Synthetic Data Generation for Realistic Analytics Examples and Testing
|
|
|
- Gwenda Peters
- 8 years ago
- Views:
Transcription
1 Synthetic Data Generation for Realistic Analytics Examples and Testing Ronald J. Nowling Red Hat, Inc.

2 Who Am I? Software Engineer at Red Hat Data Science Team, Emerging Technologies Evaluate open-source Big Data space Ensure software works for Red Hat customers Promote data science internally through consulting projects Apache BigTop PMC 2

3 Synthetic Data No licensing, privacy, or intellectual property concerns Scalable: Laptops to Clusters! More reliable than external data sets Enable more realistic example applications Enable more comprehensive testing than wordcount and TeraSort 3

4 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 4

5 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 5

6 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 6

7 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 7

8 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 8
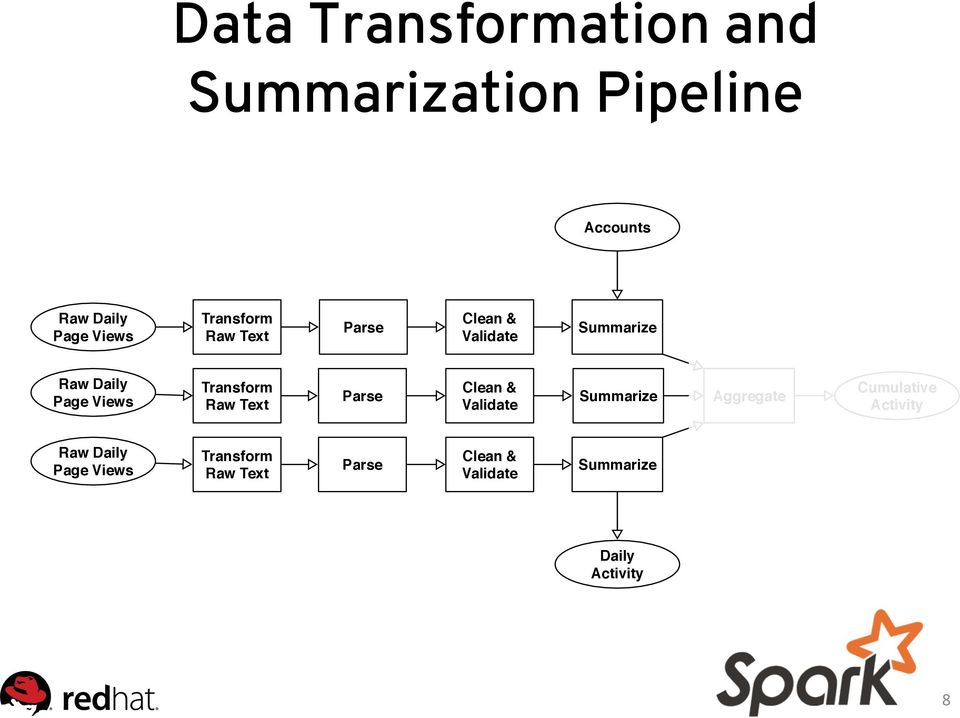
9 Data Transformation and Summarization Pipeline Accounts Transform Raw Text Parse Clean & Validate Summarize Transform Raw Text Parse Clean & Validate Summarize Aggregate Cumulative Transform Raw Text Parse Clean & Validate Summarize Daily 9

10 Synthetic Data Sensitive Data Real data on cluster for scalability testing and validation Synthetic data for local development and testing Needed smaller data sets for checking calculations Total aggregation results requires re-running old pipeline Extra burden on operations team Delay for development team 10

11 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 11

12 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 12

13 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 13

14 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 14

15 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 15

16 Validation with Synthetic Data Data Generator Accounts Transformation and Summarization Pipeline Expected Daily Daily Cumulative Expected Cumulative Validation Script 16

17 Issues Tackled Error in account validation introduced while refactoring code Usage of the correct join types Validation of date-time operations Correct Output Formats 17

18 Apache BigTop BigPetStore Blueprints Problem domain: Transactions for a fictional chain of pet stores BigPetStore Data Generator simulates customer purchasing behavior to generate realistic transaction data Blueprints for big data ecosystem Hadoop: MapReduce / Pig / Hive / Mahout Spark Flink (in progress) 18

19 BigPetStore 19

20 BigPetStore HCFS 20
21 BigPetStore HCFS Core (RDDs) 21
22 BigPetStore HCFS Core (RDDs) Spark SQL 22
23 BigPetStore HCFS Core (RDDs) Spark SQL MLLib 23
24 Team Cluster ~10 nodes 40 cores, 400GB RAM per node 24
25 Potential Issues Infrastructure Storage Software Installation Software Upgrades Spark Configuration Tuning User Management 25
26 Real Stories Creating a new user User Gluster permissions incorrect Cluster upgrade Spark upgrade didn t take because of issue with Ansible role configuration Wiped out our spark.conf master / mesos settings wrong Gluster moint points disappeared on reboot Not set in fstab 26
27 k8petstore Users BPS Data Generator Public IP Proxy Web Application BPS Data Generator BPS Data Generator Redis Master Redis Slave Redis Slave Redis Slave 27
28 k8petstore Users BPS Data Generator Public IP Proxy Web Application BPS Data Generator BPS Data Generator Redis Master Redis Slave Redis Slave Redis Slave 28
29 k8petstore Users BPS Data Generator Public IP Proxy Web Application BPS Data Generator BPS Data Generator Redis Master Redis Slave Redis Slave Redis Slave 29
30 k8petstore Users BPS Data Generator Public IP Proxy Web Application BPS Data Generator BPS Data Generator Redis Master Redis Slave Redis Slave Redis Slave 30
31 k8petstore 31
32 Use Cases Configuration Scalability Fault Tolerance 32
33 k8petstore OpenContrail networking solution demo 1 Kubernetes JuJu Charm documentation example 2 Kubernetes v1.0 launch talk at OSCON 3 [1] - [2] - [3]
34 APACHE BIGTOP DATA GENERATORS 34
35 BigPetStore 35
36 BigTop Weatherman 36
37 BigTop Bazaar 37
38 Vision Encourage synthetic data generation for testing and realistic examples Serve as a resource for the larger Apache and open source communities Emphasis on Flexibility Scalability Realism We look forward to collaborating and getting folks involved! 38
39 Conclusion Synthetic data generators and blueprints are useful! Case studies: Data Processing Pipelines Cluster Deployment Kubernetes BigPetStore and BigTop Data Generators efforts in Apache BigTop Open invitation to get involved and collaborate 39
40 Resources
41 QUESTIONS 41
HiBench Introduction. Carson Wang (carson.wang@intel.com) Software & Services Group
 Software & Services Group") HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
HiBench Introduction Carson Wang (carson.wang@intel.com) Agenda Background Workloads Configurations Benchmark Report Tuning Guide Background WHY Why we need big data benchmarking systems? WHAT What is
Lecture 32 Big Data. 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop
 Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Lecture 32 Big Data 1. Big Data problem 2. Why the excitement about big data 3. What is MapReduce 4. What is Hadoop 5. Get started with Hadoop 1 2 Big Data Problems Data explosion Data from users on social
Testing 3Vs (Volume, Variety and Velocity) of Big Data
 of Big Data") Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Testing 3Vs (Volume, Variety and Velocity) of Big Data 1 A lot happens in the Digital World in 60 seconds 2 What is Big Data Big Data refers to data sets whose size is beyond the ability of commonly used
Apache Flink Next-gen data analysis. Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas
 Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Flink Next-gen data analysis Kostas Tzoumas ktzoumas@apache.org @kostas_tzoumas What is Flink Project undergoing incubation in the Apache Software Foundation Originating from the Stratosphere research
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org @apacheignite @dsetrakyan Agenda About In- Memory
Scaling Out With Apache Spark. DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf
 Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Scaling Out With Apache Spark DTL Meeting 17-04-2015 Slides based on https://www.sics.se/~amir/files/download/dic/spark.pdf Your hosts Mathijs Kattenberg Technical consultant Jeroen Schot Technical consultant
Hadoop Ecosystem Overview. CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook
 Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Hadoop Ecosystem Overview CMSC 491 Hadoop-Based Distributed Computing Spring 2015 Adam Shook Agenda Introduce Hadoop projects to prepare you for your group work Intimate detail will be provided in future
Ali Ghodsi Head of PM and Engineering Databricks
 Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Making Big Data Simple Ali Ghodsi Head of PM and Engineering Databricks Big Data is Hard: A Big Data Project Tasks Tasks Build a Hadoop cluster Challenges Clusters hard to setup and manage Build a data
Unified Big Data Analytics Pipeline. 连 城 lian@databricks.com
 Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
Unified Big Data Analytics Pipeline 连 城 lian@databricks.com What is A fast and general engine for large-scale data processing An open source implementation of Resilient Distributed Datasets (RDD) Has an
The Flink Big Data Analytics Platform. Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org
 The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
The Flink Big Data Analytics Platform Marton Balassi, Gyula Fora" {mbalassi, gyfora}@apache.org What is Apache Flink? Open Source Started in 2009 by the Berlin-based database research groups In the Apache
Hadoop Ecosystem B Y R A H I M A.
 Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Hadoop Ecosystem B Y R A H I M A. History of Hadoop Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open
Introduction to Hadoop HDFS and Ecosystems. Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data
 Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Introduction to Hadoop HDFS and Ecosystems ANSHUL MITTAL Slides credits: Cloudera Academic Partners Program & Prof. De Liu, MSBA 6330 Harvesting Big Data Topics The goal of this presentation is to give
Hadoop IST 734 SS CHUNG
 Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Hadoop IST 734 SS CHUNG Introduction What is Big Data?? Bulk Amount Unstructured Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to
Deploying Hadoop with Manager
 Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
Deploying Hadoop with Manager SUSE Big Data Made Easier Peter Linnell / Sales Engineer plinnell@suse.com Alejandro Bonilla / Sales Engineer abonilla@suse.com 2 Hadoop Core Components 3 Typical Hadoop Distribution
CSE-E5430 Scalable Cloud Computing Lecture 2
 CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
CSE-E5430 Scalable Cloud Computing Lecture 2 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 14.9-2015 1/36 Google MapReduce A scalable batch processing
Big Data Evaluator 2.1: User Guide
 University of A Coruña Computer Architecture Group Big Data Evaluator 2.1: User Guide Authors: Jorge Veiga, Roberto R. Expósito, Guillermo L. Taboada and Juan Touriño May 5, 2016 Contents 1 Overview 3
University of A Coruña Computer Architecture Group Big Data Evaluator 2.1: User Guide Authors: Jorge Veiga, Roberto R. Expósito, Guillermo L. Taboada and Juan Touriño May 5, 2016 Contents 1 Overview 3
Hadoop. MPDL-Frühstück 9. Dezember 2013 MPDL INTERN
 Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Hadoop MPDL-Frühstück 9. Dezember 2013 MPDL INTERN Understanding Hadoop Understanding Hadoop What's Hadoop about? Apache Hadoop project (started 2008) downloadable open-source software library (current
Accelerating and Simplifying Apache
 Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Accelerating and Simplifying Apache Hadoop with Panasas ActiveStor White paper NOvember 2012 1.888.PANASAS www.panasas.com Executive Overview The technology requirements for big data vary significantly
Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II)
") UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
UC BERKELEY Mesos: A Platform for Fine- Grained Resource Sharing in Data Centers (II) Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software?
 Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Hadoop 只 支 援 用 Java 開 發 嘛? Is Hadoop only support Java? 總 不 能 全 部 都 重 新 設 計 吧? 如 何 與 舊 系 統 相 容? Can Hadoop work with existing software? 可 以 跟 資 料 庫 結 合 嘛? Can Hadoop work with Databases? 開 發 者 們 有 聽 到
Workshop on Hadoop with Big Data
 Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Workshop on Hadoop with Big Data Hadoop? Apache Hadoop is an open source framework for distributed storage and processing of large sets of data on commodity hardware. Hadoop enables businesses to quickly
Big Data Analytics. Lucas Rego Drumond
 Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Big Data Analytics Big Data Analytics Lucas Rego Drumond Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Apache Spark Apache Spark 1
Spark in Action. Fast Big Data Analytics using Scala. Matei Zaharia. www.spark- project.org. University of California, Berkeley UC BERKELEY
 Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Spark in Action Fast Big Data Analytics using Scala Matei Zaharia University of California, Berkeley www.spark- project.org UC BERKELEY My Background Grad student in the AMP Lab at UC Berkeley» 50- person
Peers Techno log ies Pv t. L td. HADOOP
 Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Page 1 Peers Techno log ies Pv t. L td. Course Brochure Overview Hadoop is a Open Source from Apache, which provides reliable storage and faster process by using the Hadoop distibution file system and
Understanding Hadoop Performance on Lustre
 Understanding Hadoop Performance on Lustre Stephen Skory, PhD Seagate Technology Collaborators Kelsie Betsch, Daniel Kaslovsky, Daniel Lingenfelter, Dimitar Vlassarev, and Zhenzhen Yan LUG Conference 15
Understanding Hadoop Performance on Lustre Stephen Skory, PhD Seagate Technology Collaborators Kelsie Betsch, Daniel Kaslovsky, Daniel Lingenfelter, Dimitar Vlassarev, and Zhenzhen Yan LUG Conference 15
Big Data Training - Hackveda
 Big Data Training - Hackveda Become a Hackveda Certified Big Data Professional - (Beginner) Skill level: Beginner Training fee: INR 9000 only (Topics covered: 108) Chief Trainer: Mr. Devanshu Shukla Training
Big Data Training - Hackveda Become a Hackveda Certified Big Data Professional - (Beginner) Skill level: Beginner Training fee: INR 9000 only (Topics covered: 108) Chief Trainer: Mr. Devanshu Shukla Training
An Industrial Perspective on the Hadoop Ecosystem. Eldar Khalilov Pavel Valov
 An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
An Industrial Perspective on the Hadoop Ecosystem Eldar Khalilov Pavel Valov agenda 03.12.2015 2 agenda Introduction 03.12.2015 2 agenda Introduction Research goals 03.12.2015 2 agenda Introduction Research
Extending Hadoop beyond MapReduce
 Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Extending Hadoop beyond MapReduce Mahadev Konar Co-Founder @mahadevkonar (@hortonworks) Page 1 Bio Apache Hadoop since 2006 - committer and PMC member Developed and supported Map Reduce @Yahoo! - Core
Hadoop & Spark Using Amazon EMR
 Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
Hadoop & Spark Using Amazon EMR Michael Hanisch, AWS Solutions Architecture 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Agenda Why did we build Amazon EMR? What is Amazon EMR?
How Bigtop Leveraged Docker for Build Automation and One-Click Hadoop Provisioning
 How Bigtop Leveraged Docker for Build Automation and One-Click Hadoop Provisioning Evans Ye Apache Big Data 2015 Budapest Who am I Apache Bigtop PMC member Software Engineer at Trend Micro Develop Big
How Bigtop Leveraged Docker for Build Automation and One-Click Hadoop Provisioning Evans Ye Apache Big Data 2015 Budapest Who am I Apache Bigtop PMC member Software Engineer at Trend Micro Develop Big
Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7
 Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7 Yan Fisher Senior Principal Product Marketing Manager, Red Hat Rohit Bakhshi Product Manager,
Architecting for the next generation of Big Data Hortonworks HDP 2.0 on Red Hat Enterprise Linux 6 with OpenJDK 7 Yan Fisher Senior Principal Product Marketing Manager, Red Hat Rohit Bakhshi Product Manager,
W H I T E P A P E R. Deriving Intelligence from Large Data Using Hadoop and Applying Analytics. Abstract
 W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
W H I T E P A P E R Deriving Intelligence from Large Data Using Hadoop and Applying Analytics Abstract This white paper is focused on discussing the challenges facing large scale data processing and the
BIG DATA TECHNOLOGY. Hadoop Ecosystem
 BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
BIG DATA TECHNOLOGY Hadoop Ecosystem Agenda Background What is Big Data Solution Objective Introduction to Hadoop Hadoop Ecosystem Hybrid EDW Model Predictive Analysis using Hadoop Conclusion What is Big
Apache Hadoop: Past, Present, and Future
 The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
The 4 th China Cloud Computing Conference May 25 th, 2012. Apache Hadoop: Past, Present, and Future Dr. Amr Awadallah Founder, Chief Technical Officer aaa@cloudera.com, twitter: @awadallah Hadoop Past
Detection of Distributed Denial of Service Attack with Hadoop on Live Network
 Detection of Distributed Denial of Service Attack with Hadoop on Live Network Suchita Korad 1, Shubhada Kadam 2, Prajakta Deore 3, Madhuri Jadhav 4, Prof.Rahul Patil 5 Students, Dept. of Computer, PCCOE,
Detection of Distributed Denial of Service Attack with Hadoop on Live Network Suchita Korad 1, Shubhada Kadam 2, Prajakta Deore 3, Madhuri Jadhav 4, Prof.Rahul Patil 5 Students, Dept. of Computer, PCCOE,
MapReduce and Hadoop Distributed File System
 MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
MapReduce and Hadoop Distributed File System 1 B. RAMAMURTHY Contact: Dr. Bina Ramamurthy CSE Department University at Buffalo (SUNY) bina@buffalo.edu http://www.cse.buffalo.edu/faculty/bina Partially
Big Data on Microsoft Platform
 Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
Big Data on Microsoft Platform Prepared by GJ Srinivas Corporate TEG - Microsoft Page 1 Contents 1. What is Big Data?...3 2. Characteristics of Big Data...3 3. Enter Hadoop...3 4. Microsoft Big Data Solutions...4
A PERFORMANCE ANALYSIS of HADOOP CLUSTERS in OPENSTACK CLOUD and in REAL SYSTEM
 A PERFORMANCE ANALYSIS of HADOOP CLUSTERS in OPENSTACK CLOUD and in REAL SYSTEM Ramesh Maharjan and Manoj Shakya Department of Computer Science and Engineering Dhulikhel, Kavre, Nepal lazymesh@gmail.com,
A PERFORMANCE ANALYSIS of HADOOP CLUSTERS in OPENSTACK CLOUD and in REAL SYSTEM Ramesh Maharjan and Manoj Shakya Department of Computer Science and Engineering Dhulikhel, Kavre, Nepal lazymesh@gmail.com,
MapReduce and Hadoop Distributed File System V I J A Y R A O
 MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
MapReduce and Hadoop Distributed File System 1 V I J A Y R A O The Context: Big-data Man on the moon with 32KB (1969); my laptop had 2GB RAM (2009) Google collects 270PB data in a month (2007), 20000PB
Hadoop2, Spark Big Data, real time, machine learning & use cases. Cédric Carbone Twitter : @carbone
 Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
Hadoop2, Spark Big Data, real time, machine learning & use cases Cédric Carbone Twitter : @carbone Agenda Map Reduce Hadoop v1 limits Hadoop v2 and YARN Apache Spark Streaming : Spark vs Storm Machine
HADOOP ON ORACLE ZFS STORAGE A TECHNICAL OVERVIEW
 HADOOP ON ORACLE ZFS STORAGE A TECHNICAL OVERVIEW 757 Maleta Lane, Suite 201 Castle Rock, CO 80108 Brett Weninger, Managing Director brett.weninger@adurant.com Dave Smelker, Managing Principal dave.smelker@adurant.com
HADOOP ON ORACLE ZFS STORAGE A TECHNICAL OVERVIEW 757 Maleta Lane, Suite 201 Castle Rock, CO 80108 Brett Weninger, Managing Director brett.weninger@adurant.com Dave Smelker, Managing Principal dave.smelker@adurant.com
Hadoop Evolution In Organizations. Mark Vervuurt Cluster Data Science & Analytics
 In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
In Organizations Mark Vervuurt Cluster Data Science & Analytics AGENDA 1. Yellow Elephant 2. Data Ingestion & Complex Event Processing 3. SQL on Hadoop 4. NoSQL 5. InMemory 6. Data Science & Machine Learning
Final Project Proposal. CSCI.6500 Distributed Computing over the Internet
 Final Project Proposal CSCI.6500 Distributed Computing over the Internet Qingling Wang 660795696 1. Purpose Implement an application layer on Hybrid Grid Cloud Infrastructure to automatically or at least
Final Project Proposal CSCI.6500 Distributed Computing over the Internet Qingling Wang 660795696 1. Purpose Implement an application layer on Hybrid Grid Cloud Infrastructure to automatically or at least
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source
 - In- Memory Data Fabric Fast Data Meets Open Source") Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
Apache Ignite TM (Incubating) - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC http://www.ignite.incubator.apache.org #apacheignite Agenda Apache Ignite (tm) In- Memory
INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS
 INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS Bogdan Oancea "Nicolae Titulescu" University of Bucharest Raluca Mariana Dragoescu The Bucharest University of Economic Studies, BIG DATA The term big data
INTEGRATING R AND HADOOP FOR BIG DATA ANALYSIS Bogdan Oancea "Nicolae Titulescu" University of Bucharest Raluca Mariana Dragoescu The Bucharest University of Economic Studies, BIG DATA The term big data
Big Data Analytics OverOnline Transactional Data Set
 Big Data Analytics OverOnline Transactional Data Set Rohit Vaswani 1, Rahul Vaswani 2, Manish Shahani 3, Lifna Jos(Mentor) 4 1 B.E. Computer Engg. VES Institute of Technology, Mumbai -400074, Maharashtra,
Big Data Analytics OverOnline Transactional Data Set Rohit Vaswani 1, Rahul Vaswani 2, Manish Shahani 3, Lifna Jos(Mentor) 4 1 B.E. Computer Engg. VES Institute of Technology, Mumbai -400074, Maharashtra,
Ubuntu and Hadoop: the perfect match
 WHITE PAPER Ubuntu and Hadoop: the perfect match February 2012 Copyright Canonical 2012 www.canonical.com Executive introduction In many fields of IT, there are always stand-out technologies. This is definitely
WHITE PAPER Ubuntu and Hadoop: the perfect match February 2012 Copyright Canonical 2012 www.canonical.com Executive introduction In many fields of IT, there are always stand-out technologies. This is definitely
Hadoop MapReduce and Spark. Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015
 Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
Hadoop MapReduce and Spark Giorgio Pedrazzi, CINECA-SCAI School of Data Analytics and Visualisation Milan, 10/06/2015 Outline Hadoop Hadoop Import data on Hadoop Spark Spark features Scala MLlib MLlib
How Companies are! Using Spark
 How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
How Companies are! Using Spark And where the Edge in Big Data will be Matei Zaharia History Decreasing storage costs have led to an explosion of big data Commodity cluster software, like Hadoop, has made
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics
 Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
Big Data Open Source Stack vs. Traditional Stack for BI and Analytics Part I By Sam Poozhikala, Vice President Customer Solutions at StratApps Inc. 4/4/2014 You may contact Sam Poozhikala at spoozhikala@stratapps.com.
Dealing with Data Especially Big Data
 Dealing with Data Especially Big Data INFO-GB-2346.30 Spring 2016 Very Rough Draft Subject to Change Professor Norman White Background: Most courses spend their time on the concepts and techniques of analyzing
Dealing with Data Especially Big Data INFO-GB-2346.30 Spring 2016 Very Rough Draft Subject to Change Professor Norman White Background: Most courses spend their time on the concepts and techniques of analyzing
Analytics in the Cloud. Peter Sirota, GM Elastic MapReduce
 Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Analytics in the Cloud Peter Sirota, GM Elastic MapReduce Data-Driven Decision Making Data is the new raw material for any business on par with capital, people, and labor. What is Big Data? Terabytes of
Outline. High Performance Computing (HPC) Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging
 Big Data meets HPC. Case Studies: Some facts about Big Data Technologies HPC and Big Data converging") Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
Outline High Performance Computing (HPC) Towards exascale computing: a brief history Challenges in the exascale era Big Data meets HPC Some facts about Big Data Technologies HPC and Big Data converging
HadoopRDF : A Scalable RDF Data Analysis System
 HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
HadoopRDF : A Scalable RDF Data Analysis System Yuan Tian 1, Jinhang DU 1, Haofen Wang 1, Yuan Ni 2, and Yong Yu 1 1 Shanghai Jiao Tong University, Shanghai, China {tian,dujh,whfcarter}@apex.sjtu.edu.cn
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster. A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech
 OIT/ART, Georgia Tech") Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
Linux Clusters Ins.tute: Turning HPC cluster into a Big Data Cluster Fang (Cherry) Liu, PhD fang.liu@oit.gatech.edu A Partnership for an Advanced Compu@ng Environment (PACE) OIT/ART, Georgia Tech Targets
How To Create A Data Visualization With Apache Spark And Zeppelin 2.5.3.5
 Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Big Data Visualization using Apache Spark and Zeppelin Prajod Vettiyattil, Software Architect, Wipro Agenda Big Data and Ecosystem tools Apache Spark Apache Zeppelin Data Visualization Combining Spark
Consulting and Systems Integration (1) Networks & Cloud Integration Engineer
 Networks & Cloud Integration Engineer") Ericsson is a world-leading provider of telecommunications equipment & services to mobile & fixed network operators. Over 1,000 networks in more than 180 countries use Ericsson equipment, & more than 40
Ericsson is a world-leading provider of telecommunications equipment & services to mobile & fixed network operators. Over 1,000 networks in more than 180 countries use Ericsson equipment, & more than 40
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Hadoop: A Framework for Data- Intensive Distributed Computing. CS561-Spring 2012 WPI, Mohamed Y. Eltabakh
 1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
1 Hadoop: A Framework for Data- Intensive Distributed Computing CS561-Spring 2012 WPI, Mohamed Y. Eltabakh 2 What is Hadoop? Hadoop is a software framework for distributed processing of large datasets
Hadoop and Map-Reduce. Swati Gore
 Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
Hadoop and Map-Reduce Swati Gore Contents Why Hadoop? Hadoop Overview Hadoop Architecture Working Description Fault Tolerance Limitations Why Map-Reduce not MPI Distributed sort Why Hadoop? Existing Data
BIG DATA What it is and how to use?
 BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
BIG DATA What it is and how to use? Lauri Ilison, PhD Data Scientist 21.11.2014 Big Data definition? There is no clear definition for BIG DATA BIG DATA is more of a concept than precise term 1 21.11.14
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments
 Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2016 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Cloudera Enterprise Reference Architecture for Google Cloud Platform Deployments Important Notice 2010-2016 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, Impala, and
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Hadoop Overview, Customer Evolution and Dell In-Memory Product Details Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Introduction to Big Data Analytics p. 1 Big Data Overview p. 2 Data Structures p. 5 Analyst Perspective on Data Repositories p.
 Introduction p. xvii Introduction to Big Data Analytics p. 1 Big Data Overview p. 2 Data Structures p. 5 Analyst Perspective on Data Repositories p. 9 State of the Practice in Analytics p. 11 BI Versus
Introduction p. xvii Introduction to Big Data Analytics p. 1 Big Data Overview p. 2 Data Structures p. 5 Analyst Perspective on Data Repositories p. 9 State of the Practice in Analytics p. 11 BI Versus
DduP Towards a Deduplication Framework utilising Apache Spark
 DduP Towards a Deduplication Framework utilising Apache Spark Niklas Wilcke Datenbanken und Informationssysteme (ISYS) University of Hamburg Vogt-Koelln-Strasse 30 22527 Hamburg 1wilcke@informatik.uni-hamburg.de
DduP Towards a Deduplication Framework utilising Apache Spark Niklas Wilcke Datenbanken und Informationssysteme (ISYS) University of Hamburg Vogt-Koelln-Strasse 30 22527 Hamburg 1wilcke@informatik.uni-hamburg.de
HYBRID CLOUD SUPPORT FOR LARGE SCALE ANALYTICS AND WEB PROCESSING. Navraj Chohan, Anand Gupta, Chris Bunch, Kowshik Prakasam, and Chandra Krintz
 HYBRID CLOUD SUPPORT FOR LARGE SCALE ANALYTICS AND WEB PROCESSING Navraj Chohan, Anand Gupta, Chris Bunch, Kowshik Prakasam, and Chandra Krintz Overview Google App Engine (GAE) GAE Analytics Libraries
HYBRID CLOUD SUPPORT FOR LARGE SCALE ANALYTICS AND WEB PROCESSING Navraj Chohan, Anand Gupta, Chris Bunch, Kowshik Prakasam, and Chandra Krintz Overview Google App Engine (GAE) GAE Analytics Libraries
Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software. SC13, November, 2013
 Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software SC13, November, 2013 Agenda Abstract Opportunity: HPC Adoption of Big Data Analytics on Apache
Intel HPC Distribution for Apache Hadoop* Software including Intel Enterprise Edition for Lustre* Software SC13, November, 2013 Agenda Abstract Opportunity: HPC Adoption of Big Data Analytics on Apache
ESS event: Big Data in Official Statistics. Antonino Virgillito, Istat
 ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
ESS event: Big Data in Official Statistics Antonino Virgillito, Istat v erbi v is 1 About me Head of Unit Web and BI Technologies, IT Directorate of Istat Project manager and technical coordinator of Web
The Greenplum Analytics Workbench
 The Greenplum Analytics Workbench External Overview 1 The Greenplum Analytics Workbench Definition Is a 1000-node Hadoop Cluster. Pre-configured with publicly available data sets. Contains the entire Hadoop
The Greenplum Analytics Workbench External Overview 1 The Greenplum Analytics Workbench Definition Is a 1000-node Hadoop Cluster. Pre-configured with publicly available data sets. Contains the entire Hadoop
Large scale processing using Hadoop. Ján Vaňo
 Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Large scale processing using Hadoop Ján Vaňo What is Hadoop? Software platform that lets one easily write and run applications that process vast amounts of data Includes: MapReduce offline computing engine
Scalable Cloud Computing Solutions for Next Generation Sequencing Data
 Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Scalable Cloud Computing Solutions for Next Generation Sequencing Data Matti Niemenmaa 1, Aleksi Kallio 2, André Schumacher 1, Petri Klemelä 2, Eija Korpelainen 2, and Keijo Heljanko 1 1 Department of
Infomatics. Big-Data and Hadoop Developer Training with Oracle WDP
 Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
Big-Data and Hadoop Developer Training with Oracle WDP What is this course about? Big Data is a collection of large and complex data sets that cannot be processed using regular database management tools
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Buzzwords Berlin - 2015 Big data analytics / machine
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Buzzwords Berlin - 2015 Big data analytics / machine
Collaborative Big Data Analytics. Copyright 2012 EMC Corporation. All rights reserved.
 Collaborative Big Data Analytics 1 Big Data Is Less About Size, And More About Freedom TechCrunch!!!!!!!!! Total data: bigger than big data 451 Group Findings: Big Data Is More Extreme Than Volume Gartner!!!!!!!!!!!!!!!
Collaborative Big Data Analytics 1 Big Data Is Less About Size, And More About Freedom TechCrunch!!!!!!!!! Total data: bigger than big data 451 Group Findings: Big Data Is More Extreme Than Volume Gartner!!!!!!!!!!!!!!!
MapReduce and Hadoop. Aaron Birkland Cornell Center for Advanced Computing. January 2012
 MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
MapReduce and Hadoop Aaron Birkland Cornell Center for Advanced Computing January 2012 Motivation Simple programming model for Big Data Distributed, parallel but hides this Established success at petabyte
Real-time Data Analytics mit Elasticsearch. Bernhard Pflugfelder inovex GmbH
 Real-time Data Analytics mit Elasticsearch Bernhard Pflugfelder inovex GmbH Bernhard Pflugfelder Big Data Engineer @ inovex Fields of interest: search analytics big data bi Working with: Lucene Solr Elasticsearch
Real-time Data Analytics mit Elasticsearch Bernhard Pflugfelder inovex GmbH Bernhard Pflugfelder Big Data Engineer @ inovex Fields of interest: search analytics big data bi Working with: Lucene Solr Elasticsearch
Big Business, Big Data, Industrialized Workload
 Big Business, Big Data, Industrialized Workload Big Data Big Data 4 Billion 600TB London - NYC 1 Billion by 2020 100 Million Giga Bytes Copyright 3/20/2014 BMC Software, Inc 2 Copyright 3/20/2014 BMC Software,
Big Business, Big Data, Industrialized Workload Big Data Big Data 4 Billion 600TB London - NYC 1 Billion by 2020 100 Million Giga Bytes Copyright 3/20/2014 BMC Software, Inc 2 Copyright 3/20/2014 BMC Software,
Manifest for Big Data Pig, Hive & Jaql
 Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
Manifest for Big Data Pig, Hive & Jaql Ajay Chotrani, Priyanka Punjabi, Prachi Ratnani, Rupali Hande Final Year Student, Dept. of Computer Engineering, V.E.S.I.T, Mumbai, India Faculty, Computer Engineering,
BIG DATA APPLICATIONS
 BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
BIG DATA ANALYTICS USING HADOOP AND SPARK ON HATHI Boyu Zhang Research Computing ITaP BIG DATA APPLICATIONS Big data has become one of the most important aspects in scientific computing and business analytics
Integrating a Big Data Platform into Government:
 Integrating a Big Data Platform into Government: Drive Better Decisions for Policy and Program Outcomes John Haddad, Senior Director Product Marketing, Informatica Digital Government Institute s Government
Integrating a Big Data Platform into Government: Drive Better Decisions for Policy and Program Outcomes John Haddad, Senior Director Product Marketing, Informatica Digital Government Institute s Government
A Brief Introduction to Apache Tez
 A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
A Brief Introduction to Apache Tez Introduction It is a fact that data is basically the new currency of the modern business world. Companies that effectively maximize the value of their data (extract value
HADOOP BIG DATA DEVELOPER TRAINING AGENDA
 HADOOP BIG DATA DEVELOPER TRAINING AGENDA About the Course This course is the most advanced course available to Software professionals This has been suitably designed to help Big Data Developers and experts
HADOOP BIG DATA DEVELOPER TRAINING AGENDA About the Course This course is the most advanced course available to Software professionals This has been suitably designed to help Big Data Developers and experts
Cost-Effective Business Intelligence with Red Hat and Open Source
 Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
Cost-Effective Business Intelligence with Red Hat and Open Source Sherman Wood Director, Business Intelligence, Jaspersoft September 3, 2009 1 Agenda Introductions Quick survey What is BI?: reporting,
CSE-E5430 Scalable Cloud Computing Lecture 11
 CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 30.11-2015 1/24 Distributed Coordination Systems Consensus
CSE-E5430 Scalable Cloud Computing Lecture 11 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 30.11-2015 1/24 Distributed Coordination Systems Consensus
Implement Hadoop jobs to extract business value from large and varied data sets
 Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
Hadoop Development for Big Data Solutions: Hands-On You Will Learn How To: Implement Hadoop jobs to extract business value from large and varied data sets Write, customize and deploy MapReduce jobs to
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop)
 Lecture 10 ( MapReduce& Hadoop)") CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
CSE 590: Special Topics Course ( Supercomputing ) Lecture 10 ( MapReduce& Hadoop) Rezaul A. Chowdhury Department of Computer Science SUNY Stony Brook Spring 2016 MapReduce MapReduce is a programming model
ANALYTICS CENTER LEARNING PROGRAM
 Overview of Curriculum ANALYTICS CENTER LEARNING PROGRAM The following courses are offered by Analytics Center as part of its learning program: Course Duration Prerequisites 1- Math and Theory 101 - Fundamentals
Overview of Curriculum ANALYTICS CENTER LEARNING PROGRAM The following courses are offered by Analytics Center as part of its learning program: Course Duration Prerequisites 1- Math and Theory 101 - Fundamentals
How To Scale Out Of A Nosql Database
 Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
Firebird meets NoSQL (Apache HBase) Case Study Firebird Conference 2011 Luxembourg 25.11.2011 26.11.2011 Thomas Steinmaurer DI +43 7236 3343 896 thomas.steinmaurer@scch.at www.scch.at Michael Zwick DI
CSE-E5430 Scalable Cloud Computing. Lecture 4
 Lecture 4 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 5.10-2015 1/23 Hadoop - Linux of Big Data Hadoop = Open Source Distributed Operating System
Lecture 4 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 5.10-2015 1/23 Hadoop - Linux of Big Data Hadoop = Open Source Distributed Operating System
BIG DATA TRENDS AND TECHNOLOGIES
 BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA TRENDS AND TECHNOLOGIES THE WORLD OF DATA IS CHANGING Cloud WHAT IS BIG DATA? Big data are datasets that grow so large that they become awkward to work with using onhand database management tools.
BIG DATA. Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management. Author: Sandesh Deshmane
 BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
BIG DATA Using the Lambda Architecture on a Big Data Platform to Improve Mobile Campaign Management Author: Sandesh Deshmane Executive Summary Growing data volumes and real time decision making requirements
Testing Big data is one of the biggest
 Infosys Labs Briefings VOL 11 NO 1 2013 Big Data: Testing Approach to Overcome Quality Challenges By Mahesh Gudipati, Shanthi Rao, Naju D. Mohan and Naveen Kumar Gajja Validate data quality by employing
Infosys Labs Briefings VOL 11 NO 1 2013 Big Data: Testing Approach to Overcome Quality Challenges By Mahesh Gudipati, Shanthi Rao, Naju D. Mohan and Naveen Kumar Gajja Validate data quality by employing
Real Time Big Data Processing
 Real Time Big Data Processing Cloud Expo 2014 Ian Meyers Amazon Web Services Global Infrastructure Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Real Time Big Data Processing Cloud Expo 2014 Ian Meyers Amazon Web Services Global Infrastructure Deployment & Administration App Services Analytics Compute Storage Database Networking AWS Global Infrastructure
Scalable Architecture on Amazon AWS Cloud
 Scalable Architecture on Amazon AWS Cloud Kalpak Shah Founder & CEO, Clogeny Technologies kalpak@clogeny.com 1 * http://www.rightscale.com/products/cloud-computing-uses/scalable-website.php 2 Architect
Scalable Architecture on Amazon AWS Cloud Kalpak Shah Founder & CEO, Clogeny Technologies kalpak@clogeny.com 1 * http://www.rightscale.com/products/cloud-computing-uses/scalable-website.php 2 Architect
What's New in SAS Data Management
 Paper SAS034-2014 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC; Mike Frost, SAS Institute Inc., Cary, NC, Mike Ames, SAS Institute Inc., Cary ABSTRACT The latest releases
Paper SAS034-2014 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC; Mike Frost, SAS Institute Inc., Cary, NC, Mike Ames, SAS Institute Inc., Cary ABSTRACT The latest releases
A Brief Outline on Bigdata Hadoop
 A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
A Brief Outline on Bigdata Hadoop Twinkle Gupta 1, Shruti Dixit 2 RGPV, Department of Computer Science and Engineering, Acropolis Institute of Technology and Research, Indore, India Abstract- Bigdata is
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000
 Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Leveraging BlobSeer to boost up the deployment and execution of Hadoop applications in Nimbus cloud environments on Grid 5000 Alexandra Carpen-Amarie Diana Moise Bogdan Nicolae KerData Team, INRIA Outline
Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box
 Installation and Configuration on Virtual Box") Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box By Kavya Mugadur W1014808 1 Table of contents 1.What is CDH? 2. Hadoop Basics 3. Ways to install CDH 4. Installation and
Cloudera Distributed Hadoop (CDH) Installation and Configuration on Virtual Box By Kavya Mugadur W1014808 1 Table of contents 1.What is CDH? 2. Hadoop Basics 3. Ways to install CDH 4. Installation and
Big Data & QlikView. Democratizing Big Data Analytics. David Freriks Principal Solution Architect
 Big Data & QlikView Democratizing Big Data Analytics David Freriks Principal Solution Architect TDWI Vancouver Agenda What really is Big Data? How do we separate hype from reality? How does that relate
Big Data & QlikView Democratizing Big Data Analytics David Freriks Principal Solution Architect TDWI Vancouver Agenda What really is Big Data? How do we separate hype from reality? How does that relate
HPCHadoop: MapReduce on Cray X-series
 HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology
HPCHadoop: MapReduce on Cray X-series Scott Michael Research Analytics Indiana University Cray User Group Meeting May 7, 2014 1 Outline Motivation & Design of HPCHadoop HPCHadoop demo Benchmarking Methodology