How long is long enough?
|
|
|
- Elijah Hoover
- 8 years ago
- Views:
Transcription
1 How long is long enough? - Modeling to predict genome assembly performance - Hayan Lee@Schatz Lab Feb 26, 2014 Quantitative Biology Seminar 1

2 Outline Background Assembly history Recent sequencing technology + Algorithm Motivation Lander-Waterman statistics Economical meaning (ROI) Our approach Genome assembly challenges Support Vector Regression (SVR) Feature engineering Model fitting Prediction : Genome assembly performance Contribution 2



3 Genome Assembly Sanger et al. 1 st Complete Organism X5375 bp Fleischmann et al. 1 st Free Living Organism TIGR Assembler. 1.8Mbp C.elegans SC 1 st Multicellular Organism BAC-by-BAC Phrap. 97Mbp Myers et al. 1 st Large WGS Assembly. Celera Assembler. 116 Mbp Venter et al., IHGSC Human Genome Celera Assembler/GigaAssembler. 2.9 Gbp Li et al. 1 st Large SGS Assembly. SOAPdenovo 2.2 Gbp 3

4 Assembling a Genome 1. Shear & Sequence DNA 2. Construct assembly graph from overlapping reads AGCCTAGGGATGCGCGACACGT GGATGCGCGACACGTCGCATATCCGGTTTGGTCAACCTCGGACGGAC 3. Simplify assembly graph CAACCTCGGACGGACCTCAGCGAA 4. Detangle graph with long reads, mates, and other links 4


5 Assembly Complexity A R B R C R B A R Long Reads is the solution!!! C



6 Long Read Sequencing Technology PacBio RS II Moleculo Oxford Nanopore CSHL/PacBio (Voskoboynik et al. 2013) AGBT


7 Read Length (bp) PacBio SMRT Sequencing Road Map October, 2013 The new P5 polymerase and C3 chemistry combination (P5-C3) extends the industry-leading sequence read lengths to an average of approximately 8,500 bases, with the longest reads exceeding 30,000 bases, doubling throughput P4 C2 P5 C3 8,500 bp C2 C2 Early chemistries LPR FCR ECR


8 S. cerevisiae W303 PacBio RS II sequencing at CSHL by Dick McCombie Size selection using an 7 Kb elution window on a BluePippin device from Sage Science Over 175x coverage in 2 days using P5-C3 Mean: x over 10kbp 8.7x over 20kb Max: 36,861bp

 PLOS One.")

9 PacBio Assembly Algorithms PBJelly PacBioToCA & ECTools HGAP & Quiver Gap Filling and Assembly Upgrade English et al (2012) PLOS One. 7(11): e47768 Hybrid/PB-only Error Correction Koren, Schatz, et al (2012) Nature Biotechnology. 30: PB-only Correction & Polishing Chin et al (2013) Nature Methods. 10: < 5x PacBio Coverage > 50x

10 Many Genomes Are Sequenced Many Questions Are Raised But How long should the read length be? What coverage should be used? Given the read length and coverage, How long are the contigs? How many contigs? How many reads are in each contigs? How big are the gaps? 10

11 Previous Works 11

12 Lander-Waterman Statistics G : Genome size L : read Length N : Number of reads C : Coverage = NL G Note : Poisson distribution is assumed! P x; λ = λx e λ x! P(No reads start in a given position) = C0 e C 0! =e C P(At least 1 read starts in a given position) = 1 e C 12
 = C0 e C 0!")
13 Lander-Waterman Statistics P(No reads start in a given position) = C0 e C 0! =e C P(At least 1 reads starts in a given position) = 1 e C Expected # of bases in Gaps = e C G Expected # of bases in Contigs = (1 e C )G Expected # of contigs = e C N Mean of contig size = Mean of contig size = (derivation) (1 e C )G e C N expected # of bases in contigs expected # of contigs = (ec 1)G N = (ec 1)L C expeated # of bases in contigs expected # of contigs = (ec 1)L c = (e(1 θ)c 1)L c 13
G N = (ec 1)L C expeated # of bases in contigs")

14 HG19 Genome Assembly Performance by Lander-Waterman Statistics Two key observations 1. Contig over genome size 2. Read Length vs. Coverage Technology vs. Money = (e(1 θ)c 1)L C 14

 to support reads up to 0.5Mbp Data (X, Y) Machine Learning Algorithm (SVR) Learned Model Data (X,?")
15 Empirical Data-driven Approach We selected 26 species across tree of life and exhaustively analyzed their assemblies using simulated reads for 4 different length (6 for HG19) and 4 different coverage per species For the extra long reads, we fixed the Celera Assembler(CA) to support reads up to 0.5Mbp Data (X, Y) Machine Learning Algorithm (SVR) Learned Model Data (X,?) Learned Model Predicted Result 15
 Machine Learning Algorithm (SVR) Learned Model Data (X,?")
16 26 Species Across Tree of Life 16


17 HG19 Genome Assembly Performance by Our Simulation Read Length has stronger impact than coverage 17

18 Why? Lander-Waterman Statistics Assumptions!!! If genome is a random sequence, it will work Our Approach Stop assuming that we cannot guarantee!!! We tried to assume as least as possible. Instead of building on top of assumptions, we let the model learn from the data Empirical data-driven approach 18


19 Repeats 19
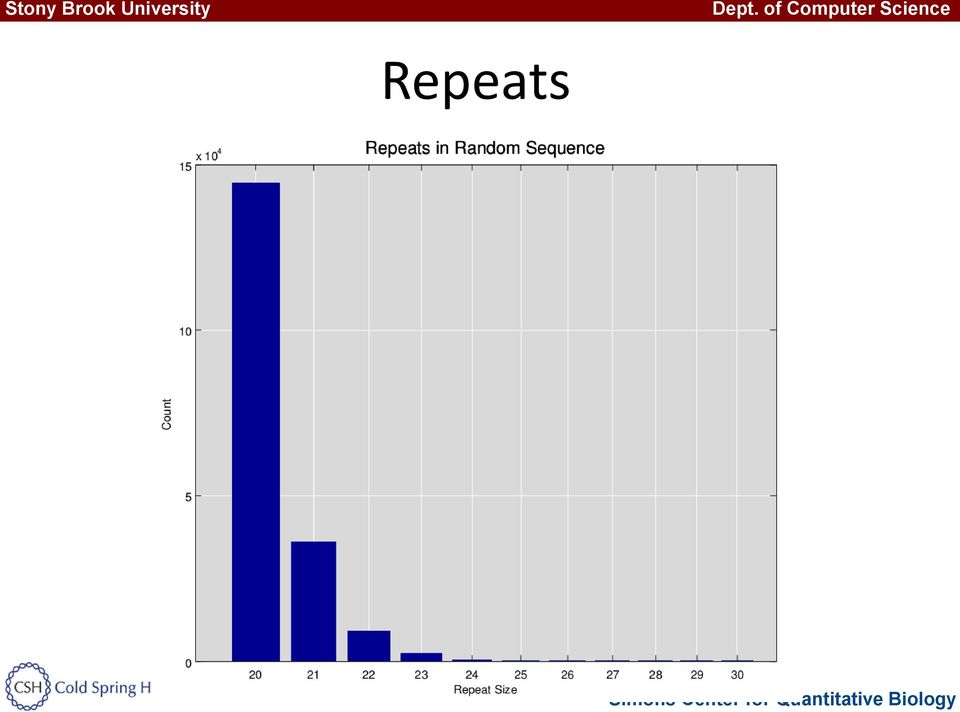

20 Repeats in Rice 20

21 Our Goal To predict genome assembly performance Performance(%) N50 from assembly N50 of chromosome segments 100 Target N50 21
22 Assembly Challenge Read Length Coverage Repeats Genome Size 22
23 Assembly Challenge (1) Read Length Read length is very important A matter of technology The longer is the better Quality was important but can be corrected PacBio produces long reads, but low quality (~15% error rate) Error correction pipeline are developed Errors are corrected very accurately up to 99% 23
 - Read Length 24")
24 - Assembly Challenge (1) - Read Length 24
25 Assembly Challenge (2) Coverage A matter of money Using perfect reads, assembly performance increased for most genomes : Lower bound Using real reads, overall performance line will shift to the higher coverage The higher is the better (?) But still it suggests that there would be a threshold that can maximize your return on investment (ROI) 25
26 Assembly Challenge (2) Coverage 26


27 A. thaliana Ler-0 Genome size: Chromosome N50: Corrected coverage: Mbp 23.0 Mbp 20x over 10kb A. thaliana Ler-0 sequenced at PacBio Sequenced using the previous P4 enzyme and C2 chemistry Size selection using an 8 Kb to 50 Kb elution window on a BluePippin device from Sage Science Total coverage >119x Sum of Contig Lengths: 149.5Mb N50 Contig Length: 8.4 Mb Number of Contigs: 1788 High quality assembly of chromosome arms Assembly Performance: 8.4Mbp/23Mbp = 36% MiSeq assembly: 63kbp/23Mbp =.2%
")
28 Assembly Challenge (2) Coverage 28
29 Assembly Challenge (3) Repeats Genome is not a random sequence Repeat hurts genome assembly performance Isolating the impact of repeats is not trivial Quantifying repeat characteristics is not trivial as well The longest repeat size # of repeats > read length 29
30 Assembly Challenge (3) Repeats Arabidopsis vs. Fruit fly Arabidopsis (120M) Longest repeat: 44kbp Fruit fly (130M) Longest repeat: 30kbp Mean Read Length # of repeats > read length # of repeats > read length 3, , , ,
")
31 Assembly Challenge (3) Repeats 31

32 $ $ 32
33 Assembly Challenge (4) Genome Size Increase the assembly complexity Make a hard problem harder. 33
34 Assembly Challenge (4) Genome Size 34
35 S. cerevisiae W303 S288C Reference sequence 12.1Mbp; 16 chromo + mitochondria; N50: 924kbp PacBio assembly using HGAP + Celera Assembler 12.4Mbp; 21 non-redundant contigs; N50: 811kbp; >99.8% id
36 36
 Genome Size 37")
37 Assembly Challenge (4) Genome Size 37
38 Our Goal To predict genome assembly performance Performance(%) N50 from assembly N50 of chromosome segments 100 f Read Length Coverage Repeats Genome Size 38
39 Challenges for Prediction Sample size is small Quality is not guaranteed Predictive Power Overfitting Support Vector Regression (SVR) Cross Validation 39
40 Support Vector Regression (SVR) Epsilon insensitive loss function L(y, f x, w ) = 0, if y f x, w ε y f x, w ε, otherwise Benefits 1. Simplest fit 2. Robust to outliers (ex) Example of onedimensional linear regression function with epsilon intensive band. 40
41 Optimization(1) Minimize 1 w C n i=0 (ξ i + ξ i ) Subject to y i w i x il y i + w i x il b ε + ξ i + b ε + ξ i ξ i, ξ i 0 for i = 1,2,, l (ex) Linear case Generalized Lagrange Multiplier (Karush Kuhn Tucker conditions) 41
 conditions Dual max 1 2 l i,j=0 α i α i α j α j l <")
42 Optimization (2) Primal min 1 w C n i=0 (ξ i + ξ i ) s.t y i w i x il b ε + ξ i y i + w i x il + b ε + ξ i ξ i, ξ i for i = 1,2,, l Karush Kuhn Tucker(KKT) conditions Dual max 1 2 l i,j=0 α i α i α j α j l < x i, x j > ε i=0 α i + α i l + i=0 y i α i α i s.t. i=0 l α i α i = 0 0 α i, α i C Kernel 42
43 Optimization (3) Parameters C } SVM ε Kernel Kernel type Linear K(x i, x j )= < x i, x j > Non-Linear meta-parameters as user-defined inputs. Polynomial K(x i, x j )=(x i T x j + 1) d usually based on applicationdomain knowledge and also should reflect distribution of input (x) values of the training data. Radial Basis Function(RBF) K(x i, x j )=exp( 1 2σ 2 x i x j 2 ) Kernel Parameters Depends on kernel type 43
44 SVR Model Fitting Using four features Read Length Coverage Genome Size # of Repeats > Read Length 44
45 Feature Engineering (1) Correlation Coefficient Performance vs. genome size R = Performance vs. Read Length R =
46 Feature Engineering (2) Correlation Coefficient Performance and log (genome size) R = Performance and log (read length) R = 0.32 Performance and log (genome size)/ log (read length) R = 0.6 Performance and log (coverage ) R = 0.58 Performance and log (# of repeats longer than read length) R =

47 C How long is long enough? 47 Lee, H, Gurtowski, J, Yoo, S, Marcus, S, McCombie, WR, Schatz MC et al. Simons (2014) Center In preparation for Quantitative Biology

48 Assembly N50 / Chromosome N50 C3 C C2 C How long is long enough? Lee, H, Gurtowski, J, Yoo, S, Marcus, S, McCombie, WR, Schatz MC et al. Simons (2014) Center In preparation for Quantitative Biology

49 C5???? C4???? C C How long is long enough? Lee, H, Gurtowski, J, Yoo, S, Marcus, S, McCombie, WR, Schatz MC et al. Simons (2014) Center In preparation for Quantitative Biology

50 Our Goal To predict genome assembly performance Performance(%) N50 from assembly N50 of chromosome segments 100 Read Length Coverage Repeats Genome Size 1. How do we measure predictive power? 2. How do we avoid overfitting? 50
51 Cross Validation K-fold Cross Validation A variation of Leave-One-Out Cross Validation (LOOCV) Leave one species out approach (LOSO) <- Our approach A variation of Leave-One-Out Cross Validation (LOOCV) Use 25 species as training data, test 1 species to measure predictive power Avoid overfitting Model selection by predictive power 51

52 How long is long enough? 52 Lee, H, Gurtowski, J, Yoo, S, Marcus, S, McCombie, WR, Schatz MC et al. Simons (2014) Center In preparation for Quantitative Biology
53 Prediction Average of residual is 10% We can predict the new genome assembly performance in 10% of error residual boundary Genome size, read length and coverage used explicitly Repeats are included implicitly 53

54 Web Service How long is long enough? 54 Lee, H, Gurtowski, J, Yoo, S, Marcus, S, McCombie, WR, Schatz MC et al. Simons (2014) Center In preparation for Quantitative Biology
55 Contribution Empirical data driven approach We selected 26 species across tree of life and exhaustively analyzed their For the extra long reads, we fixed the Celera Assembler(CA) to support reads up to 0.5Mbp We made a new model that predicts genome assembly performance Prediction in 10% of residue boundary. Our prediction is independent from any error model so that our model will provide upper bound and can be used for the general purpose The Marginal coverage forms around 20x-40x assuming no errors in reads Read Length is more important given that we have enough coverage 55
56 Contribution Recommendations < 100 Mbp: 100x PB C3-P5 expect near perfect chromosome arms < 1GB: 100x PB C3-P5 expect high quality assembly: contig N50 over 1Mbp > 1GB: hybrid/gap filling expect contig N50 to be 100kbp 1Mbp > 5GB: mschatz@cshl.edu Machine Learning & Big Data Contact hlee@cshl.edu 56

57 Acknowledgements CSHL Schatz Lab Mike Schatz James Gurtowski Shoshana Marcus BNL Shinjae Yoo McCombie Lab Dick McCombie Eric Antoniou Elena Ghiban Melissa Kramer Panchajanya Deshpande Senem Mavruk Eskipehlivan Scott Ethe Sayers Sara Goodwin 57
58 Thank You Q & A 58
Next Generation Sequencing
 Next Generation Sequencing Technology and applications 10/1/2015 Jeroen Van Houdt - Genomics Core - KU Leuven - UZ Leuven 1 Landmarks in DNA sequencing 1953 Discovery of DNA double helix structure 1977
Next Generation Sequencing Technology and applications 10/1/2015 Jeroen Van Houdt - Genomics Core - KU Leuven - UZ Leuven 1 Landmarks in DNA sequencing 1953 Discovery of DNA double helix structure 1977
NGS data analysis. Bernardo J. Clavijo
 NGS data analysis Bernardo J. Clavijo 1 A brief history of DNA sequencing 1953 double helix structure, Watson & Crick! 1977 rapid DNA sequencing, Sanger! 1977 first full (5k) genome bacteriophage Phi X!
NGS data analysis Bernardo J. Clavijo 1 A brief history of DNA sequencing 1953 double helix structure, Watson & Crick! 1977 rapid DNA sequencing, Sanger! 1977 first full (5k) genome bacteriophage Phi X!
Introduction to Support Vector Machines. Colin Campbell, Bristol University
 Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Introduction to Support Vector Machines Colin Campbell, Bristol University 1 Outline of talk. Part 1. An Introduction to SVMs 1.1. SVMs for binary classification. 1.2. Soft margins and multi-class classification.
Computational Genomics. Next generation sequencing (NGS)
") Computational Genomics Next generation sequencing (NGS) Sequencing technology defies Moore s law Nature Methods 2011 Log 10 (price) Sequencing the Human Genome 2001: Human Genome Project 2.7G$, 11 years
Computational Genomics Next generation sequencing (NGS) Sequencing technology defies Moore s law Nature Methods 2011 Log 10 (price) Sequencing the Human Genome 2001: Human Genome Project 2.7G$, 11 years
Support Vector Machine (SVM)
") Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
When you install Mascot, it includes a copy of the Swiss-Prot protein database. However, it is almost certain that you and your colleagues will want
 1 When you install Mascot, it includes a copy of the Swiss-Prot protein database. However, it is almost certain that you and your colleagues will want to search other databases as well. There are very
1 When you install Mascot, it includes a copy of the Swiss-Prot protein database. However, it is almost certain that you and your colleagues will want to search other databases as well. There are very
A Simple Introduction to Support Vector Machines
 A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
A Simple Introduction to Support Vector Machines Martin Law Lecture for CSE 802 Department of Computer Science and Engineering Michigan State University Outline A brief history of SVM Large-margin linear
Welcome to Pacific Biosciences' Introduction to SMRTbell Template Preparation.
 Introduction to SMRTbell Template Preparation 100 338 500 01 1. SMRTbell Template Preparation 1.1 Introduction to SMRTbell Template Preparation Welcome to Pacific Biosciences' Introduction to SMRTbell
Introduction to SMRTbell Template Preparation 100 338 500 01 1. SMRTbell Template Preparation 1.1 Introduction to SMRTbell Template Preparation Welcome to Pacific Biosciences' Introduction to SMRTbell
Support Vector Machines Explained
 March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
March 1, 2009 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
NGS Technologies for Genomics and Transcriptomics
 NGS Technologies for Genomics and Transcriptomics Massimo Delledonne Department of Biotechnologies - University of Verona http://profs.sci.univr.it/delledonne 13 years and $3 billion required for the Human
NGS Technologies for Genomics and Transcriptomics Massimo Delledonne Department of Biotechnologies - University of Verona http://profs.sci.univr.it/delledonne 13 years and $3 billion required for the Human
Support Vector Machines with Clustering for Training with Very Large Datasets
 Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Support Vector Machines with Clustering for Training with Very Large Datasets Theodoros Evgeniou Technology Management INSEAD Bd de Constance, Fontainebleau 77300, France theodoros.evgeniou@insead.fr Massimiliano
Next generation DNA sequencing technologies. theory & prac-ce
 Next generation DNA sequencing technologies theory & prac-ce Outline Next- Genera-on sequencing (NGS) technologies overview NGS applica-ons NGS workflow: data collec-on and processing the exome sequencing
Next generation DNA sequencing technologies theory & prac-ce Outline Next- Genera-on sequencing (NGS) technologies overview NGS applica-ons NGS workflow: data collec-on and processing the exome sequencing
Support Vector Machine. Tutorial. (and Statistical Learning Theory)
") Support Vector Machine (and Statistical Learning Theory) Tutorial Jason Weston NEC Labs America 4 Independence Way, Princeton, USA. jasonw@nec-labs.com 1 Support Vector Machines: history SVMs introduced
Support Vector Machine (and Statistical Learning Theory) Tutorial Jason Weston NEC Labs America 4 Independence Way, Princeton, USA. jasonw@nec-labs.com 1 Support Vector Machines: history SVMs introduced
Searching Nucleotide Databases
 Searching Nucleotide Databases 1 When we search a nucleic acid databases, Mascot always performs a 6 frame translation on the fly. That is, 3 reading frames from the forward strand and 3 reading frames
Searching Nucleotide Databases 1 When we search a nucleic acid databases, Mascot always performs a 6 frame translation on the fly. That is, 3 reading frames from the forward strand and 3 reading frames
Simulation Model of Mating Behavior in Flies
 Simulation Model of Mating Behavior in Flies MEHMET KAYIM & AYKUT Ecological and Evolutionary Genetics Lab. Department of Biology, Middle East Technical University International Workshop on Hybrid Systems
Simulation Model of Mating Behavior in Flies MEHMET KAYIM & AYKUT Ecological and Evolutionary Genetics Lab. Department of Biology, Middle East Technical University International Workshop on Hybrid Systems
SMRT Analysis v2.2.0 Overview. 1. SMRT Analysis v2.2.0. 1.1 SMRT Analysis v2.2.0 Overview. Notes:
 SMRT Analysis v2.2.0 Overview 100 338 400 01 1. SMRT Analysis v2.2.0 1.1 SMRT Analysis v2.2.0 Overview Welcome to Pacific Biosciences' SMRT Analysis v2.2.0 Overview 1.2 Contents This module will introduce
SMRT Analysis v2.2.0 Overview 100 338 400 01 1. SMRT Analysis v2.2.0 1.1 SMRT Analysis v2.2.0 Overview Welcome to Pacific Biosciences' SMRT Analysis v2.2.0 Overview 1.2 Contents This module will introduce
A study on machine learning and regression based models for performance estimation of LTE HetNets
 A study on machine learning and regression based models for performance estimation of LTE HetNets B. Bojović 1, E. Meshkova 2, N. Baldo 1, J. Riihijärvi 2 and M. Petrova 2 1 Centre Tecnològic de Telecomunicacions
A study on machine learning and regression based models for performance estimation of LTE HetNets B. Bojović 1, E. Meshkova 2, N. Baldo 1, J. Riihijärvi 2 and M. Petrova 2 1 Centre Tecnològic de Telecomunicacions
Class #6: Non-linear classification. ML4Bio 2012 February 17 th, 2012 Quaid Morris
 Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Class #6: Non-linear classification ML4Bio 2012 February 17 th, 2012 Quaid Morris 1 Module #: Title of Module 2 Review Overview Linear separability Non-linear classification Linear Support Vector Machines
Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms
 Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms Scott Pion and Lutz Hamel Abstract This paper presents the results of a series of analyses performed on direct mail
Comparing the Results of Support Vector Machines with Traditional Data Mining Algorithms Scott Pion and Lutz Hamel Abstract This paper presents the results of a series of analyses performed on direct mail
Making Sense of the Mayhem: Machine Learning and March Madness
 Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
Making Sense of the Mayhem: Machine Learning and March Madness Alex Tran and Adam Ginzberg Stanford University atran3@stanford.edu ginzberg@stanford.edu I. Introduction III. Model The goal of our research
July 7th 2009 DNA sequencing
 July 7th 2009 DNA sequencing Overview Sequencing technologies Sequencing strategies Sample preparation Sequencing instruments at MPI EVA 2 x 5 x ABI 3730/3730xl 454 FLX Titanium Illumina Genome Analyzer
July 7th 2009 DNA sequencing Overview Sequencing technologies Sequencing strategies Sample preparation Sequencing instruments at MPI EVA 2 x 5 x ABI 3730/3730xl 454 FLX Titanium Illumina Genome Analyzer
Data Processing of Nextera Mate Pair Reads on Illumina Sequencing Platforms
 Data Processing of Nextera Mate Pair Reads on Illumina Sequencing Platforms Introduction Mate pair sequencing enables the generation of libraries with insert sizes in the range of several kilobases (Kb).
Data Processing of Nextera Mate Pair Reads on Illumina Sequencing Platforms Introduction Mate pair sequencing enables the generation of libraries with insert sizes in the range of several kilobases (Kb).
Support Vector Machines for Classification and Regression
 UNIVERSITY OF SOUTHAMPTON Support Vector Machines for Classification and Regression by Steve R. Gunn Technical Report Faculty of Engineering, Science and Mathematics School of Electronics and Computer
UNIVERSITY OF SOUTHAMPTON Support Vector Machines for Classification and Regression by Steve R. Gunn Technical Report Faculty of Engineering, Science and Mathematics School of Electronics and Computer
Typing in the NGS era: The way forward!
 Typing in the NGS era: The way forward! Valeria Michelacci NGS course, June 2015 Typing from sequence data NGS-derived conventional Multi Locus Sequence Typing (University of Warwick, 7 housekeeping genes)
Typing in the NGS era: The way forward! Valeria Michelacci NGS course, June 2015 Typing from sequence data NGS-derived conventional Multi Locus Sequence Typing (University of Warwick, 7 housekeeping genes)
An Introduction to Machine Learning
 An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune,
An Introduction to Machine Learning L5: Novelty Detection and Regression Alexander J. Smola Statistical Machine Learning Program Canberra, ACT 0200 Australia Alex.Smola@nicta.com.au Tata Institute, Pune,
E-commerce Transaction Anomaly Classification
 E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
E-commerce Transaction Anomaly Classification Minyong Lee minyong@stanford.edu Seunghee Ham sham12@stanford.edu Qiyi Jiang qjiang@stanford.edu I. INTRODUCTION Due to the increasing popularity of e-commerce
Introduction: Overview of Kernel Methods
 Introduction: Overview of Kernel Methods Statistical Data Analysis with Positive Definite Kernels Kenji Fukumizu Institute of Statistical Mathematics, ROIS Department of Statistical Science, Graduate University
Introduction: Overview of Kernel Methods Statistical Data Analysis with Positive Definite Kernels Kenji Fukumizu Institute of Statistical Mathematics, ROIS Department of Statistical Science, Graduate University
Early defect identification of semiconductor processes using machine learning
 STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
STANFORD UNIVERISTY MACHINE LEARNING CS229 Early defect identification of semiconductor processes using machine learning Friday, December 16, 2011 Authors: Saul ROSA Anton VLADIMIROV Professor: Dr. Andrew
Statistical Models in Data Mining
 Statistical Models in Data Mining Sargur N. Srihari University at Buffalo The State University of New York Department of Computer Science and Engineering Department of Biostatistics 1 Srihari Flood of
Statistical Models in Data Mining Sargur N. Srihari University at Buffalo The State University of New York Department of Computer Science and Engineering Department of Biostatistics 1 Srihari Flood of
THE SVM APPROACH FOR BOX JENKINS MODELS
 REVSTAT Statistical Journal Volume 7, Number 1, April 2009, 23 36 THE SVM APPROACH FOR BOX JENKINS MODELS Authors: Saeid Amiri Dep. of Energy and Technology, Swedish Univ. of Agriculture Sciences, P.O.Box
REVSTAT Statistical Journal Volume 7, Number 1, April 2009, 23 36 THE SVM APPROACH FOR BOX JENKINS MODELS Authors: Saeid Amiri Dep. of Energy and Technology, Swedish Univ. of Agriculture Sciences, P.O.Box
Solar Irradiance Forecasting Using Multi-layer Cloud Tracking and Numerical Weather Prediction
 Solar Irradiance Forecasting Using Multi-layer Cloud Tracking and Numerical Weather Prediction Jin Xu, Shinjae Yoo, Dantong Yu, Dong Huang, John Heiser, Paul Kalb Solar Energy Abundant, clean, and secure
Solar Irradiance Forecasting Using Multi-layer Cloud Tracking and Numerical Weather Prediction Jin Xu, Shinjae Yoo, Dantong Yu, Dong Huang, John Heiser, Paul Kalb Solar Energy Abundant, clean, and secure
Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data
 CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
CMPE 59H Comparison of Non-linear Dimensionality Reduction Techniques for Classification with Gene Expression Microarray Data Term Project Report Fatma Güney, Kübra Kalkan 1/15/2013 Keywords: Non-linear
Keeping up with DNA technologies
 Keeping up with DNA technologies Mihai Pop Department of Computer Science Center for Bioinformatics and Computational Biology University of Maryland, College Park The evolution of DNA sequencing Since
Keeping up with DNA technologies Mihai Pop Department of Computer Science Center for Bioinformatics and Computational Biology University of Maryland, College Park The evolution of DNA sequencing Since
Drugs store sales forecast using Machine Learning
 Drugs store sales forecast using Machine Learning Hongyu Xiong (hxiong2), Xi Wu (wuxi), Jingying Yue (jingying) 1 Introduction Nowadays medical-related sales prediction is of great interest; with reliable
Drugs store sales forecast using Machine Learning Hongyu Xiong (hxiong2), Xi Wu (wuxi), Jingying Yue (jingying) 1 Introduction Nowadays medical-related sales prediction is of great interest; with reliable
An Overview of DNA Sequencing
 An Overview of DNA Sequencing Prokaryotic DNA Plasmid http://en.wikipedia.org/wiki/image:prokaryote_cell_diagram.svg Eukaryotic DNA http://en.wikipedia.org/wiki/image:plant_cell_structure_svg.svg DNA Structure
An Overview of DNA Sequencing Prokaryotic DNA Plasmid http://en.wikipedia.org/wiki/image:prokaryote_cell_diagram.svg Eukaryotic DNA http://en.wikipedia.org/wiki/image:plant_cell_structure_svg.svg DNA Structure
Environmental Remote Sensing GEOG 2021
 Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Environmental Remote Sensing GEOG 2021 Lecture 4 Image classification 2 Purpose categorising data data abstraction / simplification data interpretation mapping for land cover mapping use land cover class
Example: Boats and Manatees
 Figure 9-6 Example: Boats and Manatees Slide 1 Given the sample data in Table 9-1, find the value of the linear correlation coefficient r, then refer to Table A-6 to determine whether there is a significant
Figure 9-6 Example: Boats and Manatees Slide 1 Given the sample data in Table 9-1, find the value of the linear correlation coefficient r, then refer to Table A-6 to determine whether there is a significant
Two scientific papers (1, 2) recently appeared reporting
 recently appeared reporting") On the sequencing of the human genome Robert H. Waterston*, Eric S. Lander, and John E. Sulston *Genome Sequencing Center, Washington University, Saint Louis, MO 63108; Whitehead Institute Massachusetts
On the sequencing of the human genome Robert H. Waterston*, Eric S. Lander, and John E. Sulston *Genome Sequencing Center, Washington University, Saint Louis, MO 63108; Whitehead Institute Massachusetts
Why do statisticians "hate" us?
 Why do statisticians "hate" us? David Hand, Heikki Mannila, Padhraic Smyth "Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and to summarize the data
Why do statisticians "hate" us? David Hand, Heikki Mannila, Padhraic Smyth "Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and to summarize the data
Microbial Oceanomics using High-Throughput DNA Sequencing
 Microbial Oceanomics using High-Throughput DNA Sequencing Ramiro Logares Institute of Marine Sciences, CSIC, Barcelona 9th RES Users'Conference 23 September 2015 Importance of microbes in the sunlit ocean
Microbial Oceanomics using High-Throughput DNA Sequencing Ramiro Logares Institute of Marine Sciences, CSIC, Barcelona 9th RES Users'Conference 23 September 2015 Importance of microbes in the sunlit ocean
HT2015: SC4 Statistical Data Mining and Machine Learning
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Bayesian Nonparametrics Parametric vs Nonparametric
Genome and DNA Sequence Databases. BME 110/BIOL 181 CompBio Tools Todd Lowe March 31, 2009
 Genome and DNA Sequence Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 31, 2009 Admin Reading: Chapters 1 & 2 Notes available in PDF format on-line (see class calendar page): http://www.soe.ucsc.edu/classes/bme110/spring09/bme110-calendar.html
Genome and DNA Sequence Databases BME 110/BIOL 181 CompBio Tools Todd Lowe March 31, 2009 Admin Reading: Chapters 1 & 2 Notes available in PDF format on-line (see class calendar page): http://www.soe.ucsc.edu/classes/bme110/spring09/bme110-calendar.html
NCSS Statistical Software Principal Components Regression. In ordinary least squares, the regression coefficients are estimated using the formula ( )
") Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Chapter 340 Principal Components Regression Introduction is a technique for analyzing multiple regression data that suffer from multicollinearity. When multicollinearity occurs, least squares estimates
Logistic Regression. Jia Li. Department of Statistics The Pennsylvania State University. Logistic Regression
 Logistic Regression Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Logistic Regression Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Logistic Regression Preserve linear classification boundaries. By the Bayes rule: Ĝ(x) = arg max
Statistical Machine Learning
 Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Statistical Machine Learning UoC Stats 37700, Winter quarter Lecture 4: classical linear and quadratic discriminants. 1 / 25 Linear separation For two classes in R d : simple idea: separate the classes
Gene Expression Assays
 APPLICATION NOTE TaqMan Gene Expression Assays A mpl i fic ationef ficienc yof TaqMan Gene Expression Assays Assays tested extensively for qpcr efficiency Key factors that affect efficiency Efficiency
APPLICATION NOTE TaqMan Gene Expression Assays A mpl i fic ationef ficienc yof TaqMan Gene Expression Assays Assays tested extensively for qpcr efficiency Key factors that affect efficiency Efficiency
Reading DNA Sequences:
 Reading DNA Sequences: 18-th Century Mathematics for 21-st Century Technology Michael Waterman University of Southern California Tsinghua University DNA Genetic information of an organism Double helix,
Reading DNA Sequences: 18-th Century Mathematics for 21-st Century Technology Michael Waterman University of Southern California Tsinghua University DNA Genetic information of an organism Double helix,
Data Mining - Evaluation of Classifiers
 Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Data Mining - Evaluation of Classifiers Lecturer: JERZY STEFANOWSKI Institute of Computing Sciences Poznan University of Technology Poznan, Poland Lecture 4 SE Master Course 2008/2009 revised for 2010
Mathematical Models of Supervised Learning and their Application to Medical Diagnosis
 Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Genomic, Proteomic and Transcriptomic Lab High Performance Computing and Networking Institute National Research Council, Italy Mathematical Models of Supervised Learning and their Application to Medical
Acknowledgments. Data Mining with Regression. Data Mining Context. Overview. Colleagues
 Data Mining with Regression Teaching an old dog some new tricks Acknowledgments Colleagues Dean Foster in Statistics Lyle Ungar in Computer Science Bob Stine Department of Statistics The School of the
Data Mining with Regression Teaching an old dog some new tricks Acknowledgments Colleagues Dean Foster in Statistics Lyle Ungar in Computer Science Bob Stine Department of Statistics The School of the
Cloud Computing and the DNA Data Race Michael Schatz. June 8, 2011 HPDC 11/3DAPAS/ECMLS
 Cloud Computing and the DNA Data Race Michael Schatz June 8, 2011 HPDC 11/3DAPAS/ECMLS Outline 1. Milestones in DNA Sequencing 2. Hadoop & Cloud Computing 3. Sequence Analysis in the Clouds 1. Sequence
Cloud Computing and the DNA Data Race Michael Schatz June 8, 2011 HPDC 11/3DAPAS/ECMLS Outline 1. Milestones in DNA Sequencing 2. Hadoop & Cloud Computing 3. Sequence Analysis in the Clouds 1. Sequence
Linear Threshold Units
 Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Linear Threshold Units w x hx (... w n x n w We assume that each feature x j and each weight w j is a real number (we will relax this later) We will study three different algorithms for learning linear
Data Mining and Data Warehousing. Henryk Maciejewski. Data Mining Predictive modelling: regression
 Data Mining and Data Warehousing Henryk Maciejewski Data Mining Predictive modelling: regression Algorithms for Predictive Modelling Contents Regression Classification Auxiliary topics: Estimation of prediction
Data Mining and Data Warehousing Henryk Maciejewski Data Mining Predictive modelling: regression Algorithms for Predictive Modelling Contents Regression Classification Auxiliary topics: Estimation of prediction
Galaxy Morphological Classification
 Galaxy Morphological Classification Jordan Duprey and James Kolano Abstract To solve the issue of galaxy morphological classification according to a classification scheme modelled off of the Hubble Sequence,
Galaxy Morphological Classification Jordan Duprey and James Kolano Abstract To solve the issue of galaxy morphological classification according to a classification scheme modelled off of the Hubble Sequence,
Analyze It use cases in telecom & healthcare
 Analyze It use cases in telecom & healthcare Chung Min Chen, VP of Data Science The views and opinions expressed in this presentation are those of the author and do not necessarily reflect the position
Analyze It use cases in telecom & healthcare Chung Min Chen, VP of Data Science The views and opinions expressed in this presentation are those of the author and do not necessarily reflect the position
Intrusion Detection via Machine Learning for SCADA System Protection
 Intrusion Detection via Machine Learning for SCADA System Protection S.L.P. Yasakethu Department of Computing, University of Surrey, Guildford, GU2 7XH, UK. s.l.yasakethu@surrey.ac.uk J. Jiang Department
Intrusion Detection via Machine Learning for SCADA System Protection S.L.P. Yasakethu Department of Computing, University of Surrey, Guildford, GU2 7XH, UK. s.l.yasakethu@surrey.ac.uk J. Jiang Department
EMPIRICAL RISK MINIMIZATION FOR CAR INSURANCE DATA
 EMPIRICAL RISK MINIMIZATION FOR CAR INSURANCE DATA Andreas Christmann Department of Mathematics homepages.vub.ac.be/ achristm Talk: ULB, Sciences Actuarielles, 17/NOV/2006 Contents 1. Project: Motor vehicle
EMPIRICAL RISK MINIMIZATION FOR CAR INSURANCE DATA Andreas Christmann Department of Mathematics homepages.vub.ac.be/ achristm Talk: ULB, Sciences Actuarielles, 17/NOV/2006 Contents 1. Project: Motor vehicle
Data Mining: An Overview. David Madigan http://www.stat.columbia.edu/~madigan
 Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
Data Mining: An Overview David Madigan http://www.stat.columbia.edu/~madigan Overview Brief Introduction to Data Mining Data Mining Algorithms Specific Eamples Algorithms: Disease Clusters Algorithms:
A Basic Guide to Modeling Techniques for All Direct Marketing Challenges
 A Basic Guide to Modeling Techniques for All Direct Marketing Challenges Allison Cornia Database Marketing Manager Microsoft Corporation C. Olivia Rud Executive Vice President Data Square, LLC Overview
A Basic Guide to Modeling Techniques for All Direct Marketing Challenges Allison Cornia Database Marketing Manager Microsoft Corporation C. Olivia Rud Executive Vice President Data Square, LLC Overview
CS 2750 Machine Learning. Lecture 1. Machine Learning. http://www.cs.pitt.edu/~milos/courses/cs2750/ CS 2750 Machine Learning.
 Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Lecture Machine Learning Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square, x5 http://www.cs.pitt.edu/~milos/courses/cs75/ Administration Instructor: Milos Hauskrecht milos@cs.pitt.edu 539 Sennott
Network analysis: P.E.R.T,C.P.M & Resource Allocation Some important definition:
 Network analysis: P.E.R.T,C.P.M & Resource Allocation Some important definition: 1. Activity : It is a particular work of a project which consumes some resources (in ) & time. It is shown as & represented
Network analysis: P.E.R.T,C.P.M & Resource Allocation Some important definition: 1. Activity : It is a particular work of a project which consumes some resources (in ) & time. It is shown as & represented
Master's projects at ITMO University. Daniil Chivilikhin PhD Student @ ITMO University
 Master's projects at ITMO University Daniil Chivilikhin PhD Student @ ITMO University General information Guidance from our lab's researchers Publishable results 2 Research areas Research at ITMO Evolutionary
Master's projects at ITMO University Daniil Chivilikhin PhD Student @ ITMO University General information Guidance from our lab's researchers Publishable results 2 Research areas Research at ITMO Evolutionary
Automated DNA sequencing 20/12/2009. Next Generation Sequencing
 DNA sequencing the beginnings Ghent University (Fiers et al) pioneers sequencing first complete gene (1972) first complete genome (1976) Next Generation Sequencing Fred Sanger develops dideoxy sequencing
DNA sequencing the beginnings Ghent University (Fiers et al) pioneers sequencing first complete gene (1972) first complete genome (1976) Next Generation Sequencing Fred Sanger develops dideoxy sequencing
Chapter 8: Recombinant DNA 2002 by W. H. Freeman and Company Chapter 8: Recombinant DNA 2002 by W. H. Freeman and Company
 Genetic engineering: humans Gene replacement therapy or gene therapy Many technical and ethical issues implications for gene pool for germ-line gene therapy what traits constitute disease rather than just
Genetic engineering: humans Gene replacement therapy or gene therapy Many technical and ethical issues implications for gene pool for germ-line gene therapy what traits constitute disease rather than just
8.1 Summary and conclusions 8.2 Implications
 Conclusion and Implication V{tÑàxÜ CONCLUSION AND IMPLICATION 8 Contents 8.1 Summary and conclusions 8.2 Implications Having done the selection of macroeconomic variables, forecasting the series and construction
Conclusion and Implication V{tÑàxÜ CONCLUSION AND IMPLICATION 8 Contents 8.1 Summary and conclusions 8.2 Implications Having done the selection of macroeconomic variables, forecasting the series and construction
Linear Programming for Optimization. Mark A. Schulze, Ph.D. Perceptive Scientific Instruments, Inc.
 1. Introduction Linear Programming for Optimization Mark A. Schulze, Ph.D. Perceptive Scientific Instruments, Inc. 1.1 Definition Linear programming is the name of a branch of applied mathematics that
1. Introduction Linear Programming for Optimization Mark A. Schulze, Ph.D. Perceptive Scientific Instruments, Inc. 1.1 Definition Linear programming is the name of a branch of applied mathematics that
EDUCATION AND VOCABULARY MULTIPLE REGRESSION IN ACTION
 EDUCATION AND VOCABULARY MULTIPLE REGRESSION IN ACTION EDUCATION AND VOCABULARY 5-10 hours of input weekly is enough to pick up a new language (Schiff & Myers, 1988). Dutch children spend 5.5 hours/day
EDUCATION AND VOCABULARY MULTIPLE REGRESSION IN ACTION EDUCATION AND VOCABULARY 5-10 hours of input weekly is enough to pick up a new language (Schiff & Myers, 1988). Dutch children spend 5.5 hours/day
RETRIEVING SEQUENCE INFORMATION. Nucleotide sequence databases. Database search. Sequence alignment and comparison
 RETRIEVING SEQUENCE INFORMATION Nucleotide sequence databases Database search Sequence alignment and comparison Biological sequence databases Originally just a storage place for sequences. Currently the
RETRIEVING SEQUENCE INFORMATION Nucleotide sequence databases Database search Sequence alignment and comparison Biological sequence databases Originally just a storage place for sequences. Currently the
Modified Genetic Algorithm for DNA Sequence Assembly by Shotgun and Hybridization Sequencing Techniques
 International Journal of Electronics and Computer Science Engineering 2000 Available Online at www.ijecse.org ISSN- 2277-1956 Modified Genetic Algorithm for DNA Sequence Assembly by Shotgun and Hybridization
International Journal of Electronics and Computer Science Engineering 2000 Available Online at www.ijecse.org ISSN- 2277-1956 Modified Genetic Algorithm for DNA Sequence Assembly by Shotgun and Hybridization
Boolean Network Models
 Boolean Network Models 2/5/03 History Kaufmann, 1970s Studied organization and dynamics properties of (N,k) Boolean Networks Found out that highly connected networks behave differently than lowly connected
Boolean Network Models 2/5/03 History Kaufmann, 1970s Studied organization and dynamics properties of (N,k) Boolean Networks Found out that highly connected networks behave differently than lowly connected
Classifying Large Data Sets Using SVMs with Hierarchical Clusters. Presented by :Limou Wang
 Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
Classifying Large Data Sets Using SVMs with Hierarchical Clusters Presented by :Limou Wang Overview SVM Overview Motivation Hierarchical micro-clustering algorithm Clustering-Based SVM (CB-SVM) Experimental
A PRIMAL-DUAL APPROACH TO NONPARAMETRIC PRODUCTIVITY ANALYSIS: THE CASE OF U.S. AGRICULTURE. Jean-Paul Chavas and Thomas L. Cox *
 Copyright 1994 by Jean-Paul Chavas and homas L. Cox. All rights reserved. Readers may make verbatim copies of this document for noncommercial purposes by any means, provided that this copyright notice
Copyright 1994 by Jean-Paul Chavas and homas L. Cox. All rights reserved. Readers may make verbatim copies of this document for noncommercial purposes by any means, provided that this copyright notice
Predicting Flight Delays
 Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Predicting Flight Delays Dieterich Lawson jdlawson@stanford.edu William Castillo will.castillo@stanford.edu Introduction Every year approximately 20% of airline flights are delayed or cancelled, costing
Machine Learning in Statistical Arbitrage
 Machine Learning in Statistical Arbitrage Xing Fu, Avinash Patra December 11, 2009 Abstract We apply machine learning methods to obtain an index arbitrage strategy. In particular, we employ linear regression
Machine Learning in Statistical Arbitrage Xing Fu, Avinash Patra December 11, 2009 Abstract We apply machine learning methods to obtain an index arbitrage strategy. In particular, we employ linear regression
Semi-Supervised Support Vector Machines and Application to Spam Filtering
 Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Semi-Supervised Support Vector Machines and Application to Spam Filtering Alexander Zien Empirical Inference Department, Bernhard Schölkopf Max Planck Institute for Biological Cybernetics ECML 2006 Discovery
Go where the biology takes you. Genome Analyzer IIx Genome Analyzer IIe
 Go where the biology takes you. Genome Analyzer IIx Genome Analyzer IIe Go where the biology takes you. To published results faster With proven scalability To the forefront of discovery To limitless applications
Go where the biology takes you. Genome Analyzer IIx Genome Analyzer IIe Go where the biology takes you. To published results faster With proven scalability To the forefront of discovery To limitless applications
Genotyping by sequencing and data analysis. Ross Whetten North Carolina State University
 Genotyping by sequencing and data analysis Ross Whetten North Carolina State University Stein (2010) Genome Biology 11:207 More New Technology on the Horizon Genotyping By Sequencing Timeline 2007 Complexity
Genotyping by sequencing and data analysis Ross Whetten North Carolina State University Stein (2010) Genome Biology 11:207 More New Technology on the Horizon Genotyping By Sequencing Timeline 2007 Complexity
Biology in the Clouds
 Biology in the Clouds Michael Schatz July 30, 2012 Science Cloud Summer School Outline 1. Milestones in genomics 1. Quick primer on molecular biology 2. The evolution of sequencing 2. Hadoop Applications
Biology in the Clouds Michael Schatz July 30, 2012 Science Cloud Summer School Outline 1. Milestones in genomics 1. Quick primer on molecular biology 2. The evolution of sequencing 2. Hadoop Applications
Discrete Optimization
 Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
Discrete Optimization [Chen, Batson, Dang: Applied integer Programming] Chapter 3 and 4.1-4.3 by Johan Högdahl and Victoria Svedberg Seminar 2, 2015-03-31 Todays presentation Chapter 3 Transforms using
A Study on the Comparison of Electricity Forecasting Models: Korea and China
 Communications for Statistical Applications and Methods 2015, Vol. 22, No. 6, 675 683 DOI: http://dx.doi.org/10.5351/csam.2015.22.6.675 Print ISSN 2287-7843 / Online ISSN 2383-4757 A Study on the Comparison
Communications for Statistical Applications and Methods 2015, Vol. 22, No. 6, 675 683 DOI: http://dx.doi.org/10.5351/csam.2015.22.6.675 Print ISSN 2287-7843 / Online ISSN 2383-4757 A Study on the Comparison
Software Getting Started Guide
 Software Getting Started Guide For Research Use Only. Not for use in diagnostic procedures. P/N 001-097-569-03 Copyright 2010-2013, Pacific Biosciences of California, Inc. All rights reserved. Information
Software Getting Started Guide For Research Use Only. Not for use in diagnostic procedures. P/N 001-097-569-03 Copyright 2010-2013, Pacific Biosciences of California, Inc. All rights reserved. Information
Foundations of Machine Learning On-Line Learning. Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu
 Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Foundations of Machine Learning On-Line Learning Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Motivation PAC learning: distribution fixed over time (training and test). IID assumption.
Cross Validation techniques in R: A brief overview of some methods, packages, and functions for assessing prediction models.
 Cross Validation techniques in R: A brief overview of some methods, packages, and functions for assessing prediction models. Dr. Jon Starkweather, Research and Statistical Support consultant This month
Cross Validation techniques in R: A brief overview of some methods, packages, and functions for assessing prediction models. Dr. Jon Starkweather, Research and Statistical Support consultant This month
Protein Protein Interaction Networks
 Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Functional Pattern Mining from Genome Scale Protein Protein Interaction Networks Young-Rae Cho, Ph.D. Assistant Professor Department of Computer Science Baylor University it My Definition of Bioinformatics
Data Mining and Neural Networks in Stata
 Data Mining and Neural Networks in Stata 2 nd Italian Stata Users Group Meeting Milano, 10 October 2005 Mario Lucchini e Maurizo Pisati Università di Milano-Bicocca mario.lucchini@unimib.it maurizio.pisati@unimib.it
Data Mining and Neural Networks in Stata 2 nd Italian Stata Users Group Meeting Milano, 10 October 2005 Mario Lucchini e Maurizo Pisati Università di Milano-Bicocca mario.lucchini@unimib.it maurizio.pisati@unimib.it
First generation" sequencing technologies and genome assembly. Roger Bumgarner Associate Professor, Microbiology, UW Rogerb@u.washington.
 First generation" sequencing technologies and genome assembly Roger Bumgarner ssociate Professor, Microbiology, UW Rogerb@u.washington.edu Why discuss a technology that appears to be being replaced? Next
First generation" sequencing technologies and genome assembly Roger Bumgarner ssociate Professor, Microbiology, UW Rogerb@u.washington.edu Why discuss a technology that appears to be being replaced? Next
The Operational Value of Social Media Information. Social Media and Customer Interaction
 The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
The Operational Value of Social Media Information Dennis J. Zhang (Kellogg School of Management) Ruomeng Cui (Kelley School of Business) Santiago Gallino (Tuck School of Business) Antonio Moreno-Garcia
Average Redistributional Effects. IFAI/IZA Conference on Labor Market Policy Evaluation
 Average Redistributional Effects IFAI/IZA Conference on Labor Market Policy Evaluation Geert Ridder, Department of Economics, University of Southern California. October 10, 2006 1 Motivation Most papers
Average Redistributional Effects IFAI/IZA Conference on Labor Market Policy Evaluation Geert Ridder, Department of Economics, University of Southern California. October 10, 2006 1 Motivation Most papers
Local classification and local likelihoods
 Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Local classification and local likelihoods November 18 k-nearest neighbors The idea of local regression can be extended to classification as well The simplest way of doing so is called nearest neighbor
Marginal Person. Average Person. (Average Return of College Goers) Return, Cost. (Average Return in the Population) (Marginal Return)
 Return, Cost. (Average Return in the Population) (Marginal Return)") 1 2 3 Marginal Person Average Person (Average Return of College Goers) Return, Cost (Average Return in the Population) 4 (Marginal Return) 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
1 2 3 Marginal Person Average Person (Average Return of College Goers) Return, Cost (Average Return in the Population) 4 (Marginal Return) 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
The prevailing method of determining
 C OMPUTATIONAL B IOLOGY WHOLE-GENOME DNA SEQUENCING Computation is integrally and powerfully involved with the DNA sequencing technology that promises to reveal the complete human DNA sequence in the next
C OMPUTATIONAL B IOLOGY WHOLE-GENOME DNA SEQUENCING Computation is integrally and powerfully involved with the DNA sequencing technology that promises to reveal the complete human DNA sequence in the next
Introduction to NGS data analysis
 Introduction to NGS data analysis Jeroen F. J. Laros Leiden Genome Technology Center Department of Human Genetics Center for Human and Clinical Genetics Sequencing Illumina platforms Characteristics: High
Introduction to NGS data analysis Jeroen F. J. Laros Leiden Genome Technology Center Department of Human Genetics Center for Human and Clinical Genetics Sequencing Illumina platforms Characteristics: High
Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization. Learning Goals. GENOME 560, Spring 2012
 Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization GENOME 560, Spring 2012 Data are interesting because they help us understand the world Genomics: Massive Amounts
Why Taking This Course? Course Introduction, Descriptive Statistics and Data Visualization GENOME 560, Spring 2012 Data are interesting because they help us understand the world Genomics: Massive Amounts
On the Interaction and Competition among Internet Service Providers
 On the Interaction and Competition among Internet Service Providers Sam C.M. Lee John C.S. Lui + Abstract The current Internet architecture comprises of different privately owned Internet service providers
On the Interaction and Competition among Internet Service Providers Sam C.M. Lee John C.S. Lui + Abstract The current Internet architecture comprises of different privately owned Internet service providers
How To Cluster Of Complex Systems
 Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Entropy based Graph Clustering: Application to Biological and Social Networks Edward C Kenley Young-Rae Cho Department of Computer Science Baylor University Complex Systems Definition Dynamically evolving
Lean Six Sigma Analyze Phase Introduction. TECH 50800 QUALITY and PRODUCTIVITY in INDUSTRY and TECHNOLOGY
 TECH 50800 QUALITY and PRODUCTIVITY in INDUSTRY and TECHNOLOGY Before we begin: Turn on the sound on your computer. There is audio to accompany this presentation. Audio will accompany most of the online
TECH 50800 QUALITY and PRODUCTIVITY in INDUSTRY and TECHNOLOGY Before we begin: Turn on the sound on your computer. There is audio to accompany this presentation. Audio will accompany most of the online
Chapter 2. imapper: A web server for the automated analysis and mapping of insertional mutagenesis sequence data against Ensembl genomes
 Chapter 2. imapper: A web server for the automated analysis and mapping of insertional mutagenesis sequence data against Ensembl genomes 2.1 Introduction Large-scale insertional mutagenesis screening in
Chapter 2. imapper: A web server for the automated analysis and mapping of insertional mutagenesis sequence data against Ensembl genomes 2.1 Introduction Large-scale insertional mutagenesis screening in
On Correlating Performance Metrics
 On Correlating Performance Metrics Yiping Ding and Chris Thornley BMC Software, Inc. Kenneth Newman BMC Software, Inc. University of Massachusetts, Boston Performance metrics and their measurements are
On Correlating Performance Metrics Yiping Ding and Chris Thornley BMC Software, Inc. Kenneth Newman BMC Software, Inc. University of Massachusetts, Boston Performance metrics and their measurements are
Lecture 6: Logistic Regression
 Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Lecture 6: CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 13, 2011 Outline Outline Classification task Data : X = [x 1,..., x m]: a n m matrix of data points in R n. y { 1,
Innovations and Value Creation in Predictive Modeling. David Cummings Vice President - Research
 Innovations and Value Creation in Predictive Modeling David Cummings Vice President - Research ISO Innovative Analytics 1 Innovations and Value Creation in Predictive Modeling A look back at the past decade
Innovations and Value Creation in Predictive Modeling David Cummings Vice President - Research ISO Innovative Analytics 1 Innovations and Value Creation in Predictive Modeling A look back at the past decade