Seminar Presentation for ECE 658 Instructed by: Prof.Anura Jayasumana Distributed File Systems
|
|
|
- Sydney Harvey
- 8 years ago
- Views:
Transcription
1 Seminar Presentation for ECE 658 Instructed by: Prof.Anura Jayasumana Distributed File Systems Prabhakaran Murugesan

2 Outline File Transfer Protocol (FTP) Network File System (NFS) Andrew File System (AFS) Performance Comparison between FTP, NFS and AFS Google File System (GFS) Amazon Dynamo Hadoop Distributed File System (HDFS) Conclusion
 Amazon Dynamo Hadoop Distributed File System")
3 What is DFS? A Distributed File System ( DFS ) enables programs to store and access remote files exactly as they do local ones, allowing users to access files from any computer on a network. This is an area of active research interest today. The resources on a particular machine are local to itself. Resources on other machines are remote. A file system provides a service for clients. The server interface is the normal set of file operations: create, read, etc. on files.

4 Key Features of DFS Data sharing of multiple users User mobility Location transparency Location independence Backups and System Monitoring

5 Distributed File System Requirements Transparency Access transparency Location transparency Mobility transparency Performance transparency Scaling transparency Concurrent file updates File replication Hardware and operating system heterogeneity

6 Distributed File System Requirements Fault tolerance Consistency Security Efficiency

7 Look and feel about traditional File Three major file systems: Systems File Transfer Protocol(FTP) Connect to a remote machine and interactively send or fetch an arbitrary file. User connecting to an FTP server specifies an account and password. Superseded by HTTP for file transfer.

8 Sun's Network File System. One of the most popular and widespread distributed file system in use today since its introduction in Motivated by wanting to extend a Unix file system to a distributed environment. But, further extended to other OS as well. Design is transparent. Any computer can be a server, exporting some of its files, and a client, accessing files on other machines. High performance: try to make remote access as comparable to local access through caching and readahead.

9 Highlights of NFS NFS is stateless All client requests must be self-contained The virtual file system interface VFS operations VNODE operations Fast crash recovery Reason behind stateless design UNIX semantics at Client side Best way to achieve transparent access

10 NFS Architecture
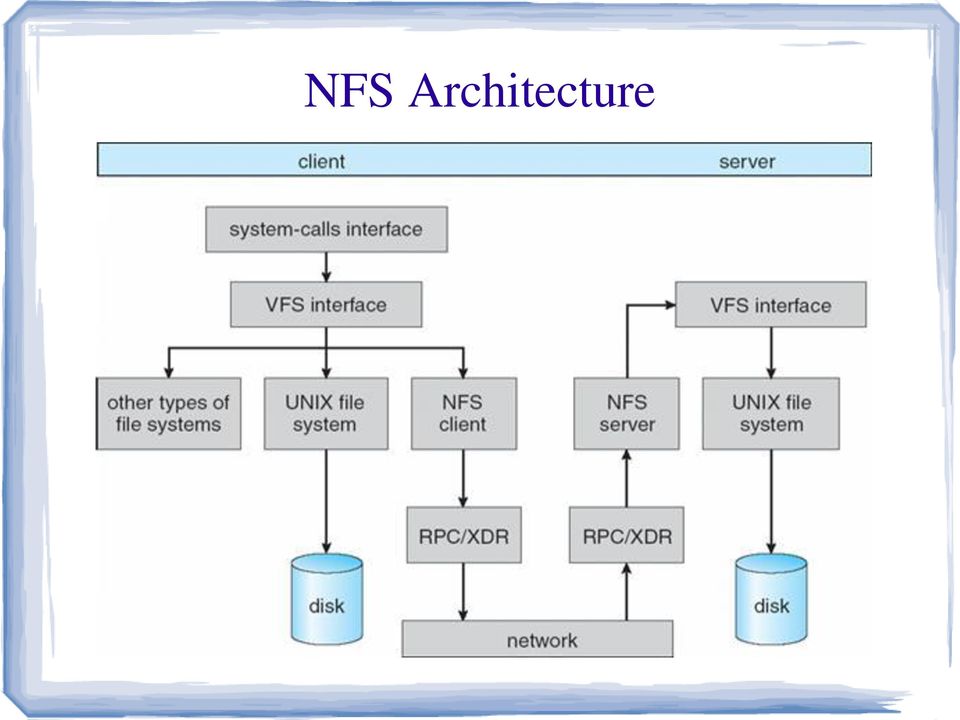
11 Andrew File System Distributed network file system which uses a set of trusted servers to present a homogeneous, location transparent file name space to all the client workstations. Distributed computing environment developed at Carnegie Mellon University (CMU) for use as a campus computing and information system [Morris et al. 1986]. Intention is to support information sharing on a large scale by minimizing client-server communication Achieved by transferring whole files between server and client computers and caching them at clients until the servers receives a more up-to-date version.

12 Features of AFS Uniform namespace Location-independent file sharing Client-side caching Secure authentication Replication Whole-file serving Whole-file caching

13 How does AFS work? Implemented as 2 software components that exists as UNIX processes called Vice and Venus Vice: Name given to the server software that runs as a userlevel UNIX process in each server computer. Venus: User level process that runs in each client computer and corresponds to the client module in our abstract model. Files available to user are either local or shared Local files are stored on a workstation's disk and are available only to local user processes. Shared files are stored on servers, copies of them are cached on the local disk of work stations.

14 AFS Distribution of processes

15 File name space seen by clients of AFS

16 Implementation of File System Calls in AFS

17 How Cache Consistency done in AFS? When Vice supplies a copy of file to a venus process, it provides callback promise. Callback have 2 states: valid and canceled. When venus process receives callback, callback state is set to cancelled. If not, cached copy of the file is used. When workstation is restarted from failure, cache validation request is done. This contains file modification timestamp. If the timestamp is current, server responds with valid and token is reinstated. If not, server responds with cancelled and token is set to cancelled. Callback must be renewed before open.

18 Traditional Distributed File System Issues

19 Naming Is the name access independent? location independent? FTP: location and access independent. NFS: location dependent through client mount points. Largely transparent for ordinary users, but the same remote file system could be mounted differently on different machines. Access independent. AFS: location independent.

20 Migration and Directories Can files be migrated between file server machines? FTP: Sure, but end user must be aware. NFS: Must change mount points on the client machines. AFS: On a per volume basis. How the directories are handled? FTP: Directory listing handled as remote command. NFS: Unix-like. AFS: Unix-like.

21 Sharing Semantics and File locking What type of file sharing semantics are supported if 2 process accessing the same file FTP: User level copies. No support. NFS: Mostly unix semantics. AFS: Session semantics. FTP: Not at all. Does the system support locking of files? NFS: Has mechanism, but external to NFS in v3. Internal to file system in version 4. AFS: Does support.
22 Caching and File Replication Is file caching supported? FTP: None. User has to maintain their own copy. NFS: File attributes and file data blocks are cached separately. Cached attributes are validated with the server on file open. AFS: File level caching with callbacks. Session semantics. Concurrent sharing is not possible. Is file replication supported? FTP: No. NFS: minimal support in version 4. AFS: For read only volumes within a cell.
23 Scalability and Security Is the system scalable? FTP: Yes. Millions of users. NFS: Not so much. AFS: Better than NFS. Keep traffic away from file servers. What security features available? FTP: Account/password authorization. NFS: RPC Unix authentication that can use KERBEROS. AFS: Unix permission for files, access control lists for directories.
24 State/Stateless and Homogeneity Do file system servers maintain state about clients? FTP: No. NFS: No. AFS: Yes FTP: No. NFS: No. AFS: No. Is hardware/software homogeneity required?
25 Other older File Systems 1. CODA: AFS spin-off at CMU. Disconnection and fault recovery. 2. Sprite: research project at UCB in 1980 s. To build a distributed Unix system. 3. Echo. Digital SRC. 4. Amoeba Bullet File Server: Tanenbaum research project. 5. xfs: serverless file system file system distributed across multiple machines. Research project at UCB.
26 The Google File System (GFS) Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google
27 Google File Systems Distributed File System developed solely to meet the demands of Google's data processing needs. It is widely deployed within Google as the storage platform for the generation and processing of data used by Google's service and for research and development efforts which requires large datasets. While sharing many of the same goals as previous distributed file systems, design has been driven by observations of Google's application workloads and technological environment.
28 Assumptions High component failure rates Modest number of huge files File are write-once, mostly appended which may be done concurrently Large streaming reads and small random reads High sustainable throughput favored over low latency System must efficiently implement well defined semantics for multiple clients that concurrently append to the same file
29 GFS Design Decisions Files stored as chunks Fixed size (64MB) Reliability through replication Each chunk replicated across 3+ chunkservers Single master to coordinate access, keep metadata Simple centralized management No data caching Little benefit due to large data sets, streaming reads Client do cache metadata Familiar interface, but customize the API Simplify the problem; focus on Google apps Add snapshot and record append operations
30 Single Master Minimal involvement in reads and write to avoid bottleneck. Easy to use global knowledge to reason about Chunk placements Replication decisions Client caches information from Master so as to avoid multiple interaction
31 GFS Architecture
32 Why 64 MB? Much larger than typical file system block sizes Reduces client interaction with the master Can cache info for Multi-TB working set Reduces network overhead Reduces the size of metadata stored in the master 64 bytes of metadata per 64 MB chunk
33 Read Algorithm 1. Application originates read request 2. GFS client translates request and sends it to master 3. Master responds with chunk handle and replica locations
34 Read Algorithm 4. Client picks a location and sends the request 5. Chunkserver sends requested data to the client 6. Client forwards the data to the application
35 Write Algorithm 1. Application originates the request 2. GFS client translates request and sends it to master 3. Master responds with chunk handle and replica locations
36 Write Algorithm 4. Client pushes write data to all locations. Data is stored in chunkserver's internal buffers
37 Write Algorithm 5. Client sends write command to primary 6. Primary determines serial order to the secondaries and tells them to perform the write 7. Primary sends the serial order to the secondaries and tells them to perform the write
38 Write Algorithm 8. Secondaries respond back to primary 9. Primary responds back to the client
39 Mutation Mutation changes metadata of chunk Write Append Each mutation is performed at all chunk replicas Lease mechanism Master grants lease to one of the replicas Lease has 60 seconds timeout
40 Atomic Record Appends GFS appends it to the file atomically at least once GFS picks the offset Works for concurrent writers Record append is heavily used by distributed applications eg., Google apps
41 Record Append Algorithm Client pushes write data to all locations Primary checks if record fits in specified chunk If the record does not fit: Pads the chunk Tells secondary to do the same Informs client and has the client retry If record fits, then the primary: Appends the record Tells secondaries to do the same Receives responses and responds to the client
42 Interesting thing happened at Google beyond GFS That s Bigtable A distributed storage system which uses GFS to store log and data files More than 60 Google apps(like Google Earth, Orkut) uses Bigtable for storing data(distributed file though GFS) Designed to scale petabytes of data and thousands of machines It s not a relational database, instead gives client a simple data model
43 Google SSTable file format Used internally to store Bigtable data Provides persistent ordered immutable map from keys to values Each SSTable contains a sequence of block and a block index 64KB Block B4K block 64KB Block K block 64KB Block 4K block SSTable Index
44 Dynamo: Amazon s Highly Available Key-Value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels Amazon.com
45 Amazon Dynamo Background Basically a data storage system. Service oriented architecture (SOA) Decentralized Loosely-coupled Hundreds of services up and running Needs storage scheme that is always available Shopping cart service
46 System Assumptions and Requirements Query Model: simple read and write operations to a data item that is uniquely identified by a key. ACID Properties: Atomicity, Consistency, Isolation, Durability. Efficiency: latency requirements which are in general measured at the 99.9th percentile of the distribution. Other Assumptions: operation environment is assumed to be non-hostile and there are no security related requirements such as authentication and authorization.
47 Amazon Dynamo s Architecture
48 Techniques used by Dynamo Consistent hashing along with Replication Used for data partitioning Decentralized, quorum protocol To maintain consistency during updates Gossip protocols Memberships Failure detection
49 Amazon Dynamo Highlights Dynamo is targeted mainly at applications that need an always writeable data store where no updates are rejected Applications do not require support for hierarchical namespaces (a norm in many file systems) Dynamo is built for latency sensitive applications that require at least 99.9% of read and write operations to be performed within a few hundred milliseconds Zero-hop DHT, where each node maintains enough routing information locally to route a request to the appropriate node directly.
50 Hadoop Distributed File System
51 Basic features Highly fault-tolerant High throughput Suitable for applications with large data sets Streaming access to file system data Can be built out of commodity hardware
52 Fault tolerance Failure is the norm rather than exception A HDFS instance may consist of thousands of server machines, each storing part of the file system s data. Since we have huge number of components and that each component has non-trivial probability of failure means that there is always some component that is non-functional. Detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
53 HDFS Architecture
54 Streaming data access Data Characteristics Applications need streaming access to data Batch processing rather than interactive user access. Large data sets and files: gigabytes to terabytes size High aggregate data bandwidth Scale to hundreds of nodes in a cluster Tens of millions of files in a single instance Write-once-read-many: a file once created, written and closed need not be changed this assumption simplifies coherency A map-reduce application or web-crawler application fits perfectly with this model.
55 Namenode and Datanodes Master/slave architecture HDFS cluster consists of a single Namenode, a master server that manages the file system namespace and regulates access to files by clients. There are a number of DataNodes usually one per node in a cluster. The DataNodes manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. A file is split into one or more blocks and set of blocks are stored in DataNodes. DataNodes: serves read, write requests, performs block creation, deletion, and replication upon instruction from Namenode.
56 File System Namespace Hierarchical file system with directories and files Create, remove, move, rename etc. Namenode maintains the file system Any meta information changes to the file system recorded by the Namenode. An application can specify the number of replicas of the file needed: replication factor of the file. This information is stored in the Namenode.
57 Data Replication HDFS is designed to store very large files across machines in a large cluster. Each file is a sequence of blocks. All blocks in the file except the last are of the same size. Blocks are replicated for fault tolerance. Block size and replicas are configurable per file. The Namenode receives a Heartbeat and a BlockReport from each DataNode in the cluster. BlockReport contains all the blocks on a Datanode.
58 Conclusion It is rather impossible to meet both Availability and Consistency Distributed File Systems are heavily employed in organizational computing, and their performance has been the subject of much tuning Current state-of-the-art distributed file systems, provide good performance across both local and wide-area networks
59 Bibliography 1. Distributed Systems: Concepts and design Fifth Edition George Coulouris, Jean Dollimore, Tim Kindberg, Gordon Blair 2. Distributed Systems: Principles and Paradigms Second Edition Andrew S.Tanenbaum, Maarten Van Steen 3. An overview of the Andrew File System John H Howard, CMU 4. The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun- Tak Leung. 5 Dynamo: Amazon s Highly Available Key-value Store - Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels 6 The Hadoop Distributed File System: Architecture and Design Dhruba Borthakur
Distributed File Systems
 Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Distributed File Systems Paul Krzyzanowski Rutgers University October 28, 2012 1 Introduction The classic network file systems we examined, NFS, CIFS, AFS, Coda, were designed as client-server applications.
Distributed File Systems
 Distributed File Systems File Characteristics From Andrew File System work: most files are small transfer files rather than disk blocks? reading more common than writing most access is sequential most
Distributed File Systems File Characteristics From Andrew File System work: most files are small transfer files rather than disk blocks? reading more common than writing most access is sequential most
Distributed File Systems
 Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File Systems Mauro Fruet University of Trento - Italy 2011/12/19 Mauro Fruet (UniTN) Distributed File Systems 2011/12/19 1 / 39 Outline 1 Distributed File Systems 2 The Google File System (GFS)
Distributed File System. MCSN N. Tonellotto Complements of Distributed Enabling Platforms
 Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
Distributed File System 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributed File System Don t move data to workers move workers to the data! Store data on the local disks of nodes
The Google File System
 The Google File System Motivations of NFS NFS (Network File System) Allow to access files in other systems as local files Actually a network protocol (initially only one server) Simple and fast server
The Google File System Motivations of NFS NFS (Network File System) Allow to access files in other systems as local files Actually a network protocol (initially only one server) Simple and fast server
Dynamo: Amazon s Highly Available Key-value Store
 Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
Hadoop Distributed File System. T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela
 Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
Hadoop Distributed File System T-111.5550 Seminar On Multimedia 2009-11-11 Eero Kurkela Agenda Introduction Flesh and bones of HDFS Architecture Accessing data Data replication strategy Fault tolerance
HDFS Architecture Guide
 by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
by Dhruba Borthakur Table of contents 1 Introduction... 3 2 Assumptions and Goals... 3 2.1 Hardware Failure... 3 2.2 Streaming Data Access...3 2.3 Large Data Sets... 3 2.4 Simple Coherency Model...3 2.5
The Google File System
 The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
The Google File System By Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (Presented at SOSP 2003) Introduction Google search engine. Applications process lots of data. Need good file system. Solution:
Lecture 5: GFS & HDFS! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl
! ti2736b-ewi@tudelft.nl") Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Big Data Processing, 2014/15 Lecture 5: GFS & HDFS!! Claudia Hauff (Web Information Systems)! ti2736b-ewi@tudelft.nl 1 Course content Introduction Data streams 1 & 2 The MapReduce paradigm Looking behind
Hadoop Architecture. Part 1
 Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Hadoop Architecture Part 1 Node, Rack and Cluster: A node is simply a computer, typically non-enterprise, commodity hardware for nodes that contain data. Consider we have Node 1.Then we can add more nodes,
Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute
 Review of Distributed File Systems: Case Studies Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute Abstract
Review of Distributed File Systems: Case Studies Sunita Suralkar, Ashwini Mujumdar, Gayatri Masiwal, Manasi Kulkarni Department of Computer Technology, Veermata Jijabai Technological Institute Abstract
Snapshots in Hadoop Distributed File System
 Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Snapshots in Hadoop Distributed File System Sameer Agarwal UC Berkeley Dhruba Borthakur Facebook Inc. Ion Stoica UC Berkeley Abstract The ability to take snapshots is an essential functionality of any
Cloud Computing at Google. Architecture
 Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
Cloud Computing at Google Google File System Web Systems and Algorithms Google Chris Brooks Department of Computer Science University of San Francisco Google has developed a layered system to handle webscale
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems
 CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
CS2510 Computer Operating Systems HADOOP Distributed File System Dr. Taieb Znati Computer Science Department University of Pittsburgh Outline HDF Design Issues HDFS Application Profile Block Abstraction
Distributed File Systems
 Distributed File Systems Alemnew Sheferaw Asrese University of Trento - Italy December 12, 2012 Acknowledgement: Mauro Fruet Alemnew S. Asrese (UniTN) Distributed File Systems 2012/12/12 1 / 55 Outline
Distributed File Systems Alemnew Sheferaw Asrese University of Trento - Italy December 12, 2012 Acknowledgement: Mauro Fruet Alemnew S. Asrese (UniTN) Distributed File Systems 2012/12/12 1 / 55 Outline
Hadoop Distributed File System. Dhruba Borthakur June, 2007
 Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Hadoop Distributed File System Dhruba Borthakur June, 2007 Goals of HDFS Very Large Distributed File System 10K nodes, 100 million files, 10 PB Assumes Commodity Hardware Files are replicated to handle
Alternatives to HIVE SQL in Hadoop File Structure
 Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
Alternatives to HIVE SQL in Hadoop File Structure Ms. Arpana Chaturvedi, Ms. Poonam Verma ABSTRACT Trends face ups and lows.in the present scenario the social networking sites have been in the vogue. The
RAID. Tiffany Yu-Han Chen. # The performance of different RAID levels # read/write/reliability (fault-tolerant)/overhead
/overhead") RAID # The performance of different RAID levels # read/write/reliability (fault-tolerant)/overhead Tiffany Yu-Han Chen (These slides modified from Hao-Hua Chu National Taiwan University) RAID 0 - Striping
RAID # The performance of different RAID levels # read/write/reliability (fault-tolerant)/overhead Tiffany Yu-Han Chen (These slides modified from Hao-Hua Chu National Taiwan University) RAID 0 - Striping
HDFS Under the Hood. Sanjay Radia. Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc.
 HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
HDFS Under the Hood Sanjay Radia Sradia@yahoo-inc.com Grid Computing, Hadoop Yahoo Inc. 1 Outline Overview of Hadoop, an open source project Design of HDFS On going work 2 Hadoop Hadoop provides a framework
Google File System. Web and scalability
 Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Google File System Web and scalability The web: - How big is the Web right now? No one knows. - Number of pages that are crawled: o 100,000 pages in 1994 o 8 million pages in 2005 - Crawlable pages might
Comparative analysis of Google File System and Hadoop Distributed File System
 Comparative analysis of Google File System and Hadoop Distributed File System R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao Dept. of Computer Science, Krishna University, Machilipatnam, India, vijayakumari28@gmail.com
Comparative analysis of Google File System and Hadoop Distributed File System R.Vijayakumari, R.Kirankumar, K.Gangadhara Rao Dept. of Computer Science, Krishna University, Machilipatnam, India, vijayakumari28@gmail.com
Hadoop Distributed File System. Jordan Prosch, Matt Kipps
 Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System Jordan Prosch, Matt Kipps Outline - Background - Architecture - Comments & Suggestions Background What is HDFS? Part of Apache Hadoop - distributed storage What is Hadoop?
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org June 3 rd, 2008 Who Am I? Hadoop Developer Core contributor since Hadoop s infancy Focussed
THE HADOOP DISTRIBUTED FILE SYSTEM
 THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
THE HADOOP DISTRIBUTED FILE SYSTEM Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Presented by Alexander Pokluda October 7, 2013 Outline Motivation and Overview of Hadoop Architecture,
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the Storage Developer Conference, Santa Clara September 15, 2009 Outline Introduction
Scalable Multiple NameNodes Hadoop Cloud Storage System
 Vol.8, No.1 (2015), pp.105-110 http://dx.doi.org/10.14257/ijdta.2015.8.1.12 Scalable Multiple NameNodes Hadoop Cloud Storage System Kun Bi 1 and Dezhi Han 1,2 1 College of Information Engineering, Shanghai
Vol.8, No.1 (2015), pp.105-110 http://dx.doi.org/10.14257/ijdta.2015.8.1.12 Scalable Multiple NameNodes Hadoop Cloud Storage System Kun Bi 1 and Dezhi Han 1,2 1 College of Information Engineering, Shanghai
Reduction of Data at Namenode in HDFS using harballing Technique
 Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.
Reduction of Data at Namenode in HDFS using harballing Technique Vaibhav Gopal Korat, Kumar Swamy Pamu vgkorat@gmail.com swamy.uncis@gmail.com Abstract HDFS stands for the Hadoop Distributed File System.
Hadoop@LaTech ATLAS Tier 3
 Cerberus Hadoop Hadoop@LaTech ATLAS Tier 3 David Palma DOSAR Louisiana Tech University January 23, 2013 Cerberus Hadoop Outline 1 Introduction Cerberus Hadoop 2 Features Issues Conclusions 3 Cerberus Hadoop
Cerberus Hadoop Hadoop@LaTech ATLAS Tier 3 David Palma DOSAR Louisiana Tech University January 23, 2013 Cerberus Hadoop Outline 1 Introduction Cerberus Hadoop 2 Features Issues Conclusions 3 Cerberus Hadoop
Dynamo: Amazon s Highly Available Key-value Store
 Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
Dynamo: Amazon s Highly Available Key-value Store Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and
IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY
 IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY Hadoop Distributed File System: What and Why? Ashwini Dhruva Nikam, Computer Science & Engineering, J.D.I.E.T., Yavatmal. Maharashtra,
IJFEAT INTERNATIONAL JOURNAL FOR ENGINEERING APPLICATIONS AND TECHNOLOGY Hadoop Distributed File System: What and Why? Ashwini Dhruva Nikam, Computer Science & Engineering, J.D.I.E.T., Yavatmal. Maharashtra,
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA
 Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Tutorial: Big Data Algorithms and Applications Under Hadoop KUNPENG ZHANG SIDDHARTHA BHATTACHARYYA http://kzhang6.people.uic.edu/tutorial/amcis2014.html August 7, 2014 Schedule I. Introduction to big data
Take An Internal Look at Hadoop. Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com
 Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Take An Internal Look at Hadoop Hairong Kuang Grid Team, Yahoo! Inc hairong@yahoo-inc.com What s Hadoop Framework for running applications on large clusters of commodity hardware Scale: petabytes of data
Design and Evolution of the Apache Hadoop File System(HDFS)
") Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Design and Evolution of the Apache Hadoop File System(HDFS) Dhruba Borthakur Engineer@Facebook Committer@Apache HDFS SDC, Sept 19 2011 Outline Introduction Yet another file-system, why? Goals of Hadoop
Prepared By : Manoj Kumar Joshi & Vikas Sawhney
 Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Prepared By : Manoj Kumar Joshi & Vikas Sawhney General Agenda Introduction to Hadoop Architecture Acknowledgement Thanks to all the authors who left their selfexplanatory images on the internet. Thanks
Transparency in Distributed Systems
 Transparency in Distributed Systems By Sudheer R Mantena Abstract The present day network architectures are becoming more and more complicated due to heterogeneity of the network components and mainly
Transparency in Distributed Systems By Sudheer R Mantena Abstract The present day network architectures are becoming more and more complicated due to heterogeneity of the network components and mainly
Big Data With Hadoop
 With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
With Saurabh Singh singh.903@osu.edu The Ohio State University February 11, 2016 Overview 1 2 3 Requirements Ecosystem Resilient Distributed Datasets (RDDs) Example Code vs Mapreduce 4 5 Source: [Tutorials
HDFS Users Guide. Table of contents
 Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Table of contents 1 Purpose...2 2 Overview...2 3 Prerequisites...3 4 Web Interface...3 5 Shell Commands... 3 5.1 DFSAdmin Command...4 6 Secondary NameNode...4 7 Checkpoint Node...5 8 Backup Node...6 9
Hadoop Distributed File System (HDFS) Overview
 Overview") 2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
2012 coreservlets.com and Dima May Hadoop Distributed File System (HDFS) Overview Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized
Distributed Filesystems
 Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Distributed Filesystems Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 8, 2014 Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 1 / 32 What is Filesystem? Controls
Apache Hadoop FileSystem and its Usage in Facebook
 Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem and its Usage in Facebook Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Indian Institute of Technology November, 2010 http://www.facebook.com/hadoopfs
Parallel Processing of cluster by Map Reduce
 Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
Parallel Processing of cluster by Map Reduce Abstract Madhavi Vaidya, Department of Computer Science Vivekanand College, Chembur, Mumbai vamadhavi04@yahoo.co.in MapReduce is a parallel programming model
GeoGrid Project and Experiences with Hadoop
 GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
GeoGrid Project and Experiences with Hadoop Gong Zhang and Ling Liu Distributed Data Intensive Systems Lab (DiSL) Center for Experimental Computer Systems Research (CERCS) Georgia Institute of Technology
MASSIVE DATA PROCESSING (THE GOOGLE WAY ) 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015
 27/04/2015. Fundamentals of Distributed Systems. Inside Google circa 2015") 7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
7/04/05 Fundamentals of Distributed Systems CC5- PROCESAMIENTO MASIVO DE DATOS OTOÑO 05 Lecture 4: DFS & MapReduce I Aidan Hogan aidhog@gmail.com Inside Google circa 997/98 MASSIVE DATA PROCESSING (THE
Hypertable Architecture Overview
 WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
WHITE PAPER - MARCH 2012 Hypertable Architecture Overview Hypertable is an open source, scalable NoSQL database modeled after Bigtable, Google s proprietary scalable database. It is written in C++ for
Data-Intensive Computing with Map-Reduce and Hadoop
 Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Data-Intensive Computing with Map-Reduce and Hadoop Shamil Humbetov Department of Computer Engineering Qafqaz University Baku, Azerbaijan humbetov@gmail.com Abstract Every day, we create 2.5 quintillion
Distributed File Systems. Chapter 10
 Distributed File Systems Chapter 10 Distributed File System a) A distributed file system is a file system that resides on different machines, but offers an integrated view of data stored on remote disks.
Distributed File Systems Chapter 10 Distributed File System a) A distributed file system is a file system that resides on different machines, but offers an integrated view of data stored on remote disks.
Jeffrey D. Ullman slides. MapReduce for data intensive computing
 Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Jeffrey D. Ullman slides MapReduce for data intensive computing Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very
Overview. Big Data in Apache Hadoop. - HDFS - MapReduce in Hadoop - YARN. https://hadoop.apache.org. Big Data Management and Analytics
 Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Overview Big Data in Apache Hadoop - HDFS - MapReduce in Hadoop - YARN https://hadoop.apache.org 138 Apache Hadoop - Historical Background - 2003: Google publishes its cluster architecture & DFS (GFS)
Hadoop Distributed File System. Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com
 Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
Hadoop Distributed File System Dhruba Borthakur Apache Hadoop Project Management Committee dhruba@apache.org dhruba@facebook.com Hadoop, Why? Need to process huge datasets on large clusters of computers
GraySort and MinuteSort at Yahoo on Hadoop 0.23
 GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
GraySort and at Yahoo on Hadoop.23 Thomas Graves Yahoo! May, 213 The Apache Hadoop[1] software library is an open source framework that allows for the distributed processing of large data sets across clusters
Journal of science STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
") Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Journal of science e ISSN 2277-3290 Print ISSN 2277-3282 Information Technology www.journalofscience.net STUDY ON REPLICA MANAGEMENT AND HIGH AVAILABILITY IN HADOOP DISTRIBUTED FILE SYSTEM (HDFS) S. Chandra
Fault Tolerance in Hadoop for Work Migration
 1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
1 Fault Tolerance in Hadoop for Work Migration Shivaraman Janakiraman Indiana University Bloomington ABSTRACT Hadoop is a framework that runs applications on large clusters which are built on numerous
A REVIEW ON EFFICIENT DATA ANALYSIS FRAMEWORK FOR INCREASING THROUGHPUT IN BIG DATA. Technology, Coimbatore. Engineering and Technology, Coimbatore.
 A REVIEW ON EFFICIENT DATA ANALYSIS FRAMEWORK FOR INCREASING THROUGHPUT IN BIG DATA 1 V.N.Anushya and 2 Dr.G.Ravi Kumar 1 Pg scholar, Department of Computer Science and Engineering, Coimbatore Institute
A REVIEW ON EFFICIENT DATA ANALYSIS FRAMEWORK FOR INCREASING THROUGHPUT IN BIG DATA 1 V.N.Anushya and 2 Dr.G.Ravi Kumar 1 Pg scholar, Department of Computer Science and Engineering, Coimbatore Institute
Load Rebalancing for File System in Public Cloud Roopa R.L 1, Jyothi Patil 2
 Load Rebalancing for File System in Public Cloud Roopa R.L 1, Jyothi Patil 2 1 PDA College of Engineering, Gulbarga, Karnataka, India rlrooparl@gmail.com 2 PDA College of Engineering, Gulbarga, Karnataka,
Load Rebalancing for File System in Public Cloud Roopa R.L 1, Jyothi Patil 2 1 PDA College of Engineering, Gulbarga, Karnataka, India rlrooparl@gmail.com 2 PDA College of Engineering, Gulbarga, Karnataka,
Big Data Processing in the Cloud. Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center
 Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
Big Data Processing in the Cloud Shadi Ibrahim Inria, Rennes - Bretagne Atlantique Research Center Data is ONLY as useful as the decisions it enables 2 Data is ONLY as useful as the decisions it enables
SOLVING LOAD REBALANCING FOR DISTRIBUTED FILE SYSTEM IN CLOUD
 International Journal of Advances in Applied Science and Engineering (IJAEAS) ISSN (P): 2348-1811; ISSN (E): 2348-182X Vol-1, Iss.-3, JUNE 2014, 54-58 IIST SOLVING LOAD REBALANCING FOR DISTRIBUTED FILE
International Journal of Advances in Applied Science and Engineering (IJAEAS) ISSN (P): 2348-1811; ISSN (E): 2348-182X Vol-1, Iss.-3, JUNE 2014, 54-58 IIST SOLVING LOAD REBALANCING FOR DISTRIBUTED FILE
Processing of massive data: MapReduce. 2. Hadoop. New Trends In Distributed Systems MSc Software and Systems
 Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Processing of massive data: MapReduce 2. Hadoop 1 MapReduce Implementations Google were the first that applied MapReduce for big data analysis Their idea was introduced in their seminal paper MapReduce:
Big Data Racing and parallel Database Technology
 EFFICIENT DATA ANALYSIS SCHEME FOR INCREASING PERFORMANCE IN BIG DATA Mr. V. Vivekanandan Computer Science and Engineering, SriGuru Institute of Technology, Coimbatore, Tamilnadu, India. Abstract Big data
EFFICIENT DATA ANALYSIS SCHEME FOR INCREASING PERFORMANCE IN BIG DATA Mr. V. Vivekanandan Computer Science and Engineering, SriGuru Institute of Technology, Coimbatore, Tamilnadu, India. Abstract Big data
Cloud Computing mit mathematischen Anwendungen
 Cloud Computing mit mathematischen Anwendungen Vorlesung SoSe 2009 Dr. Marcel Kunze Karlsruhe Institute of Technology (KIT) Steinbuch Centre for Computing (SCC) KIT the cooperation of Forschungszentrum
Cloud Computing mit mathematischen Anwendungen Vorlesung SoSe 2009 Dr. Marcel Kunze Karlsruhe Institute of Technology (KIT) Steinbuch Centre for Computing (SCC) KIT the cooperation of Forschungszentrum
Cloud Computing in Distributed System
 M.H.Nerkar & Sonali Vijay Shinkar GCOE, Jalgaon Abstract - Cloud Computing as an Internet-based computing; where resources, software and information are provided to computers on-demand, like a public utility;
M.H.Nerkar & Sonali Vijay Shinkar GCOE, Jalgaon Abstract - Cloud Computing as an Internet-based computing; where resources, software and information are provided to computers on-demand, like a public utility;
Hadoop & its Usage at Facebook
 Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop & its Usage at Facebook Dhruba Borthakur Project Lead, Hadoop Distributed File System dhruba@apache.org Presented at the The Israeli Association of Grid Technologies July 15, 2009 Outline Architecture
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
MANAGEMENT OF DATA REPLICATION FOR PC CLUSTER BASED CLOUD STORAGE SYSTEM
 MANAGEMENT OF DATA REPLICATION FOR PC CLUSTER BASED CLOUD STORAGE SYSTEM Julia Myint 1 and Thinn Thu Naing 2 1 University of Computer Studies, Yangon, Myanmar juliamyint@gmail.com 2 University of Computer
MANAGEMENT OF DATA REPLICATION FOR PC CLUSTER BASED CLOUD STORAGE SYSTEM Julia Myint 1 and Thinn Thu Naing 2 1 University of Computer Studies, Yangon, Myanmar juliamyint@gmail.com 2 University of Computer
Facebook: Cassandra. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
Facebook: Cassandra Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/24 Outline 1 2 3 Smruti R. Sarangi Leader Election
HADOOP MOCK TEST HADOOP MOCK TEST I
 http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
http://www.tutorialspoint.com HADOOP MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to Hadoop Framework. You can download these sample mock tests at
A Review of Column-Oriented Datastores. By: Zach Pratt. Independent Study Dr. Maskarinec Spring 2011
 A Review of Column-Oriented Datastores By: Zach Pratt Independent Study Dr. Maskarinec Spring 2011 Table of Contents 1 Introduction...1 2 Background...3 2.1 Basic Properties of an RDBMS...3 2.2 Example
A Review of Column-Oriented Datastores By: Zach Pratt Independent Study Dr. Maskarinec Spring 2011 Table of Contents 1 Introduction...1 2 Background...3 2.1 Basic Properties of an RDBMS...3 2.2 Example
International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Volume 2, Issue 8, August 2014 ISSN: 2321 7782 (Online) International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online
Apache Hadoop. Alexandru Costan
 1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
1 Apache Hadoop Alexandru Costan Big Data Landscape No one-size-fits-all solution: SQL, NoSQL, MapReduce, No standard, except Hadoop 2 Outline What is Hadoop? Who uses it? Architecture HDFS MapReduce Open
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique
 Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Comparative analysis of mapreduce job by keeping data constant and varying cluster size technique Mahesh Maurya a, Sunita Mahajan b * a Research Scholar, JJT University, MPSTME, Mumbai, India,maheshkmaurya@yahoo.co.in
Hadoop: Embracing future hardware
 Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
Hadoop: Embracing future hardware Suresh Srinivas @suresh_m_s Page 1 About Me Architect & Founder at Hortonworks Long time Apache Hadoop committer and PMC member Designed and developed many key Hadoop
!"#$%&' ( )%#*'+,'-#.//"0( !"#$"%&'()*$+()',!-+.'/', 4(5,67,!-+!"89,:*$;'0+$.<.,&0$'09,&)"/=+,!()<>'0, 3, Processing LARGE data sets
%#*'+,'-#.//0( !#$%&'()*$+()',!-+.'/', 4(5,67,!-+!89,:*$;'0+$.<.,&0$'09,&)/=+,!()<>'0, 3, Processing LARGE data sets") !"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
!"#$%&' ( Processing LARGE data sets )%#*'+,'-#.//"0( Framework for o! reliable o! scalable o! distributed computation of large data sets 4(5,67,!-+!"89,:*$;'0+$.
Massive Data Storage
 Massive Data Storage Storage on the "Cloud" and the Google File System paper by: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung presentation by: Joshua Michalczak COP 4810 - Topics in Computer Science
Massive Data Storage Storage on the "Cloud" and the Google File System paper by: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung presentation by: Joshua Michalczak COP 4810 - Topics in Computer Science
Storage Systems Autumn 2009. Chapter 6: Distributed Hash Tables and their Applications André Brinkmann
 Storage Systems Autumn 2009 Chapter 6: Distributed Hash Tables and their Applications André Brinkmann Scaling RAID architectures Using traditional RAID architecture does not scale Adding news disk implies
Storage Systems Autumn 2009 Chapter 6: Distributed Hash Tables and their Applications André Brinkmann Scaling RAID architectures Using traditional RAID architecture does not scale Adding news disk implies
Last class: Distributed File Systems. Today: NFS, Coda
 Last class: Distributed File Systems Issues in distributed file systems Sun s Network File System case study Lecture 19, page 1 Today: NFS, Coda Case Study: NFS (continued) Case Study: Coda File System
Last class: Distributed File Systems Issues in distributed file systems Sun s Network File System case study Lecture 19, page 1 Today: NFS, Coda Case Study: NFS (continued) Case Study: Coda File System
Chapter 11 Distributed File Systems. Distributed File Systems
 Chapter 11 Distributed File Systems Introduction Case studies NFS Coda 1 Distributed File Systems A distributed file system enables clients to access files stored on one or more remote file servers A file
Chapter 11 Distributed File Systems Introduction Case studies NFS Coda 1 Distributed File Systems A distributed file system enables clients to access files stored on one or more remote file servers A file
Processing of Hadoop using Highly Available NameNode
 Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Processing of Hadoop using Highly Available NameNode 1 Akash Deshpande, 2 Shrikant Badwaik, 3 Sailee Nalawade, 4 Anjali Bote, 5 Prof. S. P. Kosbatwar Department of computer Engineering Smt. Kashibai Navale
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Weekly Report. Hadoop Introduction. submitted By Anurag Sharma. Department of Computer Science and Engineering. Indian Institute of Technology Bombay
 Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Weekly Report Hadoop Introduction submitted By Anurag Sharma Department of Computer Science and Engineering Indian Institute of Technology Bombay Chapter 1 What is Hadoop? Apache Hadoop (High-availability
Web Email DNS Peer-to-peer systems (file sharing, CDNs, cycle sharing)
") 1 1 Distributed Systems What are distributed systems? How would you characterize them? Components of the system are located at networked computers Cooperate to provide some service No shared memory Communication
1 1 Distributed Systems What are distributed systems? How would you characterize them? Components of the system are located at networked computers Cooperate to provide some service No shared memory Communication
Highly Available Hadoop Name Node Architecture-Using Replicas of Name Node with Time Synchronization among Replicas
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 16, Issue 3, Ver. II (May-Jun. 2014), PP 58-62 Highly Available Hadoop Name Node Architecture-Using Replicas
Erlang Distributed File System (edfs)
") Indian Institute of Technology Bombay CS 492 : BTP Stage I Erlang Distributed File System (edfs) By: Aman Mangal (100050015) Coordinator: Prof. G. Sivakumar November 30, 2013 Contents Abstract 3 1 Introduction
Indian Institute of Technology Bombay CS 492 : BTP Stage I Erlang Distributed File System (edfs) By: Aman Mangal (100050015) Coordinator: Prof. G. Sivakumar November 30, 2013 Contents Abstract 3 1 Introduction
Big Table A Distributed Storage System For Data
 Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
Big Table A Distributed Storage System For Data OSDI 2006 Fay Chang, Jeffrey Dean, Sanjay Ghemawat et.al. Presented by Rahul Malviya Why BigTable? Lots of (semi-)structured data at Google - - URLs: Contents,
A programming model in Cloud: MapReduce
 A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
A programming model in Cloud: MapReduce Programming model and implementation developed by Google for processing large data sets Users specify a map function to generate a set of intermediate key/value
Introduction to Hadoop
 Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
Introduction to Hadoop 1 What is Hadoop? the big data revolution extracting value from data cloud computing 2 Understanding MapReduce the word count problem more examples MCS 572 Lecture 24 Introduction
What Is Datacenter (Warehouse) Computing. Distributed and Parallel Technology. Datacenter Computing Application Programming
 Computing. Distributed and Parallel Technology. Datacenter Computing Application Programming") Distributed and Parallel Technology Datacenter and Warehouse Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 0 Based on earlier versions by
Distributed and Parallel Technology Datacenter and Warehouse Computing Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 0 Based on earlier versions by
NoSQL and Hadoop Technologies On Oracle Cloud
 NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
NoSQL and Hadoop Technologies On Oracle Cloud Vatika Sharma 1, Meenu Dave 2 1 M.Tech. Scholar, Department of CSE, Jagan Nath University, Jaipur, India 2 Assistant Professor, Department of CSE, Jagan Nath
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components
 Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Welcome to the unit of Hadoop Fundamentals on Hadoop architecture. I will begin with a terminology review and then cover the major components of Hadoop. We will see what types of nodes can exist in a Hadoop
Chapter 7. Using Hadoop Cluster and MapReduce
 Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Chapter 7 Using Hadoop Cluster and MapReduce Modeling and Prototyping of RMS for QoS Oriented Grid Page 152 7. Using Hadoop Cluster and MapReduce for Big Data Problems The size of the databases used in
Hadoop implementation of MapReduce computational model. Ján Vaňo
 Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
Hadoop implementation of MapReduce computational model Ján Vaňo What is MapReduce? A computational model published in a paper by Google in 2004 Based on distributed computation Complements Google s distributed
BookKeeper. Flavio Junqueira Yahoo! Research, Barcelona. Hadoop in China 2011
 BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
BookKeeper Flavio Junqueira Yahoo! Research, Barcelona Hadoop in China 2011 What s BookKeeper? Shared storage for writing fast sequences of byte arrays Data is replicated Writes are striped Many processes
The Hadoop Distributed File System
 The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
The Hadoop Distributed File System Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu HDFS
Hands-on Cassandra. OSCON July 20, 2010. Eric Evans eevans@rackspace.com @jericevans http://blog.sym-link.com
 Hands-on Cassandra OSCON July 20, 2010 Eric Evans eevans@rackspace.com @jericevans http://blog.sym-link.com 2 Background Influential Papers BigTable Strong consistency Sparse map data model GFS, Chubby,
Hands-on Cassandra OSCON July 20, 2010 Eric Evans eevans@rackspace.com @jericevans http://blog.sym-link.com 2 Background Influential Papers BigTable Strong consistency Sparse map data model GFS, Chubby,
Introduction to Hadoop Distributed File System Vaibhav Gopal korat vgkorat@gmail.com
 Introduction to Hadoop Distributed File System Vaibhav Gopal korat vgkorat@gmail.com Ankush Pramod Deshmukh ankush25d@gmail.com Kumar Swamy Pamu swamy.uncis@gmail.com Abstract HDFS is a distributed file
Introduction to Hadoop Distributed File System Vaibhav Gopal korat vgkorat@gmail.com Ankush Pramod Deshmukh ankush25d@gmail.com Kumar Swamy Pamu swamy.uncis@gmail.com Abstract HDFS is a distributed file
Network File System (NFS) Pradipta De pradipta.de@sunykorea.ac.kr
 Pradipta De pradipta.de@sunykorea.ac.kr") Network File System (NFS) Pradipta De pradipta.de@sunykorea.ac.kr Today s Topic Network File System Type of Distributed file system NFS protocol NFS cache consistency issue CSE506: Ext Filesystem 2 NFS
Network File System (NFS) Pradipta De pradipta.de@sunykorea.ac.kr Today s Topic Network File System Type of Distributed file system NFS protocol NFS cache consistency issue CSE506: Ext Filesystem 2 NFS
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases. Lecture 14
 Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Department of Computer Science University of Cyprus EPL646 Advanced Topics in Databases Lecture 14 Big Data Management IV: Big-data Infrastructures (Background, IO, From NFS to HFDS) Chapter 14-15: Abideboul
Hadoop Distributed Filesystem. Spring 2015, X. Zhang Fordham Univ.
 Hadoop Distributed Filesystem Spring 2015, X. Zhang Fordham Univ. MapReduce Programming Model Split Shuffle Input: a set of [key,value] pairs intermediate [key,value] pairs [k1,v11,v12, ] [k2,v21,v22,
Hadoop Distributed Filesystem Spring 2015, X. Zhang Fordham Univ. MapReduce Programming Model Split Shuffle Input: a set of [key,value] pairs intermediate [key,value] pairs [k1,v11,v12, ] [k2,v21,v22,
Apache Hadoop FileSystem Internals
 Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
Apache Hadoop FileSystem Internals Dhruba Borthakur Project Lead, Apache Hadoop Distributed File System dhruba@apache.org Presented at Storage Developer Conference, San Jose September 22, 2010 http://www.facebook.com/hadoopfs
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing