Masood Ghayoomi 1 Ehsan Daroodi 2 1 Nancy 2 University, Nancy, France masood29@gmail.com 2 Iran National Science Foundation, Tehran, Iran darrudi@insf.org
A POS-based Word Prediction System for the Persian Language Masood Ghayoomi 1 Ehsan Daroodi 2 1 Nancy 2 University, Nancy, France masood29@gmail.com 2 Iran National Science Foundation, Tehran, Iran darrudi@insf.org
GRASP: Grammar- and Syntax-based Pattern-Finder for Collocation and Phrase Learning
 PACLIC 24 Proceedings 357 GRASP: Grammar- and Syntax-based Pattern-Finder for Collocation and Phrase Learning Mei-hua Chen a, Chung-chi Huang a, Shih-ting Huang b, and Jason S. Chang b a Institute of Information
PACLIC 24 Proceedings 357 GRASP: Grammar- and Syntax-based Pattern-Finder for Collocation and Phrase Learning Mei-hua Chen a, Chung-chi Huang a, Shih-ting Huang b, and Jason S. Chang b a Institute of Information
MORPHOLOGY BASED PROTOTYPE STATISTICAL MACHINE TRANSLATION SYSTEM FOR ENGLISH TO TAMIL LANGUAGE
 MORPHOLOGY BASED PROTOTYPE STATISTICAL MACHINE TRANSLATION SYSTEM FOR ENGLISH TO TAMIL LANGUAGE A Thesis Submitted for the Degree of Doctor of Philosophy in the School of Engineering by ANAND KUMAR M CENTER
MORPHOLOGY BASED PROTOTYPE STATISTICAL MACHINE TRANSLATION SYSTEM FOR ENGLISH TO TAMIL LANGUAGE A Thesis Submitted for the Degree of Doctor of Philosophy in the School of Engineering by ANAND KUMAR M CENTER
How to make Ontologies self-building from Wiki-Texts
 How to make Ontologies self-building from Wiki-Texts Bastian HAARMANN, Frederike GOTTSMANN, and Ulrich SCHADE Fraunhofer Institute for Communication, Information Processing & Ergonomics Neuenahrer Str.
How to make Ontologies self-building from Wiki-Texts Bastian HAARMANN, Frederike GOTTSMANN, and Ulrich SCHADE Fraunhofer Institute for Communication, Information Processing & Ergonomics Neuenahrer Str.
EAP 1161 1660 Grammar Competencies Levels 1 6
 EAP 1161 1660 Grammar Competencies Levels 1 6 Grammar Committee Representatives: Marcia Captan, Maria Fallon, Ira Fernandez, Myra Redman, Geraldine Walker Developmental Editor: Cynthia M. Schuemann Approved:
EAP 1161 1660 Grammar Competencies Levels 1 6 Grammar Committee Representatives: Marcia Captan, Maria Fallon, Ira Fernandez, Myra Redman, Geraldine Walker Developmental Editor: Cynthia M. Schuemann Approved:
stress, intonation and pauses and pronounce English sounds correctly. (b) To speak accurately to the listener(s) about one s thoughts and feelings,
 To speak accurately to the listener(s) about one s thoughts and feelings,") Section 9 Foreign Languages I. OVERALL OBJECTIVE To develop students basic communication abilities such as listening, speaking, reading and writing, deepening their understanding of language and culture
Section 9 Foreign Languages I. OVERALL OBJECTIVE To develop students basic communication abilities such as listening, speaking, reading and writing, deepening their understanding of language and culture
Master Degree Project Ideas (Fall 2014) Proposed By Faculty Department of Information Systems College of Computer Sciences and Information Technology
 Proposed By Faculty Department of Information Systems College of Computer Sciences and Information Technology") Master Degree Project Ideas (Fall 2014) Proposed By Faculty Department of Information Systems College of Computer Sciences and Information Technology 1 P age Dr. Maruf Hasan MS CIS Program Potential Project
Master Degree Project Ideas (Fall 2014) Proposed By Faculty Department of Information Systems College of Computer Sciences and Information Technology 1 P age Dr. Maruf Hasan MS CIS Program Potential Project
Effectiveness of Domain Adaptation Approaches for Social Media PoS Tagging
 Effectiveness of Domain Adaptation Approaches for Social Media PoS Tagging Tobias Horsmann, Torsten Zesch Language Technology Lab Department of Computer Science and Applied Cognitive Science University
Effectiveness of Domain Adaptation Approaches for Social Media PoS Tagging Tobias Horsmann, Torsten Zesch Language Technology Lab Department of Computer Science and Applied Cognitive Science University
Transformational Generative Grammar for Various Types of Bengali Sentences
 UT tudies, Vol. 12, No. 1, 2010; P:99-105 Transformational Generative Grammar for Various Types of Bengali entences Mohammad Reza elim 1 and Muhammed Zafar Iqbal 1 1 Department of Computer cience and Engineering,
UT tudies, Vol. 12, No. 1, 2010; P:99-105 Transformational Generative Grammar for Various Types of Bengali entences Mohammad Reza elim 1 and Muhammed Zafar Iqbal 1 1 Department of Computer cience and Engineering,
Towards a RB-SMT Hybrid System for Translating Patent Claims Results and Perspectives
 Towards a RB-SMT Hybrid System for Translating Patent Claims Results and Perspectives Ramona Enache and Adam Slaski Department of Computer Science and Engineering Chalmers University of Technology and
Towards a RB-SMT Hybrid System for Translating Patent Claims Results and Perspectives Ramona Enache and Adam Slaski Department of Computer Science and Engineering Chalmers University of Technology and
AUTOMATIC DATABASE CONSTRUCTION FROM NATURAL LANGUAGE REQUIREMENTS SPECIFICATION TEXT
 AUTOMATIC DATABASE CONSTRUCTION FROM NATURAL LANGUAGE REQUIREMENTS SPECIFICATION TEXT Geetha S. 1 and Anandha Mala G. S. 2 1 JNTU Hyderabad, Telangana, India 2 St. Joseph s College of Engineering, Chennai,
AUTOMATIC DATABASE CONSTRUCTION FROM NATURAL LANGUAGE REQUIREMENTS SPECIFICATION TEXT Geetha S. 1 and Anandha Mala G. S. 2 1 JNTU Hyderabad, Telangana, India 2 St. Joseph s College of Engineering, Chennai,
Training and evaluation of POS taggers on the French MULTITAG corpus
 Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Left-Brain/Right-Brain Multi-Document Summarization
 Left-Brain/Right-Brain Multi-Document Summarization John M. Conroy IDA/Center for Computing Sciences conroy@super.org Jade Goldstein Department of Defense jgstewa@afterlife.ncsc.mil Judith D. Schlesinger
Left-Brain/Right-Brain Multi-Document Summarization John M. Conroy IDA/Center for Computing Sciences conroy@super.org Jade Goldstein Department of Defense jgstewa@afterlife.ncsc.mil Judith D. Schlesinger
Discovering suffixes: A Case Study for Marathi Language
 Discovering suffixes: A Case Study for Marathi Language Mudassar M. Majgaonker Comviva Technologies Limited Gurgaon, India Abstract Suffix stripping is a pre-processing step required in a number of natural
Discovering suffixes: A Case Study for Marathi Language Mudassar M. Majgaonker Comviva Technologies Limited Gurgaon, India Abstract Suffix stripping is a pre-processing step required in a number of natural
The Specific Text Analysis Tasks at the Beginning of MDA Life Cycle
 SCIENTIFIC PAPERS, UNIVERSITY OF LATVIA, 2010. Vol. 757 COMPUTER SCIENCE AND INFORMATION TECHNOLOGIES 11 22 P. The Specific Text Analysis Tasks at the Beginning of MDA Life Cycle Armands Šlihte Faculty
SCIENTIFIC PAPERS, UNIVERSITY OF LATVIA, 2010. Vol. 757 COMPUTER SCIENCE AND INFORMATION TECHNOLOGIES 11 22 P. The Specific Text Analysis Tasks at the Beginning of MDA Life Cycle Armands Šlihte Faculty
The Transition of Phrase based to Factored based Translation for Tamil language in SMT Systems
 The Transition of Phrase based to Factored based Translation for Tamil language in SMT Systems Dr. Ananthi Sheshasaayee 1, Angela Deepa. V.R 2 1 Research Supervisior, Department of Computer Science & Application,
The Transition of Phrase based to Factored based Translation for Tamil language in SMT Systems Dr. Ananthi Sheshasaayee 1, Angela Deepa. V.R 2 1 Research Supervisior, Department of Computer Science & Application,
The parts of speech: the basic labels
 CHAPTER 1 The parts of speech: the basic labels The Western traditional parts of speech began with the works of the Greeks and then the Romans. The Greek tradition culminated in the first century B.C.
CHAPTER 1 The parts of speech: the basic labels The Western traditional parts of speech began with the works of the Greeks and then the Romans. The Greek tradition culminated in the first century B.C.
ARABIC PERSON NAMES RECOGNITION BY USING A RULE BASED APPROACH
 Journal of Computer Science 9 (7): 922-927, 2013 ISSN: 1549-3636 2013 doi:10.3844/jcssp.2013.922.927 Published Online 9 (7) 2013 (http://www.thescipub.com/jcs.toc) ARABIC PERSON NAMES RECOGNITION BY USING
Journal of Computer Science 9 (7): 922-927, 2013 ISSN: 1549-3636 2013 doi:10.3844/jcssp.2013.922.927 Published Online 9 (7) 2013 (http://www.thescipub.com/jcs.toc) ARABIC PERSON NAMES RECOGNITION BY USING
Index. 344 Grammar and Language Workbook, Grade 8
 Index Index 343 Index A A, an (usage), 8, 123 A, an, the (articles), 8, 123 diagraming, 205 Abbreviations, correct use of, 18 19, 273 Abstract nouns, defined, 4, 63 Accept, except, 12, 227 Action verbs,
Index Index 343 Index A A, an (usage), 8, 123 A, an, the (articles), 8, 123 diagraming, 205 Abbreviations, correct use of, 18 19, 273 Abstract nouns, defined, 4, 63 Accept, except, 12, 227 Action verbs,
Log-Linear Models. Michael Collins
 Log-Linear Models Michael Collins 1 Introduction This note describes log-linear models, which are very widely used in natural language processing. A key advantage of log-linear models is their flexibility:
Log-Linear Models Michael Collins 1 Introduction This note describes log-linear models, which are very widely used in natural language processing. A key advantage of log-linear models is their flexibility:
Adjectives and Adverbs. Lecture 9
 Adjectives and Adverbs Lecture 9 Identifying adjectives an attribute of a noun, e.g. cold weather, large windows, violent storms, etc. -able/ible; -al; -ful, etc., e.g. achievable/ illegible; functional;
Adjectives and Adverbs Lecture 9 Identifying adjectives an attribute of a noun, e.g. cold weather, large windows, violent storms, etc. -able/ible; -al; -ful, etc., e.g. achievable/ illegible; functional;
LuitPad: A fully Unicode compatible Assamese writing software
 LuitPad: A fully Unicode compatible Assamese writing software Navanath Saharia 1,3 Kishori M Konwar 2,3 (1) Tezpur University, Tezpur, Assam, India (2) University of British Columbia, Vancouver, Canada
LuitPad: A fully Unicode compatible Assamese writing software Navanath Saharia 1,3 Kishori M Konwar 2,3 (1) Tezpur University, Tezpur, Assam, India (2) University of British Columbia, Vancouver, Canada
Criterion SM Online Essay Evaluation: An Application for Automated Evaluation of Student Essays
 Criterion SM Online Essay Evaluation: An Application for Automated Evaluation of Student Essays Jill Burstein Educational Testing Service Rosedale Road, 18E Princeton, NJ 08541 jburstein@ets.org Martin
Criterion SM Online Essay Evaluation: An Application for Automated Evaluation of Student Essays Jill Burstein Educational Testing Service Rosedale Road, 18E Princeton, NJ 08541 jburstein@ets.org Martin
The Design of a Proofreading Software Service
 The Design of a Proofreading Software Service Raphael Mudge Automattic Washington, DC 20036 raffi@automattic.com Abstract Web applications have the opportunity to check spelling, style, and grammar using
The Design of a Proofreading Software Service Raphael Mudge Automattic Washington, DC 20036 raffi@automattic.com Abstract Web applications have the opportunity to check spelling, style, and grammar using
Chapter 8. Final Results on Dutch Senseval-2 Test Data
 Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
Chapter 8 Final Results on Dutch Senseval-2 Test Data The general idea of testing is to assess how well a given model works and that can only be done properly on data that has not been seen before. Supervised
MONITORING URBAN TRAFFIC STATUS USING TWITTER MESSAGES
 MONITORING URBAN TRAFFIC STATUS USING TWITTER MESSAGES FATMA AMIN ELSAFOURY February, 2013 SUPERVISORS: Dr. UlanbekTurdukulov Dr. Rob Lemmens Monitoring Urban Traffic Status Using Twitter Messages FATMA
MONITORING URBAN TRAFFIC STATUS USING TWITTER MESSAGES FATMA AMIN ELSAFOURY February, 2013 SUPERVISORS: Dr. UlanbekTurdukulov Dr. Rob Lemmens Monitoring Urban Traffic Status Using Twitter Messages FATMA
From Terminology Extraction to Terminology Validation: An Approach Adapted to Log Files
 Journal of Universal Computer Science, vol. 21, no. 4 (2015), 604-635 submitted: 22/11/12, accepted: 26/3/15, appeared: 1/4/15 J.UCS From Terminology Extraction to Terminology Validation: An Approach Adapted
Journal of Universal Computer Science, vol. 21, no. 4 (2015), 604-635 submitted: 22/11/12, accepted: 26/3/15, appeared: 1/4/15 J.UCS From Terminology Extraction to Terminology Validation: An Approach Adapted
PyCantonese: Cantonese linguistic research in the age of big data
 PyCantonese: Cantonese linguistic research in the age of big data Jackson L. Lee University of Chicago http://jacksonllee.com Childhood Bilingualism Research Center, CUHK September 15, 2015 Grammar versus
PyCantonese: Cantonese linguistic research in the age of big data Jackson L. Lee University of Chicago http://jacksonllee.com Childhood Bilingualism Research Center, CUHK September 15, 2015 Grammar versus
Correlation: ELLIS. English language Learning and Instruction System. and the TOEFL. Test Of English as a Foreign Language
 Correlation: English language Learning and Instruction System and the TOEFL Test Of English as a Foreign Language Structure (Grammar) A major aspect of the ability to succeed on the TOEFL examination is
Correlation: English language Learning and Instruction System and the TOEFL Test Of English as a Foreign Language Structure (Grammar) A major aspect of the ability to succeed on the TOEFL examination is
Syntax: Phrases. 1. The phrase
 Syntax: Phrases Sentences can be divided into phrases. A phrase is a group of words forming a unit and united around a head, the most important part of the phrase. The head can be a noun NP, a verb VP,
Syntax: Phrases Sentences can be divided into phrases. A phrase is a group of words forming a unit and united around a head, the most important part of the phrase. The head can be a noun NP, a verb VP,
Efficient Data Integration in Finding Ailment-Treatment Relation
 IJCST Vo l. 3, Is s u e 3, Ju l y - Se p t 2012 ISSN : 0976-8491 (Online) ISSN : 2229-4333 (Print) Efficient Data Integration in Finding Ailment-Treatment Relation 1 A. Nageswara Rao, 2 G. Venu Gopal,
IJCST Vo l. 3, Is s u e 3, Ju l y - Se p t 2012 ISSN : 0976-8491 (Online) ISSN : 2229-4333 (Print) Efficient Data Integration in Finding Ailment-Treatment Relation 1 A. Nageswara Rao, 2 G. Venu Gopal,
English Language Proficiency Standards: At A Glance February 19, 2014
 English Language Proficiency Standards: At A Glance February 19, 2014 These English Language Proficiency (ELP) Standards were collaboratively developed with CCSSO, West Ed, Stanford University Understanding
English Language Proficiency Standards: At A Glance February 19, 2014 These English Language Proficiency (ELP) Standards were collaboratively developed with CCSSO, West Ed, Stanford University Understanding
Effective Self-Training for Parsing
 Effective Self-Training for Parsing David McClosky dmcc@cs.brown.edu Brown Laboratory for Linguistic Information Processing (BLLIP) Joint work with Eugene Charniak and Mark Johnson David McClosky - dmcc@cs.brown.edu
Effective Self-Training for Parsing David McClosky dmcc@cs.brown.edu Brown Laboratory for Linguistic Information Processing (BLLIP) Joint work with Eugene Charniak and Mark Johnson David McClosky - dmcc@cs.brown.edu
Writing Common Core KEY WORDS
 Writing Common Core KEY WORDS An educator's guide to words frequently used in the Common Core State Standards, organized by grade level in order to show the progression of writing Common Core vocabulary
Writing Common Core KEY WORDS An educator's guide to words frequently used in the Common Core State Standards, organized by grade level in order to show the progression of writing Common Core vocabulary
C o p yr i g ht 2015, S A S I nstitute Inc. A l l r i g hts r eser v ed. INTRODUCTION TO SAS TEXT MINER
 INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
INTRODUCTION TO SAS TEXT MINER TODAY S AGENDA INTRODUCTION TO SAS TEXT MINER Define data mining Overview of SAS Enterprise Miner Describe text analytics and define text data mining Text Mining Process
Experiments in Cross-Language Morphological Annotation Transfer
 Experiments in Cross-Language Morphological Annotation Transfer Anna Feldman, Jirka Hana, and Chris Brew Ohio State University, Department of Linguistics, Columbus, OH 43210-1298, USA Abstract. Annotated
Experiments in Cross-Language Morphological Annotation Transfer Anna Feldman, Jirka Hana, and Chris Brew Ohio State University, Department of Linguistics, Columbus, OH 43210-1298, USA Abstract. Annotated
Example-based Translation without Parallel Corpora: First experiments on a prototype
 -based Translation without Parallel Corpora: First experiments on a prototype Vincent Vandeghinste, Peter Dirix and Ineke Schuurman Centre for Computational Linguistics Katholieke Universiteit Leuven Maria
-based Translation without Parallel Corpora: First experiments on a prototype Vincent Vandeghinste, Peter Dirix and Ineke Schuurman Centre for Computational Linguistics Katholieke Universiteit Leuven Maria
Submission guidelines for authors and editors
 Submission guidelines for authors and editors For the benefit of production efficiency and the production of texts of the highest quality and consistency, we urge you to follow the enclosed submission
Submission guidelines for authors and editors For the benefit of production efficiency and the production of texts of the highest quality and consistency, we urge you to follow the enclosed submission
Points of Interference in Learning English as a Second Language
 Points of Interference in Learning English as a Second Language Tone Spanish: In both English and Spanish there are four tone levels, but Spanish speaker use only the three lower pitch tones, except when
Points of Interference in Learning English as a Second Language Tone Spanish: In both English and Spanish there are four tone levels, but Spanish speaker use only the three lower pitch tones, except when
Phase 2 of the D4 Project. Helmut Schmid and Sabine Schulte im Walde
 Statistical Verb-Clustering Model soft clustering: Verbs may belong to several clusters trained on verb-argument tuples clusters together verbs with similar subcategorization and selectional restriction
Statistical Verb-Clustering Model soft clustering: Verbs may belong to several clusters trained on verb-argument tuples clusters together verbs with similar subcategorization and selectional restriction
Markus Dickinson. Dept. of Linguistics, Indiana University Catapult Workshop Series; February 1, 2013
 Markus Dickinson Dept. of Linguistics, Indiana University Catapult Workshop Series; February 1, 2013 1 / 34 Basic text analysis Before any sophisticated analysis, we want ways to get a sense of text data
Markus Dickinson Dept. of Linguistics, Indiana University Catapult Workshop Series; February 1, 2013 1 / 34 Basic text analysis Before any sophisticated analysis, we want ways to get a sense of text data
Language Lessons. Secondary Child
 Scope & Sequence for Language Lessons for the Secondary Child by Sandi Queen Queen Homeschool Supplies, Inc. Lesson 1: Picture Study and Narration Lesson 2: Creative Writing Lesson 3-5: For Copywork Lesson
Scope & Sequence for Language Lessons for the Secondary Child by Sandi Queen Queen Homeschool Supplies, Inc. Lesson 1: Picture Study and Narration Lesson 2: Creative Writing Lesson 3-5: For Copywork Lesson
Albert Pye and Ravensmere Schools Grammar Curriculum
 Albert Pye and Ravensmere Schools Grammar Curriculum Introduction The aim of our schools own grammar curriculum is to ensure that all relevant grammar content is introduced within the primary years in
Albert Pye and Ravensmere Schools Grammar Curriculum Introduction The aim of our schools own grammar curriculum is to ensure that all relevant grammar content is introduced within the primary years in
CINTIL-PropBank. CINTIL-PropBank Sub-corpus id Sentences Tokens Domain Sentences for regression atsts 779 5,654 Test
 CINTIL-PropBank I. Basic Information 1.1. Corpus information The CINTIL-PropBank (Branco et al., 2012) is a set of sentences annotated with their constituency structure and semantic role tags, composed
CINTIL-PropBank I. Basic Information 1.1. Corpus information The CINTIL-PropBank (Branco et al., 2012) is a set of sentences annotated with their constituency structure and semantic role tags, composed
Level 1 Teacher s Manual
 TABLE OF CONTENTS Lesson Study Skills Unit Page 1 STUDY SKILLS. Introduce study skills. Use a Quigley story to discuss study skills. 1 2 STUDY SKILLS. Introduce getting organized. Use a Quigley story to
TABLE OF CONTENTS Lesson Study Skills Unit Page 1 STUDY SKILLS. Introduce study skills. Use a Quigley story to discuss study skills. 1 2 STUDY SKILLS. Introduce getting organized. Use a Quigley story to
Lesson Plan. Date(s)... M Tu W Th F
... M Tu W Th F") Grade...Class(es)... Lesson 12.1 Adjectives SE/TWE pp. 451 452 Objectives: To identify predicate adjectives and adjectives that precede nouns; to use adjectives correctly to describe nouns and pronouns
Grade...Class(es)... Lesson 12.1 Adjectives SE/TWE pp. 451 452 Objectives: To identify predicate adjectives and adjectives that precede nouns; to use adjectives correctly to describe nouns and pronouns