A Tutorial Introduc/on to Big Data. Hands On Data Analy/cs over EMR. Robert Grossman University of Chicago Open Data Group
|
|
|
- Sheila Paulina Cunningham
- 8 years ago
- Views:
Transcription
1 A Tutorial Introduc/on to Big Data Hands On Data Analy/cs over EMR Robert Grossman University of Chicago Open Data Group Collin BenneE Open Data Group November 12,

2 Amazon AWS Elas/c MapReduce allows for MapReduce jobs to run over the Amazon Elas/c Cloud Infrastructure with minimal setup.

3 Running Custom Jobs Elas/c Map Reduce allows for different types of jobs to be run Streaming allows Anything which handles Standard I/O Lets you mix and match languages, shell scripts, etc.

4 Choose a Language(s) The Streaming Interface of Elas/c Map Reduce lets us use different languages for each step of the job. Choose wisely Pick a language that fits the task For the examples, Python for both Maps One reducer is in R, the other in Python

5 tutorials.opendatagroup.com

6 Create a Job

7 Example 1 MapReduce Job to read in data and build plots to help with Exploratory Data Analysis Data is already in S3 Output will be wrieen to HDFS

8 Example 2 MapReduce Job to read in data and build models in PMML: Data is already in S3 Output will be wrieen to HDFS

9 Amazon Hadoop Streaming Job Applica/on

10 Set up Job Parameters
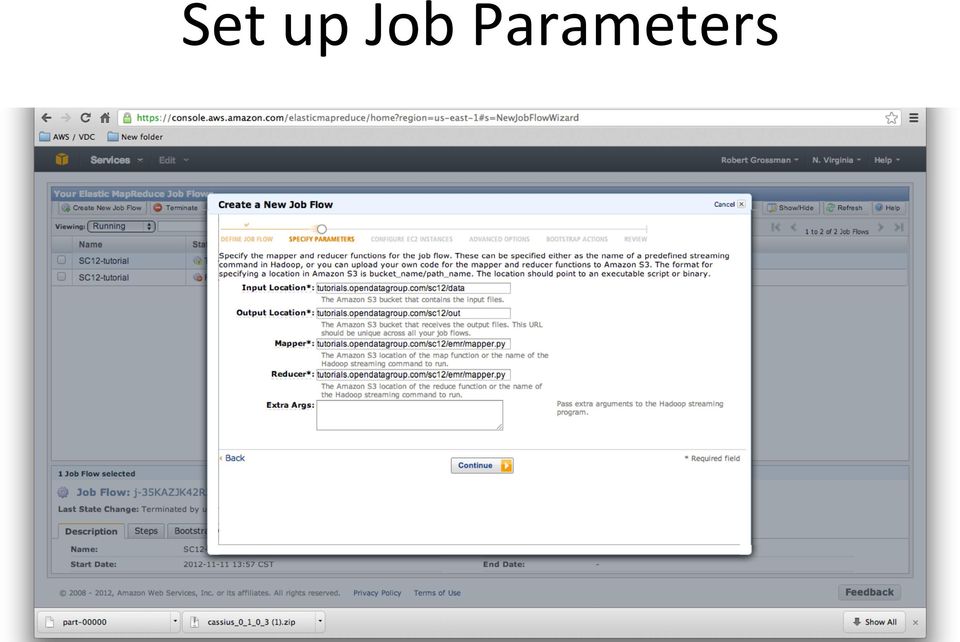
11 Values INPUT OUTPUT MAPPER REDUCER EXTRA ARGS tutorials.opendatagroup.com/ sc12/data tutorials.opendatagroup.com/ sc12/out tutorials.opendatagroup.com/ sc12/emr/mapper.py tutorials.opendatagroup.com/ sc12/emr/reducer-plots.py

12 Instance Types and Count

13 Machine Access and S3 Logs

14 SSH Access If you do not specify an EC2 keypair, then you cannot log into the nodes. If everything works, this is usually not necessary

15 Logging If you specify the Amazon S3 log path, then the standard Hadoop logging will be wrieen to the S3 bucket of your choice This directory must exist This is helpful ever if everything works as you can learn things about the job

16 Bootstrap
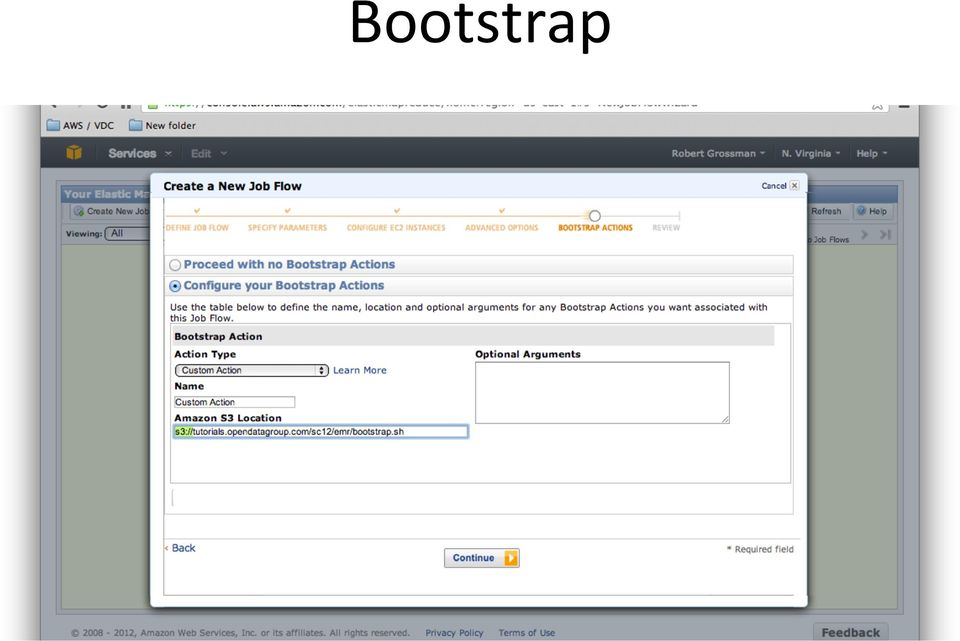
17 Bootstrap If you do not specify a bootstrap, you get the vanilla version of EMR. If you want to add any packages, run any ini/aliza/on scripts, etc, you have to do it with a bootstrap ac/on EMR offers canned bootstraps We run a custom ac/on

18 Job Summary

19 Let the Magic Happen

20 Check on Instances under EC2

21 Machine Access You can ssh into the master node if you specified an EC2 keypair during configura/on To access a slave node, 1. scp the EC2 keypair to them master node 2. ssh into the master node 3. ssh into the slave node using the EC2 keypair ssh i <path_to_key>/<key> hadoop@<ip>
22 Text- browser JobTracker Access from Master Node
23 Job Output The job we ran is the Exploratory Data Analysis (EDA) Step It generates plots as SVG files of the data The SVG plots are wrieen to HDFS SVG images are xml, not binary (With the same bootstrap and mapper, we can run a job to build models in PMML)
24 Each reducer producers a part- * file
25 Images are in the Files
26 Extrac/ng Images Depending on how many keys and reducers you have, there will be 0, 1, or more svg plots in each output file 1. Download each part- * 2. To check how many images are in a file: grep <svg part wc l If there is only one, rename to part svg If there is more than one, split the file up in your favorite text editor
27 View in a Web Browser
28 EDA Job Details While we wait for your job to finish
29 Shuffle and Sort Map output across all mappers is shuffled so that Like Keys are sent to a single reducer Map output is sorted so that all output with a key k is seen as a con/guous group. This is done behind the scenes for you by the MapReduce framework
30 Map 1. Read line- by- line 2. Parse each record Prune unwanted fields Perform data transforma/ons Select fields to be the Key Value Values are sent out over Standard I/O, so everything is a string
31 Reduce 1. Aggregate records by key 2. Perform any reduc/on steps Compute running sta/s/cs or necessary metadata Store in an efficient data structure Perform the analy/cs on the aggregated group Values are sent out over Standard I/O to the HDFS, so everything is a string
32 Code You do not need to set up Job configura/on in the code, all that is handled for you by the framework. This means that very liele code is necessary
33 Code - Map #!/usr/bin/env python import sys import time if name == " main ": for line in sys.stdin.xreadlines(): route, date, daytype, rides = line.rstrip().split(",") weekday = time.strftime("%a", time.strptime(date, "%m/%d/%y")) sys.stdout.write("%s-%s\t%s,%s\n" % (route, weekday, date, rides))
34 Code - Map #!/usr/bin/env python import sys import time Iterate over each line if name == " main ": for line in sys.stdin.xreadlines(): route, date, daytype, rides = line.rstrip().split(",") weekday = time.strftime("%a", time.strptime(date, "%m/%d/%y")) sys.stdout.write("%s-%s\t%s,%s\n" % (route, weekday, date, rides))
35 Code - Map #!/usr/bin/env python import sys import time Parse the line if name == " main ": for line in sys.stdin.xreadlines(): route, date, daytype, rides = line.rstrip().split(",") weekday = time.strftime("%a", time.strptime(date, "%m/%d/%y")) sys.stdout.write("%s-%s\t%s,%s\n" % (route, weekday, date, rides))
36 Code - Map #!/usr/bin/env python import sys import time Transform Data if name == " main ": for line in sys.stdin.xreadlines(): route, date, daytype, rides = line.rstrip().split(",") weekday = time.strftime("%a", time.strptime(date, "%m/%d/%y")) sys.stdout.write("%s-%s\t%s,%s\n" % (route, weekday, date, rides))
37 Code - Map #!/usr/bin/env python import sys import time Emit a key, value pair if name == " main ": for line in sys.stdin.xreadlines(): route, date, daytype, rides = line.rstrip().split(",") weekday = time.strftime("%a", time.strptime(date, "%m/%d/%y")) sys.stdout.write("%s-%s\t%s,%s\n" % (route, weekday, date, rides))
38 Reduce - Plots 1. Aggregate Events 2. Calculate the Mean We calculate a running mean so that the events do not have to be held in memory Trade off Does the amount of RAM required to hold all events for one key push the available limits? Can running sta/s/cs be safely computed? Build SVG plot using Cassius Values are sent to HDFS over Standard I/O
39 Reduce - Models 1. Aggregate Events 2. Calculate the Mean We calculate a running mean so that the events do not have to be held in memory Trade off Does the amount of RAM required to hold all events for one key push the available limits? Can running sta/s/cs be safely computed? Build PMML model using Augustus Values are sent to HDFS over Standard I/O
40 Model MapReduce Par//on Model Segment Events and sta/s/cs collected in the reducer are used to constructed a model describing the segment Each Bus Route Day of the Week combina/on gets a Gaussian Distribu/on with a mean and variance to predict rider volume
41 PMML Template for our Model from augustus.core.xmlbase import load import augustus.core.pmml41 as pmml # the segment is validated as PMML on load segment = load(""" <Segment> <SimplePredicate field="segment" operator="equal" value="zero"/> <BaselineModel functionname="regression"> <MiningSchema> <MiningField usagetype="active" name="rides" /> </MiningSchema> <TestDistributions field="rides" teststatistic="zvalue"> <Baseline> <GaussianDistribution mean="0" variance="1" /> </Baseline> </TestDistributions> </BaselineModel> </Segment> """, pmml.pmml)
42 Code Reducer PMML from augustus.core.xmlbase import load import augustus.core.pmml41 as pmml Use Augustus to validate template # the segment is validated as PMML on load segment = load(""" <Segment> <SimplePredicate field="segment" operator="equal" value="zero"/> <BaselineModel functionname="regression"> <MiningSchema> <MiningField usagetype="active" name="rides" /> </MiningSchema> <TestDistributions field="rides" teststatistic="zvalue"> <Baseline> <GaussianDistribution mean="0" variance="1" /> </Baseline> </TestDistributions> </BaselineModel> </Segment> """, pmml.pmml)
43 Code Reducer PMML from augustus.core.xmlbase import load import augustus.core.pmml41 as pmml Template is a hard code string # the segment is validated as PMML on load segment = load(""" <Segment> <SimplePredicate field="segment" operator="equal" value="zero"/> <BaselineModel functionname="regression"> <MiningSchema> <MiningField usagetype="active" name="rides" /> </MiningSchema> <TestDistributions field="rides" teststatistic="zvalue"> <Baseline> <GaussianDistribution mean="0" variance="1" /> </Baseline> </TestDistributions> </BaselineModel> </Segment> """, pmml.pmml)
44 Code Reducer PMML from augustus.core.xmlbase import load import augustus.core.pmml41 as pmml Segment predicate is the Par//on Key # the segment is validated as PMML on load segment = load(""" <Segment> <SimplePredicate field="segment" operator="equal" value="zero"/> <BaselineModel functionname="regression"> <MiningSchema> <MiningField usagetype="active" name="rides" /> </MiningSchema> <TestDistributions field="rides" teststatistic="zvalue"> <Baseline> <GaussianDistribution mean="0" variance="1" /> </Baseline> </TestDistributions> </BaselineModel> </Segment> """, pmml.pmml)
45 Code Reducer PMML def doany(v, date, rides): v["count"] += 1 diff = rides - v["mean"] incr = alpha * diff v["mean"] += incr v["varn"] = (1. - alpha)*(v["varn ] + diff*incr) Accumulate Step
46 Code Reducer PMML def dolast(v): if v["count"] > 1: variance = v["varn"] * v["count"] / (v["count"] - 1.) else: variance = v["varn"] v["gaussiandistribution"]["mean"] = v["mean"] v["gaussiandistribution"]["variance"] = variance v["partialsum"].attrib = {"COUNT": v["count"], "RUNMEAN": v["mean"], "RUNSN": v["varn"]} print v["segment"].xml() Write out Model
47 Code Reducer PMML def dolast(v): if v["count"] > 1: variance = v["varn"] * v["count"] / (v["count"] - 1.) else: variance = v["varn"] v["gaussiandistribution"]["mean"] = v["mean"] v["gaussiandistribution"]["variance"] = variance v["partialsum"].attrib = {"COUNT": v["count"], "RUNMEAN": v["mean"], "RUNSN": v["varn"]} print v["segment"].xml() Calculate values to fill in the template
48 Code Reducer PMML def dolast(v): if v["count"] > 1: variance = v["varn"] * v["count"] / (v["count"] - 1.) else: variance = v["varn"] v["gaussiandistribution"]["mean"] = v["mean"] v["gaussiandistribution"]["variance"] = variance v["partialsum"].attrib = {"COUNT": v["count"], "RUNMEAN": v["mean"], "RUNSN": v["varn"]} print v["segment"].xml() Fill them in
49 Code Reducer PMML def dolast(v): if v["count"] > 1: variance = v["varn"] * v["count"] / (v["count"] - 1.) else: variance = v["varn"] v["gaussiandistribution"]["mean"] = v["mean"] v["gaussiandistribution"]["variance"] = variance v["partialsum"].attrib = {"COUNT": v["count"], "RUNMEAN": v["mean"], "RUNSN": v["varn"]} print v["segment"].xml() Write model to HDFS
50 PMML PMML is the leading standard for sta/s/cal and data mining models Version 4.1 includes support for mul/ple models, such as segmented models and ensembles of models It allows for models to expressed as XML- compliant, portable documents
51 PMML in the HDFS output
52 Ques/ons? For the most recent version of these slides, please see tutorials.opendatagroup.com
CSE 344 Introduction to Data Management. Section 9: AWS, Hadoop, Pig Latin TA: Yi-Shu Wei
 CSE 344 Introduction to Data Management Section 9: AWS, Hadoop, Pig Latin TA: Yi-Shu Wei Homework 8 Big Data analysis on billion triple dataset using Amazon Web Service (AWS) Billion Triple Set: contains
CSE 344 Introduction to Data Management Section 9: AWS, Hadoop, Pig Latin TA: Yi-Shu Wei Homework 8 Big Data analysis on billion triple dataset using Amazon Web Service (AWS) Billion Triple Set: contains
Getting Started with Hadoop with Amazon s Elastic MapReduce
 Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson scott@drskippy.net http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Getting Started with Hadoop with Amazon s Elastic MapReduce Scott Hendrickson scott@drskippy.net http://drskippy.net/projects/emr-hadoopmeetup.pdf Boulder/Denver Hadoop Meetup 8 July 2010 Scott Hendrickson
Introduction to analyzing big data using Amazon Web Services
 Introduction to analyzing big data using Amazon Web Services This tutorial accompanies the BARC seminar given at Whitehead on January 31, 2013. It contains instructions for: 1. Getting started with Amazon
Introduction to analyzing big data using Amazon Web Services This tutorial accompanies the BARC seminar given at Whitehead on January 31, 2013. It contains instructions for: 1. Getting started with Amazon
CS 378 Big Data Programming. Lecture 5 Summariza9on Pa:erns
 CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
CS 378 Big Data Programming Lecture 5 Summariza9on Pa:erns Review Assignment 2 Ques9ons? If you d like to use guava (Google collec9ons classes) pom.xml available for assignment 2 Includes dependency for
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hunk & Elas=c MapReduce: Big Data Analy=cs on AWS
 Copyright 2014 Splunk Inc. Hunk & Elas=c MapReduce: Big Data Analy=cs on AWS Dritan Bi=ncka BD Solu=ons Architecture Disclaimer During the course of this presenta=on, we may make forward looking statements
Copyright 2014 Splunk Inc. Hunk & Elas=c MapReduce: Big Data Analy=cs on AWS Dritan Bi=ncka BD Solu=ons Architecture Disclaimer During the course of this presenta=on, we may make forward looking statements
MapReduce, Hadoop and Amazon AWS
 MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
MapReduce, Hadoop and Amazon AWS Yasser Ganjisaffar http://www.ics.uci.edu/~yganjisa February 2011 What is Hadoop? A software framework that supports data-intensive distributed applications. It enables
Cloud Computing. Chapter 8. 8.1 Hadoop
 Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Chapter 8 Cloud Computing In cloud computing, the idea is that a large corporation that has many computers could sell time on them, for example to make profitable use of excess capacity. The typical customer
Best Prac?ces for Building and Deploying Predic?ve Models Over Big Data
 Best Prac?ces for Building and Deploying Predic?ve Models Over Big Data Robert Grossman Open Data Group & Univ. of Chicago Collin Benne= Open Data Group October 23, 2012 1. Introduc?on 2. Building Predic?ve
Best Prac?ces for Building and Deploying Predic?ve Models Over Big Data Robert Grossman Open Data Group & Univ. of Chicago Collin Benne= Open Data Group October 23, 2012 1. Introduc?on 2. Building Predic?ve
Sriram Krishnan, Ph.D. sriram@sdsc.edu
 Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Sriram Krishnan, Ph.D. sriram@sdsc.edu (Re-)Introduction to cloud computing Introduction to the MapReduce and Hadoop Distributed File System Programming model Examples of MapReduce Where/how to run MapReduce
Extreme Computing. Hadoop MapReduce in more detail. www.inf.ed.ac.uk
 Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
Extreme Computing Hadoop MapReduce in more detail How will I actually learn Hadoop? This class session Hadoop: The Definitive Guide RTFM There is a lot of material out there There is also a lot of useless
COURSE CONTENT Big Data and Hadoop Training
 COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
COURSE CONTENT Big Data and Hadoop Training 1. Meet Hadoop Data! Data Storage and Analysis Comparison with Other Systems RDBMS Grid Computing Volunteer Computing A Brief History of Hadoop Apache Hadoop
Using RDBMS, NoSQL or Hadoop?
 Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Using RDBMS, NoSQL or Hadoop? DOAG Conference 2015 Jean- Pierre Dijcks Big Data Product Management Server Technologies Copyright 2014 Oracle and/or its affiliates. All rights reserved. Data Ingest 2 Ingest
Data Intensive Computing Handout 5 Hadoop
 Data Intensive Computing Handout 5 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Data Intensive Computing Handout 5 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Hands-on Exercises with Big Data
 Hands-on Exercises with Big Data Lab Sheet 1: Getting Started with MapReduce and Hadoop The aim of this exercise is to learn how to begin creating MapReduce programs using the Hadoop Java framework. In
Hands-on Exercises with Big Data Lab Sheet 1: Getting Started with MapReduce and Hadoop The aim of this exercise is to learn how to begin creating MapReduce programs using the Hadoop Java framework. In
CS 378 Big Data Programming. Lecture 2 Map- Reduce
 CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
CS 378 Big Data Programming Lecture 2 Map- Reduce MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is processed But viewed in small increments
Open source Google-style large scale data analysis with Hadoop
 Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Open source Google-style large scale data analysis with Hadoop Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory School of Electrical
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
FREE computing using Amazon EC2
 FREE computing using Amazon EC2 Seong-Hwan Jun 1 1 Department of Statistics Univ of British Columbia Nov 1st, 2012 / Student seminar Outline Basics of servers Amazon EC2 Setup R on an EC2 instance Stat
FREE computing using Amazon EC2 Seong-Hwan Jun 1 1 Department of Statistics Univ of British Columbia Nov 1st, 2012 / Student seminar Outline Basics of servers Amazon EC2 Setup R on an EC2 instance Stat
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Big Data and Scripting map/reduce in Hadoop
 Big Data and Scripting map/reduce in Hadoop 1, 2, parts of a Hadoop map/reduce implementation core framework provides customization via indivudual map and reduce functions e.g. implementation in mongodb
Big Data and Scripting map/reduce in Hadoop 1, 2, parts of a Hadoop map/reduce implementation core framework provides customization via indivudual map and reduce functions e.g. implementation in mongodb
PassTest. Bessere Qualität, bessere Dienstleistungen!
 PassTest Bessere Qualität, bessere Dienstleistungen! Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce
PassTest Bessere Qualität, bessere Dienstleistungen! Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce
Data Intensive Computing Handout 6 Hadoop
 Data Intensive Computing Handout 6 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Data Intensive Computing Handout 6 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Introduc)on to Hadoop
on to Hadoop") Introduc)on to Hadoop Slides compiled from: Introduc)on to MapReduce and Hadoop Shivnath Babu Experiences with Hadoop and MapReduce Jian Wen Word Count over a Given Set of Web Pages see bob throw see spot
Introduc)on to Hadoop Slides compiled from: Introduc)on to MapReduce and Hadoop Shivnath Babu Experiences with Hadoop and MapReduce Jian Wen Word Count over a Given Set of Web Pages see bob throw see spot
CS 378 Big Data Programming
 CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
CS 378 Big Data Programming Lecture 2 Map- Reduce CS 378 - Fall 2015 Big Data Programming 1 MapReduce Large data sets are not new What characterizes a problem suitable for MR? Most or all of the data is
Hadoop Setup. 1 Cluster
 In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
In order to use HadoopUnit (described in Sect. 3.3.3), a Hadoop cluster needs to be setup. This cluster can be setup manually with physical machines in a local environment, or in the cloud. Creating a
Introduction To Hive
 Introduction To Hive How to use Hive in Amazon EC2 CS 341: Project in Mining Massive Data Sets Hyung Jin(Evion) Kim Stanford University References: Cloudera Tutorials, CS345a session slides, Hadoop - The
Introduction To Hive How to use Hive in Amazon EC2 CS 341: Project in Mining Massive Data Sets Hyung Jin(Evion) Kim Stanford University References: Cloudera Tutorials, CS345a session slides, Hadoop - The
How To Use Hadoop
 Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
Hadoop in Action Justin Quan March 15, 2011 Poll What s to come Overview of Hadoop for the uninitiated How does Hadoop work? How do I use Hadoop? How do I get started? Final Thoughts Key Take Aways Hadoop
MapReduce Détails Optimisation de la phase Reduce avec le Combiner
 MapReduce Détails Optimisation de la phase Reduce avec le Combiner S'il est présent, le framework insère le Combiner dans la pipeline de traitement sur les noeuds qui viennent de terminer la phase Map.
MapReduce Détails Optimisation de la phase Reduce avec le Combiner S'il est présent, le framework insère le Combiner dans la pipeline de traitement sur les noeuds qui viennent de terminer la phase Map.
Matchmaking in the Cloud: Amazon EC2 and Apache Hadoop at eharmony
 Matchmaking in the Cloud: Amazon EC2 and Apache Hadoop at eharmony Speaker logo centered below image Steve Kuo, Software Architect Joshua Tuberville, Software Architect Goal > Leverage EC2 and Hadoop to
Matchmaking in the Cloud: Amazon EC2 and Apache Hadoop at eharmony Speaker logo centered below image Steve Kuo, Software Architect Joshua Tuberville, Software Architect Goal > Leverage EC2 and Hadoop to
Cloud Computing. AWS a practical example. Hugo Pérez UPC. Mayo 2012
 Cloud Computing AWS a practical example Mayo 2012 Hugo Pérez UPC -2- Index Introduction Infraestructure Development and Results Conclusions Introduction In order to know deeper about AWS services, mapreduce
Cloud Computing AWS a practical example Mayo 2012 Hugo Pérez UPC -2- Index Introduction Infraestructure Development and Results Conclusions Introduction In order to know deeper about AWS services, mapreduce
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
map/reduce connected components
 1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
1, map/reduce connected components find connected components with analogous algorithm: map edges randomly to partitions (k subgraphs of n nodes) for each partition remove edges, so that only tree remains
University of Maryland. Tuesday, February 2, 2010
 Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #2 Hadoop: Nuts and Bolts Jimmy Lin University of Maryland Tuesday, February 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Hadoop Data Warehouse Manual
 Ruben Vervaeke & Jonas Lesy 1 Hadoop Data Warehouse Manual To start off, we d like to advise you to read the thesis written about this project before applying any changes to the setup! The thesis can be
Ruben Vervaeke & Jonas Lesy 1 Hadoop Data Warehouse Manual To start off, we d like to advise you to read the thesis written about this project before applying any changes to the setup! The thesis can be
How to Run Spark Application
 How to Run Spark Application Junghoon Kang Contents 1 Intro 2 2 How to Install Spark on a Local Machine? 2 2.1 On Ubuntu 14.04.................................... 2 3 How to Run Spark Application on a
How to Run Spark Application Junghoon Kang Contents 1 Intro 2 2 How to Install Spark on a Local Machine? 2 2.1 On Ubuntu 14.04.................................... 2 3 How to Run Spark Application on a
Data Intensive Computing Handout 4 Hadoop
 Data Intensive Computing Handout 4 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Data Intensive Computing Handout 4 Hadoop Hadoop 1.2.1 is installed in /HADOOP directory. The JobTracker web interface is available at http://dlrc:50030, the NameNode web interface is available at http://dlrc:50070.
Important Notice. (c) 2010-2013 Cloudera, Inc. All rights reserved.
 2010-2013 Cloudera, Inc. All rights reserved.") Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Hue 2 User Guide Important Notice (c) 2010-2013 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in this document
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Amazon Web Services (AWS) Setup Guidelines
 Setup Guidelines") Amazon Web Services (AWS) Setup Guidelines For CSE6242 HW3, updated version of the guidelines by Diana Maclean [Estimated time needed: 1 hour] Note that important steps are highlighted in yellow. What
Amazon Web Services (AWS) Setup Guidelines For CSE6242 HW3, updated version of the guidelines by Diana Maclean [Estimated time needed: 1 hour] Note that important steps are highlighted in yellow. What
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment
 CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
CS380 Final Project Evaluating the Scalability of Hadoop in a Real and Virtual Environment James Devine December 15, 2008 Abstract Mapreduce has been a very successful computational technique that has
10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming
: Naive Bayes using Hadoop Streaming") 10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming Due: Friday, Feb. 21, 2014 23:59 EST via Autolab Late submission with 50% credit: Sunday, Feb. 23, 2014 23:59 EST via Autolab Policy on Collaboration
10605 BigML Assignment 4(a): Naive Bayes using Hadoop Streaming Due: Friday, Feb. 21, 2014 23:59 EST via Autolab Late submission with 50% credit: Sunday, Feb. 23, 2014 23:59 EST via Autolab Policy on Collaboration
Introduc)on to. Eric Nagler 11/15/11
on to. Eric Nagler 11/15/11") Introduc)on to Eric Nagler 11/15/11 What is Oozie? Oozie is a workflow scheduler for Hadoop Originally, designed at Yahoo! for their complex search engine workflows Now it is an open- source Apache incubator
Introduc)on to Eric Nagler 11/15/11 What is Oozie? Oozie is a workflow scheduler for Hadoop Originally, designed at Yahoo! for their complex search engine workflows Now it is an open- source Apache incubator
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster. A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech
 OIT/ART, Georgia Tech") Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
Extreme computing lab exercises Session one
 Extreme computing lab exercises Session one Michail Basios (m.basios@sms.ed.ac.uk) Stratis Viglas (sviglas@inf.ed.ac.uk) 1 Getting started First you need to access the machine where you will be doing all
Extreme computing lab exercises Session one Michail Basios (m.basios@sms.ed.ac.uk) Stratis Viglas (sviglas@inf.ed.ac.uk) 1 Getting started First you need to access the machine where you will be doing all
Hadoop WordCount Explained! IT332 Distributed Systems
 Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
Hadoop WordCount Explained! IT332 Distributed Systems Typical problem solved by MapReduce Read a lot of data Map: extract something you care about from each record Shuffle and Sort Reduce: aggregate, summarize,
HDFS. Hadoop Distributed File System
 HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
HDFS Kevin Swingler Hadoop Distributed File System File system designed to store VERY large files Streaming data access Running across clusters of commodity hardware Resilient to node failure 1 Large files
Introduc)on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu
on to the MapReduce Paradigm and Apache Hadoop. Sriram Krishnan sriram@sdsc.edu") Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan sriram@sdsc.edu Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Introduc)on to the MapReduce Paradigm and Apache Hadoop Sriram Krishnan sriram@sdsc.edu Programming Model The computa)on takes a set of input key/ value pairs, and Produces a set of output key/value pairs.
Hadoop Installation MapReduce Examples Jake Karnes
 Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
Big Data Management Hadoop Installation MapReduce Examples Jake Karnes These slides are based on materials / slides from Cloudera.com Amazon.com Prof. P. Zadrozny's Slides Prerequistes You must have an
Big Data Frameworks: Scala and Spark Tutorial
 Big Data Frameworks: Scala and Spark Tutorial 13.03.2015 Eemil Lagerspetz, Ella Peltonen Professor Sasu Tarkoma These slides: http://is.gd/bigdatascala www.cs.helsinki.fi Functional Programming Functional
Big Data Frameworks: Scala and Spark Tutorial 13.03.2015 Eemil Lagerspetz, Ella Peltonen Professor Sasu Tarkoma These slides: http://is.gd/bigdatascala www.cs.helsinki.fi Functional Programming Functional
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Hadoop Parallel Data Processing
 MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
MapReduce and Implementation Hadoop Parallel Data Processing Kai Shen A programming interface (two stage Map and Reduce) and system support such that: the interface is easy to program, and suitable for
How To Write A Map In Java (Java) On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer
 On A Microsoft Powerbook 2.5 (Ahem) On An Ipa (Aeso) Or Ipa 2.4 (Aseo) On Your Computer Or Your Computer") Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Lab 0 - Introduction to Hadoop/Eclipse/Map/Reduce CSE 490h - Winter 2007 To Do 1. Eclipse plug in introduction Dennis Quan, IBM 2. Read this hand out. 3. Get Eclipse set up on your machine. 4. Load the
Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Обработка больших данных: Map Reduce (Python) + Hadoop (Streaming) Максим Щербаков ВолгГТУ 8/10/2014
 + Hadoop (Streaming) Максим Щербаков ВолгГТУ 8/10/2014") Обработка больших данных: Map Reduce (Python) + Hadoop (Streaming) Максим Щербаков ВолгГТУ 8/10/2014 1 Содержание Бигдайта: распределенные вычисления и тренды MapReduce: концепция и примеры реализации
Обработка больших данных: Map Reduce (Python) + Hadoop (Streaming) Максим Щербаков ВолгГТУ 8/10/2014 1 Содержание Бигдайта: распределенные вычисления и тренды MapReduce: концепция и примеры реализации
Big Data Primer. 1 Why Big Data? Alex Sverdlov alex@theparticle.com
 Big Data Primer Alex Sverdlov alex@theparticle.com 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Big Data Primer Alex Sverdlov alex@theparticle.com 1 Why Big Data? Data has value. This immediately leads to: more data has more value, naturally causing datasets to grow rather large, even at small companies.
Single Node Hadoop Cluster Setup
 Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
Single Node Hadoop Cluster Setup This document describes how to create Hadoop Single Node cluster in just 30 Minutes on Amazon EC2 cloud. You will learn following topics. Click Here to watch these steps
YARN and how MapReduce works in Hadoop By Alex Holmes
 YARN and how MapReduce works in Hadoop By Alex Holmes YARN was created so that Hadoop clusters could run any type of work. This meant MapReduce had to become a YARN application and required the Hadoop
YARN and how MapReduce works in Hadoop By Alex Holmes YARN was created so that Hadoop clusters could run any type of work. This meant MapReduce had to become a YARN application and required the Hadoop
The Hadoop Eco System Shanghai Data Science Meetup
 The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
The Hadoop Eco System Shanghai Data Science Meetup Karthik Rajasethupathy, Christian Kuka 03.11.2015 @Agora Space Overview What is this talk about? Giving an overview of the Hadoop Ecosystem and related
http://www.wordle.net/
 Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Hadoop & MapReduce http://www.wordle.net/ http://www.wordle.net/ Hadoop is an open-source software framework (or platform) for Reliable + Scalable + Distributed Storage/Computational unit Failures completely
Map Reduce & Hadoop Recommended Text:
 Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Big Data Map Reduce & Hadoop Recommended Text:! Large datasets are becoming more common The New York Stock Exchange generates about one terabyte of new trade data per day. Facebook hosts approximately
Cloudera Manager Training: Hands-On Exercises
 201408 Cloudera Manager Training: Hands-On Exercises General Notes... 2 In- Class Preparation: Accessing Your Cluster... 3 Self- Study Preparation: Creating Your Cluster... 4 Hands- On Exercise: Working
201408 Cloudera Manager Training: Hands-On Exercises General Notes... 2 In- Class Preparation: Accessing Your Cluster... 3 Self- Study Preparation: Creating Your Cluster... 4 Hands- On Exercise: Working
The MapReduce Framework
 The MapReduce Framework Luke Tierney Department of Statistics & Actuarial Science University of Iowa November 8, 2007 Luke Tierney (U. of Iowa) The MapReduce Framework November 8, 2007 1 / 16 Background
The MapReduce Framework Luke Tierney Department of Statistics & Actuarial Science University of Iowa November 8, 2007 Luke Tierney (U. of Iowa) The MapReduce Framework November 8, 2007 1 / 16 Background
High Performance Computing with Hadoop WV HPC Summer Institute 2014
 High Performance Computing with Hadoop WV HPC Summer Institute 2014 E. James Harner Director of Data Science Department of Statistics West Virginia University June 18, 2014 Outline Introduction Hadoop
High Performance Computing with Hadoop WV HPC Summer Institute 2014 E. James Harner Director of Data Science Department of Statistics West Virginia University June 18, 2014 Outline Introduction Hadoop
HDFS Cluster Installation Automation for TupleWare
 HDFS Cluster Installation Automation for TupleWare Xinyi Lu Department of Computer Science Brown University Providence, RI 02912 xinyi_lu@brown.edu March 26, 2014 Abstract TupleWare[1] is a C++ Framework
HDFS Cluster Installation Automation for TupleWare Xinyi Lu Department of Computer Science Brown University Providence, RI 02912 xinyi_lu@brown.edu March 26, 2014 Abstract TupleWare[1] is a C++ Framework
Getting to know Apache Hadoop
 Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Getting to know Apache Hadoop Oana Denisa Balalau Télécom ParisTech October 13, 2015 1 / 32 Table of Contents 1 Apache Hadoop 2 The Hadoop Distributed File System(HDFS) 3 Application management in the
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Tutorial for Assignment 2.0 Florian Klien & Christian Körner IMPORTANT The presented information has been tested on the following operating systems Mac OS X 10.6 Ubuntu Linux The installation on Windows
Hadoop 2.6.0 Setup Walkthrough
 Hadoop 2.6.0 Setup Walkthrough This document provides information about working with Hadoop 2.6.0. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
Hadoop 2.6.0 Setup Walkthrough This document provides information about working with Hadoop 2.6.0. 1 Setting Up Configuration Files... 2 2 Setting Up The Environment... 2 3 Additional Notes... 3 4 Selecting
HADOOP MOCK TEST HADOOP MOCK TEST II
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
Tes$ng Hadoop Applica$ons. Tom Wheeler
 Tes$ng Hadoop Applica$ons Tom Wheeler About The Presenter Tom Wheeler Software Engineer, etc.! Greater St. Louis Area Information Technology and Services! Current:! Past:! Senior Curriculum Developer at
Tes$ng Hadoop Applica$ons Tom Wheeler About The Presenter Tom Wheeler Software Engineer, etc.! Greater St. Louis Area Information Technology and Services! Current:! Past:! Senior Curriculum Developer at
Hadoop 2.6 Configuration and More Examples
 Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
Hadoop 2.6 Configuration and More Examples Big Data 2015 Apache Hadoop & YARN Apache Hadoop (1.X)! De facto Big Data open source platform Running for about 5 years in production at hundreds of companies
HiBench Introduction. Carson Wang (carson.wang@intel.com) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Introduc8on to Apache Spark
 Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Introduc8on to Apache Spark Jordan Volz, Systems Engineer @ Cloudera 1 Analyzing Data on Large Data Sets Python, R, etc. are popular tools among data scien8sts/analysts, sta8s8cians, etc. Why are these
Step 4: Configure a new Hadoop server This perspective will add a new snap-in to your bottom pane (along with Problems and Tasks), like so:
, like so:") Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Codelab 1 Introduction to the Hadoop Environment (version 0.17.0) Goals: 1. Set up and familiarize yourself with the Eclipse plugin 2. Run and understand a word counting program Setting up Eclipse: Step
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Introduction to Cloud Computing
 Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Introduction to Cloud Computing Qloud Demonstration 15 319, spring 2010 3 rd Lecture, Jan 19 th Suhail Rehman Time to check out the Qloud! Enough Talk! Time for some Action! Finally you can have your own
Tutorial for Assignment 2.0
 Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Tutorial for Assignment 2.0 Web Science and Web Technology Summer 2012 Slides based on last years tutorials by Chris Körner, Philipp Singer 1 Review and Motivation Agenda Assignment Information Introduction
Data Processing Solutions - A Case Study
 Sector & Sphere Exploring Data Parallelism and Locality in Wide Area Networks Yunhong Gu Univ. of Illinois at Chicago Robert Grossman Univ. of Illinois at Chicago and Open Data Group Overview Cloud Computing
Sector & Sphere Exploring Data Parallelism and Locality in Wide Area Networks Yunhong Gu Univ. of Illinois at Chicago Robert Grossman Univ. of Illinois at Chicago and Open Data Group Overview Cloud Computing
A Cost-Evaluation of MapReduce Applications in the Cloud
 1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
1/23 A Cost-Evaluation of MapReduce Applications in the Cloud Diana Moise, Alexandra Carpen-Amarie Gabriel Antoniu, Luc Bougé KerData team 2/23 1 MapReduce applications - case study 2 3 4 5 3/23 MapReduce
Open source large scale distributed data management with Google s MapReduce and Bigtable
 Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
Open source large scale distributed data management with Google s MapReduce and Bigtable Ioannis Konstantinou Email: ikons@cslab.ece.ntua.gr Web: http://www.cslab.ntua.gr/~ikons Computing Systems Laboratory
A bit about Hadoop. Luca Pireddu. March 9, 2012. CRS4Distributed Computing Group. luca.pireddu@crs4.it (CRS4) Luca Pireddu March 9, 2012 1 / 18
 Luca Pireddu March 9, 2012 1 / 18") A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 luca.pireddu@crs4.it (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
A bit about Hadoop Luca Pireddu CRS4Distributed Computing Group March 9, 2012 luca.pireddu@crs4.it (CRS4) Luca Pireddu March 9, 2012 1 / 18 Often seen problems Often seen problems Low parallelism I/O is
Hadoop Tutorial. General Instructions
 CS246: Mining Massive Datasets Winter 2016 Hadoop Tutorial Due 11:59pm January 12, 2016 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted
CS246: Mining Massive Datasets Winter 2016 Hadoop Tutorial Due 11:59pm January 12, 2016 General Instructions The purpose of this tutorial is (1) to get you started with Hadoop and (2) to get you acquainted
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK A COMPREHENSIVE VIEW OF HADOOP ER. AMRINDER KAUR Assistant Professor, Department
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
MapReduce Online. Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears. Neeraj Ganapathy
 MapReduce Online Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears Neeraj Ganapathy Outline Hadoop Architecture Pipelined MapReduce Online Aggregation Continuous
MapReduce Online Tyson Condie, Neil Conway, Peter Alvaro, Joseph Hellerstein, Khaled Elmeleegy, Russell Sears Neeraj Ganapathy Outline Hadoop Architecture Pipelined MapReduce Online Aggregation Continuous
Cloudera Certified Developer for Apache Hadoop
 Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
Cloudera CCD-333 Cloudera Certified Developer for Apache Hadoop Version: 5.6 QUESTION NO: 1 Cloudera CCD-333 Exam What is a SequenceFile? A. A SequenceFile contains a binary encoding of an arbitrary number
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture
 DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
DATA MINING WITH HADOOP AND HIVE Introduction to Architecture Dr. Wlodek Zadrozny (Most slides come from Prof. Akella s class in 2014) 2015-2025. Reproduction or usage prohibited without permission of
Clusters in the Cloud
 Clusters in the Cloud Dr. Paul Coddington, Deputy Director Dr. Shunde Zhang, Compu:ng Specialist eresearch SA October 2014 Use Cases Make the cloud easier to use for compute jobs Par:cularly for users
Clusters in the Cloud Dr. Paul Coddington, Deputy Director Dr. Shunde Zhang, Compu:ng Specialist eresearch SA October 2014 Use Cases Make the cloud easier to use for compute jobs Par:cularly for users
Data-intensive computing systems
 Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Data-intensive computing systems Hadoop Universtity of Verona Computer Science Department Damiano Carra Acknowledgements! Credits Part of the course material is based on slides provided by the following
Hadoop Streaming. Table of contents
 Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Table of contents 1 Hadoop Streaming...3 2 How Streaming Works... 3 3 Streaming Command Options...4 3.1 Specifying a Java Class as the Mapper/Reducer... 5 3.2 Packaging Files With Job Submissions... 5
Introduction to Big Data! with Apache Spark" UC#BERKELEY#
 Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Introduction to Big Data! with Apache Spark" UC#BERKELEY# This Lecture" The Big Data Problem" Hardware for Big Data" Distributing Work" Handling Failures and Slow Machines" Map Reduce and Complex Jobs"
Cloud Computing Summary and Preparation for Examination
 Basics of Cloud Computing Lecture 8 Cloud Computing Summary and Preparation for Examination Satish Srirama Outline Quick recap of what we have learnt as part of this course How to prepare for the examination
Basics of Cloud Computing Lecture 8 Cloud Computing Summary and Preparation for Examination Satish Srirama Outline Quick recap of what we have learnt as part of this course How to prepare for the examination
Parallel Databases. Parallel Architectures. Parallelism Terminology 1/4/2015. Increase performance by performing operations in parallel
 Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Parallel Databases Increase performance by performing operations in parallel Parallel Architectures Shared memory Shared disk Shared nothing closely coupled loosely coupled Parallelism Terminology Speedup:
Data Management in the Cloud: Limitations and Opportunities. Annies Ductan
 Data Management in the Cloud: Limitations and Opportunities Annies Ductan Discussion Outline: Introduc)on Overview Vision of Cloud Compu8ng Managing Data in The Cloud Cloud Characteris8cs Data Management
Data Management in the Cloud: Limitations and Opportunities Annies Ductan Discussion Outline: Introduc)on Overview Vision of Cloud Compu8ng Managing Data in The Cloud Cloud Characteris8cs Data Management
CONFIGURING ECLIPSE FOR AWS EMR DEVELOPMENT
 CONFIGURING ECLIPSE FOR AWS EMR DEVELOPMENT With this post we thought of sharing a tutorial for configuring Eclipse IDE (Intergrated Development Environment) for Amazon AWS EMR scripting and development.
CONFIGURING ECLIPSE FOR AWS EMR DEVELOPMENT With this post we thought of sharing a tutorial for configuring Eclipse IDE (Intergrated Development Environment) for Amazon AWS EMR scripting and development.
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Introduction to Hadoop
 1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
1 What is Hadoop? Introduction to Hadoop We are living in an era where large volumes of data are available and the problem is to extract meaning from the data avalanche. The goal of the software tools
This exam contains 13 pages (including this cover page) and 18 questions. Check to see if any pages are missing.
 and 18 questions. Check to see if any pages are missing.") Big Data Processing 2013-2014 Q2 April 7, 2014 (Resit) Lecturer: Claudia Hauff Time Limit: 180 Minutes Name: Answer the questions in the spaces provided on this exam. If you run out of room for an answer,
Big Data Processing 2013-2014 Q2 April 7, 2014 (Resit) Lecturer: Claudia Hauff Time Limit: 180 Minutes Name: Answer the questions in the spaces provided on this exam. If you run out of room for an answer,
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open