Data Mining Analysis of a Complex Multistage Polymer Process
|
|
|
- Beverly Hines
- 8 years ago
- Views:
Transcription
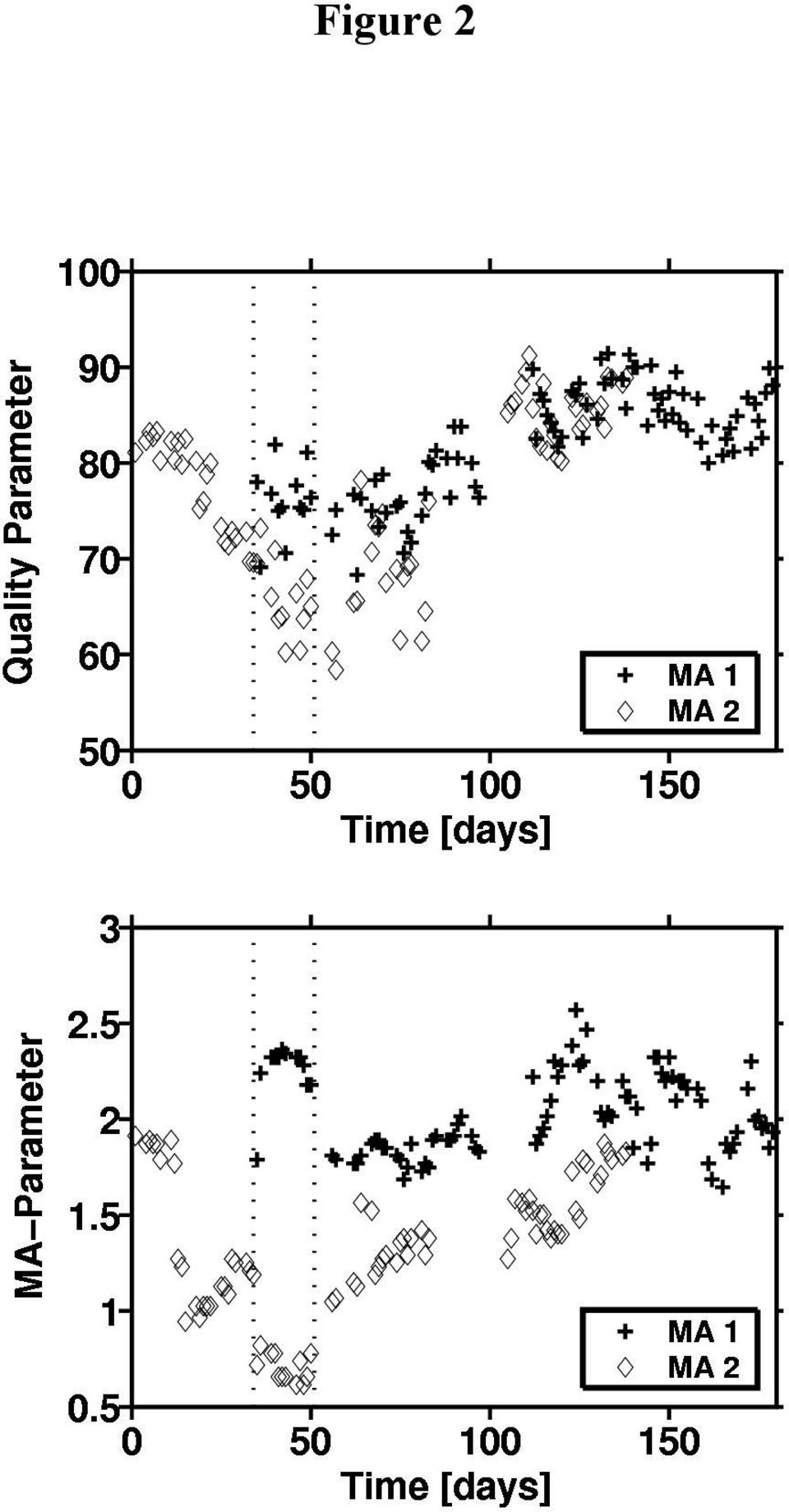
1 Data Mining Analysis of a Complex Multistage Polymer Process Rolf Burghaus, Daniel Leineweber, Jörg Lippert 1 Problem Statement Especially in the highly competitive commodities market, the chemical process industries (CPI) are forced to continually improve the efficiency and quality of their processes. To stay in this market, one has to produce the quality demanded by the customer in a very cost-effective manner. Therefore, many companies have invested in new systems for process and quality data acquisition in recent years. The large amounts of data collected are, however, often not adequately used in practice, because suitable automated analysis methods are only rarely available in the plants. By the successful analysis of a complex multistage polymer process we show that data mining can be used to extract valuable information from existing process and quality data. Data mining comprises various computational methods which are used to automatically identify interesting patterns and possible relationships in large data sets. Hypotheses are generated from the data in the form of explicit rules which can then be directly interpreted in the application context. Thereby it is often possible to discover hidden information in the data even in cases, where classical (hypothesis-based) analysis methods normally fail. The polymer process considered here consists of the two main process stages polymerization and processing, plus a number of auxiliary facilities (see Fig. 1). The polymerization stage itself is composed of several sequentially coupled units (batch/continuous) which need not be described in further detail here. On the processing stage, we consider two processing machines (MA1, MA2) which are operated in parallel. The auxiliary units are used, e.g., for solvent recovery and additive preparation. A central process information management system (PIMS) continuously collects and archives data for about 300 process parameters from polymerization, processing, and auxiliary facilities; the sampling rate is in the order of seconds. In addition, 8 quality parameters for the final polymer product are determined in the lab; only one measurement per day is available. Starting point of our data mining analysis was the need to quickly identify the cause of the large fluctuations of product quality observed over a six-month period, here shown for one of the quality parameters (see upper part of Fig. 2). Interestingly, there was a restricted time period within the analysis horizon, where the processing machines MA1 and MA2 showed significant differences regarding the quality produced. This was another fact which had to be explained. The overall objective of the analysis was, therefore, to identify the key process parameters determining quality and the corresponding cause-and-effect relationships, thus providing the basis for an improved process control. 2 Methods Used Data mining has its roots in the field of databases and artificial intelligence; there has been a rapid development in recent years [1, 2]. Classical areas of application are in marketing (customer relationship management) and in the finance and insurance industries (e.g., assessment of credit-worthiness, fraud detection). More recently, a number of interesting new areas of application specifically related to the CPI have emerged: tailored data mining technologies in combination with statistical methods and neural networks are being used successfully, e.g., at Bayer group, for process data analysis and also in catalyst and life-sciences research. The data mining approach to process data analysis is particularly interesting in the context of troubleshooting activities, because it allows to quickly identify possible causes for process upsets or quality problems from available process data. Our newly developed data mining-driven process analysis strategy is built around the so-called subgroup discovery method [3]. This method allows to automatically identify those subsets of data records (subgroups) showing interesting deviations from the whole set of all data records regarding some target attribute. At the same time, the relevant influence factors which characterize the subgroups are determined. The target attribute (dependent variable, here a quality parameter) and all attributes to be considered as potential influence factors (independent variables, here all process parameters monitored by the PIMS) must be specified in advance. In addition, continuous influence factors must be suitably discretized, because the method can handle only discrete Dr. R. Burghaus, Dr. D. Leineweber, Dr. J. Lippert, Bayer Technology Services GmbH, Process Technology Division, D Leverkusen.

2 attribute values. The discretization is done by simply splitting the continuous ranges into a (usually small) number of subintervals, e.g., for high, medium, and low attribute values. The analysis of the polymer process was complicated by the fact that it was not possible to directly merge the process and quality data due to the different sampling rates involved. Hence a data reduction had to be performed for the high resolution process data during data preprocessing (DPP). To this end, the analysis horizon was divided into suitable time intervals, and each process parameter was characterized on each time interval by a number of quasi-stationary descriptor parameters (e.g., average, standard deviation, Fourier modes, event counts). The resulting quasi-stationary process data could then be combined with the corresponding quality data. For each data mining analysis, all generated descriptor parameters were considered as potential influence factors and one of the quality parameters was chosen as target attribute. All continuous input parameters were discretized using eight subintervals; the interval boundaries were determined such that the same number of data records was assigned to each of the subintervals. For the target attribute, an equidistant discretization with ten subintervals was employed. Based on the preprocessed data, the subgroup discovery method generated a large number of rules, i.e., possible relationships between process and quality parameters. An automatic rule stability analysis ensured that only rules which are stable with respect to certain shifts of the discretization boundaries were considered, thereby eliminating meaningless dummy rules to a large extent. For instance, the following interesting rule was found (here slightly simplified for illustration): IF Average(MA Parameter) "High" AND [...] THEN Quality Parameter "High" This rule can be nicely visualized with the underlying data (see lower part of Fig. 2); it explains the quality differences between the processing machines MA1 and MA2 observed during a restricted time period (see upper part of Fig. 2). In principle, it would have been possible to find a rule like this by direct visual inspection of the preprocessed data, but this would have been very cumbersome due to the large number of potential influence factors. For more complex rules which describe the combined influence of several parameters, the visual approach quickly becomes hopeless. In the course of our data mining analysis, it turned out that the subgroup discovery method alone did not lead to the desired result. Basically, this was due to the fact that there were strong correlations among the input parameters (a quite common situation in process data analysis). Hence an extremely large number of rules was generated, most of which were redundant. In order to cope with this problem, we had to find a way of filtering out a minimal set of independent influence factors which on one hand allow a sufficiently accurate description of the target attribute, on the other hand can be plausibly interpreted and provide some means for an improved process control. To this end, the subgroup discovery method was combined with the validation through a neural network in an iterative analysis workflow as follows: 1. Subgroup discovery to identify dominant influence factors ( best descriptors ) 2. Manual selection of the most plausible best descriptor in case of correlated rules 3. Neural network training using the best descriptors found so far as input parameters 4. Comparison of neural network prediction and target measurement: in case of sufficient agreement stop, otherwise continue with step 1. With a moderate manual effort, this iterative analysis workflow leads to a meaningful list of relevant influence factors which are largely uncorrelated. Furthermore, the neural network provides a data-based process model which can later be used for quality prediction. Our complete data mining workflow for process data analysis is summarized again in Fig. 3. The DPP methods employed and the subgroup discovery method are part of our Data Mining Expert Toolbox (DAMINEX), an inhouse development on the basis of MATLAB (The Math Works, Inc.). For the neural network, we have used the commercial software NN-Tool [4]. 3 Results The above data mining workflow ultimately led to only four relevant influence factors for the quality parameter shown in Fig. 1: the averages of two relative feed streams and the standard deviation of a third relative feed stream (polymerization) as well as the average of a machine parameter (processing). A neural network which was trained with these four input parameters already provided an excellent description of the quality parameter, see upper part of Fig. 4 (only four hidden neurons were used). It turned out that almost the entire observed variation of the quality parameter could be explained by the variation of the four identified key influence parameters (model prediction and measured data were correlated with a correlation coefficient of 0.88). In addition the neural network allowed to establish a ranking of the influence factors. The effect of the MA parameter has already been discussed in the context of Fig.1; the corresponding influence was confirmed as highly plausible by the plant personnel.

3 Similarly, the influence of the relative feed rates on quality was perfectly in line with the existing process knowledge. However, there immediately arose the question, why the relative feed rates and hence the recipe of the polymer showed such large variations. In order to answer this question, one of the fluctuating relative feed rates was taken as a new target attribute, and another data mining analysis was performed according to the scheme above (see Fig. 3). Here it should be noted that the relative feed rate chosen serves as the manipulated variable for viscosity control of the polymer solution produced. Relevant influence factors for this recipe parameter were the viscosity of the polymer solution (a trivial result), and, more interestingly, the binary operation mode of the auxiliary unit solvent recycling : under high load, a second distillation train is used in parallel to the normal train. Hence this operation mode can be characterized by a discrete parameter with only two possible values (on/off). The relative feed rate could be well predicted by a neural network trained with just the two input parameters mentioned (see lower part of Fig. 4); the corresponding correlation coefficient between model and data was Identifying the influence of the solvent recycling unit turned out to be crucial for finding the root cause of the quality problems. It was possible to show by lab analyses that the solvent coming from the second parallel distillation train had a higher level of impurities than the solvent coming from the normal train. Obviously, the impurities contained in the solvent led to a poisoning of the polymerization reaction and thus, via the viscosity control, to the observed recipe and quality variations. 4 Summary and Conclusions By successfully analyzing a complex polymer process, we have shown that detailed data mining analyses can be done not only for single isolated process stages, but also for large multistage processes. Data mining allows the quick identification of hidden non-local effects which are difficult to discover with other methods. A particular advantage of data mining methods like subgroup discovery is the fact that the generated explicit rules can be interpreted directly in the application context. A specifically tailored preprocessing strategy (quasi-stationary description on suitable time intervals) allows to combine process and quality data with different time resolutions for the analysis. The combination of subgroup discovery and neural network validation within an iterative analysis workflow helps to quickly narrow down on a meaningful set of independent rules describing the target attribute of interest. Of course, our data mining methodology can be directly applied to other processes. As demonstrated by a growing number of successful applications, data mining provides a very powerful new tool for process data analysis, especially for troubleshooting. Hence data mining is the method of choice for the automated identification of special causes in the context of statistical process control [5]. By quickly identifying the quality-relevant key influences in the process and the corresponding cause-and-effect relationships, data mining can significantly contribute to process insight. References [1] Advances in Knowledge Discovery and Data Mining (Eds: U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, R. Uthurusamy), MIT Press, Cambridge [2] S. Wrobel, Künstliche Intelligenz 1998, 12(1), [3] S. Wrobel, in Principles of Data Mining and Knowledge Discovery (Eds: H. J. Komorowski, J. M. Zytkow), Lecture Notes in Computer Science 1263, Springer, Berlin 1997, [4] F. Bärmann, F. Biegler-König, Neural Networks 1992, 5(1), [5] G. Box, A. Luceno, Statistical Control by Monitoring and Feedback Adjustment, Wiley, New York 1997.
. Here it should be noted that the relative feed rate chosen serves as the manipulated variable for viscosity control of the polymer solution produced.")
4 Figure 1: Schematic depiction of the polymer process and characterization of the available process and quality data (number of measured parameters, sampling rates). Figure 2: Time profile of one of the quality parameters, classified according to the processing machines MA1 and MA2 (upper part), daily averages of the quality-relevant MA parameter identified by the analysis (lower part). In the marked time period between day 35 and day 50, the machines MA1 and MA2 produce significantly different quality. Figure 3: Iterative data mining workflow for process data analysis, comprising the two phases data preprocessing (DPP) and analysis. The neural network generated in the analysis phase can later be used for prediction of the quality parameters. Figure 4: Prediction quality for two of neural network models established as part of the analysis: description of the quality parameter as a function of the MA parameter and three polymer recipe parameters (upper part), description of the main recipe parameter as a function of the binary operation mode of the auxiliary unit solvent recovery and the viscosity of the polymer solution (lower part). The legend shows the correlation coefficient R between model prediction and measured data.
 and analysis.")
5 Figure 1

6 Figure 2
7 Figure 3

8 Figure 4

Data Mining for Manufacturing: Preventive Maintenance, Failure Prediction, Quality Control
 Data Mining for Manufacturing: Preventive Maintenance, Failure Prediction, Quality Control Andre BERGMANN Salzgitter Mannesmann Forschung GmbH; Duisburg, Germany Phone: +49 203 9993154, Fax: +49 203 9993234;
Data Mining for Manufacturing: Preventive Maintenance, Failure Prediction, Quality Control Andre BERGMANN Salzgitter Mannesmann Forschung GmbH; Duisburg, Germany Phone: +49 203 9993154, Fax: +49 203 9993234;
Healthcare Measurement Analysis Using Data mining Techniques
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 03 Issue 07 July, 2014 Page No. 7058-7064 Healthcare Measurement Analysis Using Data mining Techniques 1 Dr.A.Shaik
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume 03 Issue 07 July, 2014 Page No. 7058-7064 Healthcare Measurement Analysis Using Data mining Techniques 1 Dr.A.Shaik
How To Use Data Mining For Loyalty Based Management
 Data Mining for Loyalty Based Management Petra Hunziker, Andreas Maier, Alex Nippe, Markus Tresch, Douglas Weers, Peter Zemp Credit Suisse P.O. Box 100, CH - 8070 Zurich, Switzerland markus.tresch@credit-suisse.ch,
Data Mining for Loyalty Based Management Petra Hunziker, Andreas Maier, Alex Nippe, Markus Tresch, Douglas Weers, Peter Zemp Credit Suisse P.O. Box 100, CH - 8070 Zurich, Switzerland markus.tresch@credit-suisse.ch,
131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10
![131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10](/thumbs/25/4963058.jpg "131-1. Adding New Level in KDD to Make the Web Usage Mining More Efficient. Abstract. 1. Introduction [1]. 1/10") 1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
1/10 131-1 Adding New Level in KDD to Make the Web Usage Mining More Efficient Mohammad Ala a AL_Hamami PHD Student, Lecturer m_ah_1@yahoocom Soukaena Hassan Hashem PHD Student, Lecturer soukaena_hassan@yahoocom
Single Level Drill Down Interactive Visualization Technique for Descriptive Data Mining Results
 , pp.33-40 http://dx.doi.org/10.14257/ijgdc.2014.7.4.04 Single Level Drill Down Interactive Visualization Technique for Descriptive Data Mining Results Muzammil Khan, Fida Hussain and Imran Khan Department
, pp.33-40 http://dx.doi.org/10.14257/ijgdc.2014.7.4.04 Single Level Drill Down Interactive Visualization Technique for Descriptive Data Mining Results Muzammil Khan, Fida Hussain and Imran Khan Department
Database Marketing, Business Intelligence and Knowledge Discovery
 Database Marketing, Business Intelligence and Knowledge Discovery Note: Using material from Tan / Steinbach / Kumar (2005) Introduction to Data Mining,, Addison Wesley; and Cios / Pedrycz / Swiniarski
Database Marketing, Business Intelligence and Knowledge Discovery Note: Using material from Tan / Steinbach / Kumar (2005) Introduction to Data Mining,, Addison Wesley; and Cios / Pedrycz / Swiniarski
Introduction. Chapter 1
 Chapter 1 Introduction The area of fault detection and diagnosis is one of the most important aspects in process engineering. This area has received considerable attention from industry and academia because
Chapter 1 Introduction The area of fault detection and diagnosis is one of the most important aspects in process engineering. This area has received considerable attention from industry and academia because
Data Mining Solutions for the Business Environment
 Database Systems Journal vol. IV, no. 4/2013 21 Data Mining Solutions for the Business Environment Ruxandra PETRE University of Economic Studies, Bucharest, Romania ruxandra_stefania.petre@yahoo.com Over
Database Systems Journal vol. IV, no. 4/2013 21 Data Mining Solutions for the Business Environment Ruxandra PETRE University of Economic Studies, Bucharest, Romania ruxandra_stefania.petre@yahoo.com Over
BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL
 The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
The Fifth International Conference on e-learning (elearning-2014), 22-23 September 2014, Belgrade, Serbia BOOSTING - A METHOD FOR IMPROVING THE ACCURACY OF PREDICTIVE MODEL SNJEŽANA MILINKOVIĆ University
DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM M. Mayilvaganan 1, S. Aparna 2 1 Associate
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 DATA MINING TECHNIQUES SUPPORT TO KNOWLEGDE OF BUSINESS INTELLIGENT SYSTEM M. Mayilvaganan 1, S. Aparna 2 1 Associate
Assessing Data Mining: The State of the Practice
 Assessing Data Mining: The State of the Practice 2003 Herbert A. Edelstein Two Crows Corporation 10500 Falls Road Potomac, Maryland 20854 www.twocrows.com (301) 983-3555 Objectives Separate myth from reality
Assessing Data Mining: The State of the Practice 2003 Herbert A. Edelstein Two Crows Corporation 10500 Falls Road Potomac, Maryland 20854 www.twocrows.com (301) 983-3555 Objectives Separate myth from reality
Business Intelligence and Decision Support Systems
 Chapter 12 Business Intelligence and Decision Support Systems Information Technology For Management 7 th Edition Turban & Volonino Based on lecture slides by L. Beaubien, Providence College John Wiley
Chapter 12 Business Intelligence and Decision Support Systems Information Technology For Management 7 th Edition Turban & Volonino Based on lecture slides by L. Beaubien, Providence College John Wiley
Use of Data Mining in the field of Library and Information Science : An Overview
 512 Use of Data Mining in the field of Library and Information Science : An Overview Roopesh K Dwivedi R P Bajpai Abstract Data Mining refers to the extraction or Mining knowledge from large amount of
512 Use of Data Mining in the field of Library and Information Science : An Overview Roopesh K Dwivedi R P Bajpai Abstract Data Mining refers to the extraction or Mining knowledge from large amount of
Standardization of Components, Products and Processes with Data Mining
 B. Agard and A. Kusiak, Standardization of Components, Products and Processes with Data Mining, International Conference on Production Research Americas 2004, Santiago, Chile, August 1-4, 2004. Standardization
B. Agard and A. Kusiak, Standardization of Components, Products and Processes with Data Mining, International Conference on Production Research Americas 2004, Santiago, Chile, August 1-4, 2004. Standardization
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING
 EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
EFFICIENT DATA PRE-PROCESSING FOR DATA MINING USING NEURAL NETWORKS JothiKumar.R 1, Sivabalan.R.V 2 1 Research scholar, Noorul Islam University, Nagercoil, India Assistant Professor, Adhiparasakthi College
Using reporting and data mining techniques to improve knowledge of subscribers; applications to customer profiling and fraud management
 Using reporting and data mining techniques to improve knowledge of subscribers; applications to customer profiling and fraud management Paper Jean-Louis Amat Abstract One of the main issues of operators
Using reporting and data mining techniques to improve knowledge of subscribers; applications to customer profiling and fraud management Paper Jean-Louis Amat Abstract One of the main issues of operators
Data quality in Accounting Information Systems
 Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
Data quality in Accounting Information Systems Comparing Several Data Mining Techniques Erjon Zoto Department of Statistics and Applied Informatics Faculty of Economy, University of Tirana Tirana, Albania
International Journal of Computer Science Trends and Technology (IJCST) Volume 2 Issue 3, May-Jun 2014
 Volume 2 Issue 3, May-Jun 2014") RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
RESEARCH ARTICLE OPEN ACCESS A Survey of Data Mining: Concepts with Applications and its Future Scope Dr. Zubair Khan 1, Ashish Kumar 2, Sunny Kumar 3 M.Tech Research Scholar 2. Department of Computer
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches
 Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
Modelling, Extraction and Description of Intrinsic Cues of High Resolution Satellite Images: Independent Component Analysis based approaches PhD Thesis by Payam Birjandi Director: Prof. Mihai Datcu Problematic
DATA MINING TECHNOLOGY. Keywords: data mining, data warehouse, knowledge discovery, OLAP, OLAM.
 DATA MINING TECHNOLOGY Georgiana Marin 1 Abstract In terms of data processing, classical statistical models are restrictive; it requires hypotheses, the knowledge and experience of specialists, equations,
DATA MINING TECHNOLOGY Georgiana Marin 1 Abstract In terms of data processing, classical statistical models are restrictive; it requires hypotheses, the knowledge and experience of specialists, equations,
Data Mining Techniques and Opportunities for Taxation Agencies
 Data Mining Techniques and Opportunities for Taxation Agencies Florida Consultant In This Session... You will learn the data mining techniques below and their application for Tax Agencies ABC Analysis
Data Mining Techniques and Opportunities for Taxation Agencies Florida Consultant In This Session... You will learn the data mining techniques below and their application for Tax Agencies ABC Analysis
International Journal of Computer Trends and Technology (IJCTT) volume 4 Issue 8 August 2013
 volume 4 Issue 8 August 2013") A Short-Term Traffic Prediction On A Distributed Network Using Multiple Regression Equation Ms.Sharmi.S 1 Research Scholar, MS University,Thirunelvelli Dr.M.Punithavalli Director, SREC,Coimbatore. Abstract:
A Short-Term Traffic Prediction On A Distributed Network Using Multiple Regression Equation Ms.Sharmi.S 1 Research Scholar, MS University,Thirunelvelli Dr.M.Punithavalli Director, SREC,Coimbatore. Abstract:
A STUDY ON DATA MINING INVESTIGATING ITS METHODS, APPROACHES AND APPLICATIONS
 A STUDY ON DATA MINING INVESTIGATING ITS METHODS, APPROACHES AND APPLICATIONS Mrs. Jyoti Nawade 1, Dr. Balaji D 2, Mr. Pravin Nawade 3 1 Lecturer, JSPM S Bhivrabai Sawant Polytechnic, Pune (India) 2 Assistant
A STUDY ON DATA MINING INVESTIGATING ITS METHODS, APPROACHES AND APPLICATIONS Mrs. Jyoti Nawade 1, Dr. Balaji D 2, Mr. Pravin Nawade 3 1 Lecturer, JSPM S Bhivrabai Sawant Polytechnic, Pune (India) 2 Assistant
TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM
 TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM Thanh-Nghi Do College of Information Technology, Cantho University 1 Ly Tu Trong Street, Ninh Kieu District Cantho City, Vietnam
TOWARDS SIMPLE, EASY TO UNDERSTAND, AN INTERACTIVE DECISION TREE ALGORITHM Thanh-Nghi Do College of Information Technology, Cantho University 1 Ly Tu Trong Street, Ninh Kieu District Cantho City, Vietnam
Knowledge-Based Visualization to Support Spatial Data Mining
 Knowledge-Based Visualization to Support Spatial Data Mining Gennady Andrienko and Natalia Andrienko GMD - German National Research Center for Information Technology Schloss Birlinghoven, Sankt-Augustin,
Knowledge-Based Visualization to Support Spatial Data Mining Gennady Andrienko and Natalia Andrienko GMD - German National Research Center for Information Technology Schloss Birlinghoven, Sankt-Augustin,
Statistics 215b 11/20/03 D.R. Brillinger. A field in search of a definition a vague concept
 Statistics 215b 11/20/03 D.R. Brillinger Data mining A field in search of a definition a vague concept D. Hand, H. Mannila and P. Smyth (2001). Principles of Data Mining. MIT Press, Cambridge. Some definitions/descriptions
Statistics 215b 11/20/03 D.R. Brillinger Data mining A field in search of a definition a vague concept D. Hand, H. Mannila and P. Smyth (2001). Principles of Data Mining. MIT Press, Cambridge. Some definitions/descriptions
What is Data Mining, and How is it Useful for Power Plant Optimization? (and How is it Different from DOE, CFD, Statistical Modeling)
") data analysis data mining quality control web-based analytics What is Data Mining, and How is it Useful for Power Plant Optimization? (and How is it Different from DOE, CFD, Statistical Modeling) StatSoft
data analysis data mining quality control web-based analytics What is Data Mining, and How is it Useful for Power Plant Optimization? (and How is it Different from DOE, CFD, Statistical Modeling) StatSoft
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree
 Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
Predicting the Risk of Heart Attacks using Neural Network and Decision Tree S.Florence 1, N.G.Bhuvaneswari Amma 2, G.Annapoorani 3, K.Malathi 4 PG Scholar, Indian Institute of Information Technology, Srirangam,
What is Data Mining? Data Mining (Knowledge discovery in database) Data mining: Basic steps. Mining tasks. Classification: YES, NO
 Data mining: Basic steps. Mining tasks. Classification: YES, NO") What is Data Mining? Data Mining (Knowledge discovery in database) Data Mining: "The non trivial extraction of implicit, previously unknown, and potentially useful information from data" William J Frawley,
What is Data Mining? Data Mining (Knowledge discovery in database) Data Mining: "The non trivial extraction of implicit, previously unknown, and potentially useful information from data" William J Frawley,
Data Mining. 1 Introduction 2 Data Mining methods. Alfred Holl Data Mining 1
 Data Mining 1 Introduction 2 Data Mining methods Alfred Holl Data Mining 1 1 Introduction 1.1 Motivation 1.2 Goals and problems 1.3 Definitions 1.4 Roots 1.5 Data Mining process 1.6 Epistemological constraints
Data Mining 1 Introduction 2 Data Mining methods Alfred Holl Data Mining 1 1 Introduction 1.1 Motivation 1.2 Goals and problems 1.3 Definitions 1.4 Roots 1.5 Data Mining process 1.6 Epistemological constraints
Proficy Monitoring & Analysis. Software to harness the industrial internet
 Proficy Monitoring & Analysis Suite Software to harness the industrial internet Prepare for the Industrial Internet Massive amounts of equipment and process GE, as one of the largest and most successful
Proficy Monitoring & Analysis Suite Software to harness the industrial internet Prepare for the Industrial Internet Massive amounts of equipment and process GE, as one of the largest and most successful
Example application (1) Telecommunication. Lecture 1: Data Mining Overview and Process. Example application (2) Health
 Telecommunication. Lecture 1: Data Mining Overview and Process. Example application (2) Health") Lecture 1: Data Mining Overview and Process What is data mining? Example applications Definitions Multi disciplinary Techniques Major challenges The data mining process History of data mining Data mining
Lecture 1: Data Mining Overview and Process What is data mining? Example applications Definitions Multi disciplinary Techniques Major challenges The data mining process History of data mining Data mining
Building a Data Quality Scorecard for Operational Data Governance
 Building a Data Quality Scorecard for Operational Data Governance A White Paper by David Loshin WHITE PAPER Table of Contents Introduction.... 1 Establishing Business Objectives.... 1 Business Drivers...
Building a Data Quality Scorecard for Operational Data Governance A White Paper by David Loshin WHITE PAPER Table of Contents Introduction.... 1 Establishing Business Objectives.... 1 Business Drivers...
An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset
 P P P Health An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset Peng Liu 1, Elia El-Darzi 2, Lei Lei 1, Christos Vasilakis 2, Panagiotis Chountas 2, and Wei Huang
P P P Health An Analysis of Missing Data Treatment Methods and Their Application to Health Care Dataset Peng Liu 1, Elia El-Darzi 2, Lei Lei 1, Christos Vasilakis 2, Panagiotis Chountas 2, and Wei Huang
Comparison of K-means and Backpropagation Data Mining Algorithms
 Comparison of K-means and Backpropagation Data Mining Algorithms Nitu Mathuriya, Dr. Ashish Bansal Abstract Data mining has got more and more mature as a field of basic research in computer science and
Comparison of K-means and Backpropagation Data Mining Algorithms Nitu Mathuriya, Dr. Ashish Bansal Abstract Data mining has got more and more mature as a field of basic research in computer science and
Revenue Recovering with Insolvency Prevention on a Brazilian Telecom Operator
 Revenue Recovering with Insolvency Prevention on a Brazilian Telecom Operator Carlos André R. Pinheiro Brasil Telecom SIA Sul ASP Lote D Bloco F 71.215-000 Brasília, DF, Brazil andrep@brasiltelecom.com.br
Revenue Recovering with Insolvency Prevention on a Brazilian Telecom Operator Carlos André R. Pinheiro Brasil Telecom SIA Sul ASP Lote D Bloco F 71.215-000 Brasília, DF, Brazil andrep@brasiltelecom.com.br
Data Mining Analytics for Business Intelligence and Decision Support
 Data Mining Analytics for Business Intelligence and Decision Support Chid Apte, T.J. Watson Research Center, IBM Research Division Knowledge Discovery and Data Mining (KDD) techniques are used for analyzing
Data Mining Analytics for Business Intelligence and Decision Support Chid Apte, T.J. Watson Research Center, IBM Research Division Knowledge Discovery and Data Mining (KDD) techniques are used for analyzing
The Big Data methodology in computer vision systems
 The Big Data methodology in computer vision systems Popov S.B. Samara State Aerospace University, Image Processing Systems Institute, Russian Academy of Sciences Abstract. I consider the advantages of
The Big Data methodology in computer vision systems Popov S.B. Samara State Aerospace University, Image Processing Systems Institute, Russian Academy of Sciences Abstract. I consider the advantages of
Transforming the Telecoms Business using Big Data and Analytics
 Transforming the Telecoms Business using Big Data and Analytics Event: ICT Forum for HR Professionals Venue: Meikles Hotel, Harare, Zimbabwe Date: 19 th 21 st August 2015 AFRALTI 1 Objectives Describe
Transforming the Telecoms Business using Big Data and Analytics Event: ICT Forum for HR Professionals Venue: Meikles Hotel, Harare, Zimbabwe Date: 19 th 21 st August 2015 AFRALTI 1 Objectives Describe
Stabilization by Conceptual Duplication in Adaptive Resonance Theory
 Stabilization by Conceptual Duplication in Adaptive Resonance Theory Louis Massey Royal Military College of Canada Department of Mathematics and Computer Science PO Box 17000 Station Forces Kingston, Ontario,
Stabilization by Conceptual Duplication in Adaptive Resonance Theory Louis Massey Royal Military College of Canada Department of Mathematics and Computer Science PO Box 17000 Station Forces Kingston, Ontario,
SIMCA 14 MASTER YOUR DATA SIMCA THE STANDARD IN MULTIVARIATE DATA ANALYSIS
 SIMCA 14 MASTER YOUR DATA SIMCA THE STANDARD IN MULTIVARIATE DATA ANALYSIS 02 Value From Data A NEW WORLD OF MASTERING DATA EXPLORE, ANALYZE AND INTERPRET Our world is increasingly dependent on data, and
SIMCA 14 MASTER YOUR DATA SIMCA THE STANDARD IN MULTIVARIATE DATA ANALYSIS 02 Value From Data A NEW WORLD OF MASTERING DATA EXPLORE, ANALYZE AND INTERPRET Our world is increasingly dependent on data, and
Gerard Mc Nulty Systems Optimisation Ltd gmcnulty@iol.ie/0876697867 BA.,B.A.I.,C.Eng.,F.I.E.I
 Gerard Mc Nulty Systems Optimisation Ltd gmcnulty@iol.ie/0876697867 BA.,B.A.I.,C.Eng.,F.I.E.I Data is Important because it: Helps in Corporate Aims Basis of Business Decisions Engineering Decisions Energy
Gerard Mc Nulty Systems Optimisation Ltd gmcnulty@iol.ie/0876697867 BA.,B.A.I.,C.Eng.,F.I.E.I Data is Important because it: Helps in Corporate Aims Basis of Business Decisions Engineering Decisions Energy
Chapter 12 Discovering New Knowledge Data Mining
 Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Chapter 12 Discovering New Knowledge Data Mining Becerra-Fernandez, et al. -- Knowledge Management 1/e -- 2004 Prentice Hall Additional material 2007 Dekai Wu Chapter Objectives Introduce the student to
Data Mining. Knowledge Discovery, Data Warehousing and Machine Learning Final remarks. Lecturer: JERZY STEFANOWSKI
 Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Data Mining Knowledge Discovery, Data Warehousing and Machine Learning Final remarks Lecturer: JERZY STEFANOWSKI Email: Jerzy.Stefanowski@cs.put.poznan.pl Data Mining a step in A KDD Process Data mining:
Three types of messages: A, B, C. Assume A is the oldest type, and C is the most recent type.
 Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
Chronological Sampling for Email Filtering Ching-Lung Fu 2, Daniel Silver 1, and James Blustein 2 1 Acadia University, Wolfville, Nova Scotia, Canada 2 Dalhousie University, Halifax, Nova Scotia, Canada
STATISTICA. Financial Institutions. Case Study: Credit Scoring. and
 Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Financial Institutions and STATISTICA Case Study: Credit Scoring STATISTICA Solutions for Business Intelligence, Data Mining, Quality Control, and Web-based Analytics Table of Contents INTRODUCTION: WHAT
Data Mining System, Functionalities and Applications: A Radical Review
 Data Mining System, Functionalities and Applications: A Radical Review Dr. Poonam Chaudhary System Programmer, Kurukshetra University, Kurukshetra Abstract: Data Mining is the process of locating potentially
Data Mining System, Functionalities and Applications: A Radical Review Dr. Poonam Chaudhary System Programmer, Kurukshetra University, Kurukshetra Abstract: Data Mining is the process of locating potentially
Social Media Mining. Data Mining Essentials
 Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Introduction Data production rate has been increased dramatically (Big Data) and we are able store much more data than before E.g., purchase data, social media data, mobile phone data Businesses and customers
Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad Email: Prasad_vungarala@yahoo.co.in
 96 Business Intelligence Journal January PREDICTION OF CHURN BEHAVIOR OF BANK CUSTOMERS USING DATA MINING TOOLS Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad
96 Business Intelligence Journal January PREDICTION OF CHURN BEHAVIOR OF BANK CUSTOMERS USING DATA MINING TOOLS Dr. U. Devi Prasad Associate Professor Hyderabad Business School GITAM University, Hyderabad
Data Quality Mining: Employing Classifiers for Assuring consistent Datasets
 Data Quality Mining: Employing Classifiers for Assuring consistent Datasets Fabian Grüning Carl von Ossietzky Universität Oldenburg, Germany, fabian.gruening@informatik.uni-oldenburg.de Abstract: Independent
Data Quality Mining: Employing Classifiers for Assuring consistent Datasets Fabian Grüning Carl von Ossietzky Universität Oldenburg, Germany, fabian.gruening@informatik.uni-oldenburg.de Abstract: Independent
Iranian J Env Health Sci Eng, 2004, Vol.1, No.2, pp.51-57. Application of Intelligent System for Water Treatment Plant Operation.
 Iranian J Env Health Sci Eng, 2004, Vol.1, No.2, pp.51-57 Application of Intelligent System for Water Treatment Plant Operation *A Mirsepassi Dept. of Environmental Health Engineering, School of Public
Iranian J Env Health Sci Eng, 2004, Vol.1, No.2, pp.51-57 Application of Intelligent System for Water Treatment Plant Operation *A Mirsepassi Dept. of Environmental Health Engineering, School of Public
ANALYSIS OF WEBSITE USAGE WITH USER DETAILS USING DATA MINING PATTERN RECOGNITION
 ANALYSIS OF WEBSITE USAGE WITH USER DETAILS USING DATA MINING PATTERN RECOGNITION K.Vinodkumar 1, Kathiresan.V 2, Divya.K 3 1 MPhil scholar, RVS College of Arts and Science, Coimbatore, India. 2 HOD, Dr.SNS
ANALYSIS OF WEBSITE USAGE WITH USER DETAILS USING DATA MINING PATTERN RECOGNITION K.Vinodkumar 1, Kathiresan.V 2, Divya.K 3 1 MPhil scholar, RVS College of Arts and Science, Coimbatore, India. 2 HOD, Dr.SNS
Data Mining Applications in Higher Education
 Executive report Data Mining Applications in Higher Education Jing Luan, PhD Chief Planning and Research Officer, Cabrillo College Founder, Knowledge Discovery Laboratories Table of contents Introduction..............................................................2
Executive report Data Mining Applications in Higher Education Jing Luan, PhD Chief Planning and Research Officer, Cabrillo College Founder, Knowledge Discovery Laboratories Table of contents Introduction..............................................................2
How To Use Neural Networks In Data Mining
 International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
International Journal of Electronics and Computer Science Engineering 1449 Available Online at www.ijecse.org ISSN- 2277-1956 Neural Networks in Data Mining Priyanka Gaur Department of Information and
FREQUENT PATTERN MINING FOR EFFICIENT LIBRARY MANAGEMENT
 FREQUENT PATTERN MINING FOR EFFICIENT LIBRARY MANAGEMENT ANURADHA.T Assoc.prof, atadiparty@yahoo.co.in SRI SAI KRISHNA.A saikrishna.gjc@gmail.com SATYATEJ.K satyatej.koganti@gmail.com NAGA ANIL KUMAR.G
FREQUENT PATTERN MINING FOR EFFICIENT LIBRARY MANAGEMENT ANURADHA.T Assoc.prof, atadiparty@yahoo.co.in SRI SAI KRISHNA.A saikrishna.gjc@gmail.com SATYATEJ.K satyatej.koganti@gmail.com NAGA ANIL KUMAR.G
Application of Predictive Model for Elementary Students with Special Needs in New Era University
 Application of Predictive Model for Elementary Students with Special Needs in New Era University Jannelle ds. Ligao, Calvin Jon A. Lingat, Kristine Nicole P. Chiu, Cym Quiambao, Laurice Anne A. Iglesia
Application of Predictive Model for Elementary Students with Special Needs in New Era University Jannelle ds. Ligao, Calvin Jon A. Lingat, Kristine Nicole P. Chiu, Cym Quiambao, Laurice Anne A. Iglesia
Crime Pattern Analysis
 Crime Pattern Analysis Megaputer Case Study in Text Mining Vijay Kollepara Sergei Ananyan www.megaputer.com Megaputer Intelligence 120 West Seventh Street, Suite 310 Bloomington, IN 47404 USA +1 812-330-01
Crime Pattern Analysis Megaputer Case Study in Text Mining Vijay Kollepara Sergei Ananyan www.megaputer.com Megaputer Intelligence 120 West Seventh Street, Suite 310 Bloomington, IN 47404 USA +1 812-330-01
Using Data Mining for Mobile Communication Clustering and Characterization
 Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
Using Data Mining for Mobile Communication Clustering and Characterization A. Bascacov *, C. Cernazanu ** and M. Marcu ** * Lasting Software, Timisoara, Romania ** Politehnica University of Timisoara/Computer
not possible or was possible at a high cost for collecting the data.
 Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
Data Mining and Knowledge Discovery Generating knowledge from data Knowledge Discovery Data Mining White Paper Organizations collect a vast amount of data in the process of carrying out their day-to-day
Index Contents Page No. Introduction . Data Mining & Knowledge Discovery
 Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Index Contents Page No. 1. Introduction 1 1.1 Related Research 2 1.2 Objective of Research Work 3 1.3 Why Data Mining is Important 3 1.4 Research Methodology 4 1.5 Research Hypothesis 4 1.6 Scope 5 2.
Pentaho Data Mining Last Modified on January 22, 2007
 Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
Pentaho Data Mining Copyright 2007 Pentaho Corporation. Redistribution permitted. All trademarks are the property of their respective owners. For the latest information, please visit our web site at www.pentaho.org
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set
 EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
EM Clustering Approach for Multi-Dimensional Analysis of Big Data Set Amhmed A. Bhih School of Electrical and Electronic Engineering Princy Johnson School of Electrical and Electronic Engineering Martin
Data Mining in Telecommunication
 Data Mining in Telecommunication Mohsin Nadaf & Vidya Kadam Department of IT, Trinity College of Engineering & Research, Pune, India E-mail : mohsinanadaf@gmail.com Abstract Telecommunication is one of
Data Mining in Telecommunication Mohsin Nadaf & Vidya Kadam Department of IT, Trinity College of Engineering & Research, Pune, India E-mail : mohsinanadaf@gmail.com Abstract Telecommunication is one of
SPATIAL DATA CLASSIFICATION AND DATA MINING
 , pp.-40-44. Available online at http://www. bioinfo. in/contents. php?id=42 SPATIAL DATA CLASSIFICATION AND DATA MINING RATHI J.B. * AND PATIL A.D. Department of Computer Science & Engineering, Jawaharlal
, pp.-40-44. Available online at http://www. bioinfo. in/contents. php?id=42 SPATIAL DATA CLASSIFICATION AND DATA MINING RATHI J.B. * AND PATIL A.D. Department of Computer Science & Engineering, Jawaharlal
How To Use Data Mining For Knowledge Management In Technology Enhanced Learning
 Proceedings of the 6th WSEAS International Conference on Applications of Electrical Engineering, Istanbul, Turkey, May 27-29, 2007 115 Data Mining for Knowledge Management in Technology Enhanced Learning
Proceedings of the 6th WSEAS International Conference on Applications of Electrical Engineering, Istanbul, Turkey, May 27-29, 2007 115 Data Mining for Knowledge Management in Technology Enhanced Learning
Data Isn't Everything
 June 17, 2015 Innovate Forward Data Isn't Everything The Challenges of Big Data, Advanced Analytics, and Advance Computation Devices for Transportation Agencies. Using Data to Support Mission, Administration,
June 17, 2015 Innovate Forward Data Isn't Everything The Challenges of Big Data, Advanced Analytics, and Advance Computation Devices for Transportation Agencies. Using Data to Support Mission, Administration,
20 A Visualization Framework For Discovering Prepaid Mobile Subscriber Usage Patterns
 20 A Visualization Framework For Discovering Prepaid Mobile Subscriber Usage Patterns John Aogon and Patrick J. Ogao Telecommunications operators in developing countries are faced with a problem of knowing
20 A Visualization Framework For Discovering Prepaid Mobile Subscriber Usage Patterns John Aogon and Patrick J. Ogao Telecommunications operators in developing countries are faced with a problem of knowing
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP
 Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
Improving the Performance of Data Mining Models with Data Preparation Using SAS Enterprise Miner Ricardo Galante, SAS Institute Brasil, São Paulo, SP ABSTRACT In data mining modelling, data preparation
INTELLIGENT ENERGY MANAGEMENT OF ELECTRICAL POWER SYSTEMS WITH DISTRIBUTED FEEDING ON THE BASIS OF FORECASTS OF DEMAND AND GENERATION Chr.
 INTELLIGENT ENERGY MANAGEMENT OF ELECTRICAL POWER SYSTEMS WITH DISTRIBUTED FEEDING ON THE BASIS OF FORECASTS OF DEMAND AND GENERATION Chr. Meisenbach M. Hable G. Winkler P. Meier Technology, Laboratory
INTELLIGENT ENERGY MANAGEMENT OF ELECTRICAL POWER SYSTEMS WITH DISTRIBUTED FEEDING ON THE BASIS OF FORECASTS OF DEMAND AND GENERATION Chr. Meisenbach M. Hable G. Winkler P. Meier Technology, Laboratory
Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis
 Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis (Version 1.17) For validation Document version 0.1 7/7/2014 Contents What is SAP Predictive Analytics?... 3
Consumption of OData Services of Open Items Analytics Dashboard using SAP Predictive Analysis (Version 1.17) For validation Document version 0.1 7/7/2014 Contents What is SAP Predictive Analytics?... 3
Data Mining Framework for Direct Marketing: A Case Study of Bank Marketing
 www.ijcsi.org 198 Data Mining Framework for Direct Marketing: A Case Study of Bank Marketing Lilian Sing oei 1 and Jiayang Wang 2 1 School of Information Science and Engineering, Central South University
www.ijcsi.org 198 Data Mining Framework for Direct Marketing: A Case Study of Bank Marketing Lilian Sing oei 1 and Jiayang Wang 2 1 School of Information Science and Engineering, Central South University
Introduction. A. Bellaachia Page: 1
 Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
Introduction 1. Objectives... 3 2. What is Data Mining?... 4 3. Knowledge Discovery Process... 5 4. KD Process Example... 7 5. Typical Data Mining Architecture... 8 6. Database vs. Data Mining... 9 7.
Chapter 20: Data Analysis
 Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Chapter 20: Data Analysis Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 20: Data Analysis Decision Support Systems Data Warehousing Data Mining Classification
Research of Postal Data mining system based on big data
 3rd International Conference on Mechatronics, Robotics and Automation (ICMRA 2015) Research of Postal Data mining system based on big data Xia Hu 1, Yanfeng Jin 1, Fan Wang 1 1 Shi Jiazhuang Post & Telecommunication
3rd International Conference on Mechatronics, Robotics and Automation (ICMRA 2015) Research of Postal Data mining system based on big data Xia Hu 1, Yanfeng Jin 1, Fan Wang 1 1 Shi Jiazhuang Post & Telecommunication
Text Analytics. A business guide
 Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
Text Analytics A business guide February 2014 Contents 3 The Business Value of Text Analytics 4 What is Text Analytics? 6 Text Analytics Methods 8 Unstructured Meets Structured Data 9 Business Application
In this tutorial, we try to build a roc curve from a logistic regression.
 Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
Subject In this tutorial, we try to build a roc curve from a logistic regression. Regardless the software we used, even for commercial software, we have to prepare the following steps when we want build
LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE. indhubatchvsa@gmail.com
 LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE 1 S.Manikandan, 2 S.Abirami, 2 R.Indumathi, 2 R.Nandhini, 2 T.Nanthini 1 Assistant Professor, VSA group of institution, Salem. 2 BE(ECE), VSA
LOCAL SURFACE PATCH BASED TIME ATTENDANCE SYSTEM USING FACE 1 S.Manikandan, 2 S.Abirami, 2 R.Indumathi, 2 R.Nandhini, 2 T.Nanthini 1 Assistant Professor, VSA group of institution, Salem. 2 BE(ECE), VSA
Discretization and grouping: preprocessing steps for Data Mining
 Discretization and grouping: preprocessing steps for Data Mining PetrBerka 1 andivanbruha 2 1 LaboratoryofIntelligentSystems Prague University of Economic W. Churchill Sq. 4, Prague CZ 13067, Czech Republic
Discretization and grouping: preprocessing steps for Data Mining PetrBerka 1 andivanbruha 2 1 LaboratoryofIntelligentSystems Prague University of Economic W. Churchill Sq. 4, Prague CZ 13067, Czech Republic
CRISP-DM: Towards a Standard Process Model for Data Mining
 CRISP-DM: Towards a Standard Process Model for Mining Rüdiger Wirth DaimlerChrysler Research & Technology FT3/KL PO BOX 2360 89013 Ulm, Germany ruediger.wirth@daimlerchrysler.com Jochen Hipp Wilhelm-Schickard-Institute,
CRISP-DM: Towards a Standard Process Model for Mining Rüdiger Wirth DaimlerChrysler Research & Technology FT3/KL PO BOX 2360 89013 Ulm, Germany ruediger.wirth@daimlerchrysler.com Jochen Hipp Wilhelm-Schickard-Institute,
Analecta Vol. 8, No. 2 ISSN 2064-7964
 EXPERIMENTAL APPLICATIONS OF ARTIFICIAL NEURAL NETWORKS IN ENGINEERING PROCESSING SYSTEM S. Dadvandipour Institute of Information Engineering, University of Miskolc, Egyetemváros, 3515, Miskolc, Hungary,
EXPERIMENTAL APPLICATIONS OF ARTIFICIAL NEURAL NETWORKS IN ENGINEERING PROCESSING SYSTEM S. Dadvandipour Institute of Information Engineering, University of Miskolc, Egyetemváros, 3515, Miskolc, Hungary,
Tracking Groups of Pedestrians in Video Sequences
 Tracking Groups of Pedestrians in Video Sequences Jorge S. Marques Pedro M. Jorge Arnaldo J. Abrantes J. M. Lemos IST / ISR ISEL / IST ISEL INESC-ID / IST Lisbon, Portugal Lisbon, Portugal Lisbon, Portugal
Tracking Groups of Pedestrians in Video Sequences Jorge S. Marques Pedro M. Jorge Arnaldo J. Abrantes J. M. Lemos IST / ISR ISEL / IST ISEL INESC-ID / IST Lisbon, Portugal Lisbon, Portugal Lisbon, Portugal
Divide-n-Discover Discretization based Data Exploration Framework for Healthcare Analytics
 for Healthcare Analytics Si-Chi Chin,KiyanaZolfaghar,SenjutiBasuRoy,AnkurTeredesai,andPaulAmoroso Institute of Technology, The University of Washington -Tacoma,900CommerceStreet,Tacoma,WA980-00,U.S.A.
for Healthcare Analytics Si-Chi Chin,KiyanaZolfaghar,SenjutiBasuRoy,AnkurTeredesai,andPaulAmoroso Institute of Technology, The University of Washington -Tacoma,900CommerceStreet,Tacoma,WA980-00,U.S.A.
Mobile Phone APP Software Browsing Behavior using Clustering Analysis
 Proceedings of the 2014 International Conference on Industrial Engineering and Operations Management Bali, Indonesia, January 7 9, 2014 Mobile Phone APP Software Browsing Behavior using Clustering Analysis
Proceedings of the 2014 International Conference on Industrial Engineering and Operations Management Bali, Indonesia, January 7 9, 2014 Mobile Phone APP Software Browsing Behavior using Clustering Analysis
Data Cleansing for Remote Battery System Monitoring
 Data Cleansing for Remote Battery System Monitoring Gregory W. Ratcliff Randall Wald Taghi M. Khoshgoftaar Director, Life Cycle Management Senior Research Associate Director, Data Mining and Emerson Network
Data Cleansing for Remote Battery System Monitoring Gregory W. Ratcliff Randall Wald Taghi M. Khoshgoftaar Director, Life Cycle Management Senior Research Associate Director, Data Mining and Emerson Network
IBM Security. 2013 IBM Corporation. 2013 IBM Corporation
 IBM Security Security Intelligence What is Security Intelligence? Security Intelligence --noun 1.the real-time collection, normalization and analytics of the data generated by users, applications and infrastructure
IBM Security Security Intelligence What is Security Intelligence? Security Intelligence --noun 1.the real-time collection, normalization and analytics of the data generated by users, applications and infrastructure
Data Mining and KDD: A Shifting Mosaic. Joseph M. Firestone, Ph.D. White Paper No. Two. March 12, 1997
 1 of 11 5/24/02 3:50 PM Data Mining and KDD: A Shifting Mosaic By Joseph M. Firestone, Ph.D. White Paper No. Two March 12, 1997 The Idea of Data Mining Data Mining is an idea based on a simple analogy.
1 of 11 5/24/02 3:50 PM Data Mining and KDD: A Shifting Mosaic By Joseph M. Firestone, Ph.D. White Paper No. Two March 12, 1997 The Idea of Data Mining Data Mining is an idea based on a simple analogy.
Sanjeev Kumar. contribute
 RESEARCH ISSUES IN DATAA MINING Sanjeev Kumar I.A.S.R.I., Library Avenue, Pusa, New Delhi-110012 sanjeevk@iasri.res.in 1. Introduction The field of data mining and knowledgee discovery is emerging as a
RESEARCH ISSUES IN DATAA MINING Sanjeev Kumar I.A.S.R.I., Library Avenue, Pusa, New Delhi-110012 sanjeevk@iasri.res.in 1. Introduction The field of data mining and knowledgee discovery is emerging as a
Application of Simulation Models in Operations A Success Story
 Application of Simulation Models in Operations A Success Story David Schumann and Gregory Davis, Valero Energy Company, and Piyush Shah, Aspen Technology, Inc. Abstract Process simulation models can offer
Application of Simulation Models in Operations A Success Story David Schumann and Gregory Davis, Valero Energy Company, and Piyush Shah, Aspen Technology, Inc. Abstract Process simulation models can offer
Process Modelling from Insurance Event Log
 Process Modelling from Insurance Event Log P.V. Kumaraguru Research scholar, Dr.M.G.R Educational and Research Institute University Chennai- 600 095 India Dr. S.P. Rajagopalan Professor Emeritus, Dr. M.G.R
Process Modelling from Insurance Event Log P.V. Kumaraguru Research scholar, Dr.M.G.R Educational and Research Institute University Chennai- 600 095 India Dr. S.P. Rajagopalan Professor Emeritus, Dr. M.G.R
Express Introductory Training in ANSYS Fluent Lecture 1 Introduction to the CFD Methodology
 Express Introductory Training in ANSYS Fluent Lecture 1 Introduction to the CFD Methodology Dimitrios Sofialidis Technical Manager, SimTec Ltd. Mechanical Engineer, PhD PRACE Autumn School 2013 - Industry
Express Introductory Training in ANSYS Fluent Lecture 1 Introduction to the CFD Methodology Dimitrios Sofialidis Technical Manager, SimTec Ltd. Mechanical Engineer, PhD PRACE Autumn School 2013 - Industry
NEURAL networks [5] are universal approximators [6]. It
![NEURAL networks [5] are universal approximators [6]. It](/thumbs/25/6270299.jpg "NEURAL networks [5] are universal approximators [6]. It") Proceedings of the 2013 Federated Conference on Computer Science and Information Systems pp. 183 190 An Investment Strategy for the Stock Exchange Using Neural Networks Antoni Wysocki and Maciej Ławryńczuk
Proceedings of the 2013 Federated Conference on Computer Science and Information Systems pp. 183 190 An Investment Strategy for the Stock Exchange Using Neural Networks Antoni Wysocki and Maciej Ławryńczuk
Mining an Online Auctions Data Warehouse
 Proceedings of MASPLAS'02 The Mid-Atlantic Student Workshop on Programming Languages and Systems Pace University, April 19, 2002 Mining an Online Auctions Data Warehouse David Ulmer Under the guidance
Proceedings of MASPLAS'02 The Mid-Atlantic Student Workshop on Programming Languages and Systems Pace University, April 19, 2002 Mining an Online Auctions Data Warehouse David Ulmer Under the guidance
How To Make A Credit Risk Model For A Bank Account
 TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
TRANSACTIONAL DATA MINING AT LLOYDS BANKING GROUP Csaba Főző csaba.fozo@lloydsbanking.com 15 October 2015 CONTENTS Introduction 04 Random Forest Methodology 06 Transactional Data Mining Project 17 Conclusions
An Overview of Knowledge Discovery Database and Data mining Techniques
 An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
An Overview of Knowledge Discovery Database and Data mining Techniques Priyadharsini.C 1, Dr. Antony Selvadoss Thanamani 2 M.Phil, Department of Computer Science, NGM College, Pollachi, Coimbatore, Tamilnadu,
SECURITY METRICS: MEASUREMENTS TO SUPPORT THE CONTINUED DEVELOPMENT OF INFORMATION SECURITY TECHNOLOGY
 SECURITY METRICS: MEASUREMENTS TO SUPPORT THE CONTINUED DEVELOPMENT OF INFORMATION SECURITY TECHNOLOGY Shirley Radack, Editor Computer Security Division Information Technology Laboratory National Institute
SECURITY METRICS: MEASUREMENTS TO SUPPORT THE CONTINUED DEVELOPMENT OF INFORMATION SECURITY TECHNOLOGY Shirley Radack, Editor Computer Security Division Information Technology Laboratory National Institute
Data Warehousing and Data Mining in Business Applications
 133 Data Warehousing and Data Mining in Business Applications Eesha Goel CSE Deptt. GZS-PTU Campus, Bathinda. Abstract Information technology is now required in all aspect of our lives that helps in business
133 Data Warehousing and Data Mining in Business Applications Eesha Goel CSE Deptt. GZS-PTU Campus, Bathinda. Abstract Information technology is now required in all aspect of our lives that helps in business
Journal of Chemical and Pharmaceutical Research, 2015, 7(3):1388-1392. Research Article. E-commerce recommendation system on cloud computing
:1388-1392. Research Article. E-commerce recommendation system on cloud computing") Available online www.jocpr.com Journal of Chemical and Pharmaceutical Research, 2015, 7(3):1388-1392 Research Article ISSN : 0975-7384 CODEN(USA) : JCPRC5 E-commerce recommendation system on cloud computing
Available online www.jocpr.com Journal of Chemical and Pharmaceutical Research, 2015, 7(3):1388-1392 Research Article ISSN : 0975-7384 CODEN(USA) : JCPRC5 E-commerce recommendation system on cloud computing
Data Mining: A Preprocessing Engine
 Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Journal of Computer Science 2 (9): 735-739, 2006 ISSN 1549-3636 2005 Science Publications Data Mining: A Preprocessing Engine Luai Al Shalabi, Zyad Shaaban and Basel Kasasbeh Applied Science University,
Machine Learning, Data Mining, and Knowledge Discovery: An Introduction
 Machine Learning, Data Mining, and Knowledge Discovery: An Introduction AHPCRC Workshop - 8/17/10 - Dr. Martin Based on slides by Gregory Piatetsky-Shapiro from Kdnuggets http://www.kdnuggets.com/data_mining_course/
Machine Learning, Data Mining, and Knowledge Discovery: An Introduction AHPCRC Workshop - 8/17/10 - Dr. Martin Based on slides by Gregory Piatetsky-Shapiro from Kdnuggets http://www.kdnuggets.com/data_mining_course/